步骤1:购买并配置华为云服务器
1.1 注册华为云账号
- 访问华为云官网:打开浏览器,访问 华为云官网。
- 注册账号:
- 点击页面右上角的“注册”按钮。
- 按照提示填写必要的信息(邮箱、密码、验证码等)完成注册。
- 可能需要验证邮箱,请按照邮件中的指示完成验证。
1.2 登录华为云控制台
- 登录账号:使用刚注册的账号和密码登录华为云控制台。
- 实名认证:
- 如果是首次登录,可能需要进行实名认证。按照提示提交相关身份证明文件,完成实名认证。
1.3 创建弹性云服务器(ECS)
-
进入ECS控制台:
- 登录后,点击页面顶部导航栏中的“产品”。
- 在下拉菜单中选择“弹性云服务器”。
-
创建服务器:
- 点击“创建弹性云服务器”按钮。
-
选择镜像:
- 在“选择镜像”页面,选择
openEuler操作系统。 - 推荐选择
openEuler 22.03-LTS-SP2,点击选择。
- 在“选择镜像”页面,选择
-
选择规格:
- 根据需求选择合适的实例规格。
- 推荐配置:
- CPU:至少4核。
- 内存:8GB及以上。
- 点击“下一步”。
-
选择网络:
- 选择已有的网络或创建新的VPC(虚拟私有云)。
- 确保服务器具有公网IP地址,以便从Windows远程连接。
- 点击“下一步”。
-
配置登录凭证:
- 登录方式:选择“密码登录”。
- 设置密码:输入并确认root用户的密码。请记住此密码。
- 点击“下一步”。
-
存储配置:
- 根据需求选择系统盘和数据盘的大小。
- 默认配置通常已足够,点击“下一步”。
-
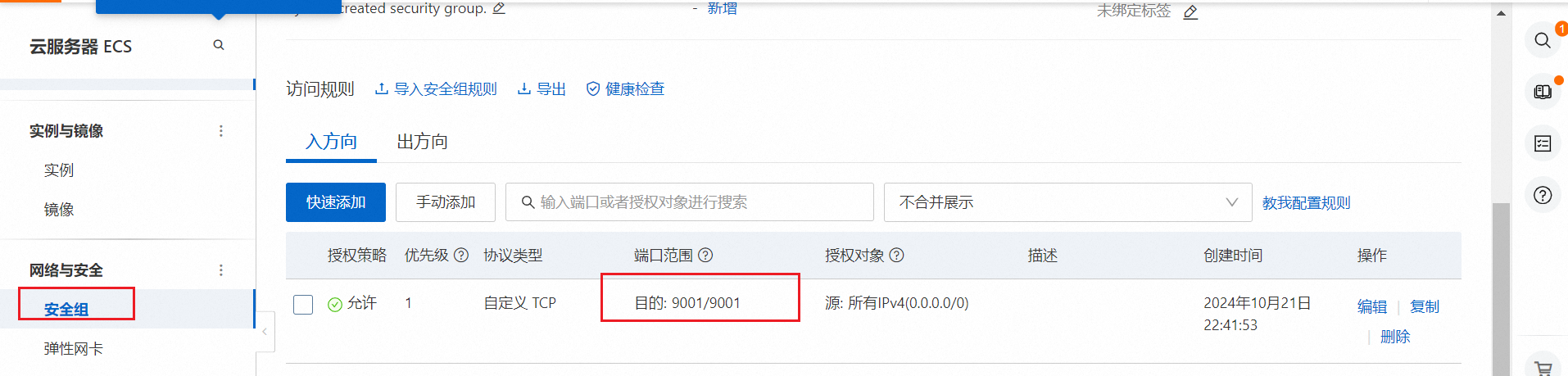
安全组配置:
- 安全组:选择默认安全组或创建新的安全组。
- 开放端口:确保至少开放22端口(SSH)。
- 点击“下一步”。
-
确认订单并创建:
- 检查所有配置是否正确。
- 点击“立即购买”完成服务器创建。
-
获取服务器信息:
- 创建完成后,在ECS管理列表中找到新创建的服务器。
- 记录下服务器的公网IP地址。
步骤2:连接到服务器
你可以使用PuTTY或Windows自带的SSH客户端连接到你的服务器。以下以PuTTY为例进行说明。
2.1 下载并安装PuTTY
-
下载PuTTY:
- 访问 PuTTY官网。
- 下载适用于Windows的最新版本PuTTY安装包。
-
安装PuTTY:
- 双击下载的安装包,按照提示完成安装。
2.2 使用PuTTY连接服务器
-
打开PuTTY:
- 安装完成后,双击桌面上的PuTTY图标打开程序。
-
配置连接:
- Host Name (or IP address):输入你的服务器公网IP地址(如
123.45.67.89)。 - Port:默认是
22。 - Connection type:选择
SSH。
- Host Name (or IP address):输入你的服务器公网IP地址(如
-
保存会话(可选):
- 在“Saved Sessions”字段输入一个名称,如
openEuler Server。 - 点击“Save”按钮,方便下次快速连接。
- 在“Saved Sessions”字段输入一个名称,如
-
连接:
- 点击“Open”按钮。
-
接受安全警告:
- 第一次连接时,PuTTY会弹出一个安全警告窗口,点击“是”继续。
-
登录:
- Login as:输入
root,按Enter。 - Password:输入你在创建服务器时设置的密码(输入时不会显示),按
Enter。
注意:如果密码输入错误,请重新尝试或检查服务器设置。
- Login as:输入
步骤3:获取GCC for openEuler软件包到服务器(从本机上传)
为了将本地的gcc-10.3.1-2024.08-aarch64-linux.tar.gz上传到服务器,可以使用WinSCP工具。
3.1 下载并安装WinSCP
-
下载WinSCP:
- 访问 WinSCP官网。
- 下载最新版本的WinSCP安装包。
-
安装WinSCP:
- 双击下载的安装包,按照提示完成安装。
3.2 使用WinSCP上传文件
-
打开WinSCP:
- 安装完成后,启动WinSCP。
-
配置连接:
- File protocol:选择
SFTP。 - Hostname:输入你的服务器公网IP地址(如
123.45.67.89)。 - Port number:默认是
22。 - Username:输入
root。 - Password:输入你在创建服务器时设置的密码。
- File protocol:选择
-
连接服务器:
- 点击“Login”按钮连接服务器。
- 如果是第一次连接,可能会提示确认服务器的主机密钥,点击“是”继续。
-
上传文件:
-
左侧窗口:显示你本地的文件系统。
-
右侧窗口:显示服务器的文件系统。
-
导航到你下载的
gcc-10.3.1-2024.08-aarch64-linux.tar.gz文件所在的本地目录。 -
在服务器端,导航到
/opt/aarch64/compiler目录。如果该目录不存在,可以先在服务器端创建。创建目录:
- 在服务器端窗口中,右键点击空白区域,选择“New” > “Directory”。
- 输入目录名
compiler,点击“OK”。 - 重复上述操作在
/opt/aarch64下创建compiler目录(如果尚未存在)。
-
将
gcc-10.3.1-2024.08-aarch64-linux.tar.gz文件从左侧窗口拖拽到右侧窗口的/opt/aarch64/compiler目录中。
-
-
确认上传:
- 上传完成后,在服务器端的
/opt/aarch64/compiler目录下应该能看到gcc-10.3.1-2024.08-aarch64-linux.tar.gz文件。
- 上传完成后,在服务器端的
步骤4:安装GCC for openEuler
4.1 创建安装目录
-
登录到服务器:
- 使用PuTTY登录到你的服务器(参考步骤2)。
-
创建安装目录:
- 执行以下命令创建安装目录:
mkdir -p /opt/aarch64/compilermkdir:创建目录。-p:递归创建父目录,如果父目录不存在则一并创建。
- 执行以下命令创建安装目录:
-
进入安装目录:
cd /opt/aarch64/compiler
4.2 将软件包上传到服务器
注意:如果你已经通过WinSCP将文件上传到/opt/aarch64/compiler,可以跳过此步骤。如果还未上传,请参考步骤3。
4.3 解压缩软件包
-
查看当前目录内容:
ls- 确认
gcc-10.3.1-2024.08-aarch64-linux.tar.gz文件存在。
- 确认
-
解压缩软件包:
tar -xf gcc-10.3.1-2024.08-aarch64-linux.tar.gztar:Unix下常用的打包工具。-x:解包。-f:指定文件名。
-
查看解压后的内容:
ls- 应该看到一个名为
gcc-10.3.1-2024.08-aarch64-linux的目录。
- 应该看到一个名为
步骤5:配置环境变量
配置环境变量可以让系统识别新安装的GCC编译器。你有两种方式来配置环境变量:编辑/etc/profile文件或使用environment-modules工具。这里推荐使用编辑/etc/profile的方法,因为它更简单。
5.1 编辑/etc/profile文件
-
打开
/etc/profile文件:vi /etc/profilevi:一种文本编辑器。/etc/profile:系统级环境变量配置文件。
-
进入插入模式:
- 按下
i键,进入插入模式。
- 按下
-
添加环境变量配置:
在文件末尾添加以下内容:# GCC for openEuler 环境变量配置 export PATH=/opt/aarch64/compiler/gcc-10.3.1-2024.08-aarch64-linux/bin:$PATH export INCLUDE=/opt/aarch64/compiler/gcc-10.3.1-2024.08-aarch64-linux/include:$INCLUDE export LD_LIBRARY_PATH=/opt/aarch64/compiler/gcc-10.3.1-2024.08-aarch64-linux/lib64:$LD_LIBRARY_PATH解释:
PATH:告诉系统在执行命令时在哪些目录查找可执行文件。INCLUDE:指定编译器的头文件目录。LD_LIBRARY_PATH:指定系统在运行程序时查找共享库的路径。
-
保存并退出:
- 按下
Esc键退出插入模式。 - 输入
:wq,然后按Enter键保存并退出vi编辑器。
- 按下
5.2 使环境变量生效
- 执行以下命令:
source /etc/profilesource:在当前shell中读取并执行指定文件中的命令。- 这样,无需重新登录,环境变量的更改立即生效。
5.3 验证环境变量配置
-
查看
PATH环境变量:echo $PATH- 确认输出中包含
/opt/aarch64/compiler/gcc-10.3.1-2024.08-aarch64-linux/bin。
- 确认输出中包含
-
查看
INCLUDE环境变量:echo $INCLUDE- 确认输出中包含
/opt/aarch64/compiler/gcc-10.3.1-2024.08-aarch64-linux/include。
- 确认输出中包含
-
查看
LD_LIBRARY_PATH环境变量:echo $LD_LIBRARY_PATH- 确认输出中包含
/opt/aarch64/compiler/gcc-10.3.1-2024.08-aarch64-linux/lib64。
- 确认输出中包含
5.4 注意事项
-
安装路径不同:如果你的安装路径与上述不同,请相应修改环境变量中的路径。
例如,如果安装在
/usr/local/gcc-10.3.1,则配置应为:export PATH=/usr/local/gcc-10.3.1/bin:$PATH export INCLUDE=/usr/local/gcc-10.3.1/include:$INCLUDE export LD_LIBRARY_PATH=/usr/local/gcc-10.3.1/lib64:$LD_LIBRARY_PATH -
顺序重要:确保新添加的路径在
$PATH等变量的前面,否则系统会优先使用默认路径下的GCC版本。
步骤6:验证安装
6.1 检查GCC版本
-
执行以下命令:
gcc -v- 你应该看到类似如下的输出:
Using built-in specs. COLLECT_GCC=gcc COLLECT_LTO_WRAPPER=/opt/aarch64/compiler/gcc-10.3.1-2024.08-aarch64-linux/libexec/gcc/aarch64-linux-gnu/10.3.1/lto-wrapper Target: aarch64-linux-gnu Configured with: ... (相关配置) Thread model: posix Supported LTO compression algorithms: zlib zstd gcc version 10.3.1 (gcc for openEuler 2.3.8)
注意:
gcc version行应显示你安装的GCC for openEuler版本信息,如gcc for openEuler 2.3.8。- 如果显示的是其他版本,如系统默认的GCC,请检查环境变量配置是否正确。
- 你应该看到类似如下的输出:
6.2 解决可能的问题
-
命令未找到:
- 确认环境变量
PATH是否正确配置,且包含了GCC的bin目录。 - 确认GCC软件包是否正确上传并解压。
- 确认环境变量
-
版本不正确:
- 确认解压的目录是否正确,且环境变量指向正确的GCC安装路径。
- 重新执行
source /etc/profile,确保环境变量已生效。
用到的命令简要说明
以下是安装过程中用到的一些常用命令及其说明,供参考:
-
mkdir -p /path/to/directory:- 创建一个目录,包括必要的父目录。
- 例如:
mkdir -p /opt/aarch64/compiler。
-
cd /path/to/directory:- 切换当前工作目录到指定路径。
- 例如:
cd /opt/aarch64/compiler。
-
ls:- 列出当前目录下的文件和子目录。
- 常用选项:
-l:长格式显示,包含详细信息。-a:显示所有文件,包括隐藏文件。
-
tar -xf file.tar.gz:- 解压缩
.tar.gz文件。 -x:解包。-f:指定文件名。
- 解压缩
-
vi /etc/profile:- 使用
vi编辑器打开/etc/profile文件。 - 基本操作:
i:进入插入模式。Esc:退出插入模式。:wq:保存并退出。:q!:不保存强制退出。
- 使用
-
echo $VARIABLE:- 显示环境变量
VARIABLE的值。 - 例如:
echo $PATH。
- 显示环境变量
-
source /etc/profile:- 重新加载
/etc/profile文件,使环境变量更改立即生效。
- 重新加载
-
gcc -v:- 显示GCC的版本信息。
步骤7:测试向量化
系统中已经安装了一个较为标准的GCC(版本为10.3.1),但是目前默认GCC版本是GCC for openEuler(12.3.1),并且这个编译器路径指向了 /opt/aarch64/compiler/...。
目标:我们需要将两个版本的GCC区分开,以便在实验中分别使用它们。你可以通过指定不同的路径来调用系统的GCC 10.3.1和GCC for openEuler 12.3.1进行对比实验。
修改环境配置以使用系统的GCC 10.3.1
目前which gcc返回的是 /opt/aarch64/compiler/...,这意味着系统路径被GCC for openEuler覆盖了。我们需要区分两个版本的GCC。
直接调用GCC的完整路径
直接使用GCC编译器的完整路径来调用不同的版本,从而确保使用的是希望的GCC编译器。
-
系统标准GCC(版本10.3.1):
- 系统GCC通常安装在
/usr/bin/gcc,可以通过直接调用完整路径来使用:
/usr/bin/gcc --version这将显示系统标准GCC的版本。
- 系统GCC通常安装在
-
GCC for openEuler(版本12.3.1):
- 你已经知道GCC for openEuler的路径是
/opt/aarch64/compiler/gcc-12.3.1-2024.09-aarch64-linux/bin/gcc。 - 可以通过调用完整路径来使用这个版本:
/opt/aarch64/compiler/gcc-12.3.1-2024.09-aarch64-linux/bin/gcc --version - 你已经知道GCC for openEuler的路径是
具体实验步骤
分别使用系统标准GCC和GCC for openEuler来编译和运行程序,并进行对比。
1. 创建并编辑矩阵乘法程序
-
创建或进入工作目录:
- 路径:
/home/gcc_experiment
mkdir -p /home/gcc_experiment cd /home/gcc_experiment - 路径:
-
创建C文件:
- 文件路径:
/home/gcc_experiment/matrix_mul.c
vi matrix_mul.c- 在编辑器中粘贴以下代码:
- 文件路径:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <omp.h>void multiply(int n, double **A, double **B, double **C) {int i, j, k;#pragma omp parallel for private(i, j, k) shared(A, B, C)for (i = 0; i < n; i++) {for (j = 0; j < n; j++) {C[i][j] = 0.0;for (k = 0; k < n; k++) {C[i][j] += A[i][k] * B[k][j];}}}
}int main() {int i, j, n;double **A, **B, **C;clock_t start, end;for (n = 100; n <= 1500; n += 100) {// 动态分配内存A = (double **)malloc(n * sizeof(double *));B = (double **)malloc(n * sizeof(double *));C = (double **)malloc(n * sizeof(double *));for (i = 0; i < n; i++) {A[i] = (double *)malloc(n * sizeof(double));B[i] = (double *)malloc(n * sizeof(double));C[i] = (double *)malloc(n * sizeof(double));}// 初始化矩阵for (i = 0; i < n; i++) {for (j = 0; j < n; j++) {A[i][j] = rand() / (double)RAND_MAX;B[i][j] = rand() / (double)RAND_MAX;}}// 矩阵乘法start = clock();multiply(n, A, B, C);end = clock();printf("Matrix size %d: %f seconds\n", n, ((double)(end - start)) / CLOCKS_PER_SEC);// 释放内存for (i = 0; i < n; i++) {free(A[i]);free(B[i]);free(C[i]);}free(A);free(B);free(C);}return 0;
}~- 保存并退出(
Esc->:wq)。
2. 使用系统GCC(10.3.1)进行编译和运行
-
编译程序:
- 路径:仍然在
/home/gcc_experiment
/usr/bin/gcc matrix_mul.c -o matrix_mul_default -fopenmp- 这个命令使用系统默认的GCC(10.3.1)进行编译,生成可执行文件
matrix_mul_default。
- 路径:仍然在
-
运行程序并记录结果:
./matrix_mul_default > default_results.txt- 该命令将运行结果保存到文件
default_results.txt中。
- 该命令将运行结果保存到文件
3. 使用GCC for openEuler(12.3.1)进行编译和运行
-
编译程序:
- 路径:继续在
/home/gcc_experiment
/opt/aarch64/compiler/gcc-12.3.1-2024.09-aarch64-linux/bin/gcc matrix_mul.c -o matrix_mul_optimized -fopenmp -O3- 使用GCC for openEuler(12.3.1)进行编译,并且使用
-O3进行优化。
- 路径:继续在
-
运行程序并记录结果:
./matrix_mul_optimized > optimized_results.txt- 运行结果保存到
optimized_results.txt中。
- 运行结果保存到
为了确保实验准确,采取了多次测试取平均值:
# euler开向量化:-ftree-vectorize
[root@ecs-euler gcc_experiment]# /opt/aarch64/compiler/gcc-12.3.1-2024.09-aarch64-linux/bin/gcc matrix_mul.c -o matrix_mul_euler_ftree_vectorize -fopenmp -O3 -ftree-vectorize
[root@ecs-euler gcc_experiment]# ./matrix_mul_euler_ftree_vectorize > matrix_mul_euler_ftree_vectorize_1.txt
[root@ecs-euler gcc_experiment]# ./matrix_mul_euler_ftree_vectorize > matrix_mul_euler_ftree_vectorize_2.txt
[root@ecs-euler gcc_experiment]# ./matrix_mul_euler_ftree_vectorize > matrix_mul_euler_ftree_vectorize_3.txt# euler不开向量化
[root@ecs-euler gcc_experiment]# /opt/aarch64/compiler/gcc-12.3.1-2024.09-aarch64-linux/bin/gcc matrix_mul.c -o matrix_mul_euler_no_ftree_vectorize -fopenmp -O3
[root@ecs-euler gcc_experiment]# ./matrix_mul_euler_no_ftree_vectorize > matrix_mul_euler_no_ftree_vectorize_1.txt
[root@ecs-euler gcc_experiment]# ./matrix_mul_euler_no_ftree_vectorize > matrix_mul_euler_no_ftree_vectorize_2.txt
[root@ecs-euler gcc_experiment]# ./matrix_mul_euler_no_ftree_vectorize > matrix_mul_euler_no_ftree_vectorize_3.txt#默认gcc
[root@ecs-euler gcc_experiment]# /usr/bin/gcc matrix_mul.c -o matrix_mul_default -fopenmp -O3
[root@ecs-euler gcc_experiment]# ./matrix_mul_default > matrix_mul_default_1.txt
[root@ecs-euler gcc_experiment]# ./matrix_mul_default > matrix_mul_default_2.txt
[root@ecs-euler gcc_experiment]# ./matrix_mul_default > matrix_mul_default_3.txt# euler开针对鲲鹏芯片调整,开向量化
[root@ecs-euler gcc_experiment]# /opt/aarch64/compiler/gcc-12.3.1-2024.09-aarch64-linux/bin/gcc matrix_mul.c -o matrix_mul_euler_kunpeng_ftree_vectorize -fopenmp -O3 -ftree-vectorize -mcpu=thunderx2t99
[root@ecs-euler gcc_experiment]# ./matrix_mul_euler_kunpeng_ftree_vectorize > matrix_mul_euler_kunpeng_ftree_vectorize_1.txt
[root@ecs-euler gcc_experiment]# ./matrix_mul_euler_kunpeng_ftree_vectorize > matrix_mul_euler_kunpeng_ftree_vectorize_2.txt
[root@ecs-euler gcc_experiment]# ./matrix_mul_euler_kunpeng_ftree_vectorize > matrix_mul_euler_kunpeng_ftree_vectorize_3.txt4. 数据导出和分析
- 使用WinSCP将结果文件下载到本地:
- 下载上述文件到本地绘图

- 下载上述文件到本地绘图
步骤8:测试其他三个编译优化指令:
openEuler GCC 性能优化实验文档
目录
- 引言
- 测试环境
- 实验概述
- 1. 动态寻址
- 2. 浮点优化
- 3. 内存优化
- 自动化编译与运行脚本
- 结果收集与绘图
- 结论
- 故障排除
- 附加建议
引言
本文档旨在详细介绍如何通过三个不同的实验,评估 GCC for openEuler 相较于系统默认 GCC 在特定优化场景下的性能提升。每个实验针对不同的应用场景,使用相应的编译优化选项,通过编写测试程序、编译运行、记录执行时间,并最终绘制对比图,直观展示优化效果。
测试环境
在开始实验前,请确保以下环境配置正确:
- 硬件: 配备 Kunpeng 920 处理器的服务器或工作站。
- 操作系统: 最新版本的 openEuler。
- 编译器:
- GCC for openEuler: 安装路径
/opt/aarch64/compiler/gcc-12.3.1-2024.09-aarch64-linux/bin/gcc - 系统默认 GCC: 安装路径
/usr/bin/gcc(版本 10.3.1)
- GCC for openEuler: 安装路径
- 工具:
- Python: 用于绘图,建议安装
matplotlib和pandas库。pip install matplotlib pandas - 文件传输工具: 如 WinSCP,用于下载结果文件到本地计算机。
- Python: 用于绘图,建议安装
实验概述
本实验包含三个部分,每部分针对不同的性能优化场景:
- 动态寻址(Dynamic Addressing)
- 浮点优化(Float Optimization)
- 内存优化(Memory Optimization)
每个实验包括以下步骤:
- 编写测试程序
- 使用两种编译器编译程序,应用相应的优化选项
- 运行程序,记录执行时间
- 收集结果并进行对比分析
1. 动态寻址
场景:
适用于需要处理大规模数组或数据结构的应用,如科学计算、数据分析和机器学习等领域。
优化选项:
-mcmodel=large: 允许程序访问更大的数据段,适合处理超过默认模型限制的大数组。
目标:
评估使用 -mcmodel=large 选项后,程序在处理大数组时的性能改进,具体体现在执行时间的减少上。
代码说明:
该程序动态分配一个大数组,初始化数组元素后计算数组元素的和,并记录执行时间。
实验步骤:
-
创建测试程序
创建文件
dynamic_addressing.c:vi dynamic_addressing.c粘贴以下代码:
#include <stdio.h> #include <stdlib.h> #include <time.h>int main(int argc, char *argv[]) {if(argc != 2) {printf("用法: %s <N>\n", argv[0]);return 1;}long N = atol(argv[1]);double *array = malloc(N * sizeof(double));if(!array) {perror("内存分配失败");return 1;}// 初始化数组for(long i = 0; i < N; i++) {array[i] = (double)i * 0.1;}clock_t start = clock();// 简单数组求和double sum = 0.0;for(long i = 0; i < N; i++) {sum += array[i];}clock_t end = clock();double time_spent = (double)(end - start) / CLOCKS_PER_SEC;printf("%ld,%f\n", N, time_spent);free(array);return 0; } -
创建CSV文件头
echo "N,Execution Time (seconds)" > dynamic_addressing_default.csv echo "N,Execution Time (seconds)" > dynamic_addressing_openEuler.csv
2. 浮点优化
场景:
适用于需要进行大量浮点运算的应用,如图形处理、物理模拟和机器学习算法,尤其在速度优先而非精度优先的情况下。
优化选项:
-ffast-math: 启用激进的浮点优化,允许编译器重新排序浮点运算、忽略某些精度保证等,以提高计算速度。
目标:
评估启用 -ffast-math 后,程序在浮点运算中的性能提升,通过记录执行时间变化来反映优化效果。
代码说明:
该程序初始化两个浮点数组,计算它们的和并累加,记录执行时间。
实验步骤:
-
创建测试程序
创建文件
float_optimization.c:vi float_optimization.c粘贴以下代码:
#include <stdio.h> #include <math.h> #include <stdlib.h> #include <time.h>int main(int argc, char *argv[]) {if(argc != 2) {printf("用法: %s <N>\n", argv[0]);return 1;}long N = atol(argv[1]);double *a = malloc(N * sizeof(double));double *b = malloc(N * sizeof(double));double *c = malloc(N * sizeof(double));if(!a || !b || !c) {perror("内存分配失败");return 1;}// 初始化数组for(long i = 0; i < N; i++) {a[i] = sin((double)i) * sin((double)i);b[i] = cos((double)i) * cos((double)i);}clock_t start = clock();// 点积运算double sum = 0.0;for(long i = 0; i < N; i++) {c[i] = a[i] + b[i];sum += c[i];}clock_t end = clock();double time_spent = (double)(end - start) / CLOCKS_PER_SEC;printf("%ld,%f\n", N, time_spent);free(a);free(b);free(c);return 0; } -
创建CSV文件头
echo "N,Execution Time (seconds)" > float_optimization_default.csv echo "N,Execution Time (seconds)" > float_optimization_openEuler.csv
3. 内存优化
场景:
适用于对内存使用敏感的应用,如嵌入式系统、低功耗设备或需要在有限资源上运行的程序,评估编译器在内存管理方面的优化效果。
优化选项:
-fomit-frame-pointer: 指示编译器在生成代码时省略帧指针,从而减少内存占用并可能提升执行速度。
目标:
评估该优化选项对程序性能的影响,特别是在需要频繁分配和释放内存的场景中,通过记录执行时间来判断优化效果。
代码说明:
该程序动态分配一个整型数组,初始化数组元素后进行简单的冒泡排序,并记录执行时间。
实验步骤:
-
创建测试程序
创建文件
memory_optimization.c:vi memory_optimization.c粘贴以下代码:
#include <stdio.h> #include <stdlib.h> #include <time.h>int main(int argc, char *argv[]) {if(argc != 2) {printf("用法: %s <N>\n", argv[0]);return 1;}long N = atol(argv[1]);int *array = malloc(N * sizeof(int));if(!array) {perror("内存分配失败");return 1;}// 初始化数组for(long i = 0; i < N; i++) {array[i] = rand();}clock_t start = clock();// 简单排序(冒泡排序,适用于较小的 N)for(long i = 0; i < N; i++) {for(long j = 0; j < N - i - 1; j++) {if(array[j] > array[j + 1]) {int temp = array[j];array[j] = array[j + 1];array[j + 1] = temp;}}}clock_t end = clock();double time_spent = (double)(end - start) / CLOCKS_PER_SEC;printf("%ld,%f\n", N, time_spent);free(array);return 0; } -
创建CSV文件头
echo "N,Execution Time (seconds)" > memory_optimization_default.csv echo "N,Execution Time (seconds)" > memory_optimization_openEuler.csv注意:
由于冒泡排序在大数据集上的效率极低,建议将N的最大值限制在 15000 以内,以确保合理的执行时间。
自动化编译与运行脚本
为了简化实验过程,创建一个脚本 run_all_tests.sh,自动完成编译、运行以及结果记录的步骤。
创建脚本文件
-
创建脚本文件
vi run_all_tests.sh -
粘贴以下内容
#!/bin/bash# 定义编译器路径
GCC_DEFAULT="/usr/bin/gcc"
GCC_OPTIMIZED="/opt/aarch64/compiler/gcc-12.3.1-2024.09-aarch64-linux/bin/gcc"# 定义测试文件和对应的 CSV 文件
declare -A TESTS
TESTS=(["dynamic_addressing"]="dynamic_addressing"["float_optimization"]="float_optimization"["memory_optimization"]="memory_optimization"
)# 定义 N 值的范围和步长
declare -A N_VALUES
N_VALUES=(["dynamic_addressing"]="1000000 3000000 5000000 7500000 10000000 12000000 15000000 200000000"["float_optimization"]="1000000 1500000 2000000 3000000 5000000 7500000 10000000"["memory_optimization"]="10000 15000 20000 35000 50000 75000 100000"
)# 清理旧结果并添加表头
for test in "${!TESTS[@]}"; dodefault_csv="${TESTS[$test]}_default.csv"optimized_csv="${TESTS[$test]}_openEuler.csv"echo "N,Execution Time (seconds)" > "$default_csv"echo "N,Execution Time (seconds)" > "$optimized_csv"
done# 运行每个测试
for test in "${!TESTS[@]}"; dodefault_csv="${TESTS[$test]}_default.csv"optimized_csv="${TESTS[$test]}_openEuler.csv"echo "Running test: $test"for N in ${N_VALUES[$test]}; doecho "Testing N = $N"# 编译并运行 Default GCCif [ "$test" == "dynamic_addressing" ]; then$GCC_DEFAULT ${test}.c -o ${test}_default -O3 -mcmodel=largeelif [ "$test" == "float_optimization" ]; then$GCC_DEFAULT ${test}.c -o ${test}_default -O3 -ffast-math -lmelif [ "$test" == "memory_optimization" ]; then$GCC_DEFAULT ${test}.c -o ${test}_default -O3 -fomit-frame-pointerfiif [ $? -ne 0 ]; thenecho "Compilation failed for $test with Default GCC on N=$N"continuefi# 运行 Default GCC 编译的程序并记录结果./$(basename ${test}_default) $N >> "$default_csv"# 编译并运行 GCC for openEulerif [ "$test" == "dynamic_addressing" ]; then$GCC_OPTIMIZED ${test}.c -o ${test}_optimized -O3 -mcmodel=largeelif [ "$test" == "float_optimization" ]; then$GCC_OPTIMIZED ${test}.c -o ${test}_optimized -O3 -ffast-math -lmelif [ "$test" == "memory_optimization" ]; then$GCC_OPTIMIZED ${test}.c -o ${test}_optimized -O3 -fomit-frame-pointerfiif [ $? -ne 0 ]; thenecho "Compilation failed for $test with GCC for openEuler on N=$N"continuefi# 运行 GCC for openEuler 编译的程序并记录结果./$(basename ${test}_optimized) $N >> "$optimized_csv"done
doneecho "All tests completed."-
保存并退出
在
vi编辑器中,按Esc键,输入:wq,然后按Enter键。 -
赋予脚本执行权限
chmod +x run_all_tests.sh -
运行脚本
./run_all_tests.sh脚本说明:
- 编译器路径: 指定系统默认 GCC 和 GCC for openEuler 的路径。
- 测试定义: 使用关联数组定义每个测试的名称和对应的 C 文件。
- N值定义: 为每个测试定义适当的输入规模范围。
- CSV初始化: 为每个测试和编译器组合创建 CSV 文件,并添加表头。
- 编译与运行:
- 根据测试类型,应用相应的编译选项。
- 编译失败时,输出错误信息并跳过当前测试。
- 运行编译后的程序,将输出结果(N值和执行时间)追加到对应的 CSV 文件中。
- 完成提示: 测试全部完成后,输出提示信息。
结果收集与绘图
完成实验后,将生成六个 CSV 文件,分别对应三个测试在系统默认 GCC 和 GCC for openEuler 下的执行时间。接下来,通过 Python 脚本将结果可视化。
步骤1: 下载CSV文件
使用 WinSCP 或其他文件传输工具,将以下 CSV 文件下载到本地计算机:
dynamic_addressing_default.csvdynamic_addressing_openEuler.csvfloat_optimization_default.csvfloat_optimization_openEuler.csvmemory_optimization_default.csvmemory_optimization_openEuler.csv
示例图表:
- 动态寻址性能对比

- 浮点优化性能对比

- 内存优化性能对比

结论
通过上述三个实验,可以全面评估 GCC for openEuler 在不同优化场景下相较于系统默认 GCC 的性能提升:
-
动态寻址:
- 场景:处理大规模数据集,如科学计算和数据分析。
- 优化指令:
-mcmodel=large。 - 结果:GCC for openEuler 在处理更大规模的数据段时表现更高效,执行时间更短。
-
浮点优化:
- 场景:需要大量浮点运算的应用,如图形处理和物理模拟。
- 优化指令:
-ffast-math。 - 结果:启用浮点优化后,GCC for openEuler 显著提高浮点运算速度,执行时间明显减少。
-
内存优化:
- 场景:内存使用敏感的应用,如嵌入式系统和低功耗设备。
- 优化指令:
-fomit-frame-pointer。 - 结果:GCC for openEuler 通过省略帧指针减少内存占用,提高程序整体执行速度。
综合结论:
GCC for openEuler 在多种优化选项下展现出显著的性能优势,特别是在大规模数据处理、浮点运算优化和内存管理方面。这使其成为在特定硬件和操作系统环境下,追求高性能应用的理想编译器选择。
故障排除
在实验过程中,可能会遇到以下常见问题及其解决方法:
1. 编译错误:undefined reference to 'sincos'
问题描述:
编译浮点优化实验程序时,出现链接错误,提示 sincos 函数未定义。
解决方法:
确保在编译时链接数学库,使用 -lm 选项。例如:
gcc float_optimization.c -o float_optimization_default -O3 -ffast-math -lm
2. 编译错误:gcc: error: unrecognized argument ‘-mcmodel=large’
问题描述:
编译动态寻址实验程序时,出现错误提示 -mcmodel=large 选项未被识别。
解决方法:
- 确认编译器版本:确保使用的是支持
-mcmodel=large选项的 GCC 版本。 - 检查编译器路径:使用正确路径下的 GCC for openEuler。
- 查看GCC文档:参考当前GCC版本的文档,确认是否支持该选项。
3. 执行错误:./dynamic_addressing_openEuler: No such file or directory
问题描述:
运行编译后的程序时,提示找不到可执行文件。
解决方法:
- 确认编译成功:检查编译过程是否有错误,确保生成了可执行文件。
- 检查文件权限:确保可执行文件具有执行权限。
chmod +x dynamic_addressing_openEuler - 确认文件路径:在正确的目录下运行程序。
4. 程序运行时间异常长
问题描述:
内存优化实验中的冒泡排序在大数据集上运行时间极长。
解决方法:
- 限制N值:将
N的最大值设置在合理范围内(如15000)。 - 优化算法:考虑使用更高效的排序算法(如快速排序),以减少执行时间。