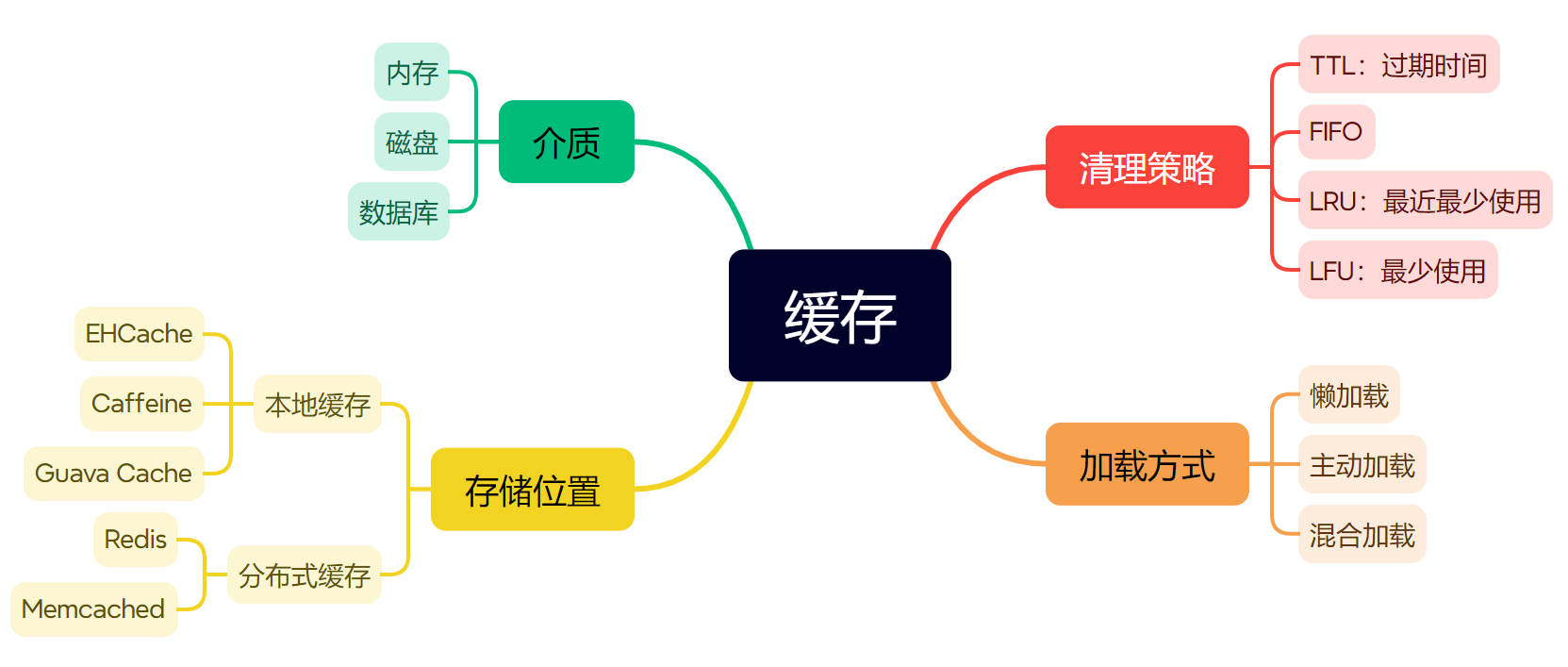
缓存分类
1、内存缓存:内存缓存是一种基于内存的缓存机制,它将经常访问的数据存储在计算机的内存中,以便更快地获取和操作数据。内存缓存通常具有高速读写性能,但容量有限,适用于存储经常访问的关键数据。
2、磁盘缓存:磁盘缓存是一种基于磁盘的缓存机制,它将经常访问的数据存储在磁盘上,以便在后续访问时能够更快地获取和操作数据。与内存缓存相比,磁盘缓存具有更大的容量和更低的成本,但读写速度较慢。
3、网络缓存:网络缓存是一种基于网络通信的缓存机制,它将经常访问的数据存储在网络中的多个节点上,以便在后续访问时能够更快地获取和操作数据。网络缓存可以减轻服务器的负载,提高数据传输速度和可靠性。
4、数据库缓存:数据库缓存是一种基于数据库系统的缓存机制,它将经常访问的数据存储在数据库系统中,以便更快地获取和操作数据。数据库缓存可以提高数据库查询速度和响应速度,同时也可以减少对数据库服务器的负载。MySQL 的数据存储到磁盘上,MySQL 为了提升读写性能,会利用 bufferpool 缓存数据页。MySQL 读取时会按照页的粒度将数据页读取到 bufferpool 中,bufferpool 中的数据页使用 LRU 算法淘汰长期没有用到的页面,缓存最近访问的数据页。
5、CDN缓存:CDN(Content Delivery Network)缓存是一种基于分布式网络的缓存机制,它将经常访问的数据存储在分布式网络中的多个节点上,以便更快地向用户提供数据。CDN缓存可以减轻服务器负载,提高数据传输速度和可靠性,同时也可以提供更好的用户体验。
6、反向代理缓存:反向代理缓存是一种基于代理服务器的缓存机制,它将经常访问的数据存储在代理服务器上,以便更快地向用户提供数据。反向代理缓存可以减轻对原始服务器的负载,提高数据传输速度和可靠性,同时也可以提供更好的网络安全保护。
7、浏览器缓存:浏览器缓存是一种基于浏览器的缓存机制,它将经常访问的网页内容存储在用户的计算机上,以便在下次访问时能够更快地加载和显示网页内容。浏览器缓存可以提高网页加载速度和响应速度,同时也可以减轻对服务器的负载。
缓存淘汰策略
缓存的大小是有限的,因为需要对缓存中数据进行淘汰,通常可以采用随机、LRU 或者 LFU 算法等淘汰数据。
LRU 是一种最常用的置换算法,淘汰最近最久未使用的数据,底层可以利用 map+双端队列的数据结构实现。
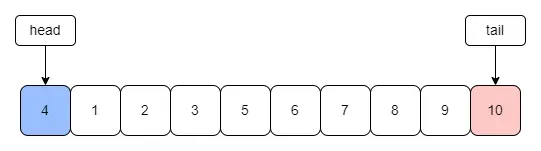
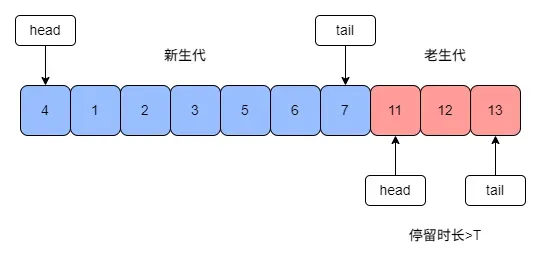
最原生的 LRU 算法是存在一些问题的。首先需要注意的是在数据结构中有互斥锁,因为 golang 对于 map 的读写会产生 panic,导致服务异常。使用互斥锁之后会导致整个缓存性能变差,可以采用分片的思想,将整个 LRUCache 分为多个,每次读取时读取其中一个 cache 片,降低锁的粒度来提升性能,常见的本地缓存包通常就利用这种方式实现的。peodMySQL 也会利用 LRU 算法对 buffer pool 中的数据页进行淘汰。由于 MySQL 存在预读,在读取磁盘时并不是按需读取,而是按照整个数据页的粒度进行读取,一个数据页会存储多条数据,除了读取当前数据页,可能也会将接下来可能用到的相邻数据页提前缓存到 bufferpool 中,如果下次读取的数据在缓存中,直接读取内存即可,不需要读取磁盘,但是如果预读的数据页一直没有被访问,那就会存在预读失效的情况,淘汰原来使用到的数据页。MySQL 将 buffer pool 中的链表分为两部分,一段是新生代,一段是老生代,新老生代的默认比是7:3,数据页被预读的时候会先加到老生代中,当数据页被访问时才会加载到新生代中,这样就可以防止预读的数据页没有被使用反而淘汰热点数据页。此外 MySQL 通常会存在扫描表的请求,会顺序请求大量的数据加载到缓存中,然后将原本缓存中所有热点数据页淘汰,这个问题通常被称为缓冲池污染,MySQL 中的数据页需要在老生代停留时间超过配置时间才会老生代移动到新生代时来解决缓存池污染。
Redis 中也会利用 LRU 进行淘汰过期的数据,如果 Redis 将缓存数据都通过一个大的链表进行管理,在每次读写时将最新访问的数据移动到链表队头,那样会严重影响 Redis 的读写性能,此外会增加额外的存储空间,降低整体存储数量。Redis 是对缓存中的对象增加一个最后访问时间的字段,在对对象进行淘汰的时候,会采用随机采样的方案,随机取5个值,淘汰最近访问时间最久的一个,这样就可以避免每次都移动节点。
但是 LRU 也会存在缓存污染的情况,一次读取大量数据会淘汰热点数据,因此 Redis 可以选择利用 LFU 进行淘汰数据,是将原来的访问时间字段变更为最近访问时间+访问次数的一个字段,这里需要注意的是访问次数并不是单纯的次数累加,而是根据最近访问时间跟当前时间的差值进行时间衰减的,简单说也就是访问越久以及访问次数越少计算得到的值也越小,越容易被淘汰。
缓存生产问题
缓存穿透等问题
- 缓存雪崩:缓存雪崩是指缓存中的某个热点数据在缓存中被删除或者过期,导致大量的热点请求同时请求数据库。解决方案可以对于热点数据设置较长的过期时间或者利用分布式锁避免多个相同请求同时访问下游服务。在新闻业务中,对于热点新闻经常会出现这种情况,事件服务利用 golang 的 singlefilght 保证同一篇文章请求在同一时刻只有一个会请求到下游,防止缓存击穿。
- 热点 key:热点 key 是指缓存中被频繁访问的 key,导致缓存该 key 的分片或者 Redis 访问量过高。可以将可热点 key 分散存储到多个 key 上,例如将热点 key+序列号的方式存储,不同 key 存储的值都是相同的,在访问时随机访问一个 key,分散原来单 key 分片的压力;此外还可以将 key 缓存到机器内存中,避免 Redis 单节点压力过大,在新闻业务中,对于热点文章就是采用这种方式,将热点文章存储到机器内存中,避免存储热点文章 Redis 单分片请求量过大。
缓存数据一致性
当数据库中的数据变更时,如何保证缓存跟数据库中的数据一致,通常有以下几种方案:
- 更新缓存再更新 DB,
- 更新 DB 再更新缓存,
- 先更新 DB 再删除缓存,
- 删除缓存再更新 DB。
这几种方案都有可能会出现缓存跟数据库中的数据不一致的情况,最常用的还是更新 DB 再删除缓存,因为这种方案导致数据不一致的概率最小,但是也依然会存在数据不一致的问题。例如在 T1 时缓存中无数据,数据库中数据为100,线程B 查询缓存没有查询到数据,读取到数据库的数据100然后去更新缓存,但是此时线程A 将数据库中的数据更新为99,然后在 T4 时刻删除缓存中的数据,但是此时缓存中还没有数据,在 T5 的时候线程B 才更新缓存数据为100,这时候就会导致缓存跟数据库中的数据不一致。
为保证缓存与数据库数据的一致性。常用的解决方案有两种,
- 一种是延时双删,先删除缓存,后续更新数据库,休眠一会再删除缓存。文章池服务中就是利用这种方案保证数据一致性,如何实现延迟删除,是通过 go 语言中 channel 实现简单延时队列,没有引入第三方的消息队列,主要为了防止服务的复杂化;
- 另外一种可以订阅 DB 的变更 binlog,数据更新时只更新 DB,通过消费 DB 的 binlog 日志,解析变更操作进行缓存变更,更新失败时不进行消息的提交,通过消息队列的重试机制实现最终一致性。





![[python] 基于PyOD库实现数据异常检测](https://gitcode.net/LuohenYJ/article_picture_warehouse/-/raw/main/wechat/content/%E5%8A%A0%E6%B2%B9%E9%B8%AD.gif)

