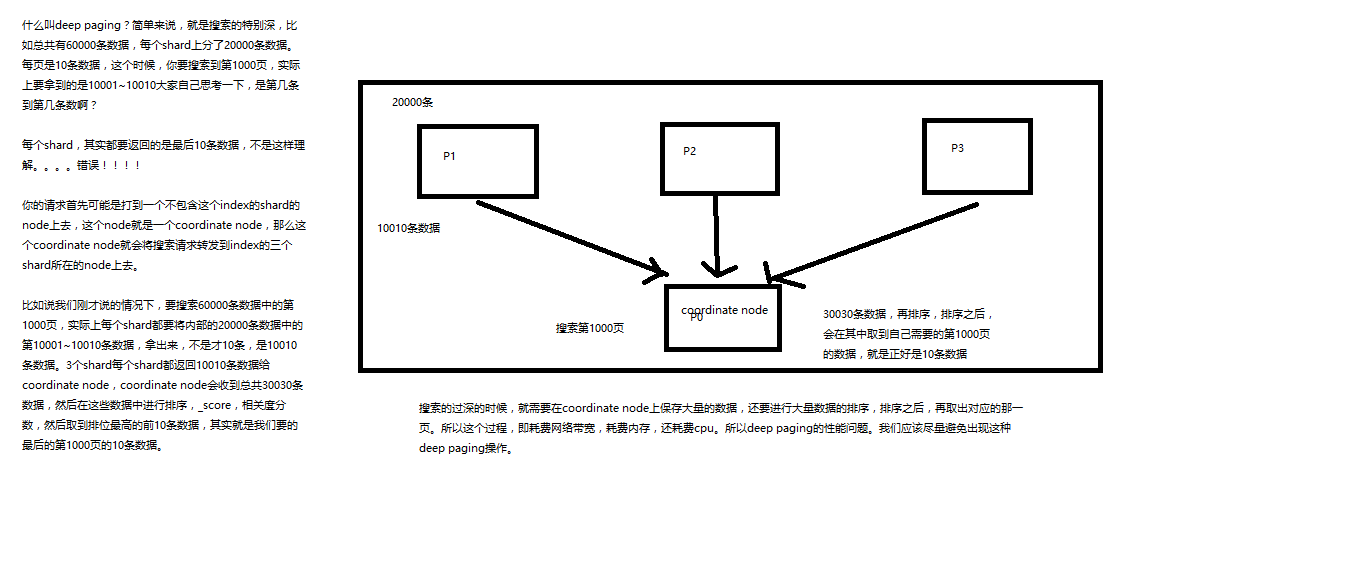
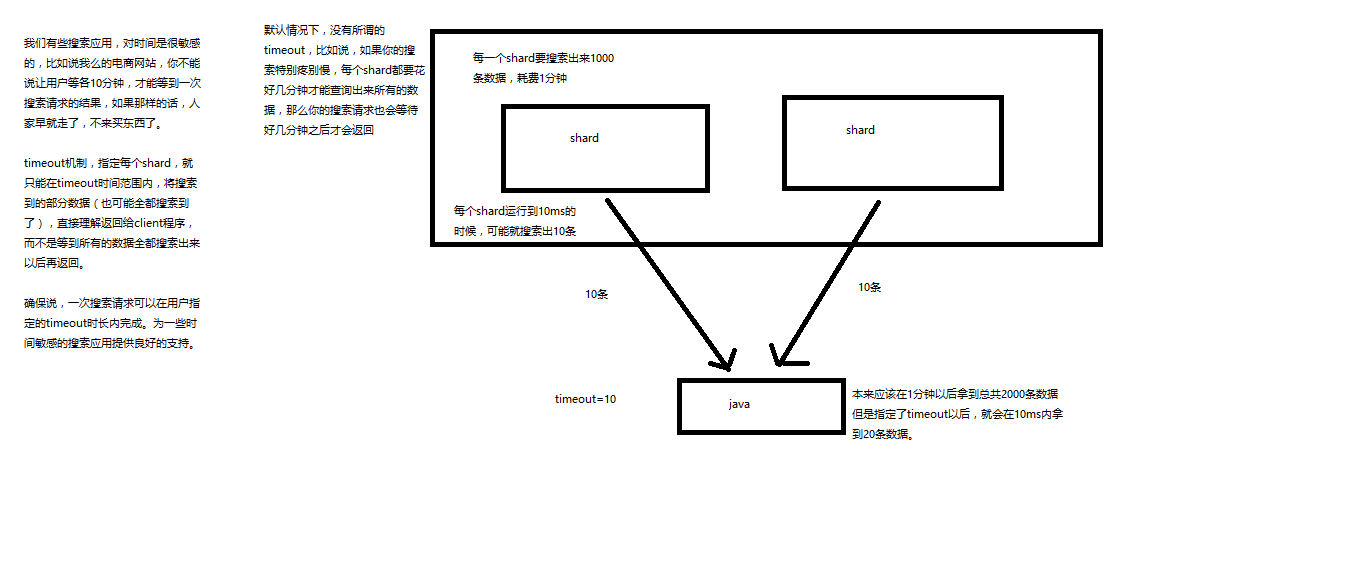
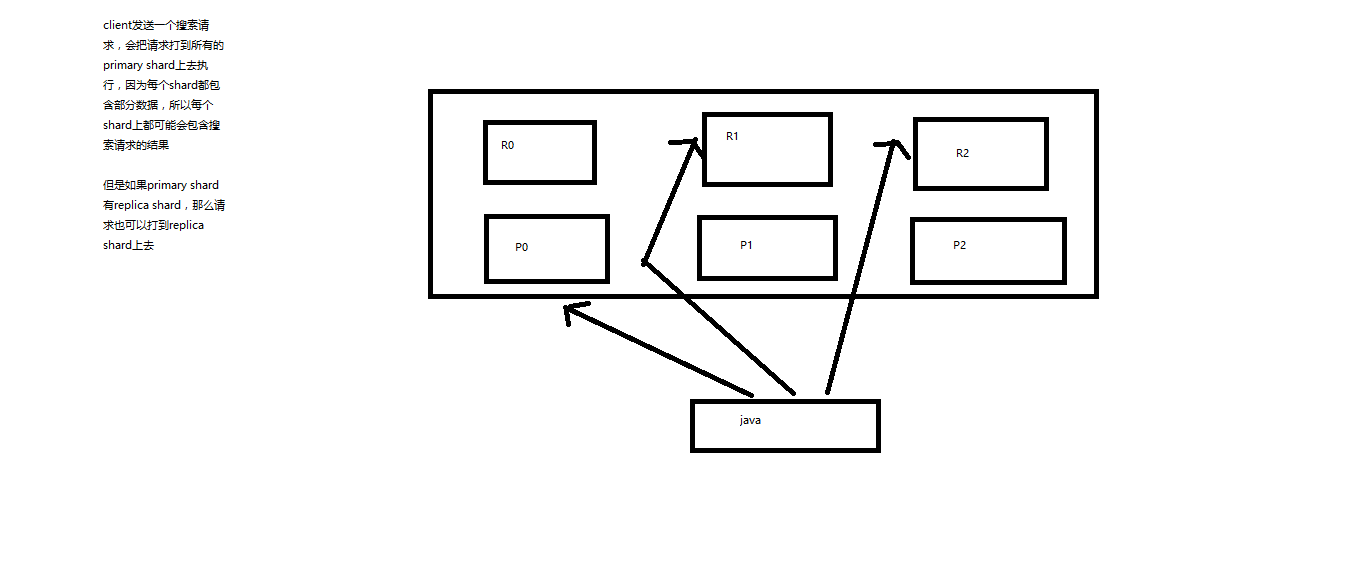
Matplotlib 实用指南(全)
原文:Hands-on Matplotlib
协议:CC BY-NC-SA 4.0
一、Python 3 简介
欢迎大家来到 Matplotlib 和相关库(如 NumPy、Pandas 和 Seaborn)的激动人心的数据可视化之旅。
本章涵盖了 Python 编程语言的基础知识,包括它的历史、安装和应用。您将编写一些简单的介绍性 Python 3 程序,并学习如何在各种操作系统平台上执行它们。
然后,我们将开始探索科学的 Python 生态系统。我们将简要讨论科学 Python 生态系统的成员库,最后,我们将探索 Jupyter Notebook,以便我们可以在本书的其余部分使用它。
具体来说,本章包含以下主题:
-
Python 编程语言
-
各种平台上的 Python 安装
-
Python 模式
-
Python IDEs
-
科学 Python 生态系统
-
Jupyter 笔记本概述和设置
-
Jupyter 笔记本中的运行代码
-
蟒蛇
阅读完这一章后,您将会对 Python 3 编程语言在各种平台上的各种模式下的安装和基本用法驾轻就熟。
Python 3 编程语言简介
Python 3 是一种通用的高级解释编程语言。在这一节中,我们将讨论 Python 编程语言及其哲学。
Python 编程语言的历史
Python 是 ABC 编程语言的继承者,ABC 编程语言本身受到 ALGOL 68 和 SETL 编程语言的启发。Python 是吉多·范·罗苏姆在 20 世纪 80 年代末度假期间作为业余项目创作的,当时他在荷兰的 Centrum Wiskunde & Informatica(英文:“国家数学和计算机科学研究所”)工作。范·罗森在荷兰出生并长大。他获得了阿姆斯特丹大学的数学和计算机科学硕士学位。他曾为谷歌和 Dropbox 工作,之后退休。然而,2020 年 11 月,他加入了微软。
自 Python 编程语言最初发布至 2018 年 7 月,Guido 一直是这个项目的首席开发者和终身慈善独裁者(BDFL)。他在 2019 年一直在 Python 的指导委员会工作,但在 2020 年,他撤回了对指导委员会连任的提名。
以下是 Python 发布时间表中的重要里程碑:
-
【1991 年 2 月 : Van Rossum 向
alt.sources发布了代码(标签为 0.9.0 版)。 -
【1994 年 1 月:1.0 版本发布。
-
【2000 年 10 月 : Python 2.0 发布。
-
【2006 年 12 月 : Python 3.0 发布。
-
【2019 年 12 月 : Python 2。 x 正式退役,不再受 Python 软件基金会支持。
如你所见,Python 2。随着 Python 2 的退役,不再支持 x 版本。Python 3 不向后兼容 Python 2。Python 3 是 Python 编程语言的最新版本,也是受支持的版本。因此,我们将在整本书中使用 Python 3 编程来演示所涵盖的概念。除非明确提到,否则在本书中,Python 指的是 Python 3。
Python 增强提案
为了指导 Python 的开发、维护和支持,Python 领导层提出了 Python 增强提案 (PEPs)的概念。它们是 Python 项目中建议新特性和修复问题的主要机制。您可以通过以下网址了解有关 pep 的更多信息:
https://www.python.org/dev/peps/
https://www.python.org/dev/peps/pep-0001/Python 编程语言的哲学
Python 的哲学在 PEP20 中有详细介绍。被称为蟒之禅,在 https://www.python.org/dev/peps/pep-0020/ 。以下是人教版的要点。有几个很搞笑。
-
漂亮总比难看好。
-
显性比隐性好。
-
简单比复杂好。
-
复杂总比复杂好。
-
扁平的比嵌套的好。
-
疏比密好。
-
可读性很重要。
-
特例不足以特殊到打破规则。
- 虽然实用性战胜了纯粹性。
-
错误永远不会无声无息地过去。
- 除非明确沉默。
-
面对暧昧,拒绝猜测的诱惑。
-
应该有一种——最好只有一种——显而易见的方法来做这件事。
- 尽管这种方式一开始可能并不明显,除非你是荷兰人。
-
现在总比没有好。
- 虽然永远也不会比现在的对好。
-
如果实现很难解释,这是一个坏主意。
-
如果实现很容易解释,这可能是一个好主意。
-
名称空间是一个非常棒的想法——让我们多做一些吧!
这些是继续影响 Python 编程语言发展的基本原则。
Python 的应用
如你所知,Python 是一种通用编程语言;它在以下领域有许多应用:
-
Web 开发
-
GUI 开发
-
科学和数值计算
-
软件开发
-
系统管理员
你可以在 https://www.python.org/success-stories/ 阅读 Python 的案例分析。
在各种平台上安装 Python
Python 实现是一个程序(Python 解释器的实际二进制可执行文件),它支持用 Python 编程语言编写的程序的执行。Guido van Russom 创建的最初实现被称为 CPython ,并作为参考实现。在整本书中,我们将使用 CPython。它可以在 Python 网站上获得,在这一节中,您将学习如何在 Windows 操作系统上安装它。我更喜欢在 Windows 电脑或装有 Raspberry Pi 操作系统的 Raspberry Pi 电脑上编写 Python 程序。您可以在 https://www.python.org/download/alternatives/ 找到备选 Python 实现的列表。
我认为现在是讨论各种 Python 发行版的好时机。你看到了 Python 的实际解释程序被称为实现。当它与一些有用的东西捆绑在一起时,比如集成开发环境(IDE)、工具和库,它被称为发行版。你可以在 https://wiki.python.org/moin/PythonDistributions 找到 Python 发行版列表。
现在,让我们看看如何在这两个平台上安装 Python。
在 Windows 电脑上安装
访问位于 https://www.python.org/downloads/ 的 Python 3 下载页面,为您的计算机下载 Python 3 的安装文件。页面会自动检测您电脑上的操作系统,并显示合适的可下载文件,如图 1-1 所示。

图 1-1
带有下载选项的 Python 项目主页
运行安装文件来安装 Python 3。在安装过程中,选中与将 Python 3 添加到 PATH 变量相关的复选框(图 1-2 )。

图 1-2
Python 安装向导
此外,选择“自定义安装”选项。这将带您进入更多选项,如图 1-3 所示。

图 1-3
Python 安装选项
选择所有复选框,然后单击“下一步”按钮继续设置。完成设置。Python 的二进制可执行程序在 Windows 上的名字是python。安装完成后,在 Windows 命令提示符下运行以下命令,cmd:
python -V这会返回 Python 3 的版本,如下所示:
Python 3.8.1您也可以按如下方式检查 pip 的版本:
pip3 -V一个递归缩写, pip 代表“pip 安装 Python”或“Pip 安装软件包”。它是 Python 编程语言的一个包管理器。您可以使用 pip 实用程序为我们的演示安装其他所需的 Python 库。
要找出 Python 的确切位置,可以运行如下的where命令:
where python这将返回以下结果:
C:\Users\Ashwin\AppData\Local\Programs\Python\Python38-32\python.exe同样,您可以通过运行以下命令找到 pip3 实用程序的位置:
where pip3我们将在整本书中大量使用这个工具,在我们使用的计算机上安装和管理 Python 3 库。以下命令列出了所有已安装的软件包:
pip3 list在 Ubuntu/Debian 衍生产品上安装
Debian 是一个流行的发行版。Ubuntu Linux 和 Raspberry Pi OS 是基于 Debian 的其他流行发行版。Python 3 和 pip3 预装在所有 Debian 发行版和衍生版本中,如 Ubuntu 或 Raspberry Pi OS。因此,我们不必单独安装它们。我在一台 8 GB 内存的 Raspberry Pi 4B 上使用 Raspberry Pi 操作系统作为我的 Linux 计算机。Python 的两个主要版本,Python 2 和 Python 3,都预装在所有的 Debian 衍生版本中。它们的解释器可执行文件在 Python 2 和 Python 3 中分别命名为python和python3。我们将使用python3进行演示。要找出所需的二进制可执行文件的版本和位置,请逐一运行以下命令:
python3 -V
pip3 -V
which python3
which pip3几乎所有其他流行的 Linux 发行版都预装了 Python。
使用 Python 模式
Python 编程语言有各种执行程序(和语句,您很快就会看到)的模式。让我们逐一讨论。但是在我们开始讨论之前,让我们看看什么是空闲。IDLE 是 Python 软件基金会为 Python 编程开发的集成开发和学习环境。在 Windows 上安装 Python 3 的 CPython 实现时,也会安装 IDLE。您可以通过多种方式在 Windows 操作系统上启动它。第一种方法是在 Windows 搜索栏中输入 IDLE 进行搜索,如图 1-4 所示。

图 1-4
Python 在 Windows 上空闲
另一种方法是通过运行以下命令从命令提示符(cmd)启动它:
idle这将启动如图 1-5 所示的窗口。

图 1-5
Python 空闲
在继续之前,您需要自定义 IDLE,以便它为您工作。您可以通过选择选项➤配置空闲来更改字体,如图 1-6 所示。

图 1-6
配置空闲
图 1-7 所示的窗口打开,您可以在空闲时更改字符的字体和大小。

图 1-7
空闲配置窗口
根据自己的喜好调整选项。
并非所有的 Linux 发行版都预装了 IDLE。您可以通过依次运行以下命令,将它安装在 Debian 及其衍生物(Ubuntu 和 Raspberry Pi OS)上:
sudo apt-get update
sudo apt-get install idle3一旦安装完成,你可以在菜单中找到 IDLE(这里是 Raspberry Pi OS 菜单),如图 1-8 所示。

图 1-8
在 Raspberry Pi 操作系统菜单中空闲
您也可以通过运行以下命令在 Linux 上启动 IDLE:
idle现在我们来讨论一下 Python 的各种模式。
对话方式
Python 的交互模式就像一个命令行 shell,执行当前语句,并在控制台上给出即时反馈。它会立即运行提供给它的语句。当新的语句被输入解释器并由解释器执行时,代码被求值。当您打开 IDLE 时,您会看到一个命令行提示。这是 Python 的交互模式。为了看一个简单的例子,让我们在交互提示中键入习惯的 Hello World 程序,如下所示:
print('Hello World!')按 Enter 键将该行输入解释器并执行它。图 1-9 显示了输出。

图 1-9
空闲时的 Python 交互模式
您也可以从命令提示符启动 Python 的交互模式。在 Linux 命令提示符下(例如 lxterminal),运行命令python3,在 Windows 命令提示符下(cmd,运行命令python。图 1-10 显示了 Windows 命令提示符下的交互模式。

图 1-10
Python 交互模式,Windows 命令提示符
脚本模式
你可以写一个 Python 程序,保存到磁盘。然后你可以用多种方式启动它。这被称为脚本模式。让我们在空闲时演示一下。您可以使用任何文本编辑器来编写 Python 程序。但是因为 IDLE 是一个 IDE,所以使用 IDLE 编写和运行 Python 程序很方便。让我们先看看那个。在空闲状态下,选择文件➤新文件。这将创建一个新的空白文件。向其中添加以下代码:
print('Hello World!')然后用名称prog01.py保存在磁盘上(图 1-11 )。

图 1-11
空闲代码编辑器中的 Python 程序
在菜单中,选择运行➤运行模块。这将在 IDLE 的提示下执行程序,如图 1-12 所示。

图 1-12
在空闲提示符下执行的 Python 程序
你甚至可以在操作系统的命令提示符下用 Python 的解释器启动程序。打开操作系统的命令提示符,导航到存储程序的目录。在 Windows 命令提示符下,运行以下命令:
python prog01.py在 Linux 终端中,您必须运行以下命令提示符:
python3 prog01.py然后解释器将在命令提示符下运行程序,输出(如果有的话)将出现在那里。
在 Linux 中,有另一种方法可以运行程序,而不需要显式地使用解释器。您可以在代码文件的开头添加一个 shebang 行。例如,假设我们的代码文件如下所示:
#!/usr/bin/python3
print('Hello World!')第一条线被称为 shebang 线。它告诉 shell 使用什么解释器及其位置。然后运行以下命令更改文件权限,使其对所有者可执行,如下所示:
chmod 755 prog01.py然后你可以像其他可执行文件一样用./直接启动你的 Python 程序文件,如下所示:
./prog01.pyshell 将执行程序并在终端中打印输出。请注意,这仅适用于类 Unix 系统(Linux 和 macOS ),因为它们支持像这样执行程序。在整本书中,你会学到更多关于 Python 编程的知识。
使用 Python IDEs
您已经学习了如何使用 Python 解释器和 IDLE 来运行 Python 3 语句和程序。您可以使用其他免费提供的 ide 和插件,让 ide 与 Python 一起工作。下面是一些著名的 Python 3 和插件的列表,以及它们主页的 URL:
-
PyCharm 社区版(
https://www.jetbrains.com/pycharm/) -
标枪 IDE (
https://www.spyder-ide.org/ -
Thonny Python 编辑(
https://thonny.org/) -
穆编辑(
https://codewith.mu/) -
Eclipse 的 PyDev 插件(
https://www.pydev.org/)
所有这些 ide 和插件都可以免费下载和使用。作为本章的一个练习,您可能想要探索它们以找到您最熟悉的 IDE。
探索科学 Python 生态系统
科学 Python 生态系统是用于科学计算的开源 Python 库的集合。它有以下核心组件:
-
Python :这是一种编程语言。
-
NumPy:这是数值计算的基础库。科学 Python 生态系统中几乎所有的库都是基于 NumPy 的。它提供了一种被称为Ndarray(N 维数组)的通用数据结构。
-
这个库有许多科学计算的例程。
-
Matplotlib :这是一个可视化的库。它的
pyplot模块有 Matlab 风格的可视化例程。
所有这些组件一起提供了类似 Matlab 的功能:
-
这是一个数据科学的图书馆,提供了高性能、易于使用的数据结构,比如用于存储数据的系列和数据框架。
-
这是给符号数学和代数的。
-
这是一个表示和可视化图形和网络的库。
-
这是一个用于图像处理的库。
-
Scikit-learn :这是一个机器学习和人工智能的库。
除了这些库,IPython 还为 Python 解释器提供了更好的交互环境。IPython 的交互环境可以通过使用 Jupyter Notebook 的基于网络的笔记本来访问。
这一章的其余部分着重于朱庇特笔记本。
Jupyter 笔记本介绍
在本章的前面,您学习了运行 Python 语句的各种方法。您在脚本中和解释器的交互模式下运行 Python 语句。使用交互模式的主要优势是即时反馈。这种模式的主要缺点是,如果您在输入的语句中出现任何错误,您必须重新编写整个语句才能重新执行。另外,很难将其保存为程序。可以在菜单的文件选项中找到保存要在解释器上运行的语句的选项。但是,所有的语句及其输出将以纯文本格式保存,扩展名为.py。如果有任何图形输出,它将单独显示,不能与语句一起存储。
由于解释器中交互模式的限制,我们将使用更好的工具在 web 浏览器中交互运行 Python 语句。这个工具被称为 Jupyter 笔记本。它是一个服务器程序,可以在网络浏览器中创建交互式笔记本。
Jupyter Notebook 是一个基于 web 的笔记本,用于各种编程语言的交互式编程,如 Python、Octave、Julia 和 r。它很受研究领域工作人员的欢迎。Jupyter Notebook 可以将代码、可视化、输出和富文本保存在一个文件中。Jupyter Notebook 相对于 Python 自带的交互提示的优势在于,你可以编辑代码,即时看到新的输出,这在 Python 的交互模式下是做不到的。另一个优点是,您将代码、富文本元素和代码输出(可以是图形或富文本格式)放在磁盘上的同一个文件中。这使得分发变得容易。您可以通过互联网或使用便携式存储设备保存和共享这些笔记本。网上有很多服务可以帮助你在云服务器上存储和执行你的笔记本脚本。
设置 Jupyter 笔记本
通过在命令提示符下运行以下命令,您可以在任何计算机上轻松安装 Jupyter 笔记本服务器程序:
pip3 install jupyter现在让我们看看如何使用 Jupyter Notebook 来编写和执行 Python 语句。在操作系统的命令提示符下运行以下命令,启动 Jupyter 笔记本服务器进程:
jupyter notebookJupyter 笔记本服务器进程将被启动,命令提示符窗口显示服务器日志,如图 1-13 所示。

图 1-13
启动新的 Jupyter 笔记本流程
此外,它会在操作系统的默认浏览器中启动一个网页。如果浏览器窗口已经打开,则它会在同一浏览器窗口的新选项卡中启动页面。打开页面的另一种方法(如果您关闭运行 Jupyter Notebook 的浏览器窗口)是在浏览器中访问http://localhost:8888/。显示如图 1-14 所示的页面。

图 1-14
使用令牌登录
以下几行文本是服务器日志。
To access the notebook, open this file in a browser:
file:///C:/Users/Ashwin/AppData/Roaming/jupyter/runtime/nbserver-8420-open.htmlOr copy and paste one of these URLs:
http://localhost:8888/?token=e4a4fab0d8c22cd01b6530d5daced19d32d7e0c3a56f925c
http://127.0.0.1:8888/?token=e4a4fab0d8c22cd01b6530d5daced19d32d7e0c3a56f925c在前面的日志中,您可以看到几个 URL。它们引用同一个页面(localhost 和 127.0.0.1 是同一个主机)。您可以直接在浏览器选项卡的地址栏中复制并粘贴这些 URL,然后打开 Jupyter 笔记本主页,或者您可以访问前面讨论过的http://localhost:8888/,然后在服务器日志中粘贴令牌(在我们的示例中是e4a4fab0d8c22cd01b6530d5daced19d32d7e0c3a56f925c)并登录。这将把你带到同一个主页。
请注意,Jupyter 笔记本服务器的每个实例都有自己的令牌,因此书中显示的令牌不适用于您的笔记本。该令牌仅对该服务器进程有效。
因此,如果您遵循前面解释的任何一条路线,您将在浏览器窗口中看到一个主页选项卡,如图 1-15 所示。

图 1-15
木星笔记本的新主页标签
如您所见,网页上有三个选项卡:文件、运行和集群。“文件”选项卡显示从命令提示符启动笔记本服务器的目录中的目录和文件。在前面的例子中,我从我的 Raspberry Pi 的 lxterminal 执行了命令jupyter notebook。当前工作目录是pi用户/home/pi的home目录。这就是为什么你可以在图 1-15 中看到我的树莓派电脑主目录下的所有文件和目录。
在右上角,您可以看到退出和注销按钮。如果您单击“注销”按钮,它将从当前会话中注销,要登录,您还需要笔记本服务器日志中嵌入了令牌的令牌或 URL,如前所述。如果你点击退出按钮,那么它会停止在命令提示符下运行的笔记本服务器进程,并显示如图 1-16 所示的模态消息框。

图 1-16
单击退出按钮后显示的消息
要使用 Jupyter 笔记本,您需要在命令提示符下再次执行命令jupyter notebook。
在右上角,就在退出和注销按钮的下方,您可以看到一个带有刷新符号的小按钮。此按钮刷新主页。您还有一个新按钮。点击后会显示下拉列表,如图 1-17 所示。

图 1-17
新笔记本的选项
如您所见,下拉列表分为两个部分,笔记本和其他。您可以创建 Octave 和 Python 3 笔记本。如果您的计算机安装了 Jupyter Notebook 支持的更多编程语言,那么所有这些语言都会显示在这里。您也可以创建文本文件和文件夹。您可以通过点按“终端”在 web 浏览器中打开命令提示符。图 1-18 显示 lxterminal 在单独的 web 浏览器选项卡中运行。

图 1-18
浏览器中的新 lxterminal 窗口
点击下拉列表中的 Python 3,创建一个新的 Python 3 笔记本,如图 1-19 所示。

图 1-19
新的 Python 3 笔记本
如果在浏览器中点击首页标签页再次进入首页,然后在首页打开运行标签页,可以看到终端和 Python 3 笔记本对应的条目,如图 1-20 所示。

图 1-20
当前 jupiter 笔记本子流程摘要
Jupyter 笔记本中的运行代码
再次转到 Python 3 的 Untitled1 选项卡,在文本区域(也称为单元格)中键入以下语句:
printf("Hello, World!\n");然后点击运行按钮。Jupyter 会将该语句作为 Python 3 语句执行,并在单元格正下方显示结果,如图 1-21 所示。

图 1-21
Jupyter 笔记本中的代码输出
如您所见,在执行之后,它会自动在结果下方创建一个新的单元格,并将光标放在那里。让我们讨论菜单栏和编程单元上方的图标。您可以通过单击软盘图标来保存文件。您可以通过单击+图标在当前单元格后添加一个新的空单元格。接下来的三个图标是剪切、复制和粘贴。使用向上和向下箭头可以分别上下移动当前单元格的位置。下一个选项是运行单元,您已经看到了。接下来的三个图标分别用于中断内核、重启内核和重新运行笔记本中的所有单元。旁边有一个下拉框,告诉您应该是哪种类型的单元格。图 1-22 显示点击时的下拉。

图 1-22
Jupyter 笔记本中的细胞类型
选择代码选项时,该单元被视为 Python 3 代码单元。当您选择降价选项时,它被视为降价单元格。Markdown 是一种可以创建富文本输出的标记语言。例如,任何跟在#后面的都创建一个标题,任何跟在##后面的都创建一个副标题,等等。只需在 Markdown 单元格中键入以下行并执行它们:
# Heading 1
## Heading 2在我们的 Python 3 演示中,我们将主要对标题使用 Markdown。但是,您可以通过访问 https:// jupyter-notebook 来进一步探索 Markdown。阅读文档。io/en/stable/examples/Notebook/Working %20 含%20 降价% 20 单元。html 。图 1-23 显示了之前演示的输出。

图 1-23
降价中的标题
您甚至可以通过单击笔记本顶部的文件名来更改笔记本文件的名称。点击后,你会看到一个用于重命名的模态框,如图 1-24 所示。

图 1-24
在 Jupyter 中重命名笔记本
如果需要,可以重命名笔记本。如果您在命令提示符下浏览磁盘上启动 Jupyter 笔记本的位置,您会发现扩展名为.ipynb的文件(意思是“IPython 笔记本”)。
同样的,你可以使用 Jupyter Notebook 与其他支持 Jupyter 的编程语言进行交互编程。我们将主要使用这种笔记本格式来存储交互式会话的代码片段。这是因为一切都保存在一个文件中,可以很容易地共享,如前所述。
您可以清除一个单元格或整个笔记本的输出。在菜单栏中,单击单元格菜单。在下拉列表中,“当前输出”和“所有输出”有一个清除选项,用于清除单元格的输出。图 1-25 显示了选项。

图 1-25
清除 Jupyter 中的输出
Jupyter Notebook 最显著的优点之一是,如果有任何语法错误或者您只是想更改代码,您可以编辑已经执行的单元格。Jupyter Notebook 就像一个运行在 web 浏览器中的 IDE,并在同一个窗口中生成输出。这种将代码、富文本和输出保存在同一个文件中的交互性和便利性使得 Jupyter Notebook 项目在世界范围内大受欢迎。运行 Python 程序的内核来自 IPython 项目。正如我前面提到的,您也可以将它用于其他编程语言。我用它来运行 GNU Octave 程序。
您可以在以下网址找到关于 Jupyter Notebook 和 IPython 的更多信息:
https://jupyter.org/
https://ipython.org/蟒蛇
在我们结束本章之前,我们需要讨论一下 Python 发行版。Python 发行版只不过是与 Python 库捆绑在一起的 Python 解释器。Anaconda 就是这样一个受欢迎的发行版。您可以在 Linux、Windows 和 macOS 上下载并安装 Anaconda。Anaconda 有很多版本。其中一个是免费的,仅供个人使用。你可以在 https://www.anaconda.com/products/individual 找到它。
Anaconda 附带了一个开源的包管理器,可以为 Python 和其他程序安装包。它被称为康达。你可以在 https://docs.conda.io/en/latest/ 找到更多关于康达包管理器的信息。
如果你已经从 Python 的网站安装了 Python,我推荐你用另一台电脑安装 Anaconda。拥有多个解释器和 Python 发行版可能会令人困惑。
摘要
在本章中,你学习了 Python 编程语言的基础。您学习了如何编写基本的 Python 程序,以及如何以各种方式执行它们。您学习了在 Windows 和 Linux 等各种操作系统上使用 Python。您还学习了 Python 编程语言的各种模式,以及如何从各种操作系统的命令提示符下启动 Python。您学习了 Python 内置包管理器 pip 的基础知识。我们还简要讨论了 Python 的其他 ide。
然后,简要介绍了科学 Python 生态系统。我们将在接下来的章节中探索这个生态系统的许多组成部分。您还学习了如何在各种平台上安装 Jupyter Notebook,并探索了如何在 Jupyter Notebook 中运行简单的 Python 语句。您了解了可以将代码和相同代码的输出存储在一个文件中,该文件可以通过 Internet 和其他媒体(如便携式存储设备)轻松共享。
在下一章,我们将从 NumPy 开始。
二、NumPy 入门
在前一章中,您学习了 Python 编程语言和科学 Python 生态系统的基础知识。您还学习了如何使用 Jupyter 在基于 web 的交互式笔记本中运行简单的 Python 程序。在本书剩余章节的大部分演示中,我们将继续使用 Jupyter Notebook。
在这一章中,我们将通过一些代码演示给出 NumPy 库的简要概述。以下是我们将在本章中探讨的主题列表:
-
NumPy Ndarrays 简介
-
n 数组属性
-
NumPy 常量
在本书的剩余章节中,我们将逐一探索科学 Python 生态系统的许多组件。在整本书中,我们将使用不同的库,它们是这个科学 Python 生态系统的一部分。你将在这一章中获得的有价值的知识是其余章节的基础。由于这是一个广泛的生态系统的介绍性章节,所以我把它写得简短而实用。
NumPy 和 Ndarrays
NumPy 是 Python 中数值计算的基础包。我们可以用它来进行数值计算。NumPy 库最有用的特性是被称为 Ndarray 的多维容器数据结构。
Ndarray 是包含具有相同数据类型和大小的项目的多维数组(也称为容器)。我们可以在创建 Ndarray 时定义项目的大小和数据类型。就像列表等其他数据结构一样,我们可以通过索引来访问 Ndarray 的内容。Ndarray 中的索引从 0 开始(就像 C 中的数组或 Python 中的列表)。我们可以使用 Ndarrays 进行各种计算。科学 Python 生态系统中的所有其他库都识别并利用 NumPy Ndarrays 和相关例程来表示它们自己的数据结构和操作。
让我们从动手材料开始。为本章创建新笔记本。运行以下命令在您的计算机上安装 NumPy 库:
!pip3 install numpy让我们通过运行以下命令将其导入到当前笔记本中:
import numpy as np您可以创建一个列表,并使用它来创建一个简单的 Ndarray,如下所示:
l1 = [1, 2, 3]
x = np.array(l1, dtype=np.int16)在这里,您从一个列表中创建了一个 Ndarray。成员的数据类型是 16 位整数。在 https://numpy.org/devdocs/user/basics.types.html 可以找到支持的数据类型的详细列表。
您可以在一行中编写前面的代码,如下所示:
x = np.array([1, 2, 3], dtype=np.int16)让我们打印 n array 的值和它的类型(我们知道,它是一个 n array)。
print(x)
print(type(x))输出如下所示:
[1 2 3]
<class 'numpy.ndarray'>正如您在前面的输出中所看到的,它属于类numpy.ndarray。
你也可以使用 Python 的交互模式来运行所有的语句,如图 2-1 所示。

图 2-1
在 Python shell 中以交互模式运行示例代码
您也可以在 Python shell 中运行您将在本书中练习的大多数代码示例。类似地,您可以通过在命令提示符下键入命令ipython来启动 IPython shell,然后运行代码示例,如图 2-2 所示。

图 2-2
在 IPython shell 中以交互模式运行示例代码
虽然您可以使用 Python 交互式 shell 和 IPython 来运行代码示例,但是不可能使用这些工具将代码、输出和其他资源(如富文本标题)保存在一个文件中,因此在本书中我们将主要使用 Jupyter 笔记本文件(*.ipynb文件)。在一些情况下,我们也将使用 Python 脚本模式程序(*.py文件)。
Ndarrays 中的索引
让我们简单看一下 Ndarrays 的索引。正如您之前简要了解到的,索引从 0 开始。让我们通过访问 Ndarray 的成员来演示一下,如下所示:
print(x[0]); print(x[1]); print(x[2])输出如下所示:
1
2
3您甚至可以使用负索引:-1 返回最后一个元素,-2 返回倒数第二个元素,依此类推。下面是一个例子:
print(x[-1])如果您提供了任何无效的索引,那么它将抛出一个错误。
print(x[3])在前面的语句中,您试图访问 Ndarray 中不存在的第四个元素。这将返回以下错误:
IndexError Traceback (most recent call last)
<ipython-input-4-d3c02b9c2b5d> in <module>
----> 1 print(x[3])IndexError: index 3 is out of bounds for axis 0 with size 3在多个维度的数组中建立索引
一个数组可以有多个维度,如下所示:
x1 = np.array([[1, 2, 3], [4, 5, 6]], np.int16)前面是一个二维矩阵。它有两行三列。您可以按如下方式访问单个元素:
print(x1[0, 0]); print(x1[0, 1]); print(x1[0, 2]);您甚至可以访问整行,如下所示:
print(x1[0, :])
print(x1[1, :])输出如下所示:
[1 2 3]
[4 5 6]您可以按如下方式访问整个列:
print(x[:, 0])输出如下所示:
[1 4]你甚至可以有一个二维以上的数组。以下是一个 3D 数组:
x2 = np.array([[[1, 2, 3], [4, 5, 6]],[[0, -1, -2], [-3, -4, -5]]], np.int16)在科学和商业应用中,经常会有多维数据。Ndarrays 对于存储数字数据很有用。尝试运行以下项目并检索先前 3D 矩阵的元素:
print(x2[0, 0, 0])
print(x2[1, 1, 2])
print(x2[:, 1, 1])n 数组属性
您可以通过参考 Ndarrays 的属性来了解更多关于它们的信息。让我们通过一个演示来看看所有的属性。具体来说,让我们使用我们之前使用的相同的 3D 矩阵。
x2 = np.array([[[1, 2, 3], [4, 5, 6]],[[0, -1, -2], [-3, -4, -5]]], np.int16)您可以使用以下语句找出维数:
print(x2.ndim)输出返回维数。
3您可以找出 n 数组的形状,如下所示:
print(x2.shape)形状是指以下尺寸的大小:
(2, 2, 3)您可以找出成员的数据类型,如下所示:
print(x2.dtype)输出如下所示:
int16您可以按如下方式找出存储器所需的大小(元素数量)和字节数:
print(x2.size)
print(x2.nbytes)输出如下所示:
12
24您可以使用以下代码计算转置:
print(x2.T)NumPy 常量
NumPy 库有许多有用的数学和科学常数,可以在程序中使用。下面的代码片段打印了所有这些重要的常量。
以下代码片段引用了 infinity:
print(np.inf)以下代码片段引用的不是数字:
print(np.NAN)以下代码片段引用了负无穷大:
print(np.NINF)以下代码片段引用了负数和正数零:
print(np.NZERO)
print(np.PZERO)以下代码片段引用了欧拉数:
print(np.e)以下代码片段引用了 Euler 的 gamma 和 pi:
print(np.euler_gamma)
print(np.pi)输出如下所示:
inf
nan
-inf
-0.0
0.0
2.718281828459045
0.5772156649015329
3.141592653589793切片数组
让我们看看 Ndarrays 上切片操作的例子。您可以使用索引通过切片提取 Ndarray 的一部分,如下所示:
a1 = np.array([1, 2, 3, 4, 5, 6, 7])
a1[1:5]这段代码将显示从第二个位置到第六个位置的元素(您知道 0 是起始索引),如下所示:
array([2, 3, 4, 5])您可以显示第四个位置的元素,如下所示:
a1[3:]输出如下所示:
array([4, 5, 6, 7])您还可以显示特定索引之前的所有元素(不包括该索引处的元素),如下所示:
a1[:3]输出如下所示:
array([1, 2, 3])你看到了负指数的使用。我们可以使用它们进行切片,如下所示:
a1[-4:-1]输出如下所示:
array([4, 5, 6])您已经以步长 1 对数据进行了切片。这意味着您正在检索结果集中的连续元素。您也可以按如下方式更改步长:
a1[1:6:2]在本例中,步长为 2。因此,输出将列出每隔一个元素。输出如下所示:
array([2, 4, 6])摘要
在本章中,您开始学习 NumPy 和 Ndarrays 的基础知识。这是一个有很多例程的大库。有整本书是献给 NumPy 的。然而,我们的出版限制不允许对这个有用的库进行那种探索。我们将在接下来的章节中探索更多来自 NumPy 库的例程,当我们的可视化演示需要它们时。
在下一章中,你将学习一些 Ndarray 创建例程和 Matplotlib 数据可视化的基础知识。
三、NumPy 例程和 Matplotlib 入门
在前一章中,您学习了 NumPy 的基础知识。具体来说,您学习了如何安装它以及如何创建 Ndarrays。你在前一章学到的所有主题将作为后面章节的基础,因为 Ndarray 是我们将在整本书中使用的基本数据结构。
在这一章中,我们将从上一章停止的地方继续,看看几个 Ndarray 创建例程。我们还将从科学计算生态系统中的主要数据可视化库 Matplotlib 开始。我们将使用 NumPy 的 Ndarray 创建例程来演示 Matplotlib 的可视化。这是一个详细的章节,非常强调编程和可视化。以下是您将在本章中了解的主题:
-
创建 n 数组的例程
-
Matplotlib
-
用 NumPy 和 Matplotlib 实现可视化
在本书的其余章节中,我们将经常使用 Matplotlib 和 NumPy 来演示数据可视化。
创建 n 数组的例程
让我们学习创建 1 和 0 的 n 数组。在这一节中,我们将探索许多数组创建例程。使用 Jupyter Notebook 创建一个新笔记本来保存本章的代码。返回给定形状和类型的新数组,不初始化条目。由于对应于成员的条目没有初始化,所以它们是任意的(随机的)。让我们来看一个小演示。在笔记本的单元格中键入以下代码并运行它:
import numpy as np
x = np.empty([3, 3], np.uint8)
print(x)输出如下所示:
[[ 64 244 49][ 4 1 0][ 0 0 124]]请注意,每个执行实例的值都不同,因为它不会在创建矩阵时初始化这些值。您可以创建任意大小的矩阵,如下所示:
x = np.empty([3, 3, 3], np.uint8)
print(x)函数np.eye()返回一个 2D 矩阵,对角线为 1,其他元素为 0。下面是一个例子:
y = np.eye(5, dtype=np.uint8)
print(y)输出如下所示:
[[1 0 0 0 0][0 1 0 0 0][0 0 1 0 0][0 0 0 1 0][0 0 0 0 1]]您可以更改对角线索引的位置。默认值为 0,表示主对角线。正值表示上对角线。负值表示对角线较低。以下是一些例子。让我们先演示一下上面的对角线:
y = np.eye(5, dtype=np.uint8, k=1)
print(y)输出如下所示:
[[0 1 0 0 0][0 0 1 0 0][0 0 0 1 0][0 0 0 0 1][0 0 0 0 0]]下面是演示下对角线的代码:
y = np.eye(5, dtype=np.uint8, k=-1)
print(y)输出如下所示:
[[0 0 0 0 0][1 0 0 0 0][0 1 0 0 0][0 0 1 0 0][0 0 0 1 0]]一个单位矩阵是对角线上所有元素都是 1,其余元素都是 0 的矩阵。函数np.identity()返回指定大小的单位矩阵,如下所示:
x = np.identity(5, dtype= np.uint8)
print(x)前面的代码与下面的代码产生相同的输出:
y = np.eye(5, dtype=np.uint8)
print(y)这两种方法的输出如下:
[[1 0 0 0 0][0 1 0 0 0][0 0 1 0 0][0 0 0 1 0][0 0 0 0 1]]函数np.ones()返回给定大小的矩阵,该矩阵的所有元素都为 1。
x = np.ones((2, 5, 5), dtype=np.int16)
print(x)运行代码,您将看到以下输出:
[[[1 1 1 1 1][1 1 1 1 1][1 1 1 1 1][1 1 1 1 1][1 1 1 1 1]][[1 1 1 1 1][1 1 1 1 1][1 1 1 1 1][1 1 1 1 1][1 1 1 1 1]]]函数np.zeroes()返回一个给定大小的矩阵,所有元素都为 0。
x = np.zeros((2, 5, 5, 2), dtype=np.int16)
print(x)运行代码并检查输出。
函数np.full()返回一个给定形状和类型的新数组,用传递的参数填充。这里有一个例子:
x = np.full((3, 3, 3), dtype=np.int16, fill_value = 5)
print(x)输出如下所示:
[[[5 5 5][5 5 5][5 5 5]][[5 5 5][5 5 5][5 5 5]][[5 5 5][5 5 5][5 5 5]]]一个下三角矩阵就是对角线和对角线以下的所有元素都是 1,其余元素都是 0。函数np.tri()返回给定大小的下三角矩阵,如下所示:
x = np.tri(3, 3, k=0, dtype=np.uint16)
print(x)输出如下所示:
[[1 0 0][1 1 0][1 1 1]]你甚至可以改变次对角线的位置。次对角线以下的所有元素都将为 0。
x = np.tri(5, 5, k=1, dtype=np.uint16)
print(x)输出如下所示:
[[1 1 0 0 0][1 1 1 0 0][1 1 1 1 0][1 1 1 1 1][1 1 1 1 1]]次对角线为负值的另一个示例如下:
x = np.tri(5, 5, k=-1, dtype=np.uint16)
print(x)输出如下所示:
[[0 0 0 0 0][1 0 0 0 0][1 1 0 0 0][1 1 1 0 0][1 1 1 1 0]]类似地,您可以使用函数np.tril()来获得下三角矩阵。它接受另一个矩阵作为参数。这里有一个演示:
x = np.ones((5, 5), dtype=np.uint8)
y = np.tril(x, k=-1)
print(y)输出如下所示:
[[0 0 0 0 0][1 0 0 0 0][1 1 0 0 0][1 1 1 0 0][1 1 1 1 0]]上三角矩阵的对角线和上面所有的元素都是 1,其余的元素都是 0。
x = np.ones((5, 5), dtype=np.uint8)
y = np.triu(x, k=0)
print(y)输出如下所示:
[[1 1 1 1 1][0 1 1 1 1][0 0 1 1 1][0 0 0 1 1][0 0 0 0 1]]你可以有一个负的次对角线,如下所示:
x = np.ones((5, 5), dtype=np.uint8)
y = np.triu(x, k=-1)
print(y)输出如下所示:
[[1 1 1 1 1][1 1 1 1 1][0 1 1 1 1][0 0 1 1 1][0 0 0 1 1]]你可以有一个负的次对角线,如下所示:
x = np.ones((5, 5), dtype=np.uint8)
y = np.triu(x, k=1)
print(y)输出如下所示:
[[0 1 1 1 1][0 0 1 1 1][0 0 0 1 1][0 0 0 0 1][0 0 0 0 0]]Matplotlib
Matplotlib 是科学 Python 生态系统不可或缺的一部分,它用于可视化。它是 NumPy 的扩展。它为绘图和可视化提供了一个类似 Matlab 的界面。它最初是由 John D. Hunter 开发的,作为可用于 Python 的开源替代方案。
您可以使用 Jupyter 笔记本进行安装,如下所示:
!pip3 install matplotlib注意pip3命令前的!符号。这是因为当你想在笔记本上运行一个操作系统命令时,你必须给它加上前缀!。
在安装 Matplotlib 库之前,您可能希望使用以下命令升级 pip:
!python -m pip install --upgrade pip要在笔记本中使用 Matplotlib 库进行基本绘图,必须导入其pyplot模块,如下所示:
import matplotlib.pyplot as pltpyplot模块提供了一个类似 Matlab 的界面来创建可视化。此外,要在笔记本中显示 Matplotlib 可视化效果,必须运行以下神奇命令:
%matplotlib inline这迫使 Matlab 在产生可视化的代码单元格的正下方内联显示输出。当我们需要使用 Matplotlib 时,我们会一直使用它。
让我们也导入 NumPy,如下所示:
import numpy as np你可以在 https://matplotlib.org/ 阅读更多关于 Matplotlib 的内容。
用 NumPy 和 Matplotlib 实现可视化
您现在将学习如何使用 Ndarray 创建例程创建 NumPy Ndarrays,然后使用 Matplotlib 来可视化它们。让我们从创建 Ndarrays 的例程开始。
第一个套路是arange()。它以给定的间隔创建均匀分布的值。停止值参数是必需的。起始值和间隔参数分别具有默认参数 0 和 1。这里有一个例子:
x = np.arange(6)在前面的示例中,停止值为 5。因此,它创建了一个从 0 开始到 4 结束的 Ndarray。该函数返回具有半开间隔的序列,这意味着停止值不包括在输出中。因为我们没有指定时间间隔,所以假设它为 1。您可以看到其输出和数据类型,如下所示:
print(x)
type(x)输出如下所示:
[0 1 2 3 4 5]
numpy.ndarray让我们继续绘制这些数字。为了在 2D 绘图,我们需要 x-y 对。让我们保持简单,通过运行下面的语句来说 y = f(x) = x:
y=x+1现在,让我们使用函数plot()来形象化这一点。它需要x和y的值以及绘图选项。您将在本章的后面了解更多关于绘图选项的内容。
plt.plot(x, y, 'o--')
plt.show()功能show()显示绘图。如你所见,我们用绘图选项o--进行可视化。这意味着点用实心圆表示,线用虚线表示,如图 3-1 所示。

图 3-1
形象化 y=f(x)=x+1
下面是一个带有开始和停止参数的函数arange()的函数调用示例:
np.arange(2, 6)它返回以下输出(它直接打印,我们没有将它存储在变量中):
array([2, 3, 4, 5])我们甚至可以为间隔添加一个参数,如下所示:
np.arange(2, 6, 2)输出如下所示:
array([2, 4])我们可以绘制如下多个图形:
plt.plot(x, y, 'o--')
plt.plot(x, -y, 'o-')
plt.show()输出将有一条线和另一条虚线,如图 3-2 所示。

图 3-2
可视化多条线
您甚至可以为图表添加标题,如下所示:
plt.plot(x, y, 'o--')
plt.plot(x, -y, 'o-')
plt.title('y=x and y=-x')
plt.show()输出的标题如图 3-3 所示。

图 3-3
可视化多行和标题
函数linspace(start, stop, number)返回指定间隔内均匀分布的数字数组。您必须向其传递起始值、结束值以及值的数量,如下所示:
N = 16
x = np.linspace(0, 15, N)
print(x)前面的代码创建了 11 个数字(0 到 10,包括 0 和 10),如下所示:
[ 0\. 1\. 2\. 3\. 4\. 5\. 6\. 7\. 8\. 9\. 10\. 11\. 12\. 13\. 14\. 15.]让我们想象一下:
y = x
plt.plot(x, y, 'o--')
plt.axis('off')
plt.show()图 3-4 显示了输出。

图 3-4
使用 linspace()时 y = x 的输出
如你所见,我们正在用线plt.axis('off')关闭轴。
同样,您可以按如下方式计算并可视化日志空间中的值:
y = np.logspace(0.1, 2, N)
print(y)
plt.plot(x, y, 'o--')
plt.show()打印功能的输出如下:
[ 1.25892541 1.68525904 2.25597007 3.01995172 4.042654875.41169527 7.2443596 9.69765359 12.98175275 17.3780082923.26305067 31.14105584 41.68693835 55.80417175 74.70218989100\. ]图 3-5 显示了输出。

图 3-5
日志空间的输出()
你甚至可以计算一个几何级数,如下所示:
y = np.geomspace(0.1, 2000, N)
print(y)
plt.plot(x, y, 'o--')
plt.show()print语句的输出如下:
[1.00000000e-01 1.93524223e-01 3.74516250e-01 7.24779664e-011.40262421e+00 2.71441762e+00 5.25305561e+00 1.01659351e+011.96735469e+01 3.80730788e+01 7.36806300e+01 1.42589867e+022.75945932e+02 5.34022222e+02 1.03346236e+03 2.00000000e+03]图 3-6 显示了输出。

图 3-6
geomspace()的输出
将 Matplotlib 程序作为脚本运行
可以使用 Python 的脚本模式运行 Matplotlib 程序。将清单 3-1 中显示的程序另存为prog01.py。
import numpy as np
import matplotlib.pyplot as pltx = np.arange(6)
print(x)
type(x)y=x+1plt.plot(x, y, 'o--')
plt.show()Listing 3-1prog01.py当你运行这个程序时,输出显示在一个单独的窗口中,如图 3-7 所示。

图 3-7
在单独的窗口中输出
我们将主要使用 Jupyter Notebook 在浏览器窗口中显示可视化效果。
摘要
本章重点介绍了创建 Ndarrays 的例程。您还学习了 Matplotlib 的基础知识。除了基础知识之外,您还学习了如何用简单的图形可视化 Ndarrays。NumPy 和 Matplotlib 的内容比您在本章中学到的更多。还有许多数字和数据可视化例程。
在下一章中,您将探索更多这样的处理 NumPy Ndarrays 的 NumPy 例程。
四、重温 Matplotlib 可视化
在前一章中,您学习了在 NumPy 库中创建和操作 Ndarrays 的许多例程。在这本书里,你会需要很多这样的程序。
本章致力于探索用 Matplotlib 准备的可视化的美学方面。您将学习如何定制 Matplotlib 可视化的外观。具体来说,我们将详细探讨以下主题:
-
单线图
-
多线图
-
网格、轴和标签
-
颜色、线条和标记
-
支线剧情
-
面向对象的风格
-
使用文本
在阅读完这一章之后,你将能够以编程的方式定制你的可视化的美学方面,使它们更美观。
单线图
当一个图形中只有一个使用函数plot()的可视化时,它被称为单线图。在本节中,您将看到绘制单线图的几种方法。我们已经使用了函数plot()来绘制单线图。让我们用几个更具体的例子来更详细地探讨这个概念。
为本章中的演示创建一个新笔记本。您还可以使用 Python 列表来可视化绘图,如下所示:
%matplotlib inline
import matplotlib.pyplot as plt
x = [4, 5, 3, 1, 6, 7]
plt.plot(x)
plt.show()图 4-1 显示了输出。

图 4-1
演示一个简单的单线图
在这种情况下,y 轴的值是假定的。
下面是另一个使用 n 数组的单线图示例:
import numpy as np
x = np.arange(25)
plt.plot(x)
plt.show()图 4-2 显示了输出。

图 4-2
带有 arange()的简单单线图
我们来形象化的描述一下二次图 y = f(x) = x 3 +1。代码如下:
plt.plot(x, [(y**3 + 1) for y in x])
plt.show()图 4-3 显示了输出。

图 4-3
y = f(x) = x 3 +1
您可以用简单的方式编写相同的代码,如下所示:
plt.plot(x, x**3 + 1)
plt.show()多线图
可以在同一输出中显示多个图。让我们看看如何在同一个可视化中显示多条曲线。下面是一个简单的例子:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(7)
plt.plot(x, -x**2)
plt.plot(x, -x**3)
plt.plot(x, -2*x)
plt.plot(x, -2**x)
plt.show()图 4-4 显示了输出。

图 4-4
多线图
如您所见,Matplotlib 自动为曲线单独分配颜色。
您可以用简单的方式编写相同的代码,如下所示:
plt.plot(x, -x**2, x, -x**3,x, -2*x, x, -2**x)
plt.show()输出将与图 4-4 相同。
让我们看另一个例子:
x = np.array([[3, 2, 5, 6], [7, 4, 1, 5]])
plt.plot(x)
plt.show()图 4-5 显示了输出。

图 4-5
多线图,另一个例子
您也可以使用随机数据创建多行图形,如下所示:
data = np.random.randn(2, 10)
print(data)
plt.plot([data[0], data[1]])
plt.show()图 4-6 显示了输出。

图 4-6
多线图,随机数据
在本例中,我们使用例程np.random.randn()以随机方式生成数据。因为这个例程会生成随机数据,所以每次执行时输出都会不同。因此,每次执行代码时,您看到的输出都是不同的。
网格、轴和标签
现在,您将学习如何在可视化中启用网格。这可以通过语句plt.grid(True)来完成。您还将学习如何操作轴的限制。但在此之前,您将很快学会如何在硬盘上将可视化保存为图像。请看下面的代码:
x = np.arange(3)
plt.plot(x, -x**2, x, -x**3, x, -2*x, x, -2**x)
plt.grid(True)
plt.savefig('test.png')
plt.show()语句plt.savefig('test.png')将图像保存在 Jupyter 笔记本文件的当前目录中。图 4-7 显示输出。

图 4-7
多线图
您可以看到轴的限制默认设置如下:
x = np.arange(3)
plt.plot(x, -x**2, x, -x**3, x, -2*x, x, -2**x)
plt.grid(True)
print(plt.axis())
plt.show()图 4-8 显示了输出。

图 4-8
查看轴的值
您也可以自定义轴的值,如下所示:
x = np.arange(3)
plt.plot(x, -x**2, x, -x**3, x, -2*x, x, -2**x)
plt.grid(True)
plt.axis([0, 2, -8, 0])
print(plt.axis())
plt.show()语句plt.axis([0, 2, -8, 0])设置轴的值。第一对(0,2)指 x 轴的极限,第二对(-8,0)指 y 轴的极限。您可以使用函数xlim()和ylim()用不同的语法编写前面的代码,如下所示:
x = np.arange(3)
plt.plot(x, -x**2, x, -x**3, x, -2*x, x, -2**x)
plt.grid(True)
plt.xlim([0, 2])
plt.ylim([-8, 0])
print(plt.axis())
plt.show()两个示例产生相同的输出,如图 4-9 所示。

图 4-9
自定义轴
您可以为轴添加标题和标签,如下所示:
x = np.arange(3)
plt.plot(x, -x**2, x, -x**3, x, -2*x, x, -2**x)
plt.grid(True)
plt.xlabel('x = np.arange(3)')
plt.xlim([0, 2])
plt.ylabel('y = f(x)')
plt.ylim([-8, 0])
plt.title('Simple Plot Demo')
plt.show()这将产生标签和标题如图 4-10 所示的输出。

图 4-10
可视化的标题和轴的标签
您可以在plot()函数中为参数label传递一个参数,然后调用函数legend()来创建一个图例,如下所示:
x = np.arange(3)
plt.plot(x, -x**2, label='-x**2')
plt.plot(x, -x**3, label='-x**3')
plt.plot(x, -2*x, label='-2*x')
plt.plot(x, -2**x, label='-2**x')
plt.legend()
plt.grid(True)
plt.xlabel('x = np.arange(3)')
plt.xlim([0, 2])
plt.ylabel('y = f(x)')
plt.ylim([-8, 0])
plt.title('Simple Plot Demo')
plt.show()该代码产生带有曲线图例的输出,如图 4-11 所示。

图 4-11
带图例的输出
除了将图例字符串作为参数传递给函数plot(),还可以将字符串列表作为参数传递给函数legend(),如下所示:
x = np.arange(3)
plt.plot(x, -x**2, x, -x**3, x, -2*x, x, -2**x)
plt.legend(['-x**2', '-x**3', '-2*x', '-2**x'])
plt.grid(True)
plt.xlabel('x = np.arange(3)')
plt.xlim([0, 2])
plt.ylabel('y = f(x)')
plt.ylim([-8, 0])
plt.title('Simple Plot Demo')
plt.show()这产生了与图 4-11 相同的输出。
您也可以通过对前面代码中的plt.legend()进行以下更改来更改图例框的位置:
x = np.arange(3)
plt.plot(x, -x**2, x, -x**3, x, -2*x, x, -2**x)
plt.legend(['-x**2', '-x**3', '-2*x', '-2**x'],loc='lower center')
plt.grid(True)
plt.xlabel('x = np.arange(3)')
plt.xlim([0, 2])
plt.ylabel('y = f(x)')
plt.ylim([-8, 0])
plt.title('Simple Plot Demo')
plt.show()图 4-12 显示了输出。

图 4-12
图例位于中上位置的输出
最后,让我们用下面的代码将可视化保存到磁盘:
x = np.arange(3)
plt.plot(x, -x**2, x, -x**3, x, -2*x, x, -2**x)
plt.legend(['-x**2', '-x**3', '-2*x', '-2**x'],loc='lower center')
plt.grid(True)
plt.xlabel('x = np.arange(3)')
plt.xlim([0, 2])
plt.ylabel('y = f(x)')
plt.ylim([-8, 0])
plt.title('Simple Plot Demo')
plt.savefig('test.png')
plt.show()颜色、样式和标记
到目前为止,在多行绘图的情况下,您已经看到 Matplotlib 自动分配颜色、样式和标记。您已经看到了一些如何定制它们的例子。现在,在本节中,您将学习如何详细定制它们。
先说颜色。以下代码列出了 Matplotlib 支持的所有原色(在此示例中,我们不自定义样式和标记):
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as npx = np.arange(5)
y = x
plt.plot(x, y+0.4, 'g')
plt.plot(x, y+0.2, 'y')
plt.plot(x, y, 'r')
plt.plot(x, y-0.2, 'c')
plt.plot(x, y-0.4, 'k')
plt.plot(x, y-0.6, 'm')
plt.plot(x, y-0.8, 'w')
plt.plot(x, y-1, 'b')
plt.show()图 4-13 显示了输出。

图 4-13
颜色演示
您也可以编写前面的代码,如下所示:
plt.plot(x, y+0.4, 'g', x, y+0.2, 'y', x, y, 'r', x, y-0.2, 'c', x, y-0.4, 'k', x, y-0.6, 'm', x, y-0.8, 'w', x, y-1, 'b')
plt.show()输出将与图 4-13 相同。
您可以自定义线条样式,如下所示:
plt.plot(x, y, '-', x, y+1, '--', x, y+2, '-.', x, y+3, ':')
plt.show()图 4-14 显示了输出。

图 4-14
线条样式
您甚至可以按如下方式更改标记:
plt.plot(x, y, '.')
plt.plot(x, y+0.5, ',')
plt.plot(x, y+1, 'o')
plt.plot(x, y+2, '<')
plt.plot(x, y+3, '>')
plt.plot(x, y+4, 'v')
plt.plot(x, y+5, '^')
plt.plot(x, y+6, '1')
plt.plot(x, y+7, '2')
plt.plot(x, y+8, '3')
plt.plot(x, y+9, '4')
plt.plot(x, y+10, 's')
plt.plot(x, y+11, 'p')
plt.plot(x, y+12, '*')
plt.plot(x, y+13, 'h')
plt.plot(x, y+14, 'H')
plt.plot(x, y+15, '+')
plt.plot(x, y+16, 'D')
plt.plot(x, y+17, 'd')
plt.plot(x, y+18, '|')
plt.plot(x, y+19, '_')
plt.show()图 4-15 显示了输出。

图 4-15
标记
您可以结合所有三种技术(针对颜色、标记和线条样式)来自定义可视化,如下所示:
plt.plot(x, y, 'mo--')
plt.plot(x, y+1 , 'g*-.')
plt.show()图 4-16 显示了输出。

图 4-16
定制一切
这些是您可以在 Matplotlib 中进行的基本自定义。您可以非常详细地定制一切。下面是一个代码示例:
plt.plot(x, y, color='g', linestyle='--', linewidth=1.5,marker='^', markerfacecolor='b', markeredgecolor='k',markeredgewidth=1.5, markersize=5)
plt.grid(True)
plt.show()图 4-17 显示了输出。

图 4-17
更加详细地定制一切
您甚至可以自定义 x 轴和 y 轴上的值,如下所示:
x = y = np.arange(10)
plt.plot(x, y, 'o--')
plt.xticks(range(len(x)), ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'])
plt.yticks(range(0, 10, 1))
plt.show()图 4-18 显示了输出。

图 4-18
自定义轴上的记号
面向对象绘图
您可以以面向对象的方式创建地块。让我们重写一个早期的代码示例,如下所示:
fig, ax = plt.subplots()
ax.plot(x, -x**2, label='-x**2')
ax.plot(x, -x**3, label='-x**3')
ax.plot(x, -2*x, label='-2*x')
ax.plot(x, -2**x, label='-2**x')
ax.set_xlabel('x = np.arange(3)')
ax.set_ylabel('y = f(x)')
ax.set_title('Simple Plot Demo')
ax.legend()
ax.grid(True)
plt.show()注意,我们使用 axis 对象来绘制和设置标签和标题。图 4-19 显示了输出。

图 4-19
面向对象绘图的输出
您也可以使用功能ax.text()或功能plt.text()添加文本。这些函数接受要显示的坐标和文本。下面是一个例子:
fig, ax = plt.subplots()
ax.plot(x, -x**2, label='-x**2')
ax.plot(x, -x**3, label='-x**3')
ax.plot(x, -2*x, label='-2*x')
ax.plot(x, -2**x, label='-2**x')
ax.set_xlabel('x = np.arange(3)')
ax.set_ylabel('y = f(x)')
ax.set_title('Simple Plot Demo')
ax.legend()
ax.grid(True)
ax.text(0.25, -5, "Simple Plot Demo")
plt.show()图 4-20 显示了输出。

图 4-20
呈现文本
支线剧情
您可以在同一个输出中显示多个单独的图形。这种技术被称为副音色。支线剧情可以有自己的标题、标签和其他说明。支线剧情是在网格中创建的。第一个支线剧情位置在左上方。其他子绘图位置相对于第一个位置。下面是一个例子:
x = np.arange(3)
plt.subplots_adjust(wspace=0.3,hspace=0.3)
plt.subplot(2, 2, 1)
plt.plot(x, -x**2)
plt.subplot(2, 2, 2)
plt.plot(x, -x**3)
plt.subplot(2, 2, 3)
plt.plot(x, -2*x)
plt.subplot(2, 2, 4)
plt.plot(x, -2**x)
plt.show()传递给plt.subplot()的前两个参数表示网格大小,第三个参数表示特定子绘图的位置。图 4-21 显示输出。

图 4-21
支线剧情
您可以用面向对象的方式编写相同的代码,如下所示:
fig, axs = plt.subplots(2, 2)
plt.subplots_adjust(wspace=0.3,hspace=0.3)
axs[0, 0].plot(x, -x**2)
axs[0, 1].plot(x, -x**3)
axs[1, 0].plot(x, -2*x)
axs[1, 1].plot(x, -2**x)
plt.show()代码产生与图 4-21 所示相同的输出。
摘要
本章着重于可视化和各种定制。您学到了很多关于数据可视化和根据需求定制可视化的知识。您还了解了面向对象的绘图风格和支线剧情。你在本章中学到的概念将在本书中用来可视化数据。
在下一章,我们将探索更多的样式表、图例和布局计算。
五、样式和布局
在前一章中,您学习了许多与使用 Matplotlib 创建可视化相关的高级概念。
在这一章中,我们将继续探索更多与可视化相关的概念。具体来说,我们将详细探讨以下主题:
-
风格
-
布局
阅读完本章后,你将能够使用颜色、样式表和自定义布局。
风格
在本节中,您将探索 Matplotlib 中可用的各种样式。到目前为止,我们一直使用默认样式。样式规定了标记大小、颜色和字体等内容。Matplotlib 内置了很多样式。下面是一个应用内置样式的简短示例:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('ggplot')
data = np.random.randn(10)现在让我们想象一下:
plt.plot(data)
plt.show()这里我们使用 ggplot2 的风格,它是 R 编程语言的可视化包。图 5-1 显示了输出。

图 5-1
ggplot style(打印样式)
你一定很想知道所有可用款式的名称。您可以使用以下命令打印姓名:
print(plt.style.available)以下是显示所有可用样式名称的输出:
['Solarize_Light2', '_classic_test_patch', 'bmh', 'classic', 'dark_background', 'fast', 'fivethirtyeight', 'ggplot', 'grayscale', 'seaborn', 'seaborn-bright', 'seaborn-colorblind', 'seaborn-dark', 'seaborn-dark-palette', 'seaborn-darkgrid', 'seaborn-deep', 'seaborn-muted', 'seaborn-notebook', 'seaborn-paper', 'seaborn-pastel', 'seaborn-poster', 'seaborn-talk', 'seaborn-ticks', 'seaborn-white', 'seaborn-whitegrid', 'tableau-colorblind10']让我们应用经典的matplotlib风格如下:
plt.style.use('classic')
plt.plot(data)
plt.show()图 5-2 显示了输出。

图 5-2
古典派风格
请注意,一旦应用了样式,该样式将应用于整个笔记本。因此,如果您想切换回默认样式,可以使用下面的代码:
plt.style.use('default')让我们用下面的数据来展示一下:
plt.plot(data)
plt.show()图 5-3 显示了输出。

图 5-3
默认样式
现在让我们演示一下当我们改变样式时颜色是如何受到影响的。让我们定义如下所示的数据:
n = 3
data = np.linspace(0, 2*n*np.pi, 300)此外,让我们定义一个自定义函数,如下所示:
def sinusoidal(sty):plt.style.use(sty)fig, ax = plt.subplots()ax.plot(data, np.sin(data), label='Sine')ax.plot(data, np.cos(data), label='Cosine')ax.legend()函数是可以被调用来执行某种操作的例程。到目前为止,我们一直在使用 Python 本身自带的库函数以及像 NumPy 和 Matplotlib 这样的库。这里,在代码片段中,我们定义了自己的自定义函数。这个自定义函数接受一个参数。我们使用传递的参数作为可视化的样式。让我们用默认样式调用这个函数,如下所示:
sinusoidal('default')
plt.show()图 5-4 显示了输出。

图 5-4
默认样式正弦图
让我们如下使用ggplot样式:
sinusoidal('ggplot')
plt.show()图 5-5 显示了输出。

图 5-5
ggplot 式正弦图
让我们来看看 Seaborn 风格,如下图所示:
sinusoidal('seaborn')
plt.show()图 5-6 显示了输出。

图 5-6
Seaborn 式正弦图
您已经看到样式应用于整个笔记本,并且您已经学会切换到默认样式。您可以局部更改代码块的样式,如下所示:
with plt.style.context('Solarize_Light2'):data = np.linspace(0, 6 * np.pi)plt.plot(np.sin(data), 'g.--')plt.show()图 5-7 显示了输出。

图 5-7
临时造型
布局
在本节中,您将学习布局。你已经学习了第四章中的支线剧情,如果你想再次使用默认样式,你可以运行下面一行代码将样式重置为默认样式:
plt.style.use('default')让我们修改一下,创建一个 2×2 的可视化效果,如下所示:
fig, axs = plt.subplots(ncols=2, nrows=2,constrained_layout=True)
plt.show()图 5-8 显示了输出。

图 5-8
支线剧情
你也可以使用gridspec创建支线剧情,如下所示:
import matplotlib.gridspec as gridspecfig = plt.figure(constrained_layout=True)
specs = gridspec.GridSpec(ncols=2, nrows=2, figure=fig)
ax1 = fig.add_subplot(specs[0, 0])
ax2 = fig.add_subplot(specs[0, 1])
ax3 = fig.add_subplot(specs[1, 0])
ax4 = fig.add_subplot(specs[1, 1])
plt.show()前面的代码将创建一个类似图 5-8 的子绘图。您必须为输出编写大量代码,而这些代码只需几行代码就可以获得。但是,您可以使用此方法创建更复杂的可视化效果。让我们创建一个 3×3 的可视化,这样一个图就占据了一整行。
fig = plt.figure(constrained_layout=True)
gs = fig.add_gridspec(3, 3)
ax1 = fig.add_subplot(gs[0, :])
ax1.set_title('gs[0, :]')
ax2 = fig.add_subplot(gs[1, :])
ax2.set_title('gs[1, :]')
ax3 = fig.add_subplot(gs[2, :])
ax3.set_title('gs[2, :]')
plt.show()该代码将产生如图 5-9 所示的输出。

图 5-9
定制支线剧情
您也可以有如下垂直图:
fig = plt.figure(constrained_layout=True)
gs = fig.add_gridspec(3, 3)
ax1 = fig.add_subplot(gs[:, 0])
ax1.set_title('gs[:, 0]')
ax2 = fig.add_subplot(gs[:, 1])
ax2.set_title('gs[:, 1]')
ax3 = fig.add_subplot(gs[:, 2])
ax3.set_title('gs[:, 2]')
plt.show()图 5-10 显示了输出。

图 5-10
定制支线剧情
让我们看一个更复杂的例子。
fig = plt.figure(constrained_layout=True)
gs = fig.add_gridspec(3, 3)
ax1 = fig.add_subplot(gs[0, :])
ax1.set_title('gs[0, :]')
ax2 = fig.add_subplot(gs[1, :-1])
ax2.set_title('gs[1, :-1]')
ax3 = fig.add_subplot(gs[1:, -1])
ax3.set_title('gs[1:, -1]')
ax4 = fig.add_subplot(gs[-1, 0])
ax4.set_title('gs[-1, 0]')
ax5 = fig.add_subplot(gs[-1, -2])
ax5.set_title('gs[-1, -2]')
plt.show()图 5-11 显示了输出。

图 5-11
定制支线剧情
这就是你定制支线剧情的方法。
摘要
这一章关注的是风格和支线剧情。在整本书中,你会有节制地使用这些概念。
在下一章,我们将探索一些 Matplotlib 的方法来创建可视化。
六、折线图、条形图和散点图
在前一章中,您学习了许多与 Matplotlib 可视化相关的高级概念。
在本章和接下来的几章中,你将学习一些创建数据可视化的技术。具体来说,在本章中,您将学习如何创建以下数据可视化:
-
线条和日志
-
误差线
-
条形图
-
散点图
阅读本章后,你将能够使用线条、对数、条形图和散点图。
线条和日志
在前面的章节中,你已经看到了如何绘制线条。为了热身,我们再来看一个线条示例,如下所示:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
data = np.linspace(0, 9, 10)现在让我们想象一下。
plt.plot(data)
plt.show()图 6-1 显示了输出。

图 6-1
线形图示例
让我们创建一个图表,使 x 轴为对数轴,y 轴为法线轴,如下所示:
t = np.arange(0.01, 10, 0.01)
plt.semilogx(t, np.cos(2 * np.pi * t))
plt.show()图 6-2 显示了输出。

图 6-2
正常 y 轴和对数 x 轴
同样,you可以create a对数y-轴和a法线x-轴as follows:
plt.semilogy(t, np.cos(2 * np.pi * t))
plt.show()图 6-3 显示了输出。

图 6-3
正常 x 轴和对数 y 轴
You可以有两个轴be l对数,as shown here:
plt.loglog(t, np.cos(2 * np.pi * t))
plt.show()图 6-4 显示了输出。

图 6-4
两个对数轴
误差线
您还可以使用可视化来显示数据中的错误。当观测数据存在误差的可能性时,通常要在观测中提及。你会说“有 96%的置信区间。”这意味着给定的数据可能有 4%的误差。这给了人们一个关于量的精度的一般概念。当你想表现这种自信(或缺乏自信)时,你可以使用误差线。
为此,您必须使用函数errorbar()。您可以创建一个数组或列表来存储错误数据。我们可以有真实的数据,也可以模拟如下:
x = np.linspace (0, 2 * np.pi, 100)
y = np.sin(x)
ye = np.random.rand(len(x))/10
plt.errorbar(x, y, yerr = ye)
plt.show()在本例中,我们在 y 轴上显示误差。图 6-5 显示了输出。

图 6-5
y 轴上的误差
同样,您可以在 x 轴上显示误差数据。
xe = np.random.rand(len(x))/10
plt.errorbar(x, y, xerr = xe)
plt.show()图 6-6 显示了输出。

图 6-6
x 轴上的误差
You可以显示两个轴上的误差,如下所示:
plt.errorbar(x, y, xerr = xe, yerr = ye)
plt.show()图 6-7 显示了输出。

图 6-7
两个轴上都有误差
条形图
条形图用条形表示离散和分类数据项。您可以用竖条或横条来表示数据。条形的高度或长度总是与数据量成比例。当您有离散的分类数据时,可以使用条形图或条形图。下面是一个简单的条形图示例:
x = np.arange(4)
y = np.random.rand(4)
plt.bar(x, y)
plt.show()图 6-8 显示了输出。

图 6-8
条形图
您可以有如下组合条形图:
y = np.random.rand(3, 4)
plt.bar(x + 0.00, y[0], color = 'b', width = 0.25)
plt.bar(x + 0.25, y[1], color = 'g', width = 0.25)
plt.bar(x + 0.50, y[2], color = 'r', width = 0.25)
plt.show()图 6-9 显示了输出。

图 6-9
组合条形图
前面的图是垂直条形图的例子。类似地,您可以有如下所示的水平条形图:
x = np.arange(4)
y = np.random.rand(4)
plt.barh(x, y)
plt.show()图 6-10 显示了输出。

图 6-10
水平条形图
您也可以组合水平条形图,如下所示:
y = np.random.rand(3, 4)
plt.barh(x + 0.00, y[0], color = 'b', height=0.25)
plt.barh(x + 0.25, y[1], color = 'g', height=0.25)
plt.barh(x + 0.50, y[2], color = 'r', height=0.25)
plt.show()图 6-11 显示了输出。

图 6-11
组合水平条形图
散点图
您还可以使用散点图来可视化您的数据。您通常会看到一组带有散点图的两个变量。一个变量分配给 x 轴,另一个分配给 y 轴。然后你为 x-y 对的值画一个点。x 和 y 的大小必须相同(它们总是一维数组)。您可以通过控制点的颜色和大小来显示其他变量。在这种情况下,表示 x、y、颜色和大小的一维数组的大小必须相同。
在下面的示例中,我们将随机的 x 轴和 y 轴值和颜色分配给 1,000 个点。所有点的大小都是 20。
N = 1000
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
size = (20)
plt.scatter(x, y, s=size, c=colors, alpha=1)
plt.show()图 6-12 显示了输出。

图 6-12
散点图
在这个例子中,点的大小是固定的。您还可以设置图形上每个位置的大小(这取决于 x 和 y 坐标的值)。这里有一个例子:
N = 1000
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
size = (50 * x * y)
plt.scatter(x, y, s=size, c=colors, alpha=1)
plt.show()图 6-13 显示了输出。

图 6-13
散点图
您刚刚学习了如何创建散点图。
摘要
在这一章中,我们以一个线条图开始了一点预热。然后,您学习了如何创建各种日志图。您还学习了如何显示误差幅度以及如何创建条形图。最后,您学习了如何创建散点图。
在下一章中,您将学习更多创建数据可视化的技术。您将学习如何创建直方图、等值线、流图和热图。
七、直方图、等高线和流图
在前一章中,您学习了许多用线条、条形图和散点图创建可视化效果的方法。
在本章中,我们将继续探索 Matplotlib 的各种可视化。您将学习如何创建直方图和等高线。您还将学习如何用流图绘制矢量。
直方图
在学习如何创建各种类型的直方图之前,您需要了解它们是什么。首先,你需要知道什么是频率表。假设您有一组具有不同值的成员。您可以创建一个表,该表在一列中包含不同的值范围。每个存储桶必须至少有一个值。然后,您可以计算落入该存储桶的成员数量,并根据存储桶记录这些数量。让我们看一个简单的例子。请为此创建一个新笔记本,如下所示:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt现在,让我们手动创建一个数据集,并将存储桶的数量定义为该集的基数(不同元素的数量)。
x = [1, 3, 5, 1, 2, 4, 4, 2, 5, 4, 3, 1, 2]
n_bins = 5您可以使用以下代码显示输出:
plt.hist(x, bins=n_bins)
plt.show()图 7-1 显示了输出。

图 7-1
简单直方图
正态(或高斯)分布是一种连续概率分布。通常是钟形曲线。让我们用正态分布曲线创建一个直方图。为了创建数据,我们将使用一个 NumPy 例程。让我们画一个正态分布的随机数据直方图如下:
np.random.seed(31415)
n_points = 10000
n_bins = 15
x = np.random.randn(n_points)
plt.hist(x, bins=n_bins)
plt.show()图 7-2 显示了输出。

图 7-2
随机数据的简单直方图
一维数据的直方图是一个 2D 图(如图 7-2 )。当您想要创建 2D 数据的直方图时,您必须创建一个 3D 图形,其中数据变量位于 x 轴和 y 轴上,直方图位于 z 轴上。换句话说,您可以使用 2D 坐标来显示这个 3D 可视化,并从顶部(俯视图)查看直方图。这些条可以用颜色编码来表示它们的大小。
y = np.random.randn(n_points)
plt.hist2d(x, y, bins=50)
plt.show()图 7-3 显示了输出。

图 7-3
2D 数据的简单直方图
您可以通过设置透明度和颜色来自定义直方图,如下所示:
plt.hist(x, 20, density=True,histtype='stepfilled',facecolor='g', alpha=0.5)
plt.show()图 7-4 显示了输出。

图 7-4
定制直方图
您也可以只显示直方图的轮廓,如下所示:
plt.hist(x, 20, density=True,histtype='step')
plt.show()图 7-5 显示了输出。

图 7-5
仅带有轮廓的自定义直方图
轮廓
轮廓代表物体的轮廓。轮廓是突出物体形状的连续(在许多情况下是闭合的)线条。等高线在制图学领域很有用,制图学就是制作地图。在地图上,等高线连接等高的点。因此,等高线上的所有点都在相同的高度(从海平面开始)。在我们使用等高线的其他应用中,同一等高线上的所有点具有相同的值(或量值)。
让我们画一个简单的轮廓。我们将通过创建如下圆形轮廓来创建和可视化我们自己的数据:
x = np.arange(-3, 3, 0.005)
y = np.arange(-3, 3, 0.005)
X, Y = np.meshgrid(x, y)
Z = (X**2 + Y**2)
out = plt.contour(X, Y, Z)
plt.clabel(out, inline=True,fontsize=10)
plt.show()图 7-6 显示了输出。

图 7-6
简单标记轮廓
您还可以向输出中添加一个颜色条,如下所示:
out = plt.contour(X, Y, Z)
plt.clabel(out, inline=True,fontsize=10)
plt.colorbar(out)
plt.show()图 7-7 显示了输出。

图 7-7
带有颜色条的简单标注轮廓
您也可以按如下方式设置轮廓的颜色:
out = plt.contour(X, Y, Z,colors='g')
plt.clabel(out, inline=True,fontsize=10)
plt.show()图 7-8 显示了输出。

图 7-8
带有自定义颜色的简单标注轮廓
您也可以有一个填充的轮廓。这些样式用于高亮显示等高线可视化中的各个区域。让我们如下可视化填充轮廓:
plt.contourf(X, Y, Z,hatches=['-', '/', '\\', '//'],cmap='cool',alpha=0.75)
plt.show()图 7-9 显示了输出。

图 7-9
填充轮廓
用流图可视化矢量
到目前为止,我们已经可视化了标量实体,它们具有量值。到目前为止,您所学的所有可视化对于标量来说都是非常好的。相反,向量是有大小和方向的实体。例如,力有大小和方向。一个具体的例子是磁力场。您可以用流图可视化矢量。让我们创建自己的数据集来对此进行可视化。我们将用X和Y创建一个网格。然后我们将创建U和V来显示数量级。
Y, X = np.mgrid[-5:5:200j, -5:5:300j]
U = X**2 + Y**2
V = X + Y您可以创建一个简单的流图,如下所示:
plt.streamplot(X, Y, U, V)
plt.show()图 7-10 显示了输出。

图 7-10
简单流图
您也可以拥有如下可变密度的流图:
plt.streamplot(X, Y, U, V,density=[0.5, 0.75])
plt.show()图 7-11 显示了输出。

图 7-11
可变密度的流图
您也可以按如下方式将颜色分配给流图:
plt.streamplot(X, Y, U, V, color=V,linewidth=1, cmap='cool')
plt.show()图 7-12 显示了输出。

图 7-12
可变颜色的流图
您也可以创建具有可变线宽的流图,如下所示:
plt.streamplot(X, Y, U, V,density=0.6,color='k',linewidth=X)
plt.show()图 7-13 显示了输出。

图 7-13
可变线宽的流图
您也可以使用箭图进行向量可视化,如下所示:
X = np.arange(-5, 5, 0.5)
Y = np.arange(-10, 10, 1)
U, V = np.meshgrid(X, Y)
plt.quiver(X, Y, U, V)
plt.show()图 7-14 显示了输出。

图 7-14
用颤动图可视化矢量场
摘要
在本章中,您学习了直方图、等值线和流图。
在下一章,你将学习如何可视化图像和音频。您还将学习图像的插值方法。
八、图像和音频可视化
在前一章中,您学习了如何用直方图、等值线和流图创建可视化效果。
在本章中,您将学习如何使用 Matplotlib 处理和可视化图像和音频。具体来说,您将了解本章中的以下主题:
-
可视化图像
-
插值方法
-
音频可视化
-
音频处理
读完这一章,我们将能够用 Matplotlib 可视化图像和音频。
可视化图像
你可以用 Matplotlib 读取数字图像,它支持许多图像格式,尽管你必须安装一个名为 pillow 的库。如下图所示安装枕头:
!pip3 install pillow我建议您为本章创建一个新的笔记本。使用以下语句导入库:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt您可以使用 Windows 上的功能imread()读取数字图像,如下所示:
img1 = plt.imread("D:/Dataset/4.2.03.tiff")Linux 和 Mac 的代码类似,如下所示:
img1 = plt.imread("~/Dataset/4.2.03.tiff")现在让我们看看变量的内容,如下所示:
print(img1)输出如下所示:
array([[[164, 150, 71],[ 63, 57, 31],[ 75, 43, 10],...,[ 5, 8, 5],[ 2, 5, 0],[ 4, 5, 2]]], dtype=uint8)为了节省空间,我删除了输出的中间部分,但这毕竟是一个数组。我们可以用下面的代码来确认这一点:
type(img1)输出如下所示:
numpy.ndarray要了解有关图像的更多信息,可以检查存储图像数据的 Ndarray 的属性。彩色图像存储为 3D 矩阵,该矩阵的每个维度都用于可视化颜色通道的强度。彩色图像以红、绿、蓝(RGB)格式读取和存储。因为灰度图像中没有颜色,所以只有一个平面(2D 矩阵)存储灰度值的强度。
您可以使用例程imshow()将任何 n 数组显示为图像,如下所示:
plt.imshow(img1)
plt.show()图 8-1 显示了输出。

图 8-1
可视化图像
这是一幅彩色图像。Matplotlib 库自动检测图像是否有多个通道,并将其显示为彩色图像。然而,当我们显示灰度图像时,它会出错一点。
img2 = plt.imread("D:/Dataset/5.1.11.tiff")
plt.imshow(img2)
plt.show()图 8-2 显示了输出。

图 8-2
可视化灰度图像
图像数据解释正确,但颜色似乎有些问题。对于灰度图像,Matplotlib 使用默认颜色映射,因此您必须按如下方式手动指定颜色映射:
plt.imshow(img2, cmap = 'gray')
plt.show()图 8-3 显示了输出。

图 8-3
用正确的颜色映射可视化灰度图像
颜色映射是定义可视化颜色的值矩阵。让我们为图像尝试另一种颜色映射,如下所示:
plt.imshow(img2, cmap = 'cool')
plt.show()图 8-4 显示了输出。

图 8-4
可视化一张 灰度图像 与一张 冷色图
您可以使用以下语句在当前版本的 Matplotlib 中显示颜色映射列表:
plt.colormaps()输出如下所示:
['Accent','Accent_r',.........'twilight_r','twilight_shifted','twilight_shifted_r','viridis','viridis_r','winter','winter_r']我已经删除了输出的一大部分,以便适合这本书。您可以使用这些彩色地图中的任何一种来满足您的可视化需求。作为练习,尝试一些带有灰度图像的彩色地图。
图像掩蔽
您可以使用圆形遮罩图像区域,如下所示:
import matplotlib.patches as patches
fig, ax = plt.subplots()
im = ax.imshow(img1)
patch = patches.Circle((245, 200),radius=200,transform=ax.transData)
im.set_clip_path(patch)ax.axis('off')
plt.show()在这个代码示例中,我们用例程Circle()在 XY 坐标 245,200 处创建一个圆。半径为 200 像素。此外,我们正在使用例程set_clip_path()裁剪带有圆圈的图像,并显示它。图 8-5 显示了输出。

图 8-5
用圆形剪裁图像
插值方法
您可以将简单的 NumPy Ndarray 显示为图像,如下所示:
img3 = [[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]]
plt.imshow(img3)
plt.show()图 8-6 显示了输出。

图 8-6
numpy ndarray 作为映像
该图像没有使用可视化的插值方法。我们可以演示如下插值方法:
methods = ['none', 'antialiased', 'nearest', 'bilinear','bicubic', 'spline16', 'spline36', 'hanning','hamming', 'hermite', 'kaiser', 'quadric','catrom', 'gaussian', 'bessel', 'mitchell','sinc', 'lanczos', 'blackman']fig, axs = plt.subplots(nrows=4, ncols=6, figsize=(9, 6),subplot_kw={'xticks': [], 'yticks': []})for ax, interp_method in zip(axs.flat, methods):ax.imshow(img3, interpolation=interp_method, cmap='hot')ax.set_title(str(interp_method))plt.tight_layout()
plt.show()在这个代码示例中,我们只是用 Matplotlib 中所有可用的插值方法显示了相同的 Ndarray。图 8-7 显示了输出。

图 8-7
插值方法演示
音频可视化
可以使用 Matplotlib 来可视化音频。您只需要 SciPy 库来读取音频文件并将数据存储到 Ndarray 中。让我们安装它,如下所示:
!pip3 install scipy让我们导入所有需要的库,如下所示:
%matplotlib inline
import matplotlib.pyplot as plt
from scipy.io import wavfile现在让我们来读一个音频文件。我正在读取一个 WAV 文件,如下所示:
samplerate, data = wavfile.read('sample.wav')让我们看看音乐的采样率,如下所示:
print(samplerate)输出如下所示:
44100这是一个常见的采样速率(44.1 kHz)。你可以在 https://www.izotope.com/en/learn/digital-audio-basics-sample-rate-and-bit-depth.html 阅读一篇关于音频采样率的资料性文章。
您还可以按如下方式显示数据:
print(data)数据如下:
[[-204 23][-233 32][-191 34]...[ 646 676][ 679 707][ 623 650]]您可以按如下方式检查音频的属性:
print(type(data))
print(data.shape)
print(data.ndim)
print(data.dtype)
print(data.size)
print(data.nbytes)输出如下所示:
<class 'numpy.ndarray'>
(2601617, 2)
2
int16
5203234
10406468如您所见,音频数据被检索并存储在 NumPy 中。它存储在 2D 矩阵中。假设音频数据有 N 个数据点(也称为采样点);那么 NumPy 数组的大小就是 N×2。如你所见,音频有两个声道,左声道和右声道。因此,每个通道存储在一个单独的大小为 N 的数组中,因此我们有 N×2。这就是所谓的立体声音频。在本例中,我们有 2,601,617 个点(样本)。每个点或样本用一对 16 位(2 字节)的整数表示。因此,每个样本需要四个字节。因此,我们可以通过将样本大小乘以 4 来计算存储音频数据所需的总原始内存。当我们可视化音频时,我们显示样本的两个声道的值。让我们将前 2000 个数据点形象化如下:
plt.plot(data[:2000])
plt.show()图 8-8 显示了输出。

图 8-8
音频文件的可视化
您可以按如下方式检查音频样本的数量:
samples = data.shape[0]
print(samples)输出如下所示:
2601617您可以创建不同的数据可视化,如下所示:
plt.plot(data[:10*samplerate])
plt.show()图 8-9 显示了输出。

图 8-9
音频文件的可视化
让我们将两个通道的数据分开,如下所示:
channel1 = data[:, 0]
channel2 = data[:, 1]
print(channel1, channel2)输出如下所示:
[-204 -233 -191 ... 646 679 623] [ 23 32 34 ... 676 707 650]让我们将数据可视化如下:
plt.subplot(2, 1, 1)
plt.plot(channel1[:10*samplerate])
plt.subplot(2, 1, 2)
plt.plot(channel2[:10*samplerate], c='g')
plt.show()图 8-10 显示了输出。

图 8-10
两个音频通道的可视化
音频处理
傅立叶变换将时域中表示为波的数据转换到频域中。因此,当您计算傅里叶变换并将其可视化时,您看到的是频域中的表示。
快速傅立叶变换(FFT)是计算波形数据的傅立叶变换的有效方法。FFT 减少了计算量,这就是它速度快的原因;这就是为什么它被称为快速傅立叶变换。让我们计算音频信号的快速傅立叶变换,如下所示:
import scipy.fftpack
datafft = scipy.fftpack.fft(data)
fftabs = abs(datafft)
print(fftabs)输出如下所示:
[[ 181\. 227.][ 201\. 265.][ 157\. 225.]...[1322\. 30.][1386\. 28.][1273\. 27.]]让我们计算频率并绘制图表如下:
freqs = scipy.fftpack.fftfreq( samples, 1/samplerate )
plt.plot(freqs, fftabs)
plt.show()图 8-11 显示了输出。

图 8-11
FFT 可视化
摘要
在本章中,您学习了如何为图像和音频创建可视化效果。
在下一章,你将学习如何可视化饼图和极坐标图。
九、饼图和极坐标图
在前一章中,您学习了如何使用 Matplotlib 和 SciPy 可视化和处理图像和音频。
在本章中,你将学习如何用 Matplotlib 创建饼图和极坐标图。
饼图
让我们先学习饼图的基础知识。顾名思义,饼图是一个根据数据放射状划分的圆。想象一个苹果派或者一个切成片的比萨饼。饼状图很符合这种描述;然而,与通常对称划分的比萨饼或馅饼不同,饼图不一定是径向对称的。这完全取决于要可视化的数据。
让我们开始吧。我建议为这个练习创建一个新的笔记本。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np让我们创建要可视化的数据,如下所示:
data = np.array([35, 25, 25, 15])让我们用一个简单的饼图来直观显示数据,如下所示:
plt.pie(data)
plt.show()图 9-1 显示了输出。

图 9-1
简单的饼图
让我们添加如下标签:
mylabels = ['A', 'B', 'C', 'D']
plt.pie(data,labels = mylabels)
plt.show()图 9-2 显示了输出。

图 9-2
带标签的简单饼图
您甚至可以将饼图的各个部分分开一点,如下所示:
explode = [0.0, 0.05, 0.1, 0.15]
plt.pie(data,labels = mylabels,explode = explode)
plt.show()输出将按照explode参数中的值将饼图的各个部分分开。图 9-3 显示输出。

图 9-3
带有标签和展开图的简单饼图
您也可以启用阴影,如下所示:
plt.pie(data,labels = mylabels,explode = explode,shadow = True)
plt.show()图 9-4 显示了输出。

图 9-4
带阴影的简单饼图
您还可以向输出中添加图例,如下所示:
plt.pie(data,labels = mylabels,explode = explode,shadow = True)
plt.legend()
plt.show()图 9-5 显示了输出。

图 9-5
带有图例的简单饼图
您可以为图例添加标题,如下所示:
plt.pie(data,labels = mylabels,explode = explode,shadow = True)
plt.legend(title='Data :')
plt.show()图 9-6 显示了输出。

图 9-6
带有图例和图例标题的简单饼图
您刚刚学习了如何创建极坐标图。
极坐标图
您还可以创建饼图形状的极坐标图。然而,与笛卡尔(X-Y)坐标系的一个根本区别是,在极坐标图中,坐标系是径向排列的,因此您需要从原点的角度(θ)和距离( r 是半径)来可视化一个点或一组点。让我们创建一个数据集,如下所示:
N = 20
theta = np.linspace(0.0, 2 * np.pi, N)
r = 10 * np.random.rand(N)这组点可以被可视化如下:
plt.subplot(projection='polar')
plt.bar(theta, r, bottom=0.0,color=['r', 'g', 'b'], alpha=0.2)
plt.show()图 9-7 显示了输出。

图 9-7
简单的极坐标图
你可以看到这创建了一个可视化的条形图,如图 9-7 所示。YouTube 上有一些有用的视频教程,您可以从中了解更多关于在极坐标系统中创建可视化效果的信息。
https://www.youtube.com/watch?v=mDT_DG_A0JA
https://www.youtube.com/watch?v=GMcRqtm4mNo
https://www.youtube.com/watch?v=VmQ1isayjJI让我们创建一个简单的图表。让我们为它创建数据集,如下所示:
r = np.arange(0, 5, 0.2)
theta = 2 * np.pi * r
plt.subplot(projection='polar')
plt.plot(theta, r)
plt.show()这在极坐标图上创建了简单的线性可视化。由于这是一个极坐标图,你会看到一个螺旋状的结构,如图 9-8 所示。

图 9-8
极图上的简单线性可视化
这不是一个完美的螺旋,因为连续点之间的距离是 0.2。如果你减少距离,那么你会得到一个完美的螺旋。让我们将数据调整如下:
r = np.arange(0, 5, 0.01)
theta = 2 * np.pi * r
plt.subplot(projection='polar')
plt.plot(theta, r)
plt.show()这就形成了一个完美的螺旋,如图 9-9 所示。

图 9-9
螺旋形视觉效果
让我们来看几个极坐标图上的散点图示例。首先,准备如下所示的数据:
N = 150
r = np.random.rand(N)
theta = 2 * np.pi * np.random.rand(N)
size = r * 100您可以这样想象:
plt.subplot(projection='polar')
plt.scatter(theta, r, c=theta,s=size, cmap='hsv',alpha=0.5)
plt.show()图 9-10 显示了输出。

图 9-10
散点图
您也可以通过设置开始和结束角度来显示可视化的一部分,如下所示:
fig = plt.figure()
ax = fig.add_subplot(projection='polar')
c = ax.scatter(theta, r, c=theta,s=size, cmap='hsv',alpha=0.5)
ax.set_thetamin(0)
ax.set_thetamax(90)
plt.show()输出仅显示整个极线图的一部分,如图 9-11 所示。

图 9-11
局部散点图
作为练习,您可能想要创建部分螺旋和条形图。
摘要
在这一章中,详细学习了如何创建饼图和极坐标图。
在下一章中,你将学习如何创建更多的可视化,即使用例程pColor()、pColormesh()和colorbar()。
十、使用颜色
在前一章中,你学习了如何用 Matplotlib 可视化饼图和极坐标图。
在这一章中,你将学习如何使用颜色。以下是您将在本章中学习使用的例程:
-
pcolor() -
pcolormesh() -
colorbar()
读完这一章,我们将能够在 Matplotlib 中使用颜色。
pcolor()
例程pcolor()创建一个带有矩形(非正方形)网格的伪彩色图。伪彩色是指物体或图像呈现的颜色不同于记录时的颜色。让我们为本章创建一个新笔记本,如下所示:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np让我们创建一个非正方形矩阵,并使用例程pcolor()将其可视化,如下所示:
data = np.random.rand(5, 6)
plt.pcolor(data)
plt.show()图 10-1 显示了输出。

图 10-1
pcolor()的简单演示
您也可以使用自定义颜色映射,如下所示:
plt.pcolor(data, cmap='YlGnBu_r')
plt.show()图 10-2 显示了输出。

图 10-2
一个简单的 pcolor()演示,带有彩色地图
让我们现在尝试添加阴影。让我们创建一个新的数据集,如下所示:
N = 100
X, Y = np.meshgrid(np.linspace(-5, 5, N),np.linspace(-4, 4, N))
Z = (X**2 + Y**2)您可以将其形象化如下:
plt.pcolor(X, Y, Z,cmap='YlGnBu_r',shading='auto')
plt.show()图 10-3 显示了输出。

图 10-3
明暗法
您也可以使用nearest作为着色方法来创建可视化。在这种阴影技术中,每个网格点都有一种居中的颜色,它在相邻网格中心之间延伸。在这种阴影技术中,每个网格点都有一种居中的颜色,它在相邻网格中心之间延伸。示例如下:
plt.pcolor(X, Y, Z,cmap='YlGnBu_r',shading='nearest')
plt.show()图 10-4 显示了输出。

图 10-4
最近阴影
pcolormesh()
例程polormesh()的行为方式与pcolor()相同;但是,它可以更快地渲染大型数据集。让我们创建一个用于图 10-4 的相同数据集的可视化,但是使用了polormesh()。代码如下:
plt.pcolormesh(X, Y, Z,cmap='YlGnBu_r',shading='auto')
plt.show()让我们看一个带有阴影和颜色贴图的示例,如下所示:
nrows = ncols = 5
x = np.arange(ncols + 1)
y = np.arange(nrows + 1)
z = np.arange(nrows * ncols).reshape(nrows, ncols)
plt.pcolormesh(x, y, z,shading='flat',cmap='coolwarm')
plt.show()图 10-5 显示了输出。

图 10-5
将 pcolormesh()与阴影和颜色贴图一起使用
使用不同的参数运行以下示例:
plt.pcolormesh(x, y, z,shading='auto',cmap='cool')
plt.show()您还可以对数据集应用简单的几何变换,如下所示:
z = np.random.rand(6, 10)
x = np.arange(0, 10, 1)
y = np.arange(4, 10, 1)
T = 0.5
X, Y = np.meshgrid(x, y)
X = X + T * Y
Y = Y + T * X
plt.pcolormesh(X, Y, Z,shading='auto')
plt.show()图 10-6 显示了输出。

图 10-6
使用 polormesh()进行简单的转换
colorbar()
您还可以添加与可视化中数据点的数量相关的颜色条。例行程序colorbar()起了作用。以下是代码:
N = 100
X, Y = np.meshgrid(np.linspace(-5, 5, N),np.linspace(-5, 5, N))
Z = (X**2 + Y**2)
img = plt.imshow(Z, cmap='YlGnBu_r')
plt.colorbar(img)
plt.show()图 10-7 显示了输出。

图 10-7
简单颜色条
您可以缩小颜色栏并按如下方式更改其位置:
img = plt.imshow(Z, cmap='coolwarm')
plt.colorbar(img, location='left', shrink=0.6)
plt.show()图 10-8 显示了输出。

图 10-8
收缩的颜色条
您也可以按如下方式扩展颜色栏:
img = plt.imshow(Z, cmap='coolwarm')
plt.colorbar(img, extend='both')
plt.show()图 10-9 显示了输出。

图 10-9
扩展颜色条
摘要
在本章中,您学习了如何使用颜色。在下一章,你将学习如何创建三维可视化。
十一、Matplotlib 中的 3D 可视化
在前一章中,你学习了如何在 Matplotlib 中使用颜色。
在本章中,您将学习如何使用 3D 可视化效果。以下是您将在本章中了解的主题:
-
绘制 3D 线、散点图和等高线
-
使用线框、曲面和样本数据
-
绘制条形图
-
绘制颤图和茎图
-
使用 3D 体积
线框、表面和 3D 轮廓用于显示体积数据。条形图用于显示分类数据。颤动图用于可视化矢量。阅读完本章后,你将能够在 Matplotlib 中使用所有这些 3D 可视化。
做好准备
我建议您为本章中的所有示例创建一个新笔记本。要做好准备,您需要安装一个额外的库,如下所示:
!pip3 install PyQt5Qt 是一个跨平台的 GUI 库。PyQt5 是 Qt 的 Python 绑定。一旦安装了库,您可以使用以下神奇的命令来强制 Jupyter Notebook 在单独的 QT 窗口中显示可视化效果:
%matplotlib qt因此,当你创建可视化时,你也能够与它们互动。让我们学习基础知识。首先,我们导入所有需要的库,如下所示:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits import mplot3d然后我们创建一个图形对象,如下所示:
fig = plt.figure()然后我们创建一个 3D 轴,如下所示:
ax = plt.axes(projection='3d')在此之后,您必须添加可视化代码。但是,对于此示例,您将使用以下行为空图形和轴创建可视化:
plt.show()图 11-1 显示了输出。

图 11-1
一个空的交互式三维可视化
您可以使用鼠标与该可视化交互并更改其方向。在继续之前,花时间探索所有的交互可能性。
绘制 3D 线
让我们画一条 3D 线。让我们创建一个图形和轴,如下所示:
fig = plt.figure()
ax = plt.axes(projection='3d')让我们按如下方式创建 3D 数据:
z = np.linspace(0, 30, 1000)
x = np.sin(z)
y = np.cos(z)您可以按如下方式创建 3D 图:
ax.plot3D(x, y, z, 'red')
plt.show()图 11-2 显示了输出。

图 11-2
三维线性图
三维散点图
您可以创建随机点并用 3D 散点图显示它们,如下所示。让我们先创建一个图形和轴,如下所示:
fig = plt.figure()
ax = plt.axes(projection='3d')您可以按如下方式创建随机数据点:
y = np.random.random(100)
x = np.random.random(100)
z = np.random.random(100)这些点可以用散点图可视化,如下所示:
ax.scatter3D(x, y, z, cmap='cool');
plt.show()图 11-3 显示了输出。

图 11-3
三维散点图
三维轮廓
您可以使用功能contour()和contour3D()创建 3D 轮廓。让我们创建一些可视化的数据。
x = np.linspace(-10, 10, 30)
y = np.linspace(-10, 10, 30)
X, Y = np.meshgrid(x, y)
Z = np.sin(np.sqrt(X ** 2 + Y ** 2))您可以按如下方式创建轮廓:
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
ax.contour(X, Y, Z, 50, cmap='coolwarm')
plt.show()图 11-4 显示了输出。

图 11-4
3D 等高线图
您可以使用以下代码获得类似的输出,如图 11-4 所示:
fig = plt.figure()
ax = plt.axes(projection='3d')
ax.contour3D(X, Y, Z, 40,cmap='coolwarm')
plt.show()您也可以使用功能contourf()创建填充轮廓,如下所示:
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
ax.contourf(X, Y, Z, 50, cmap='coolwarm')
plt.show()线框、曲面和样本数据
您可以绘制同一数据集的线框,如下所示:
fig = plt.figure()
ax = plt.axes(projection='3d')
ax.plot_wireframe(X, Y, Z, color='Green')
ax.set_title('wireframe')
plt.show()图 11-5 显示了输出。

图 11-5
3D 线框
相同的数据可以可视化为 3D 表面,如下所示:
fig = plt.figure()
ax = plt.axes(projection='3d')
ax.plot_surface(X, Y, Z, color='Blue')
ax.set_title('Surface Plot')
plt.show()图 11-6 显示了输出。

图 11-6
三维表面
您还可以使用 Matplotlib 库附带的示例数据来演示可视化效果。函数get_test_data()可以如下获取采样数据:
from mpl_toolkits.mplot3d import axes3d
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
X, Y, Z = axes3d.get_test_data(0.02)
ax.plot_wireframe(X, Y, Z,rstride=10,cstride=10)
plt.show()图 11-7 显示了输出。

图 11-7
可视化测试数据
作为练习,尝试使用测试数据创建一个表面和轮廓。
条形图
您可以在三维轴中显示 2D 条形图。让我们创建一个图形和轴,如下所示:
fig = plt.figure()
ax = fig.add_subplot(projection='3d')让我们定义条形的颜色。
colors = ['r', 'g', 'b', 'c', 'm', 'y','k']
yticks = [0, 1, 2, 3, 4, 5, 6]现在,让我们通过以下循环使用定义的颜色创建条形图:
for c, k in zip(colors, yticks):x = np.arange(25)y = np.random.rand(25)ax.bar(x, y, zs=k, zdir='y',color=c, alpha=0.8)
plt.show()图 11-8 显示了输出。

图 11-8
在 3D 坐标中可视化 2D 条形图
你也可以用 Matplotlib 创建一个 3D 条形图。让我们首先创建数据,如下所示:
fig = plt.figure()
ax = fig.add_subplot(projection='3d')x = np.arange(10) * np.arange(10)
y = np.arange(10) * np.arange(10)
x, y = np.meshgrid(x, y)
x, y = x.ravel(), y.ravel()
top = x + y
bottom = np.zeros_like(top)
width = depth = 5然后,您可以将它显示为三维条形图,如下所示:
ax.bar3d(x, y, bottom, width,depth, top,shade=True,color='g')
plt.show()图 11-9 显示了输出。

图 11-9
可视化三维条形图
颤图和茎图
颤动图用于表示方向实体(例如,向量)。让我们定义数据,如下所示:
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
x = y = z = np.arange(-0.1, 1, 0.2)
X, Y, Z = np.meshgrid(x, y, z)
u = np.cos(np.pi * X) * np.sin(np.pi * Y) * np.sin(np.pi * Z)
v = -np.sin(np.pi * X) * np.cos(np.pi * Y) * np.sin(np.pi * Z)
w = np.sin(np.pi * X) * np.sin(np.pi * Y) * np.cos(np.pi * Z)最后,您可以将数据可视化,如下所示:
ax.quiver(X, Y, Z, u, v, w,length=0.1,normalize=True)
plt.show()图 11-10 显示了输出。

图 11-10
颤动图
您也可以在可视化中绘制垂直线的位置创建 stem 图。让我们使用三角函数来定义数据,如下所示:
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
theta = np.linspace(0, 2 * np.pi)
x = np.sin(theta)
y = np.cos(theta)
z = np.cos(theta)您可以将 stem 图可视化如下:
ax.stem(x, y, z)
plt.show()图 11-11 显示了输出。

图 11-11
茎图
3D 体积
可以将 3D 体积数据显示为封闭的曲面。让我们创建如下数据:
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
u = np.linspace(0, 2 * np.pi, 100)
v = np.linspace(0, np.pi, 100)
x = 10 * np.outer(np.cos(u), np.sin(v))
y = 10 * np.outer(np.sin(u), np.sin(v))
z = 10 * np.outer(np.ones(np.size(u)), np.cos(v))您可以将此数据显示为球体,如下所示:
ax.plot_surface(x, y, z)
plt.show()图 11-12 显示了输出。

图 11-12
作为体积的曲面图
您也可以使用功能voxels()来可视化体积,如下所示:
ma = np.random.randint(1, 3, size=(3, 3, 3))
fig = plt.figure()
ax = plt.axes(projection='3d')
ax.voxels(ma, edgecolor='k')
plt.show()图 11-13 显示了输出。

图 11-13
三维体积图
摘要
在本章中,您学习了如何使用 3D 可视化效果。线框、表面和 3D 轮廓用于显示体积数据。条形图用于显示分类数据。颤动图用于可视化矢量。
在下一章,你将学习如何创建动画。
十二、Matplotlib 动画
在前一章中,您学习了如何在 Matplotlib 中使用 3D 可视化。
在这一章中,你将学习如何使用动画。以下是您将在本章中学习的主题:
-
动画基础
-
赛璐珞图书馆
读完这一章,你将能够在 Matplotlib 和另一个有用的库中使用动画。
动画基础
在本节中,您将学习如何使用 Matplotlib 创建动画。首先,让我们为本章创建一个新笔记本。然后导入以下库:
%matplotlib qt
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.animation import FuncAnimation让我们定义对象,换句话说,图形、轴和绘图,如下所示:
fig = plt.figure()
ax = plt.axes(xlim=(0, 4), ylim=(-2, 2))
line, = ax.plot([], [], lw=3)让我们定义函数init(),它将初始化动画并为动画设置数据,如下所示:
def init():line.set_data([], [])return line,让我们定义一个动画函数,如下所示:
def animate(i):x = np.linspace(0, 4, 1000)y = np.sin(2 * np.pi * (x - 0.01 * i))line.set_data(x, y)return line,该函数接受帧数作为参数(在本例中是名为i的变量),并为动画渲染帧。
现在我们已经定义了组件,让我们使用函数调用FuncAnimation()创建一个动画对象。它接受创建的函数作为参数。它还接受帧数和间隔作为参数。参数blit的自变量是True。这意味着只重画已经改变的部分。
anim = FuncAnimation(fig, animate,init_func=init,frames=1000,interval=10,blit=True)您也可以将动画保存为 GIF 格式,如下所示:
anim.save('sine_wave.gif', writer='pillow')图 12-1 显示了输出。

图 12-1
将正弦波可视化
您可以与动画互动,并用鼠标更改方向。在继续下一步之前,探索所有的交互可能性。
您可以创建渐进式螺旋,如下所示:
fig = plt.figure()
ax = plt.axes(xlim=(-50, 50), ylim=(-50, 50))
line, = ax.plot([], [], lw=2)
def init():line.set_data([], [])return line,
xdata, ydata = [], []
def animate(i):t = 0.2*ix = t*np.cos(t)y = t*np.sin(t)xdata.append(x)ydata.append(y)line.set_data(xdata, ydata)return line,
anim = FuncAnimation(fig, animate,init_func=init,frames=3000,interval=5,blit=True)图 12-2 显示了输出。

图 12-2
可视化螺旋动画
赛璐珞图书馆
你可以使用另一个简单的叫做赛璐珞的库来制作动画。让我们按如下方式安装它:
!pip3 install celluloid您可以按如下方式导入它:
from celluloid import Camera让我们创建一个人物和照相机对象,如下所示:
fig = plt.figure()
camera = Camera(fig)让我们创建一个动画的帧,并用名为camera.snap()的函数将它们保存在内存中,如下所示:
for i in range(10):plt.plot([i] * 10)camera.snap()让我们创建如下动画:
animation = camera.animate()图 12-3 显示了输出。

图 12-3
使用赛璐珞库的动画
您也可以创建正弦波,如下所示:
fig, axes = plt.subplots()
camera = Camera(fig)
t = np.linspace(0, 2 * np.pi, 128, endpoint=False)
for i in t:plt.plot(t, np.sin(t + i), color='green')camera.snap()
animation = camera.animate()图 12-4 显示了输出。

图 12-4
用赛璐珞库制作正弦波动画
条形图的另一个示例如下:
fig, axes = plt.subplots()
camera = Camera(fig)
y = np.arange(5)
for i in y:plt.bar( np.random.rand(5)*10 , y)camera.snap()
animation = camera.animate()图 12-5 显示了输出。

图 12-5
带赛璐珞库的条形图动画
摘要
在本章中,您学习了如何使用动画。
在下一章,你将学习如何用 Matplotlib 做更多的事情。
十三、使用 Matplotlib 实现更多可视化
在上一章中,您学习了如何在 Matplotlib 中处理动画。
在这一章中,你将学习更多使用 Matplotlib 的技巧。这一章是你到目前为止所获得的所有知识的顶点。这一章有一系列使用 Matplotlib 的技巧,我在前面的章节中没有提到。具体来说,以下是您将在本章中学习的主题:
-
将功能可视化为图像和轮廓
-
使用 3D 晕影
-
装饰散点图
-
使用时间图和信号
-
使用填充图、阶跃图和六边形图
-
使用 XKCD 样式
阅读完本章后,你将能够在 Matplotlib 中创建各种新的可视化。
将功能可视化为图像和轮廓
让我们想象一个数字函数。导入所有需要的库,如下所示:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt让我们将函数定义如下:
def f(x, y):return (x ** 3 + y ** 2)让我们将其形象化,如下所示:
n = 10
x = np.linspace(-3, 3, 8 * n)
y = np.linspace(-3, 3, 6 * n)
X, Y = np.meshgrid(x, y)
Z = f( X, Y )
plt.imshow(Z, interpolation='nearest',cmap = 'cool', origin='lower')
plt.axis('off')
plt.show()图 13-1 显示了输出。

图 13-1
将功能可视化为图像
你也可以把这个函数想象成一个轮廓。
n = 256
x = np.linspace(-3, 3, n)
y = np.linspace(-3, 3, n)
X, Y = np.meshgrid(x, y)
plt.contourf(X, Y, f(X, Y), 8,alpha = 0.75, cmap='hot')
C = plt.contour(X, Y, f(X, Y), 8,colors='black')
plt.clabel(C, inline=1, fontsize=10)
plt.axis('off')
plt.show()图 13-2 显示了输出。

图 13-2
将函数可视化为轮廓
3D 缩图
您可以按如下方式创建三维晕影可视化:
%matplotlib qt
fig = plt.figure()
ax = plt.axes(projection='3d')
X = np.arange(-4, 4, 0.25)
Y = np.arange(-4, 4, 0.25)
X, Y = np.meshgrid(X, Y)
R = np.sqrt(X ** 2 + Y ** 2)
Z = np.sin(R)
ax.plot_surface(X, Y, Z, rstride=1,cstride=1, cmap='hot')
ax.contourf(X, Y, Z, zdir='z',offset=-2, cmap='hot')
ax.set_zlim(-2, 2)
plt.axis('off')
ax.set_zticks(())
plt.show()图 13-3 显示了输出。

图 13-3
可视化 3D 晕影
装饰散点图
您可以使用 Matplotlib 创建装饰散点图。您需要将颜色和大小作为参数传递。这里有一个例子:
%matplotlib inline
n = 1024
X = np.random.normal(0, 1, n)
Y = np.random.normal(0, 1, n)
color = np.arctan2(Y, X)
plt.scatter(X, Y, s=75, c=color, alpha=0.5)
plt.xlim(-1.5, 1.5)
plt.ylim(-1.5, 1.5)
plt.axis('off')
plt.show()图 13-4 显示了输出。

图 13-4
可视化装饰散点图
时间图和信号
您可以将时间图和信号可视化如下:
N = 100
x = np.arange(N) # timestamps
y1 = np.random.randn(N)
y2 = np.random.randn(N)
y3 = np.random.randn(N)
y4 = np.random.randn(N)plt.subplot(2, 1, 1)
plt.plot(x, y1)
plt.plot(x, y2, ':')
plt.grid()
plt.xlabel('Time')
plt.ylabel('y1 and y2')
plt.axis('tight')
plt.subplot(2, 1, 2)
plt.plot(x, y3)
plt.plot(x, y4, 'r')
plt.grid()
plt.xlabel('Time')
plt.ylabel('y3 and y4')
plt.axis('tight')
plt.show()图 13-5 显示了输出。

图 13-5
可视化时间图和信号
也可以将两个信号相乘。在下面的代码示例中,我们使用同一个 x 轴来显示所有三个图表。
f = 1
t = np.arange( 0.0, 4.0, 0.01)
s1 = np.sin(2 *np.pi * f * t)
s2 = np.exp(-t)
s3 = s1 * s2
f = plt.figure()
plt.subplots_adjust(hspace=0.001)
ax1 = plt.subplot( 311 )
ax1.plot(t, s1)
plt.yticks(np.arange(-0.9, 1.0, 0.4))
plt.ylim(-1, 1)
ax2 = plt.subplot(312, sharex=ax1)
ax2.plot(t, s2)
plt.yticks(np.arange(0.1, 1.0, 0.2))
plt.ylim(0, 1)
ax3 = plt.subplot(313, sharex = ax1)
ax3.plot(t, s3)
plt.yticks(np.arange(-0.9, 1.0, 0.4))
plt.ylim(-1, 1)
xticklabels = ax1.get_xticklabels() + ax2.get_xticklabels()
plt.setp(xticklabels, visible=False)
plt.show()图 13-6 显示了输出。

图 13-6
乘法信号
填充图
您可以按如下方式填充地块边界内的空白空间:
N = 1000
x = np.linspace(0, 1, N)
y = np.sin(4 * np.pi * x) + np.exp(-5 * x)
plt.fill(x, y, 'g', alpha = 0.8)
plt.grid(True)
plt.show()图 13-7 显示了输出。

图 13-7
填充图
阶梯图
我们先来可视化一些正弦波。
N = 100
x = np.linspace(-np.pi, np.pi, N)
y1 = 0.5 * np.sin(3*x)
y2 = 1.25 * np.sin(2*x)
y3 = 2 * np.sin(4*x)
plt.plot(x, y1, x, y2, x, y3)
plt.show()图 13-8 显示了输出。

图 13-8
正弦曲线
您可以将它们显示为阶跃图,如下所示:
plt.step(x, y1)
plt.step(x, y2)
plt.step(x, y3)
plt.show()图 13-9 显示了输出。

图 13-9
带阶梯图的正弦曲线
赫克宾斯
您可以将数据显示为六边形,如下所示:
x, y = np.random.normal(size=(2, 10000))
plt.hexbin(x, y,gridsize=20,cmap='cool')
plt.colorbar()
plt.show()图 13-10 显示了输出。

图 13-10
Hexbin 可视化
xcd 风格
您可以在 XKCD 样式中可视化地块。XKCD 是一部流行的网络漫画。 https://xkcd.com 是网络漫画的主页。
y = np.random.randn(1000)
plt.xkcd()
plt.hist(y)
plt.show()图 13-11 显示了输出。

图 13-11
XKCD 直方图
另一个例子如下:
y = np.random.randn(1000)
plt.xkcd()
plt.hist(y, bins = 30,range=[-3.5, 3.5],facecolor='r',alpha=0.6,edgecolor='k')
plt.grid()
plt.show()图 13-12 显示了输出。

图 13-12
另一个 XKCD 直方图
您也可以用同样的方式显示 2D 直方图,如下所示:
data = np.random.randn(1000, 1000)
plt.xkcd()
plt.hist2d(data[0], data[1])
plt.show()图 13-13 显示了输出。

图 13-13
第三个 XKCD 直方图
摘要
在本章中,您学习了如何使用 Matplotlib 处理一些额外的可视化技术。
在下一章中,你将熟悉一个名为 Pandas 的数据科学库。
十四、Pandas 简介
在前一章中,您学习了许多 Matplotlib 技术。现在,您将学习如何使用数据科学和数据可视化中常见的另一个库。
在这一章中,我们将关注科学 Python 生态系统中主要数据科学和分析库的基础知识:Pandas。您将了解这个库中的数据结构。以下是本章中的主题:
-
Pandas 简介
-
Pandas 系列
-
Pandas 的数据帧
读完这一章后,你会很舒服地用 Pandas 做基本的任务。
Pandas 简介
Pandas 是科学 Python 生态系统中的数据分析组件。事实上,它是科学 Python 生态系统不可或缺的一部分。它带有多用途的数据结构和管理它们的例程。它带有多用途的数据结构和管理这些数据结构的例程。
让我们通过在 Jupyter 笔记本中运行以下命令在计算机上安装 Pandas:
!pip3 install pandas您可以通过运行以下命令将其导入到当前会话中:
import pandas as pd你可以在 https://pandas.pydata.org/ 了解更多关于 Pandas 的信息。
Pandas 系列
系列是带有标签的一维数组。它可以保存任何类型的数据。这些标签统称为索引。
您可以按如下方式创建系列:
s1 = pd.Series([3, 2, 1 , 75, -3.14])您可以按如下方式检查其数据类型:
type(s1)以下是输出:
<class 'pandas.core.series.Series'>您可以看到与数据相关联的值和索引,如下所示:
print(s1)以下是输出:
0 3.00
1 2.00
2 1.00
3 75.00
4 -3.14
dtype: float64您可以明确地提及数据类型,如下所示:
s2 = pd.Series([3, 2, 1 , 75, -3.14], dtype=np.float32)
print(s2)您可以将列表作为参数传递给构造函数来创建序列,如下所示:
x = [3, 2, 1 , 75, -3.14]
s3 = pd.Series(x)您甚至可以将 NumPy Ndarray 作为参数传递给构造函数来创建序列,如下所示:
import numpy as np
y = np.array(x)
s4 = pd.Series(y)您可以看到如下值:
print(s4.values)以下是输出:
[ 3\. 2\. 1\. 75\. -3.14]您可以按如下方式检索索引:
print(s4.index)输出如下所示:
RangeIndex(start=0, stop=5, step=1)您可以按如下方式分配自定义索引:
s5 = pd.Series( x, index = ['a', 'b', 'c', 'd', 'e'])
print(s5)输出如下所示:
a 3.00
b 2.00
c 1.00
d 75.00
e -3.14
dtype: float64系列的基本操作
您可以对系列图像执行一些基本操作。例如,您可以按如下方式显示负数:
print(s5[s5 < 0])输出如下所示:
e -3.14
dtype: float64您可以按如下方式检索正数:
print(s5[s5 > 0])输出如下所示:
a 3.0
b 2.0
c 1.0
d 75.0
dtype: float64这些是比较操作的例子。您可以执行算术运算,例如乘法,如下所示:
c = 3
print ( s5 * c )输出如下所示:
a 9.00
b 6.00
c 3.00
d 225.00
e -9.42
dtype: float64Pandas 的数据帧
数据帧是一种二维的带标签的数据结构,其列可以是不同的数据类型。您可以从系列、数据阵列、列表和字典创建数据框架。
数据帧有标签,统称为索引。您可以轻松查看和操作数据框中的数据。数据以矩形网格格式存储在数据帧中。
您可以从列表中创建数据帧,如下所示。以下是字典:
data = {'city': ['Delhi', 'Delhi', 'Delhi','Bangalore', 'Bangalore', 'Bangalore'],'year': [2020, 2021, 2022, 2020, 2021, 2022,],'population': [10.0, 10.1, 10.2, 5.2, 5.3, 5.5]}让我们由此创建一个数据帧,如下所示:
df1 = pd.DataFrame(data)
print(df1)输出如下所示:
city year population
0 Delhi 2020 10.0
1 Delhi 2021 10.1
2 Delhi 2022 10.2
3 Bangalore 2020 5.2
4 Bangalore 2021 5.3
5 Bangalore 2022 5.5您可以看到前五条记录如下:
df1.head()输出如下所示:
city year population
0 Delhi 2020 10.0
1 Delhi 2021 10.1
2 Delhi 2022 10.2
3 Bangalore 2020 5.2
4 Bangalore 2021 5.3您还可以将其他数字作为参数传递给函数head(),它将显示数据帧中的许多顶级记录。同样,您可以使用df1.tail()来查看最后的记录。它还将 5 作为默认参数,但是您可以自定义传递给它的参数。
您可以创建具有特定列顺序的数据帧,如下所示:
df2 = pd.DataFrame(data, columns=['year', 'city', 'population'])
print(df2)输出如下所示:
year city population
0 2020 Delhi 10.0
1 2021 Delhi 10.1
2 2022 Delhi 10.2
3 2020 Bangalore 5.2
4 2021 Bangalore 5.3
5 2022 Bangalore 5.5让我们创建一个带有附加列和自定义索引的数据帧,如下所示:
df3 = pd.DataFrame(data, columns=['year', 'city', 'population', 'GDP'],index = ['one', 'two', 'three', 'four', 'five', 'six'])
print(df3)以下是新的数据框架:
year city population GDP
one 2020 Delhi 10.0 NaN
two 2021 Delhi 10.1 NaN
three 2022 Delhi 10.2 NaN
four 2020 Bangalore 5.2 NaN
five 2021 Bangalore 5.3 NaN
six 2022 Bangalore 5.5 NaN您可以按如下方式打印列列表:
print(df3.columns)输出如下所示:
Index(['year', 'city', 'population', 'GDP'], dtype='object')您可以按如下方式打印索引列表:
print(df3.index)输出如下所示:
Index(['one', 'two', 'three', 'four', 'five', 'six'], dtype='object')您可以使用以下语句查看列的数据:
print(df3.year)或者也可以使用下面的语句:
print(df3['year'])以下是输出:
one 2020
two 2021
three 2022
four 2020
five 2021
six 2022
Name: year, dtype: int64您可以使用以下语句查看列的数据类型:
print(df3['year'].dtype)或者,您可以使用以下方法:
print(df3.year.dtype)输出如下所示:
int64您可以看到所有列的数据类型如下:
print(df3.dtypes)输出如下所示:
year int64
city object
population float64
GDP object
dtype: object您可以使用索引检索任何记录,如下所示:
df3.loc['one']输出如下所示:
year 2020
city Delhi
population 10.0
GDP NaN
Name: one, dtype: object您可以为列的所有成员分配相同的值,如下所示:
df3.GDP = 10
print(df3)输出如下所示:
year city population GDP
one 2020 Delhi 10.0 10
two 2021 Delhi 10.1 10
three 2022 Delhi 10.2 10
four 2020 Bangalore 5.2 10
five 2021 Bangalore 5.3 10
six 2022 Bangalore 5.5 10您可以为列GDP分配一个 Ndarray,如下所示:
import numpy as np
df3.GDP = np.arange(6)
print(df3)输出如下所示:
year city population GDP
one 2020 Delhi 10.0 0
two 2021 Delhi 10.1 1
three 2022 Delhi 10.2 2
four 2020 Bangalore 5.2 3
five 2021 Bangalore 5.3 4
six 2022 Bangalore 5.5 5您还可以为其分配一个列表,如下所示:
df3.GDP = [3, 2, 0, 9, -0.4, 7]
print(df3)输出如下所示:
year city population GDP
one 2020 Delhi 10.0 3.0
two 2021 Delhi 10.1 2.0
three 2022 Delhi 10.2 0.0
four 2020 Bangalore 5.2 9.0
five 2021 Bangalore 5.3 -0.4
six 2022 Bangalore 5.5 7.0让我们给它分配一个系列,如下所示:
val = pd.Series([-1.4, 1.5, -1.3], index=['two', 'four', 'five'])
df3.GDP = val
print(df3)输出如下所示:
year city population GDP
one 2020 Delhi 10.0 NaN
two 2021 Delhi 10.1 -1.4
three 2022 Delhi 10.2 NaN
four 2020 Bangalore 5.2 1.5
five 2021 Bangalore 5.3 -1.3
six 2022 Bangalore 5.5 NaN摘要
在这一章中,你探索了科学 Python 生态系统的 Pandas 数据科学库的基础。您学习了创建和使用基本的 Pandas 数据结构的基础知识,它们是 series 和 dataframe。
在下一章中,您将学习如何使用库 NumPy、Pandas 和 Matplotlib 以编程方式读取以各种格式存储的数据。
十五、数据采集
在前一章中,您学习了使用两个 Pandas 数据结构的基础知识,即 series 和 dataframe。
这一章着重于使用你到目前为止学习过的所有库(NumPy、Matplotlib 和 Pandas)用 Python 获取数据。以下是您将在本章中了解的主题:
-
处理纯文本文件
-
用 Python 处理 CSV 文件
-
使用 Python 和 Excel
-
用 NumPy 读写文件
-
用 NumPy 从 CSV 文件中读取数据
-
使用 Matplotlib CBook
-
从 CSV 文件中读取数据
-
从 Excel 文件中读取数据
-
从 JSON 文件中读取数据
-
从 Pickle 文件中读取数据
-
从网上读取数据
-
从关系数据库中读取数据
-
从剪贴板读取数据
读完这一章后,你将可以轻松地从各种文件格式中读取数据并保存它。
纯文本文件处理
让我们学习如何从一个纯文本文件中读取数据,以及将数据写入到一个纯文本文件中。Python 自带读写纯文本文件的功能。我们有四种打开文件的模式,如下所示:
-
w:写 -
r:阅读 -
a:追加 -
r+:读写模式
您可以按如下方式使用它们(一次一个):
f = open('testfile.txt', 'w')
print(f)这段代码以写模式打开testfile.txt文件。如果文件不存在,那么 Python 会在磁盘上的当前位置创建这个文件。如果文件已经存在,它会覆盖文件的内容。前面的代码打印 file 对象,如下所示:
<_io.TextIOWrapper name='testfile.txt' mode='w' encoding='cp1252'>让我们向文件中写入一些数据。在这种情况下,数据由多字符字符串组成。
f.write('This is a test string.\n')
f.write('This is the middle line.\n')
f.write('This is the last line.')您可以按如下方式关闭文件对象(也称为文件句柄):
f.close()您知道再次以写模式打开文件会覆盖其数据。因此,这一次,让我们以追加模式打开同一个文件,如下所示:
f = open('testfile.txt', 'a')
f.write('\nThis is the appended line.')
f.close()我们在文件中写入一行,然后关闭文件。让我们读取数据并将其打印如下:
f = open('testfile.txt', 'r')
print(f.read())
f.close()输出如下所示:
This is a test string.
This is the middle line.
This is the last line.
This is the appended line您可以检索列表中的行(文件中的每一行都对应于列表中的一个元素),如下所示:
f = open('testfile.txt', 'r')
print(f.readlines())
f.close()输出如下所示:
['This is a test string.\n', 'This is the middle line.\n', 'This is the last line.\n', 'This is the appended line.']您也可以按如下方式逐行检索文件中的数据:
f = open('testfile.txt', 'r')
for line in f:print(line)
f.close()输出如下所示:
This is a test string.This is the middle line.This is the last line.This is the appended line.用 Python 处理 CSV 文件
让我们了解一些关于逗号分隔文件(CSV)格式的事情。CSV 文件以纯文本格式存储数据,数据项或者是固定长度,或者由逗号(,)、竖线(|)或冒号(:)等分隔符分隔。最常见的 CSV 格式使用逗号作为分隔符,很多时候第一行用于存储列名。
在本节中,您将学习如何用 Python 3 处理 CSV 文件。Python 3 附带了一个内置库来处理 CSV 文件。您不需要安装任何东西。您可以按如下方式导入库:
import csv您可以在读取模式下以纯文本文件的形式打开该文件,如下所示:
file = open('test.csv', 'r')
print(file)打开文件后,可以将文件句柄传递给例程csv.reader(),如下所示:
csvfile = csv.reader(file, delimiter=',')
print(csvfile)这将打印对象的值,如下所示:
<_csv.reader object at 0x0590AC68>您可以按如下方式逐行检索数据:
for row in csvfile:print(row)这会产生以下输出:
['Banana', 'Yellow', '250']
['Orange', 'Orange', '200']
['Grapes', 'Green', '400']
['Tomato', 'Red', '100']
['Spinach', 'Green', '40']
['Potatoes', 'Gray', '400']
['Rice', 'White', '300']
['Rice', 'Brown', '400']
['Wheat', 'Brown', '500']
['Barley', 'Yellow', '500']您可以单独显示元素,如下所示:
for row in csvfile:for element in row:print(element)输出如下所示:
Banana
Yellow
250
Orange
Orange
200
Grapes
Green
400
Tomato
Red
100
Spinach
Green
40
Potatoes
Gray
400
Rice
White
300
Rice
Brown
400
Wheat
Brown
500
Barley
Yellow
500让我们关闭文件句柄,如下所示:
file.close()Python 和 Excel
让我们看看如何从 Excel 中读取数据。为此你需要一个外部库。以下代码安装我们将在本节中使用的库:
!pip3 install openpyxl您可以按如下方式导入它:
import openpyxl您可以按如下方式打开 Excel 文件:
wb = openpyxl.load_workbook('test.xlsx')
print(wb)
print(type(wb))输出如下所示:
<openpyxl.workbook.workbook.Workbook object at 0x0E87F7D8>
<class 'openpyxl.workbook.workbook.Workbook'>您可以按如下方式检索所有工作表的名称:
print(wb.sheetnames)输出如下所示:
['Sheet1', 'Sheet2', 'Sheet3']您可以按如下方式选择图纸:
currSheet = wb['Sheet1']
print(currSheet)
print(type(currSheet))输出如下所示:
<Worksheet "Sheet1">
<class 'openpyxl.worksheet.worksheet.Worksheet'>同样,下面的代码具有相同的效果:
currSheet = wb[wb.sheetnames[0]]
print(currSheet)
print(type(currSheet))您可以打印当前工作表的名称,如下所示:
print(currSheet.title)输出如下所示:
Sheet1您可以按如下方式打印单元格的值:
var1 = currSheet['A1']
print(var1.value)输出如下所示:
Food Item进行相同活动的另一种方法如下:
print(currSheet['B1'].value)您可以用另一种方式来完成,如下所示:
var2 = currSheet.cell(row=2, column=2)
print(var2.value)行数和列数可以如下获得:
print(currSheet.max_row)
print(currSheet.max_column)输出如下所示:
11
3让我们打印电子表格中的所有数据,如下所示:
for i in range(currSheet.max_row):print('---Beginning of Row---')for j in range(currSheet.max_column):var = currSheet.cell(row=i+1, column=j+1)print(var.value)print('---End of Row---')输出很长,所以我在这里截断了它。请运行代码亲自查看。
用 NumPy 读写文件
让我们看看如何用 NumPy 读写文件。让我们用 NumPy 创建一个数据集,如下所示:
import numpy as np
x = np.arange(100)
print(x)输出如下所示:
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 2324 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 4748 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 7172 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 9596 97 98 99]您可以将其保存到一个文件(NumPy 数据格式),如下所示:
np.save('test.npy', x)您可以将数据从文件加载到变量中,如下所示:
data = np.load('test.npy')
print(data)输出如下所示:
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 2324 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 4748 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 7172 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 9596 97 98 99]用 NumPy 从 CSV 文件中读取数据
CSV 文件也可以用 NumPy 读取,如下所示:
import numpy as np
# Reads only numeric data
data = np.loadtxt('data.csv', delimiter=',')
print(data)输出如下所示:
[[ 0\. 1\. 18\. 2.][ 1\. 6\. 1\. 3.][ 2\. 3\. 154\. 0.][ 4\. 978\. 3\. 6.][ 5\. 2\. 41\. 45.][ 6\. 67\. 2\. 3.][ 7\. 5\. 67\. 2.]]您也可以跳过行和列,如下所示:
data = np.loadtxt('data.csv', delimiter=',',skiprows=3, usecols=[1, 3])
print(data)输出如下所示:
[[978\. 6.][ 2\. 45.][ 67\. 3.][ 5\. 2.]]Matplotlib CBook
您可以读取以 Matplotlib 的 CBook 格式存储的数据。Matplotlib 附带了一些这种格式的示例文件。让我们看看如何读取数据:
import matplotlib.cbook as cbook
datafile = cbook.get_sample_data('aapl.npz')
r = np.load(datafile)
print(r.files)这将打印数据文件的名称,如下所示:
['price_data']让我们从该数据文件中读取数据:
print(r['price_data'])这显示了苹果股价数据如下:
[('1984-09-07', 26.5 , 26.87, 26.25, 26.5 , 2981600, 3.02)('1984-09-10', 26.5 , 26.62, 25.87, 26.37, 2346400, 3.01)('1984-09-11', 26.62, 27.37, 26.62, 26.87, 5444000, 3.07) ...('2008-10-10', 85.7 , 100\. , 85\. , 96.8 , 79260700, 96.8 )('2008-10-13', 104.55, 110.53, 101.02, 110.26, 54967000, 110.26)('2008-10-14', 116.26, 116.4 , 103.14, 104.08, 70749800, 104.08)]从 CSV 读取数据
如前所述,CSV 文件包含用逗号分隔的值。您可以使用 Pandas 中的多功能功能read_csv()来读取网络上或本地/网络磁盘上的 CSV 文件。以下是我们将在本演示中使用的 CSV 文件的内容:
rank,discipline,phd,service,sex,salary
Prof,B,56,49,Male,186960
Prof,A,12,6,Male,93000
Prof,A,23,20,Male,110515
Prof,A,40,31,Male,131205
Prof,B,20,18,Male,104800
Prof,A,20,20,Male,122400
AssocProf,A,20,17,Male,81285第一行是标题行。大多数 CSV 文件都有一个标题行,尽管这不是必需的。如您所见,这些值由逗号分隔。这是 CSV 文件的常见格式。根据系统和应用程序的不同,您可以使用各种分隔符,如空格、分号(;),或者是管道(|)。此外,CSV 文件可以使用固定数量的字符在列中存储数据。在本例中,如前所述,我们使用最常见的 CSV 格式存储数据。
让我们学习如何用 Pandas 从这样的文件中读取数据。为本章创建新笔记本。
按如下方式导入 Pandas 库:
import pandas as pd让我们阅读一个位于 Web 上的 CSV 文件,如下所示:
df1 = pd.read_csv("http://rcs.bu.edu/examples/python/data_analysis/Salaries.csv")
print(df1)您还可以读取存储在本地磁盘上的 CSV,如下所示:
df2 = pd.read_csv("Salaries.csv")
print(df2)您也可以将数据帧的数据转储到磁盘位置的 CSV 文件中,如下所示:
df2.to_csv('output.csv', index=True, header=False)该代码将在磁盘的当前目录下创建一个 CSV 文件。
从 Excel 文件中读取数据
要将 Excel 文件中的数据读入 Pandas dataframe,您需要一个外部包的支持。让我们安装一个包,如下所示:
!pip3 install xlrd现在我们来读取存储在磁盘上的 Excel 文件,如下:
excel_file = 'test.xlsx'
df1 = pd.read_excel(excel_file)在这里(在前面的例子中也是如此),文件存储在与笔记本文件相同的目录中。如果需要读取任何其他位置的文件,必须指定该文件的完整路径。前面的代码在执行时会将 Excel 文件的内容加载到 Pandas 数据帧中。您可以使用下面一行代码来查看内容:
print(df1)图 15-1 显示了输出。

图 15-1
Excel 表格中的数据
从 JSON 读取数据
您可以将 JSON 字符串的数据读入 dataframe,如下所示。首先创建一个 JSON 字符串。
obj = """
{"name": "Ashwin",
"places_lived": ["Nashik", "Hyderabad", "Bangalore"],
"pet": null,
"siblings": [{"name": "Scott", "age": 30, "pets": ["Zeus", "Zuko"]},
{"name": "Katie", "age": 38,
"pets": ["Sixes", "Stache", "Cisco"]}]
}
"""您可以按如下方式打印该字符串:
print(obj)您还可以检查变量的类型(它是 JSON 格式的字符串),如下所示:
print(type(obj))您可以将这个 JSON 格式的字符串转换成字典,如下所示:
import json
result = json.loads(obj)
print(result)让我们检查新创建的变量的数据类型,如下所示:
print(type(result))这将产生以下结果:
<class 'dict'>让我们将数据加载到数据帧中,如下所示:
df1 = pd.DataFrame(result['siblings'], columns=['name', 'age'])
print(df1)输出如下所示:
name age
0 Scott 30
1 Katie 38您还可以从 JSON 文件中读取数据,如下所示:
df2 = pd.read_json('example_2.json')
print(df2)这就是将 JSON 数据读入数据帧的方法。
从 Pickle 文件中读取数据
在 Python 编程中,Pickle 用于序列化和反序列化 Python 对象。您可以将 Pandas 数据帧存储到磁盘上的 Pickle 文件中,如下所示:
data = [1, 2, 3, 4, 5]
df1 = pd.DataFrame(data)
print(df1)
df1.to_pickle('mypickle')您可以从存储在磁盘上的 Pickle 文件中读取数据,如下所示:
df2 = pd.read_pickle('mypickle')
print(df2)从网上读取数据
让我们从网上读取数据。为此,您将需要几个库。您可以按如下方式安装它们:
!pip3 install lxml html5lib BeautifulSoup4您可以阅读位于 Web 上的 HTML 文件,如下所示:
df1 = pd.read_html('https://www.google.com/')让我们按如下方式获取对象和数据的详细信息:
print(df1)
len(df1)
type(df1)
df1[0].head()您还可以解析检索到的 HTML 文本,并从标记中获取重要信息,如下所示:
from lxml import objectify
from io import StringIO下面是一个 HTML 标记字符串和解析它的方法,如下所示:
tag = '<a href="http://www.google.com/">Google</a>'
root = objectify.parse(StringIO(tag)).getroot()您按如下方式检索该对象的根和文本:
print(root)
root.get('href')
print(root.text)这将产生以下输出:
Google
Google与 Web API 交互
让我们学习与 web API 交互,以检索数据并将其存储到 Pandas 数据帧中。按如下方式安装必要的库:
!pip3 install requests让我们按如下方式导入库:
import requests让我们创建如下 URL 字符串:
url='https://api.github.com/repos/pandas-dev/pandas/issues'您可以使用以编程方式发出的 HTTP GET 请求从 URL 获取数据,如下所示:
resp = requests.get(url)您可以检查响应代码及其数据类型,如下所示:
print(resp)
print(type(resp))输出如下所示:
<Response [200]>
<class 'requests.models.Response'>HTTP 响应代码 200 代表检索信息成功。您可以按如下方式检索实际信息:
data = resp.json()
print(type(data))这将是一个列表,如下所示:
<class 'list'>您可以将其转换为数据帧,如下所示:
output = pd.DataFrame(data, columns=['number', 'title', 'labels', 'state'])
print(output)图 15-2 显示了输出。

图 15-2
HTTPS 的数据得到了回应
这就是你如何处理网上的数据。
从关系数据库表中读取数据
您可以读取存储在关系数据库(如 MySQL 或 MariaDB)的表中的数据。您可以通过以下网址了解有关安装和使用的更多信息:
https://www.mysql.com/
https://mariadb.org/您必须安装外部库,如下所示:
!pip3 install pymysql然后,您需要将库导入笔记本,如下所示:
import pymysql您可以连接到 MySQL 或 MariaDB 数据库实例,如下所示:
db = pymysql.connect(host="localhost", user="root",password="test123", database="world")然后您可以将一个SELECT查询的输出读入一个数据帧,如下所示:
df1 = pd.read_sql('select * from country', db)
print(df1)这产生了如图 15-3 所示的输出。

图 15-3
MySQL/MariaDB 表中的数据
从剪贴板读取数据
您可以读取存储在剪贴板上的数据。剪贴板是计算机主内存(RAM)中的一个临时且未命名的缓冲区,一些操作系统为程序内部和程序之间的数据短期存储和传输提供该缓冲区。例如,无论何时从文件中复制文本数据,它都会存储在操作系统的剪贴板上。
通过选择下列数据并按下键盘上的 Ctrl+C 按钮,将这些数据复制到计算机的剪贴板中。
A B C
x 1 2 a
y 2 3 b
z 3 4 c您可以使用以下代码将其加载到 Pandas 数据帧中:
df = pd.read_clipboard()您还可以通过编程方式将数据复制到剪贴板上,如下所示:
import numpy as np
df = pd.DataFrame(np.random.randn(5, 3))
df.to_clipboard()您可以通过以编程方式将剪贴板读入 dataframe(如前所述)来查看这些数据,也可以使用 Ctrl+V 命令将其粘贴到文本编辑器中,如 Notepad(在 Windows 上)或 Leafpad 或 gedit(在 Linux 上)。
摘要
在本章中,您学习了如何从多种文件格式中读取数据,以及如何将数据加载到 Python 变量中。
在下一章中,您将学习如何使用 Matplotlib 可视化 Pandas 数据。
十六、使用 Pandas 和 Matplotlib 可视化数据
在前一章中,您学习了如何使用 NumPy、Pandas 和 Matplotlib 将各种文件格式存储的数据读入 Python 变量。
现在,您应该可以轻松处理数据了。在本章中,你将练习编写与数据科学领域另一个重要而实用的方面相关的程序:数据集可视化。这一章包含了许多简短的代码片段来演示如何创建数据集的可视化。因此,让我们通过本章中的以下主题继续我们的数据科学之旅:
-
简单的绘图
-
条形图
-
直方图
-
箱线图
-
面积图
-
散点图
-
六边形箱线图
-
饼图
在本章之后,你将能够用 Pandas 和 Matplotlib 创建令人印象深刻的数据集可视化。
简单的绘图
让我们直接进入数据可视化的实践示例。你将首先学习如何可视化简单的绘图。我建议您为本章中的代码示例创建一个新笔记本。
让我们从导入所有必需库的神奇命令开始,如下所示:
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np让我们使用例程cumsum()创建一些数据,如下所示:
df1 = pd.DataFrame(np.random.randn(100, 2), columns=['B', 'C']).cumsum()
df1['A'] = pd.Series(list(range(100)))
print(df1)结果数据集将有三列,如下所示:
B C A
0 -0.684779 -0.655677 0
1 -0.699163 -1.868611 1
2 -0.315527 -3.513103 2
3 -0.504069 -4.175940 3
4 0.998419 -4.385832 4
.. ... ... ..
95 1.149399 -1.445029 95
96 2.035029 -1.886731 96
97 0.938699 0.188980 97
98 2.449148 0.335828 98
99 2.204369 -1.304379 99[100 rows x 3 columns]让我们使用例程plot()来可视化这些数据。dataframe 对象使用的plot()例程默认调用 Pyplot 的plot()。这里有一个例子:
plt.figure()
df1.plot(x='A', y='B')
plt.show()这段代码是不言自明的。我们传递包含列名的字符串作为 x 轴和 y 轴的参数。它产生如图 16-1 所示的输出。

图 16-1
想象一个简单的绘图
您也可以在可视化中使用其他列,如下所示:
plt.figure()
df1.plot(x='A', y='C')
plt.show()运行这个例子来看看结果。这就是如何使用不同的列组合来可视化数据。
条形图
让我们使用相同的数据集创建一个简单的条形图。让我们从该数据帧中选取一条记录,如下所示:
print(df1.iloc[4])以下是输出:
B 0.998419
C -4.385832
A 4.000000
Name: 4, dtype: float64让我们使用例程bar()用这些数据画一个简单的条形图。以下是相关的代码片段:
plt.figure()
df1.iloc[4].plot.bar()
plt.axhline(0, color='k')
plt.show()在这个代码示例中,我们使用axhline()绘制一条对应于 x 轴的水平线。图 16-2 显示输出。

图 16-2
可视化简单的条形图
让我们讨论一个更复杂的条形图的例子。让我们创建一个新的数据集,如下所示:
df2 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
print(df2)输出如下所示:
a b c d
0 0.352173 0.127452 0.637665 0.734944
1 0.375190 0.931818 0.769403 0.927441
2 0.830744 0.942059 0.781032 0.557774
3 0.977058 0.594992 0.557016 0.862058
4 0.960796 0.329448 0.493713 0.971139
5 0.364460 0.516401 0.432365 0.587528
6 0.292020 0.500945 0.889294 0.211502
7 0.770808 0.519468 0.279582 0.419549
8 0.982924 0.458197 0.938682 0.123614
9 0.578290 0.186395 0.901216 0.099061在前面的例子中,我们只可视化了一行。现在,让我们将整个数据集可视化如下:
plt.figure()
df2.plot.bar()
plt.show()这将为每一行创建一个条形图。图表将按行分组,如图 16-3 所示。

图 16-3
可视化更复杂的条形图
可以看到,x 轴表示指数,y 轴表示幅度。这是一个未堆叠的垂直条形图。您可以通过传递一个简单的参数来创建它的堆叠变体,如下所示:
plt.figure()
df2.plot.bar(stacked=True)
plt.show()图 16-4 显示了输出。

图 16-4
可视化垂直堆叠条形图
您甚至可以创建水平堆叠和非堆叠条形图。让我们用例程barh()创建一个水平堆叠条形图,如下所示:
plt.figure()
df2.plot.barh(stacked=True)
plt.show()图 16-5 显示了输出。

图 16-5
可视化水平堆叠条形图
让我们通过省略参数为非堆叠水平条形图编写一段代码,如下所示:
plt.figure()
df2.plot.barh()
plt.show()图 16-6 显示了输出。

图 16-6
可视化水平未堆叠条形图
您刚刚学习了如何创建各种类型的条形图。
直方图
直方图是数字数据频率分布的直观表示。它首先被卡尔·皮尔逊使用。
我们首先将数据分成不同的桶或箱。箱子的大小取决于要求。对于整数数据集,可以有最小的容器大小,即 1。然后,对于每个库,您可以列出该库下的元素的出现次数。然后,您可以将该表显示为条形图。
你可以用 Pandas 和 Matplotlib 绘制给定数据集的直方图。让我们创建一个数据集,如下所示:
df4 = pd.DataFrame({'a': np.random.randn(1000) + 1,'b': np.random.randn(1000),'c': np.random.randn(1000) - 1},columns=['a', 'b', 'c'])
print(df4)生成的数据集如下:
a b c
0 1.454474 -0.517940 -0.772909
1 1.886328 0.868393 0.109613
2 0.041313 -1.959168 -0.713575
3 0.650075 0.457937 -0.501023
4 1.684392 -0.072837 1.821190
.. ... ... ...
995 0.800481 -1.209032 -0.249132
996 0.490104 0.253966 -1.185503
997 2.304285 0.082134 -1.068881
998 1.249055 0.040750 -0.488890
999 -1.216627 0.444629 -1.198375[1000 rows x 3 columns]让我们使用例程hist()将该数据集可视化为直方图,如下所示:
plt.figure();
df4.plot.hist(alpha=0.7)
plt.show()图 16-7 显示了输出。

图 16-7
将数据集可视化为直方图
传递给 routine 的参数决定了输出的不透明度(或 alpha 透明度)。在上一个示例中,您必须使其透明,因为直方图未堆叠。让我们创建一个堆叠直方图,桶的大小为 20,如下所示:
plt.figure();
df4.plot.hist(stacked=True, bins=20)
plt.show()图 16-8 显示了输出。

图 16-8
将同一数据集可视化为非堆叠直方图
让我们创建一个单列的水平累积直方图,如下所示:
plt.figure();
df4['a'].plot.hist(orientation='horizontal', cumulative=True)
plt.show()图 16-9 显示了输出。

图 16-9
水平累积直方图
相同直方图的垂直版本可创建如下:
plt.figure();
df4['a'].plot.hist(orientation='vertical', cumulative=True)
plt.show()图 16-10 显示了输出。

图 16-10
垂直累积直方图
接下来让我们尝试一种奇特的直方图。例程diff()计算前一行和当前行之间的数值差。
print(df4.diff())对于所有列,输出将在第一行填充 NaN(因为在第一行之前没有行)。输出如下所示:
a b c
0 NaN NaN NaN
1 0.431854 1.386333 0.882522
2 -1.845015 -2.827562 -0.823188
3 0.608762 2.417105 0.212552
4 1.034317 -0.530774 2.322213
.. ... ... ...
995 0.411207 -2.847858 0.325067
996 -0.310378 1.462998 -0.936370
997 1.814182 -0.171832 0.116622
998 -1.055230 -0.041384 0.579991
999 -2.465682 0.403880 -0.709485[1000 rows x 3 columns]让我们来可视化这个数据集,如下所示:
plt.figure()
df4.diff().hist(color='k', alpha=0.5, bins=50)
plt.show()图 16-11 显示了输出。

图 16-11
列方向直方图
您刚刚学习了如何将数据集可视化为直方图。
箱线图
您也可以用盒状图来可视化数据。箱线图(也拼写为箱线图)通过四分位数显示数字数据组。让我们创建一个数据集,如下所示:
df = pd.DataFrame(np.random.rand(10, 5),columns=['A', 'B', 'C', 'D', 'E'])
print(df)生成的数据集如下:
A B C D E
0 0.684284 0.033906 0.099369 0.684024 0.533463
1 0.614305 0.645413 0.871788 0.561767 0.149080
2 0.226480 0.440091 0.096022 0.076962 0.674901
3 0.541253 0.409599 0.487924 0.649260 0.582250
4 0.436995 0.142239 0.781428 0.634987 0.825146
5 0.804633 0.874081 0.018661 0.306459 0.008134
6 0.228287 0.418942 0.157755 0.561070 0.740077
7 0.699860 0.230533 0.240369 0.108759 0.843307
8 0.530943 0.374583 0.650235 0.370809 0.595791
9 0.213455 0.221367 0.035203 0.887068 0.593629您可以按如下方式绘制箱形图:
plt.figure()
df.plot.box()
plt.show()这将把数据集显示为箱形图,如图 16-12 所示。

图 16-12
垂直箱线图
此处显示的颜色是默认值。你可以改变他们。首先,您需要创建一个字典,如下所示:
color = dict(boxes='DarkGreen',whiskers='DarkOrange',medians='DarkBlue',caps='Gray')
print(color)以下是输出:
{'boxes': 'DarkGreen', 'whiskers': 'DarkOrange', 'medians': 'DarkBlue', 'caps': 'Gray'}最后,您将这个字典作为参数传递给绘制盒状图的例程,如下所示:
plt.figure()
df.plot.box(color=color, sym='r+')
plt.show()图 16-13 显示了输出。

图 16-13
带有自定义颜色的垂直方框图
以下示例创建了一个水平方框图可视化:
plt.figure()
df.plot.box(vert=False, positions=[1, 2, 3, 4 , 5])
plt.show()图 16-14 显示了输出。

图 16-14
水平箱形图
让我们看看另一个例程,boxplot(),它也创建了方框图。为此,让我们创建另一个数据集,如下所示:
df = pd.DataFrame(np.random.rand(10, 5))
print(df)输出数据集如下所示:
0 1 2 3 4
0 0.936845 0.365561 0.890503 0.264896 0.937254
1 0.931661 0.226297 0.887385 0.036719 0.941609
2 0.127896 0.291034 0.161724 0.952966 0.925534
3 0.938686 0.336536 0.934843 0.806043 0.104054
4 0.743787 0.600116 0.989178 0.002870 0.453338
5 0.256692 0.773945 0.165381 0.809204 0.162431
6 0.822131 0.486780 0.453981 0.612403 0.614633
7 0.062387 0.958844 0.247515 0.573431 0.194665
8 0.453193 0.152337 0.062436 0.865115 0.220440
9 0.832040 0.237582 0.837805 0.423779 0.119027您可以按如下方式绘制箱形图:
plt.figure()
bp = df.boxplot()
plt.show()图 16-15 显示了输出。

图 16-15
方框图在起作用
例程boxplot()的主要优点是您可以在单个输出中拥有列级可视化。让我们创建一个适当的数据集,如下所示:
df = pd.DataFrame(np.random.rand(10, 2), columns=['Col1', 'Col2'] )
df['X'] = pd.Series(['A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B'])
print(df)输出数据集如下所示:
Col1 Col2 X
0 0.469416 0.341874 A
1 0.176359 0.921808 A
2 0.135188 0.149354 A
3 0.475295 0.360012 A
4 0.566289 0.142729 A
5 0.408705 0.571466 B
6 0.233820 0.470200 B
7 0.679833 0.633349 B
8 0.183652 0.559745 B
9 0.192431 0.726981 B让我们按如下方式创建列级可视化:
plt.figure();
bp = df.boxplot(by='X')
plt.show()默认情况下,输出会有一个解释数据如何分组的标题,如图 16-16 所示。

图 16-16
带组的盒状图
让我们看一个稍微复杂一点的例子。以下是新数据集的代码:
df = pd.DataFrame(np.random.rand(10,3), columns=['Col1', 'Col2', 'Col3'])
df['X'] = pd.Series(['A','A','A','A','A','B','B','B','B','B'])
df['Y'] = pd.Series(['A','B','A','B','A','B','A','B','A','B'])
print(df)这段代码创建了以下数据集:
Col1 Col2 Col3 X Y
0 0.542771 0.175804 0.017646 A
1 0.247552 0.503725 0.569475 A B
2 0.593635 0.842846 0.755377 A
3 0.210409 0.235510 0.633318 A B
4 0.268419 0.170563 0.478912 A
5 0.526251 0.258278 0.549876 B
6 0.311182 0.212787 0.966183 B A
7 0.100687 0.432545 0.586907 B
8 0.416833 0.879384 0.635664 B A
9 0.249280 0.558648 0.661523 B您可以在多个列的组中创建盒图(这意味着分组标准将有多个列)。
plt.figure();
bp = df.boxplot(column=['Col1','Col2'], by=['X','Y'])
plt.show()图 16-17 显示了输出。

图 16-17
分组的盒状图(分组标准中的多列)
让我们看一个更复杂的例子,数据集有更多的变化。下面的代码创建了这样一个数据集:
np.random.seed(1234)
df_box = pd.DataFrame(np.random.randn(10, 2), columns=['A', 'B'])
df_box['C'] = np.random.choice(['Yes', 'No'], size=10)
print(df_box)输出是以下数据集:
A B C
0 0.471435 -1.190976 No
1 1.432707 -0.312652 Yes
2 -0.720589 0.887163 No
3 0.859588 -0.636524 Yes
4 0.015696 -2.242685 No
5 1.150036 0.991946 Yes
6 0.953324 -2.021255 No
7 -0.334077 0.002118 No
8 0.405453 0.289092 No
9 1.321158 -1.546906 No您可以使用 Pandas 中的例程groupby()对数据进行分组,并将其可视化,如下所示:
plt.figure()
bp = df_box.boxplot(by='C')
plt.show()图 16-18 显示了按列 c 分组的输出。

图 16-18
箱线图 plt.figure()可视化,按列 C 分组
另一个例子如下:
bp = df_box.groupby('C').boxplot()
plt.show()图 16-19 显示了输出。

图 16-19
按列 C 分组的箱形图可视化
这就是将数据集可视化为箱线图的方式。
面积图
您也可以将数据集可视化为面积图。让我们创建一个包含四列的数据集,如下所示:
df = pd.DataFrame(np.random.rand(10, 4),columns=['A', 'B', 'C', 'D'])
print(df)这将创建以下数据集:
A B C D
0 0.982005 0.123943 0.119381 0.738523
1 0.587304 0.471633 0.107127 0.229219
2 0.899965 0.416754 0.535852 0.006209
3 0.300642 0.436893 0.612149 0.918198
4 0.625737 0.705998 0.149834 0.746063
5 0.831007 0.633726 0.438310 0.152573
6 0.568410 0.528224 0.951429 0.480359
7 0.502560 0.536878 0.819202 0.057116
8 0.669422 0.767117 0.708115 0.796867
9 0.557761 0.965837 0.147157 0.029647您可以使用例程area()可视化所有这些数据,如下所示:
plt.figure()
df.plot.area()
plt.show()前面的例子创建了一个堆积面积图,如图 16-20 所示。

图 16-20
堆积面积图
您也可以通过向例程area()传递一个参数来创建未堆叠区域图,如下所示:
plt.figure()
df.plot.area(stacked=False)
plt.show()默认情况下,未堆叠面积图是透明的,因此所有单个面积图都是可见的。图 16-21 显示了输出。

图 16-21
未堆叠面积图
这是创建面积图的方法。
散点图
您还可以将任何数据集可视化为散点图。让我们创建一个数据集,如下所示:
df = pd.DataFrame(np.random.rand(10, 4),columns=['A', 'B', 'C', 'D'])
print(df)输出数据集如下所示:
A B C D
0 0.593893 0.114066 0.950810 0.325707
1 0.193619 0.457812 0.920403 0.879069
2 0.252616 0.348009 0.182589 0.901796
3 0.706528 0.726658 0.900088 0.779164
4 0.599155 0.291125 0.151395 0.335175
5 0.657552 0.073343 0.055006 0.323195
6 0.590482 0.853899 0.287062 0.173067
7 0.134021 0.994654 0.179498 0.317547
8 0.568291 0.009349 0.900649 0.977241
9 0.556895 0.084774 0.333002 0.728429您可以将 A 列和 B 列可视化为散点图,如下所示:
plt.figure()
df.plot.scatter(x='A', y='B')
plt.show()图 16-22 显示了输出。

图 16-22
简单散点图
您可以可视化多个组,如下所示:
ax = df.plot.scatter(x='A', y='B',color='Blue',label='Group 1')
plt.figure()
df.plot.scatter(x='C', y='D',color='Green',label='Group 2',ax=ax)
plt.show()图 16-23 显示了输出。

图 16-23
多组散点图
让我们看看如何自定义散点图。您可以自定义点的颜色和大小。颜色或尺寸可以是恒定的,也可以是可变的。以下是数据点可变颜色和恒定大小的示例。当颜色可变时,默认情况下会在输出中添加一个颜色条。
plt.figure()
df.plot.scatter(x='A', y='B', c='C', s=40)
plt.show()图 16-24 显示了输出。

图 16-24
数据点的不同颜色散点图
让我们将大小指定为变量,如下所示:
plt.figure()
df.plot.scatter(x='A', y='B', s=df['C']*100)
plt.show()图 16-25 显示了输出。

图 16-25
数据点大小不同的散点图
最后,让我们看一个完全定制的可变尺寸和可变颜色的示例,如下所示:
plt.figure()
df.plot.scatter(x='A', y='B', c='C', s=df['D']*100)
plt.show()图 16-26 显示了输出。

图 16-26
数据点大小不同的散点图
您刚刚学习了如何创建和定制散点图。
六边形箱线图
您也可以用六边形仓(hexbin)图来可视化数据。让我们准备一个数据集如下:
df = pd.DataFrame(np.random.randn(100, 2),columns=['A', 'B'])
df['B'] = df['B'] + np.arange(100)
print(df)输出如下所示:
A B
0 0.165445 -1.127470
1 -1.192185 1.818644
2 0.237185 1.663616
3 0.694727 3.750161
4 0.247055 4.645433
.. ... ...
95 0.650346 94.485664
96 0.539429 97.526762
97 -3.277193 95.151439
98 0.672125 96.507021
99 -0.827198 99.914196[100 rows x 2 columns]让我们用 hexbin 图来直观显示这些数据,如下所示:
plt.figure()
df.plot.hexbin(x='A', y='B', gridsize=20)
plt.show()图 16-27 显示了输出。

图 16-27
Hexbin 图示例
如您所见,您可以自定义网格的大小。
饼图
最后,您将学习如何创建饼图来可视化数据集。让我们创建一个数据集,如下所示:
series = pd.Series(3 * np.random.rand(4),index=['A', 'B', 'C', 'D'],name='series')
print(series)这将创建以下数据集:
A 1.566910
B 0.294986
C 2.140910
D 2.652122
Name: series, dtype: float64您可以将其形象化如下:
plt.figure()
series.plot.pie(figsize=(6, 6))
plt.show()图 16-28 显示了输出。

图 16-28
简单的饼图
让我们创建一个包含两列的数据集,如下所示:
df = pd.DataFrame(3 * np.random.rand(4, 2),index=['A', 'B', 'C', 'D'],columns=['X', 'Y'])
print(df)这会生成以下数据:
X Y
A 1.701163 2.983445
B 0.536219 0.036600
C 1.370995 2.795256
D 2.538074 1.419990图 16-29 显示了输出。

图 16-29
多列数据集的简单饼图
您可以自定义饼图。具体来说,您可以自定义字体、颜色和标签,如下所示:
plt.figure()
series.plot.pie(labels=['A', 'B', 'C', 'D'],colors=['r', 'g', 'b', 'c'],autopct='%.2f', fontsize=20,figsize=(6, 6))
plt.show()图 16-30 显示了输出。

图 16-30
一个简单而定制的饼图
让我们通过传递总和小于 1.0 的值来创建一个部分饼图。以下是这方面的数据:
series = pd.Series([0.1] * 4,index=['A', 'B', 'C', 'D'],name='series2')
print(series)这将创建以下数据集:
A 0.1
B 0.1
C 0.1
D 0.1
Name: series2, dtype: float64部分饼图可以如下图所示:
plt.figure()
series.plot.pie(figsize=(6, 6))
plt.show()这就形成了一个局部饼图(或半圆),如图 16-31 所示。

图 16-31
一个简单而定制的饼图
您刚刚学习了如何用饼图可视化数据。
摘要
在本章中,您学习了如何使用各种技术来可视化数据。您可以在实际项目中使用这些可视化技术。在接下来的章节中,我们将探索用 Python 创建数据可视化的其他库。
在下一章中,您将了解如何使用一个名为 Seaborn 的新库来创建数据可视化。
十七、Seaborn 数据可视化简介
在前一章中,您学习了如何可视化存储在 Pandas 系列和 dataframe 中的数据。
在本书的前几章中,您广泛学习了数据可视化库 Matplotlib 以及其他重要的数据科学库 NumPy 和 Pandas。在这一章中,您将暂时脱离 Matplotlib,学习如何使用另一个名为 Seaborn 的相关库进行数据可视化。以下是您将在本章中了解的主题:
-
什么是 Seaborn?
-
绘制统计关系
-
绘制线条
-
可视化数据的分布
读完这一章,你会很容易使用 Seaborn 库,并且能够创建很好的数据集可视化。
什么是 Seaborn?
您已经学习了如何使用 Matplotlib 库进行数据可视化。Matplotlib 并不是 Python 中唯一的数据可视化库。Python 中有许多可以可视化数据的库。科学数据可视化库支持 NumPy 和 Pandas 的数据结构。用于科学 Python 可视化的一个这样的库是 Seaborn ( https://seaborn.pydata.org/index.html )。Seaborn 是基于 Matplotlib 构建的。它为绘制吸引人的图形提供了很多功能。它在 Pandas 中内置了对 series 和 dataframe 数据结构的支持,在 NumPy 中内置了对 Ndarrays 的支持。
让我们为本章中的演示创建一个新笔记本。现在,让我们用下面的命令安装 Seaborn:
!pip3 install seaborn您可以使用以下语句将库导入到您的笔记本或 Python 脚本中:
import seaborn as sns你知道 Seaborn 图书馆支持 Pandas 数据帧。Seaborn 库也存储了许多填充了数据的数据帧。所以,我们可以用它们来做演示。让我们看看如何检索这些数据帧。以下命令返回所有内置示例数据帧的列表:
sns.get_dataset_names()以下是输出:
['anagrams','anscombe','attention','brain_networks','car_crashes','diamonds','dots','exercise','flights','fmri','gammas','geyser','iris','mpg','penguins','planets','tips','titanic']您可以将这些数据帧加载到 Python 变量中,如下所示:
iris = sns.load_dataset('iris')让我们用下面的语句来看看存储在iris数据集中的数据:
iris图 17-1 显示了输出。

图 17-1
虹膜数据集
绘制统计关系
您可以在 Seaborn 中用各种函数绘制两个变量之间的统计关系。完成这项工作的通用绘图函数是relplot()。您可以使用此功能绘制各种类型的数据。默认情况下,relplot()函数绘制散点图。这里有一个例子:
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltsns.relplot(x='sepal_length',y='sepal_width',data=iris)
plt.grid('on')
plt.show()这产生了如图 17-2 所示的散点图。

图 17-2
散点图
您可以明确指定绘图类型,如下所示:
sns.relplot(x='sepal_length', y='sepal_width',data=iris, kind='scatter')
plt.grid('on')
plt.show()函数replot()是一个通用函数,可以传递一个参数来指定绘图类型。您也可以使用功能scatterplot()创建散点图。例如,下面的代码创建了如图 17-2 所示的相同结果:
sns.scatterplot(x='sepal_length',y='sepal_width',data=iris)
plt.grid('on')
plt.show()您可以将数据集的一些其他列提供给绘图函数,如下所示:
sns.relplot(x='petal_length',y='petal_width',data=iris)
plt.grid('on')
plt.show()图 17-3 显示了输出。

图 17-3
散点图的另一个例子
您也可以用scatterplot()函数编写如下:
sns.scatterplot(x='petal_length',y='petal_width',data=iris)
plt.grid('on')
plt.show()您可以自定义绘图,并使用颜色编码显示附加列,如下所示:
sns.relplot(x='sepal_length',y='sepal_width',hue='species',data=iris)
plt.grid('on')
plt.show()图 17-4 显示了输出。

图 17-4
带颜色的散点图
使用以下代码,您会得到如图 17-4 所示的相同结果:
sns.scatterplot(x='sepal_length',y='sepal_width',hue='species',data=iris)
plt.grid('on')
plt.show()您还可以为散点图数据点(标记)分配样式,如下所示:
sns.relplot(x='sepal_length', y='sepal_width',hue='petal_length', style='species',data=iris)
plt.grid('on')
plt.show()您可以在图 17-5 中看到输出。

图 17-5
带有颜色和自定义样式的散点图
以下代码产生如图 17-5 所示的相同输出:
sns.scatterplot(x='sepal_length', y='sepal_width',hue='petal_length', style='species',data=iris)
plt.grid('on')
plt.show()您也可以调整标记的大小,如下所示:
sns.relplot(x='sepal_length', y='sepal_width',size='petal_length', style='species',hue='species', data=iris)
plt.grid('on')
plt.show()图 17-6 显示了输出。

图 17-6
带有颜色、自定义样式和标记大小的散点图
以下代码产生如图 17-5 所示的相同结果:
sns.scatterplot(x='sepal_length', y='sepal_width',size='petal_length', style='species',hue='species', data=iris)
plt.grid('on')
plt.show()绘制线条
您还可以显示连续数据,如沿线的时间序列数据。时序数据至少在一列中有时间戳数据,或者有一个索引。时间序列的一个很好的例子是每日温度记录表。让我们创建一个时间序列数据框架来演示折线图。
df = pd.DataFrame(np.random.randn(100, 4),index=pd.date_range("1/1/2020",periods=100),columns=list("ABCD"))
df = df.cumsum()您可以使用功能relplot()绘制如下直线:
sns.relplot(x=df.index, y='A', kind="line", data=df)
plt.xticks(rotation=45)
plt.show()图 17-7 显示了输出。

图 17-7
时间序列数据的线图
您也可以使用以下代码生成如图 17-7 所示的输出:
sns.lineplot(x=df.index,y='A', data=df)
plt.xticks(rotation=45)
plt.show()在下一节中,您将学习如何可视化数据的分布。
可视化数据的分布
可视化数据分布的一个最突出的例子是频率表或频率分布表。您可以创建数据可以具有的值范围的存储桶(域),然后可以列出满足存储桶标准的项目数。您还可以改变存储桶的大小,最小大小为 1。
您可以使用条形图和线条直观地显示频率分布的信息。如果你使用棒线,那么它就是所谓的直方图。您可以使用功能displot()来可视化频率数据。让我们从虚拟的单变量数据开始。
x = np.random.randn(100)
sns.displot(x)
plt.show()图 17-8 显示了输出。

图 17-8
柱状图
您还可以在输出中明确表示您需要一个直方图,如下所示:
sns.displot(x, kind='hist')
plt.show()直方图是默认的图表类型。您还可以显示高斯核密度估计(KDE),如下所示:
sns.displot(x, kind='kde')
plt.show()图 17-9 显示了输出。

图 17-9
KDE 图
您可以将经验累积分布函数(eCDF)可视化如下:
sns.displot(x, kind='ecdf')
plt.show()图 17-10 显示了输出。

图 17-10
eCDF 图
您可以将直方图和 KDE 组合起来,如下所示:
sns.displot(x, kind='hist', kde=True)
plt.show()图 17-11 显示了输出。

图 17-11
结合 KDE 的直方图
现在让我们使用一些现实生活中的数据,如下:
tips = sns.load_dataset("tips")
sns.displot(x='total_bill', data=tips, kind='hist')
plt.show()图 17-12 显示了输出。

图 17-12
现实生活中的数据可视化为直方图
您可以在可视化中自定义容器(或桶)的大小,如下所示:
sns.displot(x='total_bill', data=tips,kind='hist', bins=30, kde=True)
plt.show()图 17-13 显示了输出。

图 17-13
直方图中的自定义存储桶
您可以根据您选择的标准调整图的色调,如下所示:
sns.displot(x='total_bill', data=tips,kind='kde', hue='size')
plt.show()图 17-14 显示了输出。

图 17-14
KDE 图中的定制颜色
到目前为止,我们已经使用了单个变量来显示该图。当您使用两个变量进行绘图时,它被称为双变量图。这里有一个简单的例子:
sns.displot(x='total_bill',y='tip', data=tips)
plt.show()图 17-15 显示了输出。

图 17-15
简单的二元直方图
您可以向此示例添加颜色,如下所示:
sns.displot(x='total_bill', y='tip',hue='size', data=tips)
plt.show()图 17-16 显示了输出。

图 17-16
一个简单的带颜色的二元直方图
您还可以自定义框的大小,并在 x 轴和 y 轴上添加记号(称为地毯图),如下所示:
sns.displot(x='total_bill', y='tip',data=tips, rug=True,kind='hist', bins=30)
plt.show()图 17-17 显示了输出。

图 17-17
一个简单的双变量直方图,带有自定义的条块和地毯图
一种更有趣的可视化形式是双变量 KDE 图。它看起来像一个轮廓。代码如下:
sns.displot(x='total_bill', y='tip',data=tips, kind='kde')
plt.show()图 17-18 显示了输出。

图 17-18
一个简单的二元 KDE 图
您可以将地毯图添加到输出中,如下所示:
sns.displot(x='total_bill', y='tip',data=tips, rug=True,kind='kde')
plt.show()输出具有 KDE 和 rug 可视化效果,如图 17-19 所示。

图 17-19
带有地毯图的简单二元 KDE 图
基于数据框中的列,您可以创建按行或列排列的单个可视化效果。让我们根据吸头的大小创建一个可视化效果,如下所示:
sns.displot(x='total_bill', y='tip',data=tips, rug=True,kind='kde', col='size')
plt.show()在前面的示例中,我们启用了 rug plot 特性,这些图将根据吸头的大小单独生成。图 17-20 显示了输出。

图 17-20
一个简单的二元 KDE 图,地毯图按列排列
您也可以按如下方式按行排列各个图形:
sns.displot(x='total_bill', y='tip',data=tips, rug=True,kind='kde', row='size')
plt.show()图 17-21 显示了输出。

图 17-21
带有成行排列的地毯图的简单二元 KDE 图
您刚刚学习了如何可视化数据的分布。
摘要
这一章包含了大量的演示。您详细探索了 Python 的 Seaborn 数据可视化库。Seaborn 是一个庞大的库,在这一章中我们仅仅触及了它的皮毛。你可以参考位于 https://seaborn.pydata.org/index.html 的 Seaborn 项目主页,获取 API 文档、教程和示例库。
在本书的下一章也是最后一章,您将学习如何使用 Matplotlib 和 Seaborn 数据可视化库可视化当前正在进行的新冠肺炎疫情的真实数据。
十八、使用 Matplotlib 和 Seaborn 可视化真实数据
在上一章中,您学习了如何使用新的数据可视化库为科学 Python 任务可视化数据。您学习了从以各种格式存储的数据中创建可视化效果。
在本章中,您将利用本书前几章中获得的所有知识,将它们整合在一起,为来自新冠肺炎疫情的真实数据和来自互联网的动物疾病数据集准备可视化。以下是您将在本章中探讨的主题:
-
新冠肺炎疫情数据
-
以编程方式获取疫情数据
-
为可视化准备数据
-
使用 Matplotlib 和 Seaborn 创建可视化
-
创建动物疾病数据的可视化
阅读完本章后,您将能够轻松使用和创建真实数据集的可视化效果。
新冠肺炎疫情数据
在写这篇文章的时候(2021 年 5 月),世界正面临着新冠肺炎疫情。新冠肺炎是由严重急性呼吸综合征冠状病毒 2 型(新型冠状病毒)引起的。症状包括常见的流感样症状和呼吸困难。
世界上有多个组织收集和共享流行病的实时数据。一个是约翰霍普金斯大学( https://coronavirus.jhu.edu/map.html ),一个是 Worldometers ( https://www.worldometers.info/coronavirus/ )。这两个网页都有关于新冠肺炎疫情的数据,并且更新非常频繁。图 18-1 显示了新冠肺炎的约翰霍普金斯页面。

图 18-1
约翰霍普金斯大学新冠肺炎主页
图 18-2 显示了 Worldometers 网站。

图 18-2
世界计量新冠肺炎主页
正如我提到的,数据经常更新,所以这些网站对于最新的信息是相当可靠的。
以编程方式获取疫情数据
在本节中,您将学习如何使用 Python 程序获取两个数据集(约翰霍普金斯大学和世界计量学院)。为此,您需要为 Python 安装一个库。图书馆主页位于 https://ahmednafies.github.io/covid/ ,PyPI 页面为 https://pypi.org/project/covid/ 。使用 Jupyter 笔记本为本章创建一个新笔记本。您可以在笔记本中使用以下命令轻松安装该库:
!pip3 install covid您可以将库导入笔记本或 Python 脚本/程序,如下所示:
from covid import Covid您可以创建一个对象来从在线源获取数据。默认情况下,约翰霍普金斯大学的数据源如下:
covid = Covid()请注意,由于高流量,有时服务器没有响应。这种情况我经历过很多次。
您可以按如下方式明确提及数据源:
covid = Covid(source="john_hopkins")您可以按如下方式明确指定世界几何:
covid = Covid(source="worldometers")您可以看到数据的来源如下:
covid.source根据数据源,这会返回一个相关的字符串,如下所示:
'john_hopkins'您可以按国家名称获取状态,如下所示:
covid.get_status_by_country_name("italy")这将返回一个字典,如下所示:
{'id': '86','country': 'Italy','confirmed': 4188190,'active': 283744,'deaths': 125153,'recovered': 3779293,'latitude': 41.8719,'longitude': 12.5674,'last_update': 1621758045000}您还可以通过国家 ID 获取状态,尽管只有 Johns Hopkins 数据集有此列,因此代码将为 Worldometers 返回一个错误。
# Only valid for Johns Hopkins
covid.get_status_by_country_id(115)输出类似于前面的示例,如下所示:
{'id': '115','country': 'Mexico','confirmed': 2395330,'active': 261043,'deaths': 221597,'recovered': 1912690,'latitude': 23.6345,'longitude': -102.5528,'last_update': 1621758045000}您也可以获取国家列表,如下所示:
covid.list_countries()以下是部分输出:
{'id': '179', 'name': 'US'},{'id': '80', 'name': 'India'},{'id': '24', 'name': 'Brazil'},{'id': '63', 'name': 'France'},{'id': '178', 'name': 'Turkey'},{'id': '143', 'name': 'Russia'},{'id': '183', 'name': 'United Kingdom'},
....在本章中,您将继续使用约翰霍普金斯数据集。
您可以获得如下活动案例:
covid.get_total_active_cases()输出如下所示:
27292520您可以按如下方式获得确诊病例总数:
covid.get_total_confirmed_cases()输出如下所示:
166723247您可以获得恢复的案例总数,如下所示:
covid.get_total_recovered()输出如下所示:
103133392你可以得到总死亡人数如下:
covid.get_total_deaths()输出如下所示:
3454602您可以通过函数调用covid.get_data()获取所有数据。这将返回一个字典列表,其中每个字典保存一个国家的数据。以下是输出:
[{'id': '179','country': 'US','confirmed': 33104963,'active': None,'deaths': 589703,'recovered': None,'latitude': 40.0,'longitude': -100.0,'last_update': 1621758045000},{'id': '80','country': 'India','confirmed': 26530132,'active': 2805399,'deaths': 299266,'recovered': 23425467,'latitude': 20.593684,'longitude': 78.96288,'last_update': 1621758045000},
......为可视化准备数据
您必须准备好这些提取的数据以便可视化。为此,您必须转换 Pandas 数据框架中的词典列表。可以按如下方式完成:
import pandas as pd
df = pd.DataFrame(covid.get_data())
print(df)图 [18-3 显示了输出。

图 18-3
新冠肺炎数据的 Pandas 数据框架
您可以按如下方式进行排序:
sorted = df.sort_values(by=['confirmed'], ascending=False)然后,您必须排除世界和各大洲的数据,以便只保留单个国家的数据。
excluded = sorted [ ~sorted.country.isin(['Europe', 'Asia','South America','World', 'Africa','North America'])]让我们找出十大记录。
top10 = excluded.head(10)
print(top10)然后,您可以将列分配给各个变量,如下所示:
x = top10.country
y1 = top10.confirmed
y2 = top10.active
y3 = top10.deaths
y4 = top10.recovered使用 Matplotlib 和 Seaborn 创建可视化
让我们用 Matplotlib 和 Seaborn 将数据可视化。首先导入所有需要的库,如下所示:
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns可以获得如下简单的线性图:
plt.plot(x, y1)
plt.xticks(rotation=90)
plt.show()图 18-4 显示了输出。

图 18-4
使用 Matplotlib 绘制线性图
你可以给这个绘图加个标题。你也可以使用 Seaborn 库。以下是 Seaborn 的线形图示例:
sns.set_theme(style='whitegrid')
sns.lineplot(x=x, y=y1)
plt.xticks(rotation=90)
plt.show()在代码示例中,我们使用了函数set_theme()。它为 Matplotlib 和 Seaborn 可视化设置整个笔记本的主题。您可以将字符串'darkgrid'、'whitegrid'、'dark'、'white'或'ticks'中的一个作为参数传递给这个函数。图 18-5 显示了输出。

图 18-5
带有 Seaborn 的线性图
您可以使用 Matplotlib 创建一个简单的条形图,如下所示:
plt.bar(x, y1)
plt.xticks(rotation=45)
plt.show()图 18-6 显示了输出。

图 18-6
使用 Matplotlib 绘制条形图
同样的可视化也可以用 Seaborn 来实现,它可以生成美观得多的条形图。
sns.barplot(x=x, y=y1)
plt.xticks(rotation=45)
plt.show()图 18-7 显示了输出。

图 18-7
有 Seaborn 的条形图
您甚至可以按如下方式更改调色板:
sns.barplot(x=x, y=y1,palette="Blues_d")
plt.xticks(rotation=45)
plt.show()图 18-8 显示了输出。

图 18-8
使用带有自定义调色板的 Seaborn 的条形图
您可以按如下方式创建多行图形:
labels = ['Confirmed', 'Active', 'Deaths', 'Recovered']
plt.plot(x, y1, x, y2, x, y3, x, y4)
plt.legend(labels, loc='upper right')
plt.xticks(rotation=90)
plt.show()图 18-9 显示了输出。

图 18-9
多线图
您可以使用 Seaborn 库来创建相同的图形,如下所示:
sns.lineplot(x=x, y=y1)
sns.lineplot(x=x, y=y2)
sns.lineplot(x=x, y=y3)
sns.lineplot(x=x, y=y4)
plt.legend(labels, loc='upper right')
plt.xticks(rotation=45)
plt.show()图 18-10 显示了输出。

图 18-10
带有 Seaborn 的多线图
现在,您将看到如何使用 Matplotlib 创建多条形图,如下所示:
df2 = pd.DataFrame([y1, y2, y3, y4])
df2.plot.bar()
plt.legend(x, loc='best')
plt.xticks(rotation=45)
plt.show()图 18-11 显示了输出。

图 18-11
多行条形图
您甚至可以横向显示,如下所示:
df2.plot.barh()
plt.legend(x, loc='best')
plt.xticks(rotation=45)
plt.show()图 18-12 显示了输出。

图 18-12
多线水平图
您可以使用 Seaborn 创建散点图,如下所示:
sns.scatterplot(x=x, y=y1)
sns.scatterplot(x=x, y=y2)
sns.scatterplot(x=x, y=y3)
sns.scatterplot(x=x, y=y4)
plt.legend(labels, loc='best')
plt.xticks(rotation=45)
plt.show()图 18-13 显示了输出。

图 18-13
多行水平条形图
您甚至可以使用 Matplotlib 创建面积图,代码如下:
df2.plot.area()
plt.legend(x, loc='best')
plt.xticks(rotation=45)
plt.show()图 18-14 显示了输出。

图 18-14
堆积面积图
您可以为数据创建未堆叠的透明面积图,如下所示:
df2.plot.area(stacked=False)
plt.legend(x, loc='best')
plt.xticks(rotation=45)
plt.show()图 18-15 显示了输出。

图 18-15
堆积面积图
您可以按如下方式创建饼图:
plt.pie(y3, labels=x)
plt.title('Death Toll')
plt.show()图 18-16 显示了输出。

图 18-16
圆形分格统计图表
您也可以使用地毯图创建 KDE 图,但是对于我们在此示例中使用的数据,这可能没有太大意义。
sns.set_theme(style="ticks")
sns.kdeplot(x=y1)
sns.rugplot(x=y1)
plt.show()图 18-17 显示了输出。

图 18-17
KDE 绘图
创建动物疾病数据的可视化
您也可以为其他真实数据集创建可视化效果。让我们为动物疾病数据创建可视化。让我们首先从一个在线知识库中阅读它。
df = pd.read_csv("https://github.com/Kesterchia/Global-animal-diseases/blob/main/Data/Outbreak_240817.csv?raw=True")让我们看看前五名的记录。
df.head()图 18-18 显示了输出。

图 18-18
动物疾病数据
让我们按如下方式获取有关这些列的信息:
df.info()输出如下所示:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 17008 entries, 0 to 17007
Data columns (total 24 columns):# Column Non-Null Count Dtype
--- ------ -------------- -----0 Id 17008 non-null int641 source 17008 non-null object2 latitude 17008 non-null float643 longitude 17008 non-null float644 region 17008 non-null object5 country 17008 non-null object6 admin1 17008 non-null object7 localityName 17008 non-null object8 localityQuality 17008 non-null object9 observationDate 16506 non-null object10 reportingDate 17008 non-null object11 status 17008 non-null object12 disease 17008 non-null object13 serotypes 10067 non-null object14 speciesDescription 15360 non-null object15 sumAtRisk 9757 non-null float6416 sumCases 14535 non-null float6417 sumDeaths 14168 non-null float6418 sumDestroyed 13005 non-null float6419 sumSlaughtered 12235 non-null float6420 humansGenderDesc 360 non-null object21 humansAge 1068 non-null float6422 humansAffected 1417 non-null float6423 humansDeaths 451 non-null float64
dtypes: float64(10), int64(1), object(13)
memory usage: 3.1+ MB让我们对列country执行“分组”操作,并计算所有案例的总和,如下所示:
df2 = pd.DataFrame(df.groupby('country').sum('sumCases')['sumCases'])现在我们来排序选出十大案例。
df3 = df2.sort_values(by='sumCases', ascending = False).head(10)让我们使用以下代码绘制一个条形图:
df3.plot.bar()
plt.xticks(rotation=90)
plt.show()图 18-19 显示了输出。

图 18-19
条形图
您可以将索引转换为列,如下所示:
df3.reset_index(level=0, inplace=True)
df3输出如下所示:
country sumCases
0 Italy 846756.0
1 Iraq 590049.0
2 Bulgaria 453353.0
3 China 370357.0
4 Taiwan (Province of China) 296268.0
5 Egypt 284449.0
6 Iran (Islamic Republic of) 225798.0
7 Nigeria 203688.0
8 Germany 133425.0
9 Republic of Korea 117018.0我们做一个饼状图如下:
plt.pie(df3['sumCases'],labels=df3['country'])
plt.title('Death Toll')
plt.show()图 18-20 显示了输出。

图 18-20
圆形分格统计图表
您可以使用 Seaborn 创建更加美观的条形图,如下所示:
sns.barplot(x='country',y='sumCases',data=df3)
plt.xticks(rotation=90)
plt.show()图 18-21 显示了输出。

图 18-21
带 Seaborn 的条形图
您刚刚学会了可视化现实生活中的动物疾病数据。
摘要
在本章中,您探索了 Seaborn 数据可视化库的更多功能,它是科学 Python 生态系统的一部分。您还学习了如何将真实数据导入 Jupyter 笔记本。您使用了 Matplotlib 和 Seaborn 库来可视化数据。
如你所知,这是本书的最后一章。虽然我们非常详细地探讨了 Matplotlib,但我们只是触及了大量知识和编程 API 的皮毛。现在,您已经掌握了自己进一步探索 Matplotlib 和其他数据可视化库的知识。Python 有许多科学数据的数据可视化库。示例包括 Plotly、Altair 和 Cartopy。掌握了数据可视化的基础知识,就可以愉快地继续深入数据科学和可视化的旅程了!