| 学号姓名 | 102202132 郑冰智 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13285 |
| 这个作业的目标 | 爬取天气网、股票相关信息、中国大学2021主榜所有院校信息,并存储在数据库中 |
| 实验二仓库地址 | https://gitee.com/zheng-bingzhi/2022-level-data-collection/tree/master/实验二 |
一、作业①:中国气象网天气预报爬取与存储
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
输出信息:
Gitee文件夹链接:https://gitee.com/zheng-bingzhi/2022-level-data-collection/blob/master/实验二/weather collection.py
1.1.核心代码
1.1.1. WeatherDB类
- 该类用于与SQLite数据库交互。关键代码如下:
self.con = sqlite3.connect("weathers.db")
self.cursor.execute("create table weathers (wCity varchar(16), wDate varchar(16), ""wweather varchar(64), wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))"
)
1.1.2. WeatherForecast类
- 其forecastCity(city)方法用于获取指定城市天气数据。核心代码如下:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req).read()
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:date = li.select("h1")[0].textweather = li.select("p[class='wea']")[0].texttemp = li.select("p[class='tem'] span")[0].text + "/" + li.select("p[class='tem'] i")[0].textself.db.insert(city, date, weather, temp)
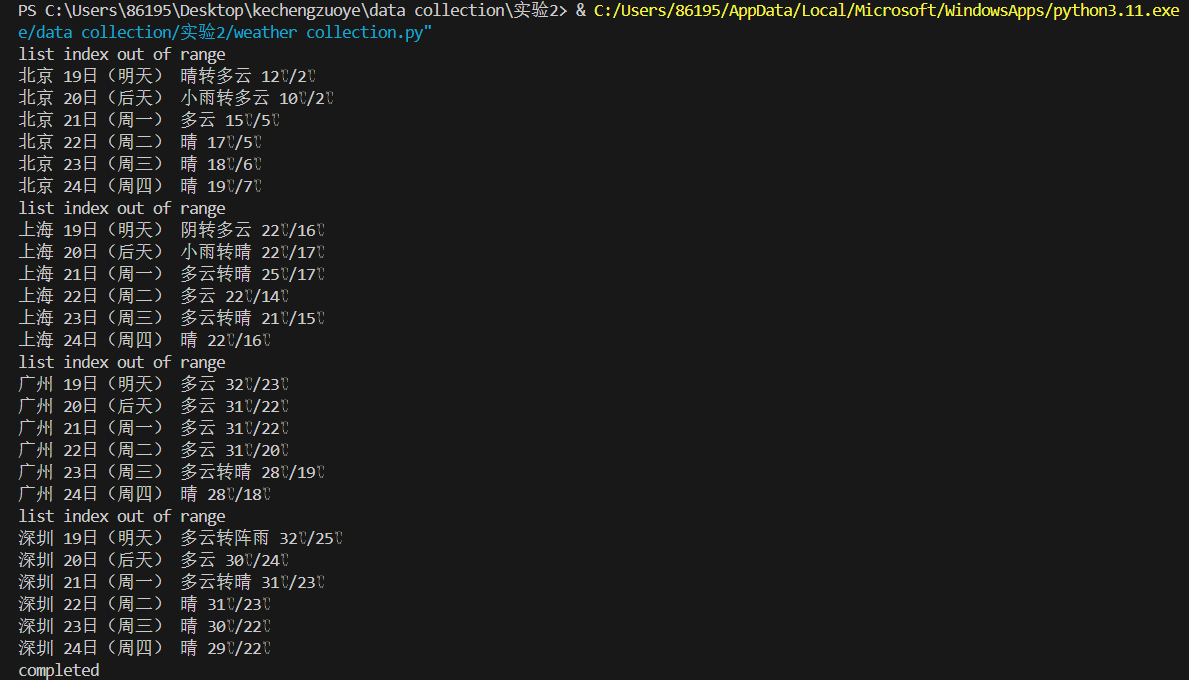
1.2.实现结果
成功获取并存储了指定城市的7日天气预报数据,如以下截图所示:

1.3实验心得
- 1.3.1. 数据库管理功能定义
创建WeatherDB类实现数据库操作,包括openDB()打开数据库并创建表格,insert()插入数据,closeDB()提交并关闭连接。 - 1.3.2. 天气数据爬取与处理实现
WeatherForecast类的forecastCity()方法利用urllib和BeautifulSoup获取并解析天气数据,再通过WeatherDB插入数据库。
二、作业②:东方财富网股票信息爬取与存储
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
输出信息:
Gitee文件夹链接:https://gitee.com/zheng-bingzhi/2022-level-data-collection/blob/master/实验二/gupiao.py
2.1.核心代码
2.1.1. insert_data_to_db(stock_data)函数
- 用于批量插入股票数据到SQLite数据库,代码如下:
def insert_data_to_db(stock_data):conn = sqlite3.connect('stock_data.db')cursor = conn.cursor()cursor.executemany('''INSERT INTO stocks (股票名称, 股票价格, 涨跌幅, 涨跌额, 成交量, 成交额, 换手率, 最高价, 最低价, 开盘价, 收盘价, 市净率, 市盈率_TTM) VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?)''', stock_data)conn.commit()conn.close()
2.1.2. fetch_page_data(page_number)函数
- 抓取指定页码股票数据,解析JSON数据并提取所需字段,代码如下:
def fetch_page_data(page_number):url = f"https://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408346152866958425_1728977618714&pn={page_number}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_={1728977618716}"response = requests.get(url)json_data = response.textjson_data_cleaned = json_data[json_data.index("(")+1 : json_data.rindex(")")]data = json.loads(json_data_cleaned)selected_data = []for item in data['data']['diff']:selected_item = (item.get('f14'), # 股票名称item.get('f2'), # 股票价格item.get('f3'), # 涨跌幅(%)item.get('f4'), # 涨跌额item.get('f5'), # 成交量(手)item.get('f6'), # 成交额(万元)item.get('f7'), # 换手率(%)item.get('f15'), # 最高价item.get('f16'), # 最低价item.get('f17'), # 开盘价item.get('f18'), # 收盘价item.get('f23'), # 市净率item.get('f115') # 市盈率(TTM))selected_data.append(selected_item)return selected_data
2.1.3. scrape_all_pages_to_db(total_pages)函数
- 循环抓取多页股票数据并存储到数据库,代码如下:
def scrape_all_pages_to_db(total_pages):all_data = []for page in range(1, total_pages + 1):page_data = fetch_page_data(page)all_data.extend(page_data)insert_data_to_db(all_data)print(f"数据已保存到数据库 (共 {len(all_data)} 条记录)")
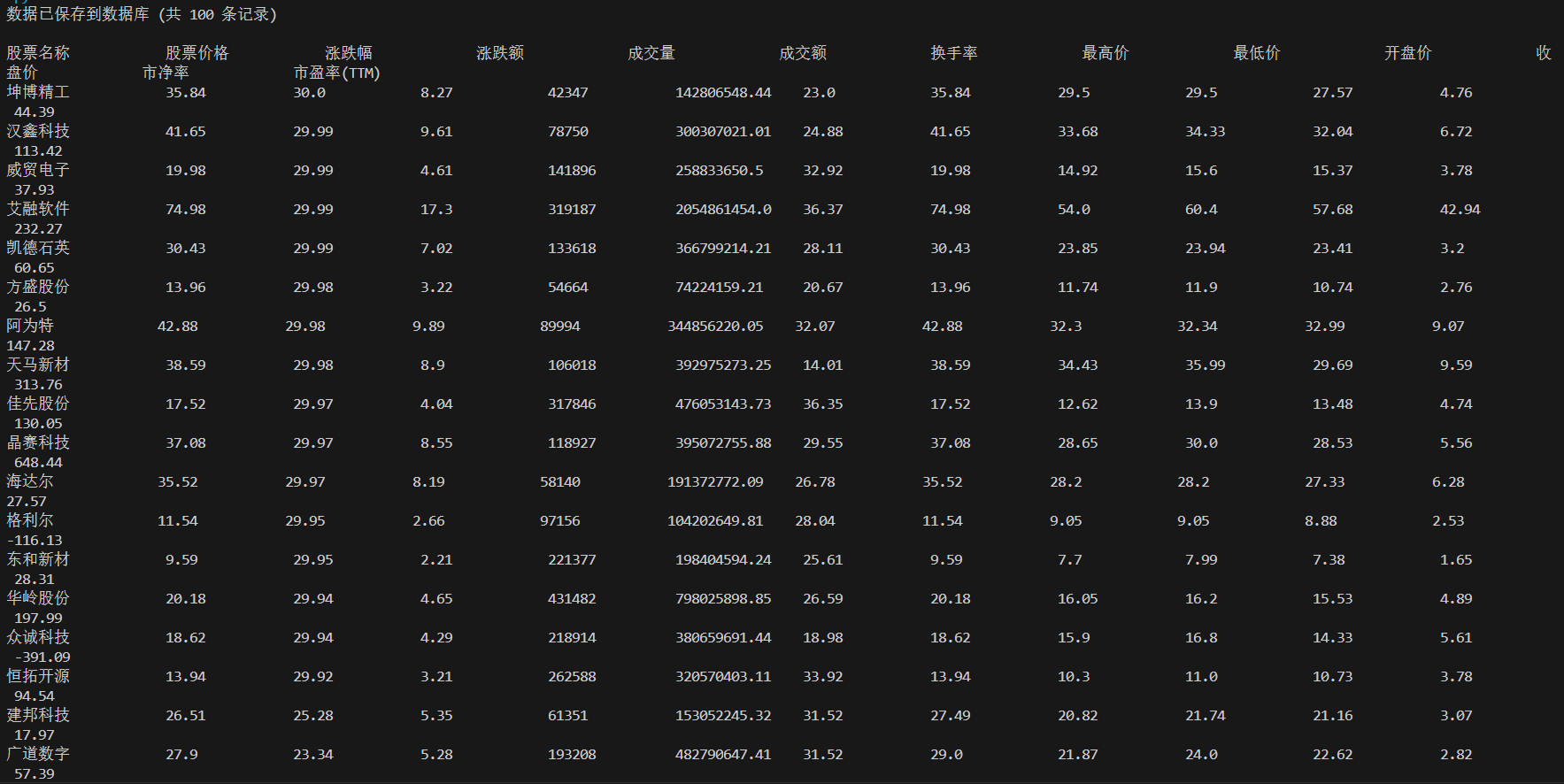
2.2实验结果
成功爬取并存储股票数据,截图如下:

2.3实验心得
- 2.3.1. 技术掌握与运用:
熟悉了requests和BeautifulSoup在Web数据抓取中的应用,尤其是JSON数据解析处理能力得到提升,同时强化了数据库操作理解。 - 2.3.2. 问题与解决
爬取时遇到API数据嵌套冗余问题,通过字符串清洗和JSON解析解决数据类型转换、字段对齐等问题,批量执行插入优化数据库性能。 - 2.3.3. 改进与优化
数据抓取和存储效率有提升空间,可考虑多线程爬取和使用更高级数据存储方案(如MongoDB)。
三、作业③:中国大学2021主榜院校信息爬取与存储
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
技巧:分析该网站的发包情况,分析获取数据的api
输出信息:
Gitee文件夹链接:https://gitee.com/zheng-bingzhi/2022-level-data-collection/blob/master/实验二/university_rankings.py
3.1核心代码
3.1.1. 发送HTTP GET请求获取数据
- 代码如下:
url = 'https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js'
headers = {'cookie': '_clck=93jbcf%7C2%7Cfq1%7C1719; Hm_lvt_af1fda4748dacbd3ee2e3a69c3496570=1726414171,1728974129,1728998508; HMACCOUNT=0427200578AECD82; Hm_lpvt_af1fda4748dacbd3ee2e3a69c3496570=1729000764; _clsk=1du80lb%7C1729000766146%7C8%7C1%7Cz.clarity.ms%2Fcollect','referer': 'https://www.shanghairanking.cn/rankings/bcur/2021','user - agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
response = requests.get(url, headers=headers)
3.1.2. 解析数据并提取信息
- 代码如下:
if response.status_code == 200:file_content = response.text
else:print(f"请求失败,状态码: {response.status_code}")exit()
extracted_data = []
if univ_data_match:univ_data_str = univ_data_match.group(1)university_pattern = re.compile(r'\{([^}]+)\}')universities = university_pattern.findall(univ_data_str)for university in universities:data_dict = {}for item in university.split(','):key_value = item.split(':')if len(key_value) == 2:key = key_value[0].strip().replace('"', '').replace("'", "")value = key_value[1].strip().replace('"', '').replace("'", "")if key == 'univNameCn':data_dict[key] = valueelif key in ['province', 'univCategory']:data_dict[key] = mapping.get(value, value)elif key == 'score':try:data_dict[key] = float(value)except ValueError:data_dict[key] = Noneextracted_data.append(data_dict)
3.1.3. 将数据存入SQLite数据库
- 代码如下:
conn = sqlite3.connect('university_rankings.db')
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS university (univNameCn TEXT, province TEXT, univCategory TEXT, score REAL)''')
cursor.executemany('''INSERT INTO university (univNameCn, province, univCategory, score) VALUES (:univNameCn, :province, :univCategory, :score)''', extracted_data)
conn.commit()
3.2.浏览器F12调试分析的过程
3.3.实验结果
成功爬取并存储大学排名数据,截图如下:
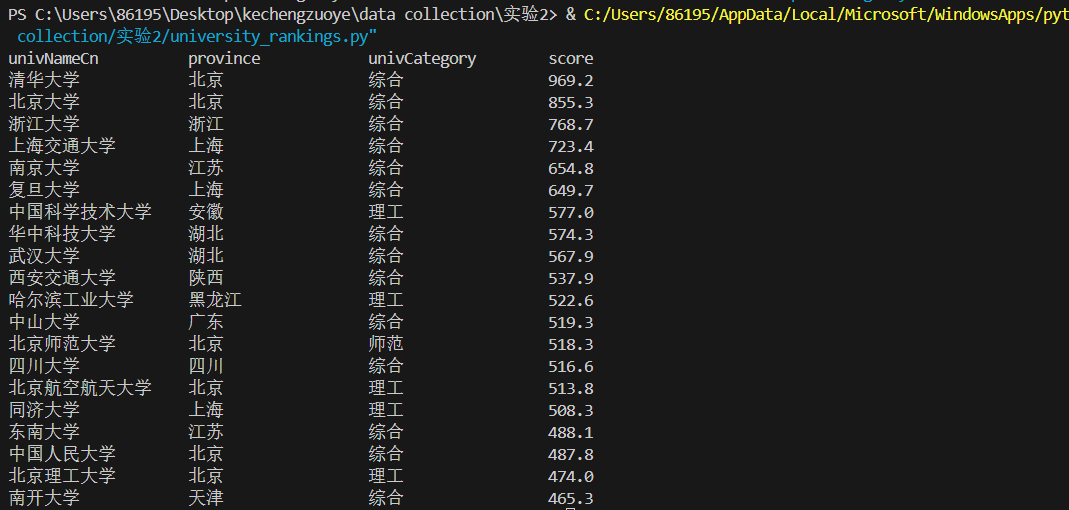

3.4.实验心得
- 3.4.1. 发包情况分析
排名数据通过API请求获取,URL为https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js,是静态资源请求。请求headers包含cookie、referer和user - agent,避免反爬虫拦截。该网站采用单页应用(SPA),通过JavaScript动态渲染数据,便于抓取完整数据集。 - 3.4.2. API数据结构分析
返回数据是JavaScript对象,非传统JSON格式。数据一次性加载且URL固定,便于大规模爬取。主要字段有univNameCn、province、univCategory、score等,通过正则表达式提取,解析时需处理字段映射和数值异常,并存储到SQLite数据库。