NLP
NLP代表自然语言处理,是关于计算机和人类语言之间交互的领域。NLP涵盖了一系列任务,包括文本处理、语音识别、语言翻译、信息检索等。NLP技术的发展使得计算机能够理解、解释和生成人类语言,促进了许多领域的发展,包括智能助手、文本分析、情感分析等。
LLM
LLM指的是大型语言模型(Large Language Models),是一类基于深度学习的模型,用于处理自然语言处理任务(NLP)。NLP是关于计算机和人类语言之间交互的领域,是一种概念;而LLM是一类基于深度学习的大型语言模型,是一种。
常见LLM模型:
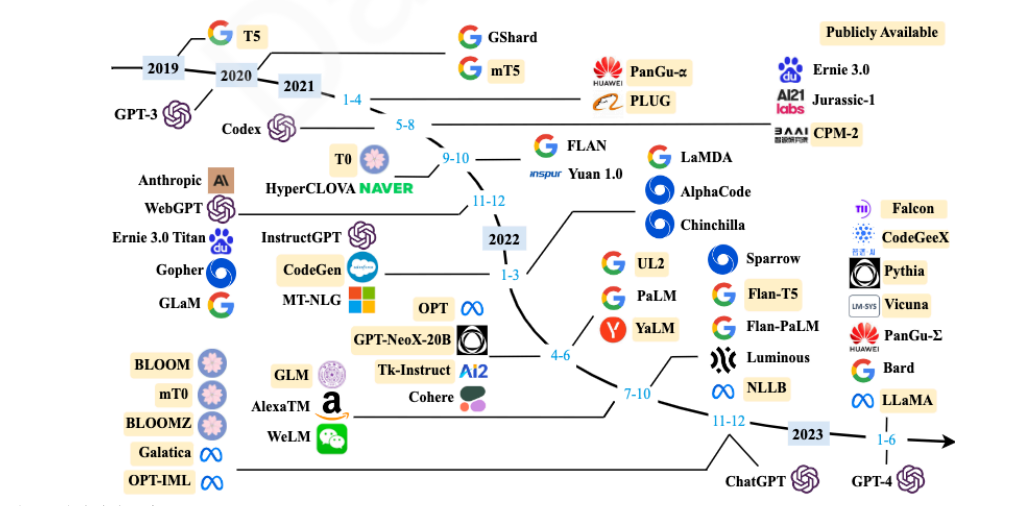
- 闭源LLM:ChatGPT(OpenAI)、Claude(Anthropic)、PaLM/Gemini(Google)、文心一言(百度)、星⽕⼤模型(讯⻜)..
- 开源LLM:LLama(Meta)、通义千问(阿里巴巴)、ChatGLM(清华+智谱)、Baichuan(百川智能)..
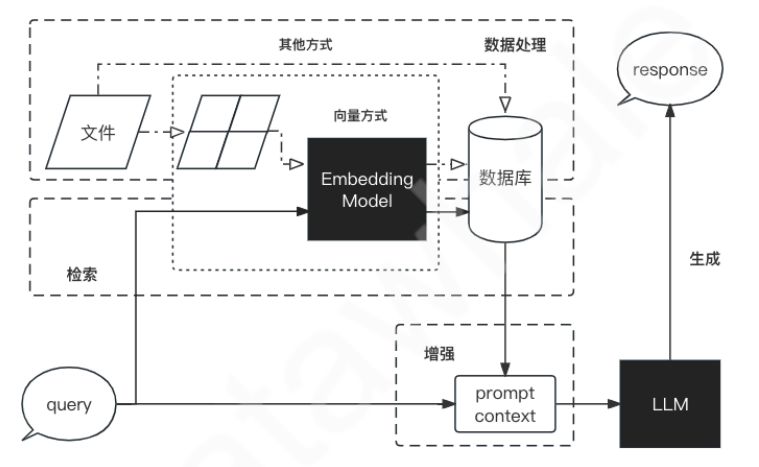
RAG
检索增强⽣成(RAG, Retrieval-Augmented Generation),一种架构,通过融合检索模块和生成模块,提供更加准确和连贯的文本生成能力。整合了从庞⼤知识库中检索到的相关信息,并以此为基础,指导⼤型语⾔模型⽣成更为精准的答案,从⽽显著提升了回答的准确性与深度。
工作流:
Finetune
微调,通过在特定数据集上进⼀步训练⼤语⾔模型,来提升模型在特定任务上的表现。
LangChain
LangChain是一个用于构建基于语言模型的应用程序的框架。它的设计目标是帮助开发者更方便地使用大型语言模型并将其集成到实际应用中。LangChain提供了一系列工具和组件,使得开发者能够更容易地进行任务如生成文本、问答、对话系统等。
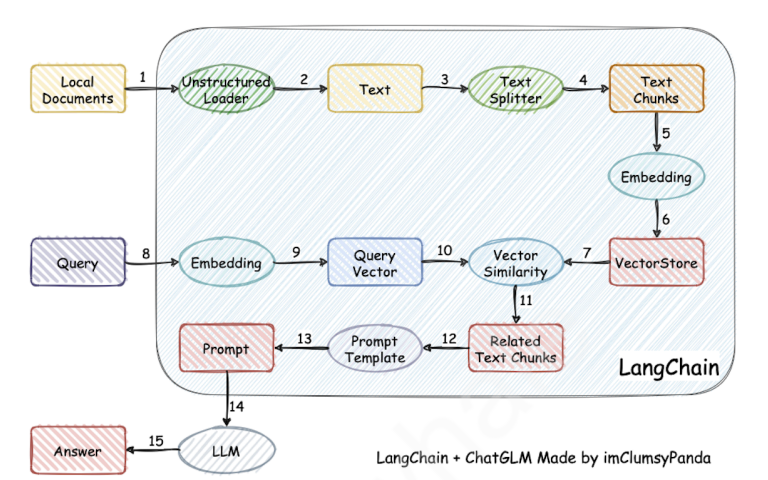
Embeddings
也叫词向量,一种文本嵌入技术,文本嵌入技术的核心思想是将文本中的单词、短语或句子映射到高维向量空间中。这些向量空间中的点表示文本单位,并且相似的文本单位在向量空间中应该距离较近。通过这种方式,文本嵌入可以捕捉到词语之间的语义关系。
向量数据库
存储经过了Embeddings的向量数据。向量数据库是⽤于⾼效计算和管理⼤量向量数据的解决⽅案。向量数据库是⼀种专⻔⽤于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是向量数据的特性和相似性。
Prompt
提示词,分为系统提示词、用户提示词。
- System Prompt:在整个会话过程中持久地影响模型的回复,且相⽐于普通Prompt 具有更⾼的重要性。(如:设定模型始终模拟一个幽默的助理)
- User Prompt:用户给模型的原始输入。
所谓的提示词工程Prompt Engineering便是通过更加合理的输入,让大模型理解问题,以输出最合理的答案。
temperature参数
LLM中的温度参数,控制模型输出的随机性和多样性的重要超参数。它通常用于采样生成文本的过程,尤其是在生成式任务中,如文本生成、对话系统等。temperature 参数可以影响生成文本的样式和内容。
Temperature ⼀般取值在 0~1 之间,当取值较低接近 0 时,预测的随机性会较低,产⽣更保守、可预测的⽂本,不太可能⽣成意想不到或不寻常的词。当取值较⾼接近 1 时,预测的随机性会较⾼,所有词被选择的可能性更⼤,会产⽣更有创意、多样化的⽂本,更有可能⽣成不寻常或意想不到的词。
Transformer
是一种深度学习模型架构,最初用于自然语言处理任务,ChatGPT就是基于此架构开发的。
TensorFlow、PyTorch
TensorFlow(谷歌)和 PyTorch(Meta)为最受欢迎的两个深度学习开源框架,它们提供了丰富的算法库和工具,支持研究者和开发人员高效地实现复杂的神经网络模型。
预训练
使用海量的训练数据(纯文本,没有QA),这些数据可以来自互联网网页、维基百科、书籍、GitHub、论文、问答网站等,构建包含数千亿甚至数万亿单词的具有多样性的内容,经过数千块高性能GPU和高速网络组成的超级计算机,花费数十天甚至数月的时间完成深度神经网络参数的训练,构建基础模型(Foundation Model),也叫基座模型。
此时,基础模型能够对长文本进行建模,具备语言生成能力,根据输入的提示词,模型可以生成文本补全句子。
有监督微调/指令微调
在已经预训练好的模型基础上,通过使用有标注的特定任务数据(QA)对模型进行进一步的训练和调整,以提高模型在特定任务或领域上的性能。
奖励模型
文本质量对比模型,它接受环境状态、生成的结果等信息作为输入,并输出一个奖励值作为反馈。奖励模型通过训练,能够识别并区分不同输出文本之间的优劣,为后续的强化学习阶段提供准确的奖励信号。
强化学习
根据数十万名用户给出的提示词,利用前一阶段训练的奖励模型,给出SFT模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。
模型量化
模型量化就是将浮点存储(运算)转换为整型存储(运算)的一种模型压缩技术。简单直白点讲,即原来表示一个权重需要使用float32表示,量化后只需要使用int8来表示就可以啦,仅仅这一个操作,就可以获得接近4倍的网络加速。
Agent
应用于特定领域的智能体,如医疗、教育、金融、娱乐等。