 数学建模学习,包含各种常用模型和Matlab源码
数学建模学习,包含各种常用模型和Matlab源码目录
- 目录
- 评价类方法
- 层次分析法
- 搜索引擎
- 算法步骤
- 算法代码
- F4锁定单元格
- 优劣解距离法
- 算法步骤
- 算法代码
- 自输入权重代码
- 基于熵权法权重的代码
- 灰色关联分析
- 传统数理统计的不足之处
- 该方法的好处
- 算法步骤
- 算法代码
- 基于灰色关联度权重的代码
- 模糊综合评价
- 算法步骤
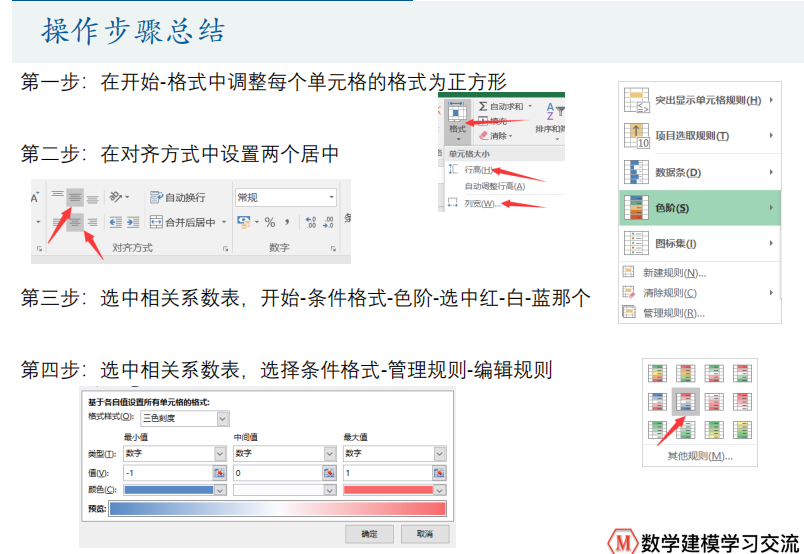
- 用excel绘制图形
- 饼图
- 柱状图
- 双向柱状图
- 条形图
- 双向条形图
- 直方图
- 折线图
- 双轴折线图
- 类别折线图
- 散点图
- 分类散点图
- 箱线图
- excel技巧
- 数据透视表(便于数据交互分析)
- 常见问题
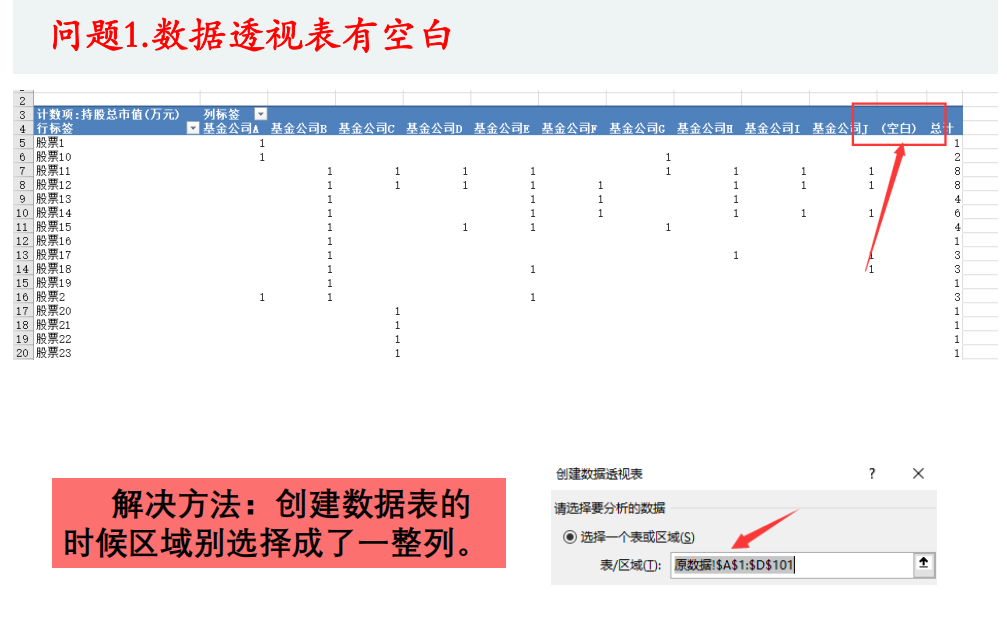
- 1.数据透视表有空白
- 2.日期或时刻为文本型
- 3.数值为文本型
- 强大的工具
- 插值算法(常用于数据缺失值处理)
- 低阶插值方法
- 中阶插值方法(龙格现象)(导数不符合)
- 高阶插值方法(导数保持一致)
- 算法代码
- 插值方法可以进行短期预测
- 数据缺失值处理
- 拟合算法
- 拟合优度(线性函数的评价指标)
- 算法代码
- 最小二乘法
- 拟合工具箱使用
- 相关学术名词解释 (word文件)
- 相关分析
- Pearson相关系数
- 算法代码
- SPSS
- 数据可视化
- 分析统计
- 矩阵散点图
- 假设检验
- 基本概念
- Pearson相关系数假设检验
- Pearson假设检验条件
- 正态分布检验
- JB检验
- 夏皮洛—威尔克检验
- Q—Q图检验
- Spearman相关系数
- 假设检验
- 两种相关系数的比较
- Pearson相关系数
- 图论
- 迪杰斯特拉算法(广度优先算法)
- 贝尔曼福特算法
- 算法代码
- 弗洛伊德算法
- 算法代码
- 多元回归分析
- 回归分析的分类
- 数据类型
- 数据收集
- 一元线性回归
- 解释变量模型
- null
- 多元线性回归
- 自变量不充分产生内生性
- 核心解释变量和控制变量解救内生性
- 回归模型解释
- 交互项
- 回归方法
- 软件
- 处理语法
- 代码
- R2较低处理方法
- 标准化回归消除量纲(度量影响力)
- 异方差
- 定义
- 异方差的影响和解决
- 检验异方差存在
- BP检验
- 怀特检验
- 异方差的解决
- 稳健标准误(推荐)
- 多重共线性
- 多重共线性检验
- 多重共线性处理方法
- 逐步回归
- 岭回归和lasso回归(逐步回归升级版)(解决多重共线性)
- 古典回归模型
- 岭回归
- λ选取
- 代码
- lasso回归(推荐)
- K折交叉验证
- 压缩不重要的自变量
- 适用情况
- 代码
- 分类模型
- 逻辑回归
- 二分类
- 多分类
- Fisher线性判别分析
- 二分类
- 多分类
- 逻辑回归
- 聚类模型
- K-means聚类算法(基于距离)
- 算法优劣
- K-means++改进算法(基于距离)
- spss操作
- 系统(层次)聚类(基于距离)(推荐)
- 算法流程
- 注意事项
- spss操作
- 肘部图(估计k)
- DBSCAN算法(基于密度)
- 基本概念
- 算法优劣
- 代码
- K-means聚类算法(基于距离)
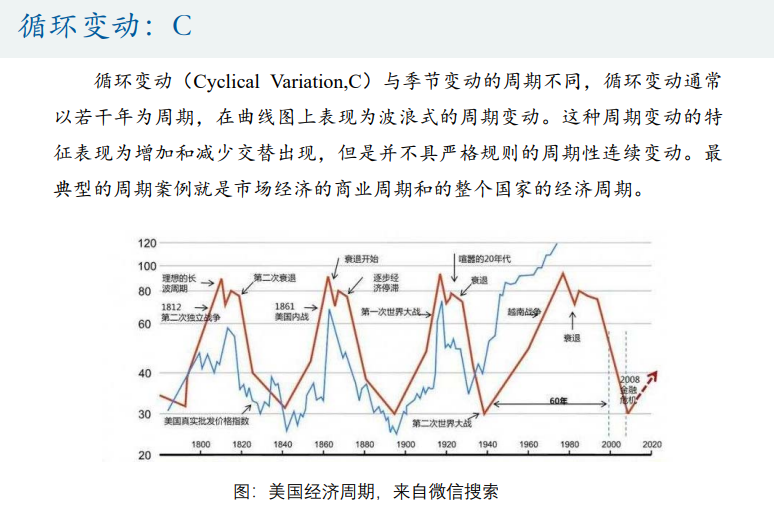
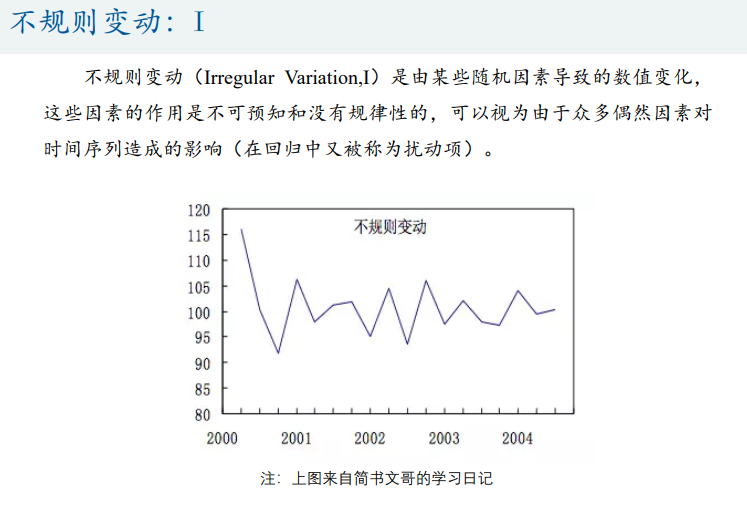
- 时间序列分析
- 基本概念
- 时间序列分解
- spss缺失值处理
- spss数据处理(时间序列图)
- 操作用途和步骤
- 模型建立
- 指数平滑模型
- 一元时间序列分析模型
- 建模思路和实例
- 季节性数据
- 人口预测
- 股票上证指数预测
- GDP增速预测
- 层次分析法
- 优化类方法
- 蒙特卡洛模拟
- 引例:浦丰投针实验
- 代码
- 概述
- 三门问题
- 代码
- 排队问题
- 代码
- 非线性约束问题
- 代码
- 代码
- 0-1规划问题
- 代码
- 导弹追踪问题
- 代码
- 旅行商问题
- 代码
- 估计自然常数
- 代码
- 武器升级
- 代码
- 选择决策方案模拟(换灯泡问题)
- 代码
- 引例:浦丰投针实验
- 蒙特卡洛模拟
评价类方法
层次分析法
搜索引擎
虫部落‐快搜 : https://search.chongbuluo.com/
算法步骤
1.写出判断矩阵
2.判断矩阵一致性检验
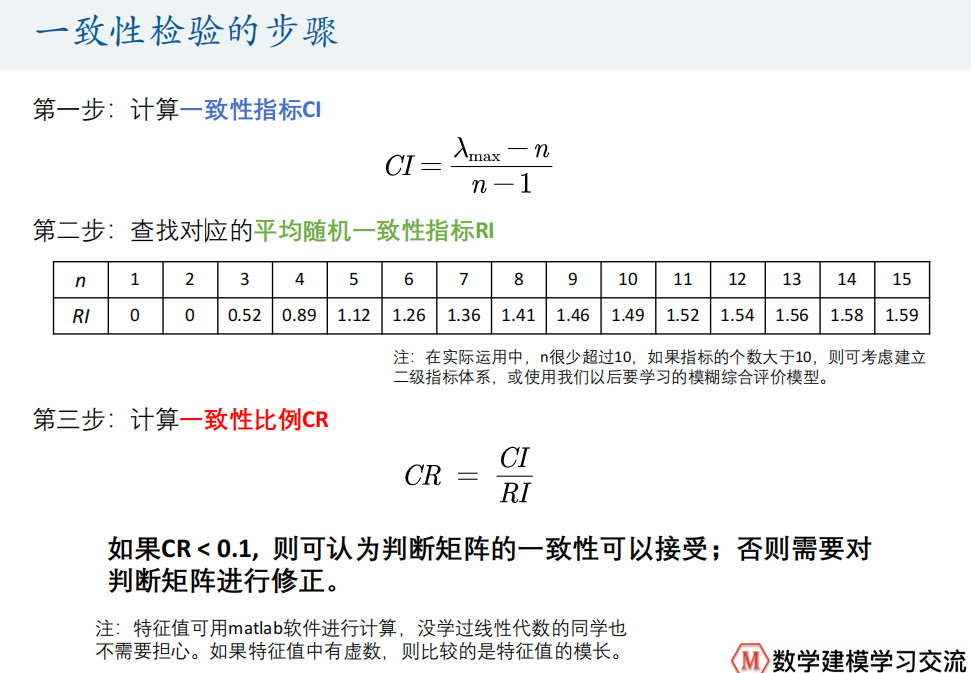
3.判断矩阵求权重
-
算术平均法

-
几何平均法
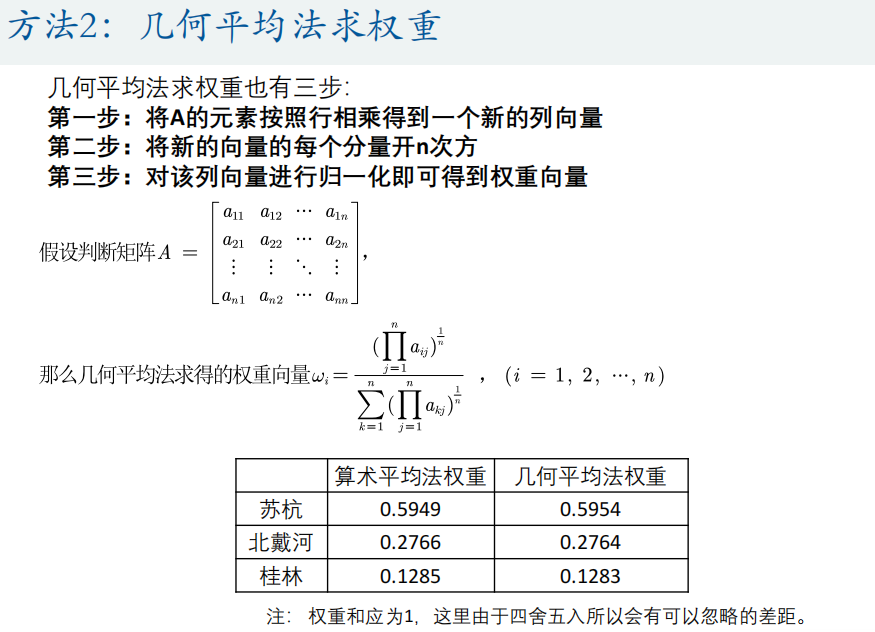
-
特征值法(最常用)
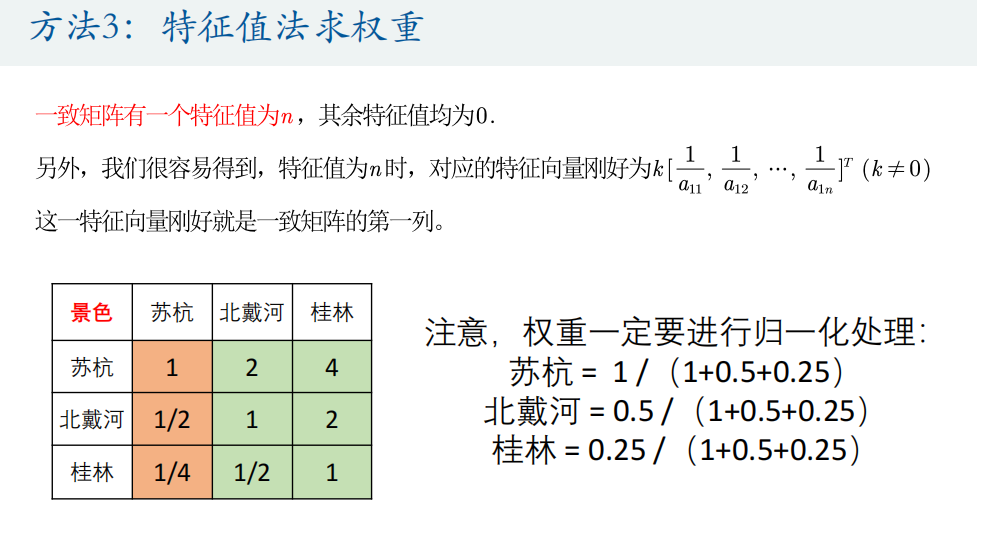
4.计算权重和
算法代码
%% 注意:在论文写作中,应该先对判断矩阵进行一致性检验,然后再计算权重,因为只有判断矩阵通过了一致性检验,其权重才是有意义的。
%% 在下面的代码中,我们先计算了权重,然后再进行了一致性检验,这是为了顺应计算过程,事实上在逻辑上是说不过去的。
%% 因此大家自己写论文中如果用到了层次分析法,一定要先对判断矩阵进行一致性检验。
%% 而且要说明的是,只有非一致矩阵的判断矩阵才需要进行一致性检验。
%% 如果你的判断矩阵本身就是一个一致矩阵,那么就没有必要进行一致性检验。% 在每一行的语句后面加上分号(一定要是英文的哦;中文的长这个样子;)表示不显示运行结果
% 多行注释:选中要注释的若干语句,快捷键Ctrl+R
% 取消注释:选中要取消注释的语句,快捷键Ctrl+Tdisp('请输入判断矩阵A') %matlab中disp()就是屏幕输出函数,类似于c语言中的printf()函数
% 注意,disp函数比较特殊,这里可要分号,可不要分号哦A=input('A=');
% 这里输入的就是我们的判断矩阵,其为n阶方阵(行数和列数相同)
% [1 3 1/3 1/3 1 1/3;1/3 1 1/4 1/5 1 1/5;3 4 1 1 2 3;3 5 1 1 2 1;1 1 1/2 1/2 1 1;3 5 1/3 1 1 1]
% [1 1 4 1/3 3;1 1 4 1/3 3;1/4 1/4 1 1/3 1/2;3 3 3 1 3;1/3 1/3 2 1/3 1]% 在开始下面正式的步骤之前,我们有必要检验下A是否因为粗心而输入有误
ERROR = 0; % 默认输入是没有错误的
%(1)检查矩阵A的维数是否不大于1或不是方阵
[r,c]=size(A);
%size(A)函数是用来求矩阵的大小的,返回一个行向量,第一个元素是矩阵的行数,第二个元素是矩阵的列数
%[r,c]=size(A) %将矩阵A的行数返回到第一个输出变量r,将矩阵的列数返回到第二个输出变量cif r ~= c || r <= 1% 注意哦,不等号是 ~= (~是键盘Tab上面那个键,要和Shift键同时按才会出来),别和C语言里面的!=搞混了% ||表示逻辑运算符‘或’(在键盘Enter上面,也要和Shift键一起按) 逻辑运算符且是 && (&读and,连接符号,是and的缩写。 )ERROR = 1;
end
% Matlab的判断语句,if所在的行不需要冒号,语句的最后一定要以end结尾 ;中间的语句要注意缩进。%(2)检验是否为正互反矩阵 a_ij > 0 且 a_ij * a_ji = 1
if ERROR == 0[n,n] = size(A);% 因为我们的判断矩阵A是一个非零方阵,所以这里的r和c相同,我们可以就用同一个字母n表示% 判断是否有元素小于0% for i = 1:n% for j = 1:n% if A(i,j)<=0% ERROR = 2;% end% end% endif sum(sum(A <= 0)) > 0ERROR = 2;end
end%顺便检验n是否超过了15,因为RI向量为15维
if ERROR == 0if n > 15ERROR = 3;end
endif ERROR == 0% 判断 a_ij * a_ji = 1 是否成立if sum(sum(A' .* A ~= ones(n))) > 0ERROR = 4;end% A' 表示求出 A 的转置矩阵,即将a_ij和a_ji互换位置% ones(n)函数生成一个n*n的全为1的方阵, zeros(n)函数生成一个n*n的全为0的方阵% ones(m,n)函数生成一个m*n的全为1的矩阵% MATLAB在矩阵的运算中,“/”号和“*”号代表矩阵之间的乘法与除法,对应元素之间的乘除法需要使用“./”和“.*”% 如果a_ij * a_ji = 1 满足, 那么A和A'对应元素相乘应该为1
endif ERROR == 0% % % % % % % % % % % % %方法1: 算术平均法求权重% % % % % % % % % % % % %% 第一步:将判断矩阵按照列归一化(每一个元素除以其所在列的和)% 第二步:将归一化的各列相加% 第三步:将相加后的向量除以n即可得到权重向量Sum_A = sum(A);% matlab中的sum函数的用法% a=sum(x);%按列求和% a=sum(x,2);%按行求和% a=sum(x(:));%对整个矩阵求和% % 基础:matlab中如何提取矩阵中指定位置的元素?% % (1)取指定行和列的一个元素(输出的是一个值)% % A(2,1) A(3,2)% % (2)取指定的某一行的全部元素(输出的是一个行向量)% % A(2,:) A(5,:)% % (3)取指定的某一列的全部元素(输出的是一个列向量)% % A(:,1) A(:,3)% % (4)取指定的某些行的全部元素(输出的是一个矩阵)% % A([2,5],:) 只取第二行和第五行(一共2行)% % A(2:5,:) 取第二行到第五行(一共4行)% % (5)取全部元素(按列拼接的,最终输出的是一个列向量)% % A(:)SUM_A = repmat(Sum_A,n,1);% B = repmat(A,m,n):将矩阵A复制m×n块,即把A作为B的元素,B由m×n个A平铺而成。% 另外一种替代的方法如下:% SUM_A = [];% for i = 1:n %循环哦,不需要加冒号,这里表示循环n次% SUM_A = [SUM_A;Sum_A];% endStand_A = A ./ SUM_A;% MATLAB在矩阵的运算中,“*”号和“/”号代表矩阵之间的乘法与除法,对应元素之间的乘除法需要使用“./”和“.*”% 这里我们直接将两个矩阵对应的元素相除即可disp('算术平均法求权重的结果为:');disp(sum(Stand_A,2) / n)% 首先对标准化后的矩阵按照行求和,得到一个列向量,然后再将这个列向量的每个元素同时除以n即可(注意这里也可以用./哦)% % % % % % % % % % % % %方法2: 几何平均法求权重% % % % % % % % % % % % %% 第一步:将A的元素按照行相乘得到一个新的列向量Prduct_A = prod(A,2);% prod函数和sum函数类似,一个用于乘,一个用于加% 第二步:将新的向量的每个分量开n次方Prduct_n_A = Prduct_A .^ (1/n);% 这里对元素操作,因此要加.号哦。 ^符号表示乘方哦 这里是开n次方,所以我们等价求1/n次方% 第三步:对该列向量进行归一化即可得到权重向量% 将这个列向量中的每一个元素除以这一个向量的和即可disp('几何平均法求权重的结果为:');disp(Prduct_n_A ./ sum(Prduct_n_A))% % % % % % % % % % % % %方法3: 特征值法求权重% % % % % % % % % % % % %% 计算矩阵A的特征值和特征向量的函数是eig(A),其中最常用的两个用法:% (1)E=eig(A):求矩阵A的全部特征值,构成向量E。% (2)[V,D]=eig(A):求矩阵A的全部特征值,构成对角阵D,并求A的特征向量构成V的列向量。(V的每一列都是D中与之相同列的特征值的特征向量)[V,D] = eig(A); %V是特征向量, D是由特征值构成的对角矩阵(除了对角线元素外,其余位置元素全为0)Max_eig = max(max(D)); %也可以写成max(D(:))哦~% 那么怎么找到最大特征值所在的位置了? 需要用到find函数,它可以用来返回向量或者矩阵中不为0的元素的位置索引。% 下面例子来自博客:https://www.cnblogs.com/anzhiwu815/p/5907033.html% 关于find函数的更加深入的用法可参考原文% >> X = [1 0 4 -3 0 0 0 8 6];% >> ind = find(X)% ind =% 1 3 4 8 9% 其有多种用法,比如返回前2个不为0的元素的位置:% >> ind = find(X,2)% >> ind =% 1 3%若X是一个矩阵,索引该如何返回呢?% >> X = [1 -3 0;0 0 8;4 0 6]% X =% 1 -3 0% 0 0 8% 4 0 6% >> ind = find(X)% ind =% 1% 3% 4% 8% 9% 这是因为在Matlab在存储矩阵时,是一列一列存储的,我们可以做一下验证:% >> X(4)% ans =% -3% 假如你需要按照行列的信息输出该怎么办呢?% [r,c] = find(X)% r =% 1% 3% 1% 2% 3% c =% 1% 1% 2% 3% 3% [r,c] = find(X,1) %只找第一个非0元素% r =% 1% c =% 1% 那么问题来了,我们要得到最大特征值的位置,就需要将包含所有特征值的这个对角矩阵D中,不等于最大特征值的位置全变为0% 这时候可以用到矩阵与常数的大小判断运算,共有三种运算符:大于> ;小于< ;等于 == (一个等号表示赋值;两个等号表示判断)% 例如:A > 2 会生成一个和A相同大小的矩阵,矩阵元素要么为0,要么为1(A中每个元素和2比较,如果大于2则为1,否则为0)[r,c]=find(D == Max_eig , 1);% 找到D中第一个与最大特征值相等的元素的位置,记录它的行和列。disp('特征值法求权重的结果为:');disp( V(:,c) ./ sum(V(:,c)) )% 我们先根据上面找到的最大特征值的列数c找到对应的特征向量,然后再进行标准化。% % % % % % % % % % % % %下面是计算一致性比例CR的环节% % % % % % % % % % % % %% 当CR<0.10时,我们认为判断矩阵的一致性可以接受;否则应对其进行修正。CI = (Max_eig - n) / (n-1);RI=[0 0.00001 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15% 这里n=2时,一定是一致矩阵,所以CI = 0,我们为了避免分母为0,将这里的第二个元素改为了很接近0的正数CR=CI/RI(n);disp('一致性指标CI=');disp(CI);disp('一致性比例CR=');disp(CR);if CR<0.10disp('因为CR<0.10,所以该判断矩阵A的一致性可以接受!');elsedisp('注意:CR >= 0.10,因此该判断矩阵A需要进行修改!');end
elseif ERROR == 1disp('请检查矩阵A的维数是否不大于1或不是方阵')
elseif ERROR == 2disp('请检查矩阵A中有元素小于等于0')
elseif ERROR == 3disp('A的维数n超过了15,请减少准则层的数量')
elseif ERROR == 4disp('请检查矩阵A中存在i、j不满足A_ij * A_ji = 1')
end
F4锁定单元格
优劣解距离法
算法步骤
-
正向化
将所有的指标转化为极大型指标
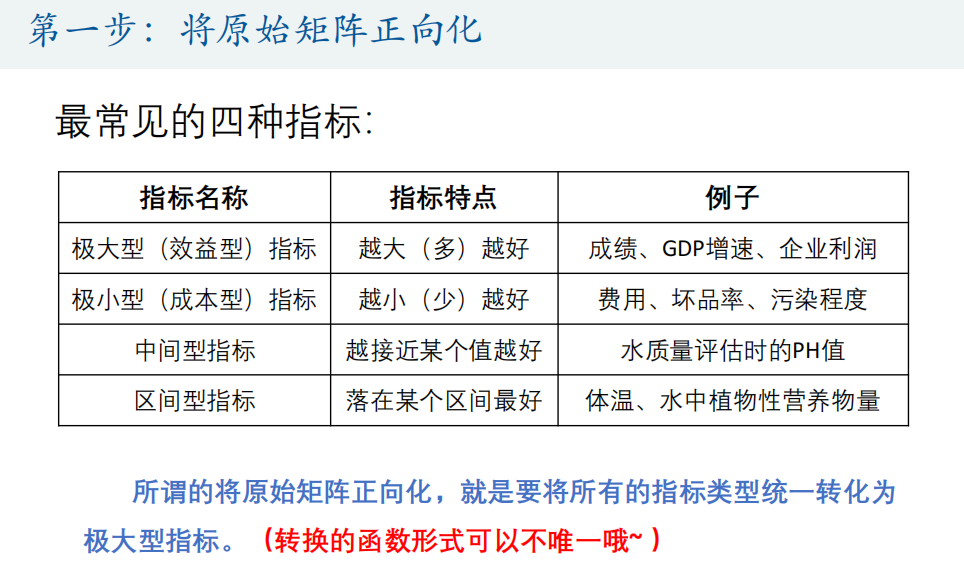
-
正向化矩阵标准化
标准化的目的是为了消除量纲的影响
-
计算得分

-
归一化
-
用excel对数据进行可视化
算法代码
主函数:
%% 第一步:把数据复制到工作区,并将这个矩阵命名为X
% (1)在工作区右键,点击新建(Ctrl+N),输入变量名称为X
% (2)在Excel中复制数据,再回到Excel中右键,点击粘贴Excel数据(Ctrl+Shift+V)
% (3)关掉这个窗口,点击X变量,右键另存为,保存为mat文件(下次就不用复制粘贴了,只需使用load命令即可加载数据)
% (4)注意,代码和数据要放在同一个目录下哦,且Matlab的当前文件夹也要是这个目录。
clear;clc
load data_water_quality.mat
%% 注意:如果提示: 错误使用 load,无法读取文件 'data_water_quality.mat'。没有此类文件或目录。
% 那么原因是因为你的Matlab的当前文件夹中不存在这个文件
% 可以使用cd函数修改Matlab的当前文件夹
% 比如说,我的代码和数据放在了: D:第2讲.TOPSIS法(优劣解距离法)\代码和例题数据
% 那么我就可以输入命令:
% cd 'D:第2讲.TOPSIS法(优劣解距离法)\代码和例题数据'
% 也可以看我更新的视频:“更新9_Topsis代码为什么运行失败_得分结果怎么可视化以及权重的确定如何更加准确”,里面有介绍%% 第二步:判断是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']);if Judge == 1Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: '); %[2,3,4]disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ')Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: '); %[2,1,3]% 注意,Position和Type是两个同维度的行向量for i = 1 : size(Position,2) %这里需要对这些列分别处理,因此我们需要知道一共要处理的次数,即循环的次数X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));% Positivization是我们自己定义的函数,其作用是进行正向化,其一共接收三个参数% 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) 回顾上一讲的知识,X(:,n)表示取第n列的全部元素% 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型)% 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列% 该函数有一个返回值,它返回正向化之后的指标,我们可以将其直接赋值给我们原始要处理的那一列向量enddisp('正向化后的矩阵 X = ')disp(X)
end%% 第三步:对正向化后的矩阵进行标准化
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)%% 第四步:计算与最大值的距离和最小值的距离,并算出得分
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ],2) .^ 0.5; % D+ 与最大值的距离向量
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ],2) .^ 0.5; % D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S)
[sorted_S,index] = sort(stand_S ,'descend')% A = magic(5) % 幻方矩阵
% M = magic(n)返回由1到n^2的整数构成并且总行数和总列数相等的n×n矩阵。阶次n必须为大于或等于3的标量。
% sort(A)若A是向量不管是列还是行向量,默认都是对A进行升序排列。sort(A)是默认的升序,而sort(A,'descend')是降序排序。
% sort(A)若A是矩阵,默认对A的各列进行升序排列
% sort(A,dim)
% dim=1时等效sort(A)
% dim=2时表示对A中的各行元素升序排列
% A = [2,1,3,8]
% Matlab中给一维向量排序是使用sort函数:sort(A),排序是按升序进行的,其中A为待排序的向量;
% 若欲保留排列前的索引,则可用 [sA,index] = sort(A,'descend') ,排序后,sA是排序好的向量,index是向量sA中对A的索引。
% sA = 8 3 2 1
% index = 4 3 1 2
Positivization 函数
% function [输出变量] = 函数名称(输入变量)
% 函数的中间部分都是函数体
% 函数的最后要用end结尾
% 输出变量和输入变量可以有多个,用逗号隔开
% function [a,b,c]=test(d,e,f)
% a=d+e;
% b=e+f;
% c=f+d;
% end
% 自定义的函数要单独放在一个m文件中,不可以直接放在主函数里面(和其他大多数语言不同)function [posit_x] = Positivization(x,type,i)
% 输入变量有三个:
% x:需要正向化处理的指标对应的原始列向量
% type: 指标的类型(1:极小型, 2:中间型, 3:区间型)
% i: 正在处理的是原始矩阵中的哪一列
% 输出变量posit_x表示:正向化后的列向量if type == 1 %极小型disp(['第' num2str(i) '列是极小型,正在正向化'] )posit_x = Min2Max(x); %调用Min2Max函数来正向化disp(['第' num2str(i) '列极小型正向化处理完成'] )disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')elseif type == 2 %中间型disp(['第' num2str(i) '列是中间型'] )best = input('请输入最佳的那一个值: ');posit_x = Mid2Max(x,best);disp(['第' num2str(i) '列中间型正向化处理完成'] )disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')elseif type == 3 %区间型disp(['第' num2str(i) '列是区间型'] )a = input('请输入区间的下界: ');b = input('请输入区间的上界: '); posit_x = Inter2Max(x,a,b);disp(['第' num2str(i) '列区间型正向化处理完成'] )disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')elsedisp('没有这种类型的指标,请检查Type向量中是否有除了1、2、3之外的其他值')end
end
正向化函数
function [posit_x] = Inter2Max(x,a,b)r_x = size(x,1); % row of x M = max([a-min(x),max(x)-b]);posit_x = zeros(r_x,1); %zeros函数用法: zeros(3) zeros(3,1) ones(3)% 初始化posit_x全为0 初始化的目的是节省处理时间for i = 1: r_xif x(i) < aposit_x(i) = 1-(a-x(i))/M;elseif x(i) > bposit_x(i) = 1-(x(i)-b)/M;elseposit_x(i) = 1;endend
endfunction [posit_x] = Mid2Max(x,best)M = max(abs(x-best));posit_x = 1 - abs(x-best) / M;
endfunction [posit_x] = Min2Max(x)posit_x = max(x) - x;%posit_x = 1 ./ x; %如果x全部都大于0,也可以这样正向化
end
自输入权重代码
主函数
%% 第一步:把数据复制到工作区,并将这个矩阵命名为X
% (1)在工作区右键,点击新建(Ctrl+N),输入变量名称为X
% (2)在Excel中复制数据,再回到Excel中右键,点击粘贴Excel数据(Ctrl+Shift+V)
% (3)关掉这个窗口,点击X变量,右键另存为,保存为mat文件(下次就不用复制粘贴了,只需使用load命令即可加载数据)
% (4)注意,代码和数据要放在同一个目录下哦,且Matlab的当前文件夹也要是这个目录。
clear;clc
load data_water_quality.mat
%% 注意:如果提示: 错误使用 load,无法读取文件 'data_water_quality.mat'。没有此类文件或目录。
% 那么原因是因为你的Matlab的当前文件夹中不存在这个文件
% 可以使用cd函数修改Matlab的当前文件夹
% 比如说,我的代码和数据放在了: D:第2讲.TOPSIS法(优劣解距离法)\代码和例题数据
% 那么我就可以输入命令:
% cd 'D:第2讲.TOPSIS法(优劣解距离法)\代码和例题数据'
% 也可以看我更新的视频:“更新9_Topsis代码为什么运行失败_得分结果怎么可视化以及权重的确定如何更加准确”,里面有介绍%% 第二步:判断是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']);if Judge == 1Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: '); %[2,3,4]disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ')Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: '); %[2,1,3]% 注意,Position和Type是两个同维度的行向量for i = 1 : size(Position,2) %这里需要对这些列分别处理,因此我们需要知道一共要处理的次数,即循环的次数X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));% Positivization是我们自己定义的函数,其作用是进行正向化,其一共接收三个参数% 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) 回顾上一讲的知识,X(:,n)表示取第n列的全部元素% 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型)% 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列% 该函数有一个返回值,它返回正向化之后的指标,我们可以将其直接赋值给我们原始要处理的那一列向量enddisp('正向化后的矩阵 X = ')disp(X)
end
%% 作业:在这里增加是否需要算加权
% 补充一个基础知识:m*n维的矩阵A 点乘 n维行向量B,等于这个A的每一行都点乘B
% (注意:2017以及之后版本的Matlab才支持,老版本Matlab会报错)
% % 假如原始数据为:
% A=[1, 2, 3;
% 2, 4, 6]
% % 权重矩阵为:
% B=[ 0.2, 0.5 ,0.3 ]
% % 加权后为:
% C=A .* B
% 0.2000 1.0000 0.9000
% 0.4000 2.0000 1.8000
% 类似的,还有矩阵和向量的点除, 大家可以自己试试计算A ./ B
% 注意,矩阵和向量没有 .- 和 .+ 哦 ,大家可以试试,如果计算A.+B 和 A.-B会报什么错误。%% 这里补充一个小插曲
% % 在上一讲层次分析法的代码中,我们可以优化以下的语句:
% % Sum_A = sum(A);
% % SUM_A = repmat(Sum_A,n,1);
% % Stand_A = A ./ SUM_A;
% % 事实上,我们把第三行换成:Stand_A = A ./ Sum_A; 也是可以的哦
% % (再次强调,新版本的Matlab才能运行哦)%% 让用户判断是否需要增加权重
disp('请输入是否需要增加权重向量,需要输入1,不需要输入0')
Judge = input('请输入是否需要增加权重: ');
if Judge == 1disp(['如果你有3个指标,你就需要输入3个权重,例如它们分别为0.25,0.25,0.5, 则你需要输入[0.25,0.25,0.5]']);weigh = input(['你需要输入' num2str(m) '个权数。' '请以行向量的形式输入这' num2str(m) '个权重: ']);OK = 0; % 用来判断用户的输入格式是否正确while OK == 0 if abs(sum(weigh) - 1)<0.000001 && size(weigh,1) == 1 && size(weigh,2) == m % 这里要注意浮点数的运算是不精准的。OK =1;elseweigh = input('你输入的有误,请重新输入权重行向量: ');endend
elseweigh = ones(1,m) ./ m ; %如果不需要加权重就默认权重都相同,即都为1/m
end%% 第三步:对正向化后的矩阵进行标准化
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)%% 第四步:计算与最大值的距离和最小值的距离,并算出得分
D_P = sum(((Z - repmat(max(Z),n,1)) .^ 2 ) .* repmat(weigh,n,1) ,2) .^ 0.5; % D+ 与最大值的距离向量
D_N = sum(((Z - repmat(min(Z),n,1)) .^ 2 ) .* repmat(weigh,n,1) ,2) .^ 0.5; % D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S)
[sorted_S,index] = sort(stand_S ,'descend')% A = magic(5) % 幻方矩阵
% M = magic(n)返回由1到n^2的整数构成并且总行数和总列数相等的n×n矩阵。阶次n必须为大于或等于3的标量。
% sort(A)若A是向量不管是列还是行向量,默认都是对A进行升序排列。sort(A)是默认的升序,而sort(A,'descend')是降序排序。
% sort(A)若A是矩阵,默认对A的各列进行升序排列
% sort(A,dim)
% dim=1时等效sort(A)
% dim=2时表示对A中的各行元素升序排列
% A = [2,1,3,8]
% Matlab中给一维向量排序是使用sort函数:sort(A),排序是按升序进行的,其中A为待排序的向量;
% 若欲保留排列前的索引,则可用 [sA,index] = sort(A,'descend') ,排序后,sA是排序好的向量,index是向量sA中对A的索引。
% sA = 8 3 2 1
% index = 4 3 1 2
基于熵权法权重的代码
%% 第一步:把数据复制到工作区,并将这个矩阵命名为X
% (1)在工作区右键,点击新建(Ctrl+N),输入变量名称为X
% (2)在Excel中复制数据,再回到Excel中右键,点击粘贴Excel数据(Ctrl+Shift+V)
% (3)关掉这个窗口,点击X变量,右键另存为,保存为mat文件(下次就不用复制粘贴了,只需使用load命令即可加载数据)
% (4)注意,代码和数据要放在同一个目录下哦。
% clear;clc
% load data_water_quality.mat%% 第二步:判断是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']);if Judge == 1Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: '); %[2,3,4]disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ')Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: '); %[2,1,3]% 注意,Position和Type是两个同维度的行向量for i = 1 : size(Position,2) %这里需要对这些列分别处理,因此我们需要知道一共要处理的次数,即循环的次数X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));% Positivization是我们自己定义的函数,其作用是进行正向化,其一共接收三个参数% 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) 回顾上一讲的知识,X(:,n)表示取第n列的全部元素% 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型)% 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列% 该函数有一个返回值,它返回正向化之后的指标,我们可以将其直接赋值给我们原始要处理的那一列向量enddisp('正向化后的矩阵 X = ')disp(X)
end
%% 作业:在这里增加是否需要算加权
% 补充一个基础知识:m*n维的矩阵A 点乘 n维行向量B,等于这个A的每一行都点乘B
% (注意:2017以及之后版本的Matlab才支持,老版本Matlab会报错)
% % 假如原始数据为:
% A=[1, 2, 3;
% 2, 4, 6]
% % 权重矩阵为:
% B=[ 0.2, 0.5 ,0.3 ]
% % 加权后为:
% C=A .* B
% 0.2000 1.0000 0.9000
% 0.4000 2.0000 1.8000
% 类似的,还有矩阵和向量的点除, 大家可以自己试试计算A ./ B
% 注意,矩阵和向量没有 .- 和 .+ 哦 ,大家可以试试,如果计算A.+B 和 A.-B会报什么错误。%% 这里补充一个小插曲
% % 在上一讲层次分析法的代码中,我们可以优化以下的语句:
% % Sum_A = sum(A);
% % SUM_A = repmat(Sum_A,n,1);
% % Stand_A = A ./ SUM_A;
% % 事实上,我们把第三行换成:Stand_A = A ./ Sum_A; 也是可以的哦
% % (再次强调,新版本的Matlab才能运行哦)%% 第三步:对正向化后的矩阵进行标准化
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)%% 让用户判断是否需要增加权重
disp("请输入是否需要增加权重向量,需要输入1,不需要输入0")
Judge = input('请输入是否需要增加权重: ');
if Judge == 1Judge = input('使用熵权法确定权重请输入1,否则输入0: ');if Judge == 1if sum(sum(Z<0)) >0 % 如果之前标准化后的Z矩阵中存在负数,则重新对X进行标准化disp('原来标准化得到的Z矩阵中存在负数,所以需要对X重新标准化')for i = 1:nfor j = 1:mZ(i,j) = [X(i,j) - min(X(:,j))] / [max(X(:,j)) - min(X(:,j))];endenddisp('X重新进行标准化得到的标准化矩阵Z为: ')disp(Z)endweight = Entropy_Method(Z);disp('熵权法确定的权重为:')disp(weight)elsedisp(['如果你有3个指标,你就需要输入3个权重,例如它们分别为0.25,0.25,0.5, 则你需要输入[0.25,0.25,0.5]']);weight = input(['你需要输入' num2str(m) '个权数。' '请以行向量的形式输入这' num2str(m) '个权重: ']);OK = 0; % 用来判断用户的输入格式是否正确while OK == 0 if abs(sum(weight) -1)<0.000001 && size(weight,1) == 1 && size(weight,2) == m % 注意,Matlab中浮点数的比较要小心OK =1;elseweight = input('你输入的有误,请重新输入权重行向量: ');endendend
elseweight = ones(1,m) ./ m ; %如果不需要加权重就默认权重都相同,即都为1/m
end%% 第四步:计算与最大值的距离和最小值的距离,并算出得分
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ] .* repmat(weight,n,1) ,2) .^ 0.5; % D+ 与最大值的距离向量
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ] .* repmat(weight,n,1) ,2) .^ 0.5; % D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S)
[sorted_S,index] = sort(stand_S ,'descend')% A = magic(5) % 幻方矩阵
% M = magic(n)返回由1到n^2的整数构成并且总行数和总列数相等的n×n矩阵。阶次n必须为大于或等于3的标量。
% sort(A)若A是向量不管是列还是行向量,默认都是对A进行升序排列。sort(A)是默认的升序,而sort(A,'descend')是降序排序。
% sort(A)若A是矩阵,默认对A的各列进行升序排列
% sort(A,dim)
% dim=1时等效sort(A)
% dim=2时表示对A中的各行元素升序排列
% A = [2,1,3,8]
% Matlab中给一维向量排序是使用sort函数:sort(A),排序是按升序进行的,其中A为待排序的向量;
% 若欲保留排列前的索引,则可用 [sA,index] = sort(A,'descend') ,排序后,sA是排序好的向量,index是向量sA中对A的索引。
% sA = 8 3 2 1
% index = 4 3 1 2增添功能函数
function [W] = Entropy_Method(Z)
% 计算有n个样本,m个指标的样本所对应的的熵权
% 输入
% Z : n*m的矩阵(要经过正向化和标准化处理,且元素中不存在负数)
% 输出
% W:熵权,1*m的行向量%% 计算熵权[n,m] = size(Z);D = zeros(1,m); % 初始化保存信息效用值的行向量for i = 1:mx = Z(:,i); % 取出第i列的指标p = x / sum(x);% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以这里我们自己定义一个函数e = -sum(p .* mylog(p)) / log(n); % 计算信息熵D(i) = 1- e; % 计算信息效用值endW = D ./ sum(D); % 将信息效用值归一化,得到权重
end% 重新定义一个mylog函数,当输入的p中元素为0时,返回0
function [lnp] = mylog(p)
n = length(p); % 向量的长度
lnp = zeros(n,1); % 初始化最后的结果for i = 1:n % 开始循环if p(i) == 0 % 如果第i个元素为0lnp(i) = 0; % 那么返回的第i个结果也为0elselnp(i) = log(p(i)); endend
end
灰色关联分析
传统数理统计的不足之处

该方法的好处

算法步骤
- 画统计图(excel)
- 确定分析数列(即确定参考数列(母序列)和比较数列(子序列))
- 对变量进行预处理(目的:1.去量纲;2.缩小变量范围简化计算)
- 计算子序列中多个指标与母序列的关联系数
- 求每个指标对于母指标的关联度(关联系数求平均)
- 比较关联度大小得出结论(关联度越大表示联系越紧密)
算法代码
%% 灰色关联分析用于系统分析例题的讲解
clear;clc
load gdp.mat % 导入数据 一个6*4的矩阵
% 不会导入数据的同学可以看看第二讲topsis模型,我们也可以自己在工作区新建变量,并把Excel的数据粘贴过来
% 注意Matlab的当前文件夹一定要切换到有数据文件的这个文件夹内
Mean = mean(gdp); % 求出每一列的均值以供后续的数据预处理
gdp = gdp ./ repmat(Mean,size(gdp,1),1); %size(gdp,1)=6, repmat(Mean,6,1)可以将矩阵进行复制,复制为和gdp同等大小,然后使用点除(对应元素相除),这些在第一讲层次分析法都讲过
disp('预处理后的矩阵为:'); disp(gdp)
Y = gdp(:,1); % 母序列:这里默认第一列为母序列
X = gdp(:,2:end); % 子序列:第二列到最后一列为子序列
absX0_Xi = abs(X - repmat(Y,1,size(X,2))) % 计算|X0-Xi|矩阵(在这里我们把X0定义为了Y)
a = min(min(absX0_Xi)) % 计算两级最小差a
b = max(max(absX0_Xi)) % 计算两级最大差b
rho = 0.5; % 分辨系数取0.5
gamma = (a+rho*b) ./ (absX0_Xi + rho*b) % 计算子序列中各个指标与母序列的关联系数
disp('子序列中各个指标的灰色关联度分别为:')
disp(mean(gamma))
基于灰色关联度权重的代码
%% 灰色关联分析用于综合评价模型例题的讲解
clear;clc
load data_water_quality.mat
% 不会导入数据的同学可以看看第二讲topsis模型,我们也可以自己在工作区新建变量,并把Excel的数据粘贴过来
% 注意Matlab的当前文件夹一定要切换到有数据文件的这个文件夹内%% 判断是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']); %1if Judge == 1Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: '); %[2,3,4]disp('请输入需要处理的这些列的指 标类型(1:极小型, 2:中间型, 3:区间型) ')Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: '); %[2,1,3]% 注意,Position和Type是两个同维度的行向量for i = 1 : size(Position,2) %这里需要对这些列分别处理,因此我们需要知道一共要处理的次数,即循环的次数X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));% Positivization是我们自己定义的函数,其作用是进行正向化,其一共接收三个参数% 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) 回顾上一讲的知识,X(:,n)表示取第n列的全部元素% 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型)% 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列% 该函数有一个返回值,它返回正向化之后的指标,我们可以将其直接赋值给我们原始要处理的那一列向量enddisp('正向化后的矩阵 X = ')disp(X)
end%% 对正向化后的矩阵进行预处理
Mean = mean(X); % 求出每一列的均值以供后续的数据预处理
Z = X ./ repmat(Mean,size(X,1),1);
disp('预处理后的矩阵为:'); disp(Z)%% 构造母序列和子序列
Y = max(Z,[],2); % 母序列为虚拟的,用每一行的最大值构成的列向量表示母序列
X = Z; % 子序列就是预处理后的数据矩阵%% 计算得分
absX0_Xi = abs(X - repmat(Y,1,size(X,2))) % 计算|X0-Xi|矩阵
a = min(min(absX0_Xi)) % 计算两级最小差a
b = max(max(absX0_Xi)) % 计算两级最大差b
rho = 0.5; % 分辨系数取0.5
gamma = (a+rho*b) ./ (absX0_Xi + rho*b) % 计算子序列中各个指标与母序列的关联系数
weight = mean(gamma) / sum(mean(gamma)); % 利用子序列中各个指标的灰色关联度计算权重
score = sum(X .* repmat(weight,size(X,1),1),2); % 未归一化的得分
stand_S = score / sum(score); % 归一化后的得分
[sorted_S,index] = sort(stand_S ,'descend') % 进行排序
模糊综合评价
算法步骤
- 确定因素集(评价指标)(分类来划分层级),评语集(评价度量),因素集权重(指标权重)
- 确定模糊综合判断矩阵(分别建立每个指标的隶属函数(指标正向化))
- 模糊向量=权重集 * 模糊综合判断矩阵
- 综合评判得出结果
用excel绘制图形
饼图
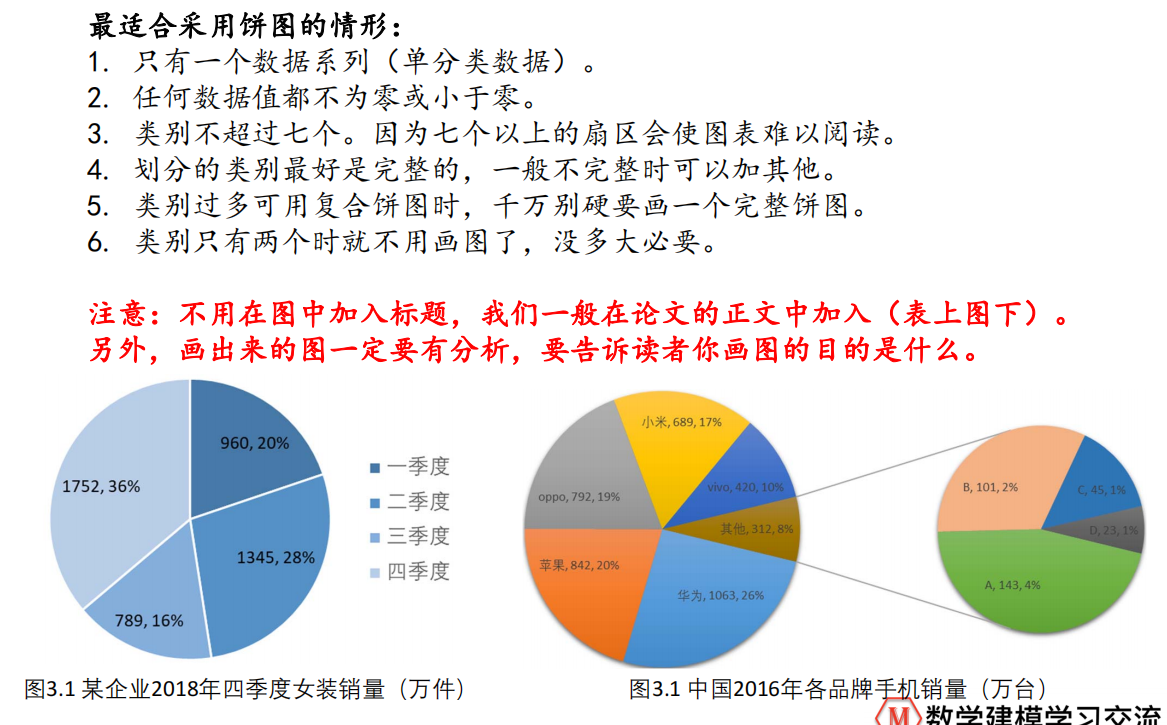
柱状图
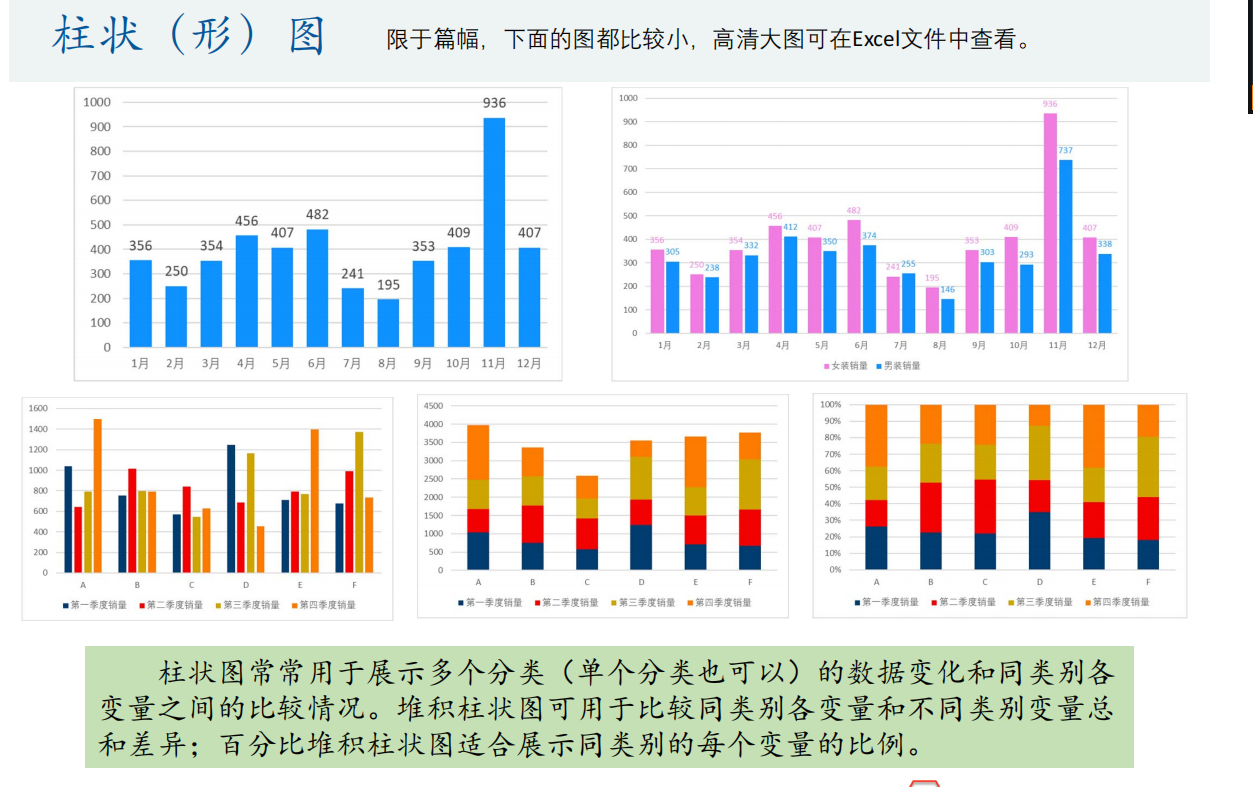
双向柱状图
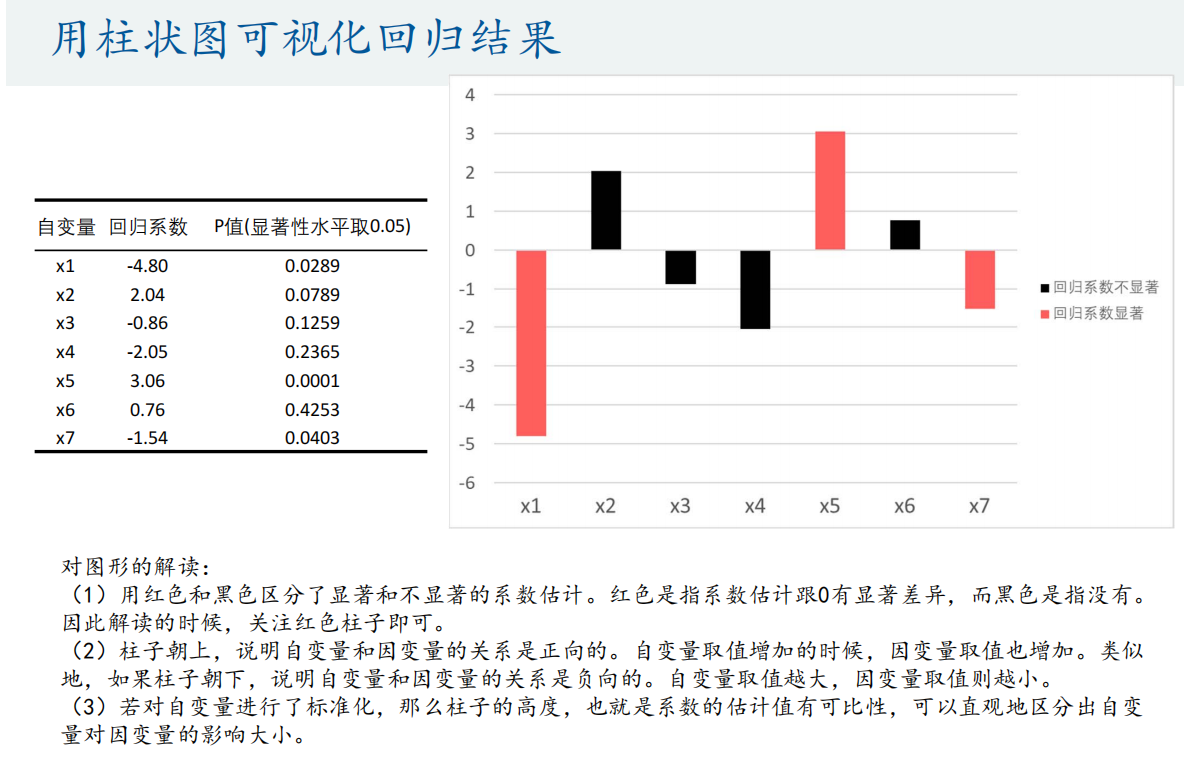
条形图
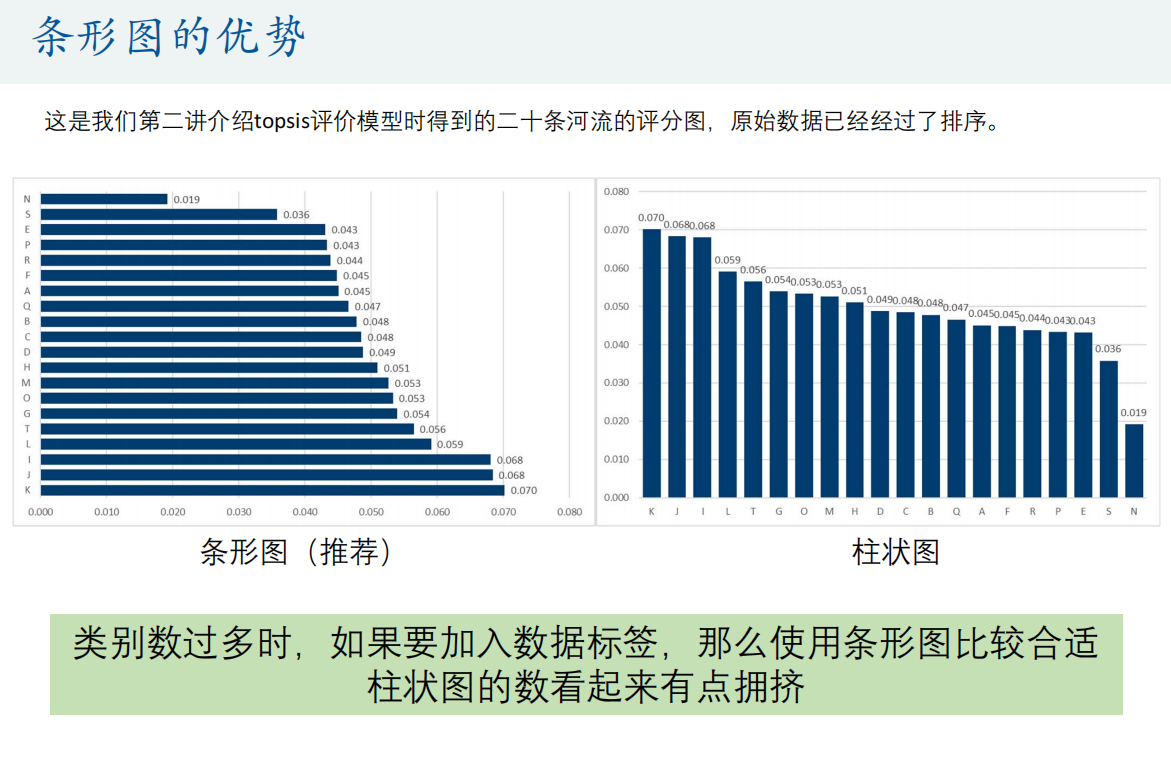
双向条形图
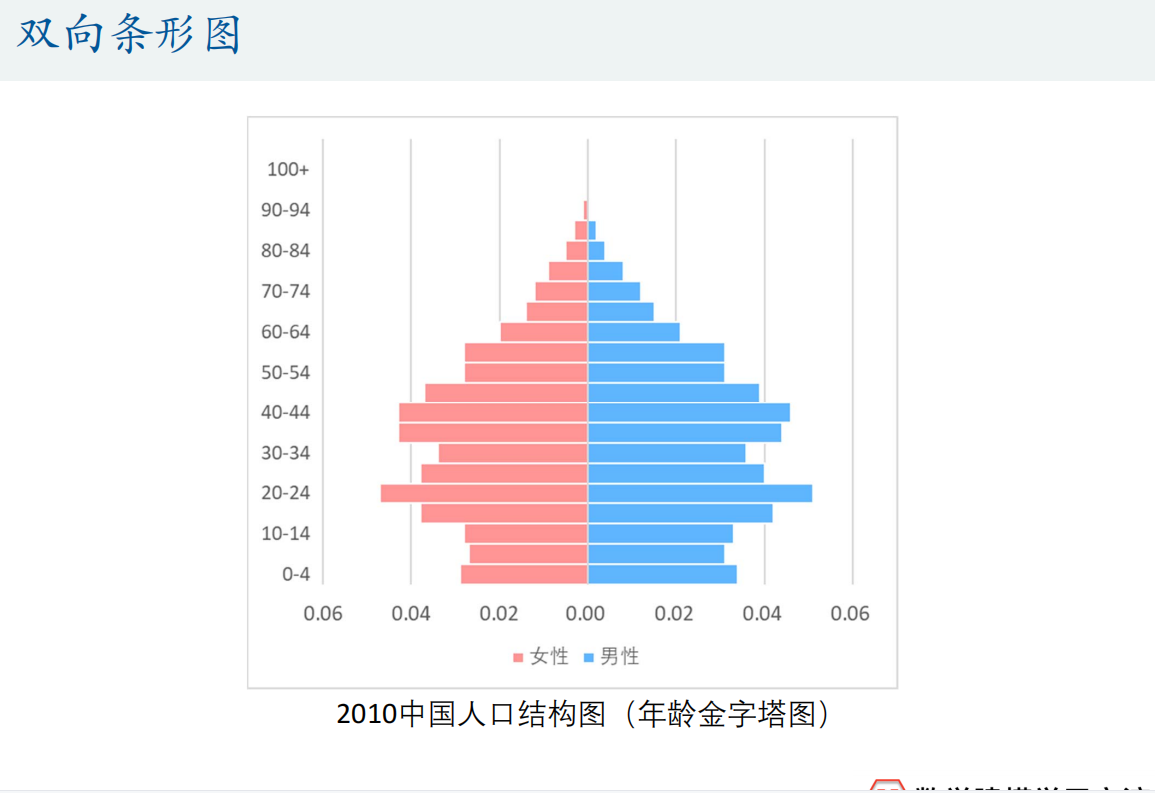
直方图
折线图
双轴折线图
类别折线图
散点图

分类散点图
箱线图

excel技巧

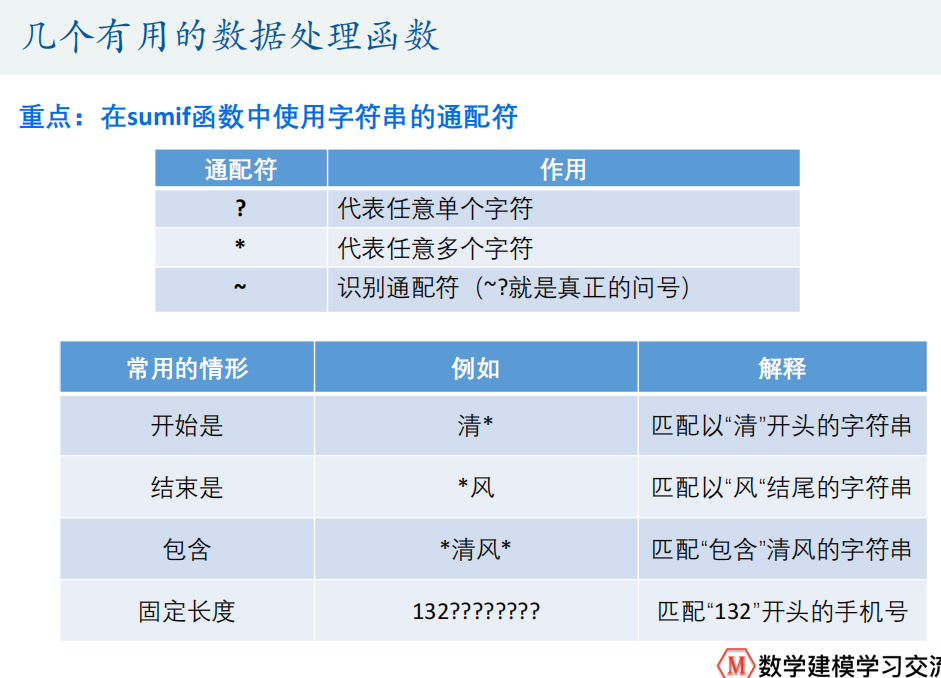
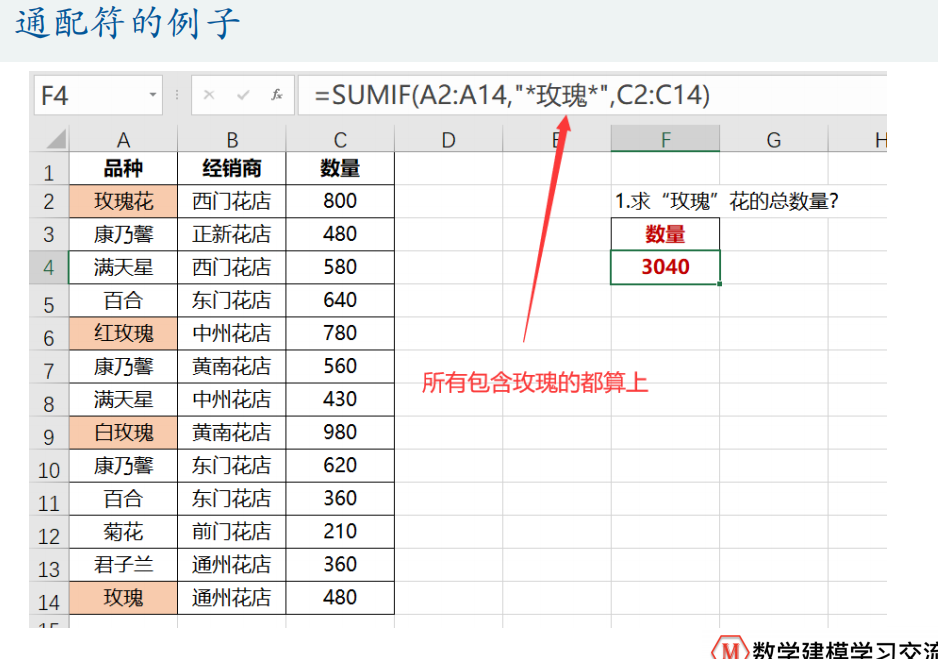
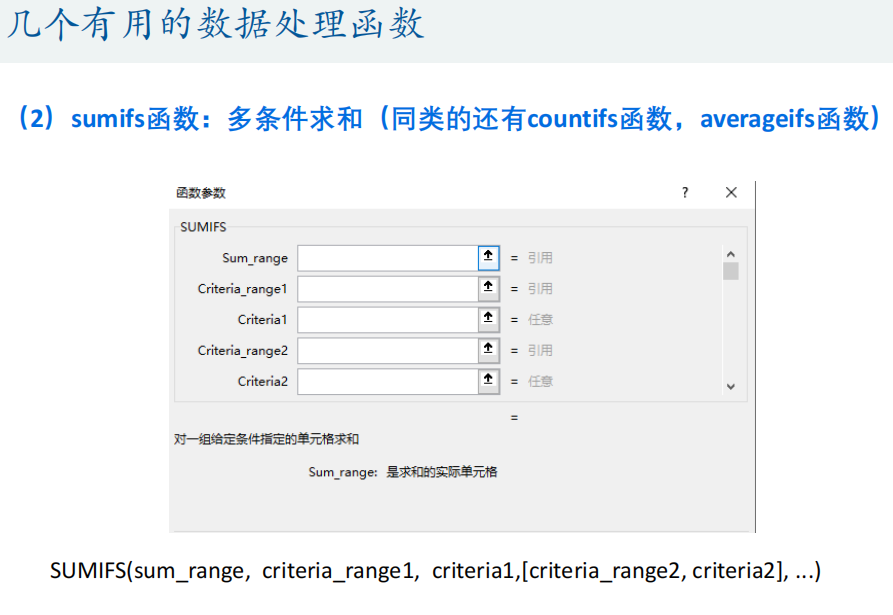
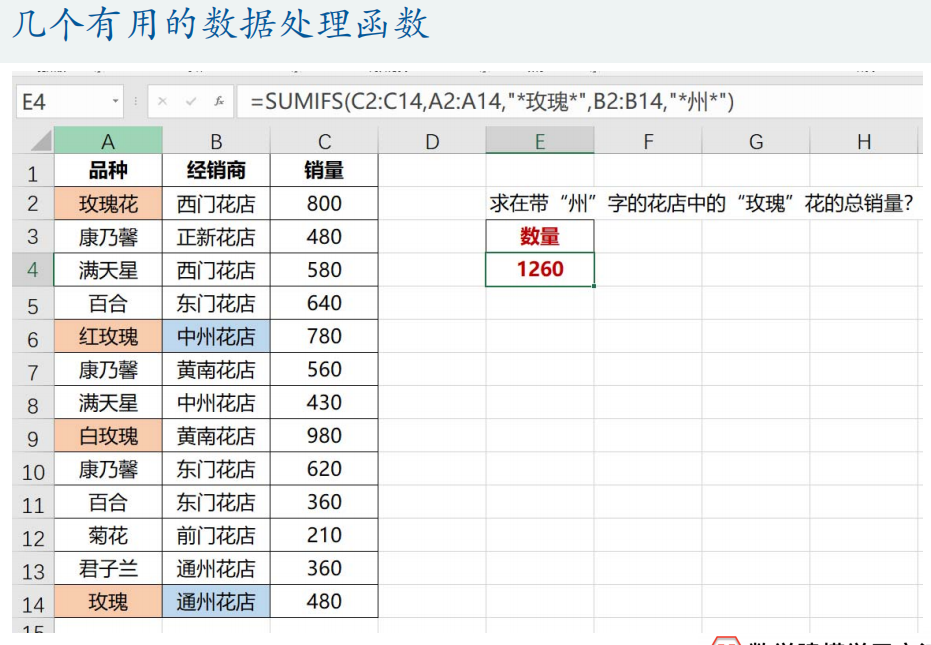
数据透视表(便于数据交互分析)

常见问题

1.数据透视表有空白
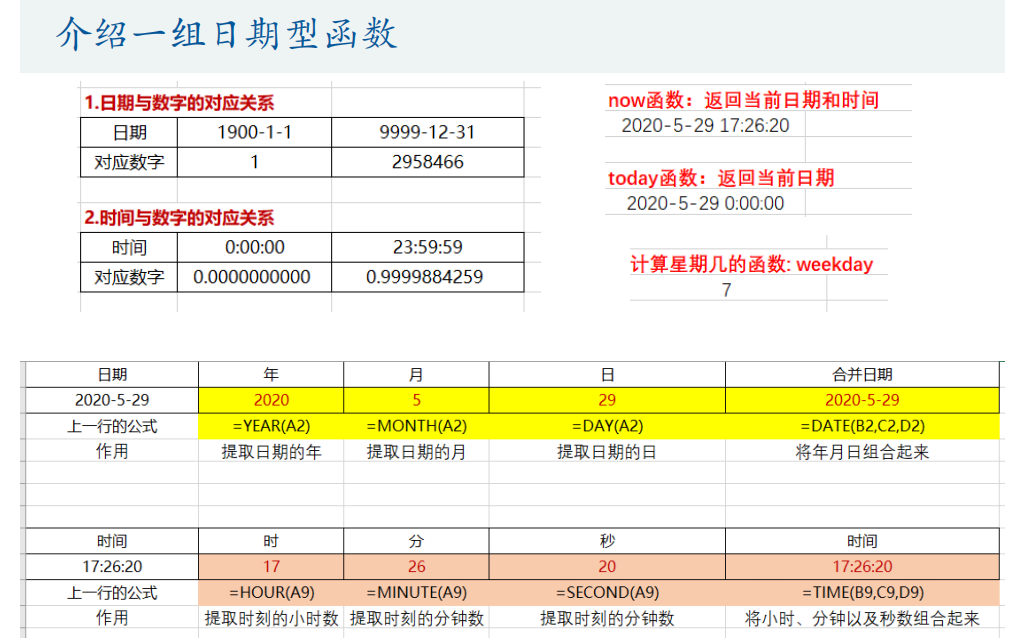
2.日期或时刻为文本型
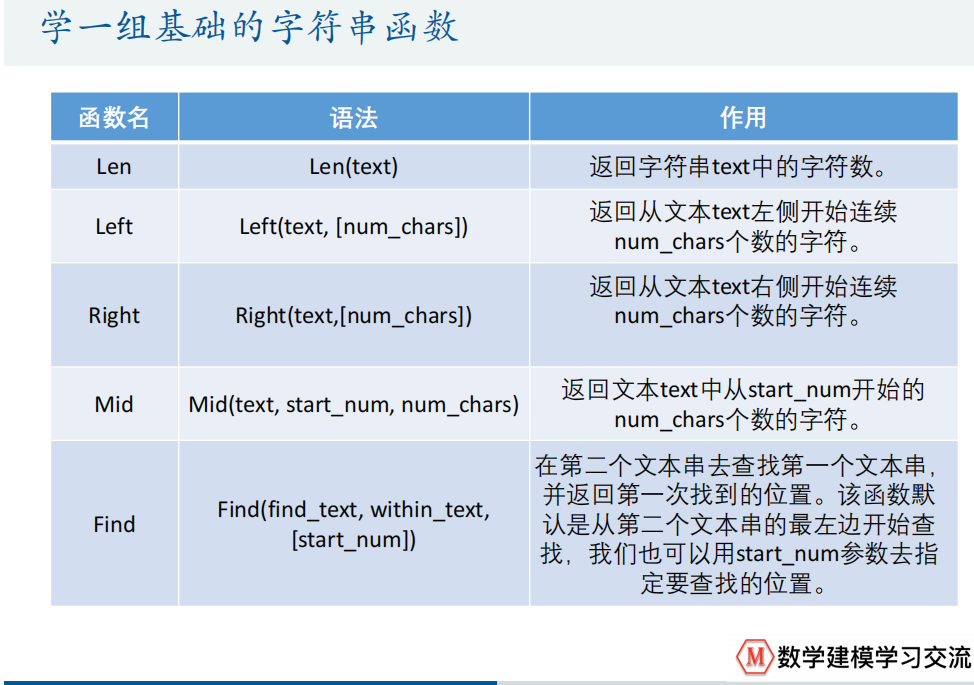
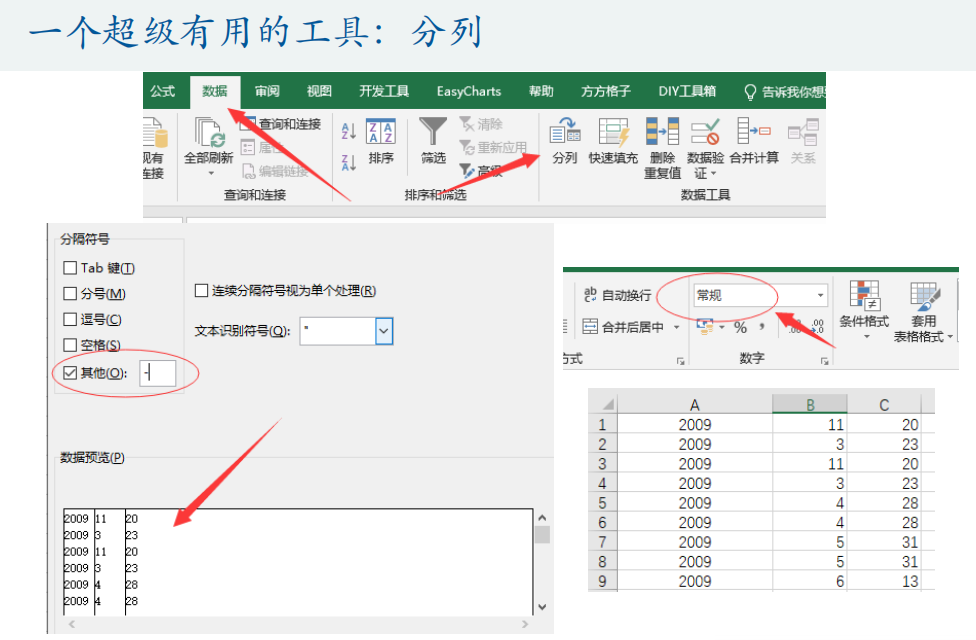
3.数值为文本型
解决方法:
- 分列功能
- 用.txt文件
强大的工具
方方格子:可以用于多文件处理
VBA
插值算法(常用于数据缺失值处理)
低阶插值方法
-
分段插值(低级但好用)
-
分段多项式插值
-
多项式插值(不好用)
中阶插值方法(龙格现象)(导数不符合)
- 拉格朗日插值
- 牛顿插值
高阶插值方法(导数保持一致)
- 埃尔米特插值(一般为三次)
- 样条插值(一般为三次)
算法代码
% 分段三次埃尔米特插值
x = -pi:pi; y = sin(x);
new_x = -pi:0.1:pi;
p = pchip(x,y,new_x);
figure(1); % 在同一个脚本文件里面,要想画多个图,需要给每个图编号,否则只会显示最后一个图哦~
plot(x, y, '-o', new_x, p, 'r-')% plot函数用法:
% plot(x1,y1,x2,y2)
% 线方式: - 实线 :点线 -. 虚点线 - - 波折线
% 点方式: . 圆点 +加号 * 星号 x x形 o 小圆
% 颜色: y黄; r红; g绿; b蓝; w白; k黑; m紫; c青% 三次样条插值和分段三次埃尔米特插值的对比
x = -pi:pi;
y = sin(x);
new_x = -pi:0.1:pi;
p1 = pchip(x,y,new_x); %分段三次埃尔米特插值
p2 = spline(x,y,new_x); %三次样条插值
figure(2);
plot(x,y,'o',new_x,p1,'r-',new_x,p2,'b-')
legend('样本点','三次埃尔米特插值','三次样条插值','Location','SouthEast') %标注显示在东南方向
% 说明:
% LEGEND(string1,string2,string3, …)
% 分别将字符串1、字符串2、字符串3……标注到图中,每个字符串对应的图标为画图时的图标。
% ‘Location’用来指定标注显示的位置% n维数据的插值
x = -pi:pi; y = sin(x);
new_x = -pi:0.1:pi;
p = interpn (x, y, new_x, 'spline');
% 等价于 p = spline(x, y, new_x);
figure(3);
plot(x, y, 'o', new_x, p, 'r-')% 人口预测(注意:一般我们很少使用插值算法来预测数据,随着课程的深入,后面的章节会有更适合预测的算法供大家选择,例如灰色预测、拟合预测等)
population=[133126,133770,134413,135069,135738,136427,137122,137866,138639, 139538];
year = 2009:2018;
p1 = pchip(year, population, 2019:2021) %分段三次埃尔米特插值预测
p2 = spline(year, population, 2019:2021) %三次样条插值预测
figure(4);
plot(year, population,'o',2019:2021,p1,'r*-',2019:2021,p2,'bx-')
legend('样本点','三次埃尔米特插值预测','三次样条插值预测','Location','SouthEast')
插值方法可以进行短期预测
数据缺失值处理
【缺失值处理】如何利用spss做均值替代、中位数替代与多重插补?
【6.缺失值与多重插补】
拟合算法
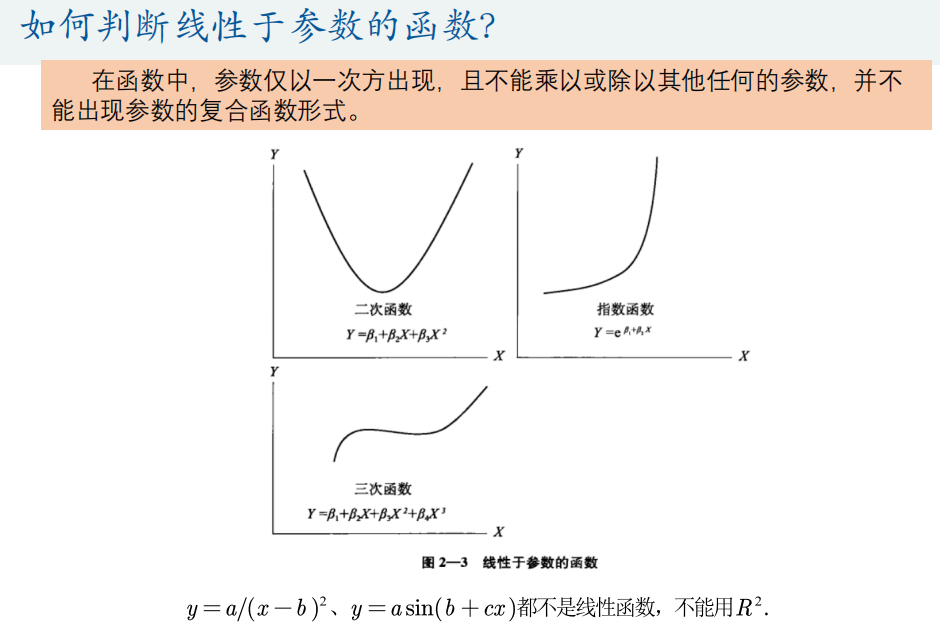
拟合优度(线性函数的评价指标)


算法代码
最小二乘法
clear;clc
load data1
plot(x,y,'o')
% 给x和y轴加上标签
xlabel('x的值')
ylabel('y的值')
n = size(x,1);
k = (n*sum(x.*y)-sum(x)*sum(y))/(n*sum(x.*x)-sum(x)*sum(x))
b = (sum(x.*x)*sum(y)-sum(x)*sum(x.*y))/(n*sum(x.*x)-sum(x)*sum(x))
hold on % 继续在之前的图形上来画图形
grid on % 显示网格线% % 画出y=kx+b的函数图像 plot(x,y)
% % 传统的画法:模拟生成x和y的序列,比如要画出[0,5]上的图形
% xx = 2.5: 0.1 :7 % 间隔设置的越小画出来的图形越准确
% yy = k * xx + b % k和b都是已知值
% plot(xx,yy,'-')% 匿名函数的基本用法。
% handle = @(arglist) anonymous_function
% 其中handle为调用匿名函数时使用的名字。
% arglist为匿名函数的输入参数,可以是一个,也可以是多个,用逗号分隔。
% anonymous_function为匿名函数的表达式。
% 举个小例子
% z=@(x,y) x^2+y^2;
% z(1,2)
% % ans = 5
% fplot函数可用于画出匿名一元函数的图形。
% fplot(f,xinterval) 将匿名函数f在指定区间xinterval绘图。xinterval = [xmin xmax] 表示定义域的范围f=@(x) k*x+b;
fplot(f,[2.5,7]);
legend('样本数据','拟合函数','location','SouthEast')y_hat = k*x+b; % y的拟合值
SSR = sum((y_hat-mean(y)).^2) % 回归平方和
SSE = sum((y_hat-y).^2) % 误差平方和
SST = sum((y-mean(y)).^2) % 总体平方和
SST-SSE-SSR % 5.6843e-14 = 5.6843*10^-14 matlab浮点数计算的一个误差
R_2 = SSR / SST
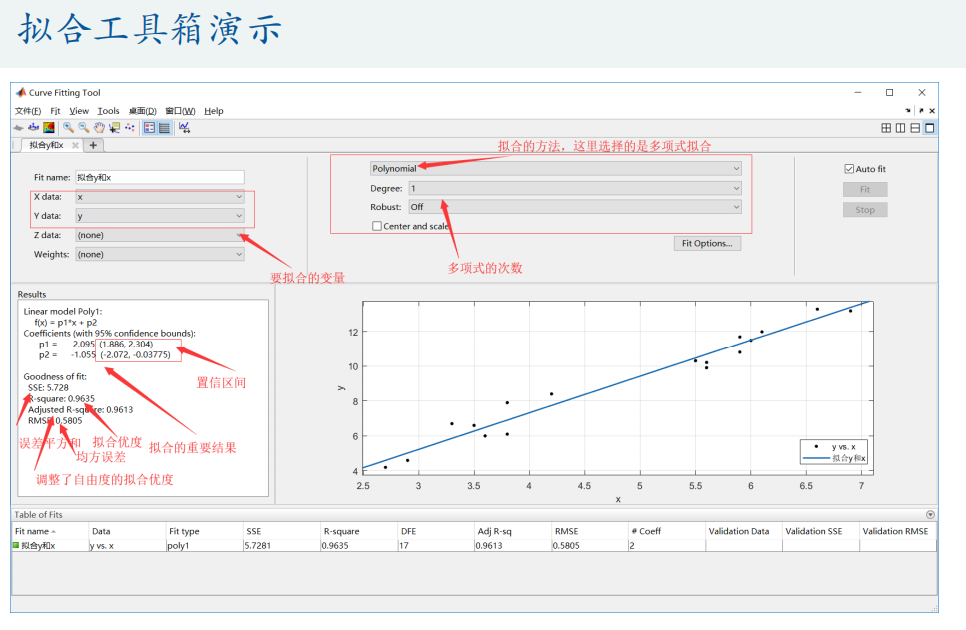
拟合工具箱使用
population = [3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4];
plot(year,population,'o')
cftool % 拟合工具箱
% (1) X data 选择 year
% (2) Y data 选择 population
% (3) 拟合方式选择:Custom Equation (自定义方程)
% (4) 修改下方的方框为:x = f(t) = xm/(1+(xm/3.9-1)*exp(-r*(t-1790)))
% (5) 左边的result一栏最上面显示:Fit computation did not converge:即没有找到收敛解,右边的拟合图形也表明拟合结果不理想
% (6) 点击Fit Options,修改非线性最小二乘估计法拟合的初始值(StartPoint), r修改为0.02,xm修改为500
% 有很多同学有疑惑,初始值为什么要这样设置?我们在未来学习微分方程模型和智能算法的课程时再来给大家介绍这里面蕴含的技巧。
% (7) 此时左边的result一览得到了拟合结果:r = 0.02735, xm = 342.4
% (8) 依次点击拟合工具箱的菜单栏最左边的文件-Point to figure(生成图像);—Generate Code(导出代码到时候可以放在你的论文附录),可以得到一个未命名的脚本文件
% (9) 在这个打开的脚本中按快捷键Ctrl+S,将这个文件保存到当前文件夹。
% (10) 在现在这个文件中调用这个函数得到参数的拟合值和预测的效果
[fitresult, gof] = createFit(year, population)
t = 2001:2030;
xm = 342.4;
r = 0.02735;
predictions = xm./(1+(xm./3.9-1).*exp(-r.*(t-1790))); % 计算预测值(注意这里要写成点乘和点除,这样可以保证按照对应元素进行计算)
figure(2)
plot(year,population,'.',t,predictions,'.') % 绘制预测结果图
相关学术名词解释 (word文件)
相关分析
Pearson相关系数


算法代码
clear;clc
load 'physical fitness test.mat' %文件名如果有空格隔开,那么需要加引号
% https://ww2.mathworks.cn/help/matlab/ref/corrcoef.html
%% 统计描述
MIN = min(Test); % 每一列的最小值
MAX = max(Test); % 每一列的最大值
MEAN = mean(Test); % 每一列的均值
MEDIAN = median(Test); %每一列的中位数
SKEWNESS = skewness(Test); %每一列的偏度
KURTOSIS = kurtosis(Test); %每一列的峰度
STD = std(Test); % 每一列的标准差
RESULT = [MIN;MAX;MEAN;MEDIAN;SKEWNESS;KURTOSIS;STD] %将这些统计量放到一个矩阵中表示%% 计算各列之间的相关系数
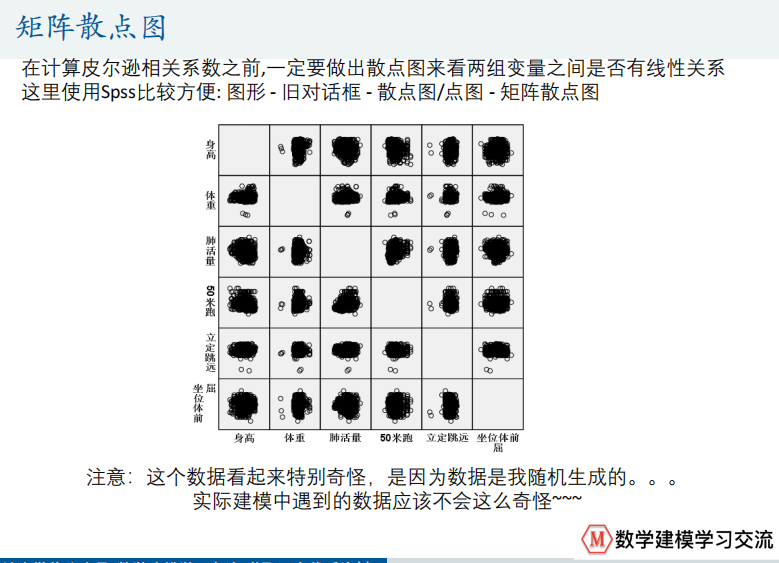
% 在计算皮尔逊相关系数之前,一定要做出散点图来看两组变量之间是否有线性关系
% 这里使用Spss比较方便: 图形 - 旧对话框 - 散点图/点图 - 矩阵散点图R = corrcoef(Test) % correlation coefficient%% 假设检验部分
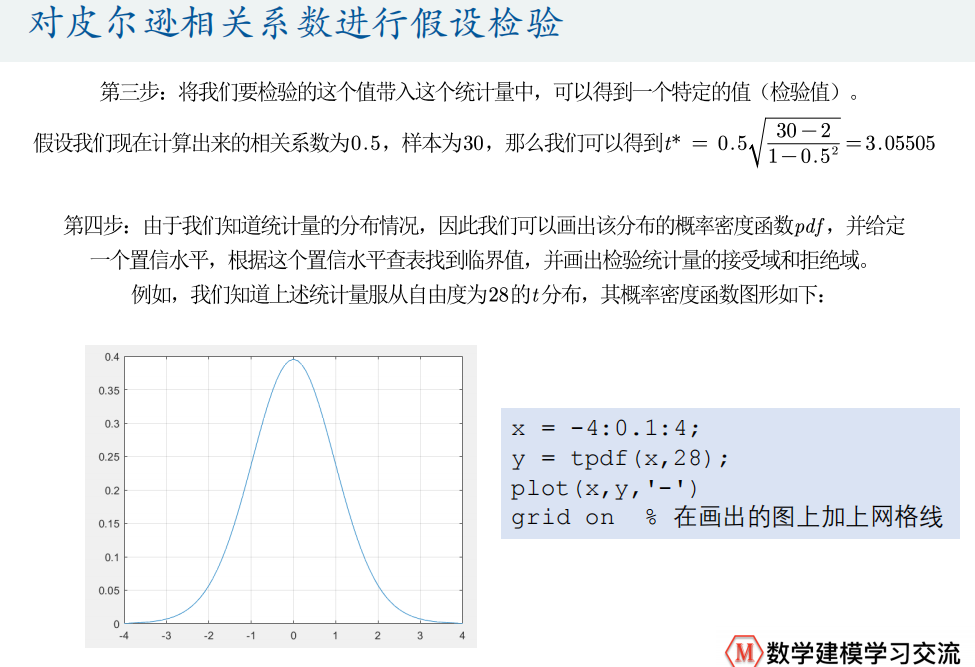
x = -4:0.1:4;
y = tpdf(x,28); %求t分布的概率密度值 28是自由度
figure(1)
plot(x,y,'-')
grid on % 在画出的图上加上网格线
hold on % 保留原来的图,以便继续在上面操作
% matlab可以求出临界值,函数如下
tinv(0.975,28) % 2.0484
% 这个函数是累积密度函数cdf的反函数
plot([-2.048,-2.048],[0,tpdf(-2.048,28)],'r-')
plot([2.048,2.048],[0,tpdf(2.048,28)],'r-')%% 计算p值
x = -4:0.1:4;
y = tpdf(x,28);
figure(2)
plot(x,y,'-')
grid on
hold on
% 画线段的方法
plot([-3.055,-3.055],[0,tpdf(-3.055,28)],'r-')
plot([3.055,3.055],[0,tpdf(3.055,28)],'r-')
disp('该检验值对应的p值为:')
disp((1-tcdf(3.055,28))*2) %双侧检验的p值要乘以2%% 计算各列之间的相关系数以及p值
[R,P] = corrcoef(Test)
% 在EXCEL表格中给数据右上角标上显著性符号吧
P < 0.01 % 标记3颗星的位置
(P < 0.05) .* (P > 0.01) % 标记2颗星的位置
(P < 0.1) .* (P > 0.05) % % 标记1颗星的位置
% 也可以使用Spss操作哦 看我演示%% 正态分布检验
% 正态分布的偏度和峰度
x = normrnd(2,3,100,1); % 生成100*1的随机向量,每个元素是均值为2,标准差为3的正态分布
skewness(x) %偏度
kurtosis(x) %峰度
qqplot(x)% 检验第一列数据是否为正态分布
[h,p] = jbtest(Test(:,1),0.05)
[h,p] = jbtest(Test(:,1),0.01)% 用循环检验所有列的数据
n_c = size(Test,2); % number of column 数据的列数
H = zeros(1,6); % 初始化节省时间和消耗
P = zeros(1,6);
for i = 1:n_c[h,p] = jbtest(Test(:,i),0.05);H(i)=h;P(i)=p;
end
disp(H)
disp(P)% Q-Q图
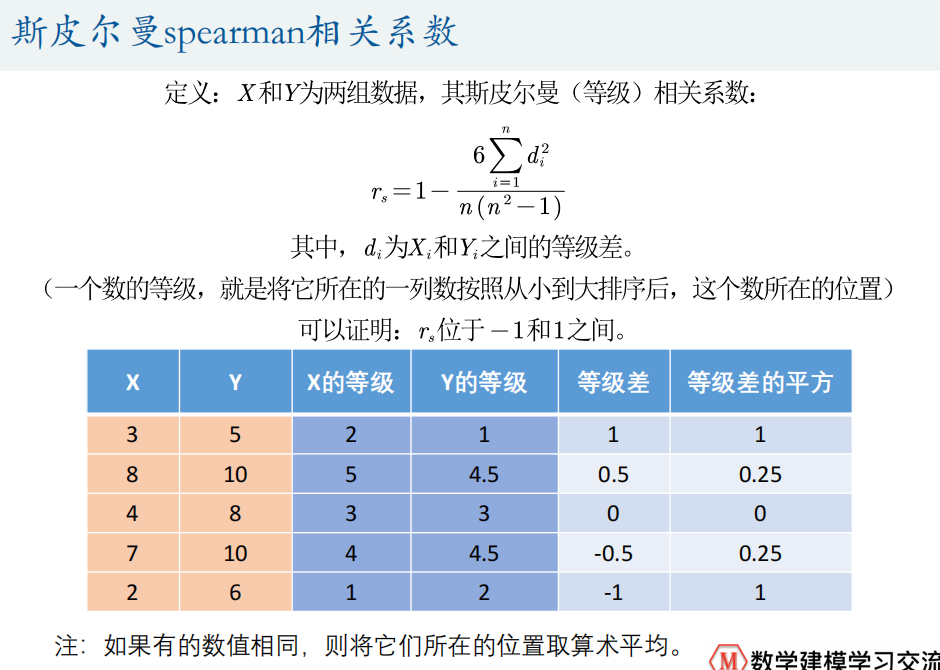
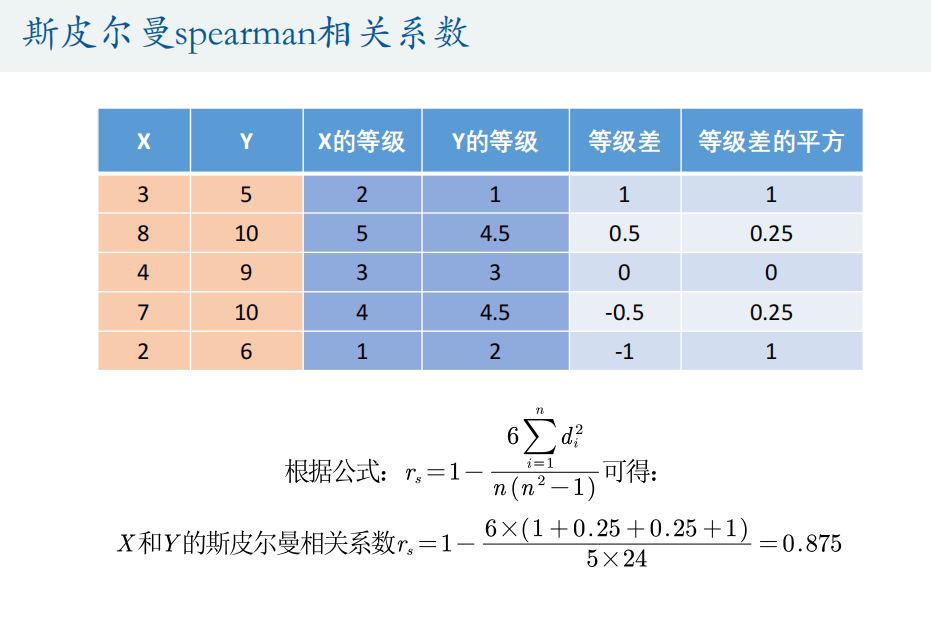
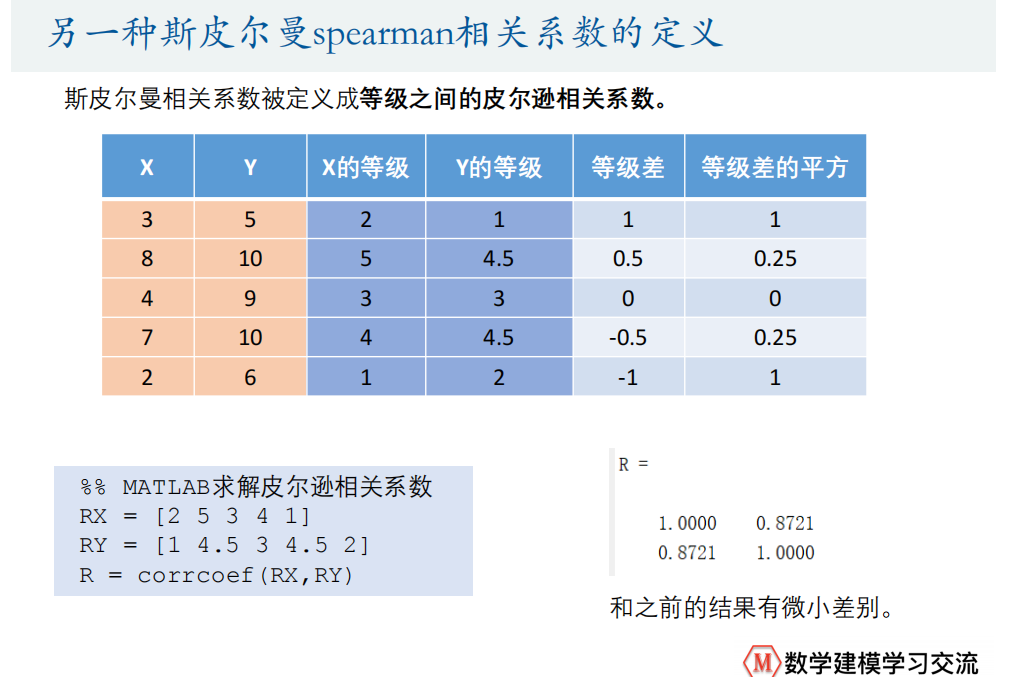
qqplot(Test(:,1))%% 斯皮尔曼相关系数
X = [3 8 4 7 2]' % 一定要是列向量哦,一撇'表示求转置
Y = [5 10 9 10 6]'
% 第一种计算方法
1-6*(1+0.25+0.25+1)/5/24% 第二种计算方法
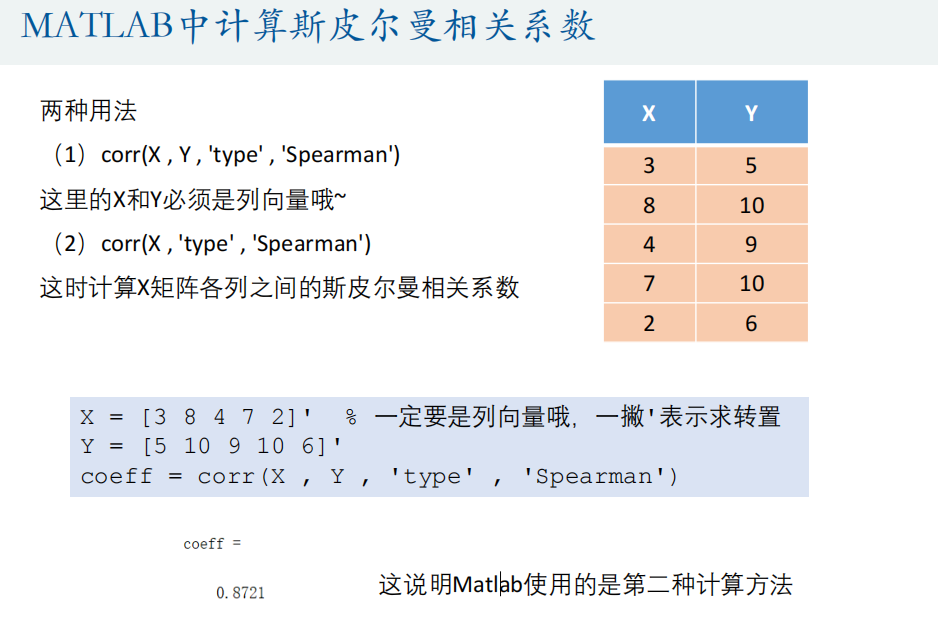
coeff = corr(X , Y , 'type' , 'Spearman')
% 等价于:
RX = [2 5 3 4 1]
RY = [1 4.5 3 4.5 2]
R = corrcoef(RX,RY)% 计算矩阵各列的斯皮尔曼相关系数
R = corr(Test, 'type' , 'Spearman')% 大样本下的假设检验
% 计算检验值
disp(sqrt(590)*0.0301)
% 计算p值
disp((1-normcdf(0.7311))*2) % normcdf用来计算标准正态分布的累积概率密度函数% 直接给出相关系数和p值
[R,P]=corr(Test, 'type' , 'Spearman')
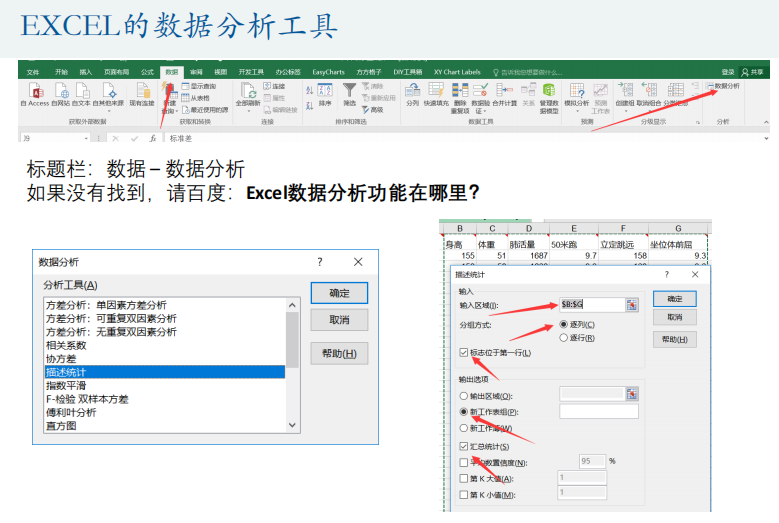
SPSS
数据可视化
分析统计
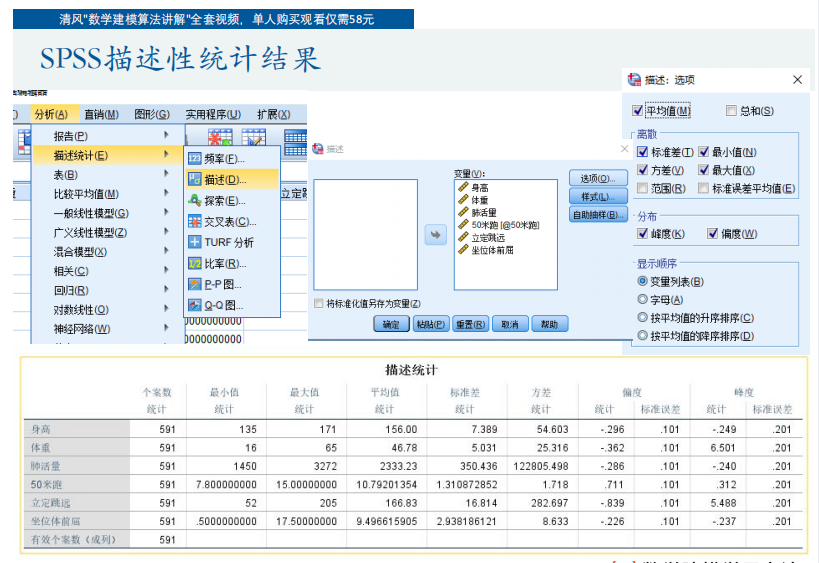
矩阵散点图
假设检验
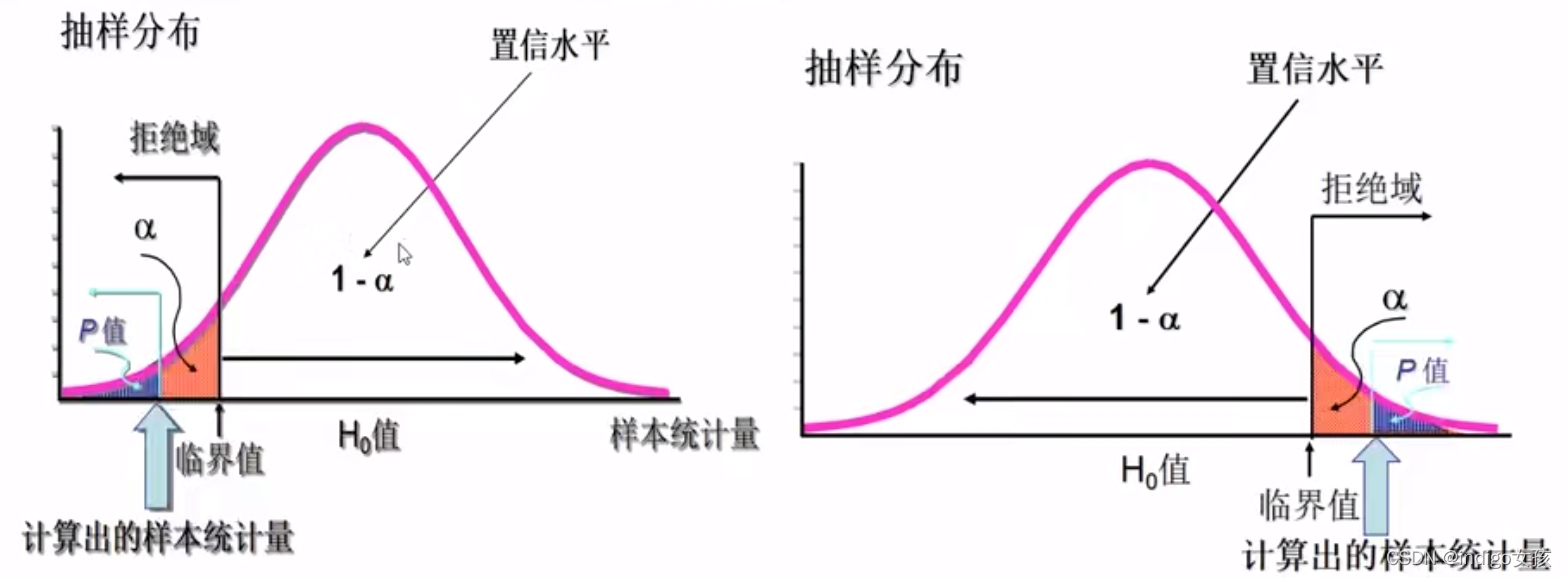
基本概念
- 原假设H0
- 备择假设H1
- 置信水平β
- 显著性水平α
- P值
等式:α+β=1
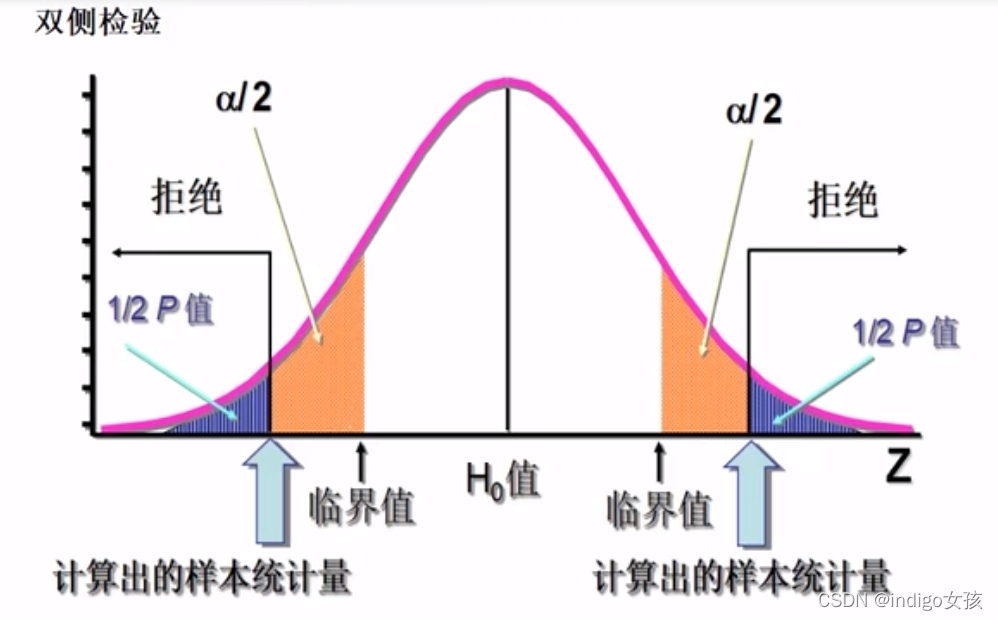
双侧检验的P值是单侧检验P值的两倍
当计算出的P值小于对应的显著性水平的时候,拒绝原假设,选择备择假设
置信水平一般取95%,显著性水平一般为5%
Pearson相关系数假设检验

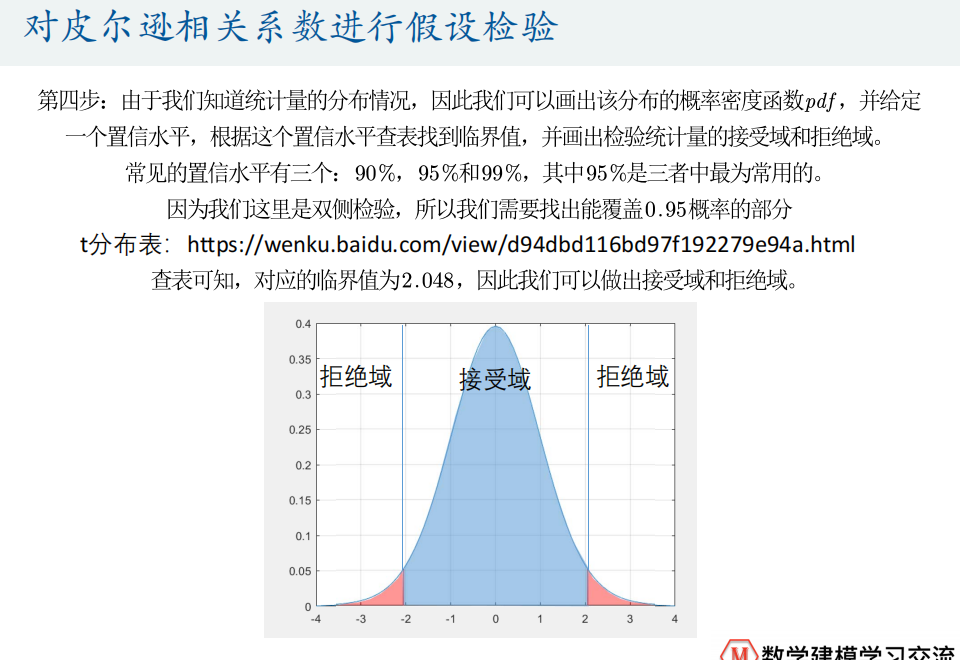
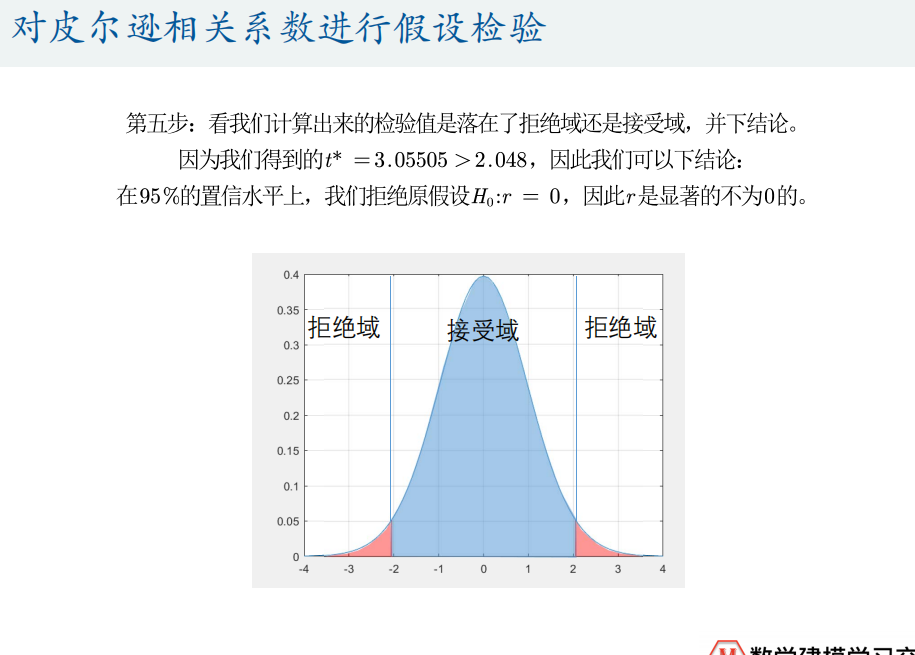
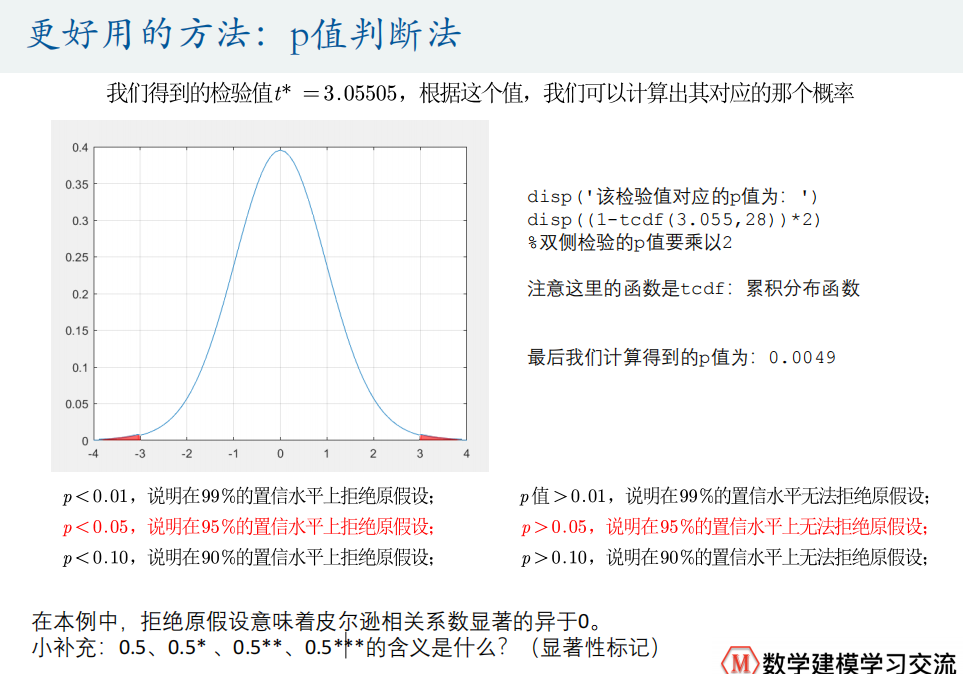
Pearson假设检验条件
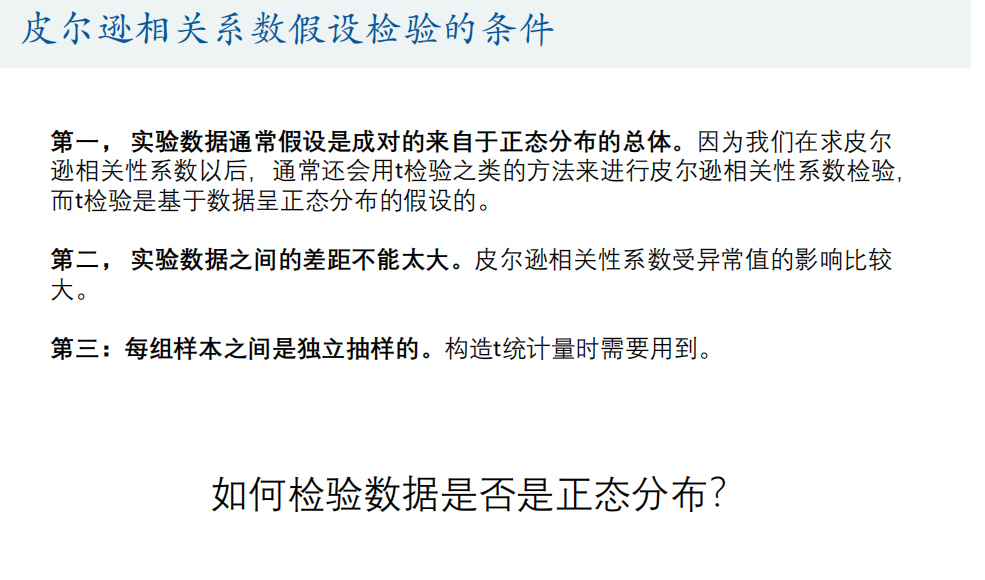
正态分布检验
【SPSS教程】检验正态分布的几种方法及释义】
JB检验


夏皮洛—威尔克检验
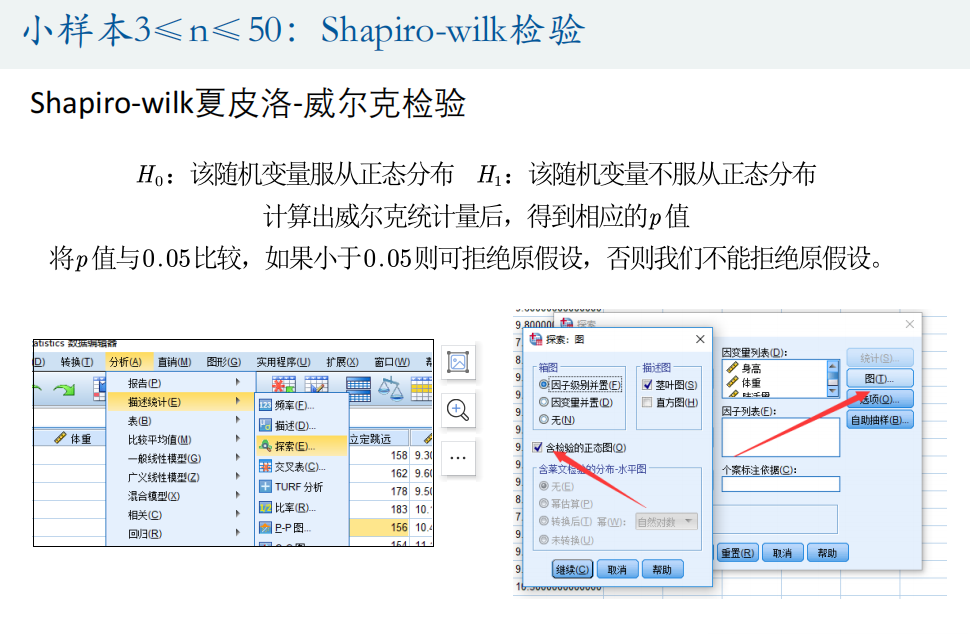
Q—Q图检验

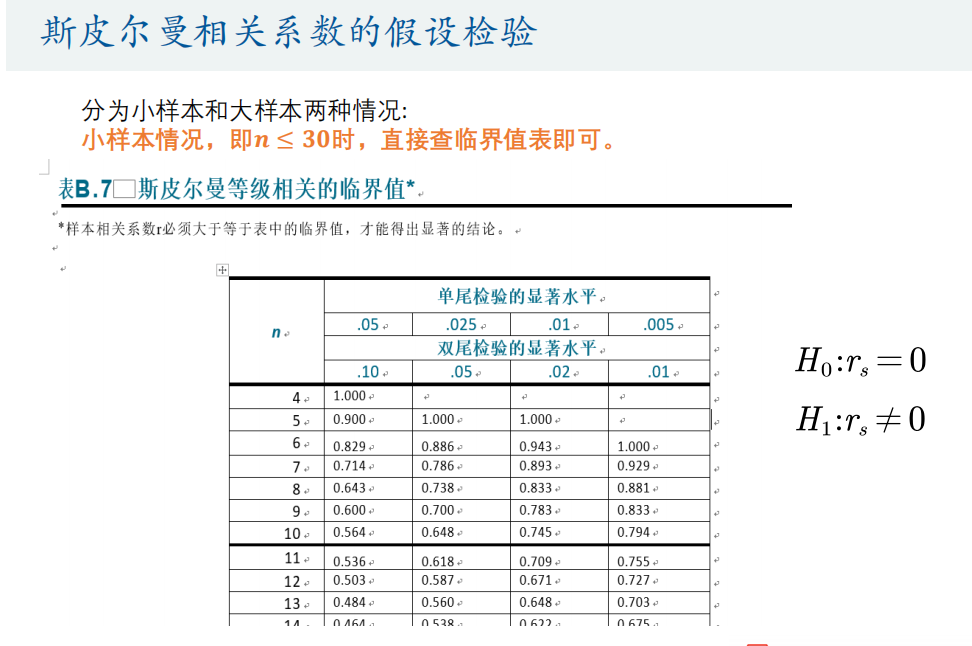
Spearman相关系数
假设检验

两种相关系数的比较

图论
在线作图

%% Matlab作无向图
% (1)无权重(每条边的权重默认为1)
% 函数graph(s,t):可在 s 和 t 中的对应节点之间创建边,并生成一个图
% s 和 t 都必须具有相同的元素数;这些节点必须都是从1开始的正整数,或都是字符串元胞数组。
s1 = [1,2,3,4];
t1 = [2,3,1,1];
G1 = graph(s1, t1);
plot(G1)
% 注意哦,编号最好是从1开始连续编号,不要自己随便定义编号
s1 = [1,2,3,4];
t1 = [2,3,1,1];
G1 = graph(s1, t1);
plot(G1)% 注意字符串元胞数组是用大括号包起来的哦
s2 = {'学校','电影院','网吧','酒店'};
t2 = {'电影院','酒店','酒店','KTV'};
G2 = graph(s2, t2);
plot(G2, 'linewidth', 2) % 设置线的宽度
% 下面的命令是在画图后不显示坐标
set( gca, 'XTick', [], 'YTick', [] ); % (2)有权重
% 函数graph(s,t,w):可在 s 和 t 中的对应节点之间以w的权重创建边,并生成一个图
s = [1,2,3,4];
t = [2,3,1,1];
w = [3,8,9,2];
G = graph(s, t, w);
plot(G, 'EdgeLabel', G.Edges.Weight, 'linewidth', 2)
set( gca, 'XTick', [], 'YTick', [] ); %% Matlab作有向图
% 无权图 digraph(s,t)
s = [1,2,3,4,1];
t = [2,3,1,1,4];
G = digraph(s, t);
plot(G)
set( gca, 'XTick', [], 'YTick', [] ); % 有权图 digraph(s,t,w)
s = [1,2,3,4];
t = [2,3,1,1];
w = [3,8,9,2];
G = digraph(s, t, w);
plot(G, 'EdgeLabel', G.Edges.Weight, 'linewidth', 3)
set( gca, 'XTick', [], 'YTick', [] );
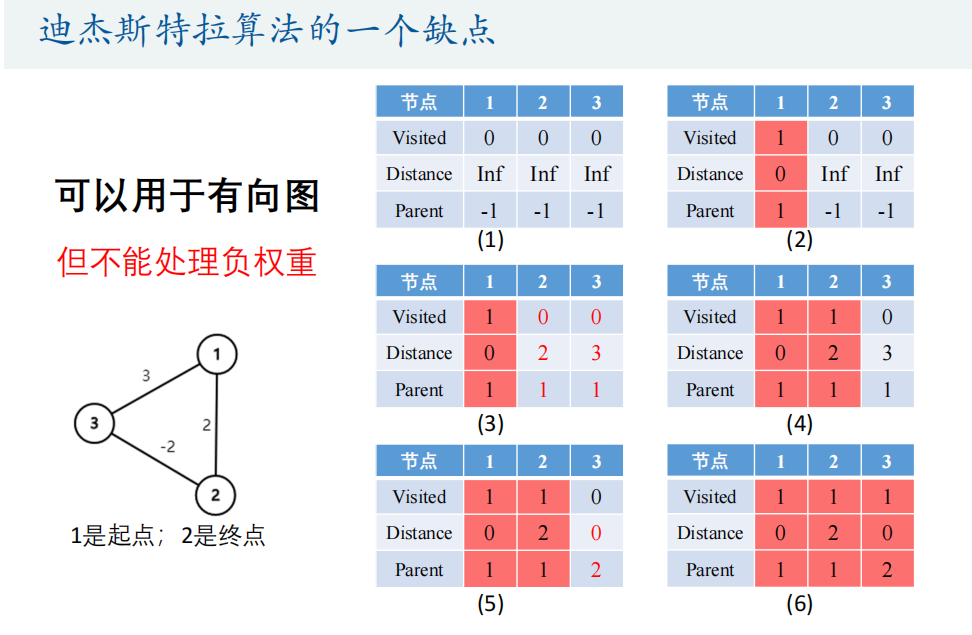
迪杰斯特拉算法(广度优先算法)
算法理论视频
贝尔曼福特算法


算法代码
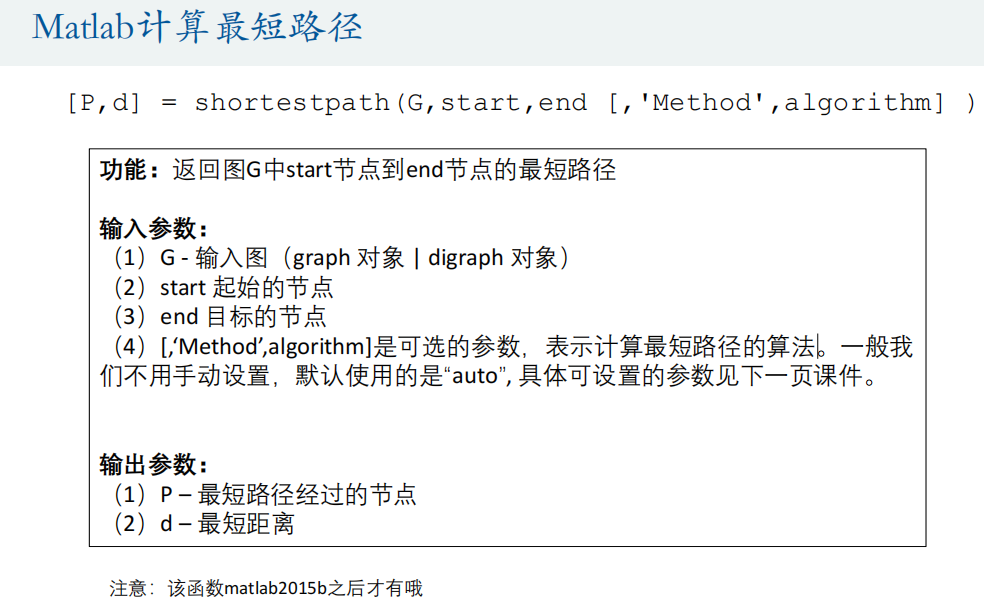

% 注意哦,Matlab中的图节点要从1开始编号,所以这里把0全部改为了9
% 编号最好是从1开始连续编号,不要自己随便定义编号
s = [9 9 1 1 2 2 2 7 7 6 6 5 5 4];
t = [1 7 7 2 8 3 5 8 6 8 5 3 4 3];
w = [4 8 3 8 2 7 4 1 6 6 2 14 10 9];
G = graph(s,t,w);
plot(G, 'EdgeLabel', G.Edges.Weight, 'linewidth', 2)
set( gca, 'XTick', [], 'YTick', [] );
[P,d] = shortestpath(G, 9, 4) %注意:该函数matlab2015b之后才有哦% 在图中高亮我们的最短路径
myplot = plot(G, 'EdgeLabel', G.Edges.Weight, 'linewidth', 2); %首先将图赋给一个变量
highlight(myplot, P, 'EdgeColor', 'r') %对这个变量即我们刚刚绘制的图形进行高亮处理(给边加上r红色)% 求出任意两点的最短路径矩阵
D = distances(G) %注意:该函数matlab2015b之后才有哦
D(1,2) % 1 -> 2的最短路径
D(9,4) % 9 -> 4的最短路径% 找出给定范围内的所有点 nearest(G,s,d)
% 返回图形 G 中与节点 s 的距离在 d 之内的所有节点
[nodeIDs,dist] = nearest(G, 2, 10) %注意:该函数matlab2016a之后才有哦
弗洛伊德算法
算法理论视频



算法代码
function [dist,path] = Floyd_algorithm(D)
%% 该函数用于求解一个权重邻接矩阵任意两个节点之间的最短路径
% 输入:
% D是权重邻接矩阵
% 输出:
% dist是最短距离矩阵,其元素dist_ij表示表示i,j两个节点的最短距离
% path是路径矩阵,其元素path_ij表示起点为i,终点为j的两个节点之间的最短路径要经过的节点n = size(D,1); % 计算节点的个数% 初始化dist矩阵
dist = D;% 下面我们来初始化path矩阵
path = zeros(n);
for j = 1:npath(:,j) = j; % 将第j列的元素变为j
end
for i = 1:npath(i,i) = -1; % 将主对角线元素变为-1
end% 下面开始三个循环
for k=1:n % 中间节点k从1- n 循环for i=1:n % 起始节点i从1- n 循环for j=1:n % 终点节点j从1-n 循环if dist(i,j)>dist(i,k)+dist(k,j) % 如果i,j两个节点间的最短距离大于i和k的最短距离+k和j的最短距离dist(i,j)=dist(i,k)+dist(k,j); % 那么我们就令这两个较短的距离之和取代i,j两点之间的最短距离path(i,j)=path(i,k); % 起点为i,终点为j的两个节点之间的最短路径要经过的节点更新为path(i,k)% 注意,上面一行语句不能写成path(i,j) = k; 这是网上很多地方都容易犯的错误,在PPT11页中会告诉大家为什么不能这么写endendend
endend
function [] = print_path(path,dist,i,j)
%% 该函数的作用是打印从i到j经过的最短路径
% 输入:
% path是使用floyd算法求出来的路径矩阵
% dist是使用floyd算法求出来的最短距离矩阵
% i是起始节点的编号
% j是终点节点的编号
% 输出:无if i == jwarning('起点和终点相同,请检查后重新输入') % 在屏幕中提示警告信息return; % 不运行下面的语句,直接退出函数
end
if path(i,j) == j % 如果path(i,j) = j,则有两种可能:
% (1)如果dist(i,j) 为 Inf , 则说明从i到j没有路径可以到达if dist(i,j) == Infdisp(['从',num2str(i),'到',num2str(j),'没有路径可以到达'])
% (2)如果dist(i,j) 不为 Inf , 则说明从i到j可直接到达,且为最短路径elsedisp(['从',num2str(i),'到',num2str(j),'的最短路径为'])disp([num2str(i),' ---> ',num2str(j)])disp(['最短距离为',num2str(dist(i,j))])end
else % 如果path(i,j) ~= j,则说明中间经过了其他节点:k = path(i,j);result = [num2str(i),' ---> ']; % 初始化要打印的这个字符串while k ~= j % 只要k不等于j, 就一直循环下去result = [result , num2str(k) , ' ---> ' ]; % i先走到k这个节点处k = path(k,j);endresult = [result , num2str(k)];disp(['从',num2str(i),'到',num2str(j),'的最短路径为'])disp(result)disp(['最短距离为',num2str(dist(i,j))])
endend
function [] = print_all_path(D)
%% 该函数的作用是求解一个权重邻接矩阵任意两个节点之间的最短路径,并打印所有的结果出来
% 输入:
% D是权重邻接矩阵
% 输出:无[dist,path] = Floyd_algorithm(D); % 调用之前的Floyd_algorithm函数
n = size(D,1);
if n == 1warning('请输入至少两阶以上的权重邻接矩阵') % 在屏幕中提示警告信息return; % 不运行下面的语句,直接退出函数
endfor i = 1:nfor j = 1:nif i ~= j % 不等号用~=表示print_path(path,dist,i,j); % 调用之前的print_path函数disp('-------------------------------------------')disp(' ')endend
endend
主函数
% PPT第七页的例子
%% 首先将图转换为权重邻接矩阵D
n = 5; %一共五个节点
D = ones(n) ./ zeros(n); % 全部元素初始化为Inf
for i = 1:nD(i,i) = 0; % 主对角线元素为0
end
D(1,2) = 3;
D(1,3) = 8;
D(1,5) = -4;
D(2,5) = 7;
D(2,4) = 1;
D(3,2) = 4;
D(4,3) = -5;
D(5,4) = 6;
D(4,1) = 2;%% 调用Floyd_algorithm函数求解
[dist,path] = Floyd_algorithm(D)print_path(path,dist,1,5)
print_path(path,dist,1,4)
print_path(path,dist,3,1)clc
disp('下面我们打印任意两点之间的最短距离:')
print_all_path(D)% 思考题的参考答案
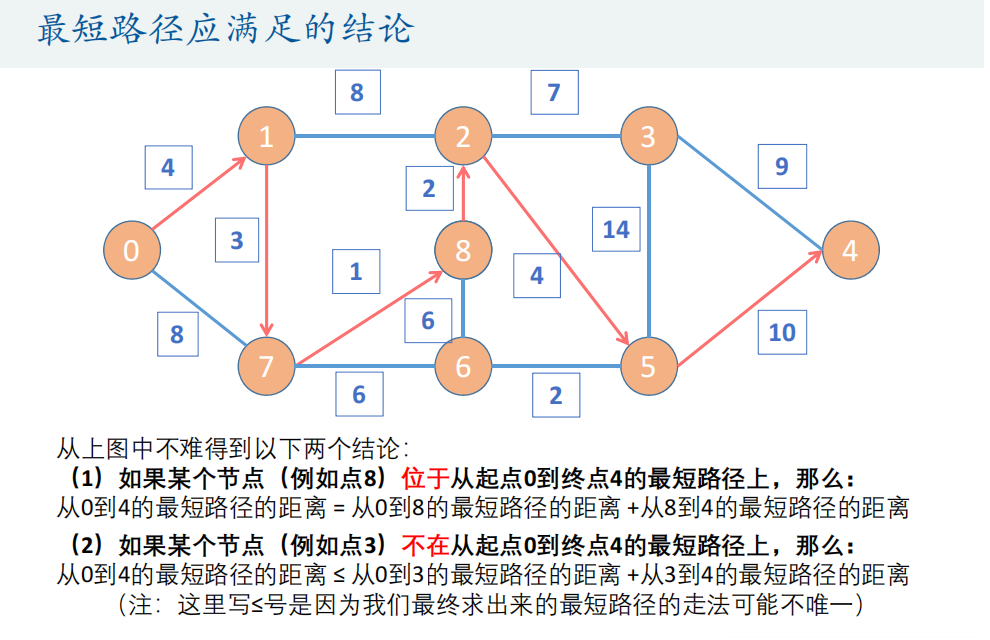
%% 首先将图转换为权重邻接矩阵D
n = 9; %一共九个节点
D = zeros(n); % 全部元素初始化为0, 等会你们就知道为什么这样设置啦
% 因为是无向图,所以权重邻接矩阵是一个对称矩阵
D(1,2) = 4; D(1,8) = 8;
D(2,8) = 3; D(2,3) = 8;
D(8,9) = 1; D(8,7) = 6;
D(9,7) = 6; D(9,3) = 2;
D(7,6) = 2; D(3,4) = 7;
D(3,6) = 4; D(6,4) = 14;
D(4,5) = 9; D(6,5) = 10;
D = D+D'; % 这个操作可以得到对称矩阵的另一半
for i = 1:nfor j = 1:nif (i ~= j) && (D(i,j) == 0) D(i,j) = Inf; % 将非主对角线上的0元素全部变为Infendend
end%% 调用Floyd_algorithm函数求解
[dist,path] = Floyd_algorithm(D)
print_all_path(D)
多元回归分析




回归分析的分类
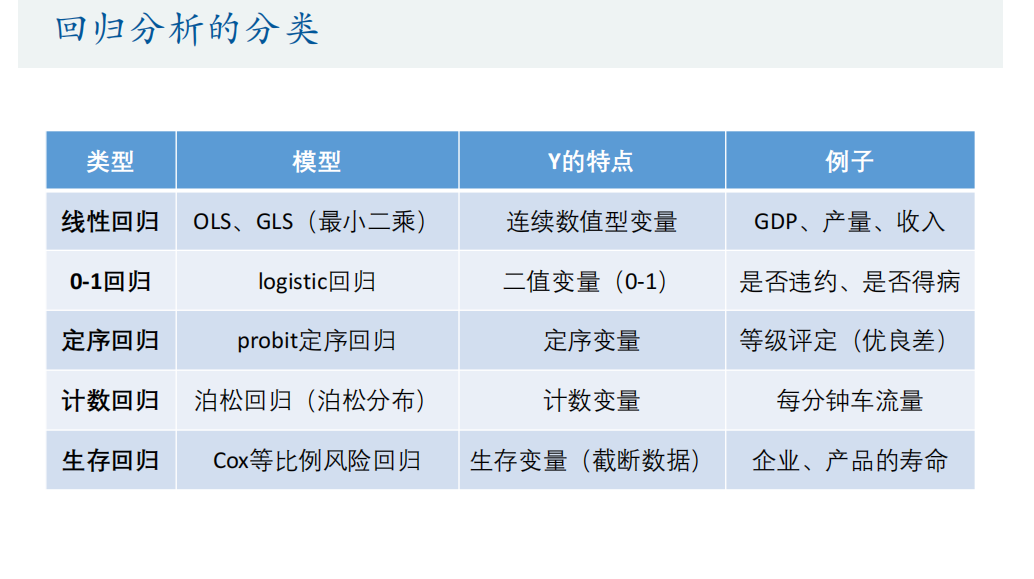
数据类型



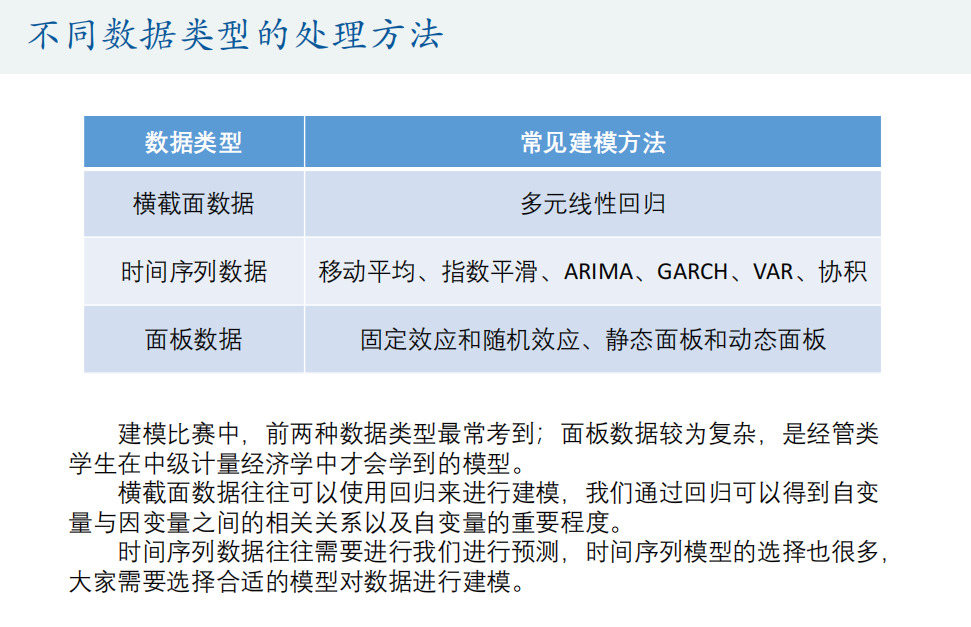
数据收集
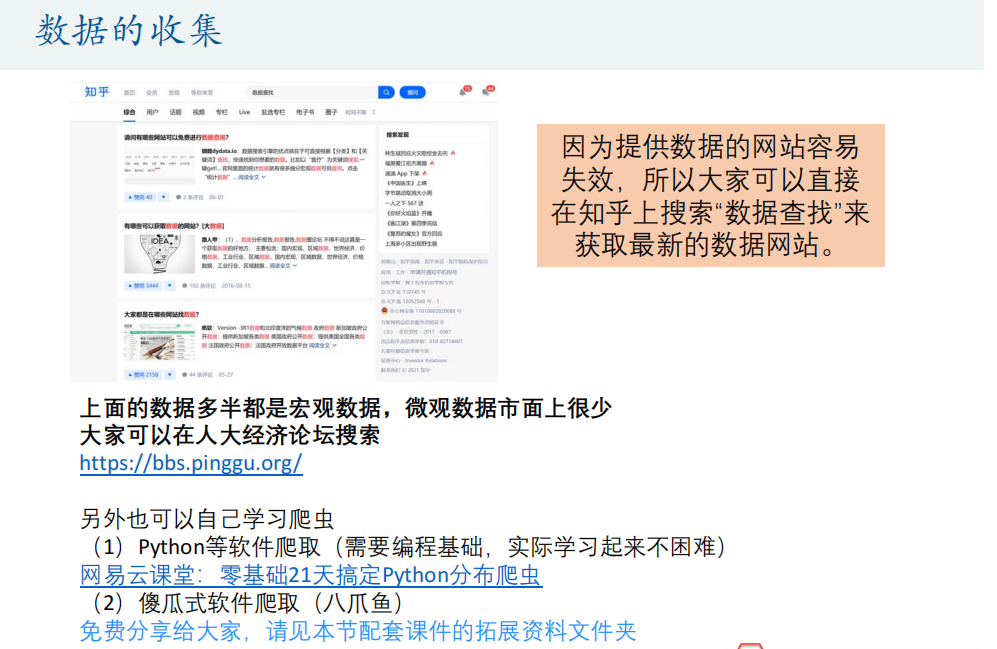
一元线性回归
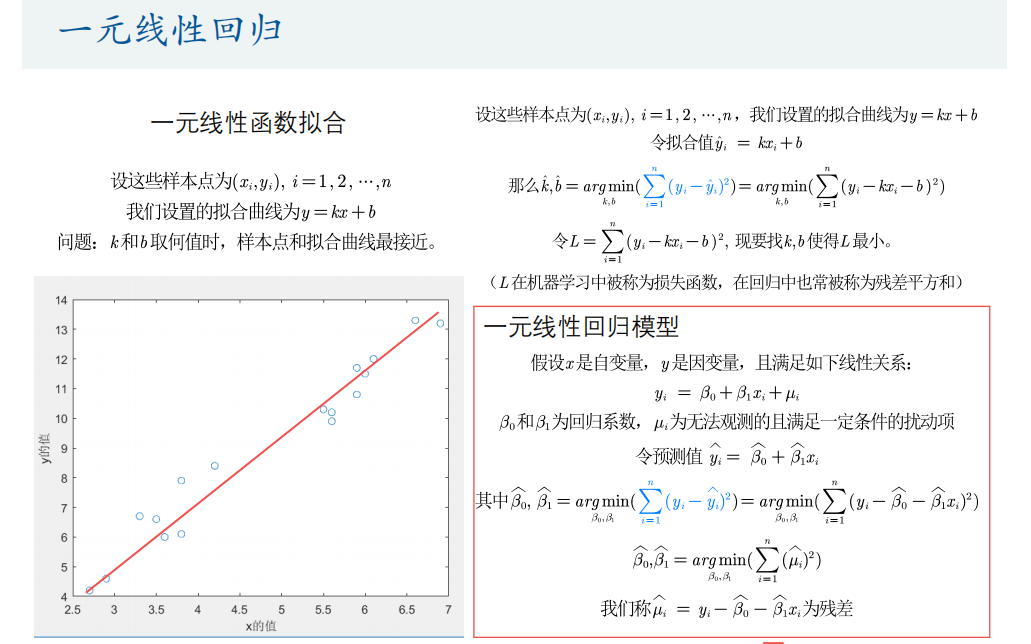

解释变量模型



多元线性回归

自变量不充分产生内生性
内生性:因为自变量个数不充分引起的
外生性:自变量个数恰好可以完全解释因变量
多重共线性:自变量过多,引起自变量之间存在相关性
核心解释变量和控制变量解救内生性

回归模型解释

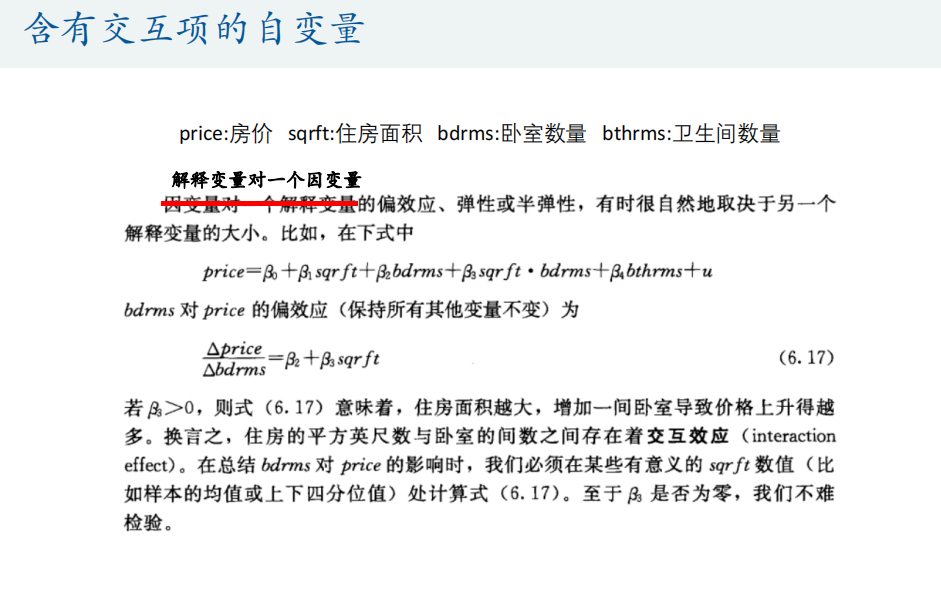
交互项
回归方法
软件

处理语法
数据描述
- summarize 定量数据
- tabulate 定性数据
- regress y x1 x2 ... xk
原假设:回归系数不显著异于0
当P<0.05时拒绝原假设,认为回归系数显著异于0,回归系数有效
联合显著性检验:验证回归模型的正确性
原假设同上
代码
// 按键盘上的PageUp可以使用上一次输入的代码(Matleb中是上箭头)
// 清除所有变量
clear
// 清屏 和 matlab的clc类似
cls
// 导入数据(其实是我们直接在界面上粘贴过来的,我们用鼠标点界面导入更方便 本条请删除后再复制到论文中,如果评委老师看到了就知道这不是你写的了)
// import excel "C:\Users\hc_lzp\Desktop\数学建模视频录制\第7讲.多元回归分析\代码和例题数据\课堂中讲解的奶粉数据.xlsx", sheet("Sheet1") firstrow
import excel "课堂中讲解的奶粉数据.xlsx", sheet("Sheet1") firstrow
// 定量变量的描述性统计
summarize 团购价元 评价量 商品毛重kg // 对定量数据进行描述性统计
// 定性变量的频数分布,并得到相应字母开头的虚拟变量
tabulate 配方,gen(A) // 对定性数据进行描述性统计
tabulate 奶源产地 ,gen(B)
tabulate 国产或进口 ,gen(C)
tabulate 适用年龄岁 ,gen(D)
tabulate 包装单位 ,gen(E)
tabulate 分类 ,gen(F)
tabulate 段位 ,gen(G)
// 下面进行回归
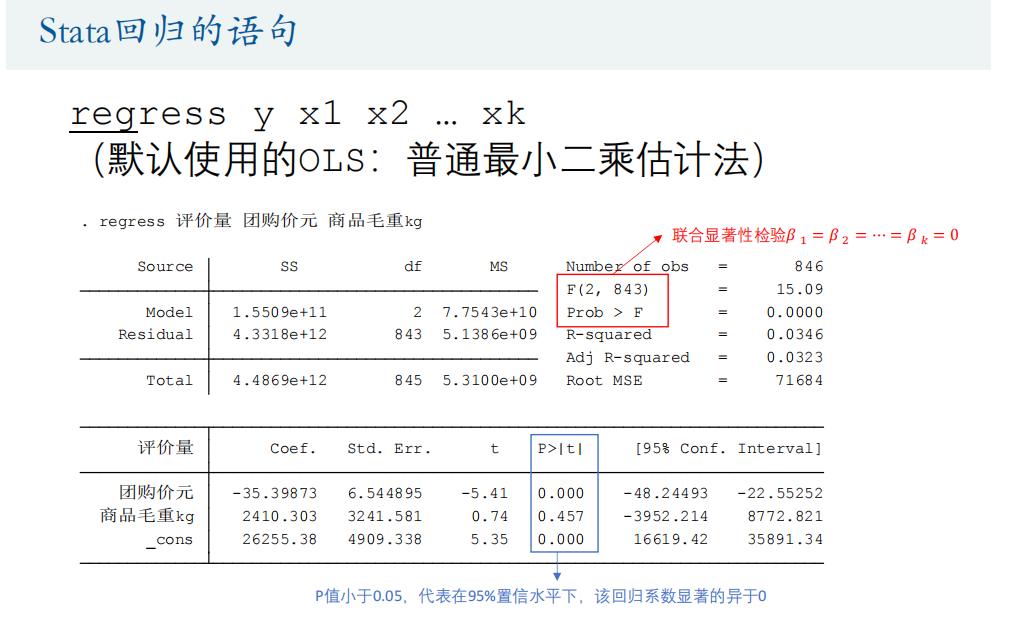
regress 评价量 团购价元 商品毛重kg // 默认OLS:最小二乘法
// 下面的语句可帮助我们把回归结果保存在Word文档中
// 在使用之前需要运行下面这个代码来安装下这个功能包(运行一次之后就可以注释掉了)
// ssc install reg2docx, all replace
// 如果安装出现connection timed out的错误,可以尝试换成手机热点联网,如果手机热点也不能下载,就不用这个命令吧,可以自己做一个回归结果表,如果觉得麻烦就直接把回归结果截图。
est store m1
reg2docx m1 using m1.docx, replace
// *** p<0.01 ** p<0.05 * p<0.1// Stata会自动剔除多重共线性的变量
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4
est store m2
reg2docx m2 using m2.docx, replace// 得到标准化回归系数
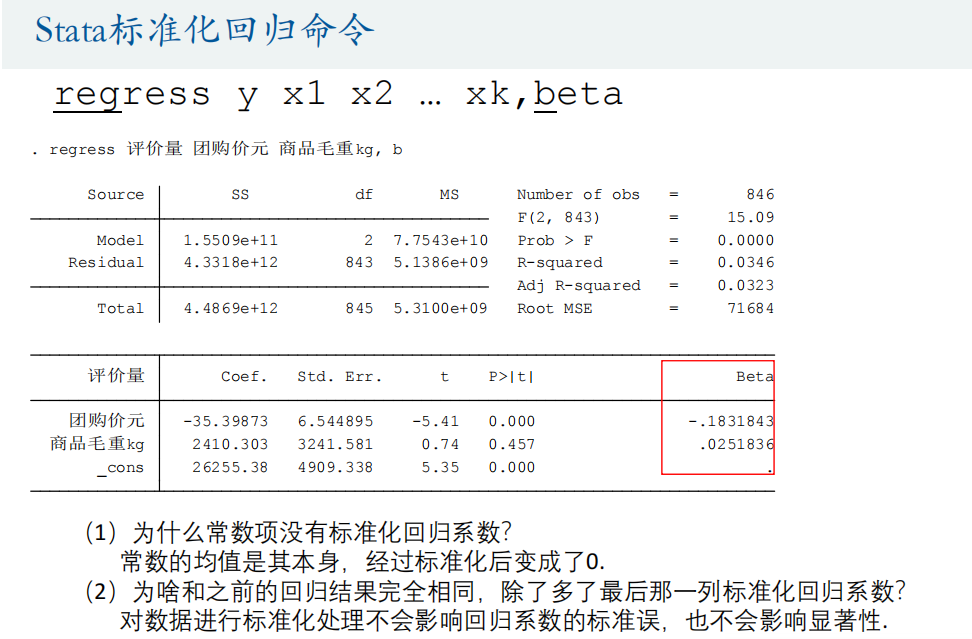
regress 评价量 团购价元 商品毛重kg, b // 画出残差图
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4
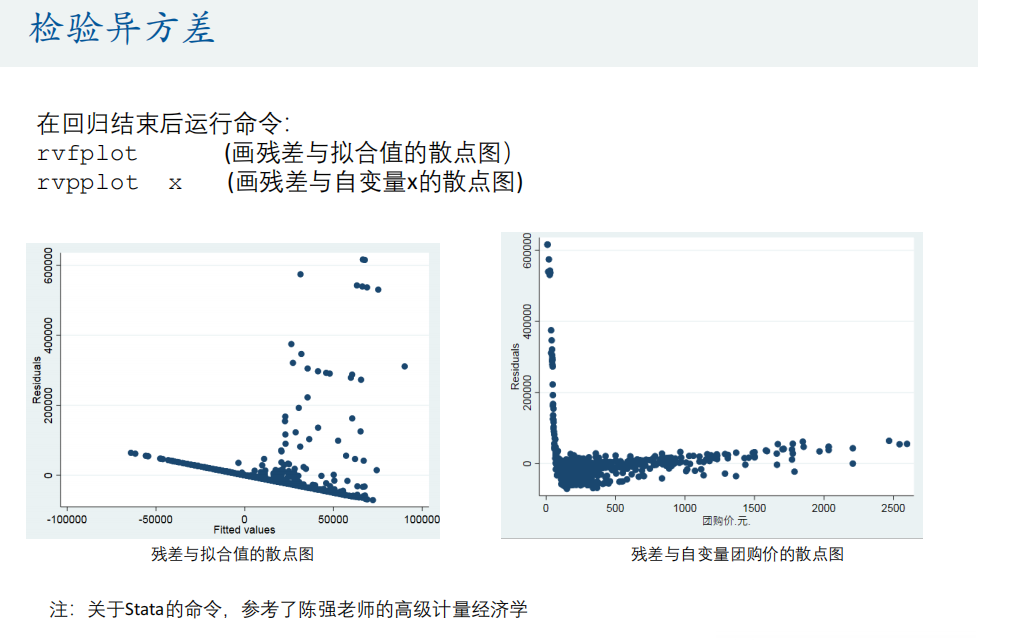
rvfplot
// 残差与拟合值的散点图
graph export a1.png ,replace
// 残差与自变量团购价的散点图
rvpplot 团购价元
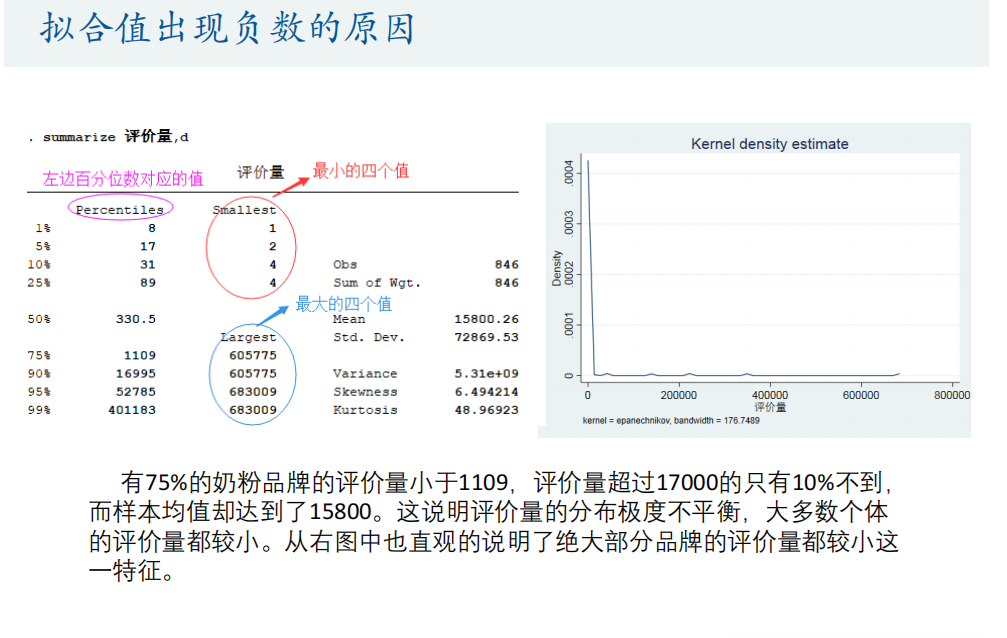
graph export a2.png ,replace// 为什么评价量的拟合值会出现负数?
// 描述性统计并给出分位数对应的数值
summarize 评价量,d// 作评价量的概率密度估计图
kdensity 评价量
graph export a3.png ,replace// 异方差BP检验
estat hettest ,rhs iid// 异方差怀特检验
estat imtest,white// 使用OLS + 稳健的标准误
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4, r
est store m3
reg2docx m3 using m3.docx, replace// 计算VIF
estat vif// 逐步回归(一定要注意完全多重共线性的影响)
// 向前逐步回归(后面的r表示稳健的标准误)
stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r pe(0.05)
// 向后逐步回归(后面的r表示稳健的标准误)
stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r pr(0.05)
// 向后逐步回归的同时使用标准化回归系数(在r后面跟上一个b即可)
stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r b pr(0.05)// 补充语法 (大家不需要具体的去学Stata软件,掌握我课堂上教给大家的一些命令应对数学建模比赛就可以啦)
// 事实上大家学好Excel,学好后应对90%的数据预处理问题都能解决
// (1) 用已知变量生成新的变量
generate lny = log(评价量)
generate price_square = 团购价元 ^2
generate interaction_term = 团购价元*商品毛重kg// (2) 修改变量名称,因为用中文命名变量名称有时候可能容易出现未知Bug
rename 团购价元 price
虚变量

R2较低处理方法
- 预测性回归看重R2、解释性回归不看重R2
- 调整模型,将自变量或者因变量取对数,或者交互项(解释不清楚)
- 数据存在异常值,或者数据分布不均匀。调整数据

标准化回归消除量纲(度量影响力)
异方差
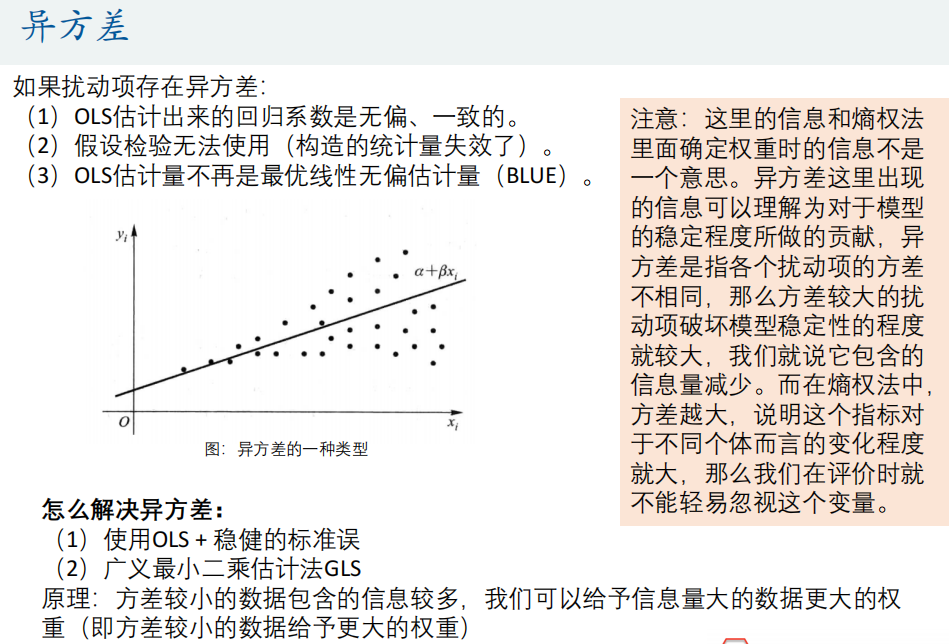
异方差:扰动项方差不一致
截面数据容易出现异方差
定义

异方差的影响和解决
影响
- 导致回归系数失效
- 假设检验无法使用
- OLS估计量不是最优线性无偏估计量
解决方法
- 使用OLS+稳健标准误(推荐)
- 广义最小二乘法GLS
检验异方差存在
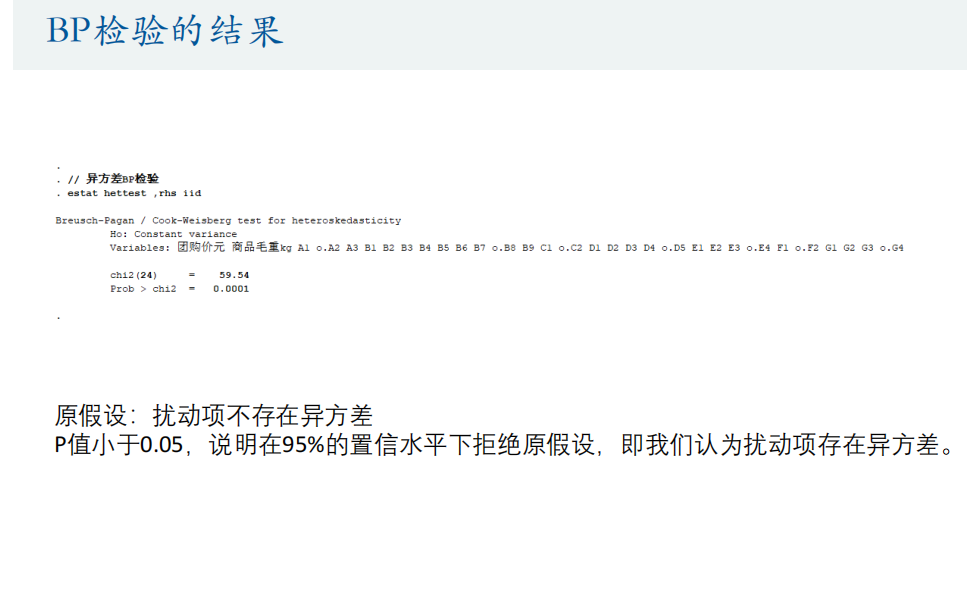
BP检验
原假设:不存在异方差
P>0.05时说明在95%的置信水平下扰动项不存在异方差
即不拒绝原假设

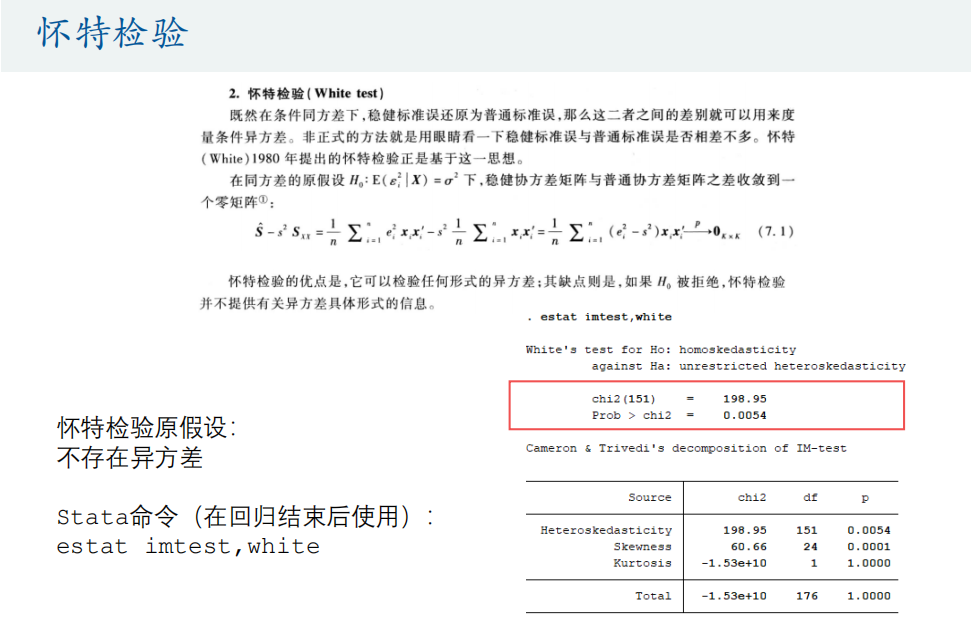
怀特检验
原假设同上
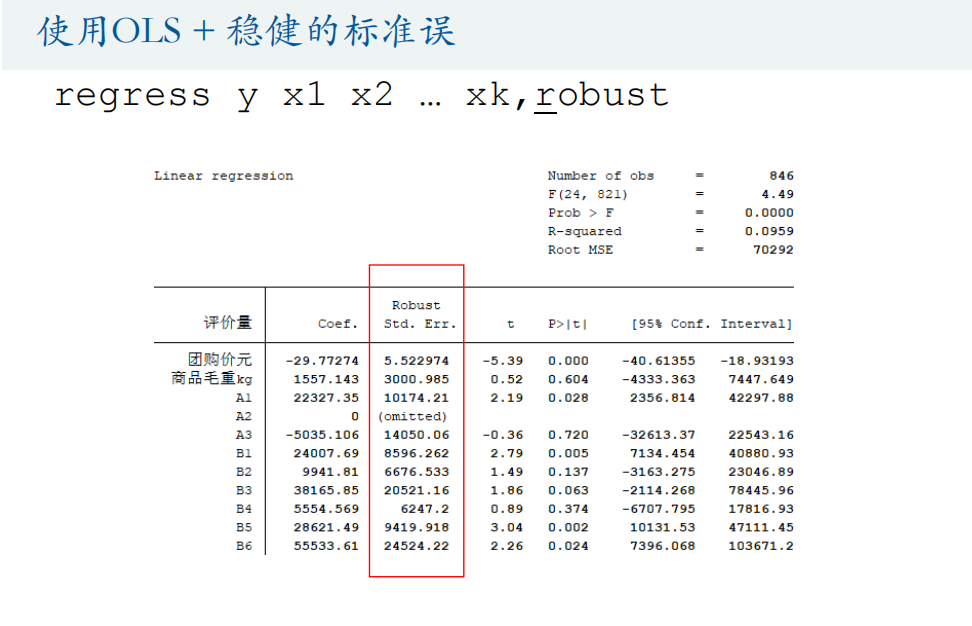
异方差的解决

稳健标准误(推荐)
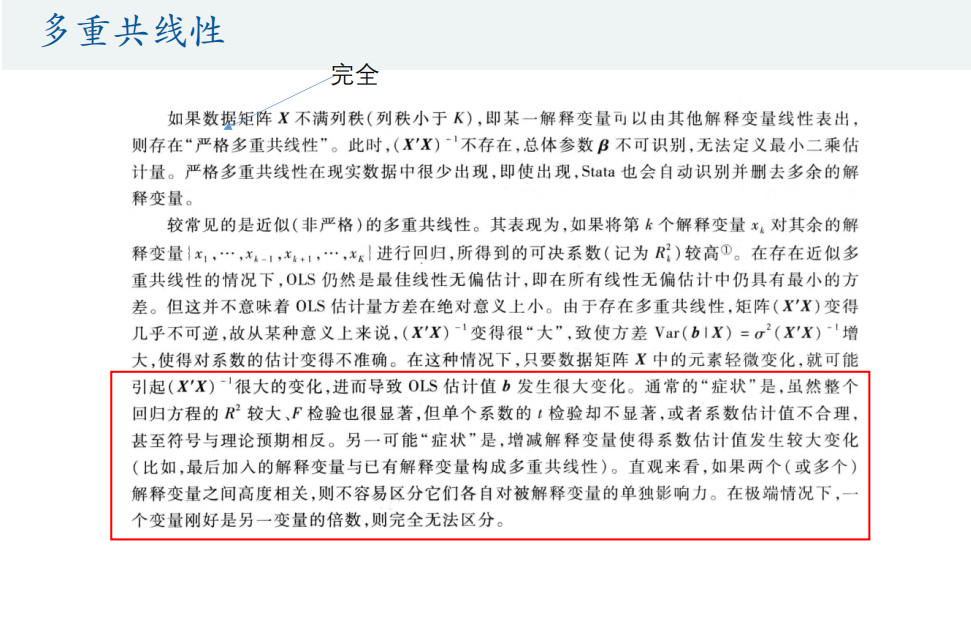
多重共线性
自变量之间存在相关性引起
影响:
- 多重共线性会使得回归系数估计不准确
- 总体F检验显著,但单个系数t检验不显著
多重共线性检验
VIF>10认为存在严重的多重共线性
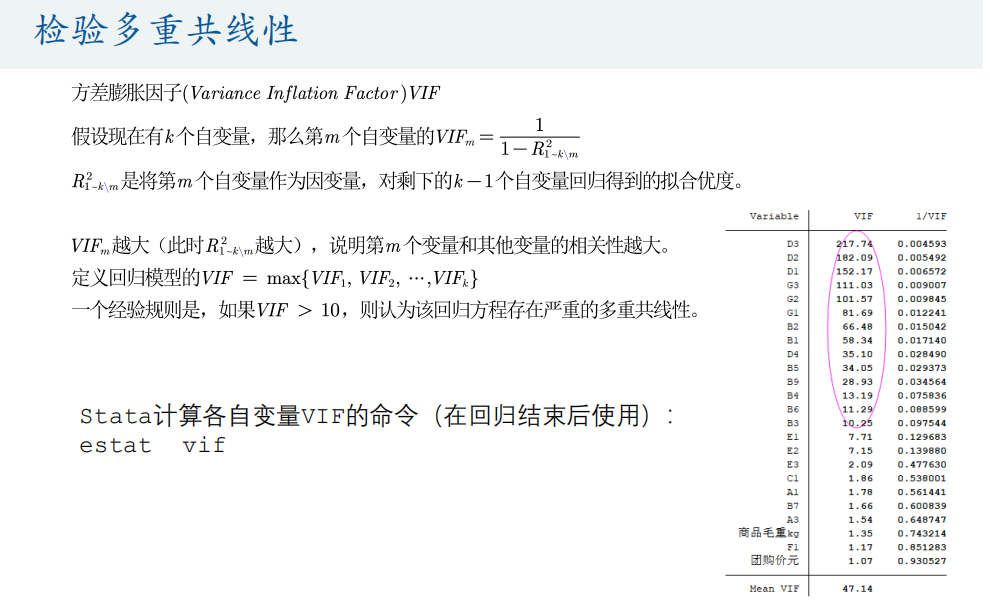
多重共线性处理方法
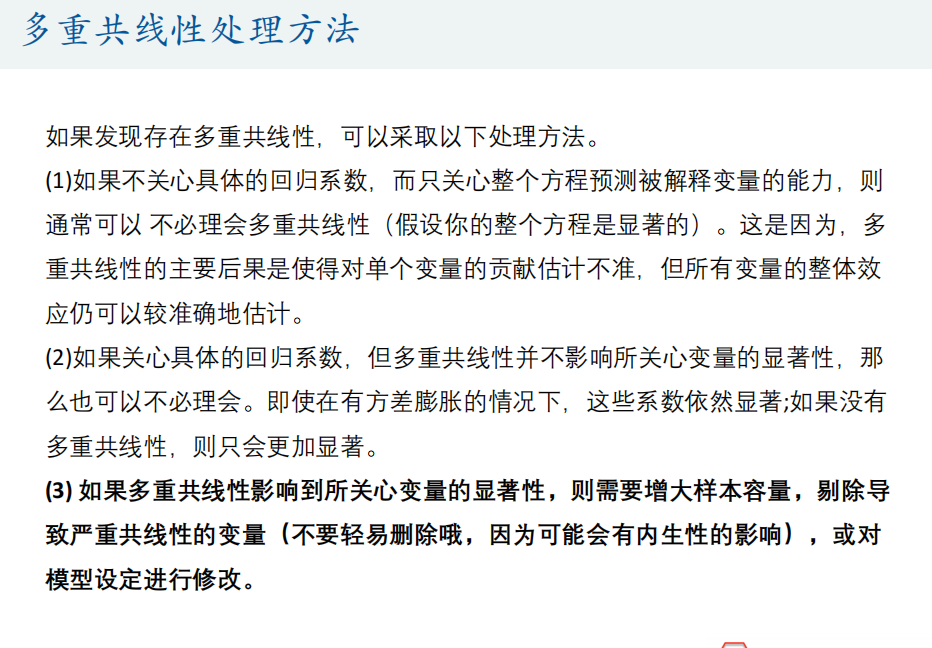
- 预测回归不关注多重共线性问题,解释回归关注
- 当多重共线性不影响解释变量时,可以不考虑多重共线性的影响
- 当多重共线性影响解释变量时,增大样本容量,剔除导致严重共线性的变量或者修改模型
- 逐步回归法
逐步回归
向后逐步回归更好



岭回归和lasso回归(逐步回归升级版)(解决多重共线性)
- 逐步回归升级版
- 解决多重共线性

古典回归模型
瞒住四个假定:
- 线性假定
- 严格外生性
- 无多重共线性
- 球形扰动项
岭回归
适用于样本数量n小于指标数量的情况

λ选取
方法
- 岭迹分析
- VIF法(方差膨胀因子)
- 最小化均方误差(MPSE)


代码
知乎链接
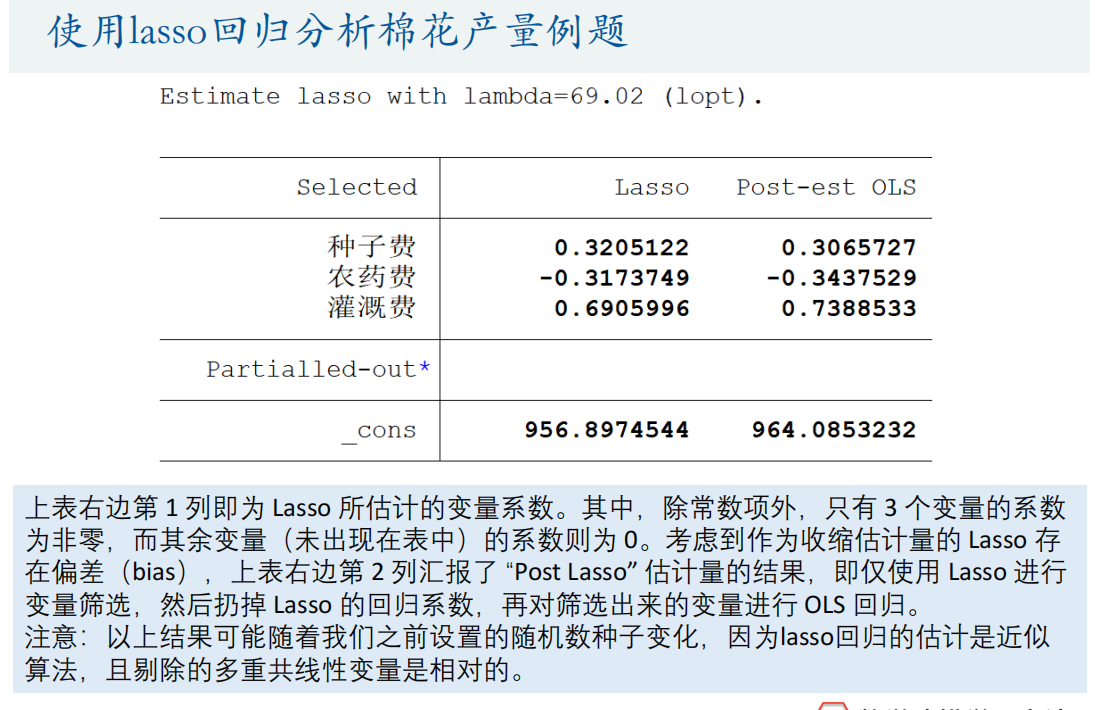
lasso回归(推荐)
优点
- 可以将不重要的回归系数压缩至0
缺点
- 没有显示解,只能使用近似估计算法

K折交叉验证

压缩不重要的自变量
适用情况

代码

// 清空工作区数据
clear
// 安装lassopack命令,见课件
// findit lassopack
// 导入数据,注意修改Excel文件的地址
import excel "C:\Users\hc_lzp\Desktop\数学建模视频录制\A01更新\岭回归和lasso回归\数据和拓展资料\棉花产量论文作业的数据.xlsx", sheet("data") firstrow
// 注意:这里自变量的量纲相同所以不用标准化,如果需要标准化,那么可以借助Matlab的zscore函数,或者直接使用SPSS(分析-描述统计-描述:在描述列表的方框左下角,看到“将标准化得分另存为变量(Z)之后点击打勾,然后确定。)
// Stata中也有相应的标准化变量的命令,不过一次只能标准化一个变量,例如: egen Y = std(单产) 这个代码就表示将单产标准化,得到的变量记为Y
cvlasso 单产 种子费 化肥费 农药费 机械费 灌溉费, lopt seed(520)
分类模型
方法
- 逻辑回归(logistic regression)
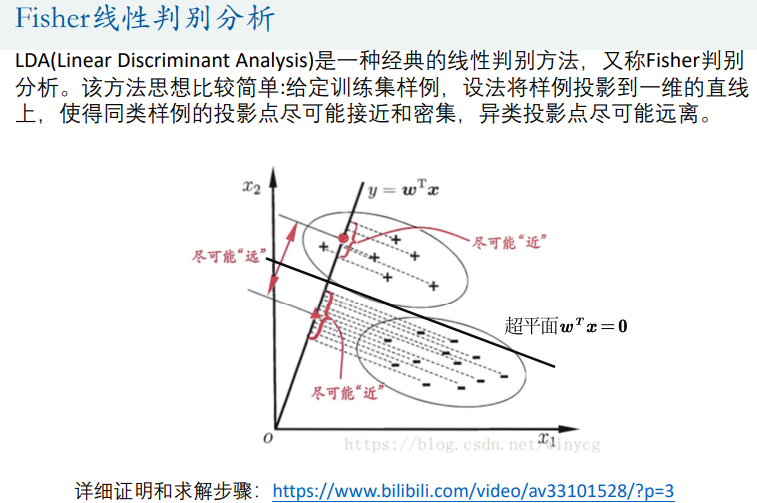
- 费希尔线性回归(Fisher线性判别)
逻辑回归
二分类
首先:将决策变量转化为虚拟变量0-1
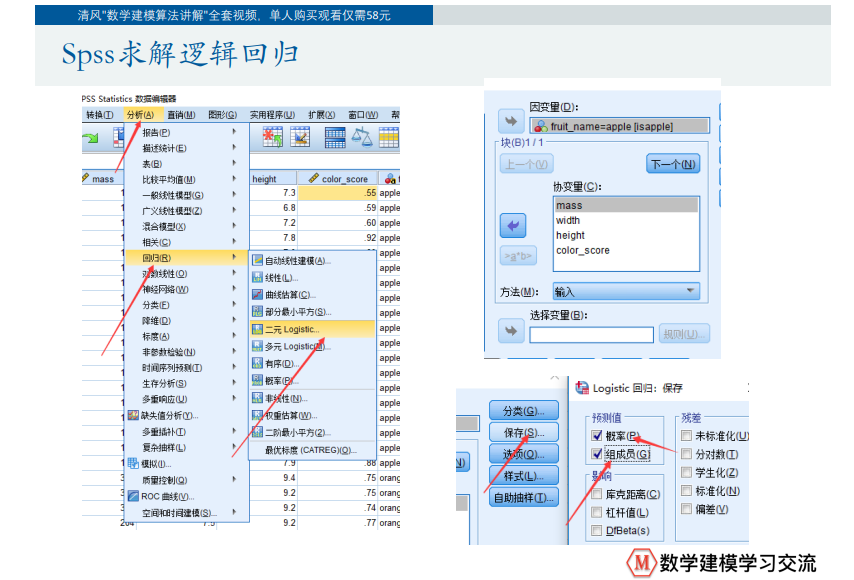
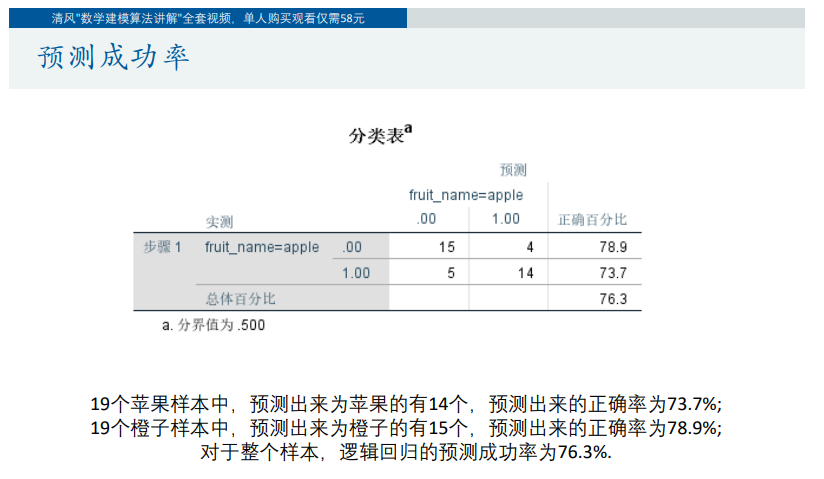
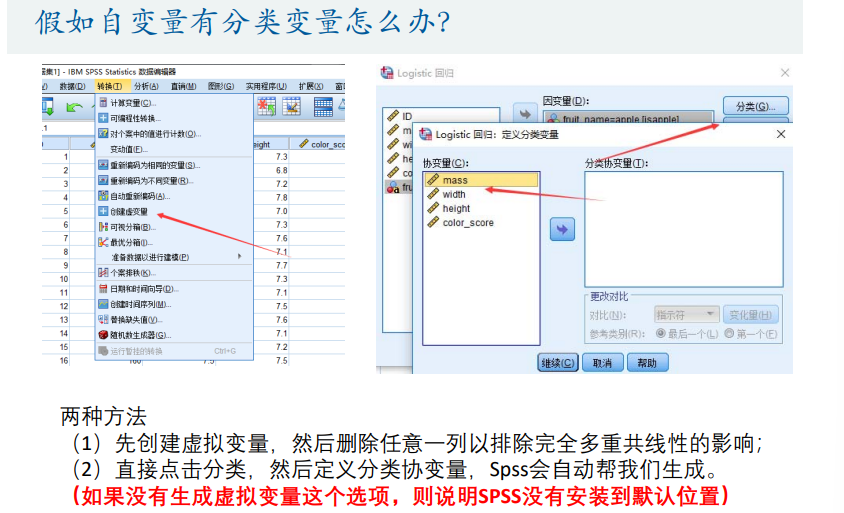
如果自变量是定性变量,需要对自变量进行虚拟化
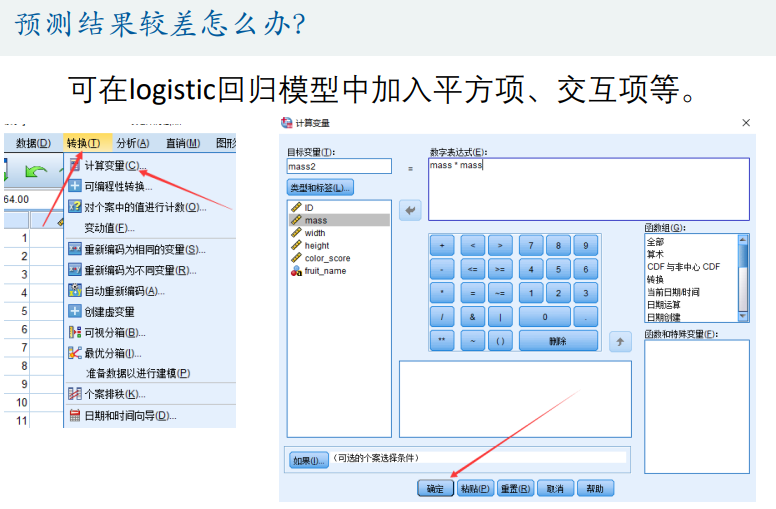
提高预测精度的方法
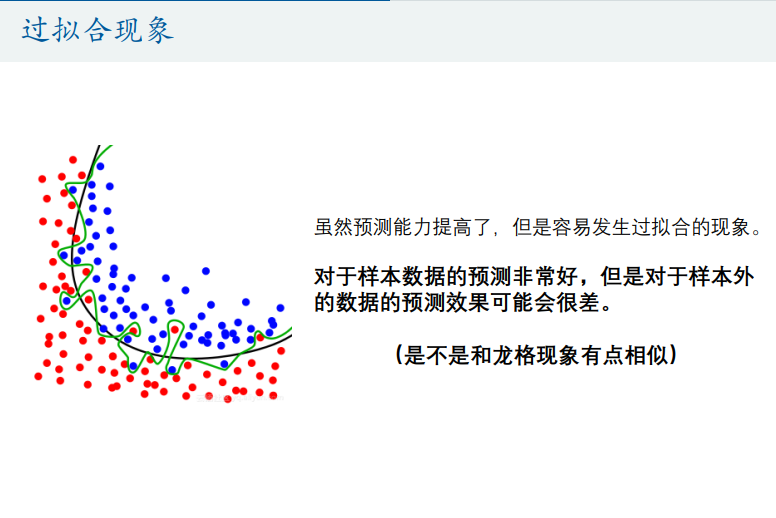
- 加入平方项或交互项(可能会造成过拟合现象)
- 交叉验证

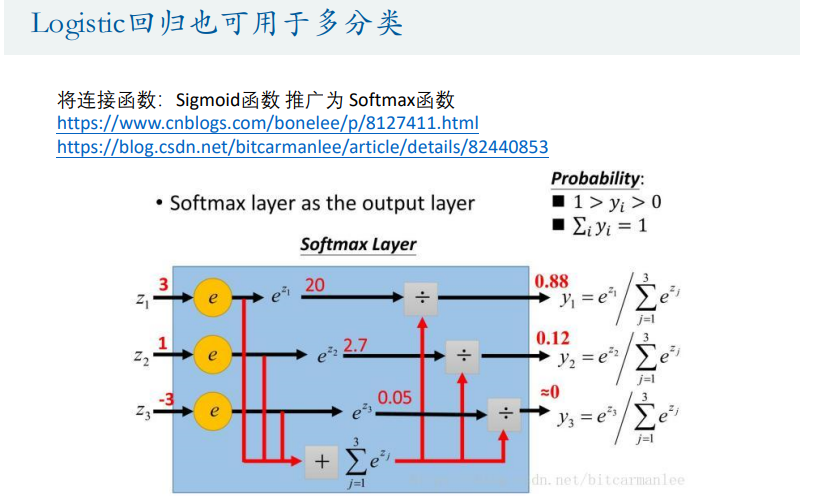
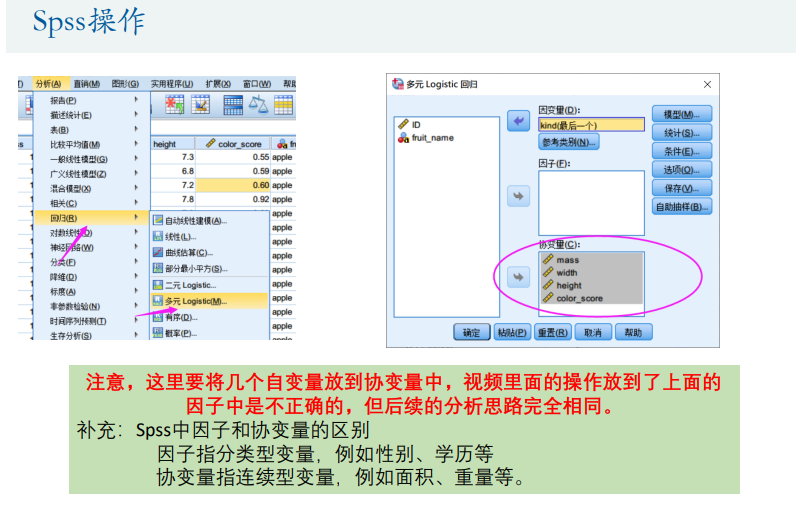
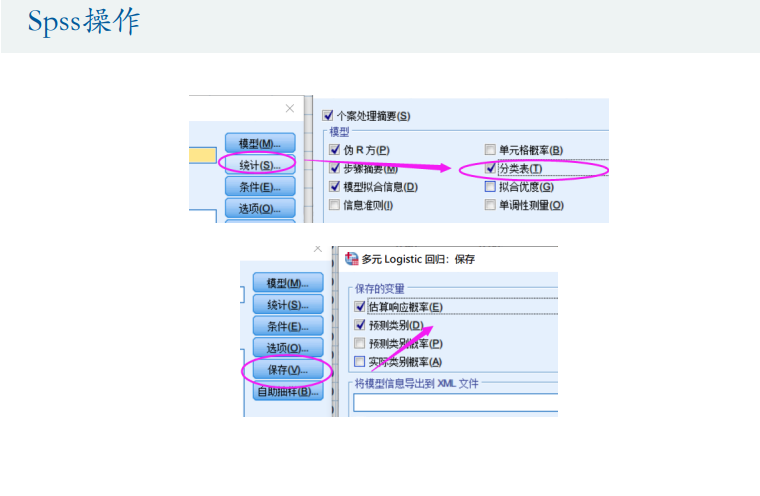
多分类
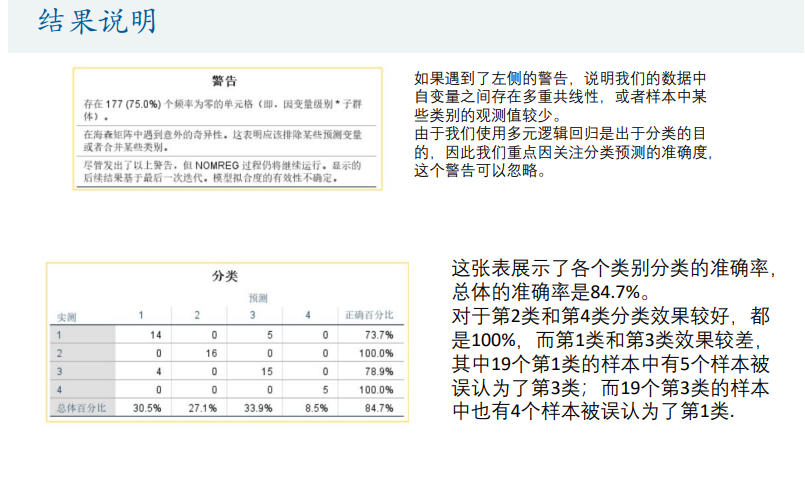
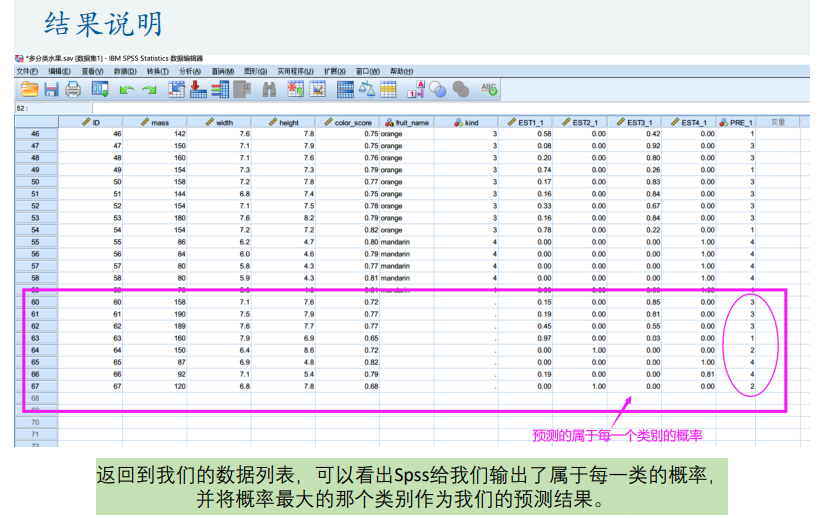
Fisher线性判别分析
二分类
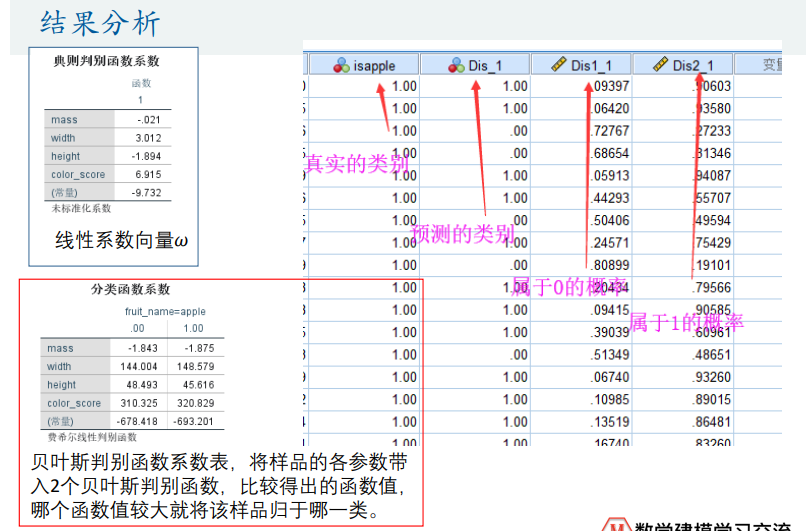
多分类
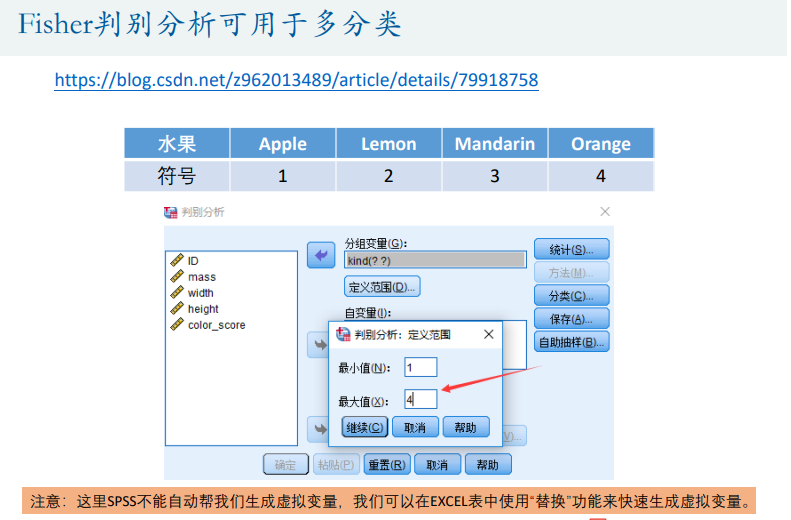
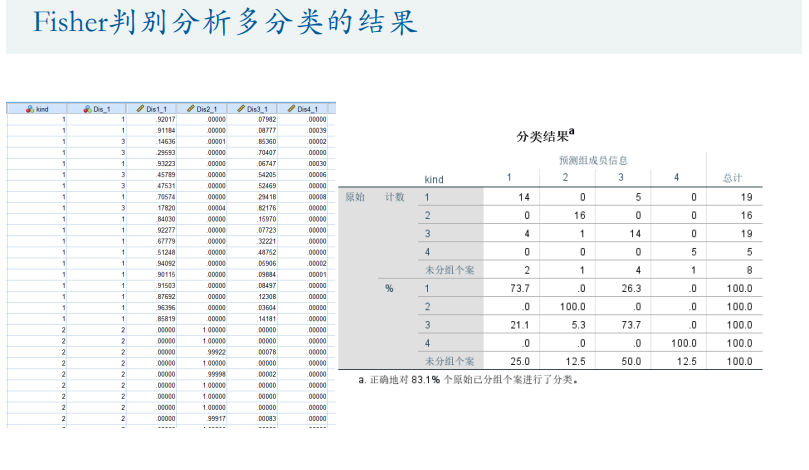
聚类模型
注意:需要对数据进行标准化
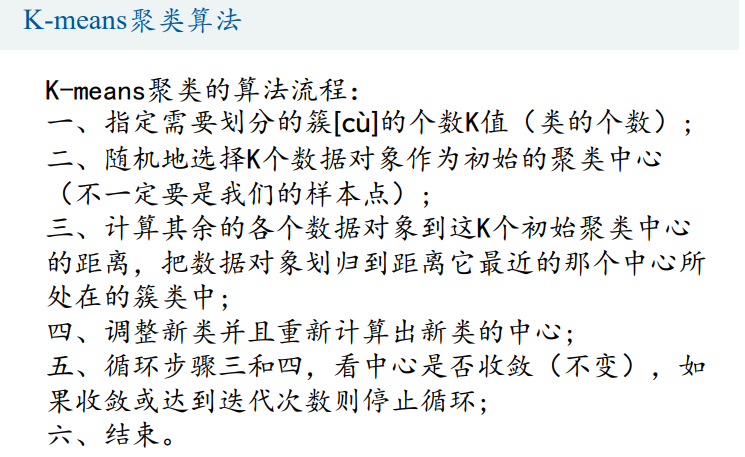
K-means聚类算法(基于距离)
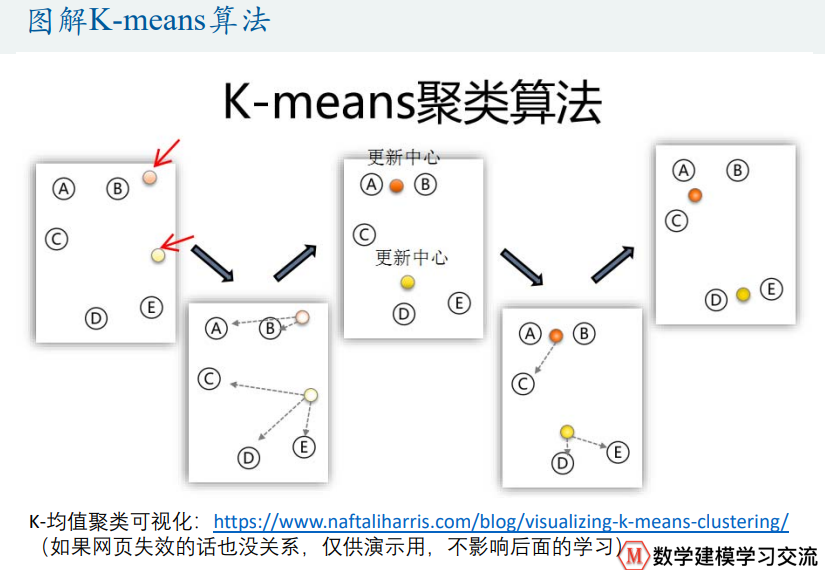
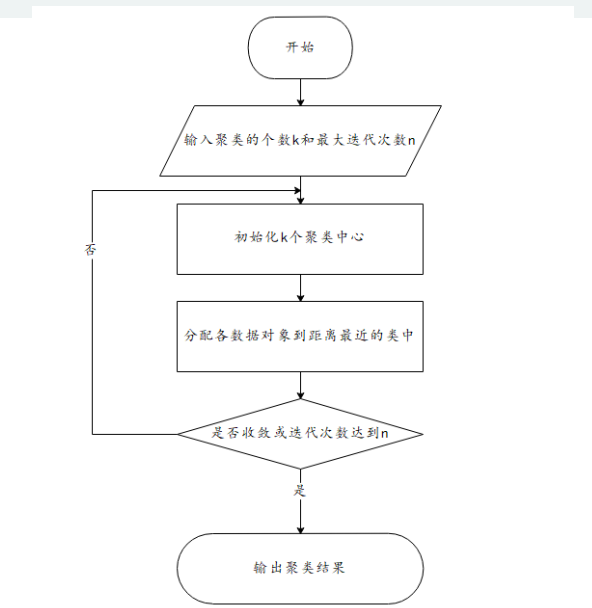
算法优劣

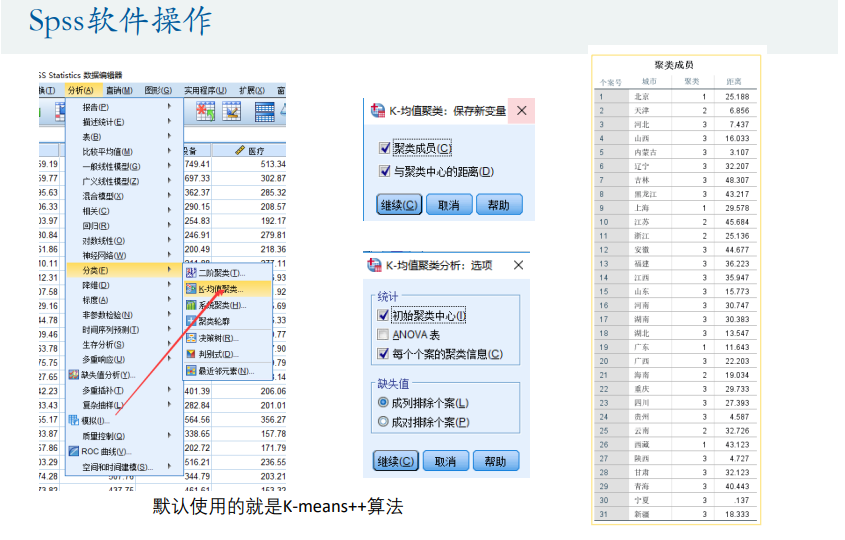
K-means++改进算法(基于距离)

spss操作
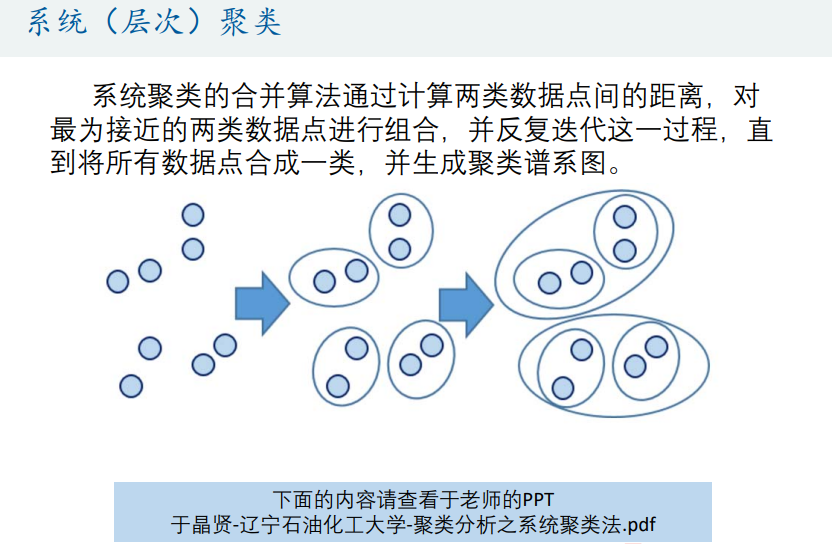
系统(层次)聚类(基于距离)(推荐)
算法流程

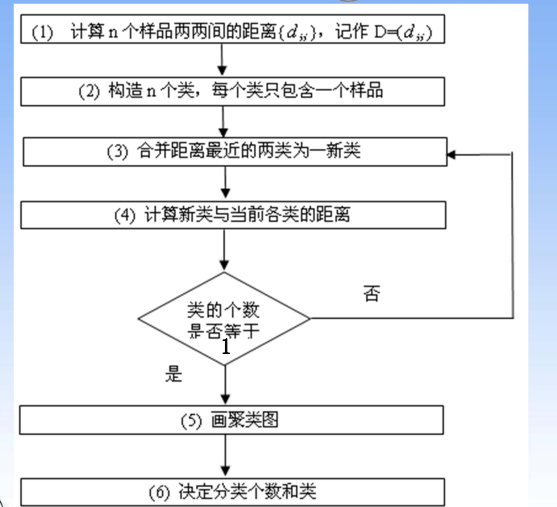
注意事项

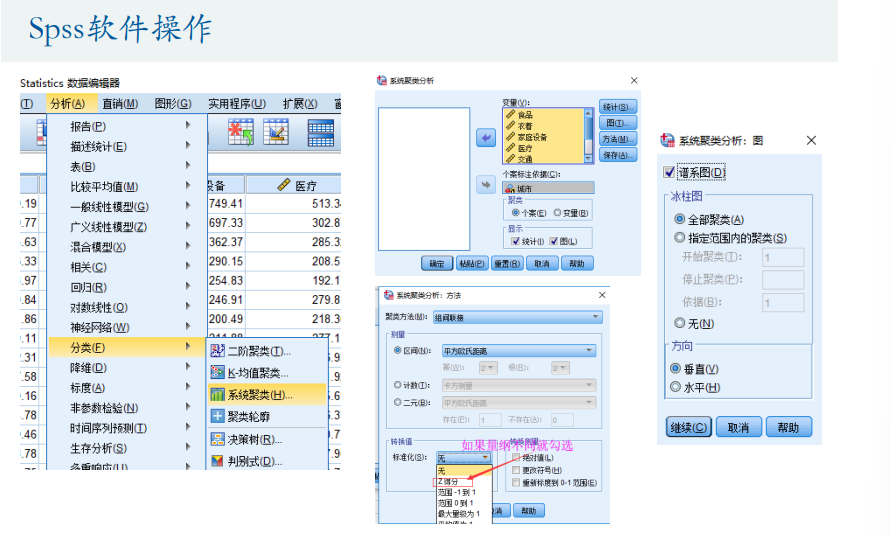
spss操作

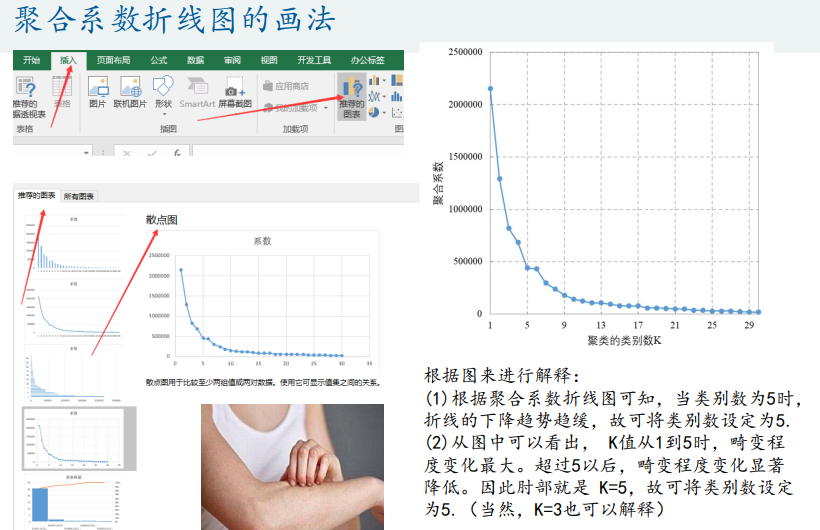
肘部图(估计k)

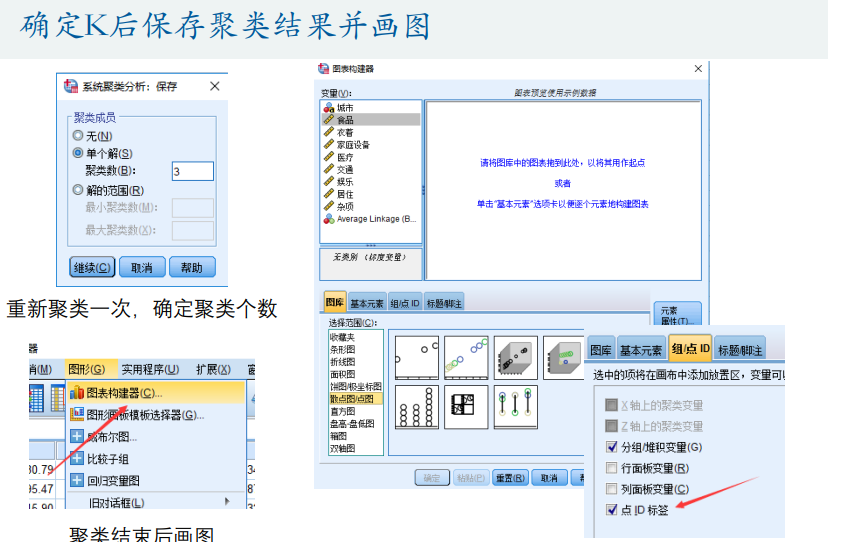
DBSCAN算法(基于密度)

基本概念
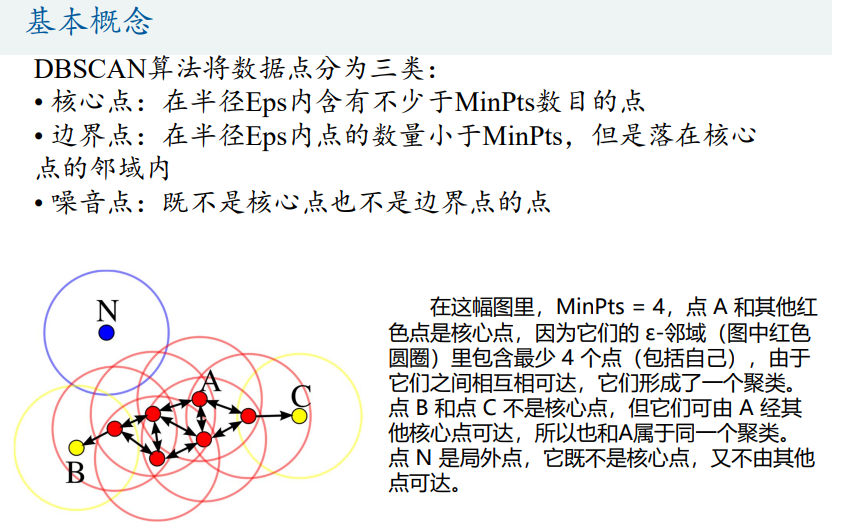
算法优劣

代码
function [IDX, isnoise]=DBSCAN(X,epsilon,MinPts)C=0;n=size(X,1);IDX=zeros(n,1); % 初始化全部为0,即全部为噪音点D=pdist2(X,X);visited=false(n,1);isnoise=false(n,1);for i=1:nif ~visited(i)visited(i)=true;Neighbors=RegionQuery(i);if numel(Neighbors)<MinPts% X(i,:) is NOISEisnoise(i)=true;elseC=C+1;ExpandCluster(i,Neighbors,C);endendendfunction ExpandCluster(i,Neighbors,C)IDX(i)=C;k = 1;while truej = Neighbors(k);if ~visited(j)visited(j)=true;Neighbors2=RegionQuery(j);if numel(Neighbors2)>=MinPtsNeighbors=[Neighbors Neighbors2]; %#okendendif IDX(j)==0IDX(j)=C;endk = k + 1;if k > numel(Neighbors)break;endendendfunction Neighbors=RegionQuery(i)Neighbors=find(D(i,:)<=epsilon);endendfunction PlotClusterinResult(X, IDX)k=max(IDX);Colors=hsv(k);Legends = {};for i=0:kXi=X(IDX==i,:);if i~=0Style = 'x';MarkerSize = 8;Color = Colors(i,:);Legends{end+1} = ['Cluster #' num2str(i)];elseStyle = 'o';MarkerSize = 6;Color = [0 0 0];if ~isempty(Xi)Legends{end+1} = 'Noise';endendif ~isempty(Xi)plot(Xi(:,1),Xi(:,2),Style,'MarkerSize',MarkerSize,'Color',Color);endhold on;endhold off;axis equal;grid on;legend(Legends);legend('Location', 'NorthEastOutside');endclc;
clear;
close all;%% Load Dataload mydata;%% Run DBSCAN Clustering Algorithmepsilon=0.5;
MinPts=10;
IDX=DBSCAN(X,epsilon,MinPts);%% Plot Results
% 如果只要两个指标的话就可以画图啦
PlotClusterinResult(X, IDX);
title(['DBSCAN Clustering (\epsilon = ' num2str(epsilon) ', MinPts = ' num2str(MinPts) ')']);
时间序列分析
基本概念



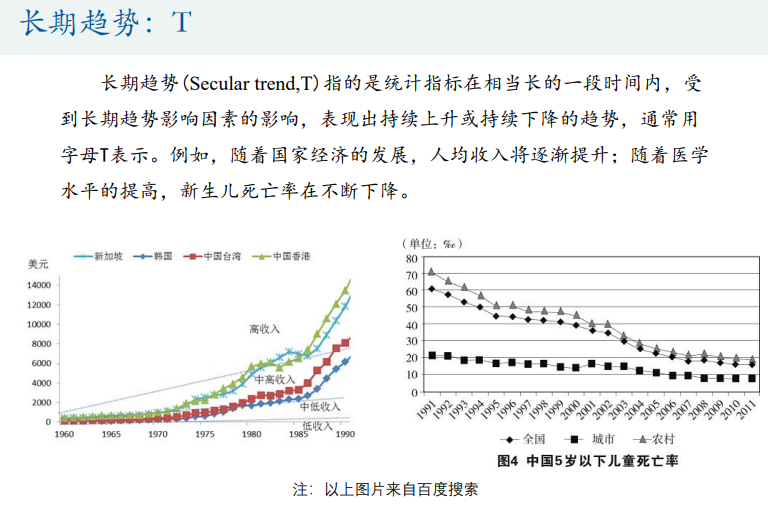
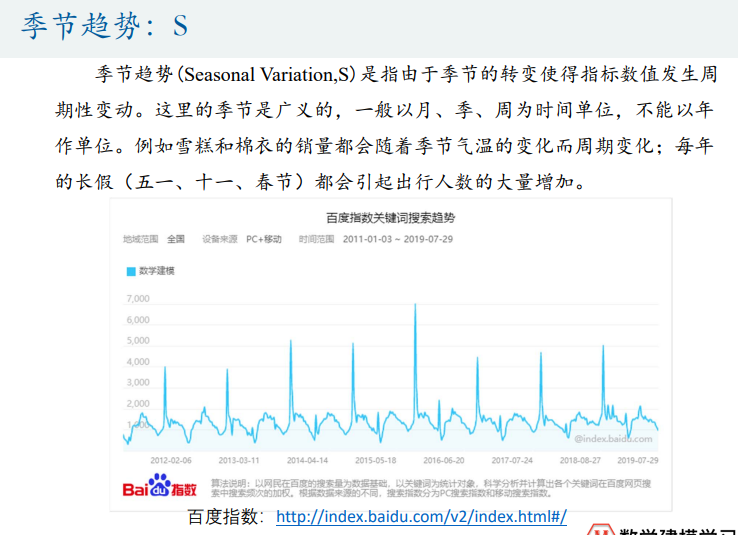
时间序列分解

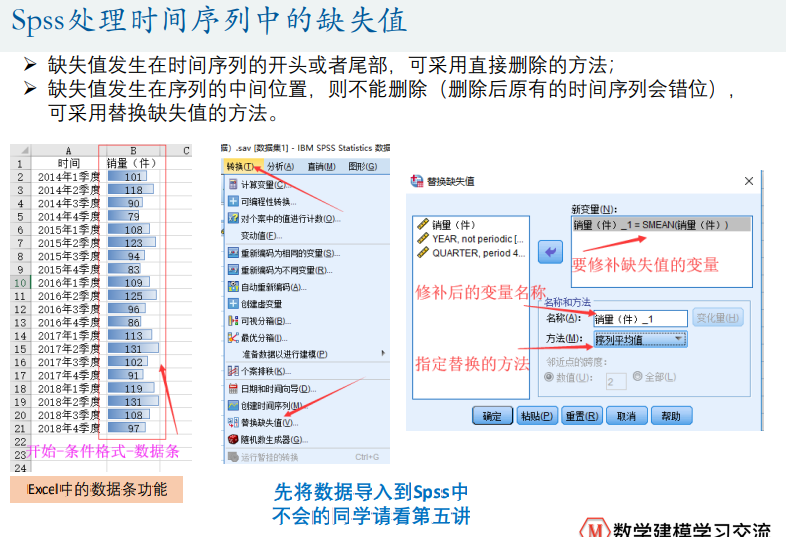
spss缺失值处理
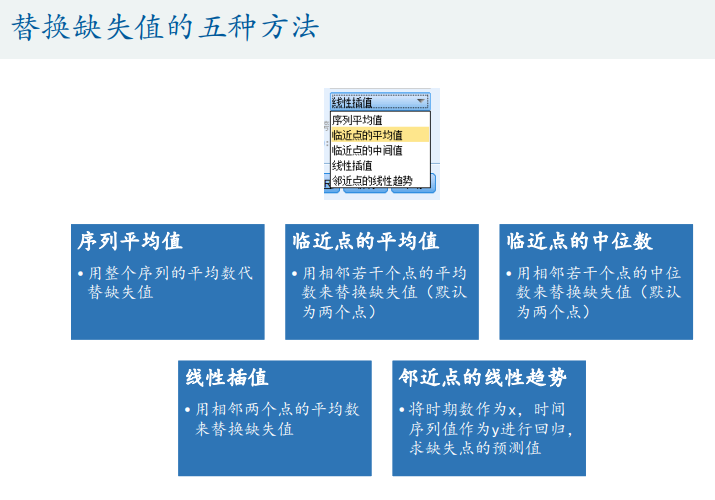
spss数据处理(时间序列图)
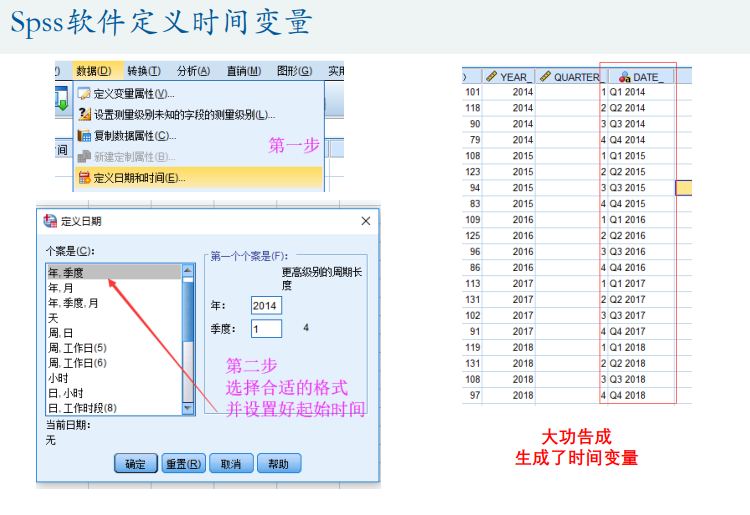
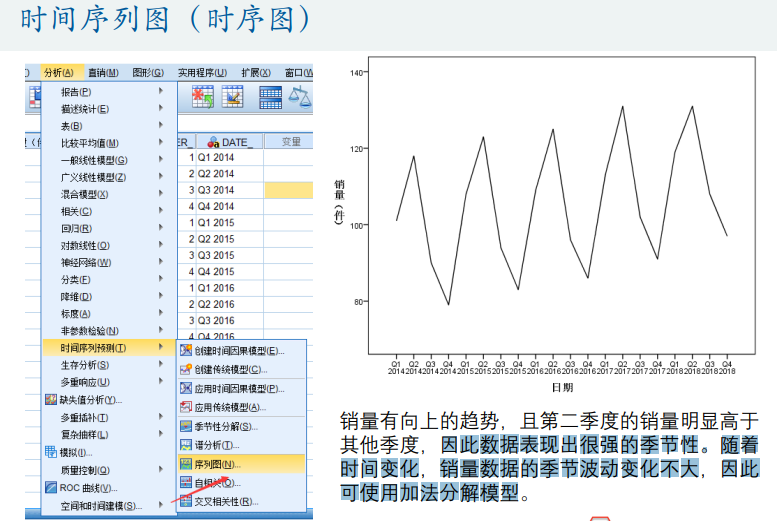
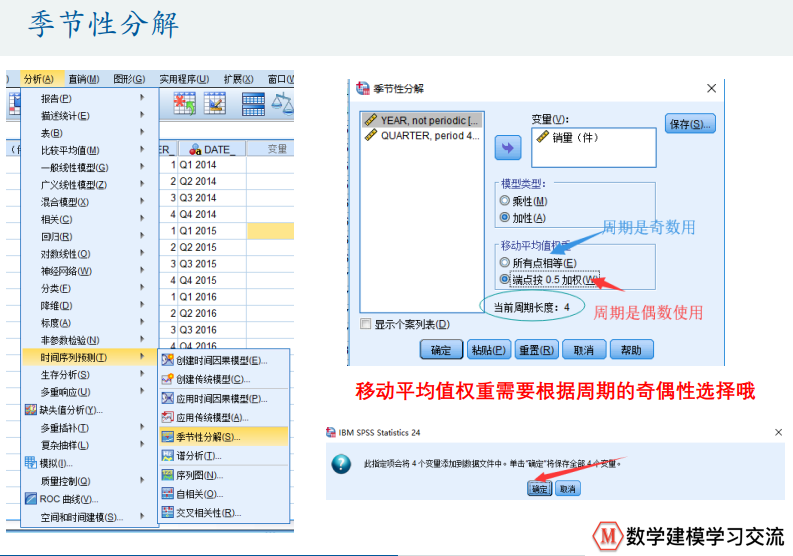
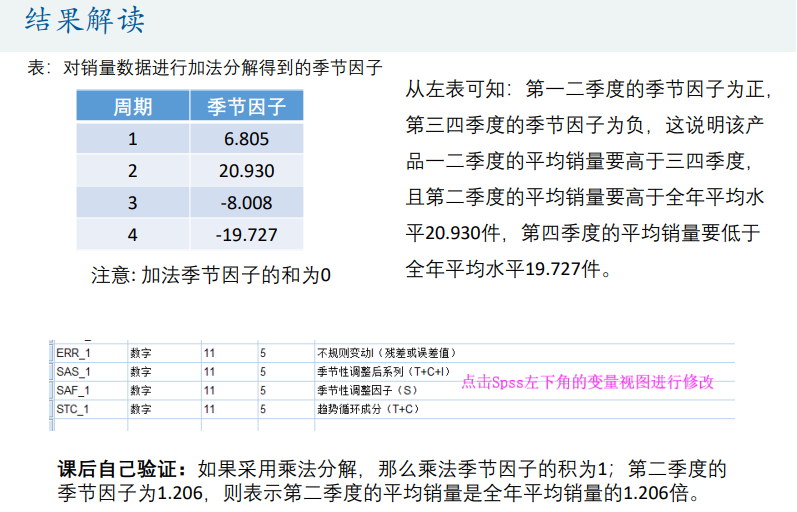
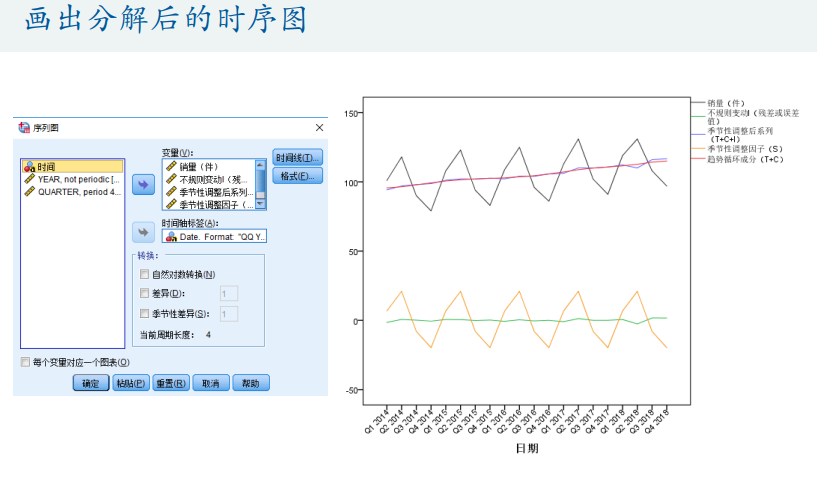
操作用途和步骤
模型建立

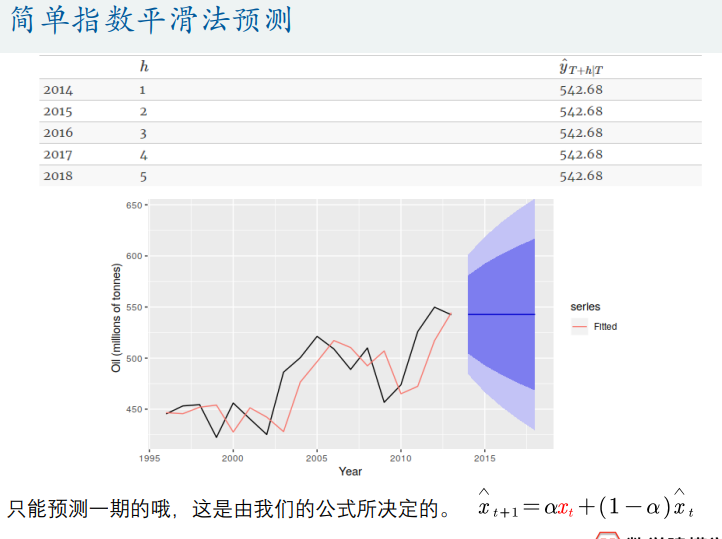
指数平滑模型




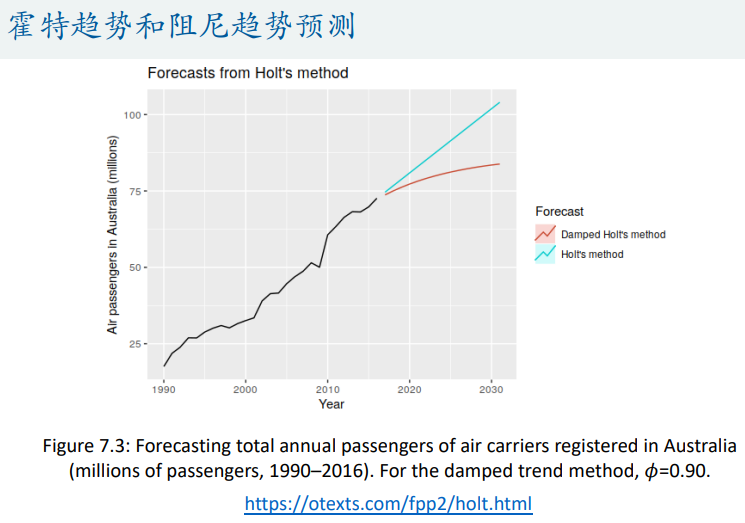


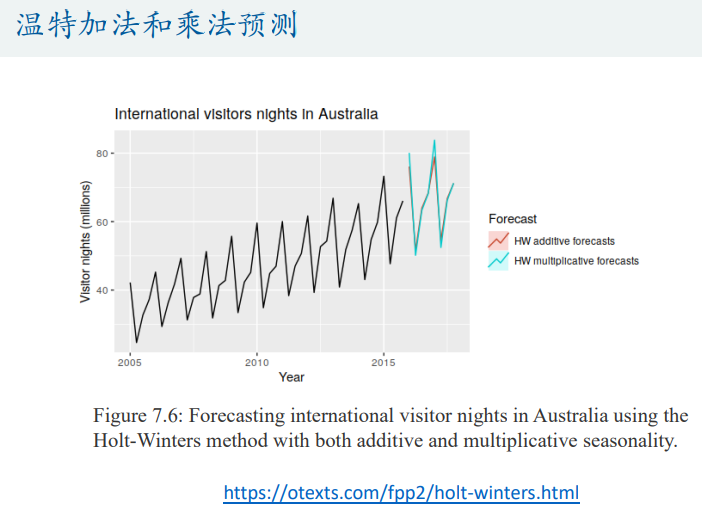
一元时间序列分析模型

建模思路和实例
季节性数据

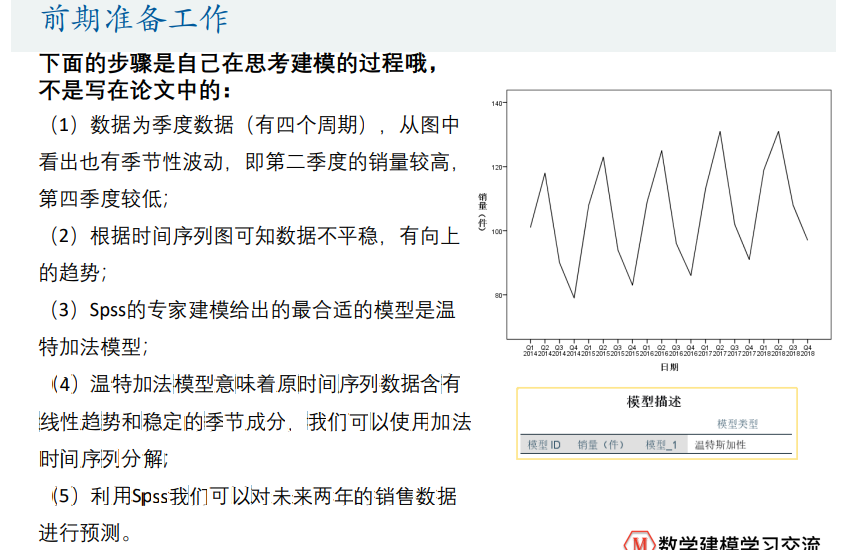
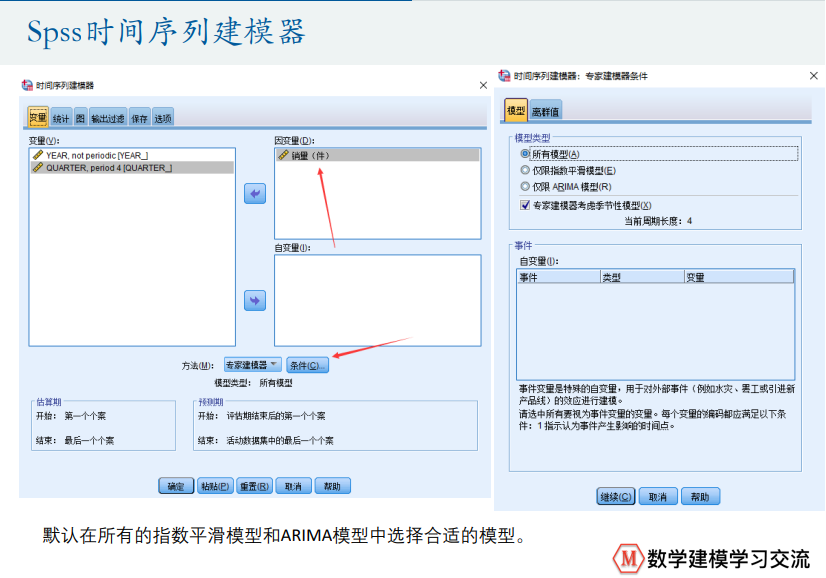
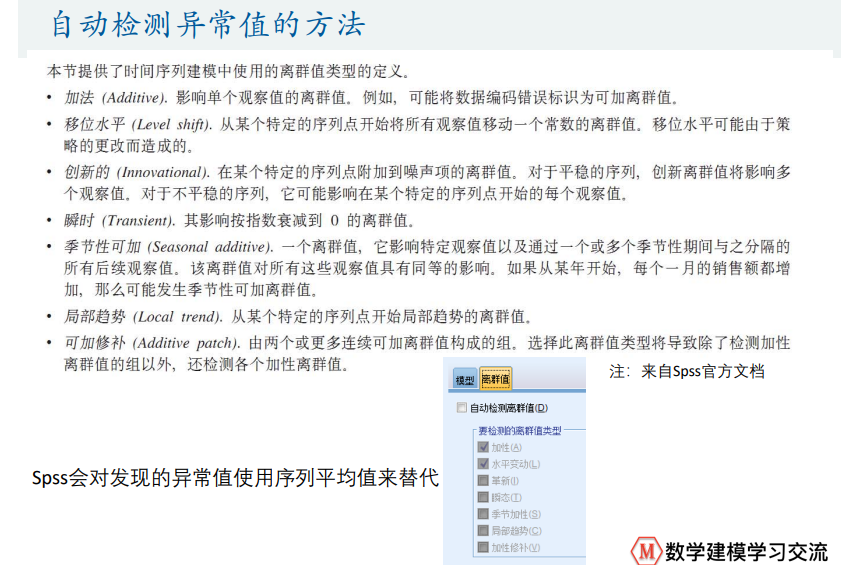
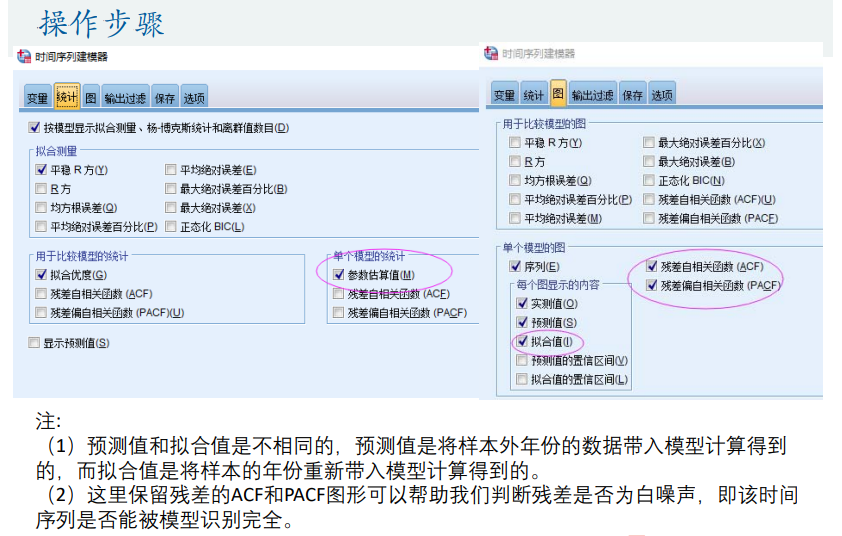
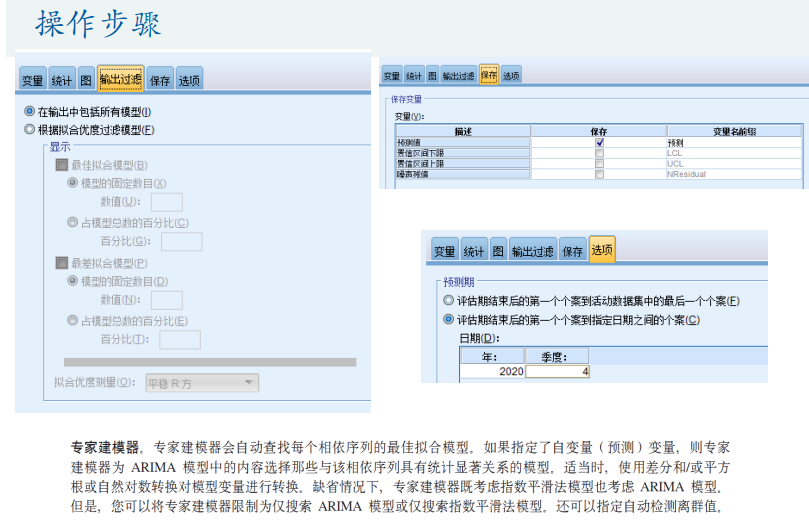

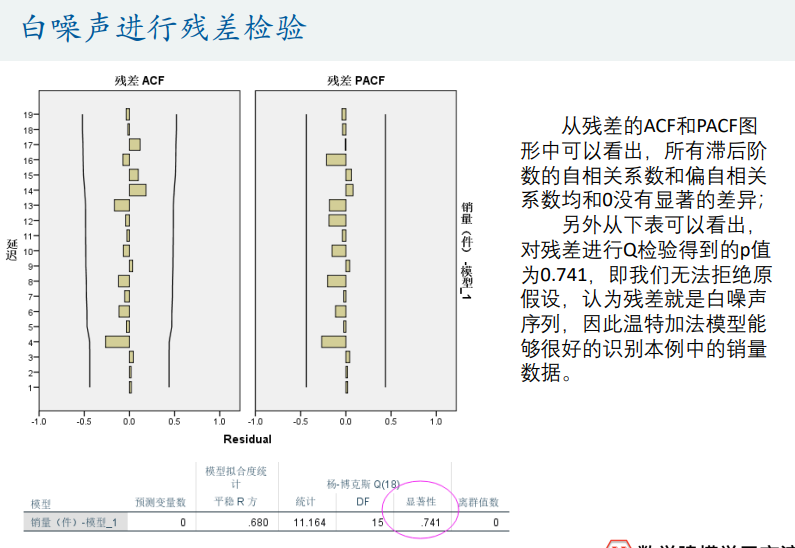
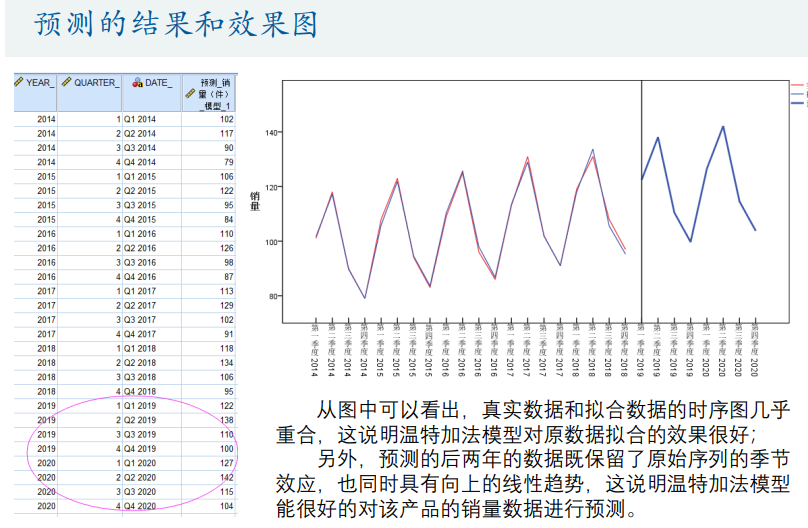
人口预测
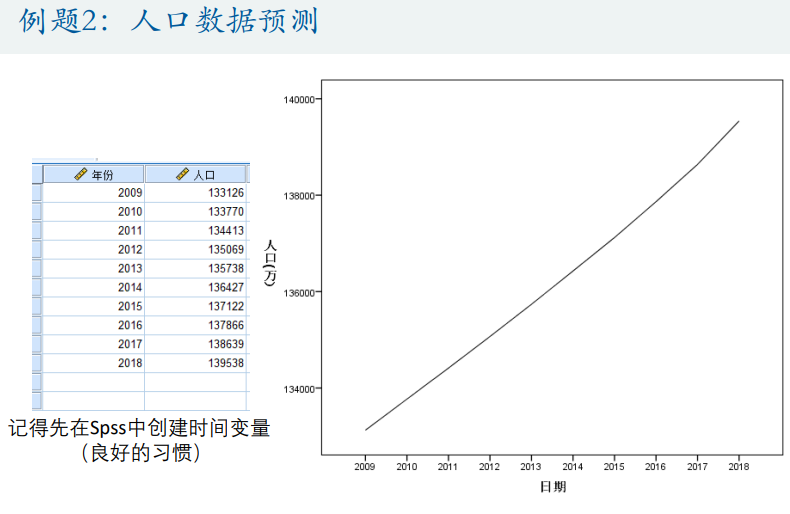

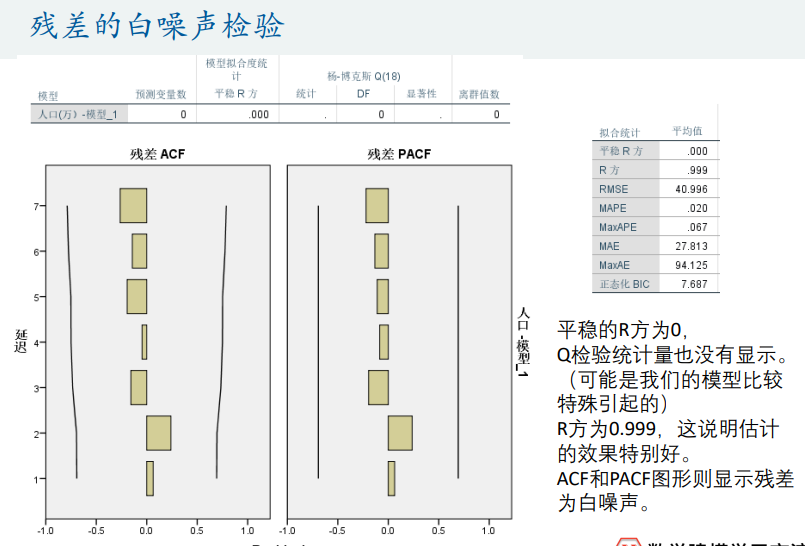
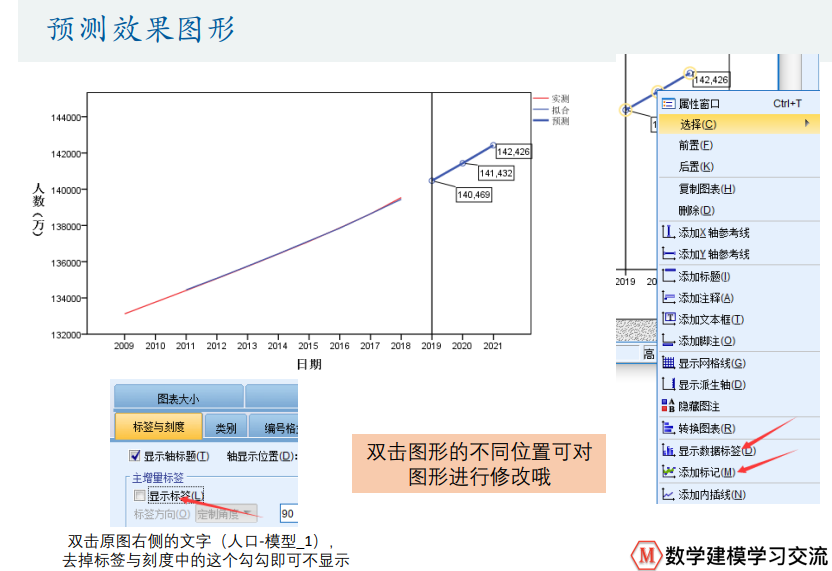
股票上证指数预测
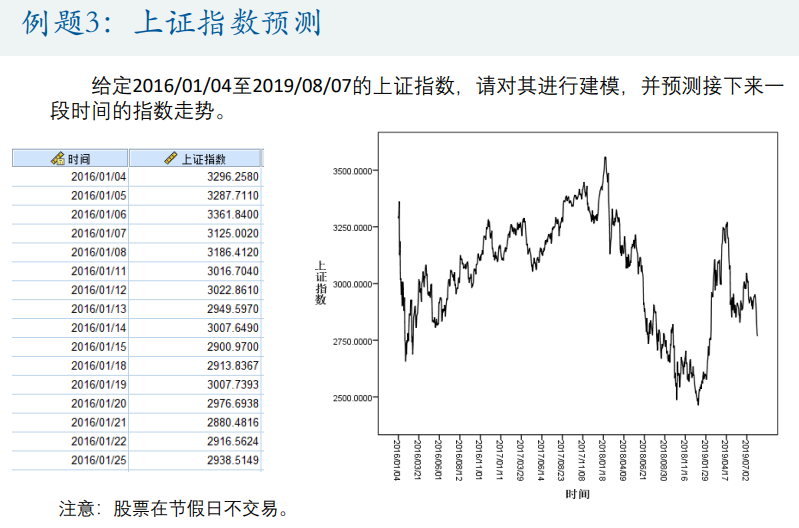
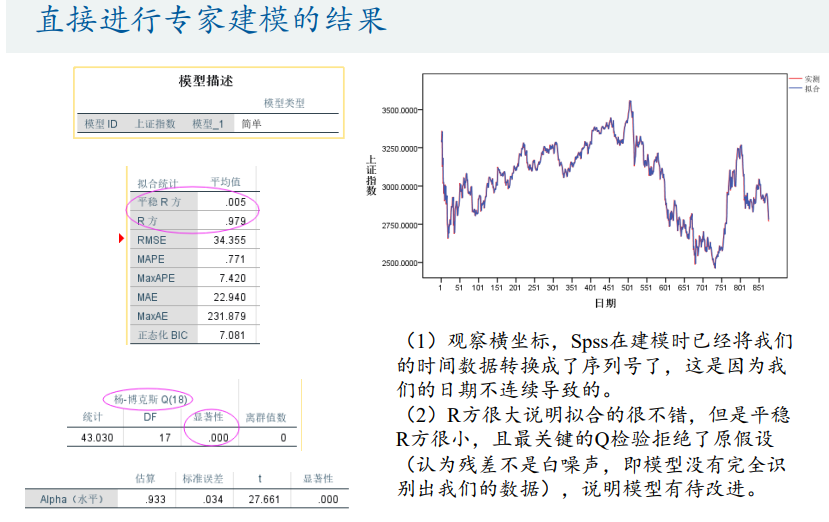
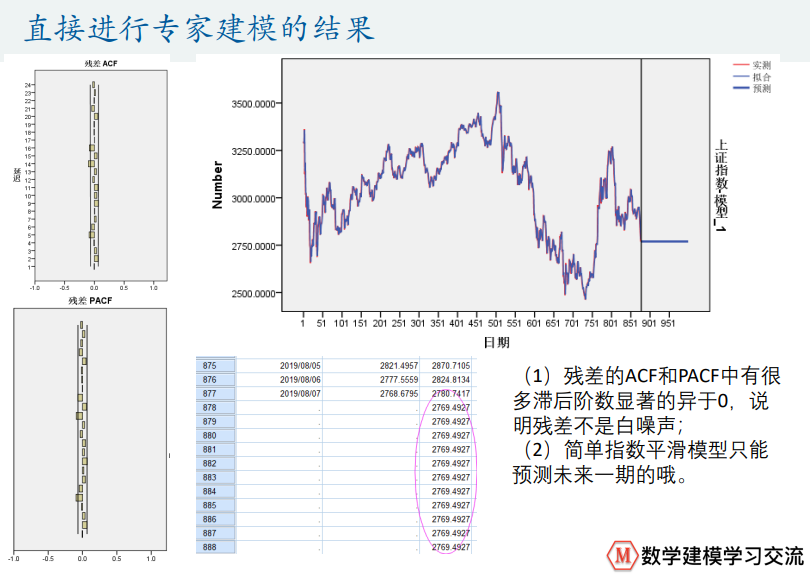
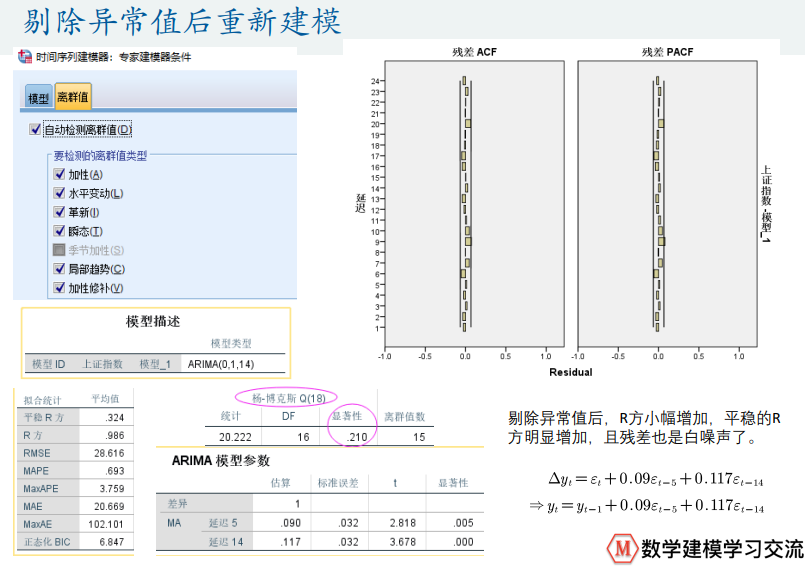
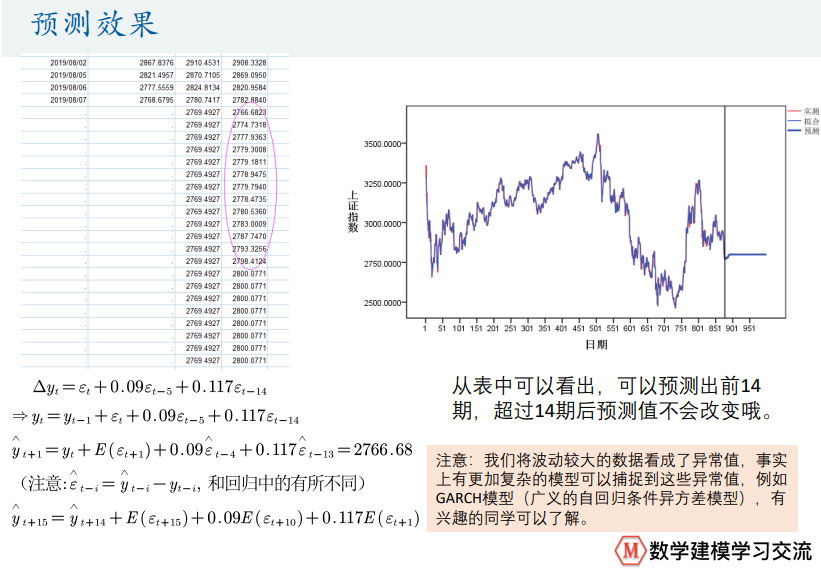
GDP增速预测
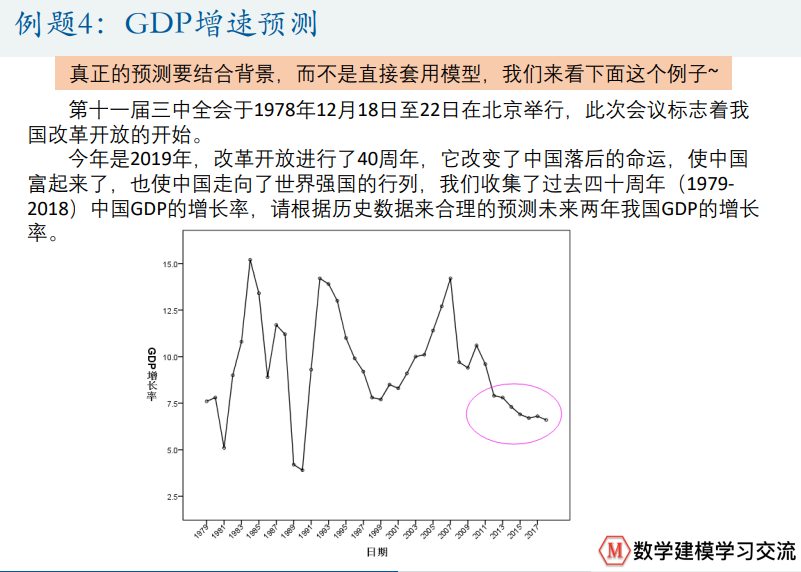
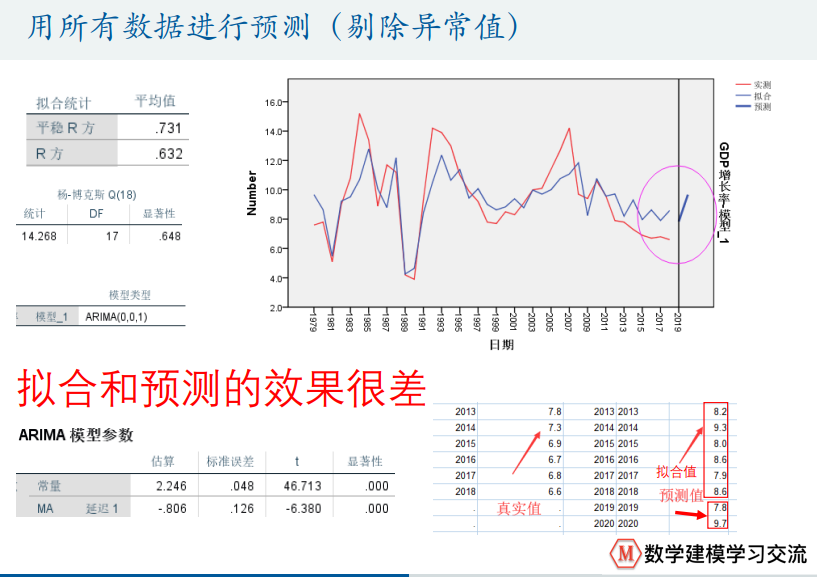
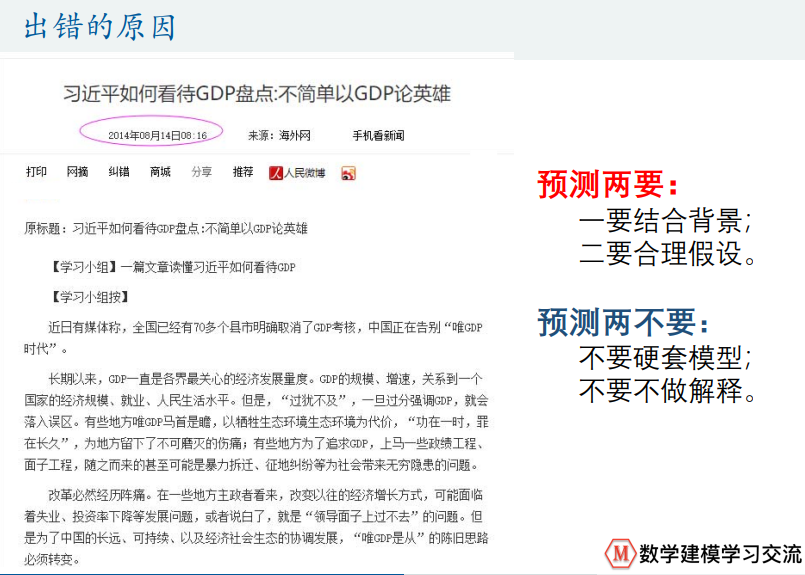
优化类方法
蒙特卡洛模拟
引例:浦丰投针实验

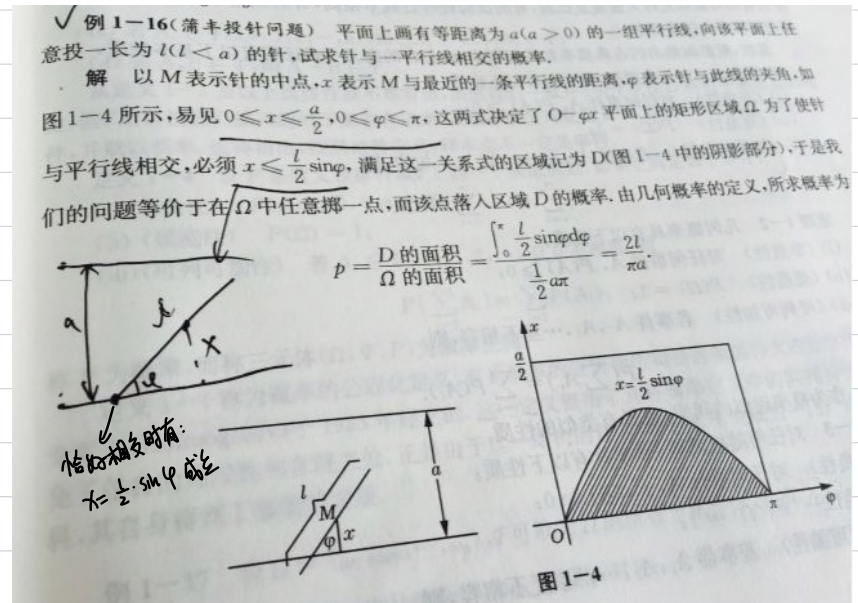
代码
%% 蒙特卡罗用于布丰投针实验%% (1)预备知识
% rand(m,n)函数产生由在[0,1]之间均匀分布的随机数组成的m行n列的矩阵(或称为数组)。
rand(5,4)
% 0.8300 0.1048 0.2396 0.4398
% 0.5663 0.1196 0.8559 0.5817
% 0.9281 0.2574 0.3013 0.9355
% 0.3910 0.3173 0.2108 0.1676
% 0.3645 0.4372 0.8819 0.9232
rand(3) % 若只给一个输入,则会生成一个方阵
% 0.1709 0.4951 0.0541
% 0.9374 0.8500 0.6155
% 0.2400 0.3156 0.5741
% a + rand(m,n)*(b-a) 可以输出在[a,b]之间均匀分布的随机数组成的m行n列的矩阵。
-2 + rand(3,2) * (2 - (-2)) % 输出在[-2,2]之间均匀分布的随机数组成的3行2列的矩阵。
% -1.2743 0.6013
% -1.3084 0.0766
% 1.5075 0.7563
% a + rand(m,n)*(b-a)等价于unifrnd(a,b,m,n)
unifrnd(-2,2,3,2)%% (2)代码部分
l = 0.520; % 针的长度(任意给的)
a = 1.314; % 平行线的宽度(大于针的长度l即可)
n = 10000; % 做n次投针试验,n越大求出来的pi越准确
m = 0; % 记录针与平行线相交的次数
x = rand(1, n) * a / 2 ; % 在[0, a/2]内服从均匀分布随机产生n个数, x中每一个元素表示针的中点和最近的一条平行线的距离
phi = rand(1, n) * pi; % 在[0, pi]内服从均匀分布随机产生n个数,phi中的每一个元素表示针和最近的一条平行线的夹角
% axis([0,pi, 0,a/2]); box on; % 画一个坐标轴的框架,x轴位于0-pi,y轴位于0-a/2, 并打开图形的边框
for i=1:n % 开始循环,依次看每根针是否和直线相交if x(i) <= l / 2 * sin(phi (i)) % 如果针和平行线相交m = m + 1; % 那么m就要加1plot(phi(i), x(i), 'r.') % 模仿书上的那个图,横坐标为phi,纵坐标为x , 用红色的小点进行标记hold on % 在原来的图形上继续绘制end
end
p = m / n; % 针和平行线相交出现的频率
mypi = (2 * l) / (a * p); % 我们根据公式计算得到的pi
disp(['蒙特卡罗方法得到pi为:', num2str(mypi)])%% (3) 由于一次模拟的结果具有偶然性,因此我们可以重复100次后再来求一个平均的pi
result = zeros(100,1); % 初始化保存100次结果的矩阵
l = 0.520; a = 1.314;
n = 1000000;
for num = 1:100m = 0; x = rand(1, n) * a / 2 ;phi = rand(1, n) * pi;for i=1:nif x(i) <= l / 2 * sin(phi (i))m = m + 1;endendp = m / n;mypi = (2 * l) / (a * p);result(num) = mypi; % 把求出来的myphi保存到结果矩阵中
end
mymeanpi = mean(result); % 计算result矩阵中保存的100次结果的均值
disp(['蒙特卡罗方法得到pi为:', num2str(mymeanpi)])
概述
蒙特卡罗⽅法⼜称统计模拟法,是⼀种随机模拟⽅法
蒙特卡洛模拟是一种算法思想,不是直接的算法
三门问题

代码
%% 蒙特卡罗用于模拟三门问题
clear;clc
%% (1)预备知识
% randi([a,b],m,n)函数可在指定区间[a,b]内随机取出大小为m*n的整数矩阵
randi([1,5],5,8) %在区间[1,5]内随机取出大小为5*8的整数矩阵
% 2 5 4 5 3 1 4 2
% 3 3 1 5 4 2 1 2
% 4 1 3 3 2 2 5 1
% 5 3 3 4 4 5 4 4
% 4 2 3 4 2 4 2 4
randi([1,5]) %在区间[1,5]内随机取出1个整数
% 3% 字符串的连接方式:(1)['字符串1','字符串2'] (2)strcat('字符串1','字符串2') (第一期视频第一讲)
['数学建模','学习交流']
strcat('数学建模','学习交流')% num2str函数:将数值转换为字符串 (第一期视频第一讲)
mystr = num2str(1224) % 注意观察工作区的mystr这个变量的值
disp([num2str(1224),'祝大家平安夜平平安安']) % disp函数是输出函数%% (2)代码部分(在成功的条件下的概率)
n = 100000; % n代表蒙特卡罗模拟重复次数
a = 0; % a表示不改变主意时能赢得汽车的次数
b = 0; % b表示改变主意时能赢得汽车的次数
for i= 1 : n % 开始模拟n次x = randi([1,3]); % 随机生成一个1-3之间的整数x表示汽车出现在第x扇门后y = randi([1,3]); % 随机生成一个1-3之间的整数y表示自己选的门% 下面分为两种情况讨论:x=y和x~=yif x == y % 如果x和y相同,那么我们只有不改变主意时才能赢a = a + 1; b = b + 0;else % x ~= y ,如果x和y不同,那么我们只有改变主意时才能赢a = a + 0; b = b +1;end
end
disp(['蒙特卡罗方法得到的不改变主意时的获奖概率为:', num2str(a/n)]);
disp(['蒙特卡罗方法得到的改变主意时的获奖概率为:', num2str(b/n)]);%% (3)考虑失败情况的代码(无条件概率)
n = 100000; % n代表蒙特卡罗模拟重复次数
a = 0; % a表示不改变主意时能赢得汽车的次数
b = 0; % b表示改变主意时能赢得汽车的次数
c = 0; % c表示没有获奖的次数
for i= 1 : n % 开始模拟n次x = randi([1,3]); % 随机生成一个1-3之间的整数x表示汽车出现在第x扇门后y = randi([1,3]); % 随机生成一个1-3之间的整数y表示自己选的门change = randi([0, 1]); % change =0 不改变主意,change = 1 改变主意% 下面分为两种情况讨论:x=y和x~=yif x == y % 如果x和y相同,那么我们只有不改变主意时才能赢if change == 0 % 不改变主意a = a + 1; else % 改变了主意c= c+1;endelse % x ~= y ,如果x和y不同,那么我们只有改变主意时才能赢if change == 0 % 不改变主意c = c + 1; else % 改变了主意b= b + 1;endend
end
disp(['蒙特卡罗方法得到的不改变主意时的获奖概率为:', num2str(a/n)]);
disp(['蒙特卡罗方法得到的改变主意时的获奖概率为:', num2str(b/n)]);
disp(['蒙特卡罗方法得到的没有获奖的概率为:', num2str(c/n)]);
排队问题
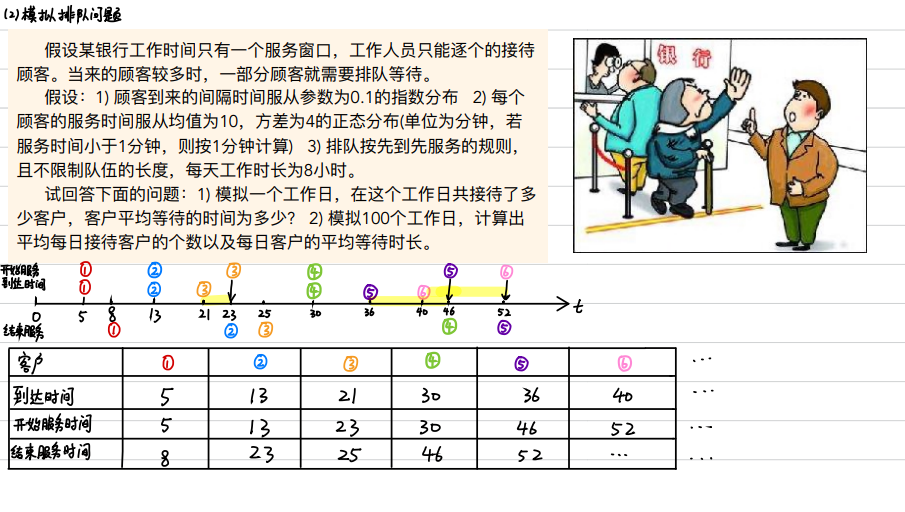
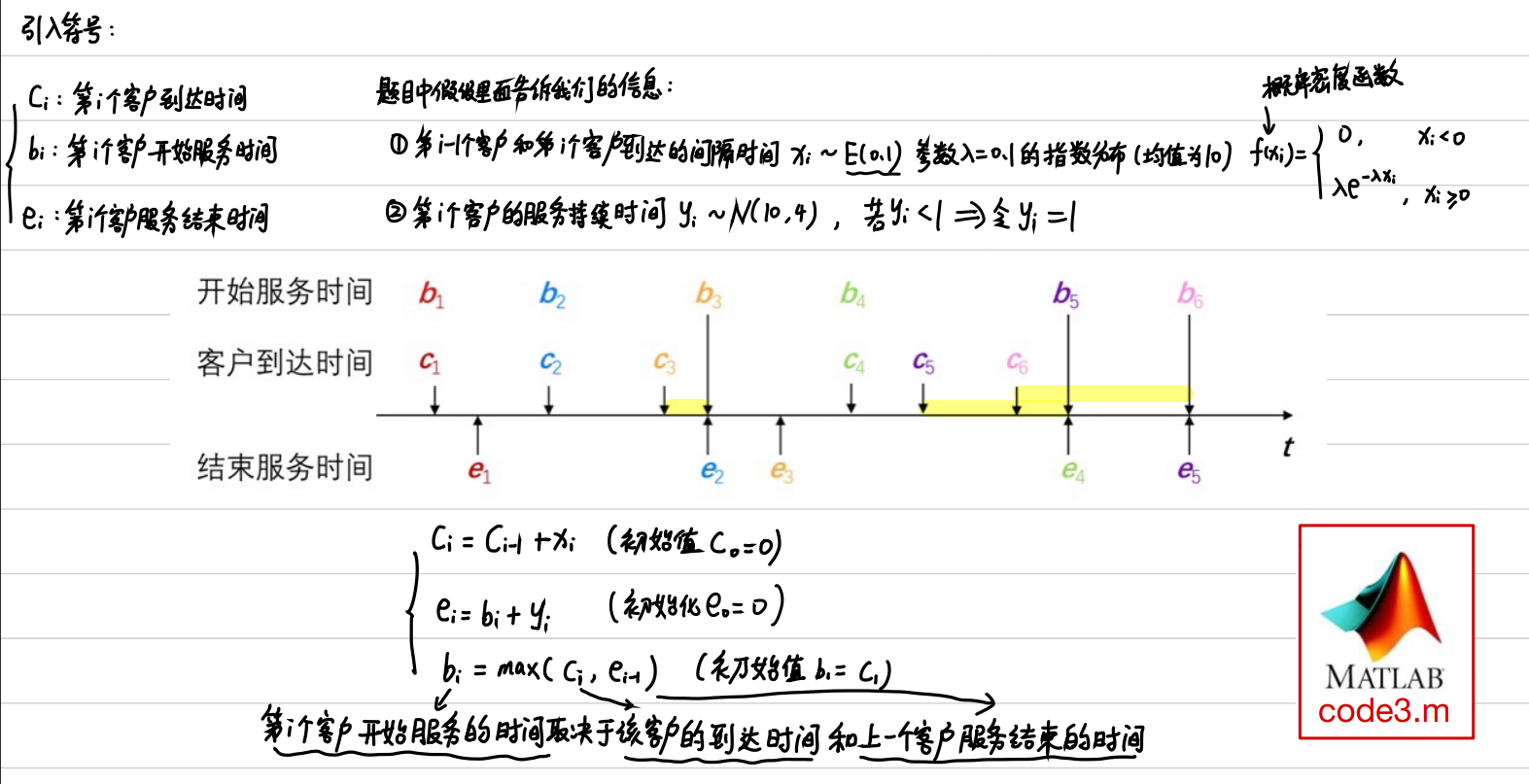
代码
%% 蒙特卡罗模拟排队问题%% (1)预备知识
% normrnd(MU,SIGMA):生成一个服从正态分布(MU参数代表均值,SIGMA参数代表标准差,方差开根号是标准差)的随机数
normrnd(10,2) % 均值为10 标准差为2(方差为4)的正态分布随机数
% exprnd(M)表示生成一个均值为M的指数分布随机数(其对应的参数为1/M)
exprnd(5) % 均值为5的指数分布随机数(对应的参数为0.2)
% mean函数是用来求解均值的函数(第一期视频第五讲)
mean([1,2,3])
% tic函数和toc函数可以用来返回代码运行的时间,例如我们要计算一段代码的运行时间,就可以在这段代码前加上tic,在这段代码后加上toc (我的微信公众号"数学建模学习交流"中有一篇推送《为什么要对代码初始化》中使用过这对函数)
tic
a = 2^100
toc%% (2)模型中出现的变量的说明
% x(i)表示第i-1个客户和第i个客户到达的间隔时间,服从参数为0.1的指数分布
% y(i)表示第i个客户的服务持续时间,服从均值为10方差为4(标准差为2)的正态分布 (若小于1则按1计算)
% c(i)表示第i个客户的到达时间,那么c(i) = c(i-1) + x(i),初始值c0=0
% b(i)表示第i个客户开始服务的时间
% e(i)表示第i个客户结束服务的时间,初始值e0=0
% 第i个客户结束服务的时间 = 第i个客户开始服务的时间 + 第i个客户的服务持续时间
% 即:e(i) = b(i) + y(i)
% 第i个客户开始服务的时间取决于该客户的到达时间和上一个客户结束服务的时间
% 即:b(i) = max(c(i),e(i-1)),初始值b1=c1;
% 第i个客户等待的时间 = 第i个客户开始服务的时间 - 第i个客户到达银行的时间
% 即:wait(i) = b(i) - c(i)
% w表示所有客户等待时间的总和
% 假设一天内银行最终服务了n个顾客,那么客户的平均等待时间t = w/n%% (3)问题1的代码
clear
tic %计算tic和toc中间部分的代码的运行时间
i = 1; % i表示第i个客户,最开始取i=1
w = 0; % w用来表示所有客户等待的总时间,初始化为0
e0 = 0; c0 = 0; % 初始化e0和c0为0
x(1) = exprnd(10); % 第0个客户(假想的)和第1个客户到达的时间间隔
c(1) = c0 + x(1); % 第1个客户到达的时间
b(1) = c(1); % 第1个客户的开始服务的时间
while b(i) <= 480 % 开始设置循环,只要第i个顾客开始服务的时间(时刻)小于480,就可以对其服务(银行每天工作8小时,折换为分钟就是480分钟)y(i) = normrnd(10,2); % 第i个客户的服务持续时间,服从均值为10方差为4(标准差为2)的正态分布if y(i) < 1 % 根据题目的意思:若服务持续时间不足一分钟,则按照一分钟计算y(i) = 1;ende(i) = b(i) + y(i); % 第i个客户结束服务的时间 = 第i个客户开始服务的时间 + 第i个客户的服务持续时间wait(i) = b(i) - c(i); % 第i个客户等待的时间 = 第i个客户开始服务的时间 - 第i个客户到达银行的时间w = w + wait(i); % 更新所有客户等待的总时间i = i + 1; % 增加一名新的客户x(i) = exprnd(10); % 这位新客户和上一个客户到达的时间间隔c(i) = c(i-1) + x(i); % 这位新客户到达银行的时间 = 上一个客户到达银行的时间 + 这位新客户和上一个客户到达的时间间隔b(i) = max(c(i),e(i-1)); % 这个新客户开始服务的时间取决于其到达时间和上一个客户结束服务的时间
end
n = i-1; % n表示银行一天8小时一共服务的客户人数
t = w/n; % 客户的平均等待时间
disp(['银行一天8小时一共服务的客户人数为: ',num2str(n)])
disp(['客户的平均等待时间为: ',num2str(t)])
toc %计算tic和toc中间部分的代码的运行时间%% (4)问题2的代码
clear
tic %计算tic和toc中间部分的代码的运行时间
day = 100; % 假设模拟100天
n = zeros(day,1); % 初始化用来保存每日接待客户数结果的矩阵
t = zeros(day,1); % 初始化用来保存每日客户平均等待时长的矩阵
for k = 1:dayi = 1; % i表示第i个客户,最开始取i=1w = 0; % w用来表示所有客户等待的总时间,初始化为0e0 = 0; c0 = 0; % 初始化e0和c0为0x(1) = exprnd(10); % 第0个客户(假想的)和第1个客户到达的时间间隔c(1) = c0 + x(1); % 第1个客户到达的时间b(1) = c(1); % 第1个客户的开始服务的时间while b(i) <= 480 % 开始设置循环,只要第i个顾客开始服务的时间(时刻)小于480,就可以对其服务(银行每天工作8小时,折换为分钟就是480分钟)y(i) = normrnd(10,2); % 第i个客户的服务持续时间,服从均值为10方差为4(标准差为2)的正态分布if y(i) < 1 % 根据题目的意思:若服务持续时间不足一分钟,则按照一分钟计算y(i) = 1;ende(i) = b(i) + y(i); % 第i个客户结束服务的时间 = 第i个客户开始服务的时间 + 第i个客户的服务持续时间wait(i) = b(i) - c(i); % 第i个客户等待的时间 = 第i个客户开始服务的时间 - 第i个客户到达银行的时间w = w + wait(i); % 更新所有客户等待的总时间i = i + 1; % 增加一名新的客户x(i) = exprnd(10); % 这位新客户和上一个客户到达的时间间隔c(i) = c(i-1) + x(i); % 这位新客户到达银行的时间 = 上一个客户到达银行的时间 + 这位新客户和上一个客户到达的时间间隔b(i) = max(c(i),e(i-1)); % 这个新客户开始服务的时间取决于其到达时间和上一个客户结束服务的时间endn(k) = i-1; % n(k)表示银行第k天服务的客户人数t(k) = w/n(k); % t(k)表示该银行第k天客户的平均等待时间
end
disp([num2str(day),'个工作日中,银行每日平均服务的客户人数为: ',num2str(mean(n))])
disp([num2str(day),'个工作日中,银行每日客户的平均等待时间为: ',num2str(mean(t))])
toc %计算tic和toc中间部分的代码的运行时间
非线性约束问题
- 写出各个自变量的大致范围
- 用随机数模拟
- 找出符合条件的最大值


代码
%% 蒙特卡罗求解有约束的非线性规划问题
% max f(x) = x1*x2*x3
% s.t.
% (1) -x1+2*x2+2*x3>=0
% (2) x1+2*x2+2*x3<=72
% (3) x2<=20 & x2>=10
% (4) x1-x2 == 10%% (1)预备知识
% (1) format long g 可以将Matlab的计算结果显示为一般的长数字格式(默认会保留四位小数,或使用科学计数法)
5/7
5895*514100
format long g
5/7
5895*514100
% (2)unifrnd(a,b,m,n)可以输出在[a,b]之间均匀分布的随机数组成的m行n列的矩阵。(等价于 a + rand(m,n)*(b-a))
unifrnd(0,5,4,3)
% 4.07361843196589 3.16179623112705 4.78753417717149
% 4.5289596853781 0.487702024997048 4.82444267599638
% 0.63493408146753 1.39249109433524 0.788065408387741
% 4.5668792806951 2.73440759602492 4.85296390880308%% (2)代码部分
clc,clear;
tic %计算tic和toc中间部分的代码的运行时间
n=10000000; %生成的随机数组数
x1=unifrnd(20,30,n,1); % 生成在[20,30]之间均匀分布的随机数组成的n行1列的向量构成x1
x2=x1 - 10;
x3=unifrnd(-10,16,n,1); % 生成在[-10,16]之间均匀分布的随机数组成的n行1列的向量构成x3
fmax=-inf; % 初始化函数f的最大值为负无穷(后续只要找到一个比它大的我们就对其更新)
for i=1:nx = [x1(i), x2(i), x3(i)]; %构造x向量, 这里千万别写成了:x =[x1, x2, x3]if (-x(1)+2*x(2)+2*x(3)>=0) & (x(1)+2*x(2)+2*x(3)<=72) % 判断是否满足条件result = x(1)*x(2)*x(3); % 如果满足条件就计算函数值if result > fmax % 如果这个函数值大于我们之前计算出来的最大值fmax = result; % 那么就更新这个函数值为新的最大值X = x; % 并且将此时的x1 x2 x3保存到一个变量中endend
end
disp(strcat('蒙特卡罗模拟得到的最大值为',num2str(fmax)))
disp('最大值处x1 x2 x3的取值为:')
disp(X)
toc %计算tic和toc中间部分的代码的运行时间%% (3)缩小范围重新模拟得到更加精确的取值
clc,clear;
tic %计算tic和toc中间部分的代码的运行时间
n=10000000; %生成的随机数组数
x1=unifrnd(22,23,n,1); % 生成在[22,23]之间均匀分布的随机数组成的n行1列的向量构成x1
x2=x1 - 10;
x3=unifrnd(11,13,n,1); % 生成在[11,13]之间均匀分布的随机数组成的n行1列的向量构成x3
fmax=-inf; % 初始化函数f的最大值为负无穷(后续只要找到一个比它大的我们就对其更新)
for i=1:nx = [x1(i), x2(i), x3(i)]; %构造x向量, 这里千万别写成了:x =[x1, x2, x3]if (-x(1)+2*x(2)+2*x(3)>=0) & (x(1)+2*x(2)+2*x(3)<=72) % 判断是否满足条件result = x(1)*x(2)*x(3); % 如果满足条件就计算函数值if result > fmax % 如果这个函数值大于我们之前计算出来的最大值fmax = result; % 那么就更新这个函数值为新的最大值X = x; % 并且将此时的x1 x2 x3保存到一个变量中endend
end
disp(strcat('蒙特卡罗模拟得到的最大值为',num2str(fmax)))
disp('最大值处x1 x2 x3的取值为:')
disp(X)
toc %计算tic和toc中间部分的代码的运行时间

代码
%% 蒙特卡罗求解非线性规划问题
% min f(x) =2*(x1^2)+x2^2-x1*x2-8*x1-3*x2
% s.t.
% (1) 3*x1+x2>9
% (2) x1+2*x2<16
% (3) x1>0 & x2>0%% (1)初次寻找最小值的代码
clc,clear;
format long g %可以将Matlab的计算结果显示为一般的长数字格式(默认会保留四位小数,或使用科学计数法)
tic %计算tic和toc中间部分的代码的运行时间
n=10000000; %生成的随机数组数
x1=unifrnd(0,16,n,1); % 生成在[0,16]之间均匀分布的随机数组成的n行1列的向量构成x1
x2=unifrnd(0,8,n,1); % 生成在[0,8]之间均匀分布的随机数组成的n行1列的向量构成x2
fmin=+inf; % 初始化函数f的最小值为正无穷(后续只要找到一个比它小的我们就对其更新)
for i=1:nx = [x1(i), x2(i)]; %构造x向量, 这里千万别写成了:x =[x1, x2]if (3*x(1)+x(2)>9)&&(x(1)+2*x(2)<16) % 判断是否满足条件result = 2*(x(1)^2)+x(2)^2-x(1)*x(2)-8*x(1)-3*x(2); % 如果满足条件就计算函数值if result < fmin % 如果这个函数值小于我们之前计算出来的最小值fmin = result; % 那么就更新这个函数值为新的最小值X = x; % 并且将此时的x1 x2 保存到相应的变量中endend
end
disp(strcat('蒙特卡罗模拟得到的最小值为',num2str(fmin)))
disp('最小值处x1 x2的取值为:')
disp(X)
toc %计算tic和toc中间部分的代码的运行时间%% (2)缩小范围重新模拟得到更加精确的取值
clc,clear;
tic %计算tic和toc中间部分的代码的运行时间
n=10000000; %生成的随机数组数
x1=unifrnd(2,3,n,1); % 生成在[2,3]之间均匀分布的随机数组成的n行1列的向量构成x1
x2=unifrnd(2,3,n,1); % 生成在[2,3]之间均匀分布的随机数组成的n行1列的向量构成x2
fmin=+inf; % 初始化函数f的最小值为正无穷(后续只要找到一个比它小的我们就对其更新)
for i=1:nx = [x1(i), x2(i)]; %构造x向量, 这里千万别写成了:x =[x1, x2]if (3*x(1)+x(2)>9) & (x(1)+2*x(2)<16) % 判断是否满足条件result = 2*(x(1)^2)+x(2)^2-x(1)*x(2)-8*x(1)-3*x(2); % 如果满足条件就计算函数值if result < fmin % 如果这个函数值小于我们之前计算出来的最小值fmin = result; % 那么就更新这个函数值为新的最小值X = x; % 并且将此时的x1 x2 保存到相应的变量中endend
end
disp(strcat('蒙特卡罗模拟得到的最小值为',num2str(fmin)))
disp('最小值处x1 x2的取值为:')
disp(X)
toc %计算tic和toc中间部分的代码的运行时间
0-1规划问题
- 类似暴力搜索
- 当穷举次数远远大于模拟次数的时候,结果不正确
- 但是它比穷举法要稳定的多
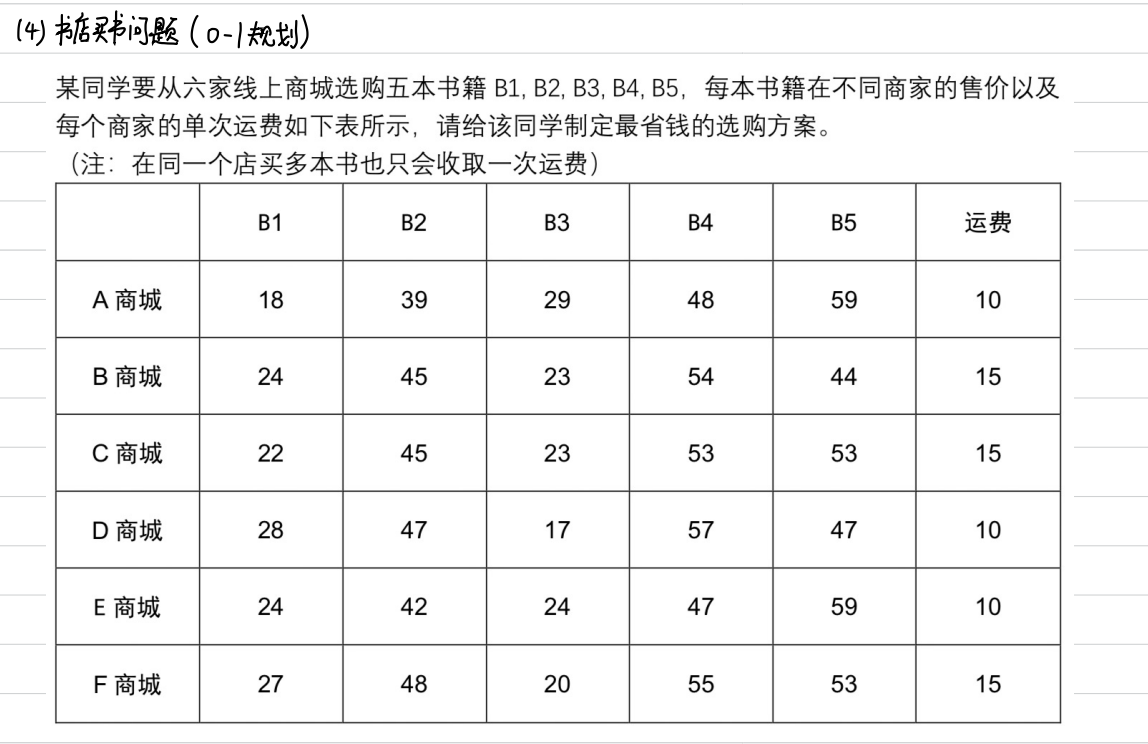

代码
%% 书店买书问题的蒙特卡罗的模拟
%% (1)预备知识
% (1)unique函数: 剔除一个矩阵或者向量的重复值,并将结果按照从小到大的顺序排列
% adj. 唯一的; 独一无二的 [ju'ni:k]
unique([1 2 5; 6 8 9;2 4 6])
unique([5 6 8 8 4 1 6 2 2 4 8 4 5 6])% (2)randi([a,b],m,n)函数可在指定区间[a,b]内随机取出大小为m*n的整数矩阵
randi([-5,5],2,6)%% (2)代码求解
min_money = +Inf; % 初始化最小的花费为无穷大,后续只要找到比它小的就更新
min_result = randi([1, 6],1,5); % 初始化五本书都在哪一家书店购买,后续我们不断对其更新
%若min_result = [5 3 6 2 3],则解释为:第1本书在第5家店买,第2本书在第3家店买,第3本书在第6家店买,第4本书在第2家店买,第5本书在第3家店买
n = 100000; % 蒙特卡罗模拟的次数
M = [18 39 29 48 5924 45 23 54 4422 45 23 53 5328 47 17 57 4724 42 24 47 5927 48 20 55 53]; % m_ij 第j本书在第i家店的售价
freight = [10 15 15 10 10 15]; % 第i家店的运费
for k = 1:n % 开始循环result = randi([1, 6],1,5); % 在1-6这些整数中随机抽取一个1*5的向量,表示这五本书分别在哪家书店购买index = unique(result); % 在哪些商店购买了商品,因为我们等下要计算运费money = sum(freight(index)); % 计算买书花费的运费% 计算总花费:刚刚计算出来的运费 + 五本书的售价for i = 1:5 money = money + M(result(i),i); endif money < min_money % 判断刚刚随机生成的这组数据的花费是否小于最小花费,如果小于的话min_money = money;% 我们更新最小的花费min_result = result; % 用这组数据更新最小花费的结果end
end
min_money % 18+39+48+17+47+20
min_result
导弹追踪问题
- 这类似一个差分模型
- 取时间间隔t趋近于0
- 当导弹与B船的距离小于某一值的(一般较小)时,认为它们已经相撞
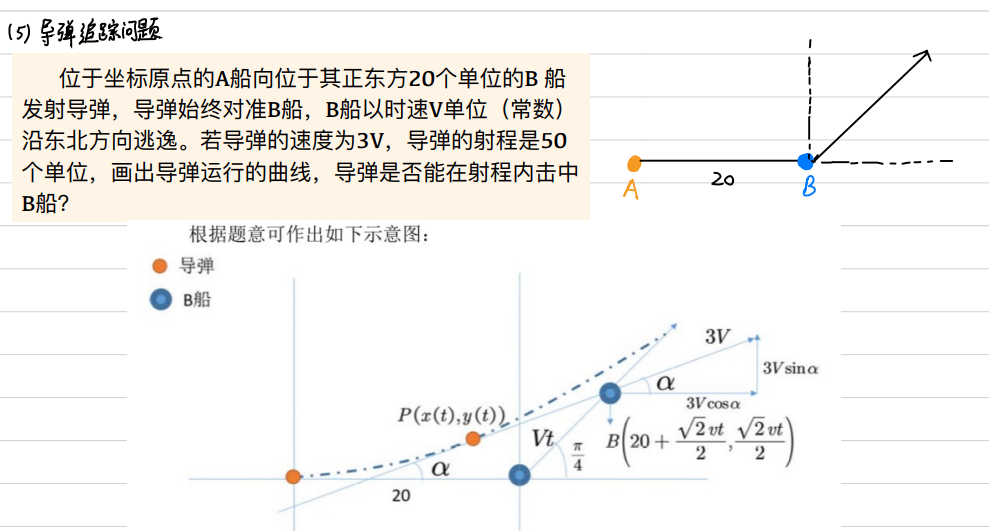
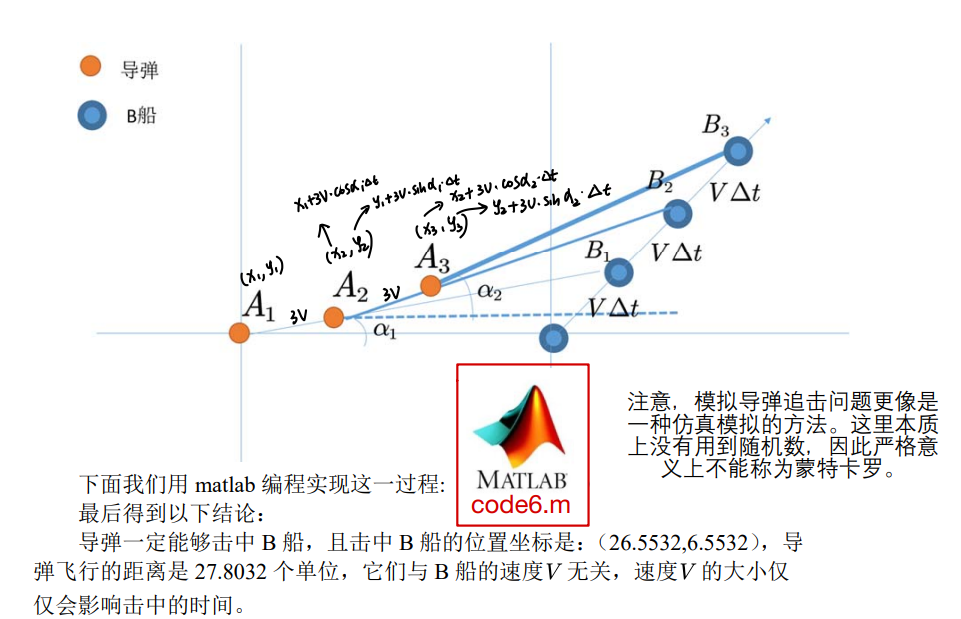
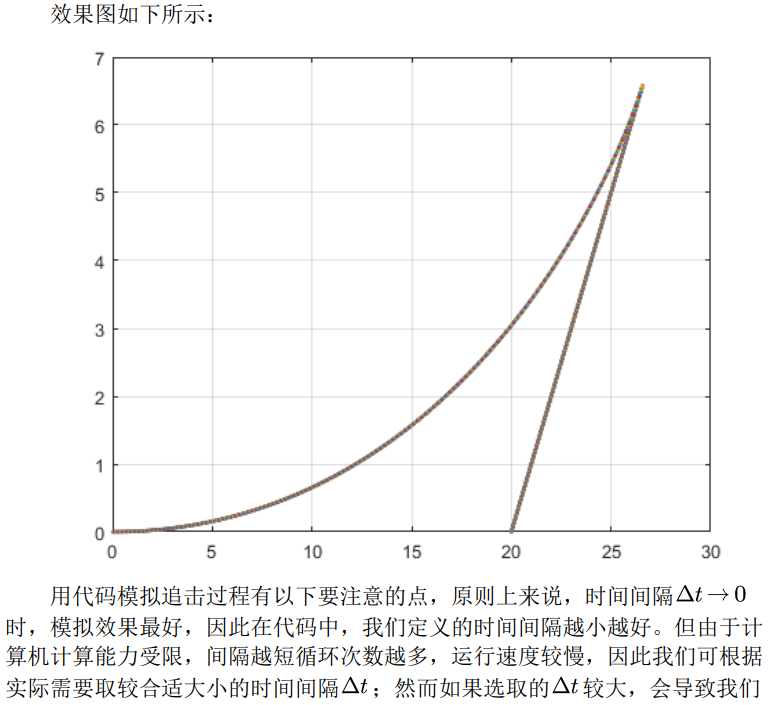
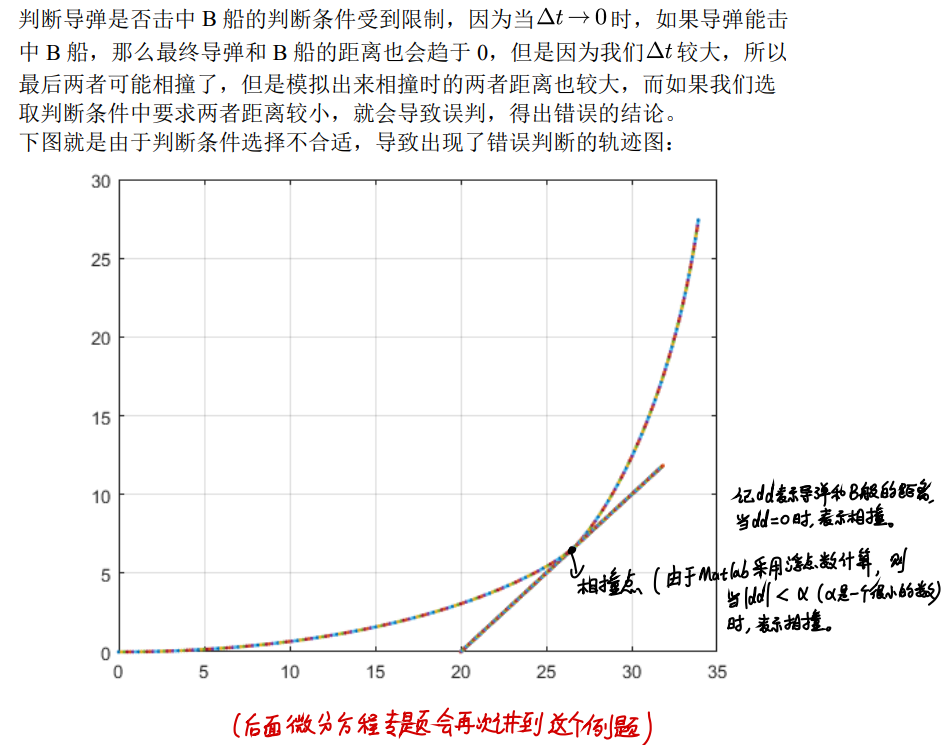
代码
%% 蒙特卡罗用于模拟导弹追击问题
% 注意,模拟导弹追击问题更像是一种仿真模拟的方法。这里本质上没有用到随机数,因此严格意义上不能称为蒙特卡罗。
clear;clc
%% (1)预备知识
% mod(m,n)表示求m/n的余数
mod(8,3)
mod(1000,50)% 设置横纵坐标的范围并标上字符
x = 1:0.01:3;
y = x .^ 2;
plot(x,y) % 画出x和y的图形
axis([0 3 0 10]) % 设置横坐标范围为[0, 3] 纵坐标范围为[0, 10]
pause(3) % 暂停3秒后再继续接下来的命令
text(2,4,'清风') % 在坐标为(2,4)的点上标上字符串:清风
close % 关闭图形窗口%% (2) 代码求解
% 1. 不画追击的示意图
clear;clc
v=200; % 任意给定B船的速度(后期我们可以再改的)
dt=0.0000001; % 定义时间间隔
x=[0,20]; % 定义导弹和B船的横坐标分别为x(1)和x(2)
y=[0,0]; % 定义导弹和B船的纵坐标分别为y(1)和y(2)
t=0; % 初始化导弹击落B船的时间
d=0; % 初始化导弹飞行的距离
m=sqrt(2)/2; % 将sqrt(2)/2定义为一个常量,使后面看起来很简洁
dd=sqrt((x(2)-x(1))^2+(y(2)-y(1))^2); % 导弹与B船的距离
while(dd>=0.001) % 只要两者的距离足够大,就一直循环下去。(两者距离足够小时表示导弹击中,这里的临界值要结合dt来取,否则可能导致错过交界处的情况)t=t+dt; % 更新导弹击落B船的时间d=d+3*v*dt; % 更新导弹飞行的距离x(2)=20+t*v*m; y(2)=t*v*m; % 计算新的B船的位置 (注:m=sqrt(2)/2)dd=sqrt((x(2)-x(1))^2+(y(2)-y(1))^2); % 更新导弹与B船的距离tan_alpha=(y(2)-y(1))/(x(2)-x(1)); % 计算斜率,即tan(α)cos_alpha=sqrt(1/(1+tan_alpha^2)); % sec(α)^2 = (1+tan(α)^2)sin_alpha=sqrt(1-cos_alpha^2); % sin(α)^2 +cos(α)^2 = 1x(1)=x(1)+3*v*dt*cos_alpha; y(1)=y(1)+3*v*dt*sin_alpha; % 计算新的导弹的位置if d>50 % 导弹的有效射程为50个单位disp('导弹没有击中B船');break; % 退出循环endif d<=50 & dd<0.001 % 导弹飞行的距离小于50个单位且导弹和B船的距离小于0.001(表示击中)disp(['导弹飞行',num2str(d),'单位后击中B船'])disp(['导弹飞行的时间为',num2str(t*60),'分钟'])end
end%% 2. 画追击的示意图
clear;clc
v=200; % 任意给定B船的速度(后期我们可以再改的)
dt=0.0000001; % 定义时间间隔
x=[0,20]; % 定义导弹和B船的横坐标分别为x(1)和x(2)
y=[0,0]; % 定义导弹和B船的纵坐标分别为y(1)和y(2)
t=0; % 初始化导弹击落B船的时间
d=0; % 初始化导弹飞行的距离
m=sqrt(2)/2; % 将sqrt(2)/2定义为一个常量,使后面看起来很简洁
dd=sqrt((x(2)-x(1))^2+(y(2)-y(1))^2); % 导弹与B船的距离
for i=1:2plot(x(i),y(i),'.k','MarkerSize',1); % 画出导弹和B船所在的坐标,点的大小为1,颜色为黑色(k),用小点表示grid on; % 打开网格线hold on; % 不关闭图形,继续画图
end
axis([0 30 0 10]) % 固定x轴的范围为0-30 固定y轴的范围为0-10
k = 0; % 引入一个变量 为了控制画图的速度(因为Matlab中画图的速度超级慢)
while(dd>=0.001) % 只要两者的距离足够大,就一直循环下去。(两者距离足够小时表示导弹击中,这里的临界值要结合dt来取,否则可能导致错过交界处的情况)t=t+dt; % 更新导弹击落B船的时间d=d+3*v*dt; % 更新导弹飞行的距离x(2)=20+t*v*m; y(2)=t*v*m; % 计算新的B船的位置 (注:m=sqrt(2)/2)dd=sqrt((x(2)-x(1))^2+(y(2)-y(1))^2); % 更新导弹与B船的距离tan_alpha=(y(2)-y(1))/(x(2)-x(1)); % 计算斜率,即tan(α)cos_alpha=sqrt(1/(1+tan_alpha^2)); % 利用公式:sec(α)^2 = (1+tan(α)^2) 计算出cos(α)sin_alpha=sqrt(1-cos_alpha^2); % 利用公式: sin(α)^2 +cos(α)^2 = 1 计算出sin(α)x(1)=x(1)+3*v*dt*cos_alpha; y(1)=y(1)+3*v*dt*sin_alpha; % 计算新的导弹的位置k = k +1 ; if mod(k,500) == 0 % 每刷新500次时间就画出下一个导弹和B船所在的坐标 mod(m,n)表示求m/n的余数for i=1:2plot(x(i),y(i),'.k','MarkerSize',1);hold on; % 不关闭图形,继续画图endpause(0.001); % 暂停0.001s后再继续下面的操作endif d>50 % 导弹的有效射程为50个单位disp('导弹没有击中B船');break; % 退出循环endif d<=50 & dd<0.001 % 导弹飞行的距离小于50个单位且导弹和B船的距离小于0.001(表示击中)disp(['导弹飞行',num2str(d),'个单位后击中B船'])disp(['导弹飞行的时间为',num2str(t*60),'分钟'])end
end
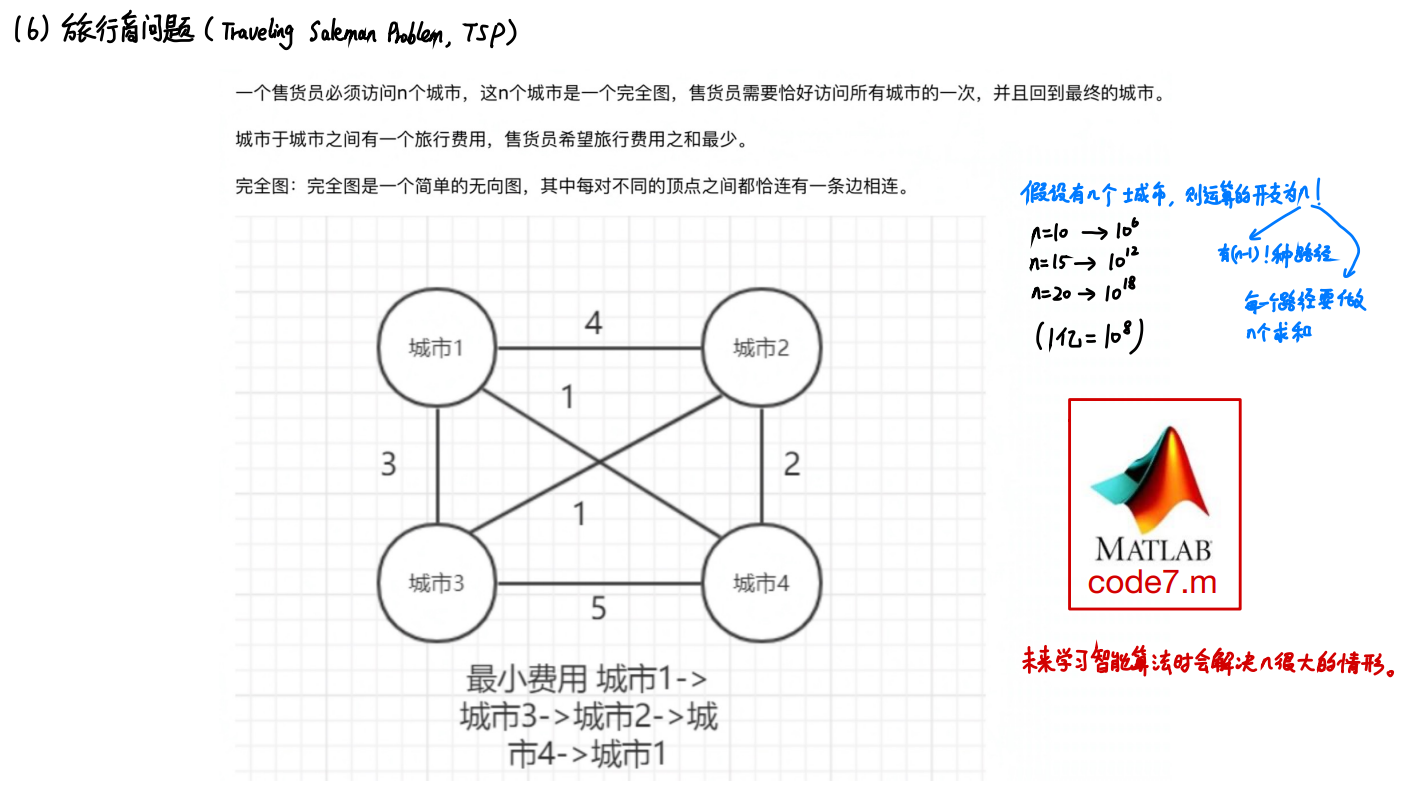
旅行商问题
- 当地点过多时(大于15)蒙特卡洛模拟将很难得到比较好的结果
- 在这种情况下,智能算法更加适用问题的求解
代码
%% TSP(旅行商问题)
% (1)预备知识
plot([1,2],[5,10],'-o') % 画出一条线段,x范围是[1, 2] ,y范围是[5,10]
text(1.5,7.5,'清风') % 在坐标(1.5,7.5)处标上文本:清风
close% randperm函数的用法
randperm(5) % 生成1-5组成的一个随机序列(类似于洗牌的操作)
% 3 5 1 2 4
% 1 4 5 3 2%% (2)代码求解
clear;clc
% 只有10个城市的简单情况
coord =[0.6683 0.6195 0.4 0.2439 0.1707 0.2293 0.5171 0.8732 0.6878 0.8488 ;0.2536 0.2634 0.4439 0.1463 0.2293 0.761 0.9414 0.6536 0.5219 0.3609]' ; % 城市坐标矩阵,n行2列
% 38个城市,TSP数据集网站(http://www.tsp.gatech.edu/world/djtour.html) 上公测的最优结果6656。% coord = [11003.611100,42102.500000;11108.611100,42373.888900;11133.333300,42885.833300;11155.833300,42712.500000;11183.333300,42933.333300;11297.500000,42853.333300;11310.277800,42929.444400;11416.666700,42983.333300;11423.888900,43000.277800;11438.333300,42057.222200;11461.111100,43252.777800;11485.555600,43187.222200;11503.055600,42855.277800;11511.388900,42106.388900;11522.222200,42841.944400;11569.444400,43136.666700;11583.333300,43150.000000;11595.000000,43148.055600;11600.000000,43150.000000;11690.555600,42686.666700;11715.833300,41836.111100;11751.111100,42814.444400;11770.277800,42651.944400;11785.277800,42884.444400;11822.777800,42673.611100;11846.944400,42660.555600;11963.055600,43290.555600;11973.055600,43026.111100;12058.333300,42195.555600;12149.444400,42477.500000;12286.944400,43355.555600;12300.000000,42433.333300;12355.833300,43156.388900;12363.333300,43189.166700;12372.777800,42711.388900;12386.666700,43334.722200;12421.666700,42895.555600;12645.000000,42973.333300];n = size(coord,1); % 城市的数目figure(1) % 新建一个编号为1的图形窗口
plot(coord(:,1),coord(:,2),'o'); % 画出城市的分布散点图
for i = 1:ntext(coord(i,1)+0.01,coord(i,2)+0.01,num2str(i)) % 在图上标上城市的编号(加上0.01表示把文字的标记往右上方偏移一点)
end
hold on % 等一下要接着在这个图形上画图的d = zeros(n); % 初始化两个城市的距离矩阵全为0
for i = 2:n for j = 1:i coord_i = coord(i,:); x_i = coord_i(1); y_i = coord_i(2); % 城市i的横坐标为x_i,纵坐标为y_icoord_j = coord(j,:); x_j = coord_j(1); y_j = coord_j(2); % 城市j的横坐标为x_j,纵坐标为y_jd(i,j) = sqrt((x_i-x_j)^2 + (y_i-y_j)^2); % 计算城市i和j的距离end
end
d = d+d'; % 生成距离矩阵的对称的一面min_result = +inf; % 假设最短的距离为min_result,初始化为无穷大,后面只要找到比它小的就对其更新
min_path = [1:n]; % 初始化最短的路径就是1-2-3-...-n
N = 10000000; % 蒙特卡罗模拟的次数
for k = 1:N % 开始循环result = 0; % 初始化走过的路程为0path = randperm(n); % 生成一个1-n的随机打乱的序列for i = 1:n-1 result = d(path(i),path(i+1)) + result; % 按照这个序列不断的更新走过的路程这个值endresult = d(path(1),path(n)) + result; % 别忘了加上从最后一个城市返回到最开始那个城市的距离if result < min_result % 判断这次模拟走过的距离是否小于最短的距离,如果小于就更新最短距离和最短的路径min_path = path;min_result = result;end
end
min_path
min_path = [min_path,min_path(1)]; % 在最短路径的最后面加上一个元素,即第一个点(我们要生成一个封闭的图形)
n = n+1; % 城市的个数加一个(紧随着上一步)
for i = 1:n-1 j = i+1;coord_i = coord(min_path(i),:); x_i = coord_i(1); y_i = coord_i(2); coord_j = coord(min_path(j),:); x_j = coord_j(1); y_j = coord_j(2);plot([x_i,x_j],[y_i,y_j],'-') % 每两个点就作出一条线段,直到所有的城市都走完pause(0.5) % 暂停0.5s再画下一条线段hold on
end
估计自然常数
代码
%% 作业参考答案:蒙特卡罗的方法去估计自然常数e
%% (1)预备知识
% (1)randperm函数的用法
randperm(5) % 生成1-5组成的一个随机序列
% 3 5 1 2 4
% 1 4 5 3 2% (2)find函数的用法 (第一期视频第一讲)
% 假设a是一个向量,那么find(a)可以用来返回这个向量中非零元素的下标,如果a中所有元素都为0,则返回空值
find([1,5,6,0,8,0,-5]) % 1 2 3 5 7
find([0,0,0,0,0]) % 空的 1×0 double 行矢量% (3) 矩阵(或向量)和常量的比较运算可返回逻辑矩阵(或向量)(元素全为0和1)
[1,5,6,0,8,0,-5] > 0 % 1 1 1 0 1 0 0
[1,5,6,0,8,0,-5] == 0 % 0 0 0 1 0 1 0% (4) isempty(A)函数可以用来判断A是否为空, 如果A为空, isempty(A) 返回逻辑值1(true),否则返回逻辑值0(false)。
isempty(find([0,0,0,0,0])) % 1
isempty(find([0,1,0,0,0])) % 0
isempty([0,0,0,0,0]) % 注意,别搞错啦,它不是空矩阵(空矩阵是指里面没有元素)%% (2)参考答案
clear;clc
tic %计算tic和toc中间部分的代码的运行时间
n = 1000000; % 蒙特卡洛的次数(理论上n取得越大,计算出来的结果越精确)
m = 0; % 每个人拿到的都不是自己卡片的次数(频数)
people = 100; % 假设一共有100个人玩这个游戏 (任给的)
for i = 1: n % 开始循环if isempty(find(randperm(people) - [1:people] == 0)) % 如果每个人拿到的都不是自己的卡片m = m + 1; % 那么次数就加1end
end
frequency = m / n; % 每个人拿到的都不是自己卡片的频率(概率)
disp(['自然常数e的蒙特卡罗模拟值为:', num2str(1 / frequency)]) % 注:自然常数真实值约为2.7182
toc %计算tic和toc中间部分的代码的运行时间
武器升级

代码
%% 蒙特卡罗解决武器升级问题
% 现在有一把神器,初始为1级,可免费领取(即价值为0),可花费金币对其升级,每次10000金币,最多升到5级。
% 给定一个升级的概率表(见讲义),问:5级神器价值多少金币?(即升级到5级神器平均的花费)%% (1)预备知识
% 以一定的概率产生随机数 randsrc(m,n,[alphabet; prob])
% m和n表示生成的随机数矩阵的行数和列数
% alphabet表示需要产生的随机数的数字,用一个行向量表示
% prob表示这些数字出现的概率大小,用一个行向量表示,向量长度和alphabet向量要完全相同, 且这些概率的和要为1
% 比如:要产生1、4、 6这三个数。它们分别出现的概率为 0.1、0.2、0.7,如何设计程序使得按照这个概率产生10个随机数呢?
alphabet = [1 4 6]; prob = [0.1 0.2 0.7];
randsrc(10,1,[alphabet; prob])%% (2)参考答案
% clear;clc
tic %计算tic和toc中间部分的代码的运行时间
% 升级的成功率储存在success矩阵中,以第一行和第三行为例,表格的解释:
% 1级武器强化时,有20%概率升到2级,10%概率升到3级,5%概率升到4级,65%概率不变。
% 3级武器强化时,10%概率跌到1级,20%概率跌到2级,20%概率升到4级,10%概率升到5级
success = [0.65 0.2 0.1 0.05 0;0.25 0.4 0.2 0.1 0.05;0.1 0.2 0.4 0.2 0.1;0 0.1 0.3 0.4 0.2] ;
n = 10000; % 蒙特卡罗模拟的次数
MONEY = zeros(n,1); % 初始化用来存储每次蒙特卡罗计算出来的表示强化费用的向量
for i = 1:nrank = 1; % 武器的初始等级money = 0; %花费的钱数,初始化为0alphabet = [1 2 3 4 5]; % 用来表示五个等级while rank ~= 5 % 只要等级不是5级, 就一直循环下去prob =success(rank,:); % 令生成随机数的概率为第rank行rank = randsrc(1,1,[alphabet; prob]); % 生成一个在1-5中的随机数,表示强化后的等级money = money + 10000; % 更新强化的费用endMONEY(i) = money; % 将这次蒙特卡罗的结果保存到MONEY向量中
end
disp(['将武器升级到5级的平均花费为:',num2str(mean(MONEY))])
toc %计算tic和toc中间部分的代码的运行时间
选择决策方案模拟(换灯泡问题)
代码
%% 选择决策方案的模拟
% 某设备上安装有四只型号规格完全相同的电子管,已知电子管寿命为1000--2000小时之间的均匀分布(假定为整数)。
% 当电子管损坏时有两种维修方案,一是每次更换损坏的那一只;二是当其中一只损坏时四只同时更换。
% 已知更换时间为换一只时需1小时,4只同时换为2小时。
% 更换时机器因停止运转每小时的损失为20元,又每只电子管价格10元,
% 试用模拟方法决定哪一个方案经济合理?%% (1)预备知识
% randi([a,b],m,n) 随机生成m*n的矩阵,矩阵中的每个元素都是[a,b]中的随机整数
randi([1, 5],3,2)
randi([1, 5]) % 不写m*n代表只生成1个随机数% find函数的用法
% find函数的用法在第一期视频:层次分析法那一节讲过,我们当时找最大特征值的位置
a = [2 3 5 1 7 5];
find(a) % 找到a中所有非0元素的位置
find(a == 5) % 找到a中等于5的元素的位置
find(a == 5,1) % 找到a中第一个等于5的元素的位置
find(a == min(a)) % 找到a中最小元素的位置%% (2)代码部分
clear;clc
T = 100000000; % T表示模拟的总时间(单位为小时)
t = 0; % 初始化当前时刻为0小时
c1 = 0; c2 = 0; % 初始化两种方案的总花费都为0%% 方案一
life = randi([1000,2000],1,4); % 随机生成四个电子管的寿命,假设为整数
while t < T % 只要现在的时刻没有超过总时刻,就不断循环下去result = min(life); % 找出寿命最短的那一个电子管的寿命t = t+result+1; % 现在的时间更改到有电子管损坏的时刻(加上1表示更换电子管需要花费的时间)c1 = c1 + 20 * 1 +10; % 更新方案一的花费 k = find(life == result,1); % 找到哪一个电子管是坏的life = life - result -1; % 更新所有电子管的寿命(这里不减去1也是可以的,减少了1也无所谓,对结果的影响很小) life(k) = randi([1000,2000]); % 把坏掉的那个电子管的寿命重置
end%% 方案二
t = 0; % 初始化当前时刻为0小时
while t < T % 只要现在的时刻没有超过总时刻,就不断循环下去life = randi([1000,2000],1,4); % 随机生成四个电子管的寿命,假设为整数result = min(life); % 找出寿命最小的那一个电子管的寿命t = t+result+2; % 现在的时间更改到有电子管损坏的时刻(加上2表示更换所有电子管需要花费的时间)c2 =c2 + 20 * 2 +40; % 更新方案二的花费
end%% 两种方案的花费
c1
c2




![SQLSTATE[42S22]: Column not found: 1054 Unknown column Color in field list](https://img2024.cnblogs.com/blog/1295962/202407/1295962-20240717124854088-281169181.jpg)