作业①
1)用requests和BeautifulSoup库方法定向爬取给定网址的数据,屏幕打印爬取的大学排名信息。
a、主要代码解析
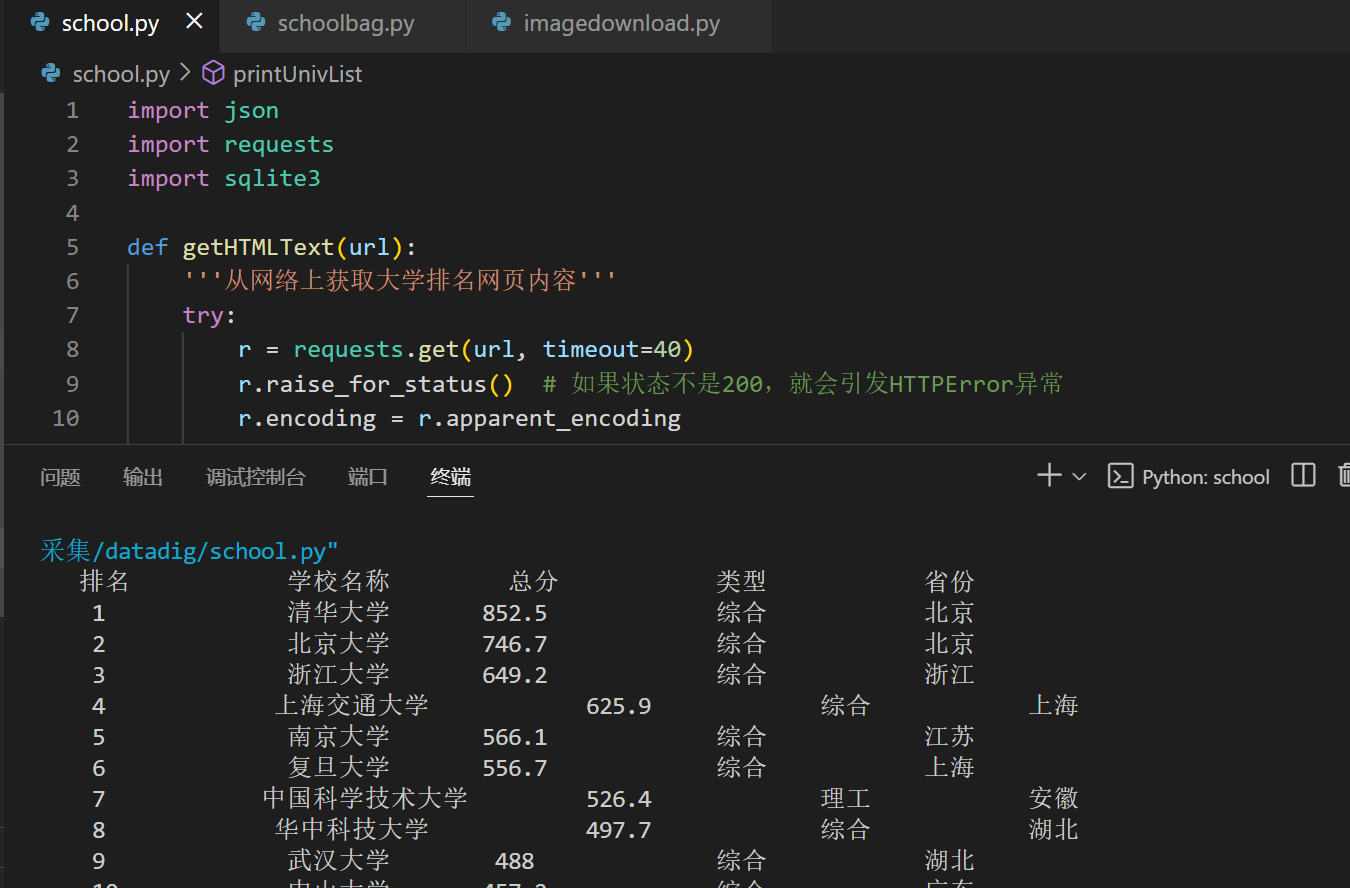
该函数从获取的JSON数据中提取前 num 名大学的信息,并将这些信息存储到 ulist 列表中,同时格式化输出这些大学的排名信息
def printUnivList(ulist, html, num):'''提取 html 网页内容中 前 num 名大学信息到 ulist列表中 ''' data = json.loads(html) # 对数据进行解码 # 提取 数据 rankings 包含的内容content = data['data']['rankings'] # 把 学校的相关信息放到 ulist 里面for i in range(num):index = content[i]['rankOverall']name = content[i]['univNameCn']score = content[i]['score']category = content[i]['univCategory']province = content[i]['province'] # 提取省份信息ulist.append([index, name, score, category, province]) # 打印前 num 名的大学 tplt = "{0:^10}\t{1:^10}\t{2:^10}\t{3:^10}\t{4:^10}" # 更新格式,而不使用{3}print(tplt.format("排名 ", "学校名称", "总分", "类型", "省份")) # 更新这里,保持一致for i in range(num):u = ulist[i] print(tplt.format(u[0], u[1], u[2], u[3], u[4])) # 直接传入值
- 使用了 json.loads 对网页的返回内容进行JSON解码,这意味着该网页返回的数据是一个JSON格式的结构。
- 从 data['data']['rankings'] 提取大学的具体排名信息,包含排名、学校名称、得分、类别(如综合类、理工类等)以及所在省份。
- 使用 tplt 定义了表格的输出格式,确保打印的大学信息整齐对齐。使用了 center(^) 方式格式化输出。
b、输出信息
c、git文件夹链接
2)心得体会
- 使用格式化字符串打印大学信息,增强了输出的可读性,便于用户快速理解
- 通过 json.loads 解析 JSON 数据,将网络请求获得的响应直接转化为 Python 对象,简化了数据处理过程
作业②:
1)用requests和re库方法设计爬取当当网以关键词“书包”搜索页面的数据,爬取商品名称和价格。
a、主要代码解析
发送HTTP请求:
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
html = response.read()
- 创建一个请求对象并发送请求,获取网页的HTML内容。
处理HTML编码:
dammit = UnicodeDammit(html)
data = dammit.unicode_markup
- 使用UnicodeDammit处理返回的HTML,确保其编码为Unicode,以便后续处理。
pattern = re.compile(r'<a[^>]*title="([^"]*)"[^>]*>.*?<span class="price_n">([^<]+)</span>', re.S)
matches = pattern.findall(data)
#### 正则表达式提取商品名称和价格
- 编写正则表达式,提取商品名称(title)和价格(price)。
- re.S 使.匹配包括换行符在内的所有字符。
b、输出信息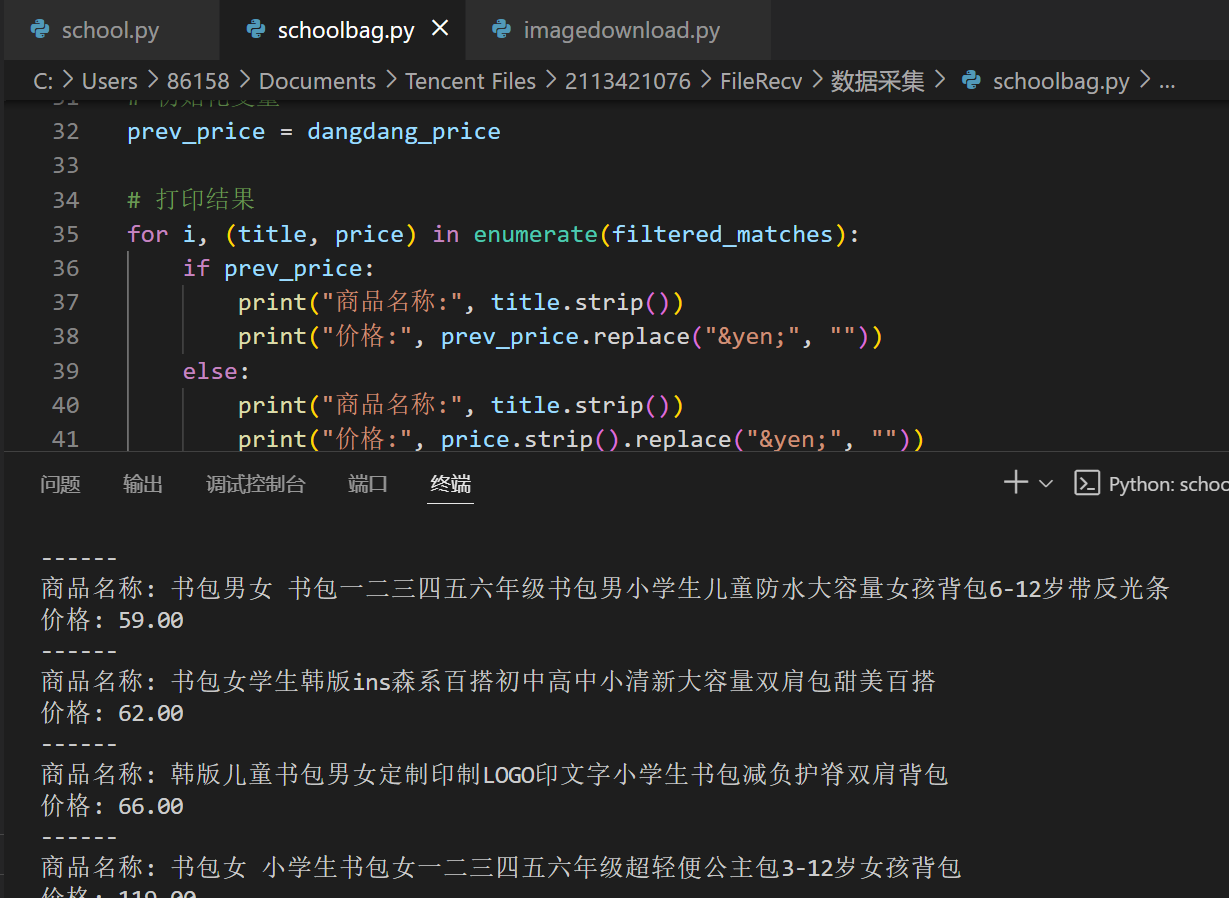
c、git文件夹链接
2)心得体会
- 使用正则表达式提取特定模式的内容是数据爬取中的一个重要技能。通过精确的模式匹配,可以有效地从复杂的HTML中提取所需的信息
- 不同网页可能会使用不同的编码格式,使用UnicodeDammit确保获取到的数据在后续处理中不会因为编码问题而出现错误是非常必要的。
作业③:
1)爬取一个当当网以糖果为关键词搜索的网页的所有JPEG和JPG格式文件
a、主要代码解析
解析网页内容以获取图片链接,这个函数使用BeautifulSoup解析HTML并提取所有图片的链接
def parsePageForImages(data):img_urls = []soup = BeautifulSoup(data, 'html.parser')images = soup.find_all('img')for img in images:src = img.get('src') or img.get('data-src')if src and not src.startswith('http'):src = 'http:' + srcif src:img_urls.append(src)return img_urls
- 它会检查src和data-src属性,确保每个URL都是完整的。
这个函数用于并发下载多张图片
def downloadImages(img_urls, path='./candyimages/', limit=38):if not os.path.exists(path):os.makedirs(path)with ThreadPoolExecutor(max_workers=10) as executor:future_to_url = {executor.submit(downloadImage, url, path): url for url in img_urls[:limit]}for future in as_completed(future_to_url):url = future_to_url[future]try:future.result() # 获取执行结果except Exception as e:print(f"{url} generated an exception: {e}")
- 使用ThreadPoolExecutor来管理线程池,max_workers=10表示最多同时运行10个线程。
b、输出信息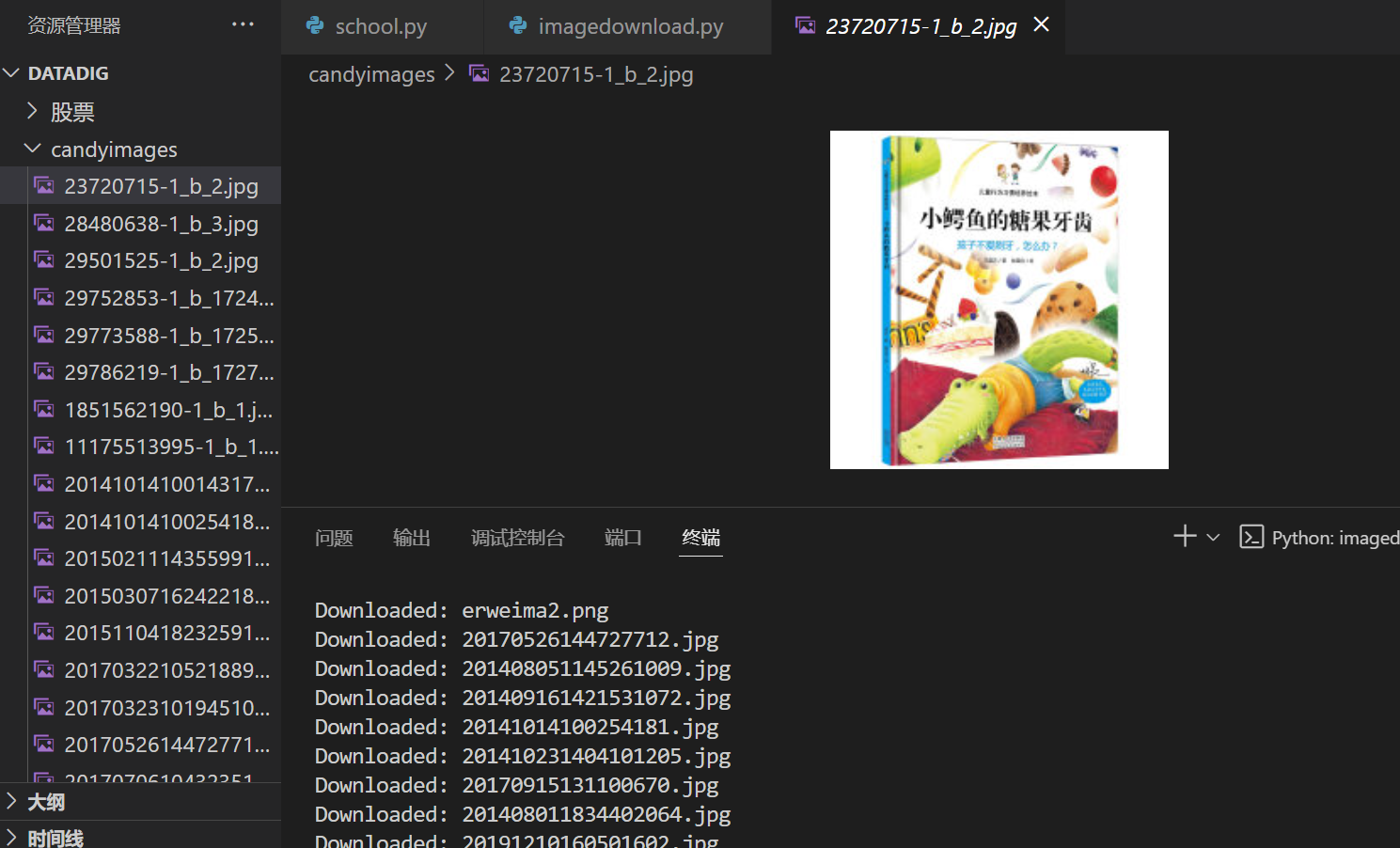
c、git文件夹链接
2)心得体会
- BeautifulSoup作为HTML解析库,非常直观易用。其选择器功能可以轻松找到需要的HTML元素,使得网页数据抓取变得简单。
- 使用ThreadPoolExecutor能够显著提高下载速度,尤其是当网络延迟较高时,多个线程同时下载可以充分利用带宽资源。
- 使用多层次的异常处理,这对于网络请求和文件操作尤其重要。确保程序在遇到错误时不会崩溃,并能提供有效的错误信息。