吴恩达机器学习笔记(2-1到2-7)
https://www.bilibili.com/video/BV164411b7dx?p=5
https://www.bilibili.com/video/BV164411b7dx?p=6
https://www.bilibili.com/video/BV164411b7dx?p=7
https://www.bilibili.com/video/BV164411b7dx?p=8
https://www.bilibili.com/video/BV164411b7dx?p=9
https://www.bilibili.com/video/BV164411b7dx?p=10
https://www.bilibili.com/video/BV164411b7dx?p=11
机器学习-吴恩达
二、一元线性回归拟合模型
数学基础:
1、方差
描述数据集离散程度的数学量。
-
一组数据有一个平均数,方差描述了这些数据与平均数的差距的平方的平均值
-
$$
\begin{aligned}
& 数据集: (x_1,y_1),(x_2,y_2),(x_3,y_3)...(x_n,y_n)\
& 平均数:average = \frac{1}{n}\sum_{i=1}^{n}y_i\
& 方差: variance = \frac{1}{n}\sum_{i=1}{n}(average-y_i)2
\end{aligned} \
$$
2、函数导数与偏导数
略
3、复合函数求导
$u=f(x),g(u),则g'(x) = f'(x)*g'(u)$
-
$$
\begin{aligned}
例如对函数 & g(x) = (3x2+2x+1)2求导:\
令u = f(x) & = 3x^2+2x+1 \quad,\quad g(u) = u^2\
\therefore f'(x) & = 6x+2 \quad,\quad g'(u) = 2u\
\therefore g'(x) & = (6x+2)2(3x^2+2x+1)\\即:内求 & 导乘以外求导\\ 注:如果 & 是复杂的多层嵌套函数,依旧遵循内求导*外求导,然后反复向最外层迭代即可\end{aligned} \
$$
4、函数f(x)导数的含义与特性
- 1、导数表示函数当前位置的斜率
- 2、越陡峭的地方斜率越大,越平缓的地方斜率越小
- 3、从某点
(x, f(x))出发,向着 $x-\alpha f'(x)$ 处移动是向更小值处移动($\alpha>0时$)
5、凸函数
-

- 左侧碗状的开口向上的叫凸函数,右侧为非凸函数。
1、回归方程
对数据集$(x_1,y_1),(x_2,y_2),(x_3,y_3)...(x_n,y_n)$进行拟合时,假设方程(预测函数,也叫回归方程)为 $h(x) = \theta_1 x + \theta_0$ 如下图所示。其中 $h$ 表示房价函数,$x$ 表示占地面积。$\theta_1与\theta_0$表示回归方程参数。(注,这种也叫一元线性回归,并不是说必须使用一元线性回归,而是入门使用它便于学习)

而这个学习算法的任务就是:输入一系列训练集,通过算法后,输出一个函数。这个函数$h$作用就是,当输入一个房屋占地面积后能够预测出房价。

既然是预测函数,这个函数就需要满足"每一个训练集数据的房价与其对应占地面积相同的预测房价平均偏差最小"。因为只有这样这个预测函数才是最拟合训练集的函数。
备注:需要说明的是,严格来说,在进行计算预测函数之前,虽然训练集数据是真实的,但是也需要排除极端值情况,个别数据可能因为其他因素会很极端高或者极端低。但因为刚入门,可以不用考虑这个。
即相当于数学中对数据集求方差。对于数据集(假设m个数据)中的所有数据项 $x_{i}\ y_i$ ,使用方差公式:
$$
variance = \frac{1}{m}\sum_{i=1}{m}(h(x_i)-y_i)2
$$
这个问题就变成 为了使得variance值最小,寻找到合适的 $\theta_1$ 与 $\theta_0$。现在定义这个函数叫做“代价函数 $J$ ”:
$$
J(\theta_0,\theta_1) = \frac{1}{m}\sum_{i=1}{m}(h(x_i)-y_i)2=\frac{1}{m}\sum_{i=1}{m}((\theta_1x_i+\theta_0)-y_i)2
$$
这个代价函数形状类似于下图(使用其他数学工具实现的绘图),可以明确的是上面的代价函数肯定有解(但不一定只有一个),图最底部或许有多个局部最优解。

总结下来,对于一元线性回归,有如下公式
$$
\begin{aligned}
& 回归方程: h(x) = \theta_1 x + \theta_0\
& 参数:\theta_1、\theta_0\
& 代价函数:J(\theta_0,\theta_1) = \frac{1}{m}\sum_{i=1}{m}((\theta_1x_i+\theta_0)-y_i)2\
& 目标:min\ \ J(\theta_0,\theta_1)
\\ \\ \\
&注:在解代价函数时,解\sum_{i=1}^{m}((\theta_1x_i+\theta_0)-y_i)^2的效果是一样的
\end{aligned} \
$$
2、"Batch"梯度下降法解代价函数
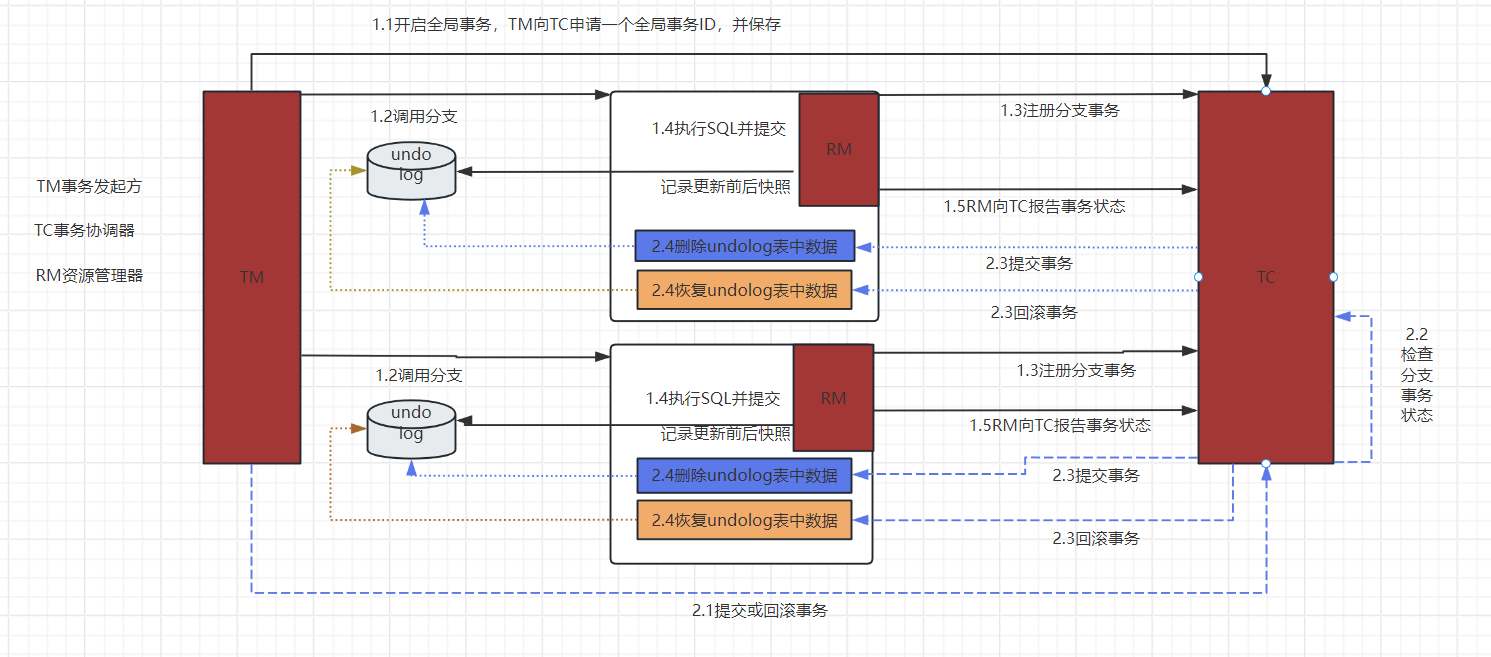
1、梯度下降法作用
寻找局部最小值
2、梯度下降法思路

从出发点开始,不断寻找周围极小邻域内最小值的点,然后继续从最小值点出发,循环这个过程直到找不到更小值的点。那么最终找到的点就是局部最优点。如上图。

由上图所知,由于出发点的不同,最后的解也不一定相同,因此是局部最优解而非全局最优解。
这种梯度下降算法也叫“Batch”梯度下降法(中文:全批次梯度下降法),特征是要遍历所有的数据集,如果是内存有限,这种方法并不是很好。在后面章节会讲解其他方式解代价函数。
需要特别说明的是,线性回归类的模型,代价函数都是碗状的凸函数,这是线性回归模型的性质之一,即线性回归模型的没有极值点,只有最值点(当然,最值也是一种极值),其实这里很好思考的:因为在一堆数据里拟合方差最小,那么这个拟合曲线(拟合方程)必然是唯一的,即结果唯一。
3、梯度下降法流程
a、代码流程
$$
\begin{aligned}
&// 假设有函数 J(\theta_0, \theta_1) \
&// 以下为伪代码 \\
&let\ θ1 = 0; \\
&let\ θ2 = 0; \\
&const\ accuracy = 0.000001; // 最终结果斜率\\
&let\ step = 1; // 梯度下降法的步长,依据情况取值,并非必须是1\\\\&let\ der0= \frac{\delta J(\theta_0,\theta_1)}{\delta \theta_0};\ \\
&let\ der1= \frac{\delta J(\theta_0,\theta_1)}{\delta \theta_1};\ \\\\&while(der0>accuracy \ \ || \ \ der1>accuracy)\{ \\&\qquad let\ θ_0\_temp\ =\ θ_0\ ;\\&\qquad if(der0>accuracy)\{ \\&\qquad \qquad θ_0\_temp = \ θ_0\ -\ step\ * \ der0\ ; \\&\qquad \qquad der0= \frac{\delta J(\theta_0,\theta_1)}{\delta \theta_0};\ \\&\qquad \} \\\\&\qquad let\ θ_1\_temp\ =\ θ_1\ ;\\&\qquad if(der1>accuracy)\{ \\&\qquad \qquad θ_1\_temp = \ θ_1\ -\ step\ * \ der1\ ; \\&\qquad \qquad der1= \frac{\delta J(\theta_0,\theta_1)}{\delta \theta_1};\ \\&\qquad \} \\\\&\qquad θ0 = θ_0\_temp; \\&\qquad θ1 = θ_1\_temp; \\
&\} \\
& console.log(^"最小值:\ ^"+J(θ1,θ2))
\end{aligned}
$$
依据 $\underline{当\alpha > 0时f(x)一定比f(x-\alpha f'(x))大}$ 的数学原理,让函数$J(\theta_0,\theta_1)$自动的向着局部最小值不断的逼近,直到斜率为0到达局部最优解处。
之所以在伪代码处设置最终斜率为0.000001,是因为越靠近极值处斜率越小,斜率越小$step\ *\ \frac{\delta J(\theta_0,\theta_1)}{\delta \theta_0}$ 值越小,就会导致越靠近极值处逼近越慢。因此为了防止无穷无尽的算下去,刻意优化了结果斜率。此外还优化了步骤,但原理是一样的。
在视频2-6中有讲解step的取值过大过小会导致的后果,也说明了为什么step不用自动调节的原因,同时也讲了越靠近极值逼近的速度越慢的原因。
若要实现上面的伪代码编程,难点为如何实现$\frac{\delta J(\theta_0,\theta_1)}{\delta \theta}$的计算。
b、偏导函数
$$
\begin{aligned}
已知代价函数\ J(\theta_0,\theta_1) &= \frac{1}{m}\sum_{i=1}{m}((\theta_1x_i+\theta_0)-y_i)2 \
①对 \theta_0 求偏导数:\qquad \qquad &\
\frac{\delta J(\theta_0,\theta_1)}{\delta \theta_0} &= \frac{1}{m}\sum_{i=1}^{m}{2*((\theta_1 x_i+\theta_0)-y_i)} \
&= \frac{2}{m}\sum_{i=1}^{m}((\theta_1 x_i+\theta_0)-y_i)\\
②对 \theta_1 求偏导数:\qquad \qquad &\\
\frac{\delta J(\theta_0,\theta_1)}{\delta \theta_1} &= \frac{1}{m}\sum_{i=1}^{m}\{2*((\theta_1 x_i+\theta_0)-y_i)*x_i\} \\
&= \frac{2}{m}\sum_{i=1}^{m}((\theta_1 x_i+\theta_0)-y_i)*x_i\\\\
\end{aligned}
$$
附件
代价函数演示代码:
import matplotlib.pyplot as plt
import numpy as np# 生成随机的 x 数据,范围在 0 到 10 之间,共 100 个点
np.random.seed(42) # 设置随机种子以确保结果可重复
x = np.random.uniform(0, 1, 100)
# 生成符合 y = 2x + 2 的 y 数据,加上一定的噪声
true_a = 2.0 # 设定真实的斜率 a
true_b = 2.0 # 设定真实的截距 b
# noise = np.random.normal(0, 1, 100) # 添加较小的随机噪声
# y = true_a * x + true_b + noise
# 去除噪声效果更明显
y = true_a * x + true_b + 0# 绘制数据点的散点图
plt.figure(figsize=(10, 7))
plt.scatter(x, y, color='blue', label='Data points')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Scatter plot of data points')
plt.legend()
plt.show()# 定义 t = sum((a * x_i + b - y_i)^2) 的函数并绘制 3D 图
A = np.linspace(1, 3, 200) # 定义 a 参数的范围
B = np.linspace(1, 3, 200) # 定义 b 参数的范围
A_mesh, B_mesh = np.meshgrid(A, B)
# 计算 T 值
T = np.zeros_like(A_mesh)
for i in range(len(x)):T += ((A_mesh * x[i] + B_mesh - y[i])**2)# 创建 3D 图
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
# 绘制等高线
ax.contour(A_mesh, B_mesh, T, levels=[0, 0.1, 1, 4, 7], colors=['black'], linewidths=1, linestyles='solid', zorder=10)
# 绘制曲面
ax.plot_surface(A_mesh, B_mesh, T, cmap='viridis', zorder=1)
# 设置坐标轴标签
ax.set_xlabel('a')
ax.set_ylabel('b')
ax.set_zlabel('T')plt.title('3D plot of T(a, b)')
plt.show()
其中a、b是θ参数,T是代价函数值,中间圆圈处有明显的局部最优解