第2章 模型评估与选择
2.1 经验误差与过拟合
错误率(error rate):分类错误的样本数占样本总数的比例称为错误率。
精度(accuracy):精度 = 1 - 错误率。
如果在m个样本中有a个样本分类错误,那么错误率,精度 = 1 - E。
学习器的实际预测输出与样本的真实输出之间的差异称为误差(error)。
学习器在训练集上的误差称为训练误差(training error)或经验误差(empirical error),在新样本上的误差称为泛化误差(generalization error)。
过拟合:学习器把训练样本学习的太好了,已经把训练样本自身的特点当做了所有潜在样本会存在的一般性质,会导致泛化性能下降,这种现象称为过拟合(overfitting)。
欠拟合:一般指对训练样本的一般性质尚未学好。
导致过拟合最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不大一般的特性都学到了,而过拟合通常是由于学习能力低下而造成的。
过拟合是无法避免的,我们所能做的只是“缓解”,或者说减小其风险。
2.2 评估方法
通常,我们使用一个测试集来测试学习器对新样本的判别能力,然后以测试集上的“测试误差”来作为泛化误差的近似。需要注意,测试集应与训练集互斥,即测试样本尽量不在训练集中出现或未在训练集中使用过。
当我们只有一个包含m个样例的数据集D,既要训练又要测试时,需要通过对D进行适当的处理,产生出训练集S和测试集T。以下介绍几种常见的划分方法:
2.2.1 留出法
留出法:直接将数据集D划分为两个互斥的集合,其中一个作为训练集S,另一个作为测试集T,保证S∩T=∅且S∪T=D。
注意:训练集与测试集的划分要尽可能保证数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。
如果从采样(sampling)的角度来看待数据集的划分过程,则保留类别比例的采样方法一般称为“分层采样”(stratified sampling)。
单次使用留出法得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值为留出法的评估结果。
例如:进行100次随机划分,每次产生一个训练集和测试集用于实验评估,100次会得到100个结果,而留出法的返回应当是这100个结果的平均。
常见做法是将大约2/3~4/5的样本用于训练,剩余样本用于测试。
2.2.2 交叉验证法
交叉验证法:将数据集D划分为k个大小相似的互斥子集,即D=D1∪D2∪…∪Dk,Di∩Dj=∅(i≠j)。每个子集Di都尽可能保持数据分布的一致性,即从D中分层采样得到。然后每次用k-1个子集的并集作为训练集,剩下的那个子集作为测试集,这样就可以得到k组训练/测试集,从而进行k次训练和测试,最终返回这k次测试的均值。
显然,交叉验证法评估结果的稳定性与保真性在很大程度上取决于k的取值,为了强调这一点,通常把交叉验证法称为k折交叉验证(k-fold cross validation)。k常取值:5,10,20。
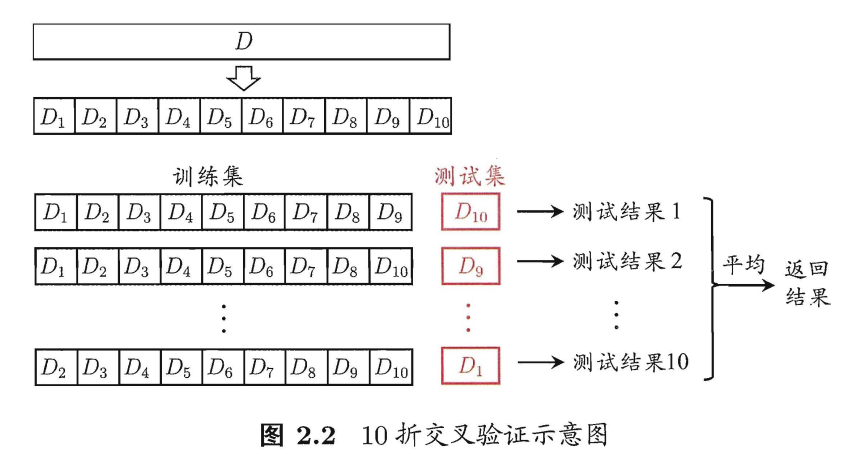
与留出法相似,将D划分为k个子集有多种方法,假设k折交叉验证要随机使用不同的划分重复p次,则最终评估结果是这p次k折交叉验证结果的均值,常见有10次10折交叉验证(训练100次)。
交叉验证法也存在一个特例:留一法(Leave-One-Out,简称LOO):假定数据集D中有m个样本,令k=m,则会发现,m个样本只有唯一的划分方法来划分为m个子集——每个子集一个样本,所以留一法的训练集与数据集D相比只差一个样本,故留一法中被实际评测的模型与期望评估的用D训练出的模型很相似,因此,留一法的评估结果往往被认为较准确。但是在数据集很大的时候,训练m个模型的开销明显是难以忍受的。故NLF定理在这里也同样适用。
2.2.3 自助法
在留出法和交叉验证法中,由于保留了一部分样本作为测试,所以实际评估的模型中所使用的训练集比D小,而我们希望评估的是D训练出的模型,所以这必然会引入一些因训练样本规模不同而导致的估计偏差。
自助法以自助采样为基础:给定包含m个样本的数据集D,我们对它进行采样产生数据集D’:每次从D中随机选一个样本,将其拷贝如D’中,再将其放回D中,重复m次,那么就可以得到包含m个样本的数据集D’。显然D中一部分样本会在D’中多次出现,而另一部分不出现,由一个简单的估计可以得到样本在m次采样中不被采到的概率如下:

于是我们可将D’当做训练集,D-D’作为测试集,这样,实际评估模型与期望评估模型都有m个训练样本,而我们仍然有数据总量1/3的样本用于测试,这样的测试结果,称为“包外估计”。
注意:自助法在数据量较少,难以有效划分训练集和测试集的时候很有用,然而自助法改变了初始数据分布,引入了估计偏差,故在数据量足够的时候,留出法和交叉验证法更常用一些。
2.2.4 调参与最终模型
给定包含m个样本的数据集D,在模型评估与选择过程中由于需要留出一部分数据进行评估测试,事实上我们只使用了一部分数据训练模型。因此,在模型选择完成后,学习算法和参数配置已选定,此时应该用数据集D重新训练模型。
需要注意的是,我们通常把学得模型在实际使用中遇到的数据称为测试数据,为了加以区分,模型评估与选择中用于评估测试的数据集称为验证集(validation set)。例如,在研究对比不同算法的泛化性能时,我们用测试集上的判别效果来估计泛化性能,而把训练数据另外划分为测试集和验证集,基于验证集上的性能来进行模型选择和调参。
2.3 性能度量
对学习器的泛化能力进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量(performance measure)。什么样的模型是好的,不仅取决于算法和数据,还决定于任务需求。要评估学习器f的性能,就需要把学习器预测结果f(x)同真实标记y进行比较。
2.3.1 错误率与精度
错误率:分类错误的样本数占样本总数的比例。
精度:分类正确的样本数占样本总数的比例。
对样例集D,分类错误率定义为:
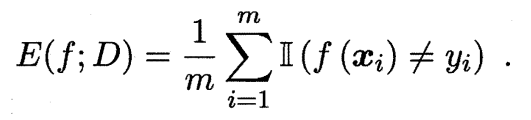
精度定义为:

更一般的,对于数据分布D和概率密度函数(• ),错误率和精度可分别描述为:
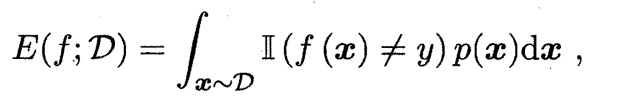

2.3.2 查准率,查全率和F1
信息检索中,我们经常会关心"检索出的信息中有多少比例是用户感兴趣的" 、“用户感兴趣的信息中有多少被检索出来了”,“查准率”(precision)与“查全率" (recall) 是更为适用于此类需求的性能度量。
对于二分类任务,可将样例根据其真实类别与学习器预测类别的组合划分为真正例、假正例、真反例与假反例四种情形。分别对应为TP、FP、TN、FN。TP+FP+TN+FN=样例总数。
- TP:被模型预测为正类的正样本(实际为正,预测也为正)。
- TN:被模型预测为负类的负样本(实际为负,预测也为负)。
- FP:被模型预测为正类的负样本(实际为负,预测为正)。
- FN:被模型预测为负类的正样本(实际为正,预测为负)。
查准率P(准确率)与查全率R(召回率)分别定义为:
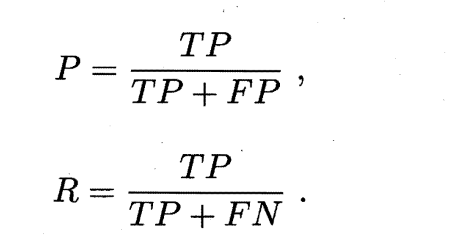
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率低。
以查准率为纵轴,查全率为横轴,可以得到查准率-查全率曲线,简称“P-R”曲线。
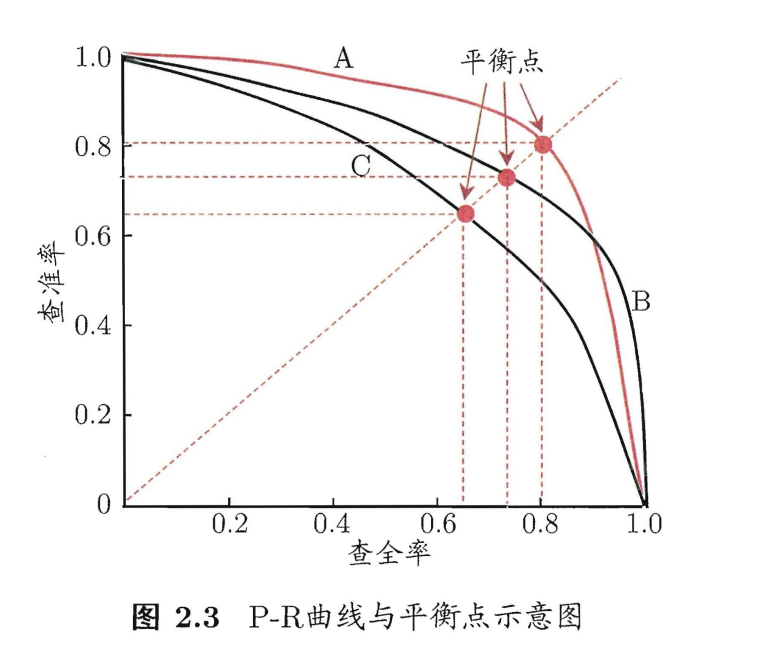
A,B,C三条曲线代表三个不同的学习器,而如果一个学习器的P-R曲线完全包裹了另一个学习器,则认为前者性能优于后者,但是如果出现图中A,B曲线这种情况,出现交点时,就需要引入平衡点(Break-Event Point, BEP)来度量学习器的优劣。平衡点是查准率=查全率时的取值,图中A点平衡点高于B点,故可认为学习器A优于学习器B。
但BEP太过于简化,更常用的是F1度量:

为了表达我们对查准率/查全率的不同偏好,在这里引入F1度量的一般形式:
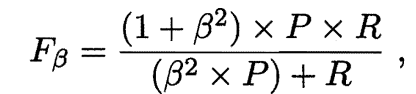
其中β>0度量了查全率对查准率的相对重要性。β=1时,退化为标准的F1;β<1时,认为查准率有更大影响;β>1时认为查全率有更大影响。
2.3.3 ROC与AUC
很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与一个分类阈值进行比较,若大于阈值则分为正类,否则为反类。实际上,根据这个实值或概率预测结果,可将测试样本进行排序,“最可能”是正例的排在前面,“最不可能”是正例的排在后面。排序本身的质量好坏,体现了学习器在不同任务下的“期望泛化性能”的好坏,ROC曲线则是从这个角度出发研究学习器泛化性能的有力工具。
ROC曲线的纵轴是“真正例率”(True Positive Rate, TPR),横轴是“假正例率”(False Positive Rate, FPR),两者定义如下:
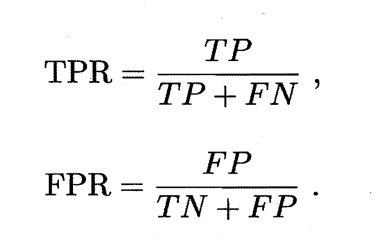
进行学习器性能的比较时,与P-R图相似,若一个学习器的ROC曲线被另一个完全包裹,则可断言后者性能优于前者。若两个ROC曲线发生交叉,此时若要比较两者学习器性能的优劣,较为合理的判据是比较ROC曲线下的面积,即AUC(Area Under ROC Curve)。如图所示:
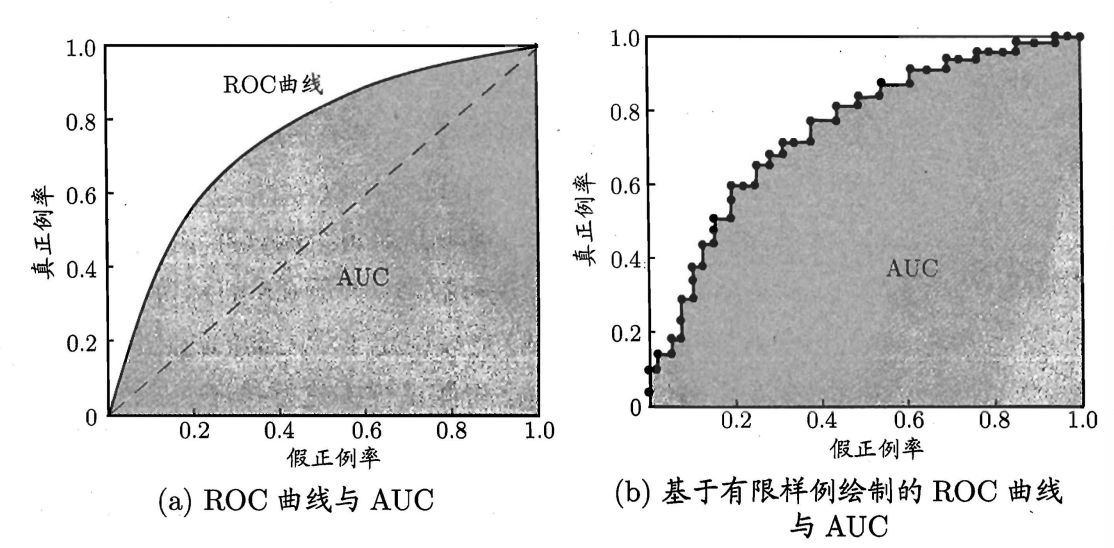
对角线对应于随机猜测模型,而点(0,1)则对应于将所有正例都排在反例之前。
2.3.4 代价敏感错误率与代价曲线
在现实中存在这样一类问题:不同类型的错误所造成的后果不同。为了权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价”(unequal cost)。
以二分类任务为例,可以根据任务的领域知识设定一个“代价矩阵”(cost matrix)。其中costij表示将第i类样本分为第j类样本所付出的代价。一般来说,costii=0;若将第0类判别为第1类所造成的损失更大,则cost01>cost10;损失程度相差越大,则cost01与cost~10差别越大。
注意:一般情况下着重的是代价的比值而非代价的绝对值,例如cost01:cost10=5:1与50:10所起效果相同。
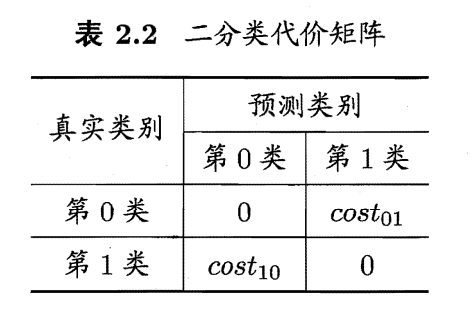
所以,在代价不均的情况下,我们所希望的不再是简单的最小化错误次数,而是最小化“总体代价”,例如:若cost01:cost10=6:1,那么将第0类错分到第1类所造成的代价(或者说损失)是把第1类错分到第0类所造成的代价的6倍,如果仅看错误次数,那么就会误认为m次错分第0类与m次错分第1类造成的损失是相同的,而实际上这两类大不相同。
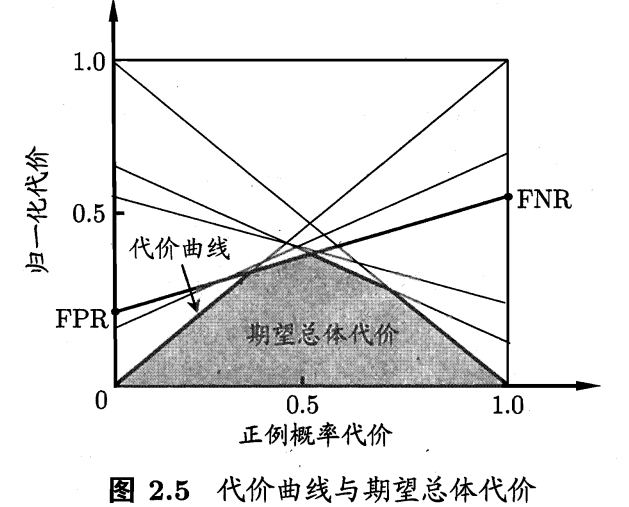
在非均等代价的情况下,ROC曲线将不能直接反映出学习器的期望总体代价,而“代价曲线”(cost curve)则可达到这个目的,代价曲线的横轴是取值为[0,1]的正例概率代价:
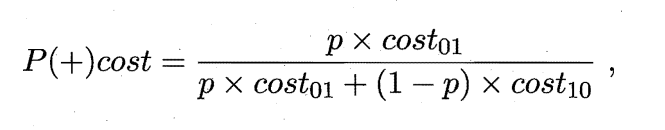
其中p是样例为正例的概率;纵轴是取值为[0,1]的归一化代价。

规范化:将不同变化范围的位映射到相同的固定范围中,常见的是[0,1]。此时亦称"归一化"。
在上式中,FPR为之前定义的假正例率,FNR=1-TPR是假反例率。
2.4 比较检验
机器学习中性能比较这件事要比大家想象的复杂得多.这里面涉及几个重要因素:首先,我们希望比较的是泛化性能,然而通过实验评估方法我们获得的是测试集上的性能,两者的对比结果可能未必相同;第二,测试集上的性能与测试集本身的选择有很大关系,且不论使用不同大小的测试集会得到不同的结果,即使用相同大小的测试集,若包含的测试样例不同,测试结果也会有不同;第三,很多机器学习算法本身有一定的随机性,即便用相同的参数设置在同一个测试集上多次运行,其结果也会有不同。那么,有没有适当的方法对学习器的性能进行比较呢?
统计假设检验(hypothesis test)为我们进行学习器性能比较提供了重要依据。基于假设检验结果我们可以推断出,如果在测试集上观察到学习器A比B好,则A的泛化性能是否在统计意义上优于B,以及这个结论的把握有多少。本书默认以错误率为性能度量,用 ε 表示。此处错误率指泛化错误率
2.4.1 假设检验
在实际问题中,我们无法获知泛化错误率,但是可以知道,测试错误率与泛化错误率相差较小,故在这里可以用测试错误率εt来推导泛化错误率ε。
泛化错误率为ε的学习器在一个样本上犯错的概率是ε;测试错误率εt意味着在m个样本中恰有 个样本被误分类,可以估算出泛化错误率为ε的学习器恰将个样本误分类的概率如下式所示:
个样本被误分类,可以估算出泛化错误率为ε的学习器恰将个样本误分类的概率如下式所示:

这也表达了在包含m个样本的测试集上,泛化错误率为ε的学习器被测得测试错误率为εt的概率。
上式对ε求偏导可知,该概率在ε = εt时取得最大值,符合二项分布。如图所示,若ε=0.3,则10个样本中测得3个被误分类的概率最大:

此处α为显著度,1-α为置信度。
更一般的,考虑假设ε<=ε0,则在1-α的概率内所能观测到的最大错误率如下式计算,直观的来看,对应于图中非阴影部分的范围。

此时若εt小于临界值,则可得出结论:能以1-α的置信度认为,学习器的泛化错误率不大于ε0,反之亦然。
在很多时候我们并非仅做一次留出法估计,而是多次估计,这样会得到多个测试错误率ε1…εk,则平均错误率μ和方差σ2为:
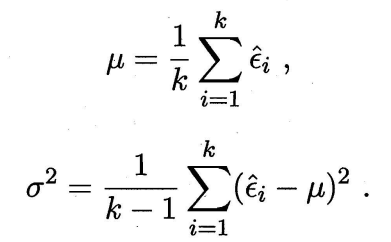
考虑到这k个测试错误率都可看作错误率ε0的独立采用,则变量:

服从自由度为k-1的t分布,如图:
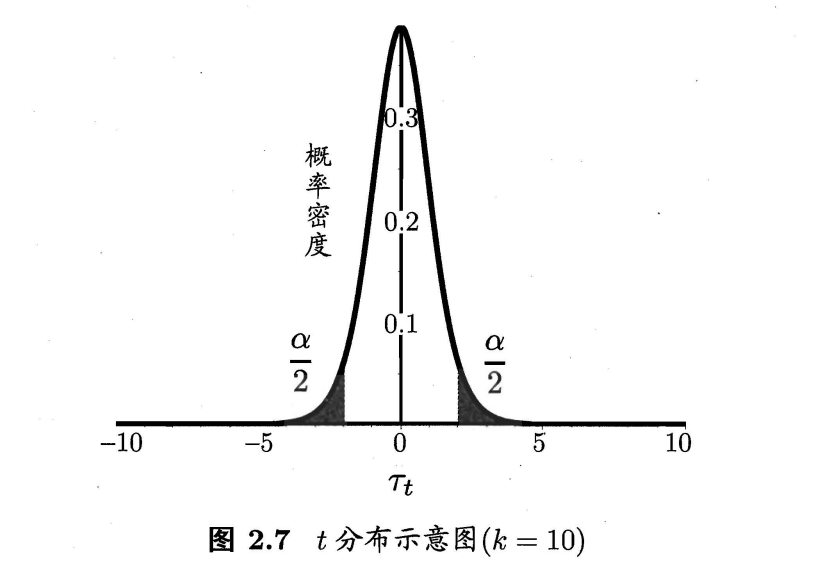
假设阴影部分的面积为(-∞,t-α/2]和[tα/2,∞],则若上方变量位于临界值范围[t-α/2,tα/2]内,则可认为泛化错误率为ε0,置信度为1-α。α常用取值为0.05,0.1。以下是一些常用临界值:

2.4.2 交叉验证t检验
具体来说,对k折交叉验证产生的k对测试错误率:先对每对结果求;若两个学习器性能相同,则差值均值应为零.因此,可根据差值△1,2.,..△k来对“学习器A与B性能相同”这个假设做t检验,计算出差值的均值μ和方差σ2,在显著度a下,若变量
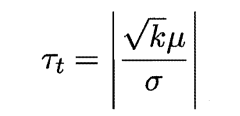
小于临界值t(a/2),k-1,则假设不能被拒绝,即认为两个学习器的性能没有显著差别;否则可认为两个学习器的性能有显著差别,且平均错误率较小的那个学习器性能较优.这里t(a/2), k-1是自由度为k-1的t分布上尾部累积分布为a/2的临界值。
2.4.3 McNemar检验
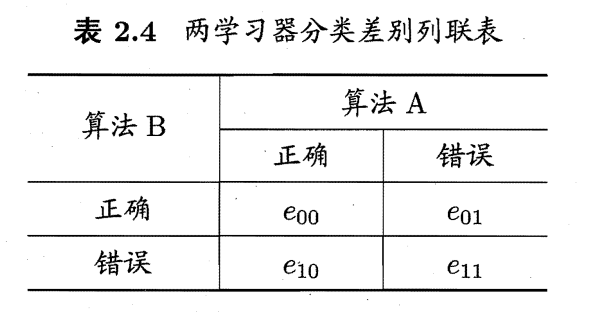
对二分类问题,使用留出法不仅可估计出学习器A 和B 的测试错误率,还可获得两学习器分类结果的差别,即两者都正确、都错误、一个正确另一个错误的样本数,如“列联表“:
若我们做的假设是两学习器性能相同,则应有e01= e10,那么变量|eo1一e1o|应当服从正态分布,且均值为1,方差为e01 + e10. 因此变量
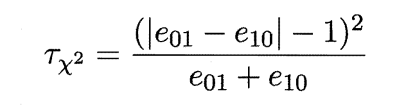
服从自由度为1的卡方分布,具体显著度判别方法同t分布。
2.4.4 Friedman检验与Nemenyi后续检验
在很多时候,我们会在一组数据集上对多个算法进行比较。当有多个算法参与比较时,一种做法是在每个数据集上分别列出两两比较的结果,而在两两比较时可使用前述方法;另一种方法更为直接,即使用基于算法排序的Friedman 检验。
常用的有Nemenyi后续检验,Nemenyi检验计算出平均序值差别的临界值域
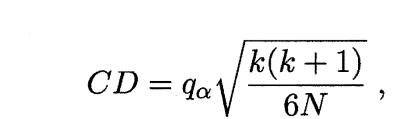
2.5 偏差与方差
对学习算法除了通过实验估计其泛化性能,人们往往还想了解它为什么有这样的性能,此处用“偏差-方差分解”可以较好地解释。偏分-方差分解试图对学习算法的期望泛化错误率进行拆解。
学习算法的期望预测为:

使用样本数不同的训练集产生的方差为:
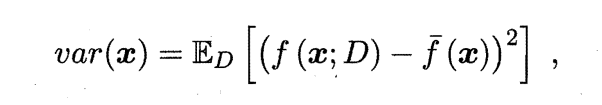
噪声为:

期望输出与真实标记的差别称为偏差(bias),即:
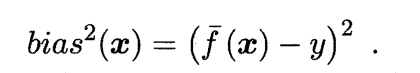
经过推导可知:
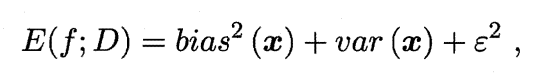
也就是说,泛化误差可以分解为偏差,方差与噪声之和。
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
偏差-方差分解说明,泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。
一般来说,偏差与方差是有冲突的,这称为偏差-方差窘境,如下图。
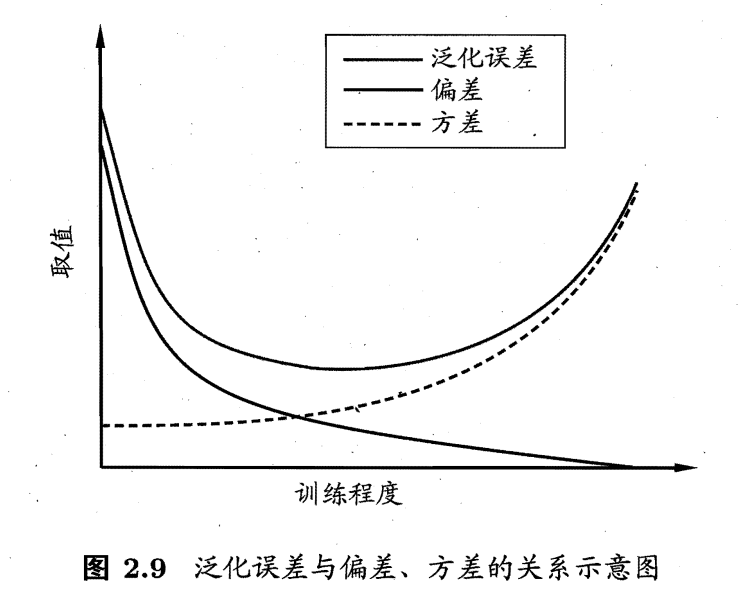
给定学习任务,假定我们能控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学到了,则将发生过拟合.