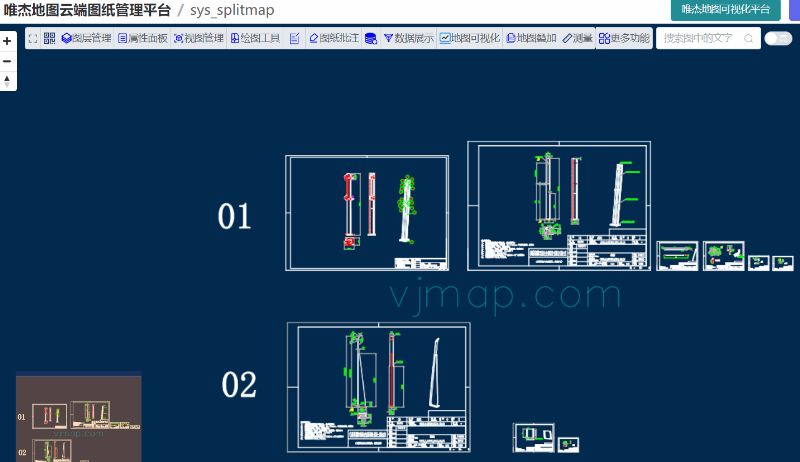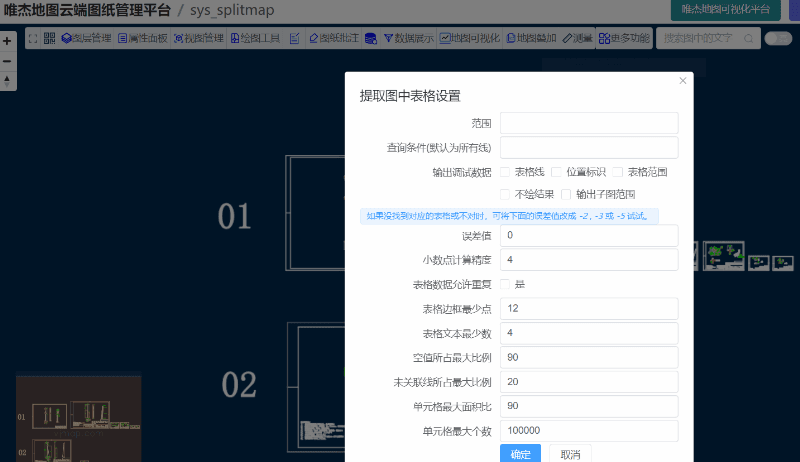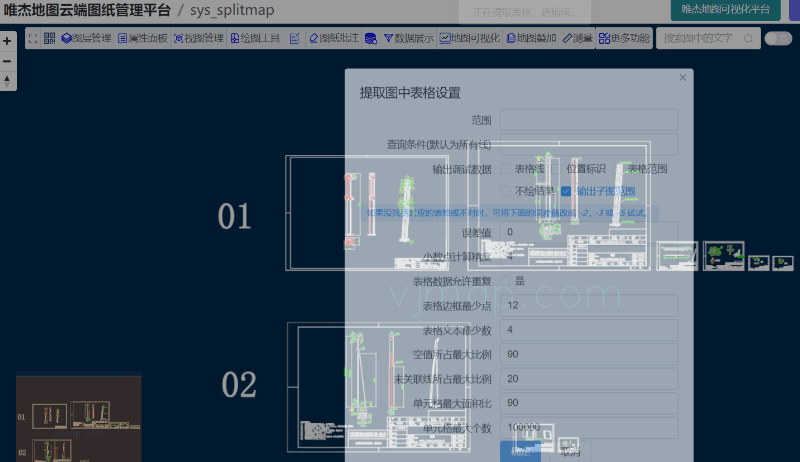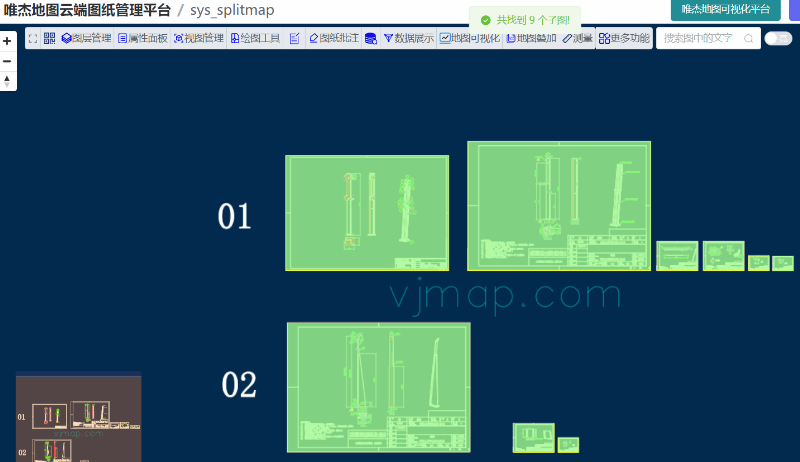
#include <stdio.h>
#include <cuda_runtime.h>// 128 x 128 ->
__global__ void mm(float* a, float* b, float* c) {// 8 x 8个方块,每个方块16x16extern __shared__ float buf[];float* a_local = buf;float* b_local = buf + 16*128;for(int i=0; i<8; i++) {a_local[threadIdx.x + i*16 + threadIdx.y*128] = a[threadIdx.x + i*16 + threadIdx.y*128 + blockIdx.y*128*16];b_local[(threadIdx.y + i*16)*16 + threadIdx.x] = b[(threadIdx.y + i*16)*128 + threadIdx.x + blockIdx.x*16];}__syncthreads();float tmp = 0.0f;for(int k=0; k<128; k++) tmp += a_local[threadIdx.y*128+k]*b_local[k*16+threadIdx.x];c[(blockIdx.y*16+threadIdx.y)*128+blockIdx.x*16+threadIdx.x] = tmp;
}#define CHECK_ERROR(expr) { \cudaError_t err = expr; \if(err != cudaSuccess) { \fprintf(stderr, "[Error] %s:%d %s\n", __FILE__, __LINE__, cudaGetErrorString(err)); \} \
}#define A(i,j) a[i*128+j]
#define B(i,j) b[i*128+j]
#define C(i,j) c[i*128+j]
#define G(i,j) golden[i*128+j]int main() {// int deviceId = 0;// CHECK_ERROR(cudaSetDevice(deviceId));constexpr size_t size = 128*128*sizeof(float);float* a = (float*)malloc(size);float* b = (float*)malloc(size);float* c = (float*)malloc(size);float* golden = (float*)malloc(size);// generate input data and goldenfor(int i=0; i<128; i++) {for(int j=0; j<128; j++) {A(i,j) = (float)(random()%1024);B(i,j) = (float)(random()%1024);}}for(int i=0; i<128; i++) {for(int j=0; j<128; j++) {G(i,j) = 0.0f;for(int k=0; k<128; k++) {G(i,j) += A(i,k)*B(k,j);}}}float *a_d, *b_d, *c_d;CHECK_ERROR(cudaMalloc((void**)&a_d, size));CHECK_ERROR(cudaMalloc((void**)&b_d, size));CHECK_ERROR(cudaMalloc((void**)&c_d, size));cudaStream_t stream;CHECK_ERROR( cudaStreamCreate(&stream) );CHECK_ERROR( cudaMemcpy(a_d, a, size, cudaMemcpyHostToDevice) );CHECK_ERROR( cudaMemcpy(b_d, b, size, cudaMemcpyHostToDevice) );mm<<<dim3(8,8,1), dim3(16, 16, 1), 16*128*2*4, stream>>>(a_d, b_d, c_d);{cudaError_t err = cudaGetLastError();if(err!=cudaSuccess) {fprintf(stderr, "[Error] %s:%d %s\n", __FILE__, __LINE__, cudaGetErrorString(err));}}CHECK_ERROR(cudaMemcpy(c, c_d, size, cudaMemcpyDeviceToHost));CHECK_ERROR( cudaStreamSynchronize(stream) );//check resultfloat res = 0.0f;for(int i=0; i<128; i++) for(int j=0; j<128; j++) res += fabs(G(i,j) - C(i,j));for(int i=0; i<10; i++) printf("golden[%d]: %f vs real[%d]: %f \n", i, golden[i], i, c[i]);if(res < 1.0e-2) printf("test pass!\n");else {printf("test fail! res = %f\n", res);}free(a); free(b); free(c); free(golden);cudaFree(a_d); cudaFree(b_d); cudaFree(c_d);return 0;
}采用8x8的block, 每个block中完成c矩阵中16x16
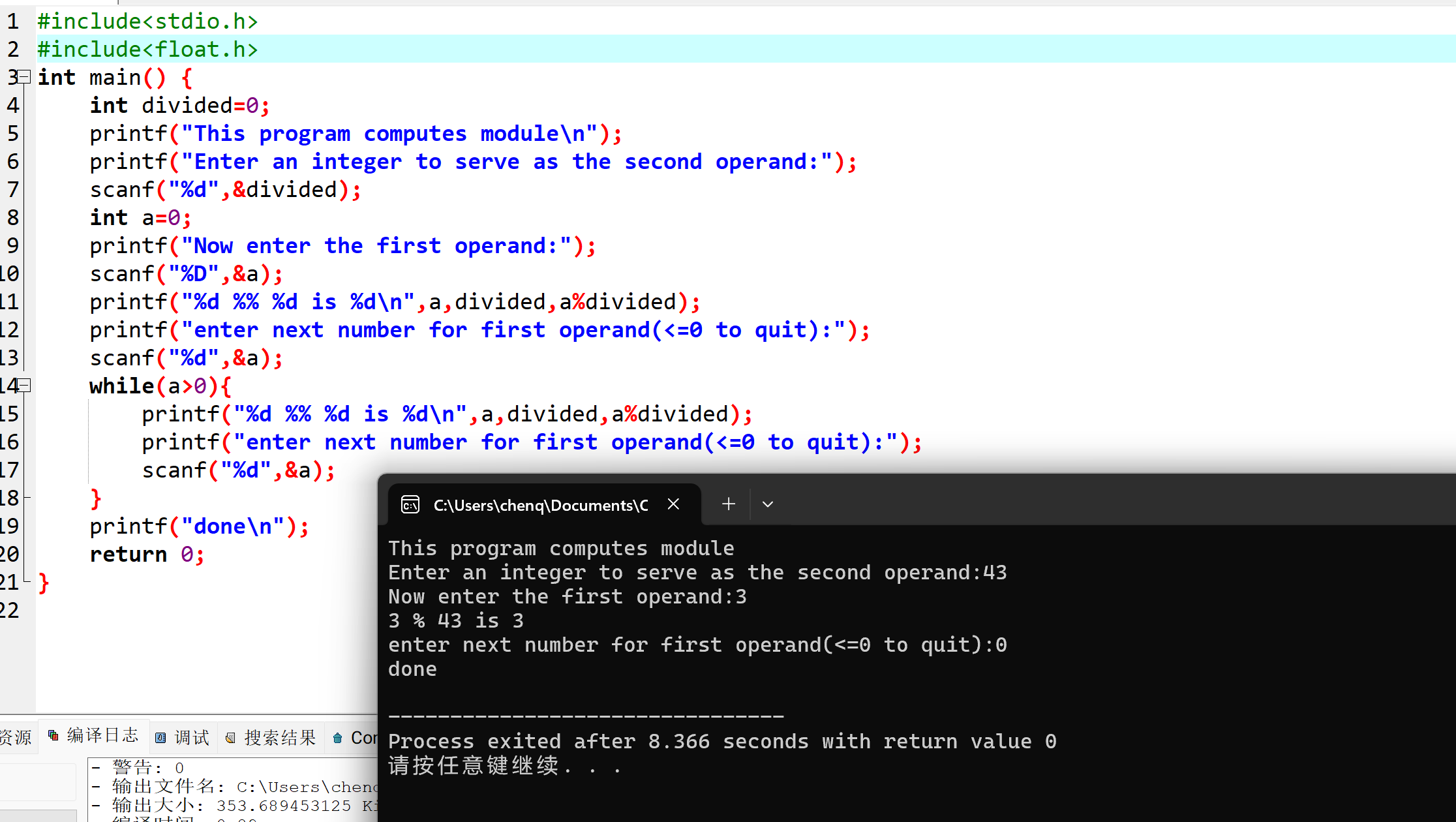
编译执行结果。
$ nvcc mmad.cu -Xptxas -v
$ ./a.out
golden[0]: 32589786.000000 vs real[0]: 32589786.000000
golden[1]: 38473160.000000 vs real[1]: 38473160.000000
golden[2]: 30227116.000000 vs real[2]: 30227116.000000
golden[3]: 28977550.000000 vs real[3]: 28977550.000000
golden[4]: 34897048.000000 vs real[4]: 34897048.000000
golden[5]: 36245064.000000 vs real[5]: 36245064.000000
golden[6]: 31798204.000000 vs real[6]: 31798204.000000
golden[7]: 30707464.000000 vs real[7]: 30707464.000000
golden[8]: 34893612.000000 vs real[8]: 34893612.000000
golden[9]: 36354168.000000 vs real[9]: 36354168.000000
test pass!