吴恩达机器学习
学习视频参考b站:吴恩达机器学习
本文是参照视频学习的随手笔记,便于后续回顾。
强化学习(reinforce learning)
什么是强化学习
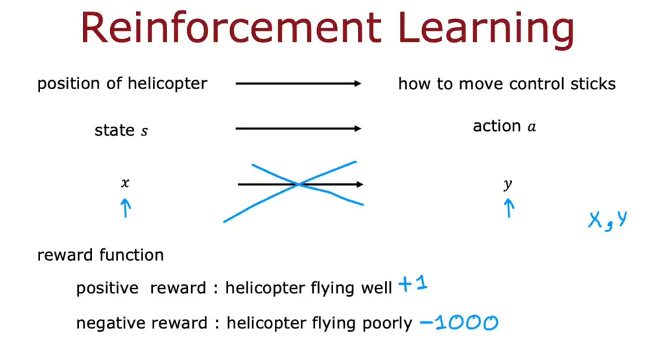
示例:如何让遥控飞机学会倒飞?
监督学习并不适用,因为很难有好的数据集
奖励函数,告诉飞机什么时候是表现好什么时候是表现差
强化学习是你需要告诉他该做什么而不是如何去做
如果飞机飞的好就给予奖励像是+1,不好就给予惩罚-1000
其他示例:
狗跨越障碍,控制机器人,工厂优化,金融股票交易,玩游戏等


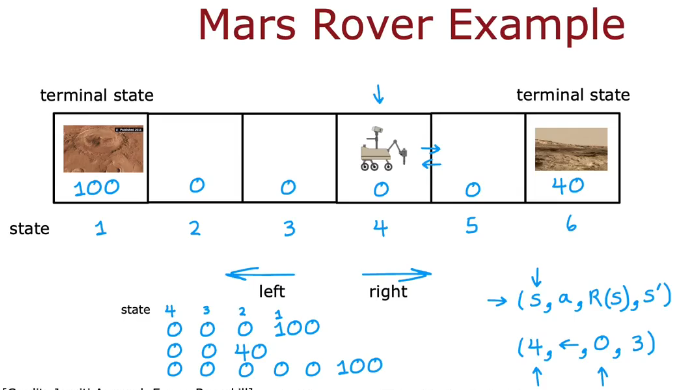
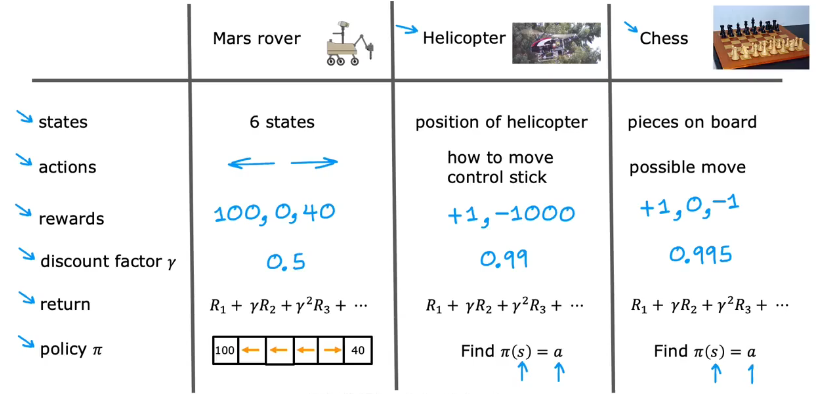
火星探测器示例
火星车在每一个格子中代表不同状态
图下方的是奖励
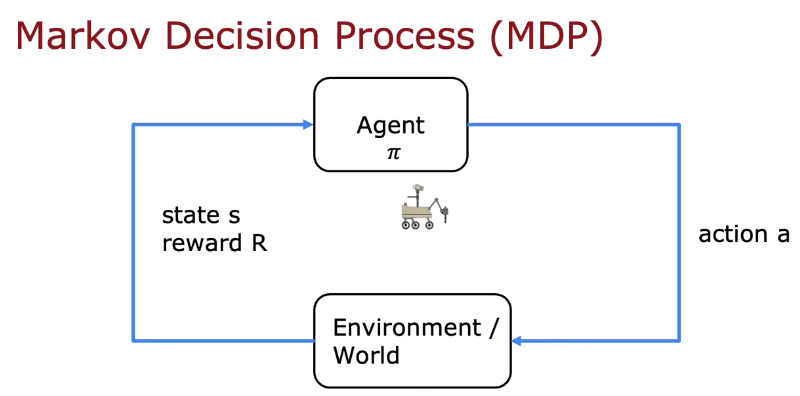
s状态,a动作,R(s)奖励,S'新状态
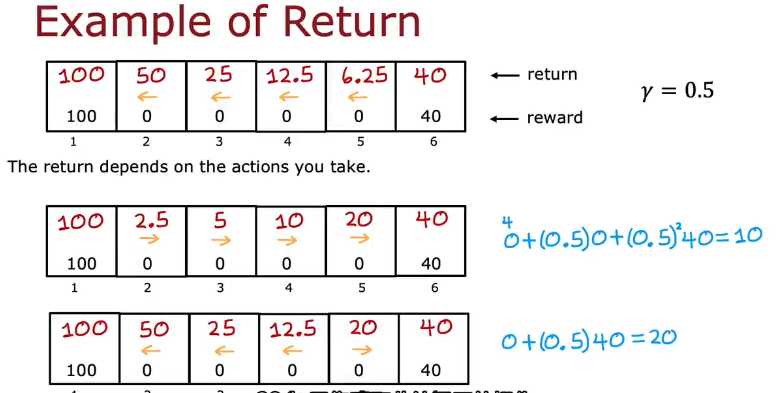
强化学习的回报(return)
return=每个奖励乘折扣系数γ的和(折扣系数幂从0开始到n)

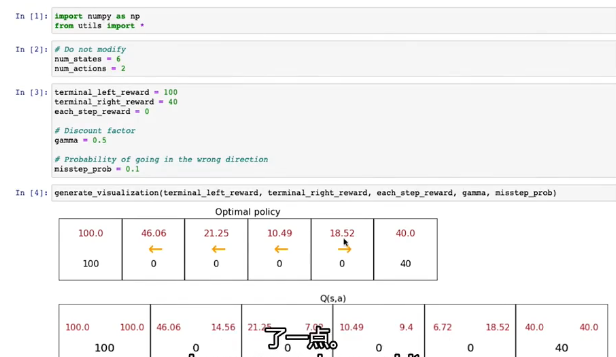
下图是从每一格总是往左走或往右走的或左右都可以走回报,γ=0.5
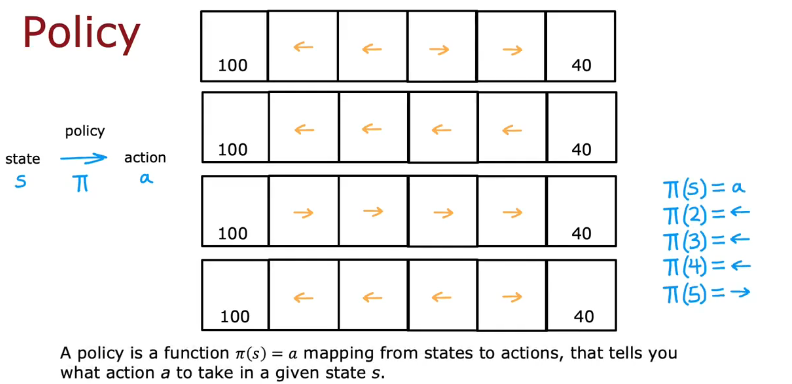
如何做决策
Policy用符号π表示在某个状态时该采取怎样的动作action
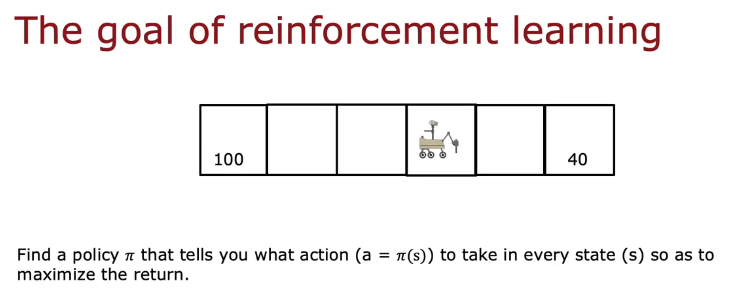
强化学习的目标就是找到最大化回报的π
回顾关键概念
马尔科夫决策过程(Markov Decision Process-MDP)
未来只取决于你现在在哪,而不关注你如何到达这的
状态-动作价值函数
定义
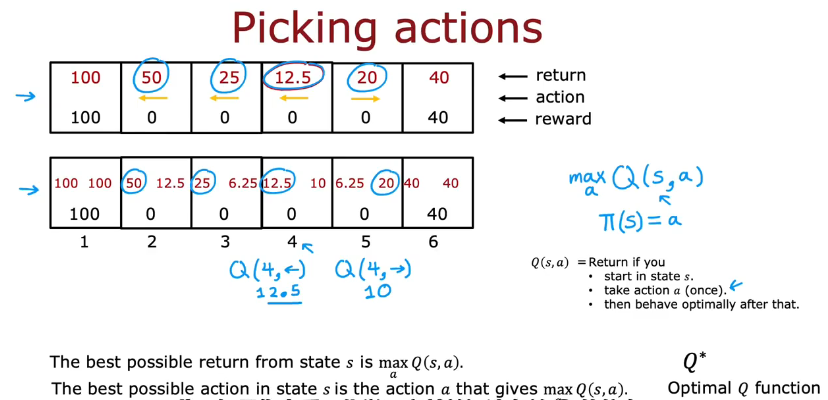
状态动作函数Q()
Q(2,→)=2-3-2-1
Q(2,左)=2-1
Q()的定义:从状态s执行动作a所得到表现最优

将在某个状态最高的回报标注
最优Q函数Q*和Q函数差不多
示例
可选实验室,修改火星车的部分参数来观测结果
贝尔曼方程(Bellman Equation)
Q(s,a)=R(s)+γmax(s',a')
如下面示例

在两端时Q(s,a)=R(s)

本质是:从当前状态得到的回报加下一状态得到最优回报


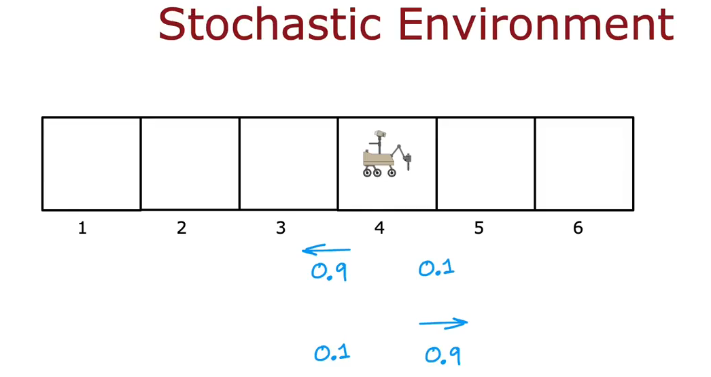
随机环境(Random(stochastic) environment)
随机环境示例:
命令火星车往左走,会有0.9概率往左,0.1概率往右(0.1概率失败)
命令火星车往右走,会有0.9概率往右,0.1概率往左(0.1概率失败)
保证预期回报最大化,即最大化平均值
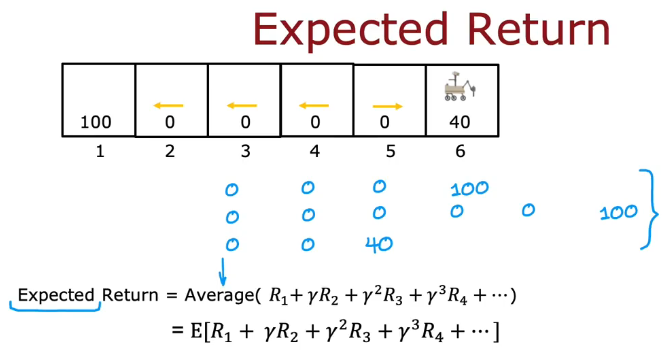
下一次的状态会变化(有可能失败)

像是右0.1概率会失败,期望回报为所有下一动作回报平均值,就会发生如下变化
连续状态空间应用示例
一个火星车可以在一条线很长的距离每个状态都可能存在
或者卡车的x,y距离,朝向角度θ和变化后的这些状态等

描述直升机的位置:x,y,z轴,左右滚动,向前投球还是向后投球,指南针偏向和变化后的这些状态等

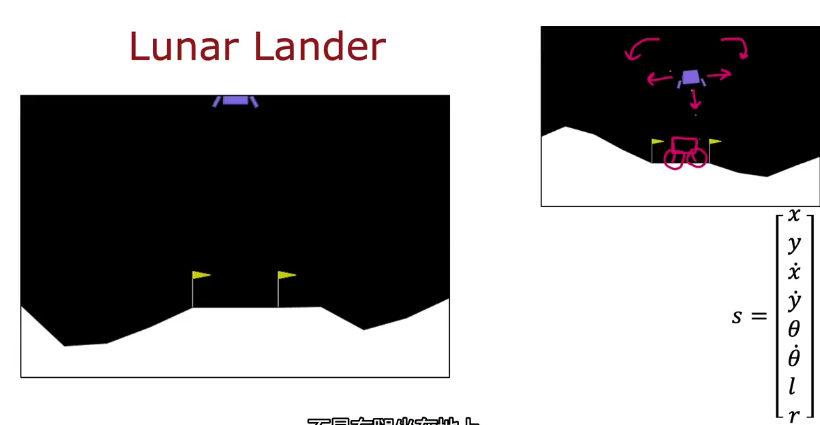
月球着陆器
适当时间使用推进器让着陆器着陆

四种选择,什么都不做惯性下降,左右推进器,下方推进器
状态s:x,y坐标,角度θ,左右腿是否着地l,r
回报:是否正常着陆(离旗越近回报越少),出问题扣分
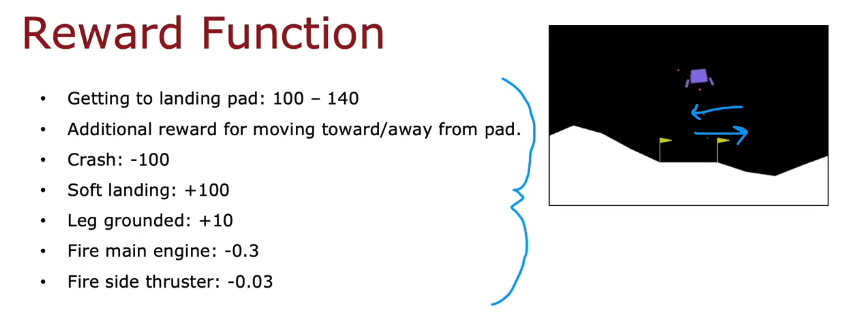
折扣系数γ选择0.985

状态值函数(state-value function)
训练神经网络通过输入状态(s,a)计算Q(s,a)
使用监督学习,大量数据x-y来训练,但是如何获得大量数据?
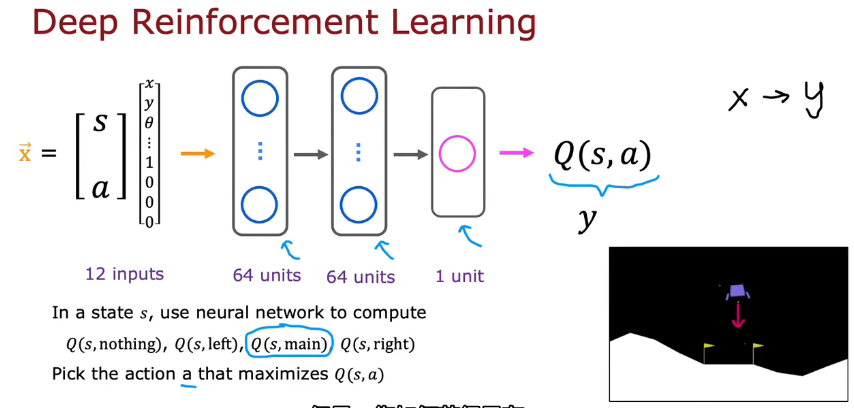
实际测试的数据(s,a,R(s),s'),计算y来组成训练集,如何得到Q?一开始只是随便猜测的,会越来越精确

为了防止使用计算机内存太多,只记最近的10000次,重放缓冲区(Replay Buffer)技术
使用得到的10000个数据训练使Q()接近y值

算法改进
改进神经网络架构
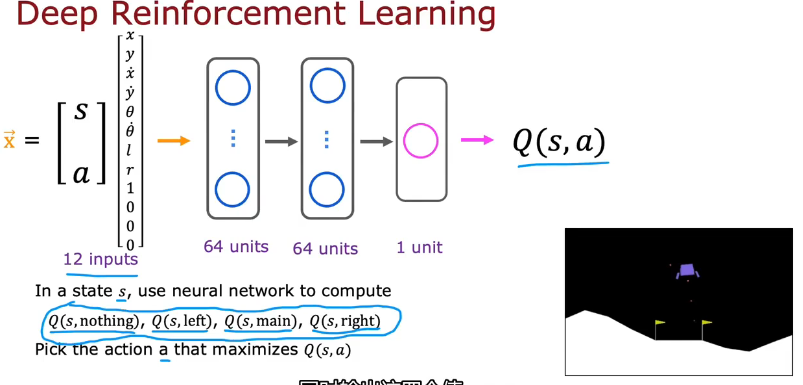
改进后效率更高更好,如下图
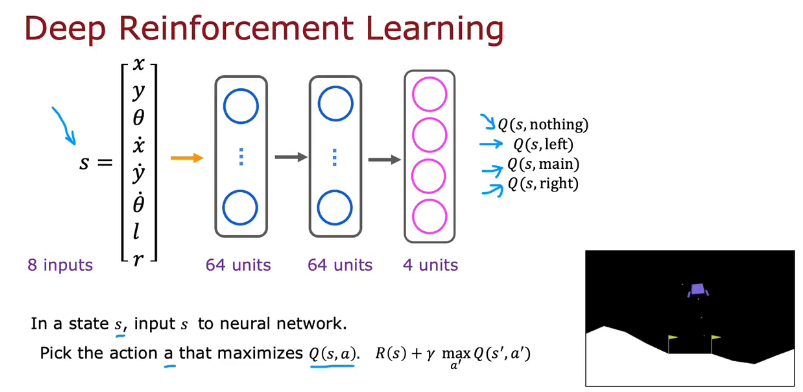
ε-贪婪策略(greedy policy)
如何学习在某一个状态该采取什么动作?

不想完全随机动作,可能那是坏的,使用当前猜测的Q(s,a)预测动作,可能不是最好的,但会一点一点训练变好
如果在某个状态时,随机猜的的Q,使使用主推进器的Q总是很低,那么模型就不会采用main动作(这一步称为贪婪或剥削)
所以要有概率让模型自己探索(Exploration),让它克服先入己见(这一步称为探索)
ε为随机探索的概率
刚开始的时候ε很大,随着训练进程越来越小

小批量和软更新(mini-batch and soft update)
从监督学习开始:
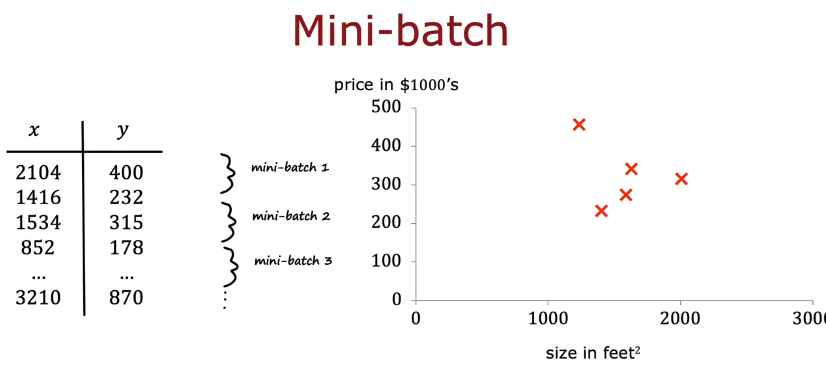
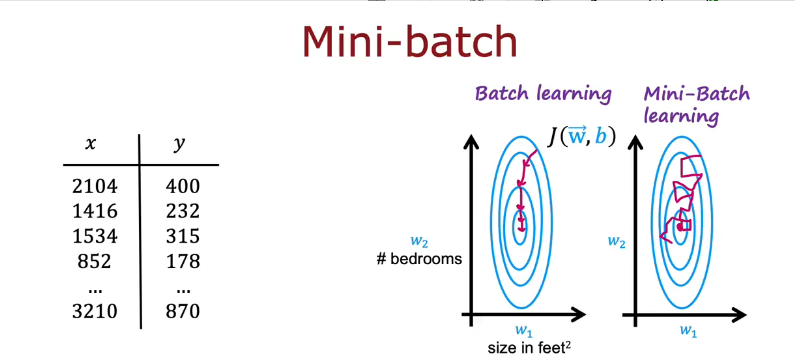
当训练集数量太多时,每一步梯度下降都要进行很多步计算,速度很慢
选择一个主要示例m=1000,每一步都进行1000次而不是1百万次

第一次梯度下降使用5个示例,下一次再使用5个不同示例,如此往复,可以从数据集中从上往下依此选,也可以完全选5个不同的数据
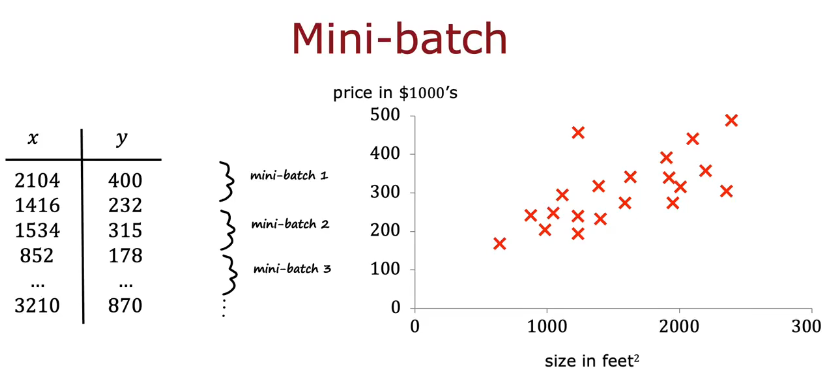
mini-batch趋向全局最小值,每次计算量小,计算成本低,虽然可能会有嘈杂
强化学习:
每次只用1000个示例训练而不是10000个
Set Q=Qnew这种方法可能会使模型比之前还糟糕,赋值一个更差的Q,使用软更新有助于防止Qnew变得更糟

软更新:
使用0.99的旧版本的参数值+0.01新版本的参数值

强化学习现状

课程总结

Summary
本周主要学习了以下内容
1.强化学习的概念和火星车示例,强化学习的回报,如何采取决策,马尔科夫决策过程
2.状态-动作价值函数Q(s,a),贝尔曼方程,随机环境
3.连续状态空间应用示例,月球着陆器示例,状态值函数
4.算法改进,包括神经网络架构改进,贪婪策略,小批量和软更新
5.强化学习现状,课程总结