作业①
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
代码与运行结果
代码:
#导入所需要的库
import requests
from bs4 import BeautifulSoup
import pandas as pd#爬取网址的网址
url = "https://www.shanghairanking.cn/rankings/bcur/2024"
#发送请求
response = requests.get(url)
#设置编码格式
response.encoding = 'utf-8'
#获取相应内容
html = response.text#定义存储形式为字典
all = {"school": {}, "province": {}, "type": {}, "score": {}}#定义beautifulSoup对象
soup = BeautifulSoup(html, "html.parser")
#找到内容存储主体部分
body = soup.find(attrs={"class": "rk-table"}).find("tbody").find_all("tr")#定义获取到的信息在all中的存储位置
count = 0#按排名顺序遍历主体部分,获取到每一个大学信息的信息存储容器
for info in body:# 获取学校名字school_names = soup.find_all("span", attrs={"class": "name-cn"})# 处理数据并保存name_count = 0for name in school_names:all["school"][name_count] = name.text.strip().replace(" ", "").replace("\n", "")name_count += 1#因为省份等信息存储在td中,所以通过寻找td来解析获取到的数据td = info.find_all("td")province = td[2].text.strip().replace(" ", "").replace("\n", "")all["province"][count] = provincetype_ = td[3].text.strip().replace(" ", "").replace("\n", "")all["type"][count] = type_score = td[4].text.strip().replace(" ", "").replace("\n", "")all["score"][count] = score#位置加一,以便后面获取到的信息依次存储count += 1# 将字典转换为 pandas DataFrame
df = pd.DataFrame({'排名': range(1, len(all['school']) + 1),'学校名字': [all['school'][i] for i in range(len(all['school']))],'省市': [all['province'][i] for i in range(len(all['province']))],'学校类型': [all['type'][i] for i in range(len(all['type']))],'总分': [all['score'][i] for i in range(len(all['score']))]
})# 显示转换后的 DataFrame,index=False是取消原来的dataframe自动编号
print(df.to_string(index=False))# 如果需要,可以将其保存为 CSV 文件
# df.to_csv('school_ranking.csv', index=False, encoding='utf-8')
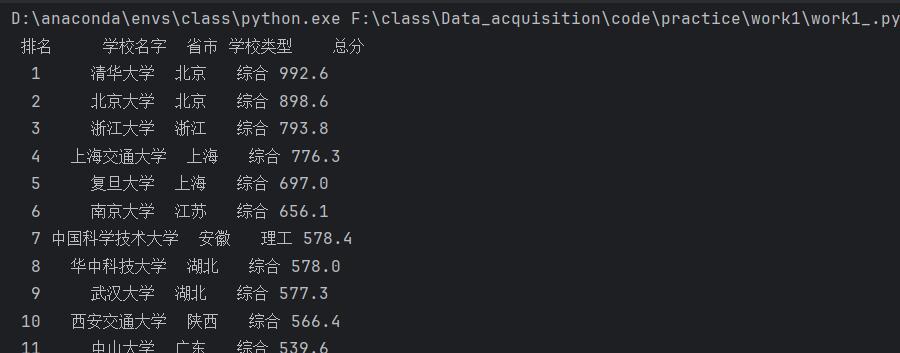
运行结果:
命令行输出:
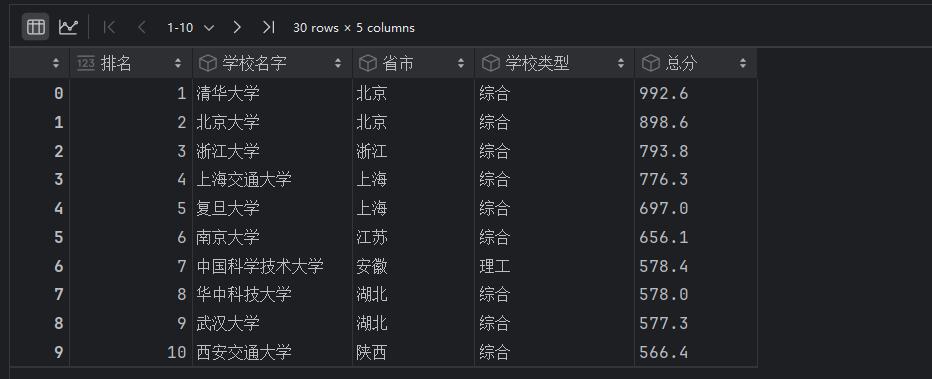
jupyter输出:
心得体会
通过这种直接给网页发送请求获取网页数据的方式还是比较简单的,数据直接存储在网页结构里面,主要是对网页解析部分,有些返回的数据会参杂着没有用的字符,如空格换行符等,这个时候就需要再次解析才能过滤获得想要的数据。最后采用了DataFrame的形式展现数据,一个是能使数据排列整齐,一个是存储到DataFrame中能更好的用做数据分析。
对于requests库的使用,该库集成了很多功能,能使代码编写更加简单,使我们高效的编写代码与调试代码;对于BeautifulSoup的使用,该库对于元素的解析非常高效,语法简洁明了,但是对于细节处理部分稍微会差一点,因为该库只能检索标签,没有很好的能将text值多余部分消除。
作业②
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码与运行结果
代码:
import requests # 用于发送HTTP请求
import re # 正则表达式模块,用于匹配字符串模式
import threading # 线程模块,用于并发下载图片
import time # 时间模块,用于暂停程序的执行
import random # 随机模块,用于生成随机数
import os # 操作系统模块,用于文件操作# 模拟浏览器登录,定义一个User-Agent,伪装请求为浏览器发出的
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0"# 定义cookie字符串,用于保持会话状态,模拟登录后的请求
cookie = "__jdu=17271449574151433017795; shshshfpa=ded88cf8-09ce-a477-ebe4-2493c67e8e78-1727144962; shshshfpx=ded88cf8-09ce-a477-ebe4-2493c67e8e78-1727144962; TrackID=13Pn2WnjRYPpif5576bxpXfg2LgdzJBvmBmxNDVlnjcS2PW7g12CEUt-Weeae7DJvs5YXD72sNwIeo07aE67NLntR3j7K6iiAOvC6d98uS7z43bHiiT8DSitPopoziGmu; thor=715141BE6C9536F17D1864B0AB49B027336956B4A93B43087E32EF1A158B0017B8955B71BC4CC9CDDF3603CA60C4A03365163B28FFC27EEE0597B416E5DCC1412E994C9E0A9F1C656ACFCD63CD64EB06BE1436FF223EBEA4D2940AAF7BF457B4964FD83E5B9723D347C0E642ECE4A7C11952DC98A41773BB0CC93B344004403895112E7460413D45066A56C24A62751FE4F6B20901534C5193B63C175FAC1CEC; light_key=AASBKE7rOxgWQziEhC_QY6yalHIWSMfjmMdQCIfmiiLp90g34uoBR2WngQeQmaR45Rno5KRb; pinId=t8vUk2ONJqfeMhHAdNEcfA; pin=jd_IMrvTjYrsOYY; unick=jd_i8b81qc9y0r86f; _tp=QPV29p3JH9DfoHpsRIj1wQ%3D%3D; _pst=jd_IMrvTjYrsOYY; qrsc=3; ipLoc-djd=16-1303-1305-48927; __jdv=76161171|cn.bing.com|-|referral|-|1728467486377; shshshfpb=BApXSqce5c_dALiLo-4lKw1ktTeR9uD-iBmVVTk1r9xJ1Mr4f74C2; 3AB9D23F7A4B3C9B=4VJNECADUFJ4BVR3NKQPF75TI2MLCZHTQQCGPYAFMQD33EJ6JXO6INMPS7JUYEUTFXHXKPAQTXWRV5Y2ZPWFC4TFIQ; __jda=76161171.17271449574151433017795.1727144957.1728467486.1729399437.8; __jdb=76161171.1.17271449574151433017795|8.1729399437; __jdc=76161171; 3AB9D23F7A4B3CSS=jdd034VJNECADUFJ4BVR3NKQPF75TI2MLCZHTQQCGPYAFMQD33EJ6JXO6INMPS7JUYEUTFXHXKPAQTXWRV5Y2ZPWFC4TFIQAAAAMSVA6VL3IAAAAADPNSJBEFDTSPL4X; _gia_d=1; flash=3_0b5lq6EleaKtOFGosYp8NM4saVZ87rUzmUmVT9RA5qPOvwuy9Rc7RHOjHgX_QOiTXb5rjB0soP8FSHLMo6Wen1vJjjDuy46ML7P9uXntJgprrRSLdPy9aiA_EPUXLDy2lmtbqLKf4BedJz0rurzL-ZxYCfvD42Muko84jAG3bKeRvcuLcLry; PCSYCityID=CN_350000_350100_0; jsavif=1; jsavif=1; xapieid=jdd034VJNECADUFJ4BVR3NKQPF75TI2MLCZHTQQCGPYAFMQD33EJ6JXO6INMPS7JUYEUTFXHXKPAQTXWRV5Y2ZPWFC4TFIQAAAAMSVA6VL3IAAAAADPNSJBEFDTSPL4X"# 将User-Agent和Cookie信息存储在headers中,作为请求头发送
headers = {"user-agent": user_agent, "cookie": cookie}# 定义获取图片函数,参数n代表要爬取的页数
def getPic(n):global threads # 使用全局变量threads来保存所有启动的线程count = 0 # 用于记录图片的编号# 循环遍历每一页for page in range(1, n + 1):url = f"https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&page={page}" # 构建请求URL,模拟搜索“书包”# 使用requests库发起HTTP GET请求try:response = requests.get(url, headers=headers, timeout=10) # 发送请求,超时设置为10秒response.raise_for_status() # 如果请求失败,抛出HTTPError异常html = response.text # 获取页面HTML内容except requests.RequestException as e:print(f"Failed to retrieve page {page}: {e}") # 请求出错时,打印错误信息并跳过当前页continue# 使用正则表达式匹配每一个商品的HTML容器reg_li = r'<li data-sku.*?</li>.*?</div>\n\t</li>'match_li = re.findall(reg_li, html, re.DOTALL) # 匹配所有<li>标签# 遍历匹配到的商品列表for li in match_li:# 使用正则表达式匹配商品的图片信息reg_pic = "<img w.*?>"match_pic = re.findall(reg_pic, li, re.DOTALL)# 提取图片URLreg_pic_url = 'data-lazy-img="(.*?)"' # 匹配图片路径if match_pic: # 如果找到图片信息try:pic_url = "https:" + re.findall(reg_pic_url, match_pic[0])[0] # 拼接完整的图片URLcount += 1 # 计数器递增# 创建下载线程并启动T = threading.Thread(target=downLoad, args=(pic_url, count))T.setDaemon(False) # 设置线程为非守护线程,主线程结束前,子线程要完成T.start() # 启动线程threads.append(T) # 将线程添加到线程列表except IndexError:print("Failed to find image URL in match_pic.") # 如果没有找到图片URL,打印错误信息except Exception as e:print(e) # 打印其他异常# 随机暂停0到3秒,避免频繁请求被封禁time.sleep(random.randint(0, 3))# 定义下载图片的函数
def downLoad(url, title):try:# 使用requests下载图片数据response = requests.get(url, timeout=100) # 请求图片,设置超时时间为100秒response.raise_for_status() # 如果请求失败,抛出HTTPError异常data = response.content # 获取图片的二进制数据# 检查保存图片的文件夹是否存在,如果不存在则创建if not os.path.exists("./jingdong"):os.makedirs("./jingdong")# 生成图片保存路径downLoadPath = f"./jingdong/{str(title)}.jpg"# 将图片数据写入文件with open(downLoadPath, "wb") as fobj:fobj.write(data)except requests.RequestException as e:print(f"Failed to download {url}: {e}") # 如果下载失败,打印错误信息except Exception as e:print(e) # 打印其他异常# 初始化线程列表,用于保存所有的线程对象
threads = []# 启动获取图片的函数,参数为要爬取的页数
getPic(2)# 等待所有线程执行完毕
for t in threads:t.join() # 阻塞主线程,等待子线程执行完毕print("The End") # 打印结束标志
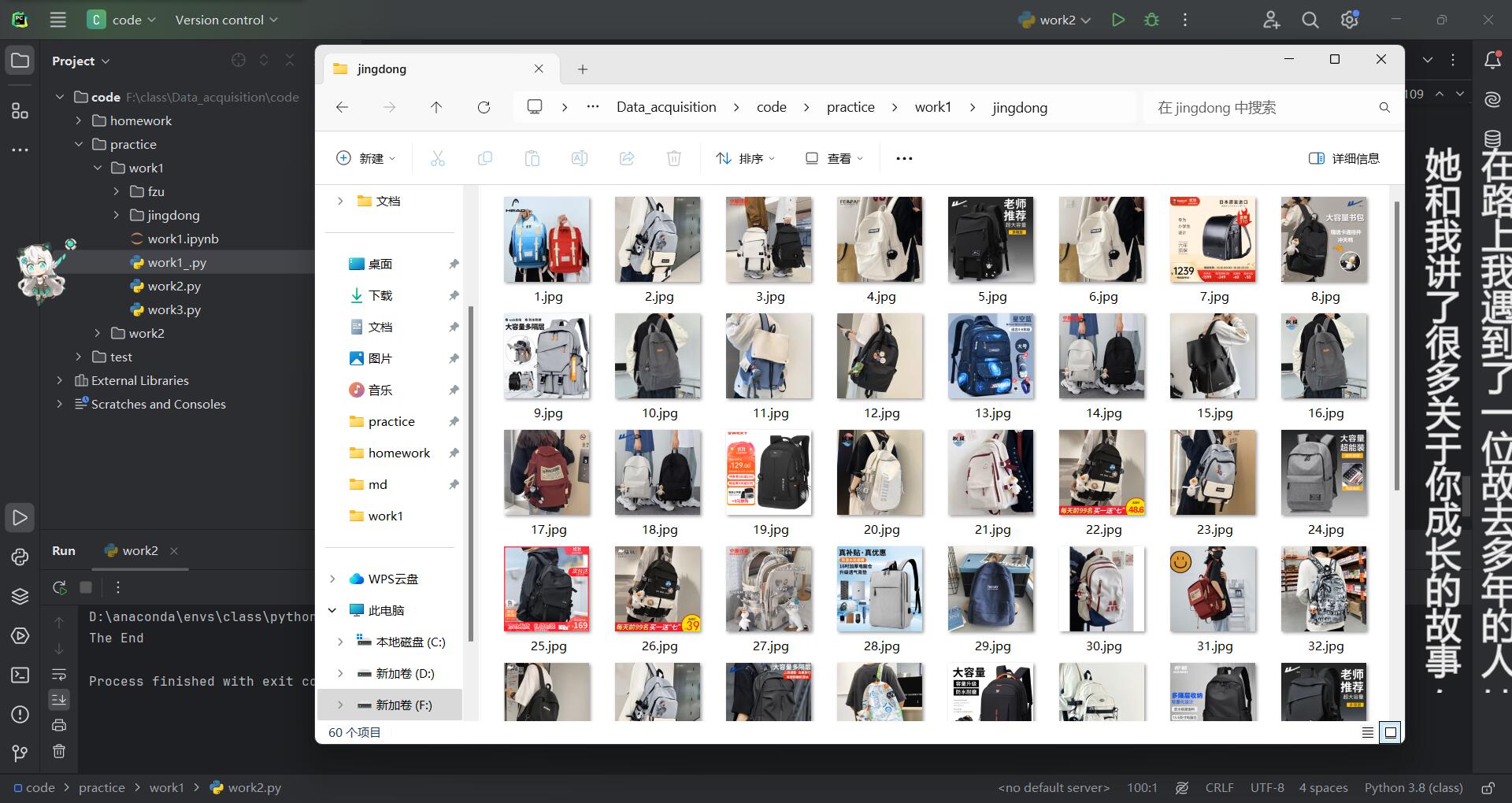
运行结果:
心得体会
使用多线程对京东的图片进行爬取,将网页解析与图片下载过程分开,大大的提高了下载效率。而后面所加入的线程阻塞,能大大的提高图片下载的成功率,可以看到本次试验是爬取两页图片,每页有30张图片,总共爬取到了60张图片,没有多线程的加持成功率大概只有百分之五十。当然加入多线程并不一定会将成功率提到百分百,借用淘宝图片爬取的例子,其单线程到多线程的成功率只能从大约百分之五十提到七八十。
作业③:
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
代码与运行结果
代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库,用于解析HTML文档
import requests # 导入requests库,用于发送HTTP请求
import os # 导入os模块,用于文件操作# 定义下载图片的函数
def downLoad(url, title):try:# 使用requests库发送HTTP GET请求,下载图片response = requests.get(url, timeout=100) # 设置请求超时为100秒response.raise_for_status() # 如果请求不成功,抛出异常data = response.content # 获取图片的二进制数据# 检查保存图片的目录是否存在,如果不存在则创建if not os.path.exists("./fzu"):os.makedirs("./fzu")# 定义图片保存路径,命名为"title.jpg"downLoadPath = f"./fzu/{str(title)}.jpg"# 将下载的图片数据写入文件with open(downLoadPath, "wb") as fobj:fobj.write(data)except requests.RequestException as e:print(f"Failed to download {url}: {e}") # 捕获请求异常,打印错误信息except Exception as e:print(e) # 捕获其他异常并打印# 要爬取的福州大学新闻网站URL
url = "https://news.fzu.edu.cn/yxfd.htm"# 使用requests库发送HTTP GET请求获取网页内容
response = requests.get(url, timeout=10) # 设置请求超时为10秒
response.raise_for_status() # 如果请求失败,抛出异常
html = response.text # 获取页面的HTML内容# 使用BeautifulSoup解析HTML文档
bs = BeautifulSoup(html, "html.parser")# 查找页面中所有的<img>标签,获取图片的相关信息
img_url = bs.select("img") # 使用CSS选择器获取所有图片标签# 定义一个列表来保存所有jpg和jpeg格式的图片URL
img_jpg_or_jpeg = []# 遍历找到的所有图片URL
for url in img_url:# 筛选出后缀为jpg或jpeg的图片if url["src"][-3:] == "jpg" or url["src"][-4:] == "jpeg":# 补全相对路径为完整URLnew_url = "https://news.fzu.edu.cn" + url["src"]# 将符合条件的图片URL添加到列表中img_jpg_or_jpeg.append(new_url)# 初始化计数器,用于命名下载的图片
count = 1# 遍历筛选出的图片URL列表,下载每一张图片
for url in img_jpg_or_jpeg:# 调用下载函数downLoad,传入图片URL和计数器作为图片名称downLoad(url, count)count = count + 1 # 计数器递增,用于为下一张图片命名
运行结果:
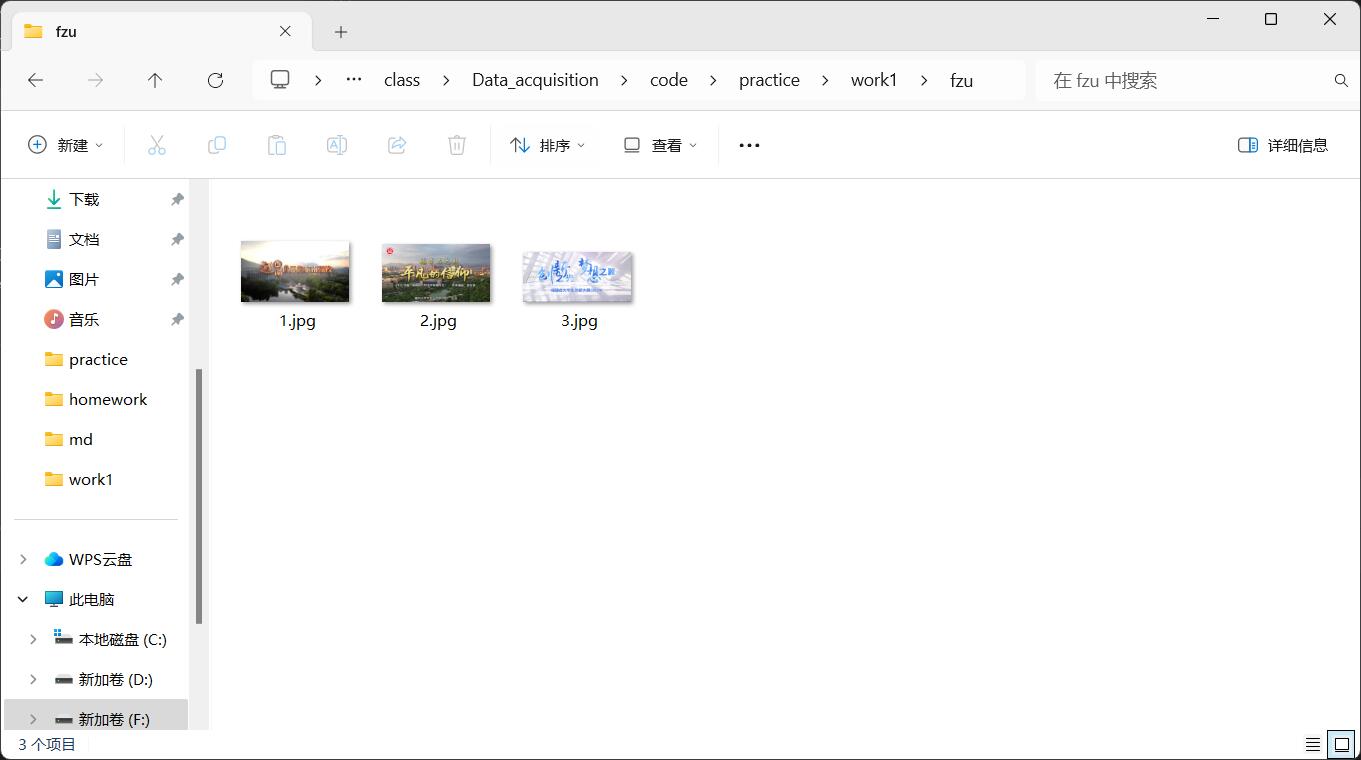
心得体会
因为该任务的爬取数量不是很多,就没有用前面的那种多线程,如果爬取的图片比较多的话改为和前面的多线程一样即可。但是这里有要求是要爬取JPG或者JPEG格式的图片,在后面加个判断后缀名即可,可以看到原来的网站的很多PNG图片都被过滤掉了,只剩下了最后的3张符合要求的图片。