性能调优
MySQL调优的五个维度
对于MySQL的性能优化,其实也可以从多个维度出发,共计优化项如下:
- ①客户端与连接层的优化:调整客户端
DB连接池的参数和DB连接层的参数。 - ②
MySQL结构的优化:合理的设计库表结构,表中字段根据业务选择合适的数据类型、索引。 - ③
MySQL参数优化:调整参数的默认值,根据业务将各类参数调整到合适的大小。 - ④整体架构优化:引入中间件减轻数据库压力,优化
MySQL架构提高可用性。 - ⑤编码层优化:根据库表结构、索引结构优化业务
SQL语句,提高索引命中率。
这五个性能优化项中,通常情况下,带来的性能收益排序为④ > ② > ⑤ > ③ > ①,不过带来的性能收益越大,也就意味着成本会更高。
MySQL连接层优化策略
从一个用户请求最终会在Java程序中分配一条线程处理,最终会变成一条SQL发往MySQL执行,而Java程序、MySQL-Server之间是通过建立网络连接的方式进行通信,这些连接在MySQL中被称为数据库连接,本质上在MySQL内部也是一条条工作线程负责执行SQL语句,那么思考一个问题:数据库连接数是越大越好吗?
线程数远超核心数,会导致线程上下文切换的开销,远大于线程执行的开销。
对于MySQL连接池的最大连接数,这点无需咱们关心,重点调整的是客户端连接池的连接数,为啥呢?因为MySQL实例一般情况下只为单个项目提供服务,你把应用程序那边的连接数做了限制,自然也就限制了服务端的连接数。但为啥不将MySQL的最大连接数和客户端连接池的最大连接数保持一致呢?这是由于有可能你的数据库实例不仅仅只为单个项目提供服务,比如你有时候会通过终端工具远程连接MySQL,如果你将两个连接池的连接数保持一致,就很有可能导致MySQL连接数爆满,最终造成终端无法连上MySQL。
客户端的连接池大小该如何设置呢?先来借鉴一下
PostgreSQL提供的计算公式:
最大连接数 = (CPU核心数 * 2) + 有效磁盘数
但是要注意:
C3P0、DBCP、Druid、HikariCP...等连接池的底层本质上是一个线程池,对于线程池而言,想要处理足够高的并发,那应该再配备一个较大的等待队列,也就是当目前池中无可用连接时,其他的用户请求/待执行的SQL语句则会加入队列中阻塞等待。
当然,上述这个公式虽说能够应对绝大部分情况,但实际业务中,还需要考虑SQL的执行时长,比如一类业务的SQL执行只需10ms,而另一类SQL由于业务过为繁琐,每次调用时会产生一个大事务,一次执行下来可能需要5s+,那这两种情况都采用相同的连接池可以吗?可以是可以,但大事务会影响其他正常的SQL,因此想要完美的解决这类问题,最好再单独开一个连接池,为大事务或执行耗时较长的SQL提供服务
偶发高峰类业务的连接数配置:
啥叫偶发高峰类业务呢?就类似于滴滴打车这类业务,在早晚上下班时间段、周末假期时间段,其流量显然会比平常高很多,对于这类业务,常驻线程数不适合太多,因为并发来临时会导致创建大量连接,而并发过后一直保持数据库连接会导致资源被占用,所以对于类似的业务,可以将最大连接数按之前的公式配置,而常驻连接数则可以配成CPU核数+1,同时缩短连接的存活时间,及时释放空闲的数据库连接,以此确保资源的合理分配。
对于最佳连接数的计算,首先要把CPU核数放首位考虑,紧接着是磁盘,最后是网络带宽,因为带宽会影响SQL执行时间,综合考虑后才能计算出最合适的连接数大小。
MySQL结构的优化方案
所谓的MySQL结构优化,主要是指三方面,即表结构、字段结构以及索引结构。
表结构的优化
InnoDB引擎基本上都会将数据操作放到内存中完成,而当一张表的字段数量越多,那么能载入内存的数据页会越少,当操作时数据不在内存,又不得不去磁盘中读取数据,这显然会很大程度上影响MySQL性能。
一张表最多最多只能允许设计
30个字段左右,否则会导致查询时的性能明显下降。有时候经常做连表查询的字段,可以适当的在一张表中冗余几个字段,这种做法的最大好处是能够减少连表查询次数,用空间换时间的思想。这里的冗余是指经常连表查询的字段。
主键的选择一定要合适。首先一张表中必须要有主键,其次主键最好是顺序递增的数值类型,最好为int类型。一张表如果业务中自带自增属性的字段,最好选择这些字段作为主键,例如学生表中的学号、职工表中的工号....,如果一张表的业务中不带有这类字段,那也可以设计一个与业务无关、无意义的数值序列字段作为主键,因为这样做最适合维护表数据(跟聚簇索引有关)。
只有当迫不得已的情况下,再考虑使用其他类型的字段作为主键,但也至少需要保持递增性,比如分布式系统中的分布式
ID,这种情况下就无法依靠数据库int自增去确保唯一性,就必须得通过雪花算法这类的ID生成策略,以此来确保ID在全局的唯一性。
④对于实时性要求不高的数据建立中间表。很多时候咱们为了统计一些数据时,通常情况下都会基于多表做联查,以此来确保得到统计所需的数据,但如若对于实时性的要求没那么高,就可以在库中建立相应的中间表,然后每日定期更新中间表的数据,从而达到减小连表查询的开销,同时也能进一步提升查询速度。
啥叫中间表呢?举个最简单的例子,比如排名类的统计业务,就可以这么实现,好比
MOBA游戏中的战力排名,以英雄联盟、王者荣耀为例,由于每个玩家的战力在一天内都会不断变化,同时一个用户在任何时间段都有可能去查询战力排名,所以每次查询都基于数据库的多张表去联查,基于这些游戏的用户量而言,其带来的开销必然的巨大的,因此可以对英雄战力设计一张中间表,每日凌晨五点统计一次.....
上述这种做法也是大多数MOBA游戏的实现方式,但实际场景中也会结合Redis来实现,毕竟这种方式速度会更快,但这里就不多拓展了,总之记住一点即可:适当的场景下建立中间表,是一种能够带来不小性能收益的手段。
⑤根据业务特性为每张不同的表选择合适的存储引擎。其实存储引擎这块主要是在InnoDB、MyISAM两者之间做抉择,对于一些经常查询,很少发生变更的表,就可以选择MyISAM引擎,比如字典表、标签表、权限表....,因为读远大于写的表中,MyISAM性能表现会更佳,其他的表则可以使用默认的InnoDB引擎。
字段结构的优化
字段结构的优化其实主要指选择合适的数据类型。
- ①在保证足够使用的范围内,选择最小数据类型,因为它们会占用更少的磁盘、内存和
CPU缓存,同时在处理速度也会更快。 - ②尽量避免索引字段值为
NULL,定义字段时应尽可能使用NOT NULL关键字,因为字段空值过多会影响索引性能。 - ③在条件允许的情况下,尽量使用最简单的类型代替复杂的类型,如
IP的存储可以使用int而并非varchar,因为简单的数据类型,操作时通常需要的CPU资源更少。
索引结构的优化
索引结构优化主要是指根据业务创建更合适的索引,这里主要可以从四个方面考虑,下面一起来聊一聊。
①索引字段的组成尽量选择多个,如果一个表中需要建立多个索引,应适当根据业务去将多个单列索引组合成一个联合索引,这样做一方面可以节省磁盘空间,第二方面还可以充分使用索引覆盖的方式查询数据,能够在一定程度上提升数据库的整体性能。
②对一个值较长的字段建立索引时,可以选用字段值的前
N个字符创建索引,也就是对于值较长的字段尽量建立前缀索引,而不是通过完整的字段值建立索引,因为索引字段值越小,单个B+Tree的节点中能存储的索引键会越多,一个节点存下的索引键越多,索引树会越矮,查询性能自然会越高。
③索引类型的选择一定要合理,对于经常做模糊查询的字段,可以建立全文索引来代替普通索引,因为基于普通索引做
like查询会导致索引失效,而采用全文索引的方式做模糊查询效率会更高更快,并且全文索引的功能更为强大。
④索引结构的选择可以根据业务进行调整,在某些不会做范围查询的字段上建立索引时,可以选用
hash结构代替B+Tree结构,因为Hash结构的索引是所有数据结构中最快的,散列度足够的情况下,复杂度仅为O(1)。
调整InnoDB缓冲区
在MySQL参数中,首先最值得调整的就是InnoDB缓冲区的大小,因为InnoDB将是MySQL启动后使用最多的引擎,所以为其分配一个足够大的缓冲区,能够在最大程度上提升MySQL的性能。最佳比例应该控制在70~75%左右,比如一台服务器的内存为32GB,将innodb_buffer_pool_size = 22938M(23GB)左右最合理。
为
InnoDB的缓冲区分配了足够的大小后,运行期间InnoDB会根据实际情况,去自动调整内部各区域中的数据,如热点数据页、自适应哈希索引.....,调整该区域的大小后,能直接让MySQL性能上升一个等级。
同时当InnoDB缓冲区空间大于1GB时,InnoDB会自动将缓冲区划分为多个实例空间,这样做的好处在于:多线程并发执行时,可以减少并发冲突。MySQL官方的建议是每个缓冲区实例必须大于1GB,因此如果机器内存较小时,例如8/16GB,可以指定为1GB,但是机器内存够大时,比如达到了32GB/64GB甚至更高,哪可以适当将每个缓冲区实例调整到2GB左右。
比如现在假设缓冲区共计拥有
40GB内存,哪设置将缓冲区实例设置为innodb_buffer_pool_instances = 20个比较合适。
调整工作线程的缓冲区
除开可以调整InnoDB的缓冲区外,同时还可以调大sort_buffer、read_buffer、join_buffer几个区域,这几个区属于线程私有区域,也就意味着每条线程都拥有这些区域:
sort_buffer_size:排序缓冲区大小,影响group by、order by...等排序操作。read_buffer_size:读取缓冲区大小,影响select...查询操作的性能。join_buffer_size:联查缓冲区大小,影响join多表联查的性能。
对于这些区域,最好根据机器内存来设置为一到两倍MB,啥意思呢?比如4GB的内存,建议将其调整为4/8MB、8GB的内存,建议将其调整为8/16MB.....,但这些区域的大小最好控制在64MB以下,因为线程每次执行完一条SQL后,就会将这些区域释放,所以再调大也没有必要了。
OK~,对于排序查询的操作,还可以调整一个参数:
max_length_for_sort_data,这个参数关乎着MySQL排序的方式,如果排序字段值的最大长度小于该值,则会将所有要排序的字段值载入内存排序,但如果大于该值时,则会一批一批的加载排序字段值进内存,然后一边加载一边做排序。
上述这两种排序算法,显然第一种效率更高,毕竟这种方式是基于所有的数据做排序,第二种算法则是一批一批数据做排序,每批数据都可能会打乱之前排好序的数据,因此可以适当调大该参数的值(但这个值究竟多少合适,要根据具体的业务来做抉择,否则交给还是使用MySQL自己来控制)。
调整临时表空间
同时还可以调整tmp_table_size、max_heap_table_size两个参数,这两个参数主要是限制临时表可用的内存空间,当创建的临时表空间占用超过tmp_table_size时,就会将其他新创建的临时表转到磁盘中创建,这显然是十分违背临时表的设计初衷,毕竟创建临时表的目的就是用来加快查询速度,结果又最后又把临时表放到磁盘中去了,这反而还多了一步开销。
那么这两个参数该设置多大呢?这要根据
show global status like 'created_tmp%';的统计信息来决定,用统计出来的信息:Created_tmp_disk_tables / Created_tmp_tables * 100% = 120%,达到这个标准就比较合适,但调整这个区域的值需要反复重启MySQL以及压测,因此比较费时间,如果你在项目中很少使用临时表,哪也可以不关心这块参数的调整。
调整空闲线程的存活时间
兜兜转转再回到数据库连接数的配置,之前讲到过:其实对于MySQL最大连接数无需做过多控制,客户端连接池那边做了调整即可,对于这点是没错的,可以通过下述命令查看数据库连接的峰值:
show global status like 'Max_used_connections';
一般在客户端做了连接数控制后,这个峰值一般都会在客户端最大连接数的范围之内,对于数据库连接这块唯一需要稍微调整的即是空闲连接的超时时间,即wait_timeout、interactive_timeout两个参数,这两个参数必须一同设置,否则不会生效,MySQL内部默认为8小时,也就是一个连接断开后,默认也会将对应的工作线程缓存八小时后再销毁,这里我们可以手动调整成30min~1h左右,可以让无用的连接能及时释放,减少资源的占用。
架构优化与SQL优化
变更项目的整体架构,这是性能优化收益最大的手段。
对于架构优化主要牵扯两块,一方面是从整个项目的角度出发,引入一些中间件来优化整体性能。另一方面则是调整
MySQL的部署架构,以此来确保可承载更大的流量访问,提高数据层的整体吞吐,下面逐个介绍一些常用的架构。
引入缓存中间件解决读压力
正常的项目业务中,往往读请求的数量远超写请求,如果将所有的读请求都落入数据库处理,这自然会对MySQL造成巨大的访问压力,严重的情况下甚至会由于流量过大,直接将数据库打到宕机,因此为了解决这系列问题,通常都会在应用程序和数据库之间架设一个缓存,例如最常用的Redis,关系图如下:
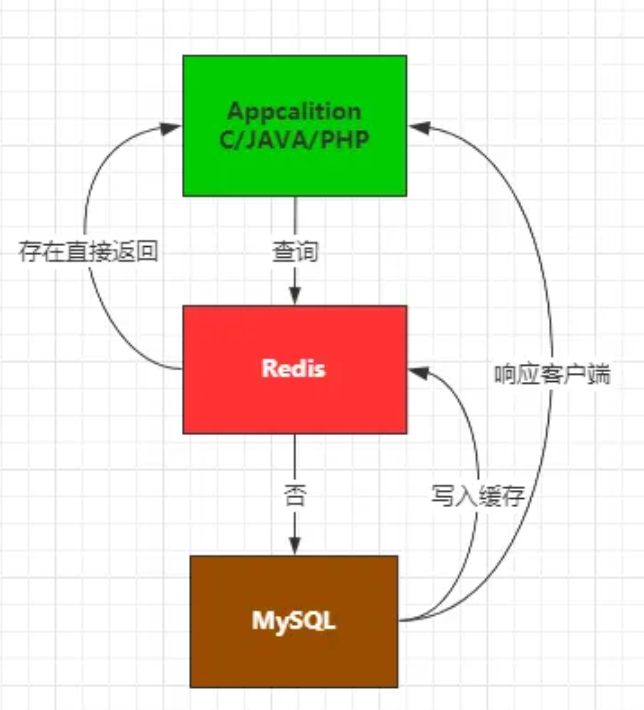
在项目中引入Redis作为缓存后,在缓存Key设计合理的情况下,至少能够为MySQL分担70%以上的读压力,查询MySQL之前先查询一次Redis,Redis中有缓存数据则直接返回,没有数据时再将请求交给MySQL处理,从MySQL查询到数据后,再次将数据写入Redis,后续有相同请求再来读取数据时,直接从Redis返回数据即可。
引入消息中间件解决写压力
前面项目中引入Redis后,能够在很大程度上减轻MySQL的读请求压力,但当业务系统中的写操作也较为频繁时又该怎么办呢?Redis在这里似乎只能分担读操作的流量呀?这时就可以引入MQ消息中间件做削峰填谷,关系图如下:
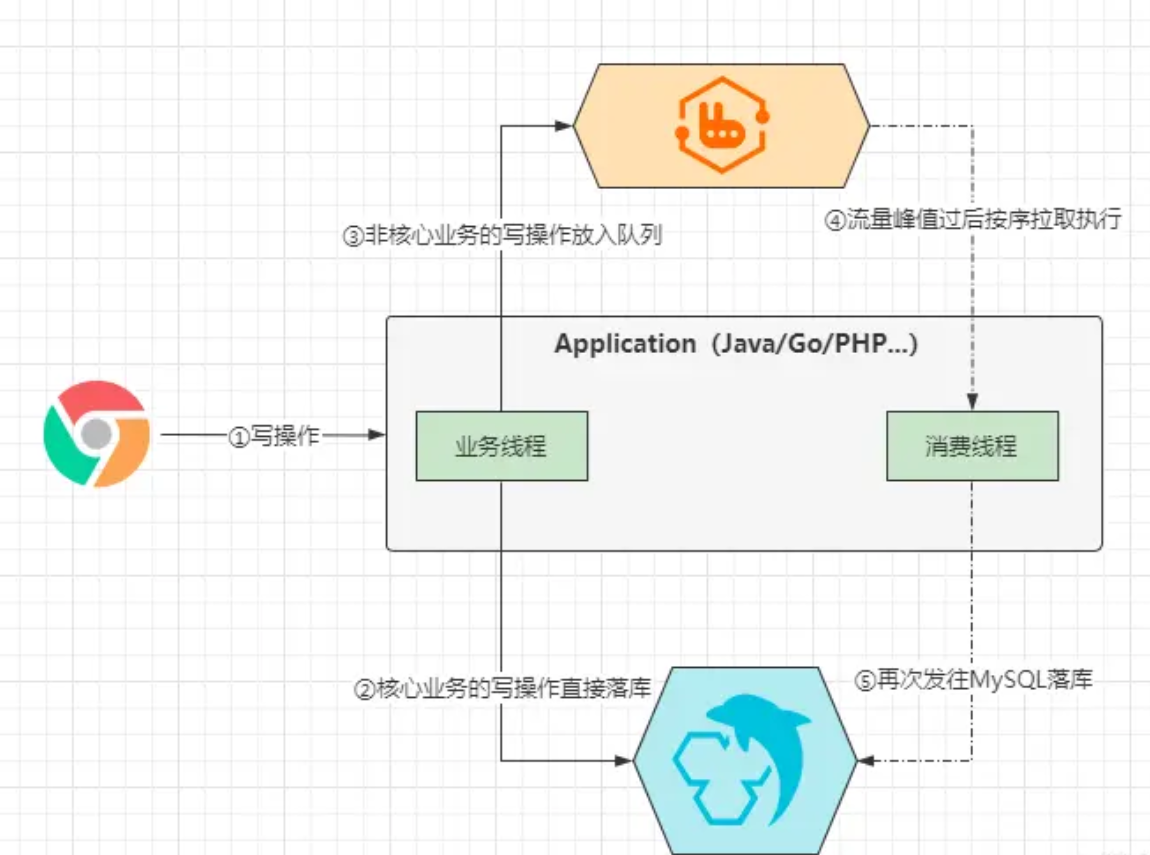
上面这幅图看起来就没有前面那张图容易理解,这里结合业务来说明一下,还是拿经典的下单业务来说明情况,一个下单业务通常由「提交订单、支付费用、扣减库存、修改订单状态、添加发票记录、添加附赠服务....」这一系列操作组成,其中「提交订单、支付费用」属于核心业务,因此当用户下单时,这两类请求可以发往MySQL执行落库操作,而对于「扣减库存、修改订单状态、添加发票记录、添加附赠服务....」这类操作则可以发往MQ,当写入MQ成功,则直接返回客户端下单成功,后续再由消费线程去按需拉取后执行。
当然,对于「扣减库存」而言,其实在
Redis中也会缓存商品信息,在扣减库存时仅仅只会减掉Redis中的商品库存,确保其他用户看到的库存信息都是实时的,最终的减库存操作,是去异步消费MQ中的消息后,最终才落库的。
经过MQ做了流量的削峰填谷后,这能够在极大的程度上减轻MySQL的写压力,能够将写压力控制到一个相较平缓的程度,防止由于大量写请求直接到达MySQL,避免负载过高造成的宕机现象出现。
MySQL主从读写分离
下面则来介绍一些
MySQL的架构优化方案,分别是指三种:主从架构、双主架构、分库分表架构。
主从复制,这是大多数中间件都会存在的一种高可用机制,而MySQL中也存在这种架构,也就是使用两台服务器来部署两个MySQL节点,一台为主机,另一台为从机,从节点会一直不断的从主节点上同步增量数据,当主节点发生故障时,从节点可以替换原本的主节点,以此来为客户端提供正常服务,架构模型如下:
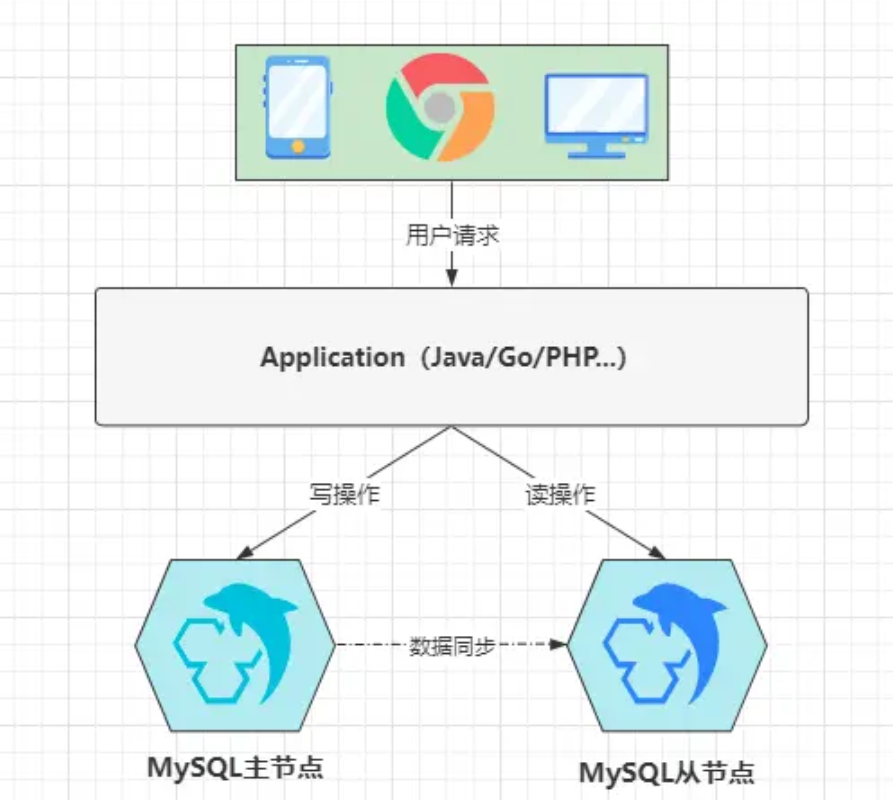
在上图中就是一个典型的主从架构,但如果从节点仅仅只是作为一个备胎,这难免有些浪费资源,因此可以在主从架构的模式下,再略微做些调整,即实现读写分离,由于读操作并不会变更数据,所以对于读请求可以分发到从节点上处理,对于会引发数据变更的写请求,则分发到主节点处理,这样从而能够进一步提升MySQL的整体性能。
主节点的数据变更后,从节点也会基于
bin-log日志去同步数据,但这种模式下会存在些许的数据不一致性,因为同步是需要时间的,向主节点修改一条数据后,立马去从节点中查询,这时不一定能够看到最新的数据,因为这时数据也许还未被同步过来。
哪上述这个数据不一致性问题能不能有好的办法去解决呢?其实并没有太好的办法,选择用这种方案来提升性能,必然也会出现些许问题,这也是你必须要接受的,如果项目业务对数据实时性要求特别高,哪就不要考虑主从架构。
MySQL双主双写热备
前面主从读写分离的方案,更适用于一些读大于写的业务,但对于一些类似于仓储这种写大于读的项目业务,这种方案带来的性能收益不见得有多好,因此从机分担的读压力,可能仅是系统的10~20%流量,因此对于这种场景下,双主双写(双主热备)方案才是最佳选择,其架构图如下:
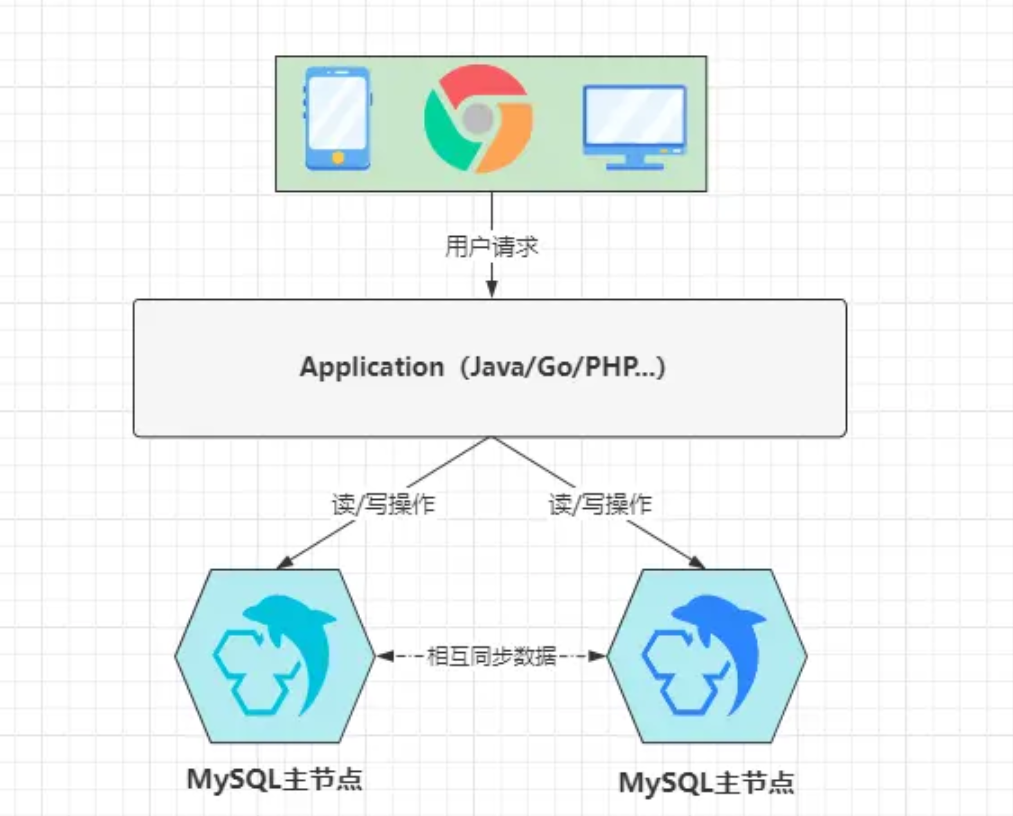
似乎看起来和之前的图差不多,但在这里的两个MySQL节点都为主,同时它们也都为从,啥意思呢?其实就是指这两个节点互为主从,两者之间相互同步数据,同时都具备处理读/写请求的能力,当出现数据库的读/写操作时,可以将请求抛给其中任意一个节点处理。
但是为了兼容两者之间的数据,对于每张表的主键要处理好,如果表的主键是
int自增类型的,请一定要手动设置一下自增步长和起始值,比如这里有两个MySQL节点,那么可以将步长设置为2,起始值分别为1、2,这样做的好处是啥?能够确保主键的唯一性,设置后两个节点自增ID的序列如下:
节点1:[1、3、5、7、9、11、13、15、17、19.....]
节点2:[2、4、6、8、10、12、14、16、18、20.....]
当插入数据的SQL语句发往节点1时,会按照奇数序列自增ID,发往节点2时会以偶数序列自增ID,然后双方相互同步数据,最终两个MySQL节点都会具备完整的数据,因此后续的读请求,无论发往哪个节点都可以读到数据。
有人或许会思考,既然两个节点互为主从可以实现双主双写,哪能不能搞三个节点、四个节点呢?答案是当然可以,不过没必要这么做,因为当需要上三主、四主....的项目,直接就做分库分表更实在,因为这种多主模式存在一个天大的弊端!!
MySQL分库分表思想
刚刚在聊多主架构时,提到过多主模式有一个天大的弊端!这个弊端是指存储容量的上限+木桶效应,因为多主模式中的每个节点都会存储完整的数据,因此当数据增长达到硬件的最大容量时,就无法继续写入数据了,此时只能通过加大磁盘的形式进一步提高存储容量,但硬件也不可能无限制的加下去,而且由于多主是基于主从架构实现的,因为具备木桶效应,要加得所有节点一起加,否则另一个节点无法同步写入数据时,就会造成所有节点无法写入数据。
也正是由于上述这个原因,因此我才不建议采用三主、四主....这种架构模式,毕竟需要用到这么多
MySQL节点的业务,其数据的增长速度自然不慢,因此在存储容量方面很容易抵达瓶颈,这种情况下选择分库分表才是最佳方案。
分库分表相信每位接触过数据库的小伙伴都听说过,这实则是一种分布式存储的思想,如下:
上述是分库分表的一种情况,这种分库的模式被称为垂直分库,也就是根据业务属性的不同,会创建不同的数据库,然后由不同的业务连接不同的数据库,各自之间数据分开存储,节点之间数据不会同步,以这种方式来部署MySQL,即提高了数据库的整体吞吐量和并发能力,同时也不存在之前的存储容量的木桶问题。
但不要认为分库分表是一种很完美的解决方案,实际上当你对项目做了分库分表之后,带来的问题、要解决的问题只会更多,只不过相较于分库分表带来的收益而言,解决问题的成本是值得的,所以才会使用分库分表技术。
编写高质量SQL
编写SQL时的注意点
在写SQL的时候,往往很多时候的细节不注意,就有可能导致索引失效,也因此会造成额外的资源开销,而我们要做的就是避开一些误区,确保自己的SQL在执行过程中能够最大程度上节省资源、缩短执行时间,下面罗列一些经典的SQL注意点
-
查询时尽量不要使用 *****
- ①分析成本变高。一条
SQL在执行前都会经过分析器解析,当使用*时,解析器需要先去解析出当前要查询的表上*表示哪些字段,因此会额外增加解析成本。 - ②网络开销变大。返回数据时需要经过网络传输,而由于返回的是所有字段数据,因此网络数据包的体积就会变大,从而导致占用的网络带宽变高,影响数据传输的性能和资源开销。
- ③内存占用变高。
InnoDB引擎,当查询一条数据时都会将其结果集放入到BufferPool的数据缓冲页中,如果每次用*来查询数据,查到的结果集自然会更大,占用的内存也会越大,单个结果集的数据越大,整个内存缓冲池中能存下的数据也就越少,当其他SQL操作时,在内存中找不到数据,又会去触发磁盘IO,最终导致MySQL整体性能下降。 - 基于非主键字段查询可能会产生回表现象,如果是基于联合索引查询数据,需要的结果字段在联合索引中有时,可能通过索引覆盖原理去读数据,从而减少一次回表查询。但使用
*查询所有字段数据时,由于联合索引中没有完整数据,因此只能做一次回表从聚簇索引中拿数据。
- ①分析成本变高。一条
-
连表查询时尽量不要关联太多表
一般来说,交互型的业务中,关联的表数量应当控制在
5张表之内 -
多表查询时一定要以小驱大
-
不要使用like左模糊和全模糊查询
-
查询时尽量不要对字段做空值判断
当出现基于字段做空值判断的情况时,会导致索引失效,因为判断
null的情况不会走索引 -
不要在条件查询
=前对字段做任何运算 -
避免频繁创建、销毁临时表
-
尽量将大事务拆分为小事务执行
索引优化参考项
explain`工具中的每个字段值,字段数量也比较多,但在做索引优化时,值得咱们参考的几个字段为:
key:如果该值为空,则表示未使用索引查询,此时需要调整SQL或建立索引。type:这个字段决定了查询的类型,如果为index、all就需要进行优化。rows:这个字段代表着查询时可能会扫描的数据行数,较大时也需要进行优化。filtered:这个字段代表着查询时,表中不会扫描的数据行占比,较小时需要进行优化。Extra:这个字段代表着查询时的具体情况,在某些情况下需要根据对应信息进行优化。