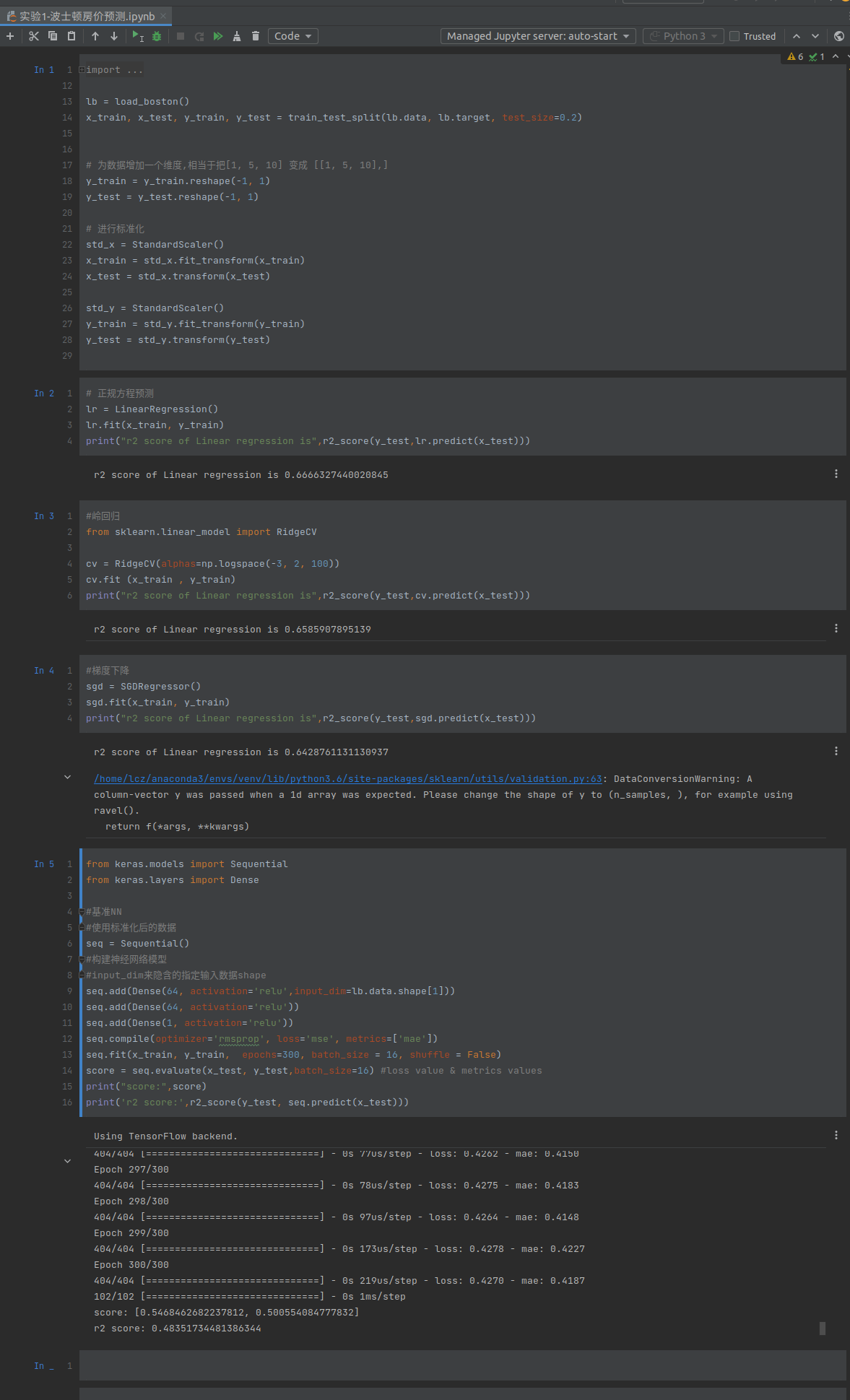
朴素贝叶斯是一种基于贝叶斯定理的分类算法,常用于解决文本分类和垃圾邮件过滤等问题。它的"朴素"体现在对每个特征之间的条件独立性的假设,即假设给定目标值的情况下,每个特征都是相互独立的。尽管这个假设在实际问题中并不总是成立,但朴素贝叶斯的简单性和高效性使其在实践中仍然表现良好。
实验的案例用的老师课后作业题目预测某天是否会打网球,假设每个特征独立。
1.贝叶斯公式
P(A|B)=P(B|A)P(B)P(A)=P(Bi)P(A|Bi)∑ni=1P(Bi)P(A|Bi)
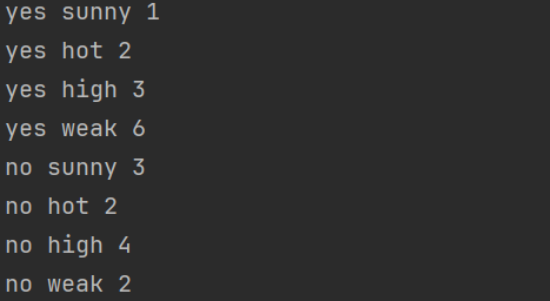
2.训练集
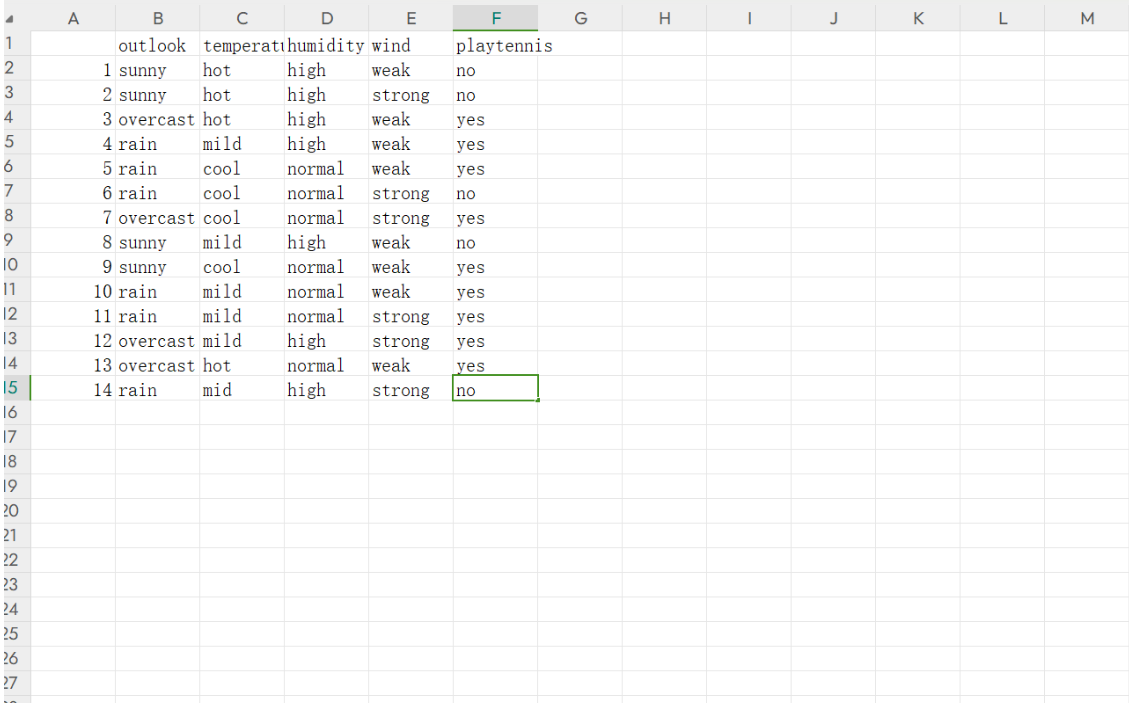
处理训练数据:
1.定义一个字典yy来存储样本预测类别即yes 和no的类别.
用xx来存储每个预测类别的特征的的数量
定义一个classes存储预测的类别
yy = defaultdict(int) xx= defaultdict(lambda: defaultdict(int)) classes = set()
2.对训练集进行处理得到每个样本特征的数量,以及总的数量。
通过循环遍历样本数据。发现每个数据都有五个变量。举一个例子,例如当我们取第二个样本的时候预测类别为no,把他加入集合对yy中no标签的数量+1,接下来依次取出特征suuny hot high strong 在xx no标签上的这些特征依次加一。
leny = len(y) for i in range(leny): fea = X[i] label = y[i] classes.add(label) yy[label] += 1 for fea1 in fea: xx[label][fea1] += 1
3.先验概率
先验概率是指在考虑任何数据或证据之前,根据先前的知识或经验,对事件发生的概率所作的猜测或估计
根据上面的案例容易得到分类为no的概率为5/14,分类为yes的概率为9/14。
4.后验概率
在已知观测数据的情况下,对模型参数或假设的概率分布进行估计或推断。
后验概率也就是说在某个已知条件下发生,也就是条件概率,这时候就要用到朴素贝叶斯公式
由于相互独立,公式简化为
P(A|B)=P(A)P(B)
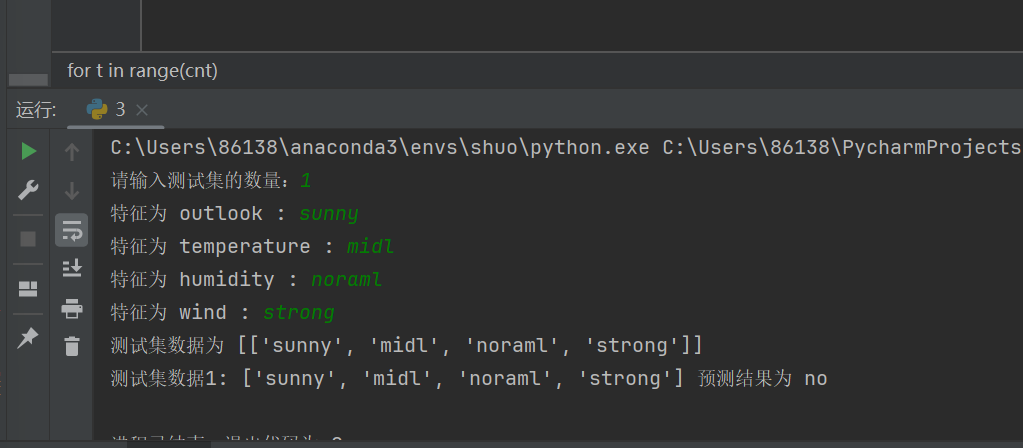
对于每个测试集得到一个对应的预测分类,存储在predictions = [];我们每一次取到一个测试集数据。假设取到的是sunny, mild, normal, strong,我们需要分析它的类别。我们就要遍历每一种类别得到这个数据预测为该类别的概率。用max_prob和predicted_class来记录预测概率最大的类别。假设每个特征之间相互独立的,所以计算就只需要把该类别对应的特征的概率累乘运行就可以得到该类别i下的后验概率,我们在所有类别后验概率中选取概率最大的那一个作为答案即可
def predict(X): predictions = [] for fea in X: maxp = -0.01 ans = None for label in classes: p = ynum[label] for fea1 in fea: p *= xx[label][fea1] / sum(xnum[label].values()) if p > maxp: maxp = p ans = label predictions.append(ans) return predictions
实验总代码
`from collections import defaultdict
yy = defaultdict(int)
xx= defaultdict(lambda: defaultdict(int))
classes = set()
def xygl(X, y):
leny = len(y)
for i in range(leny):
fea = X[i]
label = y[i]
classes.add(label)
yy[label] += 1
for fea1 in fea:
xx[label][fea1] += 1
for label in classes:yy[label] /= leny# for label in classes:
# for feature in X[0]:
# print(label,fea, feature_counts[label][fea]);# for label in classes:
# print(label,"=",class_probabilities[label]);
def predict(X):
predictions = []
for fea in X:maxp = -0.01ans = Nonefor label in classes:p = yy[label]for fea1 in fea:p *= xx[label][fea1] / sum(xx[label].values())if p > maxp:maxp = pans = labelpredictions.append(ans)
return predictions
T = ['outlook', 'temperature', 'humidity', 'wind']
X = [
['sunny', 'hot', 'high', 'weak'],
['sunny', 'hot', 'high', 'strong'],
['overcast', 'hot', 'high', 'weak'],
['rain', 'mild', 'high', 'weak'],
['rain', 'cool', 'normal', 'weak'],
['rain', 'cool', 'normal', 'strong'],
['overcast', 'cool', 'normal', 'strong'],
['sunny', 'mild', 'high', 'weak'],
['sunny', 'cool', 'normal', 'weak'],
['rain', 'mild', 'normal', 'weak'],
['rain', 'mild', 'normal', 'strong'],
['overcast', 'mild', 'high', 'strong'],
['overcast', 'hot', 'normal', 'weak'],
['rain', 'mid', 'high', 'strong']
]
y = ['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
xygl(X, y)
test_data = []
cnt = int(input("请输入测试集的数量:"))
for t in range(cnt):
sample = []
for i in range(4): # 假设每个样本有4个特征值
test = input(f"特征为 {T[i]} : ")
sample.append(test)
test_data.append(sample)
print("测试集数据为", test_data)
predictions = predict(test_data)
lenp = len(predictions)
for i in range(lenp):
print(f"测试集数据{i + 1}:", test_data[i], "预测结果为", predictions[i])`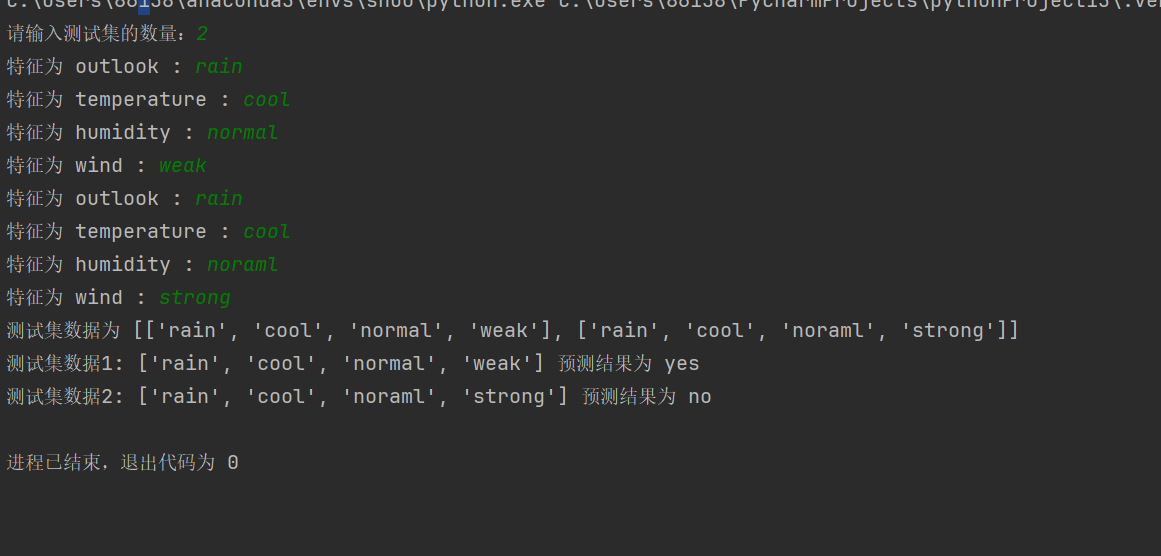
实验中遇到的问题:
1初始时对数据的处理方式可能不够灵活,导致了实现算法时的困难。使用字典型数据结构可以更灵活地处理数据,有助于提高算法的效率和可扩展性。
2.测试集中存在超出训练集范围的数据,表明数据集可能不够完善,存在欠拟合问题。
3.在开始选择数据集的时候本来想调用sklearn库使用经典鸢尾花数据集,后来发现老师给的例子更合适。
优缺点分析
优点:
简单快速: 实现简单,计算速度快,适用于大规模数据集。
高效性: 在数据较少的情况下仍然有效,适用于多分类任务。
适应多种数据类型: 可以处理多种类型的特征,包括离散型和连续型特征。
对缺失值不敏感: 在数据存在缺失值时表现良好。
对噪声数据不敏感: 对于分类不准确的数据不太敏感,能够处理一些噪声数据。
缺点:
假设特征独立: 朴素贝叶斯算法假设所有特征都是相互独立的,这在现实中很少成立,因此可能会影响分类的准确性。
处理连续变量时的假设: 如果数据集中包含连续变量,朴素贝叶斯算法将使用概率密度函数进行建模,但实际数据可能不符合这种假设,导致分类效果下降。
对输入数据的表达形式敏感: 如果输入数据的表示形式不合适,可能会导致模型的性能下降。
样本类别不平衡问题: 如果样本中某些类别的数量远远超过其他类别,可能会影响模型的训练效果。
朴素贝叶斯模型的学习效果受限: 因为其天生的特征独立假设,导致模型的表达能力有限,可能无法准确地建模复杂的关系。
![C121 李超树+DP P4655 [CEOI2017] Building Bridges](https://img2024.cnblogs.com/blog/1973969/202405/1973969-20240514213501564-1920676835.png)