来自:https://draveness.me/whys-the-design-tcp-message-frame/
为什么这么设计(Why’s THE Design)是一系列关于计算机领域中程序设计决策的文章,我们在这个系列的每一篇文章中都会提出一个具体的问题并从不同的角度讨论这种设计的优缺点、对具体实现造成的影响。如果你有想要了解的问题,可以在文章下面留言。
TCP/IP 协议簇建立了互联网中通信协议的概念模型,该协议簇中的两个主要协议就是 TCP 和 IP 协议。TCP/ IP 协议簇中的 TCP 协议能够保证数据段(Segment)的可靠性和顺序,有了可靠的传输层协议之后,应用层协议就可以直接使用 TCP 协议传输数据,不在需要关心数据段的丢失和重复问题1。
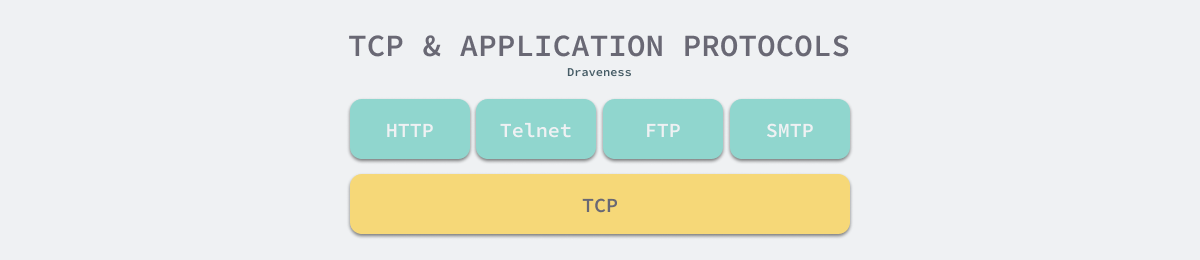
图 1 - TCP 协议与应用层协议
IP 协议解决了数据包(Packet)的路由和传输,上层的 TCP 协议不再关注路由和寻址2,那么 TCP 协议解决的是传输的可靠性和顺序问题,上层不需要关心数据能否传输到目标进程,只要写入 TCP 协议的缓冲区的数据,协议栈几乎都能保证数据的送达。
当应用层协议使用 TCP 协议传输数据时,TCP 协议可能会将应用层发送的数据分成多个包依次发送,而数据的接收方收到的数据段可能有多个『应用层数据包』组成,所以当应用层从 TCP 缓冲区中读取数据时发现粘连的数据包时,需要对收到的数据进行拆分。
粘包并不是 TCP 协议造成的,它的出现是因为应用层协议设计者对 TCP 协议的错误理解,忽略了 TCP 协议的定义并且缺乏设计应用层协议的经验。本文将从 TCP 协议以及应用层协议出发,分析我们经常提到的 TCP 协议中的粘包是如何发生的:
- TCP 协议是面向字节流的协议,它可能会组合或者拆分应用层协议的数据;
- 应用层协议的没有定义消息的边界导致数据的接收方无法拼接数据;
很多人可能会认为粘包是一个比较低级的甚至不值得讨论的问题,但是在作者看来这个问题还是很有趣的,不是所有人都系统性地学过基于 TCP 的应用层协议设计,也不是所有人对 TCP 协议都有那么深入的理解,相信很多人学习编程的过程都是自底向上的,所以作者认为这是一个值得回答的问题,我们应该传递正确的知识,而不是负面的和居高临下的情绪。
面向字节流
TCP 协议是面向连接的、可靠的、基于字节流的传输层通信协议3,应用层交给 TCP 协议的数据并不会以消息为单位向目的主机传输,这些数据在某些情况下会被组合成一个数据段发送给目标的主机。
Nagle 算法是一种通过减少数据包的方式提高 TCP 传输性能的算法4。因为网络 带宽有限,它不会将小的数据块直接发送到目的主机,而是会在本地缓冲区中等待更多待发送的数据,这种批量发送数据的策略虽然会影响实时性和网络延迟,但是能够降低网络拥堵的可能性并减少额外开销。
在早期的互联网中,Telnet 是被广泛使用的应用程序,然而使用 Telnet 会产生大量只有 1 字节负载的有效数据,每个数据包都会有 40 字节的额外开销,带宽的利用率只有 ~2.44%,Nagle 算法就是在当时的这种场景下设计的。
当应用层协议通过 TCP 协议传输数据时,实际上待发送的数据先被写入了 TCP 协议的缓冲区,如果用户开启了 Nagle 算法,那么 TCP 协议可能不会立刻发送写入的数据,它会等待缓冲区中数据超过最大数据段(MSS)或者上一个数据段被 ACK 时才会发送缓冲区中的数据。

图 2 - Nagle 算法
几十年前还会发生网络拥塞的问题,但是今天的网络带宽资源不再像过去那么紧张,在默认情况下,Linux 内核都会使用如下的方式默认关闭 Nagle 算法:
Linux 内核中使用如下所示的 tcp_nagle_test 函数测试我们是否应该发送当前的 TCP 数据段,感兴趣的读者可以以这段代码为入口详细了解 Nagle 算法在今天的实现:
Nagle 算法确实能够在数据包较小时提高网络带宽的利用率并减少 TCP 和 IP 协议头带来的额外开销,但是使用该算法也可能会导致应用层协议多次写入的数据被合并或者拆分发送,当接收方从 TCP 协议栈中读取数据时会发现不相关的数据出现在了同一个数据段中,应用层协议可能没有办法对它们进行拆分和重组。
除了 Nagle 算法之外,TCP 协议栈中还有另一个用于延迟发送数据的选项 TCP_CORK,如果我们开启该选项,那么当发送的数据小于 MSS 时,TCP 协议就会延迟 200ms 发送该数据或者等待缓冲区中的数据超过 MSS5。
无论是 TCP_NODELAY 还是 TCP_CORK,它们都会通过延迟发送数据来提高带宽的利用率,它们会对应用层协议写入的数据进行拆分和重组,而这些机制和配置能够出现的最重要原因是 — TCP 协议是基于字节流的协议,其本身没有数据包的概念,不会按照数据包发送数据。
消息边界
如果我们系统性地学习过 TCP 协议以及基于 TCP 的应用层协议设计,那么设计一个能够被 TCP 协议栈任意拆分和组装数据包的应用层协议就不会有什么问题。既然 TCP 协议是基于字节流的,这其实就意味着应用层协议要自己划分消息的边界。
如果我们能在应用层协议中定义消息的边界,那么无论 TCP 协议如何对应用层协议的数据包进程拆分和重组,接收方都能根据协议的规则恢复对应的消息。在应用层协议中,最常见的两种解决方案就是基于长度或者基于终结符(Delimiter)。

图 3 - 实现消息边界的方法
基于长度的实现有两种方式,一种是使用固定长度,所有的应用层消息都使用统一的大小,另一种方式是使用不固定长度,但是需要在应用层协议的协议头中增加表示负载长度的字段,这样接收方才可以从字节流中分离出不同的消息,HTTP 协议的消息边界就是基于长度实现的:
在上述 HTTP 消息中,我们使用 Content-Length 头表示 HTTP 消息的负载大小,当应用层协议解析到足够的字节数后,就能从中分离出完整的 HTTP 消息,无论发送方如何处理对应的数据包,我们都可以遵循这一规则完成 HTTP 消息的重组6。
不过 HTTP 协议除了使用基于长度的方式实现边界,也会使用基于终结符的策略,当 HTTP 使用块传输(Chunked Transfer)机制时,HTTP 头中就不再包含 Content-Length 了,它会使用负载大小为 0 的 HTTP 消息作为终结符表示消息的边界。
当然除了这两种方式之外,我们可以基于特定的规则实现消息的边界,例如:使用 TCP 协议发送 JSON 数据,接收方可以根据接收到的数据是否能够被解析成合法的 JSON 判断消息是否终结。
总结
TCP 协议粘包问题是因为应用层协议开发者的错误设计导致的,他们忽略了 TCP 协议数据传输的核心机制 — 基于字节流,其本身不包含消息、数据包等概念,所有数据的传输都是流式的,需要应用层协议自己设计消息的边界,即消息帧(Message Framing),我们重新回顾一下粘包问题出现的核心原因:
- TCP 协议是基于字节流的传输层协议,其中不存在消息和数据包的概念;
- 应用层协议没有使用基于长度或者基于终结符的消息边界,导致多个消息的粘连;
网络协议的学习过程非常有趣,不断思考背后的问题能够让我们对定义有更深的认识。到最后,我们还是来看一些比较开放的相关问题,有兴趣的读者可以仔细思考一下下面的问题:
- 基于 UDP 协议的应用层协议应该如何设计?会出现粘包的问题么?
- 有哪些应用层协议使用基于长度的分帧?又有哪些使用基于终结符的分帧?
如果对文章中的内容有疑问或者想要了解更多软件工程上一些设计决策背后的原因,可以在博客下面留言,作者会及时回复本文相关的疑问并选择其中合适的主题作为后续的内容。