目录
- 概
- 符号说明
- STAR
- Retrieval
- Ranking
- 最后的结果
Lee D., Kraft A., Jin L., Mehta N., Xu T., Hong L., Chi E. H. and Yi X. STAR: A simple training-free approach for recommendations using large language models. 2024.
概
本文提出了一种融合语义/协同/时序信息的方法, 使得 LLM 无需微调即可轻松超越传统方法.
符号说明
- \(u \in U\), user;
- \(s_i \in I\), item;
- \(S_u = \{s_1, s_2, \ldots, s_n\}\), 为用户 \(u\) 的交互序列;
STAR
Retrieval
-
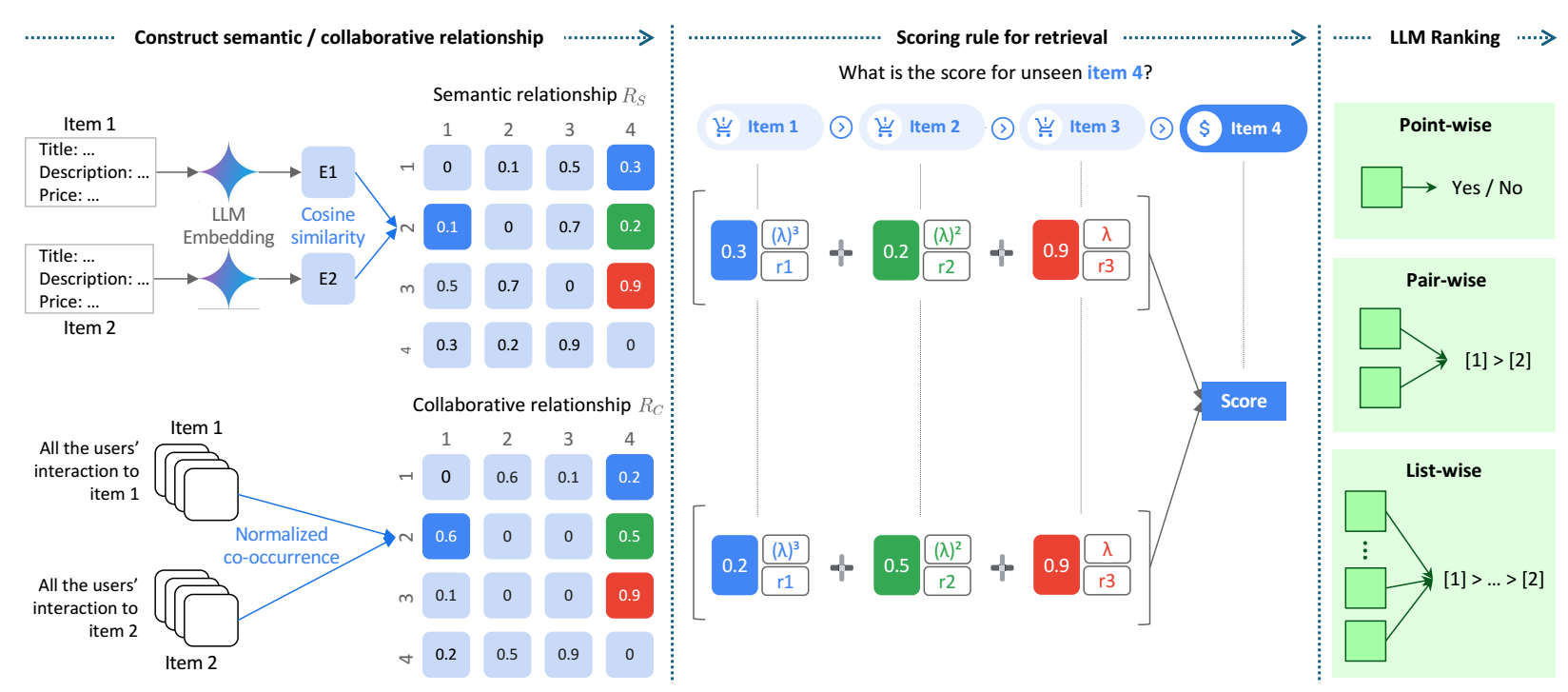
首先, STAR 会通过某个方式为 LLM 检索出一些合适的候选 items.
-
作者希望, 这个检索方式能够同时考虑到语义和协同信息:
- 语义信息: 作者将 item 的一些文本信息 (title, description, category, brand, sales ranking, price) 通过编码模型 (本文采用 text-embedding-004) 进行编码, 然后计算两两的 cosine 相似度 \(R_S \in \mathbb{R}^{|I| \times |I|}\).
- 协同信息: 令 \(C \in \mathbb{R}^{|I| \times |U|}\), \(C_{iu}\) 表示 item \(i\) 出现在对应 user \(u\) 的交互序列中的次数. 然后, 此时 item-item 的协同相似度为, 各自的稀疏行向量的 cosine 相似度. 记为 \(R_C \in \mathbb{R}^{|I| \times |I|}\).
-
于是, 对于用户 \(u\) (其交互序列为 \(S_u = \{s_1, s_2, \ldots, s_n\}\)), 其对 item \(x \in I\) 的打分定义为:
\[\text{score}(x) = \frac{1}{n} \sum_{j=1}^n r_j \cdot \lambda^{n - j + 1} \cdot [a \cdot R_S[x, j] + (1 - \alpha) \cdot R_C [x, j]]. \]其中 \(r_j\) 是 user 给 item \(s_j\) 的打分, \(\lambda \in (0, 1]\) (比如 0.7) 用于建模越近的 item 越重要这一特性, \(\alpha \in (0, 1)\) 用于平衡语义信息和协同信息. 这些都是超参数.
Ranking
-
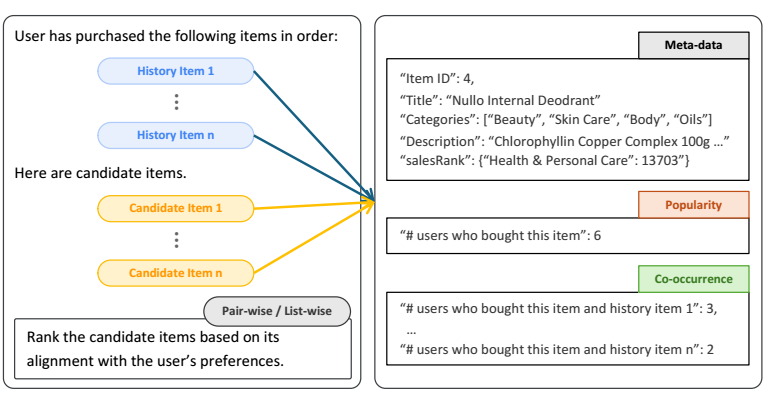
假设, 我们通过上面的策略检索出 top-K 个候选 items, 我们希望对这些候选 items 排个序.
-
Point-wise: 这个方法很简单, 把每个 item 的结果通过上述方式传给大模型, 然后用大模型得到一个分数, 倘若有两个 item 分数一样, 则采用之前的检索的方式的排序.
-
Pair-wise:
- 假设候选 items 按照检索排名为 (从高到低):\[i_1, i_2, \ldots, i_{K-2}, i_{K-1}, i_K. \]
- 然后首先让 LLM 判断 \(i_{K-1}, i_K\) 的次序, 倘若 \(i_{K} > i_{K-1}\) 则交换二则的次序得到:\[\tilde{i}_1 = i_1, \tilde{i}_2 = i_2, \ldots, \tilde{i}_{K-2} = i_{K-2}, \tilde{i}_{K-1} = i_K, \tilde{i}_{K} = i_{K-1}, \]否则保持原样.
- 然后再排序 \(\tilde{i}_{K-2}, \tilde{i}_{K-2}\), 重复上述操作.
- 假设候选 items 按照检索排名为 (从高到低):
-
List-wise:
- 这是上述 pair-wise 的一个推广, 设定一个滑动窗口 \(w\) 和滑动步长 \(d\), 每一次对一个窗口内的 items 进行排序, 然后不断滑动.
最后的结果
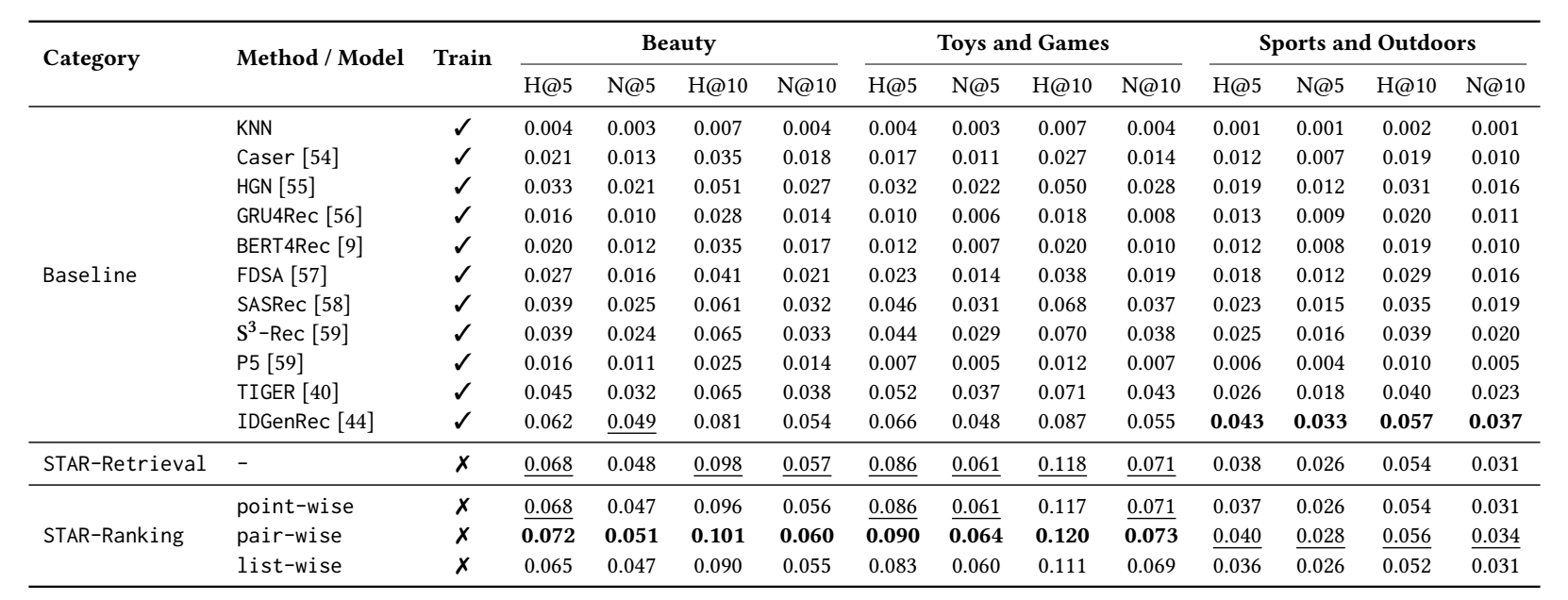
- 其实可以发现, 最最重要的, 其实是检索的效率很高啊.