1 概述
简述:CDC/增量数据同步
CDC的全称是Change Data Capture(增量数据捕获)
- 在广义的概念上,只要能捕获数据变更的技术,我们都可以称为
CDC。- 我们目前通常描述的
CDC技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
- CDC 的技术实现方案
- 基于查询的 CDC:
- 优点 : 实现简单,是通过批处理实现的
- 缺点 : 需要依赖离线调度,不能保证数据强一致性和实时性;
- 基于日志的 CDC:
- 缺点 : 实现比较复杂
- 优点 : 但是可以实时消费日志,流式处理,可保证数据一致性和实时性;
CDC 的优势
- 如今,大多数公司仍然使用批处理在系统之间同步数据。使用批处理:
- 数据未立即同步
- 更多分配的资源用于同步数据库
- 数据复制仅在指定的批次期间发生
- 然而,变更数据捕获具有一些优势:
- 不断跟踪源数据库的变化
- 即时更新目标数据库
- 使用流处理来保证即时更改
有了CDC, 不同的数据库就会持续同步 ,批量任务已经成为过去。此外,由于 CDC 仅传输增量更改————因此,降低了传输数据的成本。
方案对比
目前市面上的CDC技术比较多,我们选取了几种主要的开源CDC方案做了对比,总体如下图:
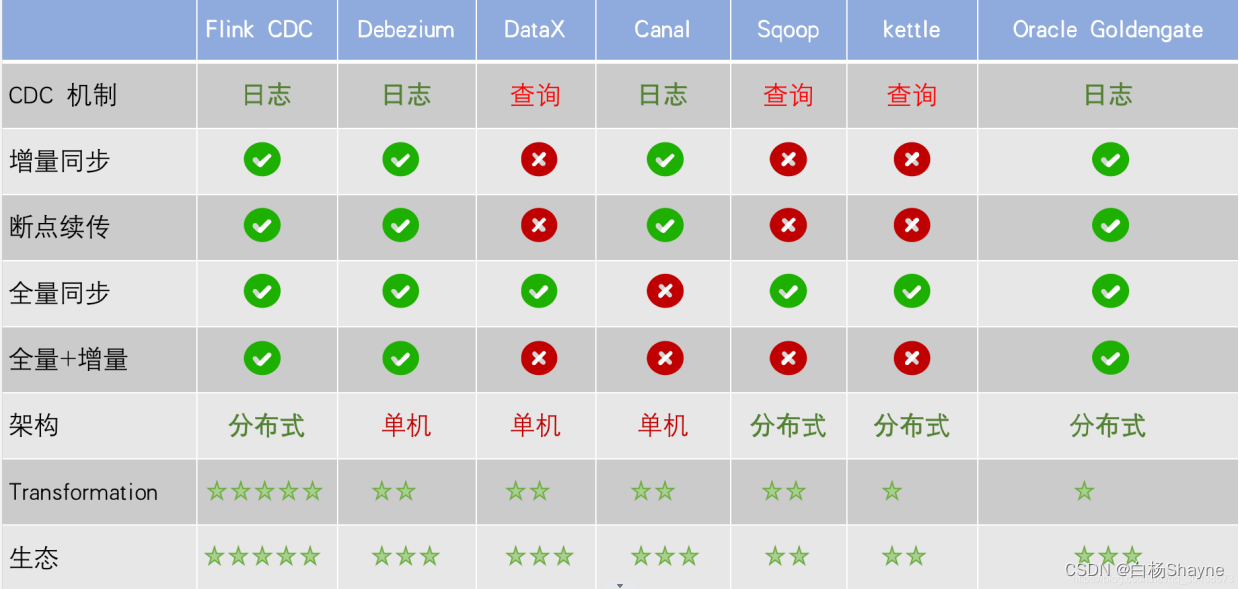
从CDC机制、增量同步、断电续传、全量同步、全量+增量、架构、数据计算、生态这八个方面做了对比。可以看出其中的佼佼者主要是Flink CDC和Oracle OGG以及Debezium;
由于基于查询的CDC方案缺陷明显,这里不作讨论,下面我们对基于日志的CDC方案的优劣来做详细的介绍。
Flink CDC
Flink CDC:Flink CDC是最近几年的新贵,Flink CDC 底层封装了Debezium,功能比较全面,目前已经迭代到了2.4版本,社区活跃度在几个方案中是最高的;
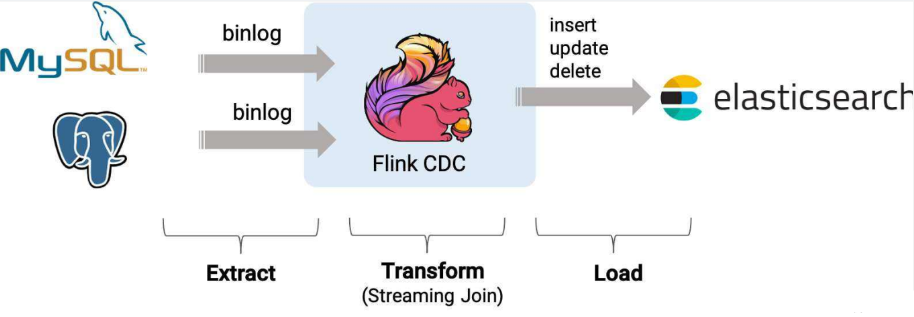
- 优点:
- 全、增量一体的分布式数据集成框架;
- 同步时无需加锁;
- 吞吐量大,适合海量数据实时同步;
- 操作简单,SQL即可完成;
- 具有强大的 transformation 能力,通过 Flink SQL 即可完成ETL 中的数据转换;
- 有丰富的 Connector,除关系型数据库外,HBase、ClickHouse、TiDB等也支持,而且支持自定义 connector;
- 缺点:依赖Flink集群,数据量较大时对服务器要求较高;
Oracle OGG
- Oracle OGG:Oracle OGG 历史比较悠久,最初是设计用来从Oracle迁移数据到其它数据库,或者从其它平台迁移数据到Oracle,随着发展,目前已支持 Mysql、Hadoop、Hive、Kafka 等数据源;
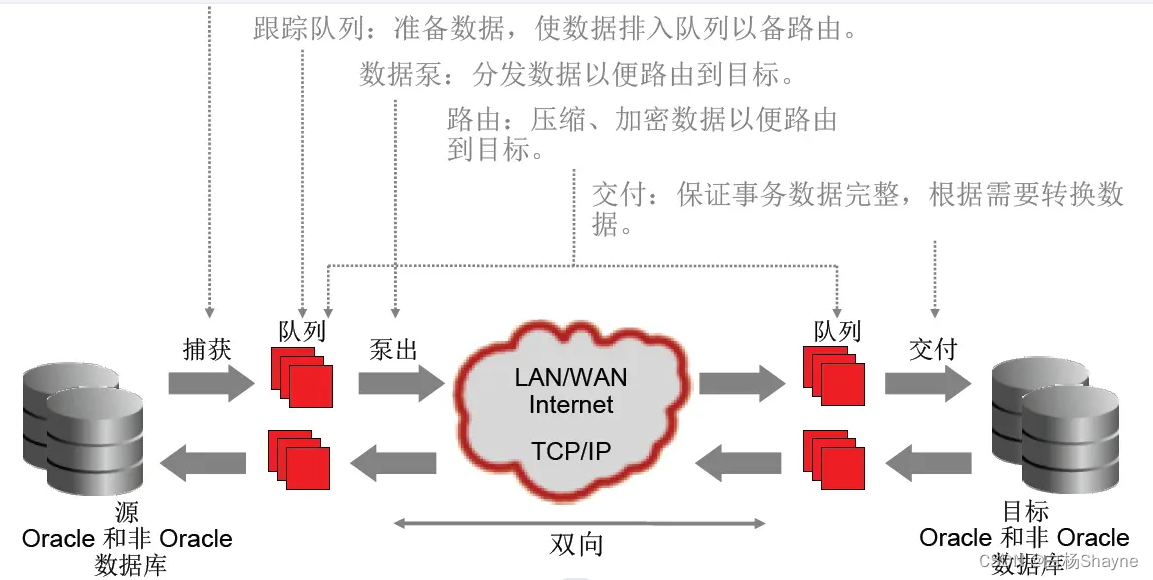
- 优点:
- 支持增量和全量同步
- 支持分布式
- 高性能
- 支持数据过滤和转化,是目前主流的实时同步方案之一;
- 缺点:支持的数据库比较少,像一些MongoDB、TiDB等不支持;
Debezium
Debezium:
Debezium最初设计成一个Kafka Connect的Source Plugin。- 目前开发者虽致力于将其与
Kafka Connect解耦,但当前的代码实现还未变动。
下图引自
Debeizum官方文档,可以看到一个Debezium在一个完整CDC系统中的位置。
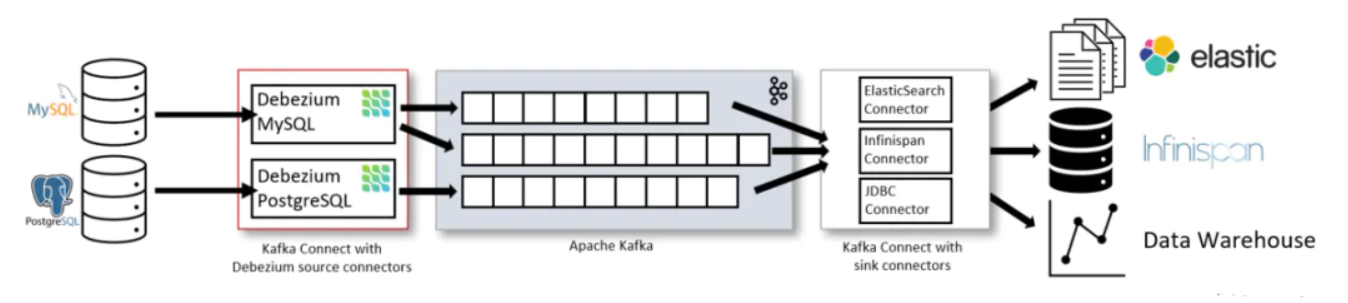
- 优点:
- 支持全量+增量同步;
- 缺点:
- 全量同步时会加锁,而且加锁时间不确定,会严重影响业务;
- 最重要的是跟Kafka等消息中间件强耦合,下游数据要经过Kafka;
Canal
-
Canal:主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。 -
优点:用于单一的MySQL环境做数据同步还不错;
-
缺点:
- 缺点较为明显,只支持MySQL的CDC,只支持增量同步,全量需要用DataX或者Sqoop,全量和增量同步割裂;
- 不支持分布式;
Debezium 平台
什么是 Debezium ?
- 官网
- https://debezium.io
- https://github.com/debezium
- https://github.com/debezium/debezium
- https://github.com/debezium/debezium-ui
- https://github.com/debezium/debezium-examples
- https://github.com/debezium/debezium-examples/tree/main/tutorial
- 官方的口号与定位
从数据库流式传输更改。
Debezium 是一个用于变更数据捕获的开源分布式平台。
启动它,将它指向你的数据库,你的应用程序就可以开始响应其他应用程序提交给你的数据库的所有插入、更新和删除操作。
Debezium 耐用且快速,因此您的应用程序可以快速响应,即使出现问题也不会错过事件。
Debezium是一个构建在Apache Kafka之上的CDC开源平台。
它的主要用途是在事务日志中,记录提交给每个源数据库表的所有行级更改 。
侦听这些事件的每个应用程序都可以根据增量数据更改执行所需的操作。
Debezium提供了一个连接器库,支持多种数据库
例如 MySQL、MongoDB、PostgreSQL 等。
-
这些连接器可以监视和记录数据库更改、并将其发布到
Kafka等流服务。 -
此外, 即使我们的应用程序出现故障,Debezium 也会进行监控 。
重新启动后,它将开始消耗上次停止的事件,因此不会丢失任何内容。
Debezium架构
-
部署 Debezium 取决于我们拥有的基础设施,但更常见的是,我们经常使用
Apache Kafka Connect。 -
Kafka Connect是一个框架,与Kafka代理一起作为单独的服务运行。我们用它在Apache Kafka和其他系统之间传输数据。 -
我们还可以定义连接器来将数据传入和传出 Kafka。
下图显示了基于 Debezium 的变更数据捕获管道的不同部分:

- 首先,在左侧,我们有一个 MySQL 源数据库,我们希望将其数据复制并在目标数据库(如 PostgreSQL 或任何分析数据库)中使用。
- 其次, Kafka Connect 连接器解析并解释事务日志并将其写入 Kafka 主题。
- 接下来,Kafka 充当消息代理,将变更集可靠地传输到目标系统。
- 然后,在右侧,我们有 Kafka 连接器轮询 Kafka 并将更改推送到目标数据库。
- **Debezium 在其架构中使用 Kafka **,但它还提供其他部署方法来满足我们的基础设施需求。
我们可以将其用作 Debezium 服务器的独立服务器,也可以将其作为库嵌入到我们的应用程序代码中。
我们将在以下部分中看到这些方法。
Debezium 服务器
Debezium提供了一个独立的服务器 来捕获源数据库的更改。它配置为使用Debezium源连接器之一。
此外,这些连接器将更改事件发送到各种消息基础设施,例如
Amazon Kinesis或Google Cloud Pub/Sub。
嵌入式 Debezium
Kafka Connect在用于部署Debezium时提供容错能力和可扩展性。
然而,有时我们的应用程序不需要这种级别的可靠性,并且我们希望最大限度地降低基础设施的成本。
值得庆幸的是, 我们可以通过将 Debezium 引擎嵌入到我们的应用程序中来做到这一点。
完成此操作后,我们必须配置连接器。
案例:基于 Debezium 的 Spring Boot CDC 应用程序
需求及架构
- 为了使我们的应用程序保持简单,我们将创建一个用于客户管理的 Spring Boot 应用程序。
customer表模型有 ID 、 全名 和 电子邮件 字段。
对于数据访问层,使用
Spring Data JPA。
最重要的是,应用程序将运行 Debezium 的嵌入式版本。
想象一下这个应用程序的架构:

首先,Debezium 引擎将跟踪源 MySQL 数据库(来自另一个系统或应用程序)上的
customer表的事务日志。
其次,每当我们对
customer表执行插入/更新/删除等数据库操作时,Debezium 连接器都会调用一个服务方法。
最后,根据这些事件,该方法会将
customer表的数据同步到目标 MySQL 数据库(我们应用程序的主数据库)。
Maven 依赖项
- 让我们首先将 所需的依赖项 添加到 pom.xml 中:
<dependency><groupId>io.debezium</groupId><artifactId>debezium-api</artifactId><version>1.4.2.Final</version>
</dependency>
<dependency><groupId>io.debezium</groupId><artifactId>debezium-embedded</artifactId><version>1.4.2.Final</version>
</dependency>
-
同样,我们为应用程序将使用的每个
Debezium连接器添加依赖项。 -
在我们的例子中,我们将使用 MySQL 连接器:
<dependency><groupId>io.debezium</groupId><artifactId>debezium-connector-mysql</artifactId><version>1.4.2.Final</version>
</dependency>
安装数据库
- 我们可以手动安装和配置我们的数据库。但是,为了加快速度,我们将使用
docker-compose文件:
version: "3.9"
services:# Install Source MySQL DB and setup the Customer databasemysql-1:container_name: source-databaseimage: mysqlports:- 3305:3306environment:MYSQL_ROOT_PASSWORD: rootMYSQL_USER: userMYSQL_PASSWORD: passwordMYSQL_DATABASE: customerdb# Install Target MySQL DB and setup the Customer databasemysql-2:container_name: target-databaseimage: mysqlports:- 3306:3306environment:MYSQL_ROOT_PASSWORD: rootMYSQL_USER: userMYSQL_PASSWORD: passwordMYSQL_DATABASE: customerdb-
该文件将在不同端口上运行两个数据库实例。
-
我们可以使用命令
docker-compose up -d运行此文件。
建表 : customer
- 现在,让我们通过运行 SQL 脚本来创建
customer表:
CREATE TABLE customer
(id integer NOT NULL,fullname character varying(255),email character varying(255),CONSTRAINT customer_pkey PRIMARY KEY (id)
);
- 在本节中,我们将配置 Debezium MySQL 连接器、并了解如何运行嵌入式 Debezium 引擎。
配置 Debezium 连接器
- 为了配置 Debezium MySQL 连接器,我们将创建一个 Debezium 配置 bean:
@Bean
public io.debezium.config.Configuration customerConnector() {return io.debezium.config.Configuration.create().with("name", "customer-mysql-connector").with("connector.class", "io.debezium.connector.mysql.MySqlConnector").with("offset.storage", "org.apache.kafka.connect.storage.FileOffsetBackingStore").with("offset.storage.file.filename", "/tmp/offsets.dat").with("offset.flush.interval.ms", "60000").with("database.hostname", customerDbHost).with("database.port", customerDbPort).with("database.user", customerDbUsername).with("database.password", customerDbPassword).with("database.dbname", customerDbName).with("database.include.list", customerDbName).with("include.schema.changes", "false").with("database.server.id", "10181").with("database.server.name", "customer-mysql-db-server").with("database.history", "io.debezium.relational.history.FileDatabaseHistory").with("database.history.file.filename", "/tmp/dbhistory.dat").build();
}
让我们更详细地检查此配置。
该 bean 中的 create 方法 使用构建器来创建 Properties 对象 。
无论首选连接器如何,此构建器都会设置引擎所需的多个属性。为了跟踪源 MySQL 数据库,我们使用 MySqlConnector 类。
当此连接器运行时,它开始跟踪源中的更改并记录“偏移量”以确定 它从事务日志中处理了多少数据 。
有多种方法可以保存这些偏移量,但在本例中,我们将使用类 FileOffsetBackingStore 在本地文件系统上存储偏移量。
连接器的最后几个参数是 MySQL 数据库属性。
现在我们已经有了配置,我们可以创建我们的引擎了。
配置、运行 Debezium 引擎
DebeziumEngine充当我们的 MySQL 连接器的包装器。让我们使用连接器配置创建引擎:
private DebeziumEngine<RecordChangeEvent<SourceRecord>> debeziumEngine;public DebeziumListener(Configuration customerConnectorConfiguration, CustomerService customerService) {this.debeziumEngine = DebeziumEngine.create(ChangeEventFormat.of(Connect.class)).using(customerConnectorConfiguration.asProperties()).notifying(this::handleEvent).build();this.customerService = customerService;
}
更重要的是,引擎将为每个数据更改调用一个方法 - 在我们的示例中为 handleChangeEvent 。
在此方法中,首先, 我们将根据 调用 create() 时指定的格式解析每个事件。
然后,我们找到我们进行的操作并调用 CustomerService 在目标数据库上执行创建/更新/删除功能:
private void handleChangeEvent(RecordChangeEvent<SourceRecord> sourceRecordRecordChangeEvent) {SourceRecord sourceRecord = sourceRecordRecordChangeEvent.record();Struct sourceRecordChangeValue= (Struct) sourceRecord.value();if (sourceRecordChangeValue != null) {Operation operation = Operation.forCode((String) sourceRecordChangeValue.get(OPERATION));if(operation != Operation.READ) {String record = operation == Operation.DELETE ? BEFORE : AFTER;Struct struct = (Struct) sourceRecordChangeValue.get(record);Map<String, Object> payload = struct.schema().fields().stream().map(Field::name).filter(fieldName -> struct.get(fieldName) != null).map(fieldName -> Pair.of(fieldName, struct.get(fieldName))).collect(toMap(Pair::getKey, Pair::getValue));this.customerService.replicateData(payload, operation);}}
}
现在我们已经配置了 DebeziumEngine 对象,让我们使用服务执行器异步启动它:
private final Executor executor = Executors.newSingleThreadExecutor();@PostConstruct
private void start() {this.executor.execute(debeziumEngine);
}@PreDestroy
private void stop() throws IOException {if (this.debeziumEngine != null) {this.debeziumEngine.close();}
}
运行
要查看我们的代码的实际效果,让我们对源数据库的 customer 表进行一些数据更改。
Step1 插入记录
- 要将新记录添加到 customer 表中,我们将进入 MySQL shell 并运行:
INSERT INTO customerdb.customer (id, fullname, email) VALUES (1, 'John Doe', '[email protected]')
- 运行此查询后,我们将看到应用程序的相应输出:
23:57:57.897 [pool-1-thread-1] INFO c.b.l.d.listener.DebeziumListener - Key = 'Struct{id=1}' value = 'Struct{after=Struct{id=1,fullname=John Doe,[email protected]},source=Struct{version=1.4.2.Final,connector=mysql,name=customer-mysql-db-server,ts_ms=1617746277000,db=customerdb,table=customer,server_id=1,file=binlog.000007,pos=703,row=0,thread=19},op=c,ts_ms=1617746277422}'
Hibernate: insert into customer (email, fullname, id) values (?, ?, ?)
23:57:58.095 [pool-1-thread-1] INFO c.b.l.d.listener.DebeziumListener - Updated Data: {fullname=John Doe, id=1, [email protected]} with Operation: CREATE
- 最后,我们检查一条新记录是否已插入到我们的目标数据库中:
id fullname email
1 John Doe [email protected]
Step2 更新记录
- 现在,让我们尝试更新最后插入的客户并检查会发生什么:
UPDATE customerdb.customer t SET t.email = '[email protected]' WHERE t.id = 1
- 之后,我们将得到与插入相同的输出,除了操作类型更改为“UPDATE”,当然,Hibernate 使用的查询是“更新”查询:
00:08:57.893 [pool-1-thread-1] INFO c.b.l.d.listener.DebeziumListener - Key = 'Struct{id=1}' value = 'Struct{before=Struct{id=1,fullname=John Doe,[email protected]},after=Struct{id=1,fullname=John Doe,[email protected]},source=Struct{version=1.4.2.Final,connector=mysql,name=customer-mysql-db-server,ts_ms=1617746937000,db=customerdb,table=customer,server_id=1,file=binlog.000007,pos=1040,row=0,thread=19},op=u,ts_ms=1617746937703}'
Hibernate: update customer set email=?, fullname=? where id=?
00:08:57.938 [pool-1-thread-1] INFO c.b.l.d.listener.DebeziumListener - Updated Data: {fullname=John Doe, id=1, [email protected]} with Operation: UPDATE
- 我们可以验证目标数据库中约翰的电子邮件已更改:
id fullname email
1 John Doe [email protected]
Step3 删除记录
现在,我们可以通过执行以下命令删除 客户 表中的条目:
DELETE FROM customerdb.customer WHERE id = 1
同样,这里我们操作发生变化,再次查询:
00:12:16.892 [pool-1-thread-1] INFO c.b.l.d.listener.DebeziumListener - Key = 'Struct{id=1}' value = 'Struct{before=Struct{id=1,fullname=John Doe,[email protected]},source=Struct{version=1.4.2.Final,connector=mysql,name=customer-mysql-db-server,ts_ms=1617747136000,db=customerdb,table=customer,server_id=1,file=binlog.000007,pos=1406,row=0,thread=19},op=d,ts_ms=1617747136640}'
Hibernate: delete from customer where id=?
00:12:16.951 [pool-1-thread-1] INFO c.b.l.d.listener.DebeziumListener - Updated Data: {fullname=John Doe, id=1, [email protected]} with Operation: DELETE
我们可以验证目标数据库上的数据已被删除:
select * from customerdb.customer where id= 1
0 rows retrieved
Y 推荐文献
- [大数据] ETL之增量数据抽取(CDC) - 博客园/千千寰宇
- [数据库] 浅谈mysql的serverId/serverUuid - 博客园/千千寰宇
- [数据库] MYSQL之binlog概述 - 博客园/千千寰宇
- CDC问题 - 常见问题 - 实时计算Flink版 - Aliyun
X 参考文献
- Flink CDC、OGG、Debezium等基于日志开源CDC方案对比 - CSDN
- Debezium入门介绍 - baeldung-cn.com