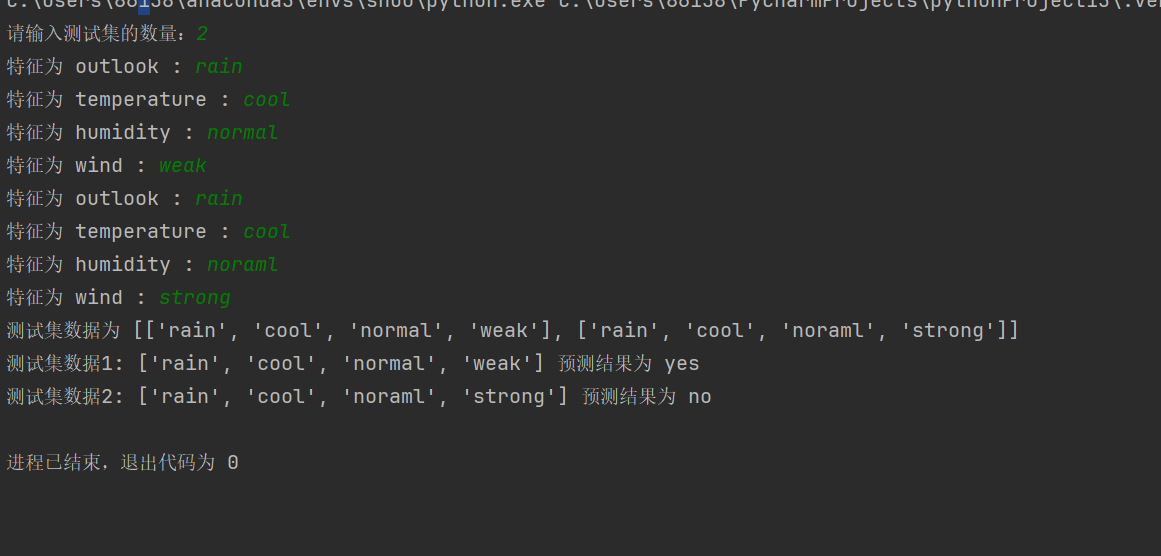
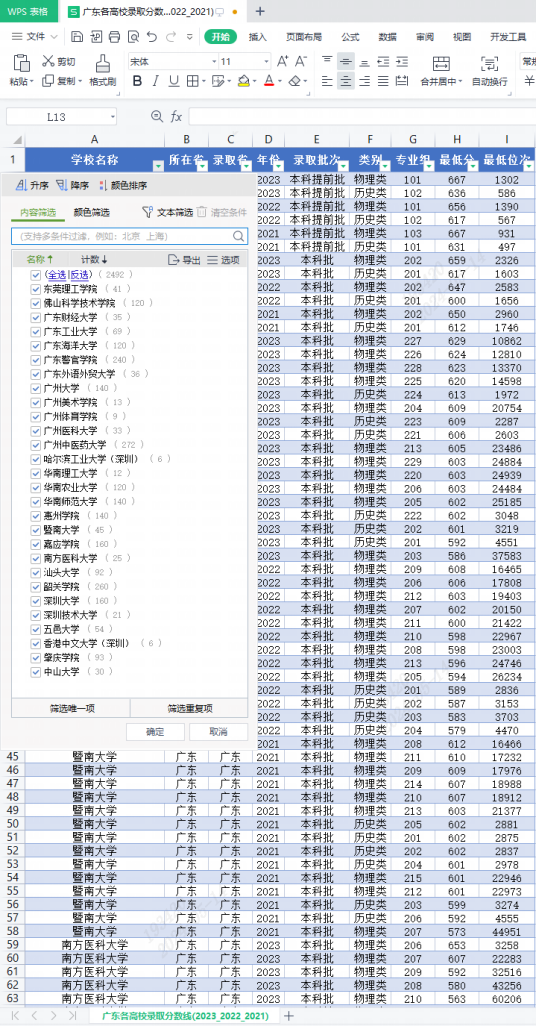
为了帮助考生更好地进行志愿填报,更好的对数据筛选,故整理 广东各高校2023/2022/2021三年录取分数excel文件, 部分数据及文件见下图, 数据根据历年录取分数线汇总,仅供参考, 详细请登陆各高校网站查询。 如有需要,可根据步骤下载文件:
- 文件列表及数据如下图所示,真实有效。
- 关注上述公众号 - 发送消息 - 数据下载 - 广东高校 即可返回百度云盘下载地址。
- 详细高校列表见文章下方,目前已收集广东大部分的高校,其它省份目前在汇总中,可留意公众号的消息发布。 湖南,湖北,江苏汇总中, 近日发布,请留意。
高校列表:
香港中文大学(深圳)
香港中文大学(深圳)
哈尔滨工业大学(深圳)
暨南大学
南方医科大学
深圳大学
华南农业大学
华南师范大学
广州医科大学
中山大学
佛山科学技术学院
东莞理工学院
华南理工大学
广东外语外贸大学
广东工业大学
广州中医药大学
广东海洋大学
广东警官学院
广东财经大学
广州体育学院
广州美术学院
汕头大学
深圳技术大学
广州大学
五邑大学
惠州学院
肇庆学院
韶关学院
嘉应学院