大家好,我是Python进阶者。
一、前言
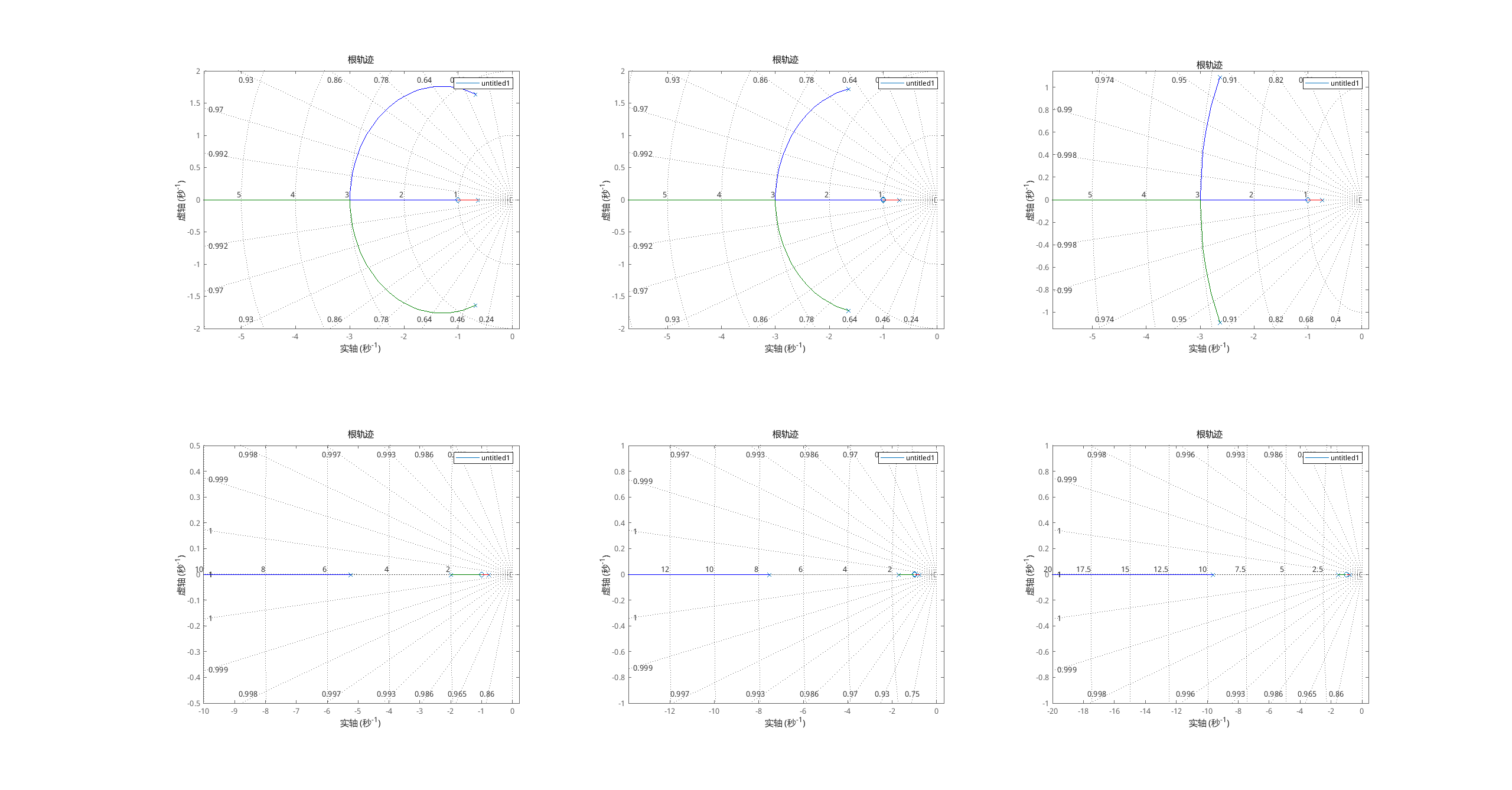
前几天在Python白银交流群【沐子山树】问了一个Python网络爬虫的问题,问题如下:爬取同样内容,xpath方法会比bs4要慢很多吗?
二、实现过程
这里【Kimi】给了个思路如下:
爬取网页内容时,使用XPath和BeautifulSoup(bs4)这两种方法的速度差异通常不会特别显著,但可能会有一些小的差异,具体取决于多种因素:
解析器效率:BeautifulSoup 使用的解析器(如lxml或html.parser)可能在某些情况下比XPath解析器(如xml.etree.ElementTree)更快。
查询复杂度:如果XPath查询非常复杂,可能会比BeautifulSoup的搜索方法慢一些。BeautifulSoup提供了一些方便的搜索方法,如 .find() 和 .find_all() ,这些方法在处理复杂的HTML结构时可能更直观。
数据结构:BeautifulSoup将HTML文档转换成一个树形结构,这使得导航和搜索变得相对简单。而XPath需要解析整个文档,然后根据路径表达式进行搜索。
编程语言:BeautifulSoup是Python的一个库,而XPath是XML路径语言,通常在Python中使用时需要依赖于xml库。不同库的实现效率可能会有所不同。
使用场景:对于简单的HTML文档,两者的速度差异可能微乎其微。但对于大型或复杂的HTML文档,BeautifulSoup可能因为其易用性和直观性而更有优势。
个人偏好和熟悉度:开发者对工具的熟悉程度也会影响开发速度。如果开发者对BeautifulSoup非常熟悉,可能会更快地编写出高效的代码。
总的来说,两者在速度上的差异通常不会是决定性因素。选择哪种方法更多地取决于个人偏好、项目需求以及对特定库的熟悉程度。如果你对XPath非常熟悉并且需要处理的HTML结构相对简单,使用XPath也是一个不错的选择。相反,如果你更熟悉Python和BeautifulSoup,并且需要处理更复杂的HTML文档,那么BeautifulSoup可能是更好的选择。
后来粉丝【沐子山树】继续问到:xpath出来的是列表,还要进行一下join,确实麻烦好多,不如BS4的find和find_all简单粗暴。
【瑜亮老师】补充道:find_all出来不也是列表?其实二者都是很好用的,bs比xpath最优势的地方在于:对不规范页面的解析上。
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!

三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python正则表达式的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【沐子山树】提出的问题,感谢【Kimi】、【瑜亮老师】给出的思路,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。