一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | 400 | 450 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 70 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 30 | 25 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 50 | 60 |
| · Design | · 具体设计 | 60 | 70 |
| · Coding | · 具体编码 | 120 | 140 |
| · Code Review | · 代码复审 | 40 | 45 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 80 | 70 |
| · Test Repor | · 测试报告 | 40 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 25 |
| ·合计 | 830 | 790 |
github仓库链接:https://github.com/moyuer147/3122004517/tree/master
二、模块接口的设计和实现
类
- COS类功能为计算余弦相似度
- Getwordcount类功能为计算每个词语出现的次数
- IK_analyzer类为引入maven依赖使用ikanalyzer进行句子的分词
- IO类为读取文件并返回字符串
- JavaBreakIterator类为文档断句,分成句子装入list里面
- Main类为实现函数
- origtxt类为原文档的数据,使用static修饰减少代码运行次数
- Union类为两个文档出现过的词语的并集
类之间的关系
先使用IO读取文档内容转化成字符串形式,;然后通过JavaBreakIterator将字符串断句,分成一个个句子装入list集合中;IK_analyzer负责将list中的每个句子进行分词,装入list集合中记录所有词语;Getwordcount创建一个map集合将list集合中所有分词的出现次数进行统计,键是词语,值是词语的出现次数;Union把两个文档出现过的分词进行并集计算,存储在list中;COS将map集合中的值通过与Union产生的并集进行向量化储存在一维数组中,把两个一维数组进行余弦计算,再乘两个文本字数的占比,即可得出两个文本的余弦相似度,即是文本的重复率;最后由main实现。
算法的关键
在COS类中,参数为两个文本分词后的list集合和Union的并集(两个文本出现过的词语的集合),先通过Getwordcount把list转化为map,遇到重复的词语值+1,这样就得到了每个词语和其出现的次数,通过for循环遍历Union的集合,for(i = 0; i < union.size(); i++)arr[i] = map.getOrDefault(union.get(i), 0);,生成一个向量化的数组,然后把两个数组的成员分别进行余弦运算。
独到之处
由于原文本每次查重都会使用到,所以把原文本的所有数据用static修饰,使得原文本的数据在程序运行过程中只需运行一次,减少计算量;引入了maven依赖的中文分词法,减少工作量;使用TreeSet集合记录文本的分词,将分词按一定规律的顺序排序,在后续遍历查找对比的时候减少代码的复杂度。
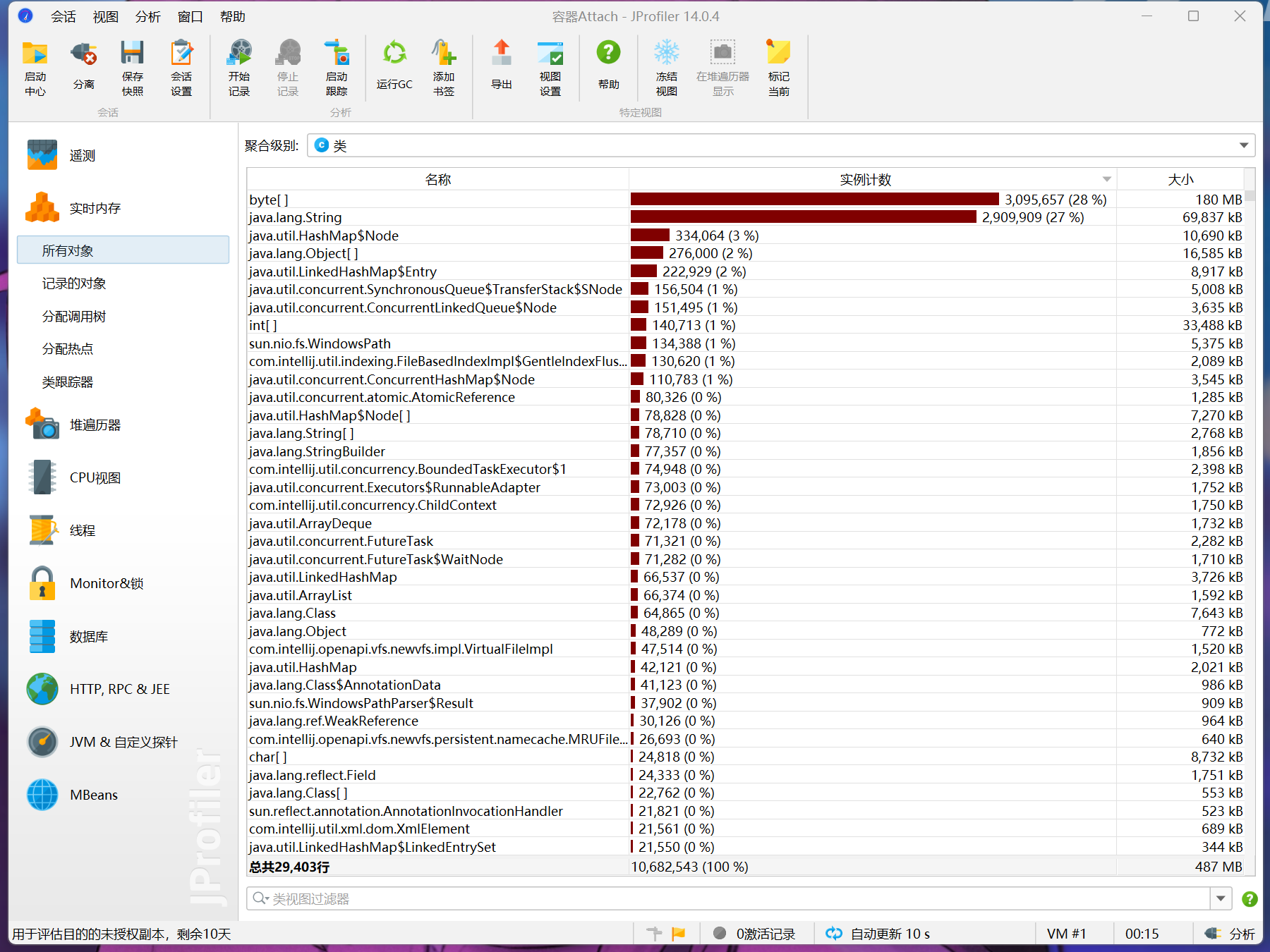
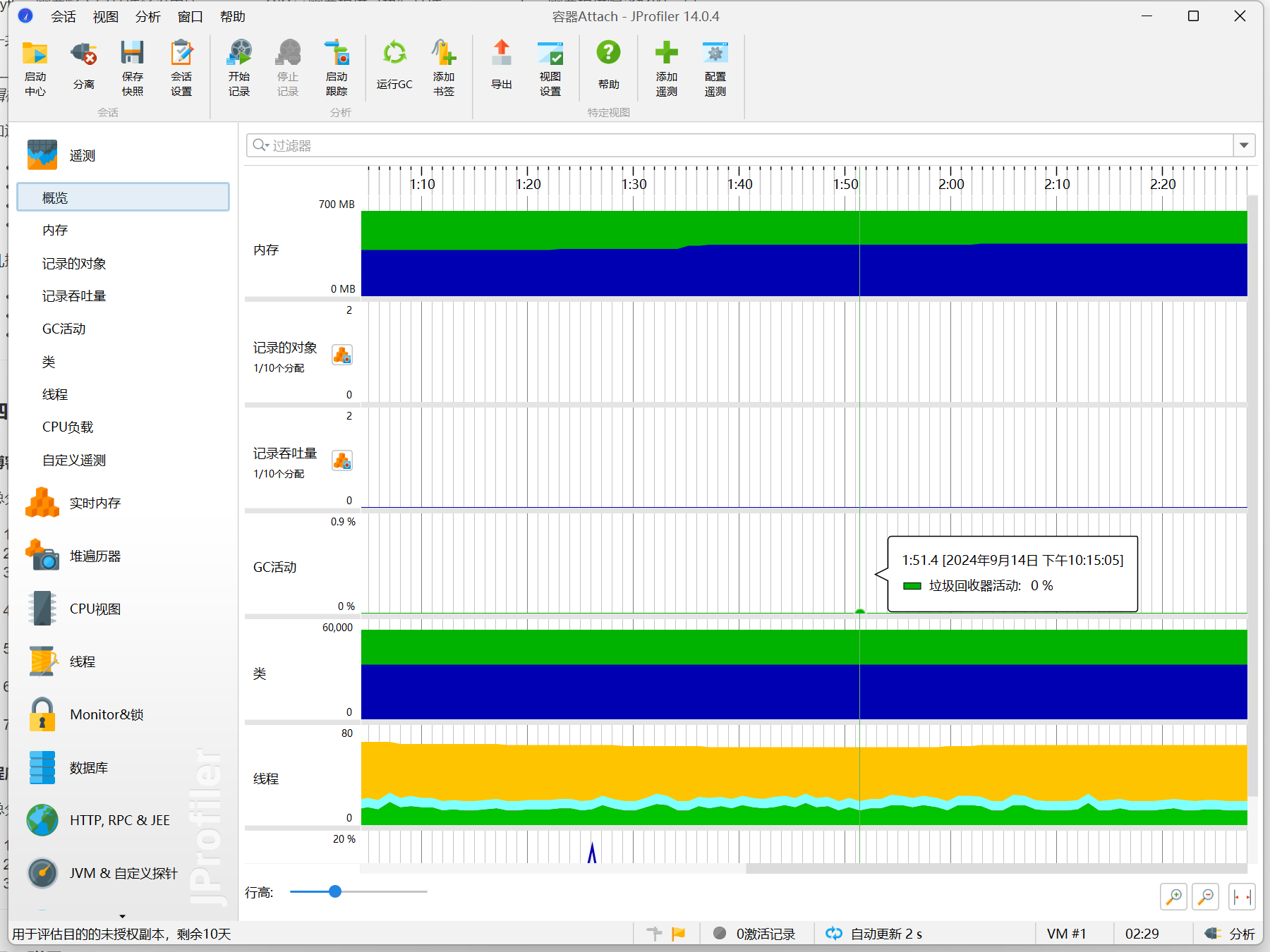
性能改进
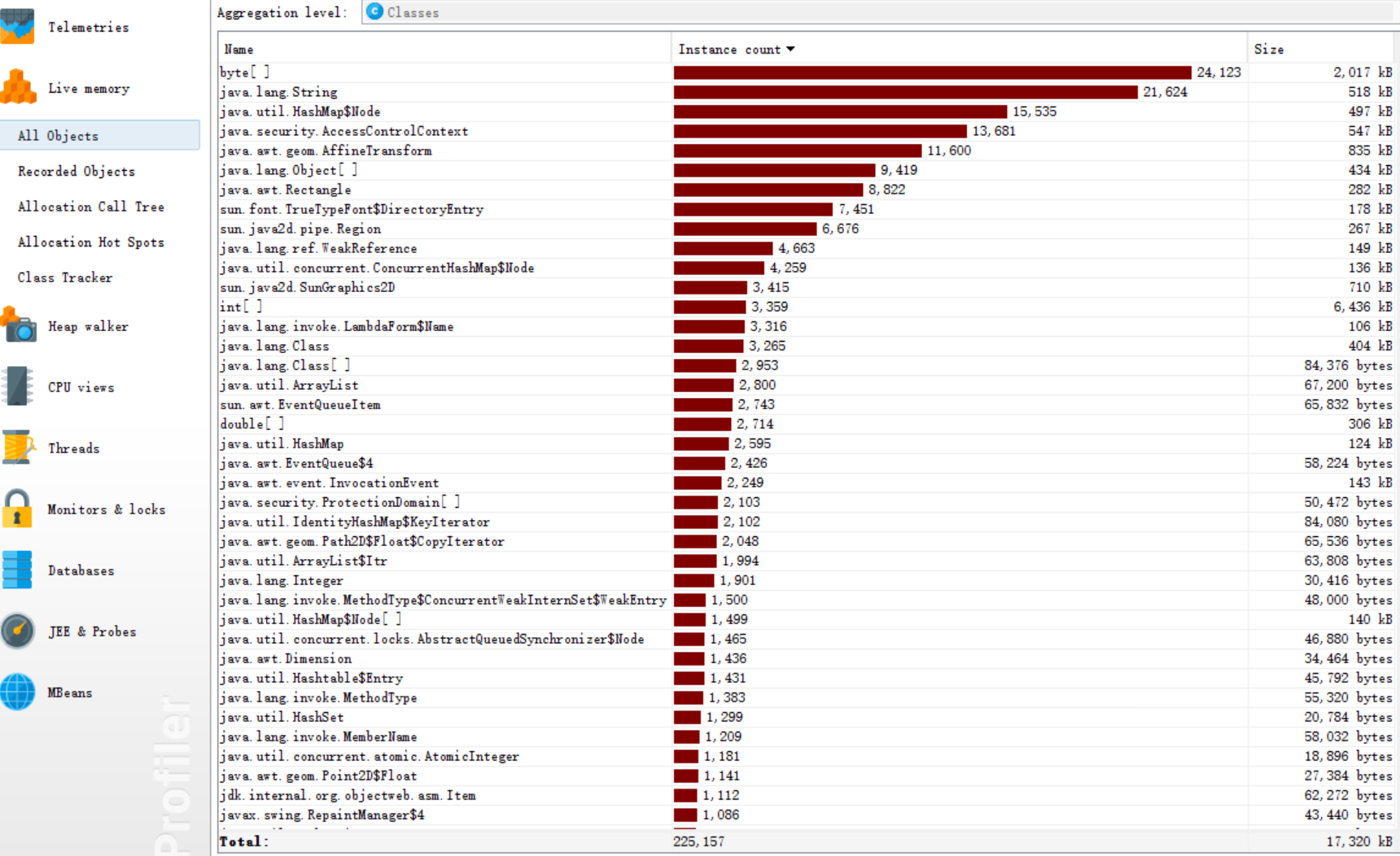
因为使用了FileReader的带参构造,用byte数组接收字符串,再转化成string,所以占用内存高。

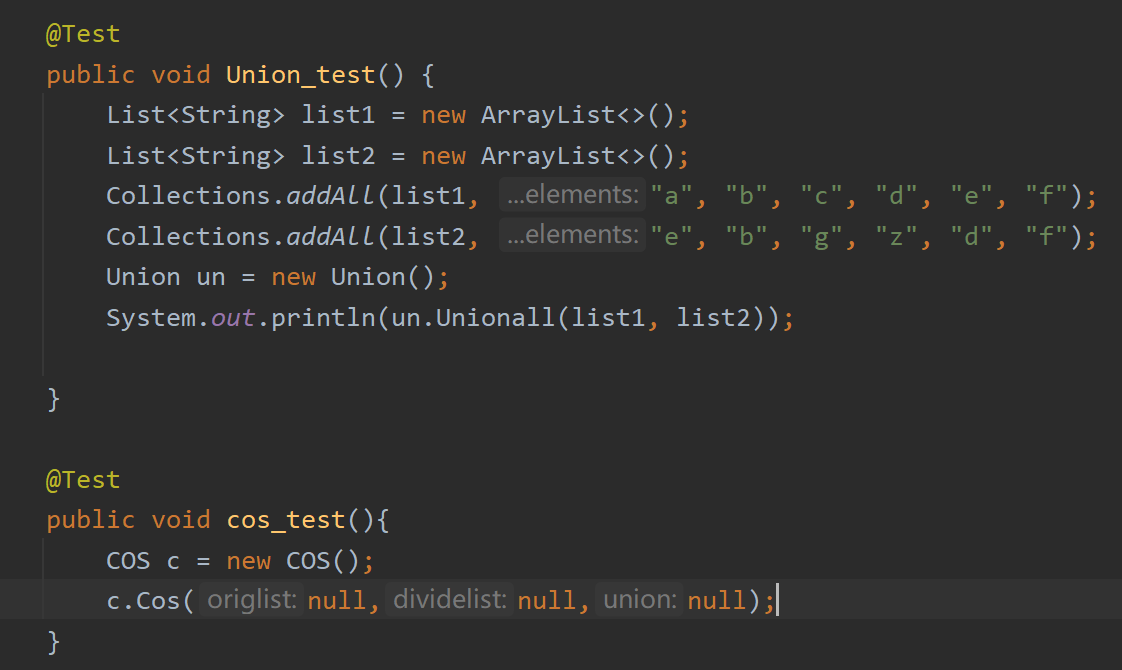
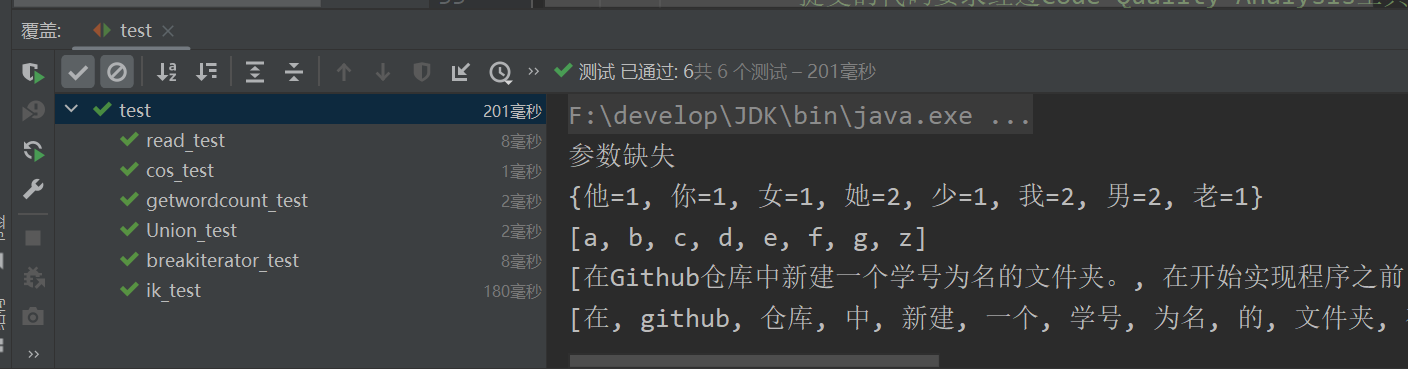
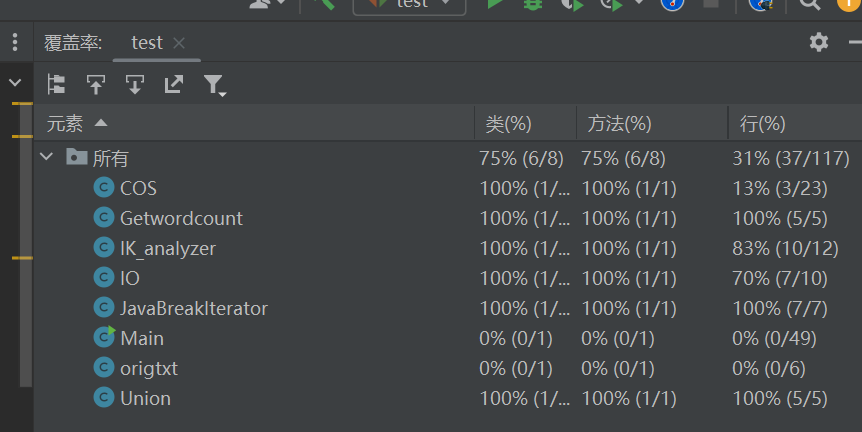
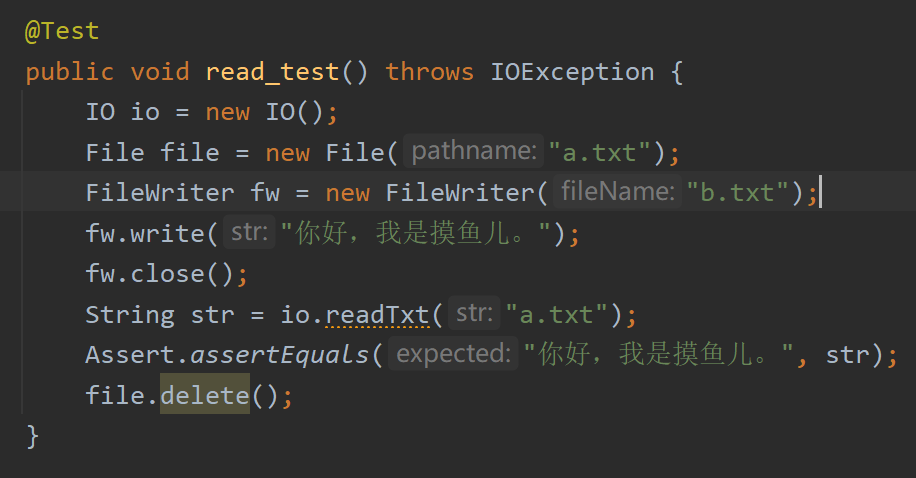
单元测试

异常处理说明
找不到文件或者文件不可读取:

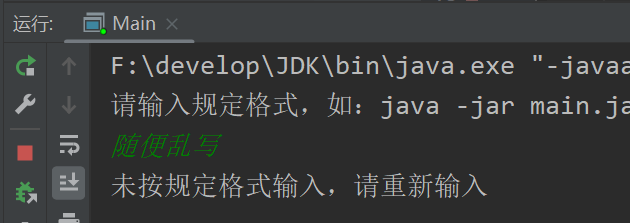
未按指定格式输入:
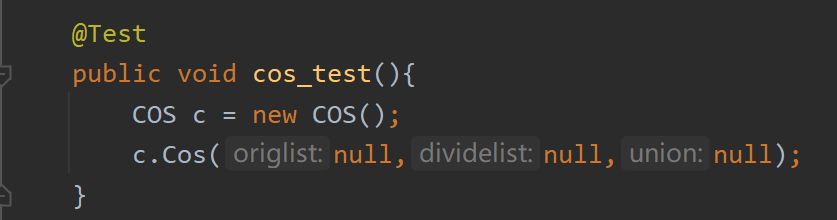
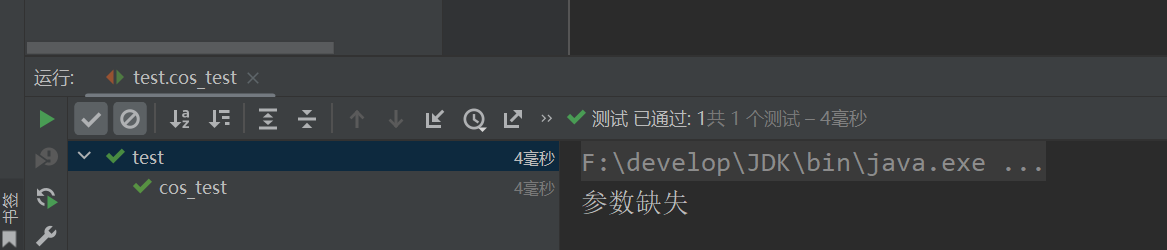
参数丢失:


![[安洵杯 2019]easy_web](https://img2024.cnblogs.com/blog/3374335/202409/3374335-20240914212802336-470572184.png)

![[BJDCTF2020]Cookie is so stable](https://img2024.cnblogs.com/blog/3374335/202409/3374335-20240914201920172-402012060.png)
