在处理Spark Streaming中的背压(Backpressure)问题时,综合考虑提升数据消费速度与应对下游消费能力上限是至关重要的。以下内容将详细介绍背压的原理、应对策略以及具体的调优参数配置,帮助您有效缓解背压问题,提升Spark Streaming应用的性能和稳定性。
一、背压(Backpressure)原理
背压指的是数据生产速度超过数据消费速度,导致数据在系统中积压。这种积压可能引发资源耗尽、内存溢出、处理延迟增加等问题,从而影响整个流处理应用的稳定性和性能。
背压产生的主要原因
- 数据生产过快:数据源(如Kafka、Socket等)产生数据的速度超过Spark Streaming的消费能力。
- 消费处理瓶颈:Spark Streaming的处理逻辑复杂,导致消费速度跟不上数据生产速度。
- 下游系统限制:数据消费后需要写入下游系统(如数据库、存储系统),其处理能力有限,成为瓶颈。
二、应对背压的策略
针对背压问题,主要有两大策略:
- 加快数据消费速度:通过提升Spark Streaming应用自身的处理能力,使其能够更快地处理和消费流入的数据。
- 管理下游消费能力上限:在下游系统消费能力有限时,采取流量控制和缓冲机制,避免系统过载。
1. 加快数据消费速度
原理
提升Spark Streaming应用的并行处理能力和资源利用率,使其能够更高效地处理数据流,从而减少数据积压。
具体措施及调优参数
a. 增加并行度
-
配置参数:
# Executor配置 spark.executor.instances=20 # 根据集群资源调整 spark.executor.cores=4 # 每个Executor的核心数 spark.executor.memory=8g # 每个Executor的内存 -
原理:增加Executor数量和每个Executor的核心数,提升整体的并行处理能力。同时,调整
spark.default.parallelism和spark.sql.shuffle.partitions,确保任务能够充分并行。 -
配置示例:
spark.default.parallelism=160 # 总Executor核心数 × 2 spark.sql.shuffle.partitions=160 # 与 default.parallelism 保持一致
b. 优化处理逻辑
-
优化方法:
- 减少复杂的计算和数据转换。
- 尽量使用内置函数,避免自定义UDF。
- 减少Shuffle操作,如使用
reduceByKey代替groupByKey。
-
示例代码优化:
// 使用reduceByKey代替groupByKey dstream.map(record => (key, value)).reduceByKey(_ + _)
c. 调整批次间隔
-
配置参数:
val batchInterval = Seconds(1) // 根据数据量和处理能力调整 val streamingContext = new StreamingContext(sparkConf, batchInterval) -
原理:合理设置批次间隔,确保每个批次的数据能够在规定时间内被处理完,避免延迟积累。
d. 优化资源配置
-
配置参数:
spark.executor.memory=8g spark.executor.cores=4 spark.driver.memory=4g -
原理:确保Spark应用有足够的内存和CPU资源,避免因资源不足导致的性能瓶颈。
e. 使用高效的序列化方式
-
配置参数:
spark.serializer=org.apache.spark.serializer.KryoSerializer spark.kryo.registrationRequired=true spark.kryo.registrator=your.custom.KryoRegistrator # 如有需要 -
原理:使用Kryo序列化,提高序列化效率,减少数据传输和存储开销。
f. 使用缓存和持久化
-
配置方法:
dstream.cache() // 或者 dstream.persist(StorageLevel.MEMORY_AND_DISK) -
原理:对多次使用的数据进行缓存或持久化,避免重复计算,提高处理效率。
2. 处理下游消费能力的上限
原理
当下游系统(如数据库、存储系统)的消费能力有限时,需通过流量控制和缓冲机制,防止数据积压和系统过载。
具体措施及调优参数
a. 实施速率限制
-
配置参数:
# 启用背压机制 spark.streaming.backpressure.enabled=true# 设置初始接收速率(每秒每个接收器的数据量) spark.streaming.backpressure.initialRate=500# 设置每个接收器的最大接收速率 spark.streaming.receiver.maxRate=1000 -
原理:通过限制数据输入速率,防止下游系统过载。
b. 使用缓冲队列
-
实现方法:
- 在Spark Streaming与下游系统之间引入Kafka或RabbitMQ作为中间缓冲层。
- 调整Spark Streaming的消费速率,确保缓冲队列不被填满。
-
配置示例(Kafka参数):
spark.streaming.kafka.maxRatePerPartition=200
c. 采用流量控制机制
-
实现方法:
- 监控下游系统的负载指标(如响应时间、CPU使用率)。
- 根据监控指标动态调整Spark Streaming的消费速率。
-
示例代码:
// 需要结合外部监控和调度工具,自定义RateLimiter逻辑 // 示例仅为概念性说明 if (downstreamLoadHigh) {streamingContext.receiver.maxRate -= 100 } else {streamingContext.receiver.maxRate += 100 }
d. 扩展下游系统能力
-
优化方法:
- 增加下游系统的处理节点,提升并行处理能力。
- 优化下游系统的处理逻辑和查询性能。
- 使用更高效的存储引擎或索引机制。
-
原理:提升下游系统的处理能力,减少成为瓶颈的可能性。
e. 利用Spark的内置背压机制
-
配置参数:
spark.streaming.backpressure.enabled=true spark.streaming.backpressure.initialRate=500 spark.streaming.receiver.maxRate=1000 -
原理:Spark Streaming的背压机制可以自动调整数据接收速率,以适应下游的处理能力,避免系统过载。
f. 设计弹性和容错机制
-
配置方法:
// 启用检查点 streamingContext.checkpoint("hdfs://path/to/checkpoint/dir")// 配置任务失败重试 spark.task.maxFailures=8 -
原理:通过检查点和重试机制,确保系统在出现背压时能够稳定运行,不会因数据积压导致崩溃。
三、综合调优参数配置示例
以下是一个综合的Spark Streaming调优参数配置示例,结合了上述提升消费速度和处理下游消费能力上限的策略:
# ------------------------------
# 1. Executor配置
# ------------------------------
spark.executor.instances=20 # 根据集群资源调整
spark.executor.cores=4 # 每个Executor的核心数
spark.executor.memory=8g # 每个Executor的内存
spark.driver.memory=4g # Driver内存# ------------------------------
# 2. 并行度配置
# ------------------------------
spark.default.parallelism=160 # 总Executor核心数 × 2
spark.sql.shuffle.partitions=160 # 与 default.parallelism 保持一致# ------------------------------
# 3. 动态资源分配
# ------------------------------
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=20 # 最小Executor数
spark.dynamicAllocation.maxExecutors=100 # 最大Executor数
spark.shuffle.service.enabled=true # 启用Shuffle服务# ------------------------------
# 4. 序列化优化
# ------------------------------
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.kryo.registrationRequired=true
spark.kryo.registrator=your.custom.KryoRegistrator # 如有需要,自定义Kryo注册器# ------------------------------
# 5. Spark Streaming背压配置
# ------------------------------
spark.streaming.backpressure.enabled=true
spark.streaming.backpressure.initialRate=500
spark.streaming.receiver.maxRate=1000
spark.streaming.blockInterval=100 # 数据块时间间隔(ms)# ------------------------------
# 6. Kafka参数(若使用Kafka作为数据源)
# ------------------------------
spark.streaming.kafka.maxRatePerPartition=200
spark.streaming.kafka.consumer.poll.ms=512# ------------------------------
# 7. 批次间隔
# ------------------------------
spark.streaming.batch.duration=1000ms # 1秒的批次间隔# ------------------------------
# 8. 任务失败重试
# ------------------------------
spark.task.maxFailures=8 # 任务失败重试次数# ------------------------------
# 9. 检查点
# ------------------------------
streamingContext.checkpoint("hdfs://path/to/checkpoint/dir")
解释
-
Executor配置:
spark.executor.instances=20:20个Executor,根据集群资源调整。spark.executor.cores=4:每个Executor 4个核心。spark.executor.memory=8g:每个Executor 8GB内存。spark.driver.memory=4g:Driver 4GB内存。
-
并行度配置:
spark.default.parallelism=160:基于总核心数(20 × 4 = 80)×2。spark.sql.shuffle.partitions=160:与default.parallelism保持一致,确保Shuffle操作的并行度。
-
动态资源分配:
spark.dynamicAllocation.enabled=true:启用动态资源分配。spark.dynamicAllocation.minExecutors=20:最小Executor数。spark.dynamicAllocation.maxExecutors=100:最大Executor数。spark.shuffle.service.enabled=true:启用Shuffle服务,支持动态资源分配。
-
序列化优化:
spark.serializer=org.apache.spark.serializer.KryoSerializer:使用Kryo序列化。spark.kryo.registrationRequired=true:要求注册自定义类,提升序列化性能。spark.kryo.registrator=your.custom.KryoRegistrator:如有需要,指定自定义Kryo注册器。
-
Spark Streaming背压配置:
spark.streaming.backpressure.enabled=true:启用背压机制。spark.streaming.backpressure.initialRate=500:初始接收速率。spark.streaming.receiver.maxRate=1000:每个接收器的最大接收速率。spark.streaming.blockInterval=100:数据块时间间隔,优化数据处理粒度。
-
Kafka参数(若使用Kafka作为数据源):
spark.streaming.kafka.maxRatePerPartition=200:每个Kafka分区的最大接收速率。spark.streaming.kafka.consumer.poll.ms=512:Kafka消费者轮询间隔。
-
批次间隔:
spark.streaming.batch.duration=1000ms:1秒的批次间隔,根据数据量和处理能力调整。
-
任务失败重试:
spark.task.maxFailures=8:任务失败后重试次数,确保任务的可靠性。
-
检查点:
streamingContext.checkpoint("hdfs://path/to/checkpoint/dir"):设置检查点目录,保证容错性。
四、最佳实践与注意事项
1. 根据集群资源合理设置参数
- 计算总核心数:
总Executor数 × 每个Executor的核心数。 - 设置并行度:
spark.default.parallelism和spark.sql.shuffle.partitions一般设置为总核心数的2倍。 - 调整Executor数量与核心数:根据实际集群资源和作业需求,避免资源浪费或任务调度瓶颈。
2. 持续监控与动态调优
- 使用Spark UI监控:观察任务的执行情况、Shuffle阶段的性能、资源利用率等。(是否有Queued?)
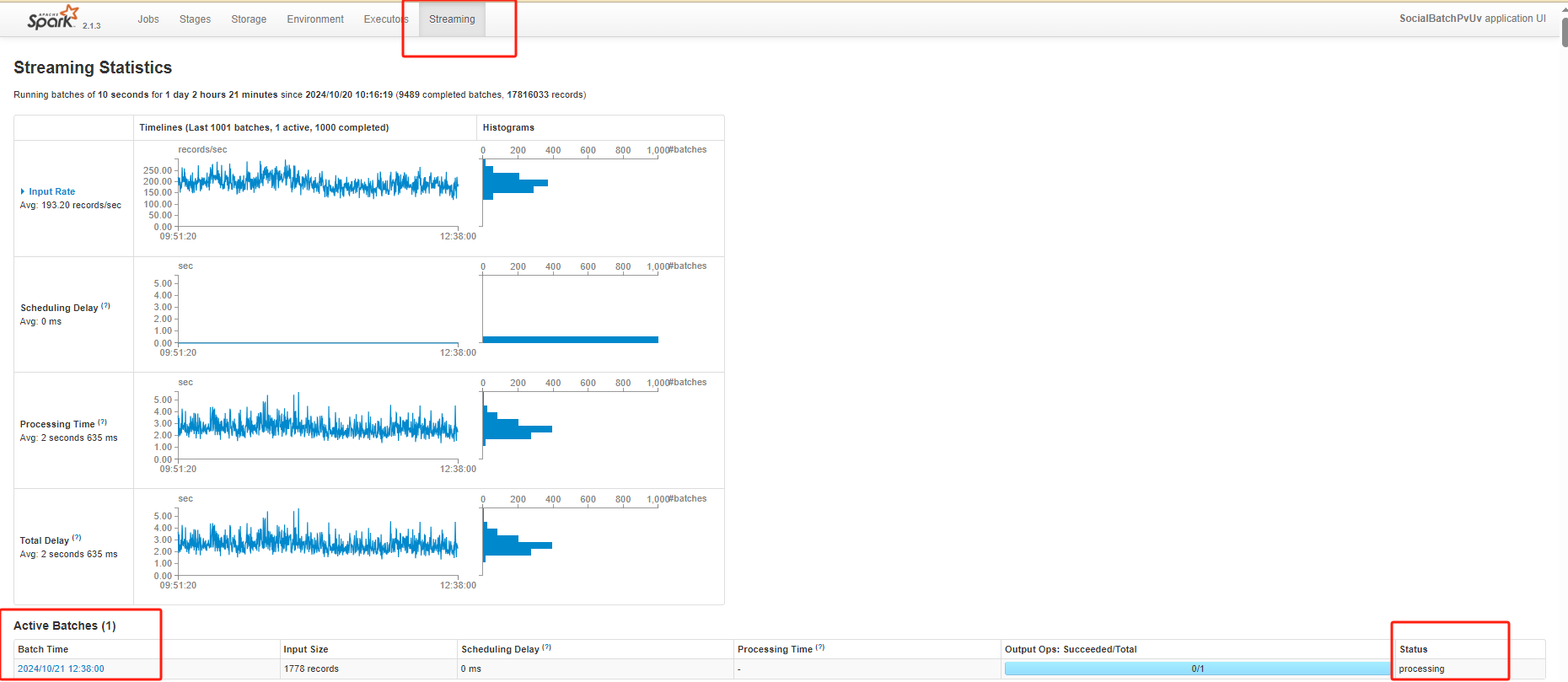
- 根据监控数据调整参数:动态调整并行度、速率限制等参数,优化作业性能。
3. 优化数据处理逻辑
- 减少不必要的Shuffle操作:如使用
reduceByKey替代groupByKey,减少数据传输量。 - 使用高效的算法和数据结构:提升数据处理效率,减少计算开销。
4. 启用动态资源分配
- 根据负载动态调整资源:确保在高峰期有足够的资源处理数据,在低峰期释放资源,提升资源利用率。
5. 合理设置批次间隔
- 平衡吞吐量与延迟:根据数据量和处理能力,设置合适的批次间隔,既保证高吞吐量,又控制延迟。
6. 测试与验证
- 在生产环境部署前进行充分测试:验证参数配置的有效性,确保系统稳定运行。
- 逐步调整参数:避免一次性大幅调整参数,逐步优化,观察效果。
7. 设计弹性和容错机制
- 启用检查点和重试机制:确保在出现背压或故障时系统能够自动恢复,保持稳定运行。
五、总结
处理Spark Streaming中的背压问题,需要从提升消费能力和管理下游消费能力上限两个方面入手。通过合理配置并行度参数(spark.default.parallelism 和 spark.sql.shuffle.partitions)、优化资源配置、调整批次间隔、使用高效的序列化方式以及引入缓冲和速率限制机制,可以有效缓解背压带来的负面影响,确保流式数据处理的高效性和稳定性。
关键要点:
- 并行度配置:确保Spark应用能够充分利用集群资源,提升数据处理能力。
- 背压机制:启用并配置Spark Streaming的背压机制,动态调整数据接收速率。
- 资源优化:合理配置Executor数量、核心数和内存,确保资源充足且利用率高。
- 监控与调优:持续监控Spark应用的性能指标,基于监控数据动态调整配置参数。
- 容错设计:通过检查点和重试机制,增强系统的稳定性和可靠性。
通过以上综合措施,您可以有效处理Spark Streaming中的背压问题,提升数据消费速度,并在下游消费能力有限时确保系统的稳定运行。