1. 为什么要使用MQ,使用场景是什么
- 异步 : 减少请求响应时间,实现非核心流程异步化 (架构设计原则,能异步就不要同步)
- 解耦:屏蔽异构平台的细节,生产者消费者可自行扩展修改系统能力只需遵循消息约束,生产者消费者不受对方影响
- 流量削峰:消息堆积能力,消息保存在MQ中, 消费端以稳定的速率拉取消息消费,控制流量
- 复用,可靠:一次发送,多次消费;如发送消息时接收者不可用,消息队列会持久化消息,直到成功传递
2. 选型理由
| 特性 | Kafka | RocketMQ | RabbitMQ | ActiveMQ |
|---|---|---|---|---|
| 开发语言 | Scala | Java | erlang | Java |
| 单机吞吐量 | 10w级 | 10w级 | 万级 | 万级 |
| 高可用 | 分布式架构 | 分布式架构 | 主从架构 | 主从架构 |
| 时效性 | ms级 | ms级 | us级 | ms级 |
| 功能 | 只支持主要MQ功能, 没有消息查询,消息回溯功能, 大数据领域应用广 |
MQ功能完备,扩展性好, 支持消息查询,延时消息,顺序消息等 |
并发能力很强,性能好,延时低 | 成熟的社区产品,文档丰富 |
3. RocketMQ的工作流程是什么?
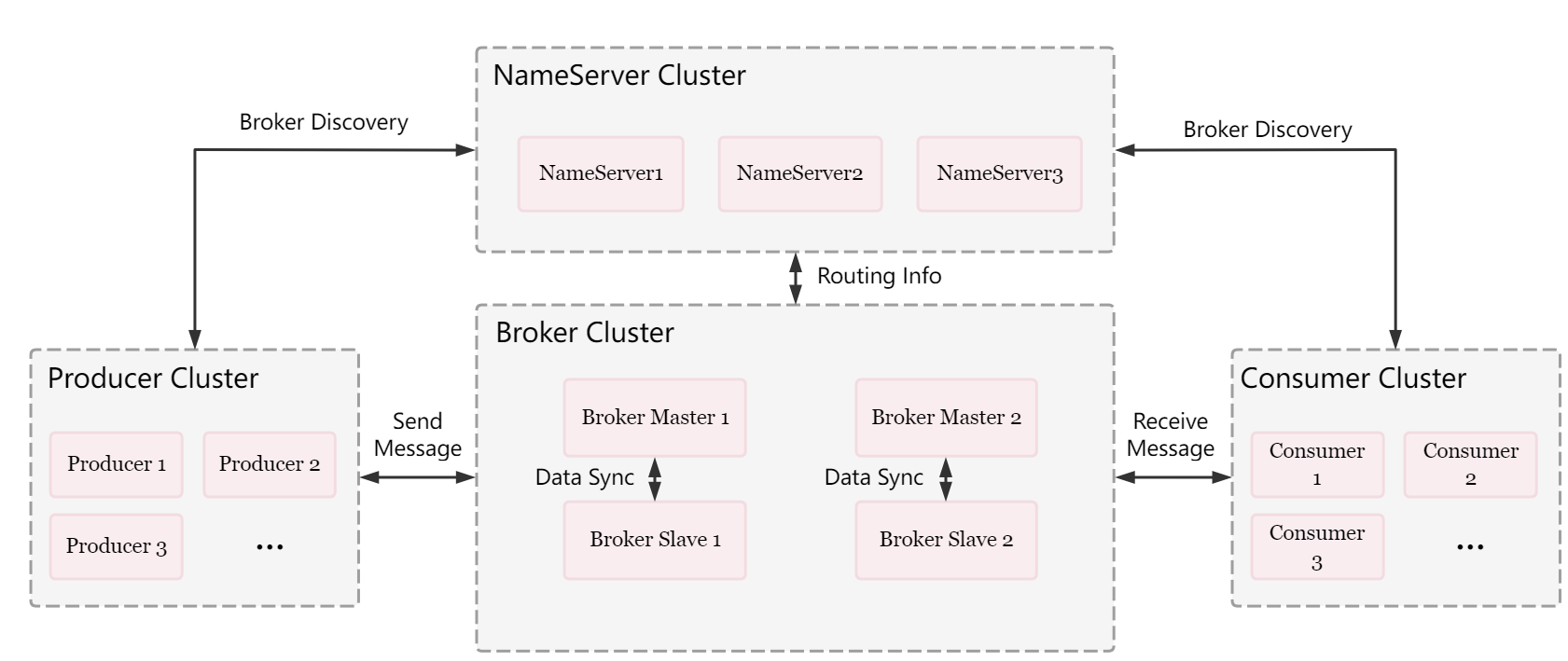
-
NameServer : Topic路由注册中心
- 管理Broker集群,注册发现,心跳检测
- 管理路由信息,如TopicA在哪些broker上
- 集群部署,每个NameServer都有完整的信息
-
Broker
- Store Service & Index Service 消息存储,消息查询(索引服务)
- Client Manager : 管理客户端(Producer&Consumer),维护Consumer的Topic订阅信息
- Remoting Module: 通信模块
- HA Service: 高可用服务,提供Master和Slave的数据同步功能
-
工作流程
- NameServer启动
- Broker启动,跟所有NameServer保持长连接,发送心跳包(IP+端口+Topic信息)
- 创建Topic,并指定存在哪些Broker上
- Producer发消息:先跟NameServer中的一台建立长链接,并得知该Topic存在哪些Broker上,轮询队列列表选择一个队列,与该队列所在的Broker建立长连接发送消息。
- Consumer消费:和4相同
4. Broker如何保存数据
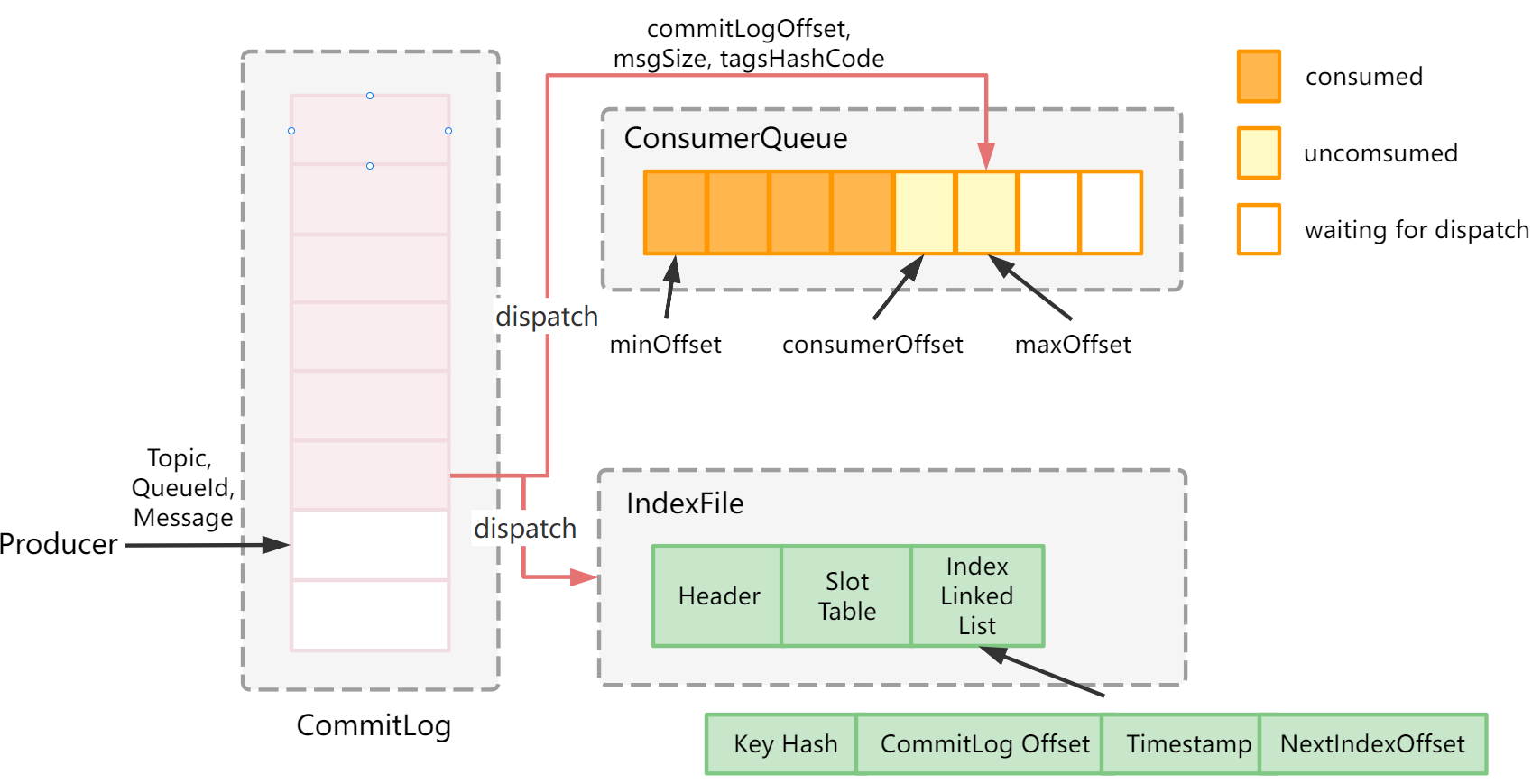
-
Broker的目录构成:
-
|-- commitlog : 消息主体和元数据,单个文件默认为1G,文件名为起始偏移量前面补0,消息顺序写入
-
|-- consumequeue:消息消费队列(消费的索引文件),提高消息消费性能,保存了指定Topic下队列消息在Commitlog中的起始物理偏移量,消息大小和消息tag的hashcode
- |-- topic
- |-- queue
- |-- file 每个文件由30W条目构成,每个条目包括8字节offset,4字节消息长度,8字节tag HashCode
- |-- queue
- |-- topic
-
|-- index 提供了通过key或时间区间查询消息的方法,indexFile文件名是创建的时间戳,底层存储设计为在文件系统中实现HashMap,索引底层为hash索引
- |-- 20200922025600444
- ...
-
5. RocketMQ读写速度为什么这么快
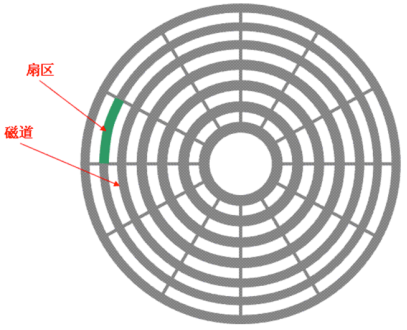
- 写Commitlog是顺序写入
影响硬盘性能的因素:寻道时间(将读写磁头移动到正确的磁道上所需要的时间),旋转延迟,数据传输时间;随机读写,需要将磁头移动至正确的磁道上,磁头需要不停移动
-
PageCache和MappedByteBuffer
PageCache 页缓存: 对于数据的写入,OS会先写入Cache,然后通过异步的方式由pdflush内核线程将Cache内的数据刷盘到物理磁盘; 对于数据读取,如果第一次读文件未命中PageCache,OS从物理磁盘读文件时,会顺序对相邻块数据文件进行预读取(空间局部性原理)
- ConsumeQueue数据存储得很少,并且是顺序读取,在PageCache的机制的预读下,文件读性能几乎接近读内存
- CommitLog读消息时,会产生很多随机访问读取,影响性能,需要合适的系统IO调度算法来提升性能(No Operation, CFQ, DeadLine, AS预测)
- MappedByteBuffer对文件的读写,零拷贝,(正因为需要使用内存映射机制,RocketMQ的文件存储都使用定长结构来存储,方便一次将整个文件映射至内存)
-
异步刷盘
- 异步刷盘,能充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高MQ的性能和吞吐量。
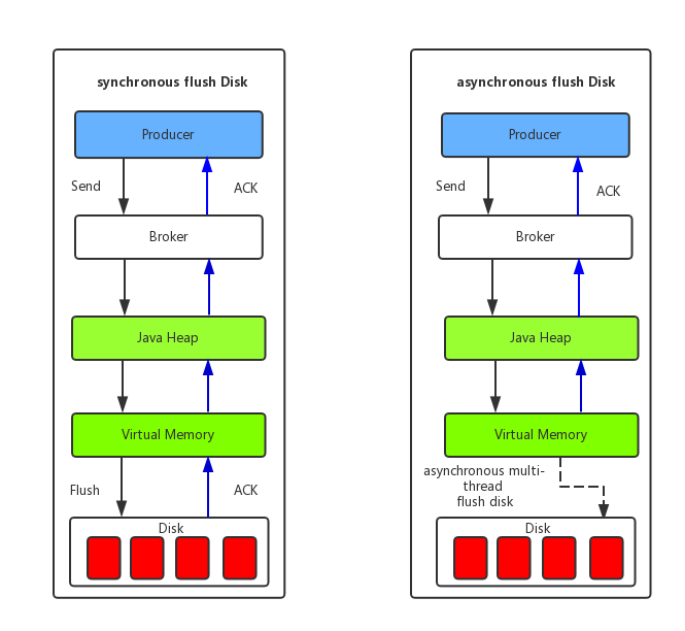
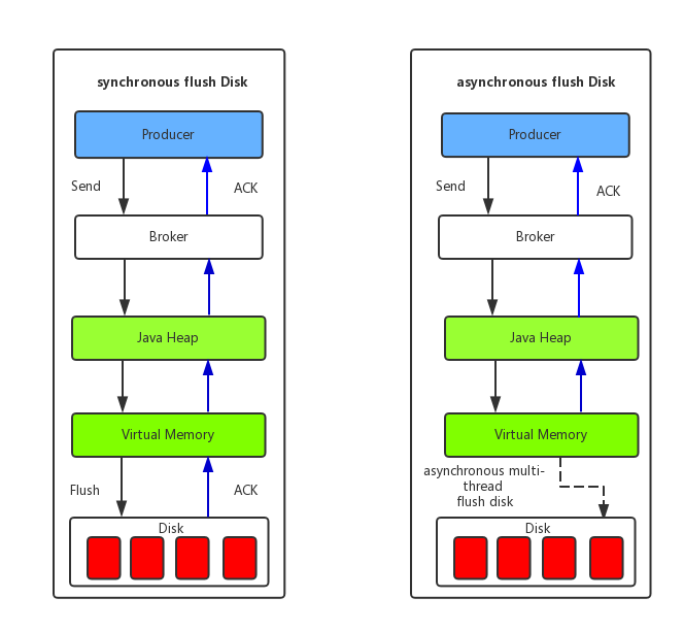
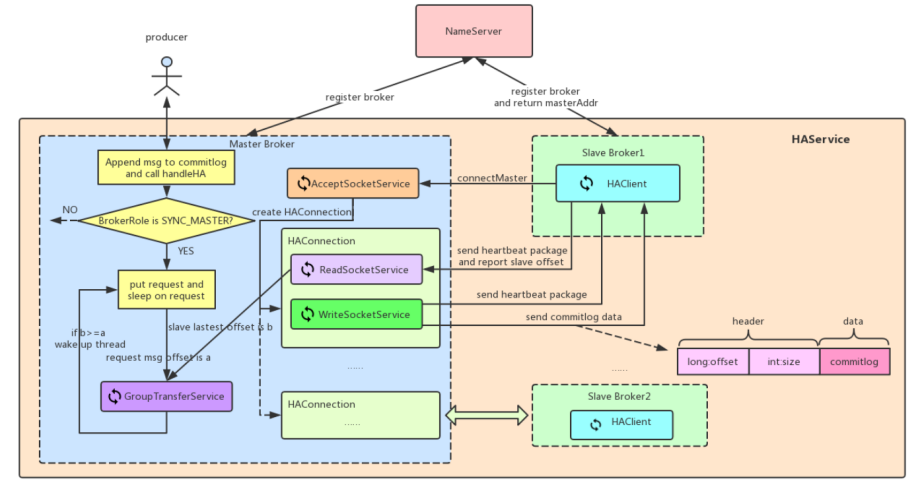
6. Master和Slave之间如何同步数据
- 需要同步的数据:
- CommitLog复制:Slave在同步commitlog时会唤醒ReputMessageService线程,根据commitLog文件内容进行构建consumequeue和indexFile信息 (?为什么要自己构建)
- 同步复制,效率损失,数据可靠;异步复制,效率高,数据可能不一致
MQ4.5版本前,master宕机,slave上不能接收producer生产的消息,但可以继续消费
4.5之后,可以根据RAFT算法,master宕机,选择一个副本节点作为master可以正常生产和消费
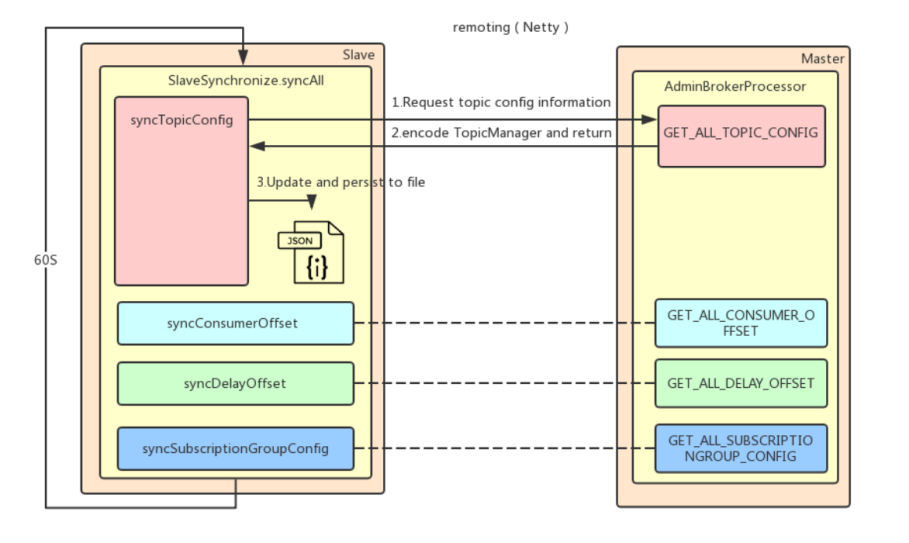
- Slave节点启一个线程,每隔10s进行一次同步
- 同步Topic信息
- 同步消费者偏移量
- 同步延迟消息偏移量
- 同步定于的消息组信息
7. RocketMQ是如何支持分布式事务消息
2PC和3PC
- 2PC使用两个roundtrip来达成新的共识或维持旧有的共识. 其局限性在于不能保证有节点永久性崩溃(fail-stop)的情况下算法能向前推进;
- 3PC扩展了2PC, 使用三个roundtrip达成共识. 其局限性在于不能保证在节点暂时性崩溃(fail-recover), 或是有网络划分的情况下, 共识依旧成立.
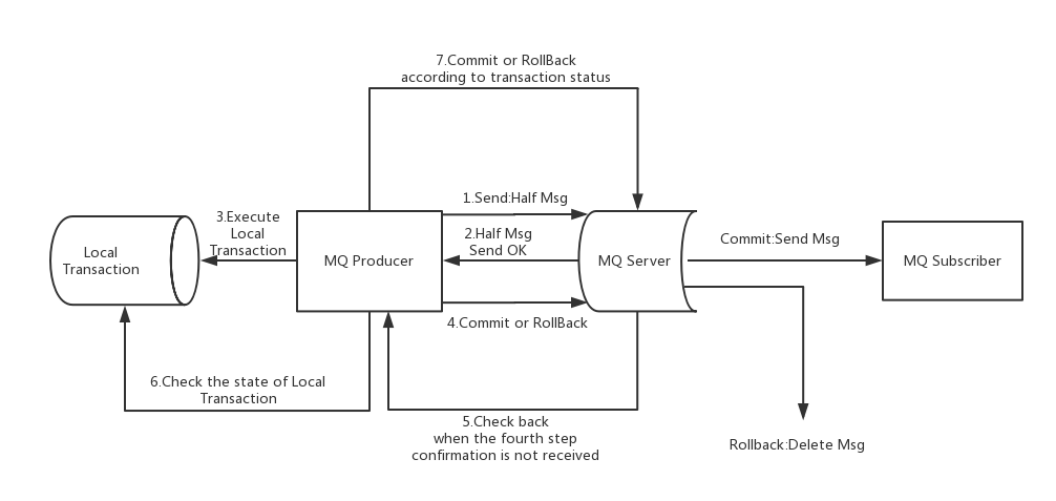
RocketMQ的分布式事务
-
2PC + 补偿逻辑
-
Propose阶段:
- coordinator向所有voter发送事务执行请求,并等待参与者反馈事务执行结果
- voter收到请求后,执行事务但不提交,并记录日志
- voter将自己事务的执行情况反馈给coordinator,同时阻塞等待协调者的后续指令
-
Commit阶段
- 所有voter都能回复并正常执行事务 -> 发起事务提交通知
- 一个或多个voter回复失败 -> 发起事务回滚
-
问题
- fail-stop
- 同步阻塞
- 数据不一致,第二阶段coordinator发出commit通知,但是网不好,部分voter收到了commit操作,另外一些voter还在阻塞,数据不一致
-
补偿流程
- 对没有Commit/Rollback的事务消息,从服务端进行一次回查,Producer收到回查消息,检查对应的本地事务状态,重新Commit和Rollback
- 用于解决消息Commit或者Rollback发生超时或者失败的情况
- 事务消息在一阶段对用户不可见,将自动备份至主题为RMQ_SYS_TRANS_HALF_TOPIC的消费队列,由于消费端没有订阅这个主题,就不会消费这个half msg, 然后RocketMQ会开启一个定时任务,从该Topic拉取消息进行消费,回查事务状态请求,来决定提交或者回滚
-
引入Op消息标志一个事务消息的状态,(RocketMQ无法真正删除一条消息,消息时顺序写入的)
-
在执行二阶段Commit操作时,利用了一阶段存储的消息内容,在二阶段恢复出一条完整的普通消息,走一遍消息写入的流程
OP消息
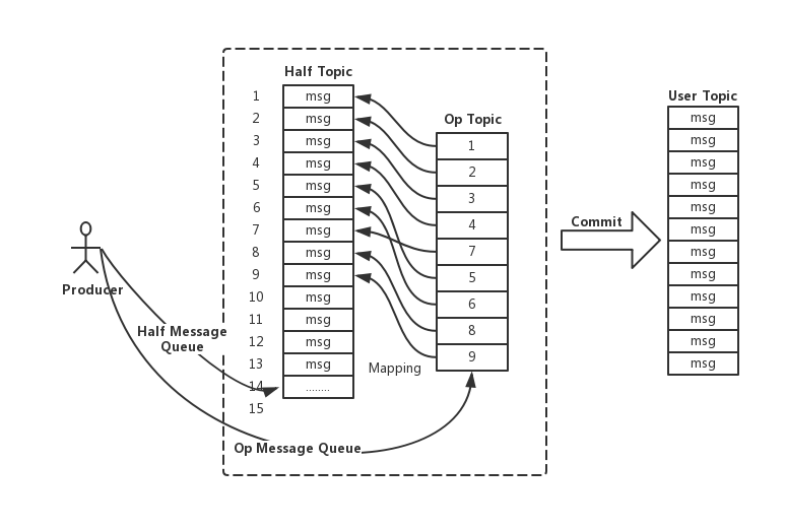
- Op消息的内容为对应的Half消息的存储的Offset,这样通过Op消息能索引到Half消息进行后续的回查
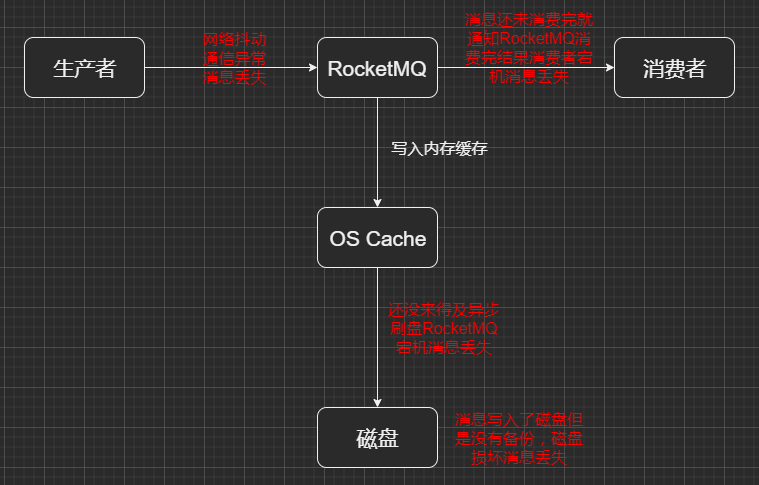
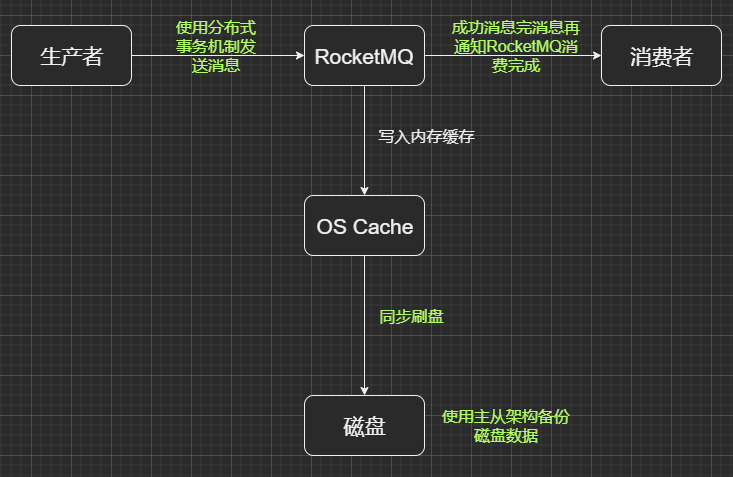
8. RocketMQ消息存在哪些丢失场景,怎么解决?
9. 消费消息的2种方式Pull与Push的区别
- Push: consumer把轮询过程封装了,并注册MessageListener监听器,收到消息后唤醒consumeMessage()来消费 - > 慢消费,消费堆积
- Pull: 取消息的过程是用户自己写的 -> 等待时间,消费延迟(?)
- 本质都是Pull, 即consumer轮询从broker拉消息
10. 如何解决消费速度慢的问题
- 提高消费并行度,增加Consumer实例、提高单个Consumer消费的并行线程,修改参数consumeThreadMin, consumeThreadMax实现
- 批量消费,设置consumeMessageBatchMaxSize,默认是1
- 路过非重要消息
- 优化每条消息消费过程,减少耗时操作,如DB,网络,文件操作等
11. 顺序消息
- 全局顺序,指定一个Topic,FIFO
- 分区顺序,指定一个Topic, 所有消息根据sharding key进行区块分区,FIFO;sharding key是顺序消息中用来区分不同分区的关键字段,
12. 延时消息
- 消息是指消息发送到broker后不会被立即消费,等待特定的时间投递给真正的topic
- broker有配置项messageDelayLevel,默认值为“1s,5s,10s,30s,1m,2m,3m,4m,5m,6m,7m,8m,9m,10m,20m,30m,1h,2h”
- level==0为非延迟消息
- 定时消息会暂存在名为SCHEDULE_TOPIC_XXXX的topic中,并根据delayTimeLevel存入特定的queue, queueId = delayTimeLevel - 1, 一个queue只存相同的延迟消息,broker会调度地消费SCHEDULE_TOPIC_XXX,将消息写入真实的topic
问题
1. 死信队列是什么?
消费客户端返回了CONSUMMER_SUCCESS才认为是成功,否则进行重试,重试会放到重试主题的队列 %RETRY%TOPIC, 默认重试16次,大概4小时,如果依然没有成功,就会进入死信队列。死信队列无法消费,需要人为处理。
2. rocketmq如何保证不重复消费?
rocketmq本身是存在重复投递给消费端的问题,这个要消费端自己保证幂等。
3. rocketmq 集群消费和广播消费分别是如何实现的?
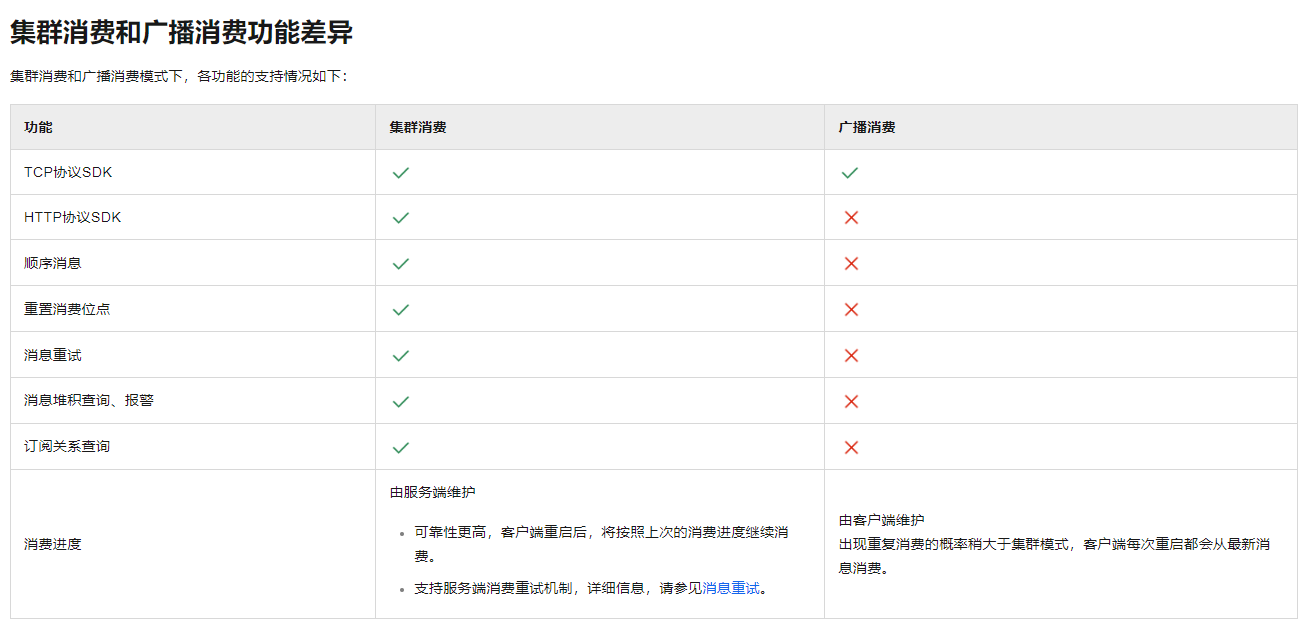

- 广播消费消费进度保存在消费端,因为每个消费端都会消费所有消息,他们进度不同
- 集群消费消费进度保存在broker,同一个消费只会被消费一次。消费进度会参与到消费负载均衡中,消费进度需要共享。
rebalance机制
一个topic下的多个queue在同一个consumer group中多个consumer间进行重新分配的过程,rebalance机制的前提是集群消费。
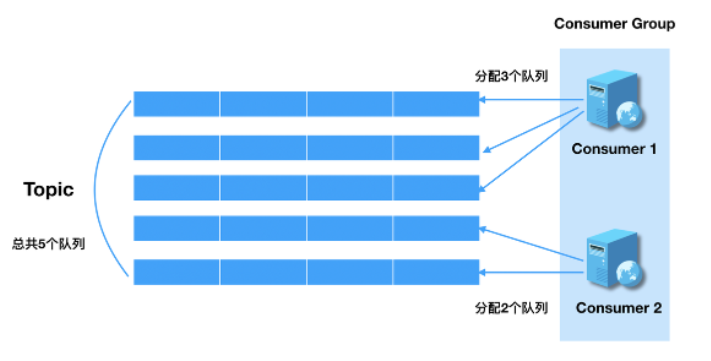
queue分配算法
- 平均消费
- 一致性hash
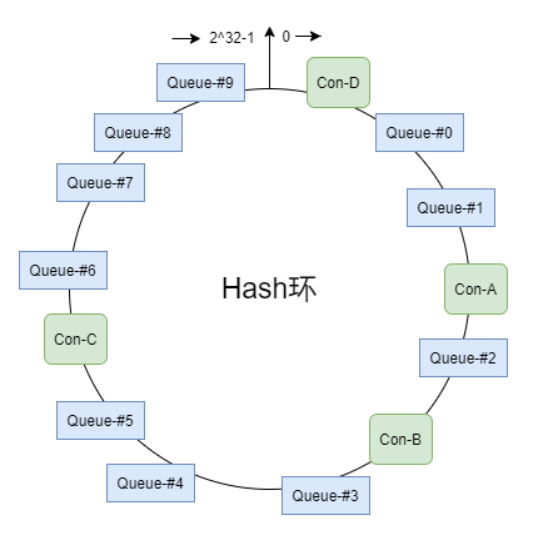
- 同机房策略
4. rocketmq和kafka对比
kafka可以海量堆积消息,性能会更好,producer端合并小消息,使用zk进行集群管理,配置管理,leader选举。