吴恩达大模型教程笔记(七)
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P29:5——基于文档的问答 - 吴恩达大模型 - BV1gLeueWE5N

人们构建的最常见复杂应用之一。

使用llm是一个可回答文档内或关于文档问题的系统,给定一段文本可能来自PDF文件或网页,或公司内部文档库,你能用nlm回答关于这些文档内容的问题吗,帮助用户深入了解并获取所需信息,这非常强大。
因为它开始将语言模型与它们未受过训练的数据结合起来,这使得它们更加灵活和适应您的用例,这也非常令人兴奋,因为我们将开始超越语言模型,提示和输出解析器,并开始引入链接链的一些关键组件。
如嵌入模型和向量存储,如安德鲁提到的,这是我们拥有的最受欢迎的链之一,所以,我希望你兴奋,实际上,嵌入和向量存储是现代最强大的技术之一,所以如果你还没有见过它们,它们非常值得学习,那么让我们深入。
让我们开始,我们将开始导入环境变量,我们现在总是这样做。

我们将导入一些在构建此链时将帮助我们,我们将导入检索qa链,这将对一些文档进行检索,或导入,我们最喜欢的聊天openai语言模型,我们将导入一个文档加载器,这将用于加载一些专有数据。
我们将与语言模型结合,在这种情况下,它将在csv中,因此我们将导入csv加载器,最后我们将导入一个向量存储,有许多不同类型的向量存储,我们稍后将涵盖它们的确切含义。

但我们将从docker ray内存搜索向量存储开始,这真的很棒,因为它是一个内存向量存储。

并且不需要连接到任何外部数据库,这使得它非常容易开始,我们还将导入。

显示和markdown,用于在jupyter笔记本中显示信息的常用工具,我们提供了一个户外服装的csv,我们将与语言模型结合,在这里我们将初始化一个加载器。

使用此文件的路径初始化csv加载器,接下来我们将导入一个索引。

向量存储索引创建器。

这将帮助我们非常容易地创建一个向量存储,我们将导入,显示和markdown,用于在jupyter笔记本中显示信息的常用工具,如下面所示,只需几行代码即可创建,创建它,我们将指定两件事,首先。
我们将指定向量存储类,如前所述。

我们将使用此向量存储,因为它特别容易入门。

创建后,我将从加载器调用,接受文档加载器列表。

我们只关心一个加载器,这就是传入的内容。

现已创建,可开始提问。

将解释内部发生了什么,现在别担心这个。

现在从查询开始,使用索引查询创建响应,再次传入查询。


现在先不解释内部情况。

等待响应,完成后。

现在可查看返回内容,返回Markdown表格,含防晒衬衫名和描述,语言模型提供小结。

已过文档问答方法,但内部究竟如何?

先思考总体思路,想用语言模型结合文档,存在关键问题,语言模型一次只能检查几千个单词。

所以如果我们有非常大的文档,如何让语言模型回答文档中所有内容的问题,这时嵌入和向量存储开始发挥作用。

让我们谈谈嵌入,嵌入,为文本片段创建数值表示。

该数值表示捕获了文本片段的语义含义,它已被运行过,具有相似内容的文本片段,将有相似向量,这让我们能在向量空间比较文本片段,在示例下,我们有3个句子,前两个关于宠物很好。

第三个关于汽车,若看数值空间表示,当我们比较文本片段的2个向量,对应于关于宠物的句子。
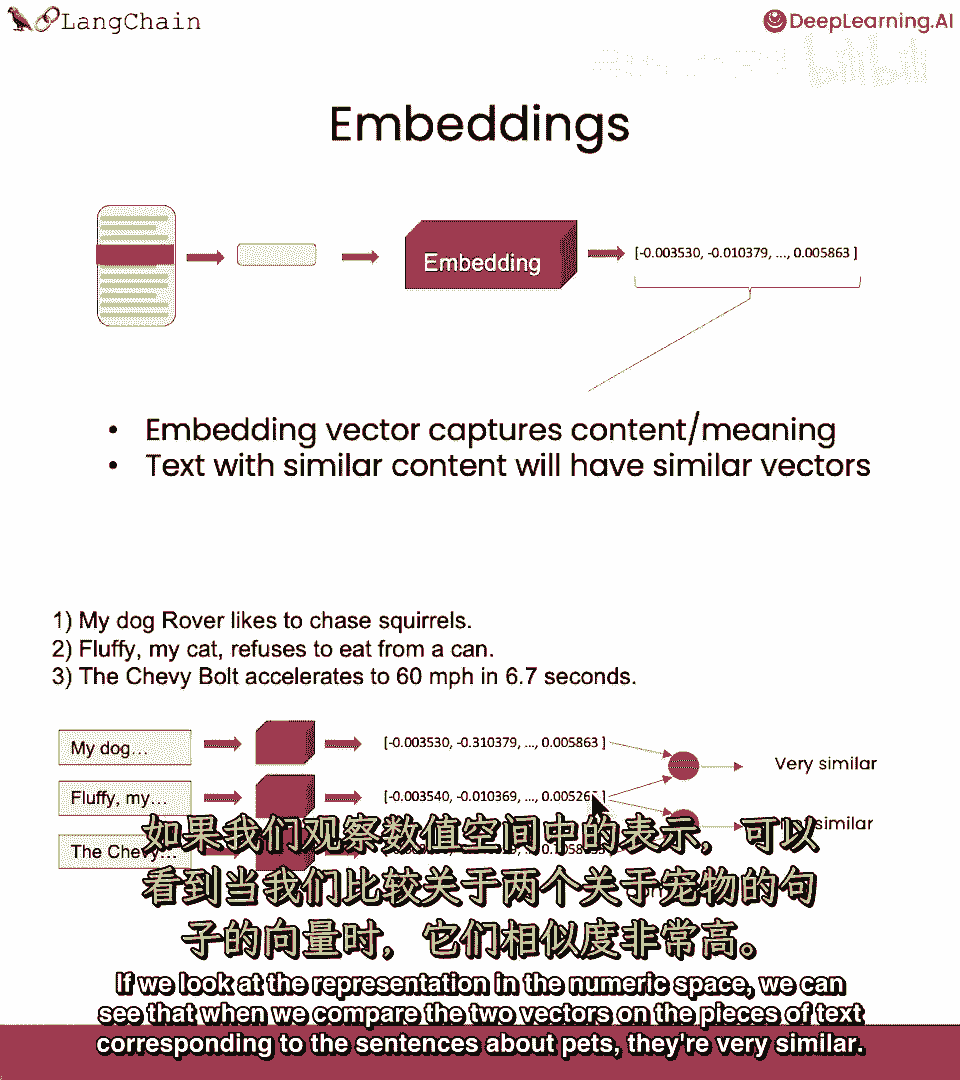
它们非常相似很好,若与谈论汽车的相比。
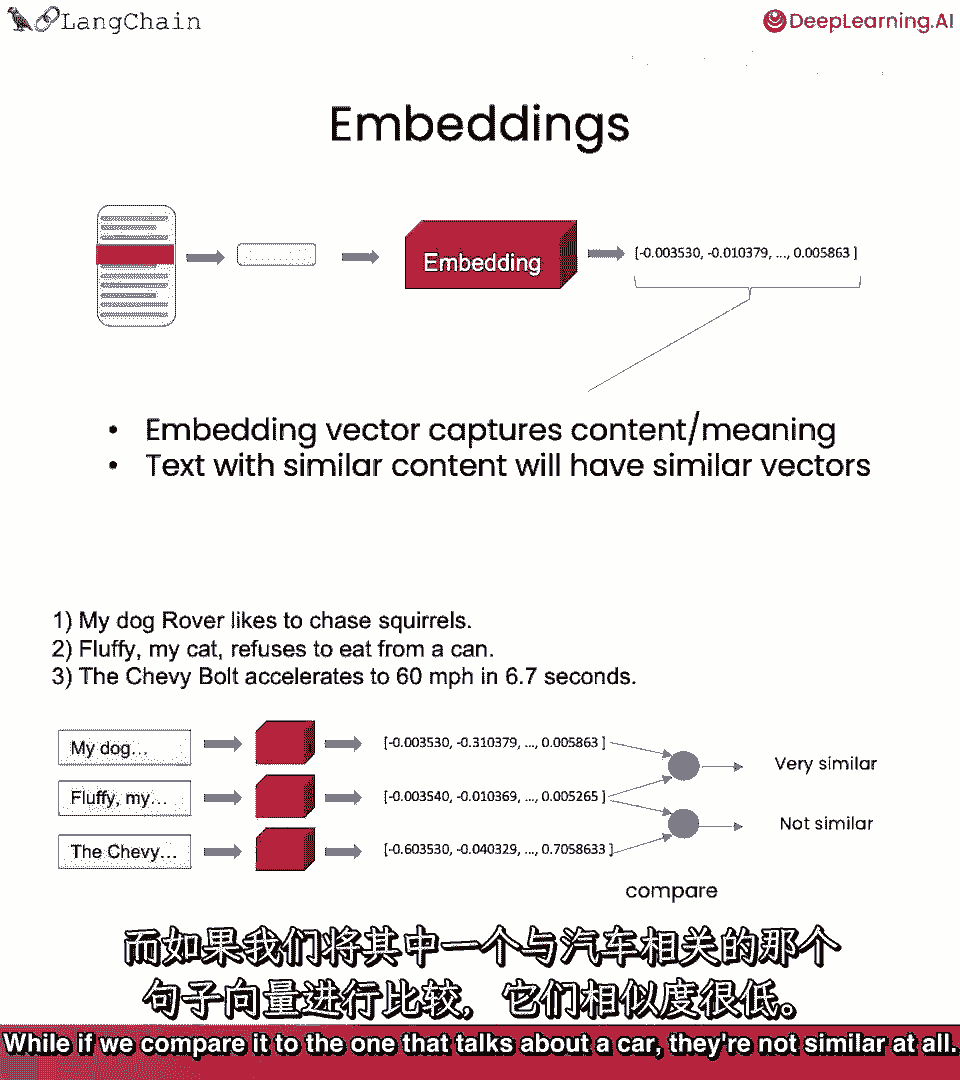
它们完全不同,这将使我们容易找出哪些文本相似。
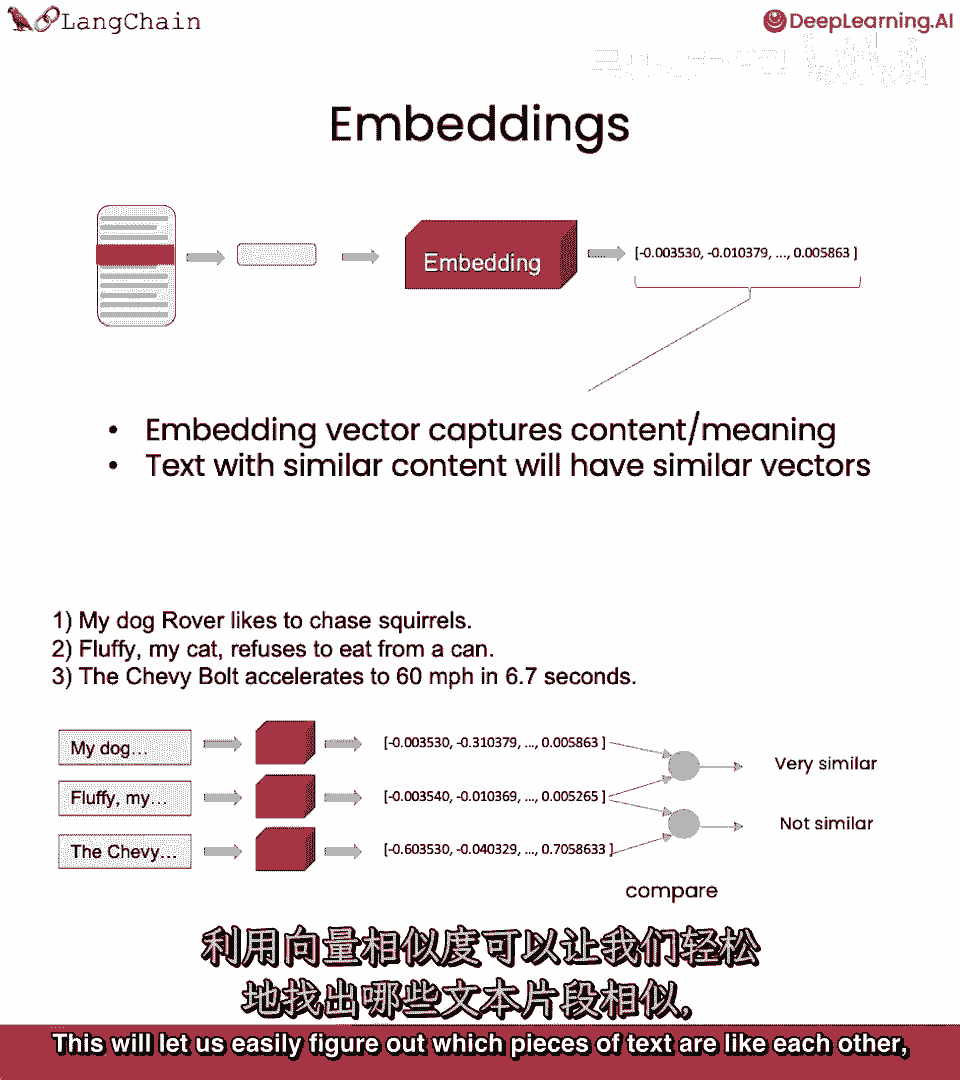
这将非常有用,因为我们考虑包含哪些文本。

当传递给语言模型回答问题时,接下来要讲的组件是向量数据库。
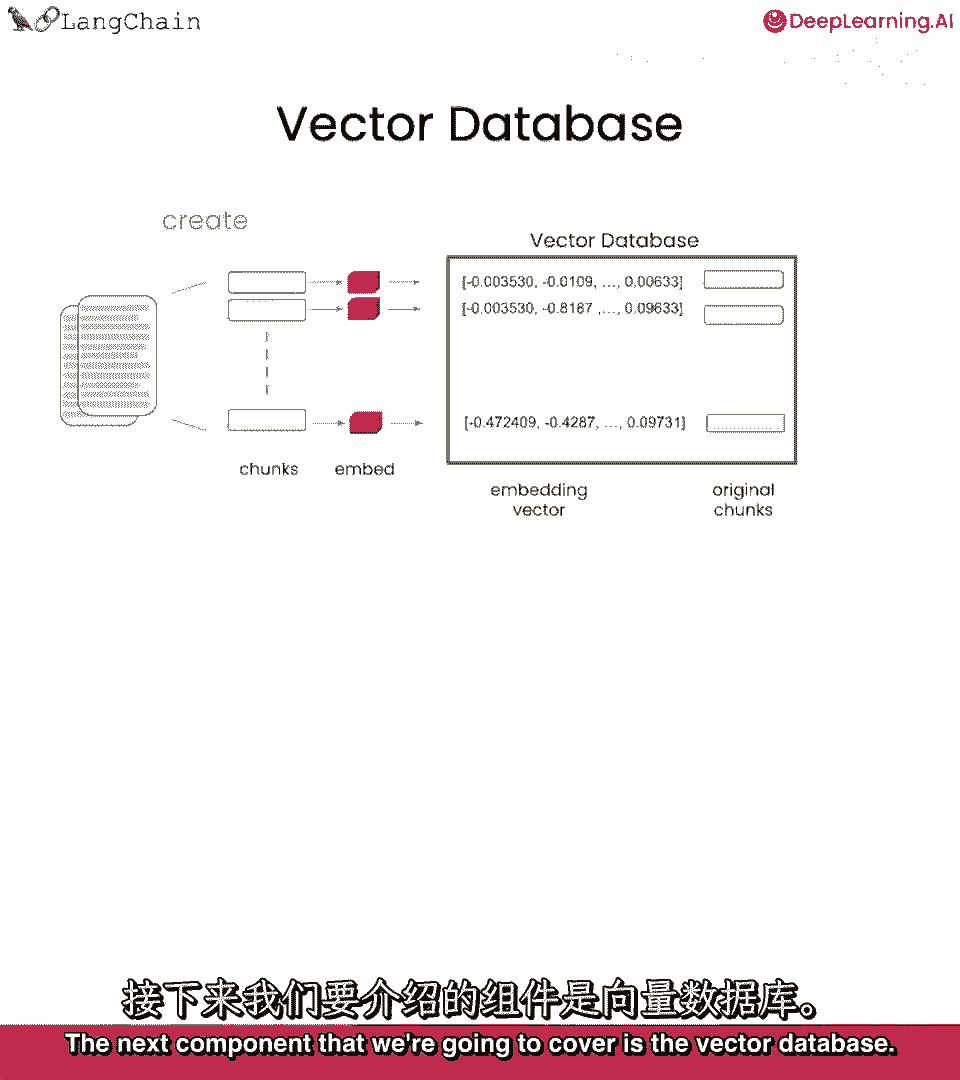
向量数据库是存储之前步骤中创建的向量表示的一种方式。
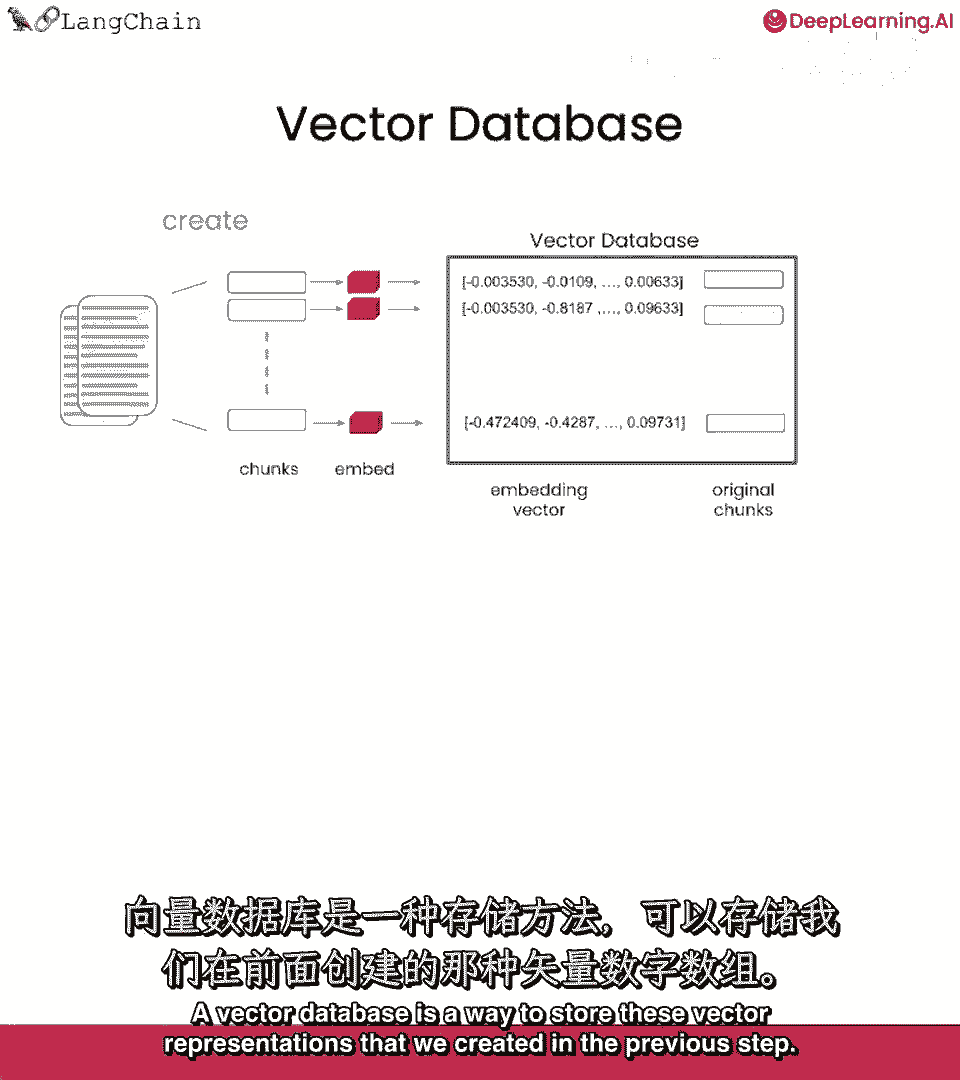
我们创建向量数据库的方式是。
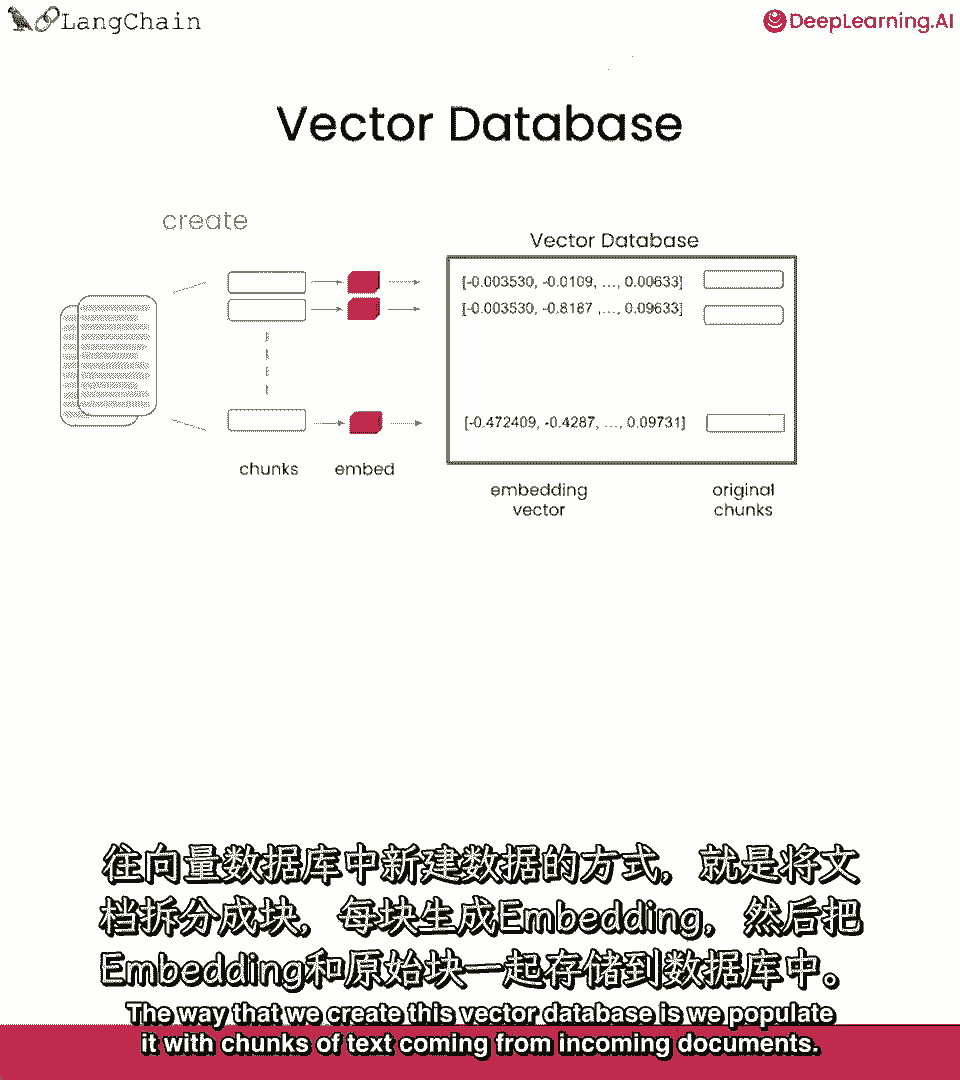
用来自入站文档的文本块填充它,当我们得到一个大的入站文档时,我们首先将其拆分为较小的块,这有助于创建比原始文档更小的文本块,这很有用,因为我们可能无法将整个文档传递给语言模型。
因此,我们想创建这些小块,以便我们只能将最相关的传递给语言模型。
然后,我们为这些块创建嵌入。
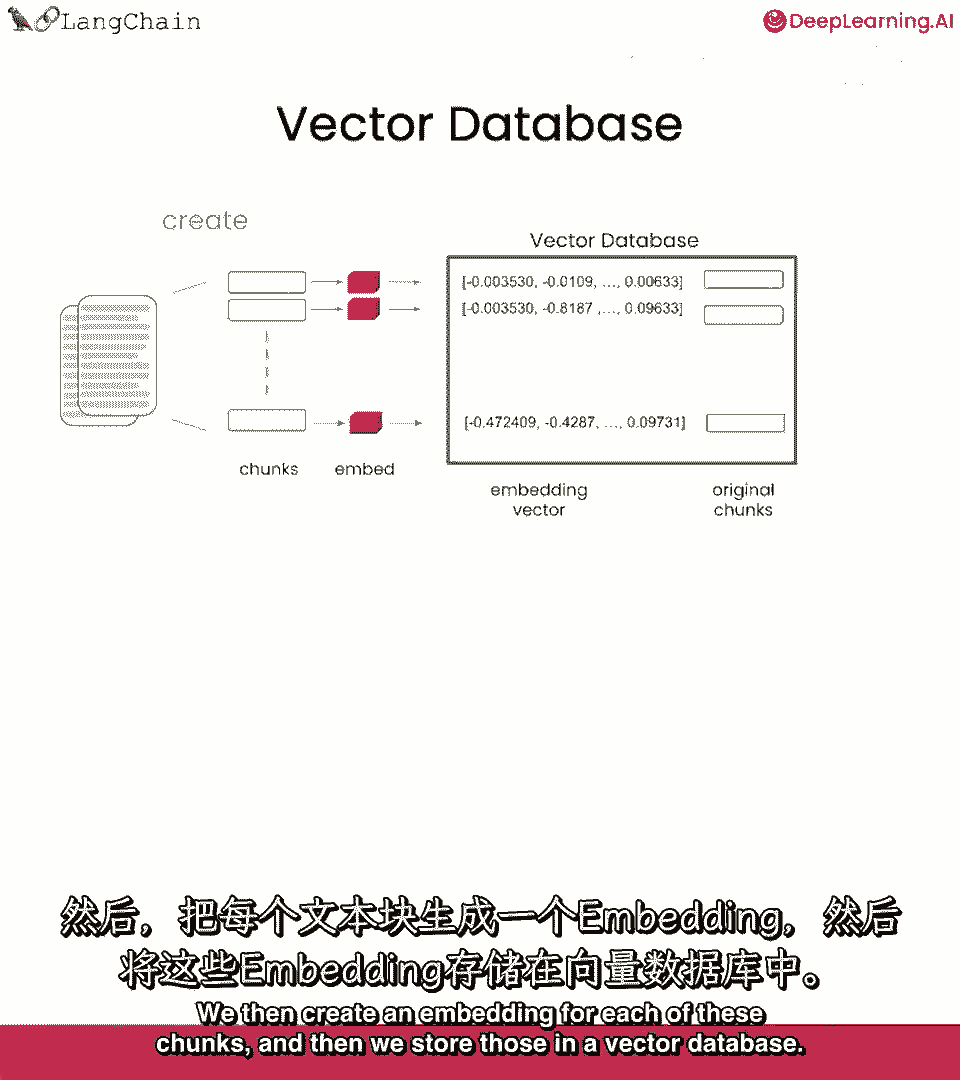
然后将它们存储在向量数据库中,这就是创建索引时发生的情况。
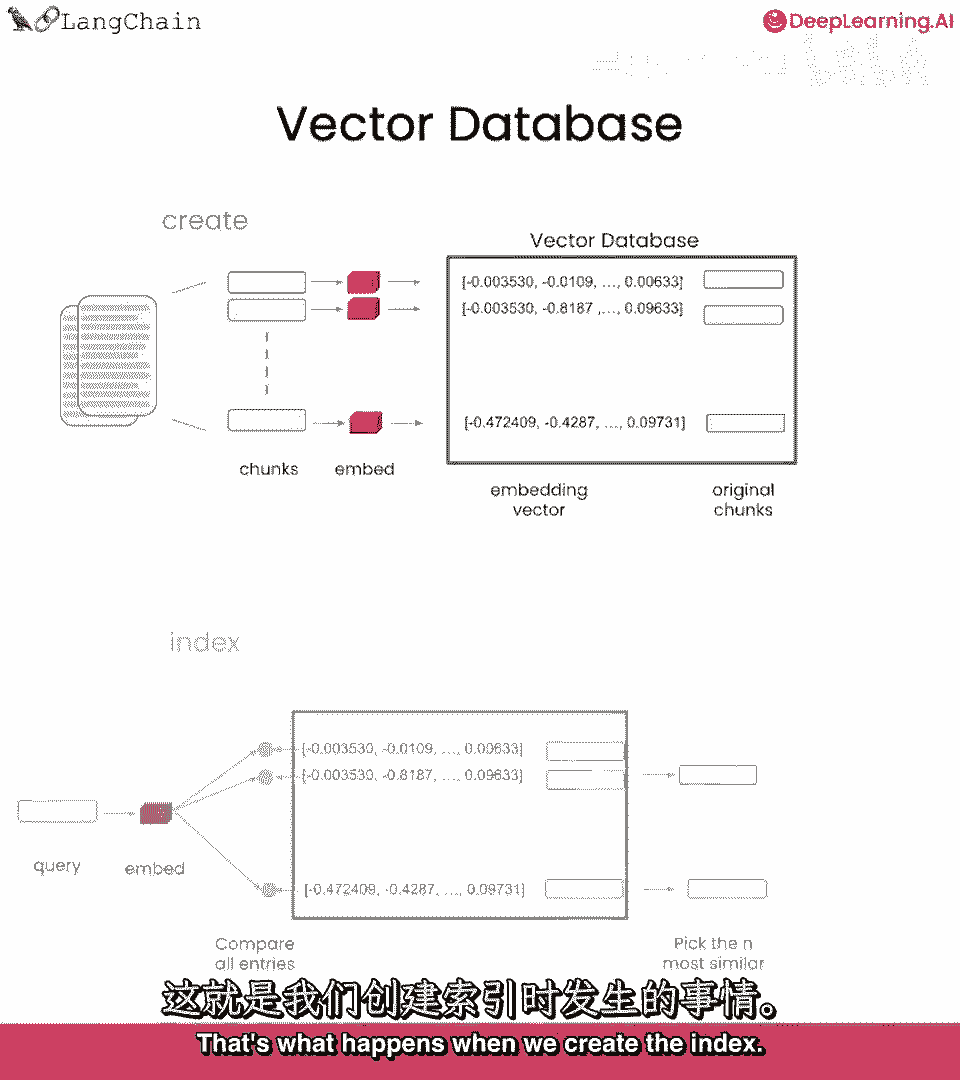
现在我们已经有了这个索引,我们可以在运行时使用它,找到与入站查询最相关的文本块。
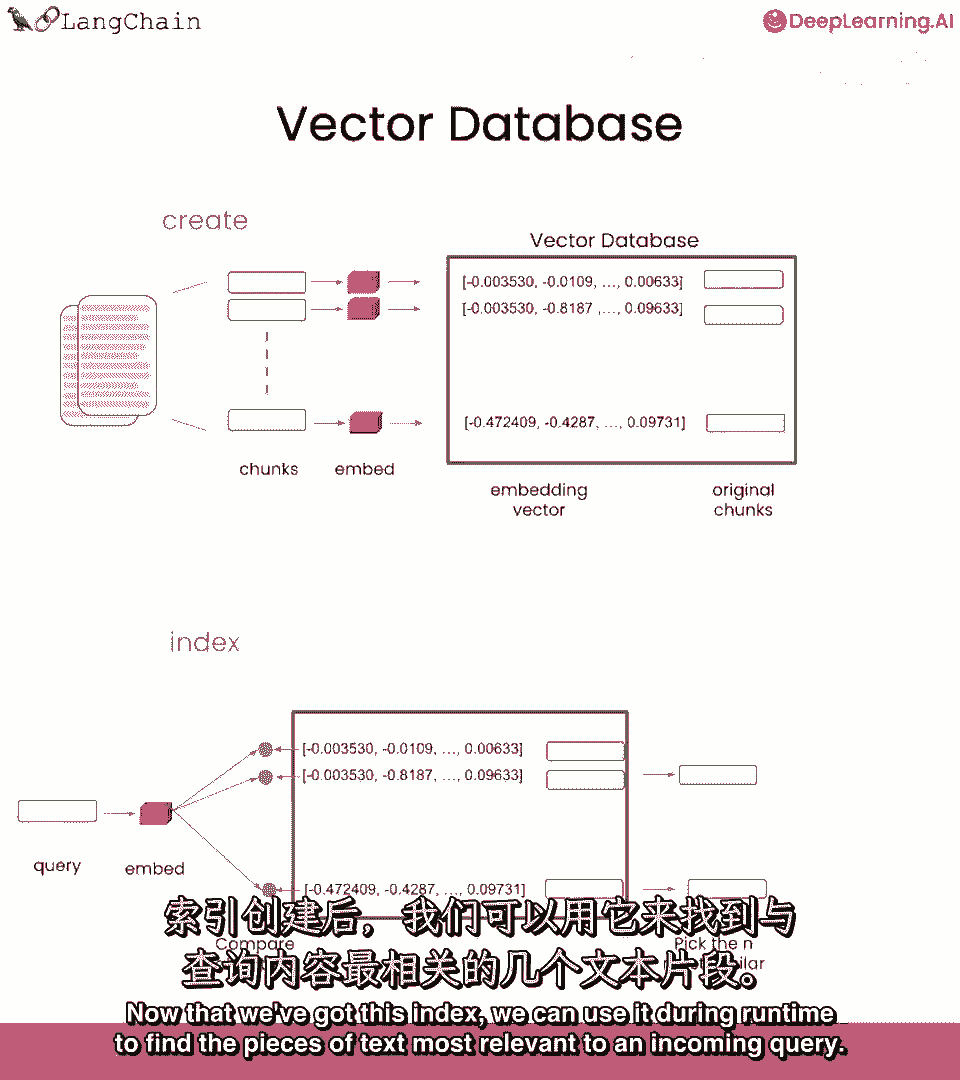
当查询进来时,我们首先为该查询创建嵌入。
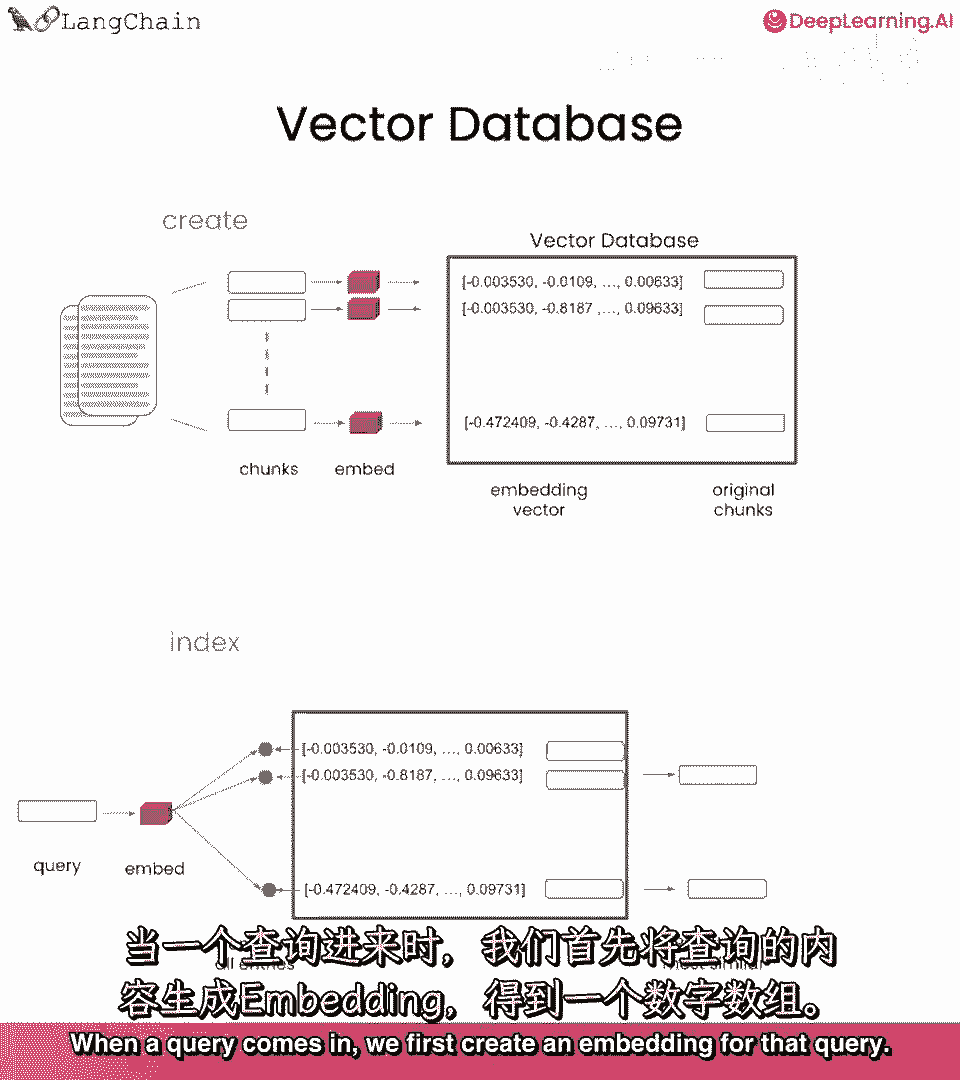
然后我们将其与向量数据库中的所有向量进行比较。
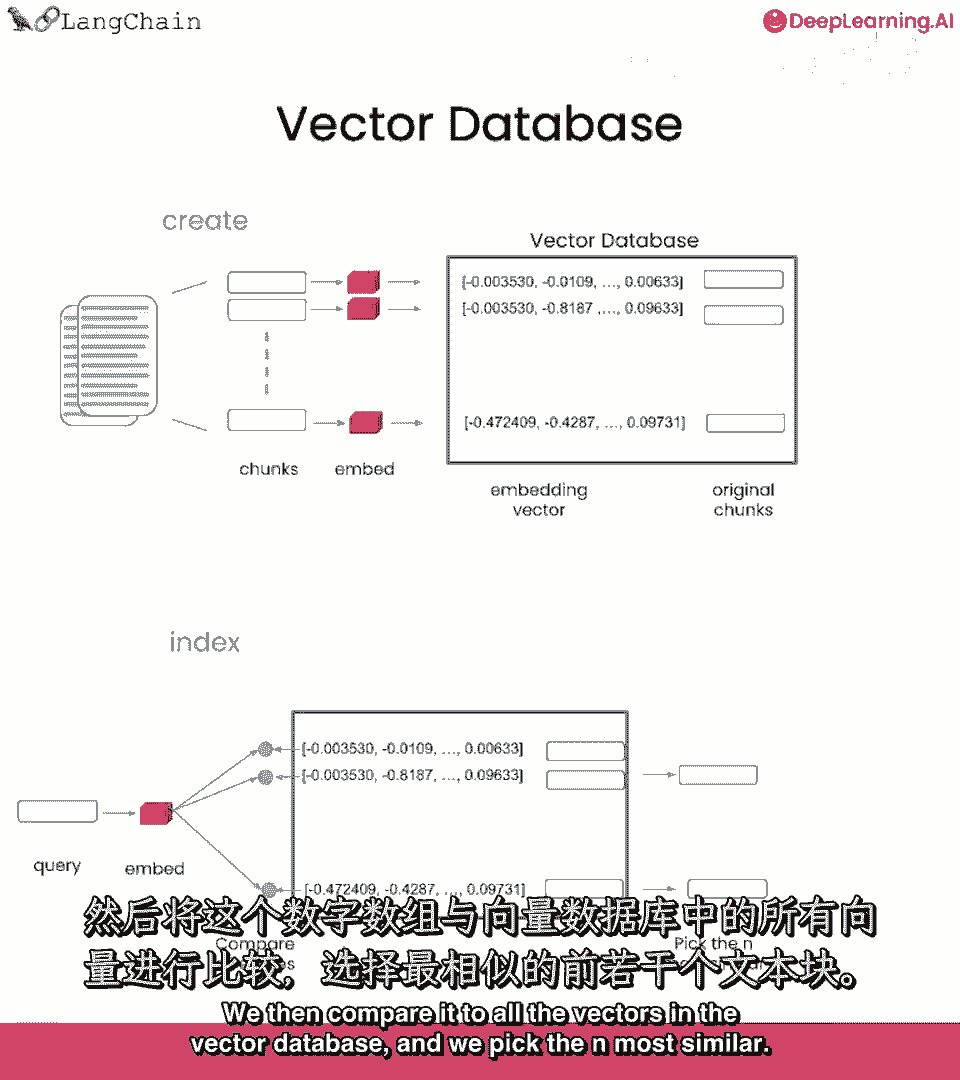
并选择最相似的n个,这些然后被返回,我们可以将它们放入提示中传递给语言模型以获取最终答案。
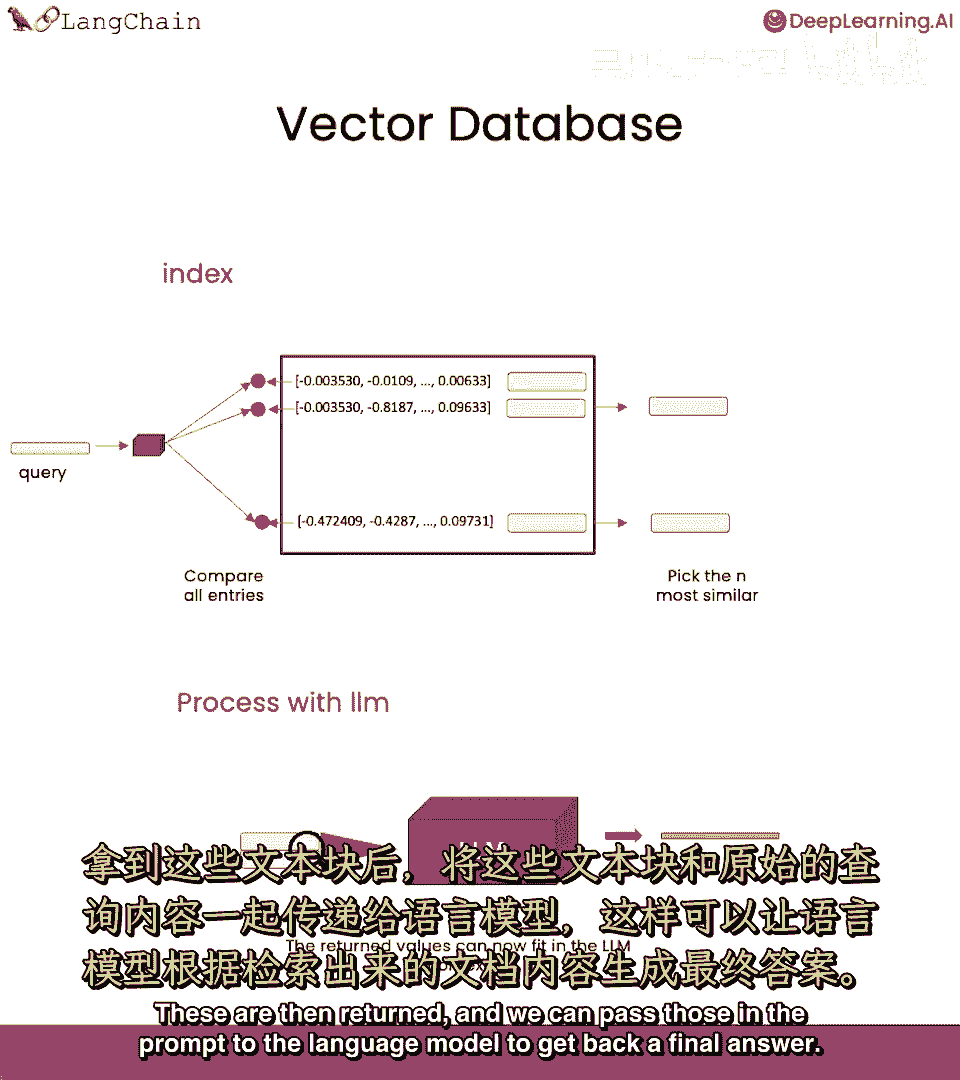
因此,上面我们创建了这个链条,只有几行代码,非常适合快速开始,但现在让我们更详细地做,并了解底层到底发生了什么。

第一步与上面类似,我们将创建一个文档加载器,从包含所有产品描述的csv中加载,我们想回答的问题。

然后,我们可以从这个文档加载器中加载文档。

如果我们查看单个文档,我们可以看到每个文档对应csv中的一个产品,之前我们讨论了创建块,因为这些文档已经很小,实际上我们不需要在这里做任何切块。

因此,我们可以直接创建嵌入。

要创建嵌入,我们将使用open eyes的嵌入类,我们可以导入它并在这里初始化它,如果我们想看看这些嵌入做了什么,实际上,我们可以看看当我们嵌入特定文本时会发生什么,让我们使用嵌入查询方法在嵌入对象上。
为特定文本创建嵌入,在这种情况下,句子'hi',我的名字是哈里森。

看看这个嵌入,有超过一千个不同元素。

每个元素是一个数值,结合这些,形成文本的整体数值表示。

要为加载的所有文本创建嵌入。

然后将其存储在向量存储中,可以使用向量存储的from_documents方法。

该方法接受文档列表和嵌入对象,然后创建整体向量存储。

现在可以使用向量存储查找与查询相似的文本。

看看查询,请推荐一件带些遮挡的衬衫。

如果使用向量存储的相似搜索方法并传入查询。

将返回文档列表。


可以看到返回了4个文档,查看第一个。

确实是一件关于遮挡的衬衫,如何使用这个来回答我们自己的文档问题,首先需要从这个向量存储创建检索器。
检索器是一个通用接口,可以由任何接受查询并返回文档的方法支持。

向量存储和嵌入是实现这一方法的一种,尽管有大量不同的方法,有些不那么先进,有些更先进,因为我们想进行文本生成并返回自然语言响应,将导入语言模型,将使用chat openai。

如果手工操作,我们会将文档合并成单篇文本。

像这样,将所有页面内容合并到变量中。

然后传递这个变量或问题的变体,如请列出所有带有保护措施的搜索表格,用标记语言并总结每个到语言模型,如果打印出响应,可以看到我们得到了表格。

正如我们所要求的,所有这些步骤都可以用lane chain链封装,所以这里可以创建检索。

Qing,这做检索,然后在检索的文档上做问答以创建这样的链。

将传入几个不同的东西,首先将传入语言模型,这将在最后用于文本生成。

接下来将传入链类型,我们将使用stuff,这是最简单的方法,因为它只是把所有文档放入上下文并调用一次语言模型,还有一些其他方法可以使用来提问,回答将在最后提及,但不会详细查看,第三步传入检索器。
上面创建的检索器仅是获取文档的接口,将用于获取文档并将其传递给语言模型。

最后设置verbose等于true。

现在可以创建查询并运行链在此查询上,收到响应时,再次使用display和markdown工具显示。

您可以暂停视频并尝试使用大量不同查询。

这就是详细做法,但请记住,我们仍然可以很容易地,使用上面的单行代码,因此,这两件事等同于相同的结果,这是关于linchain有趣的部分,你可以在一行中完成,或者查看单独的项并将其分解为五个更详细的项。
五个更详细的项允许您设置关于正在发生什么的更多具体信息,单行代码易于开始,所以取决于你。

关于你更喜欢如何前进,我们还可以在创建索引时自定义索引。

所以如果你记得我们手动创建它,我们指定了嵌入。

我们还可以在这里指定嵌入,因此,这给了我们控制嵌入本身如何创建的灵活性。

我们还可以将向量存储器替换为不同类型的向量存储器。

当你手动创建它时所做的相同级别的定制。

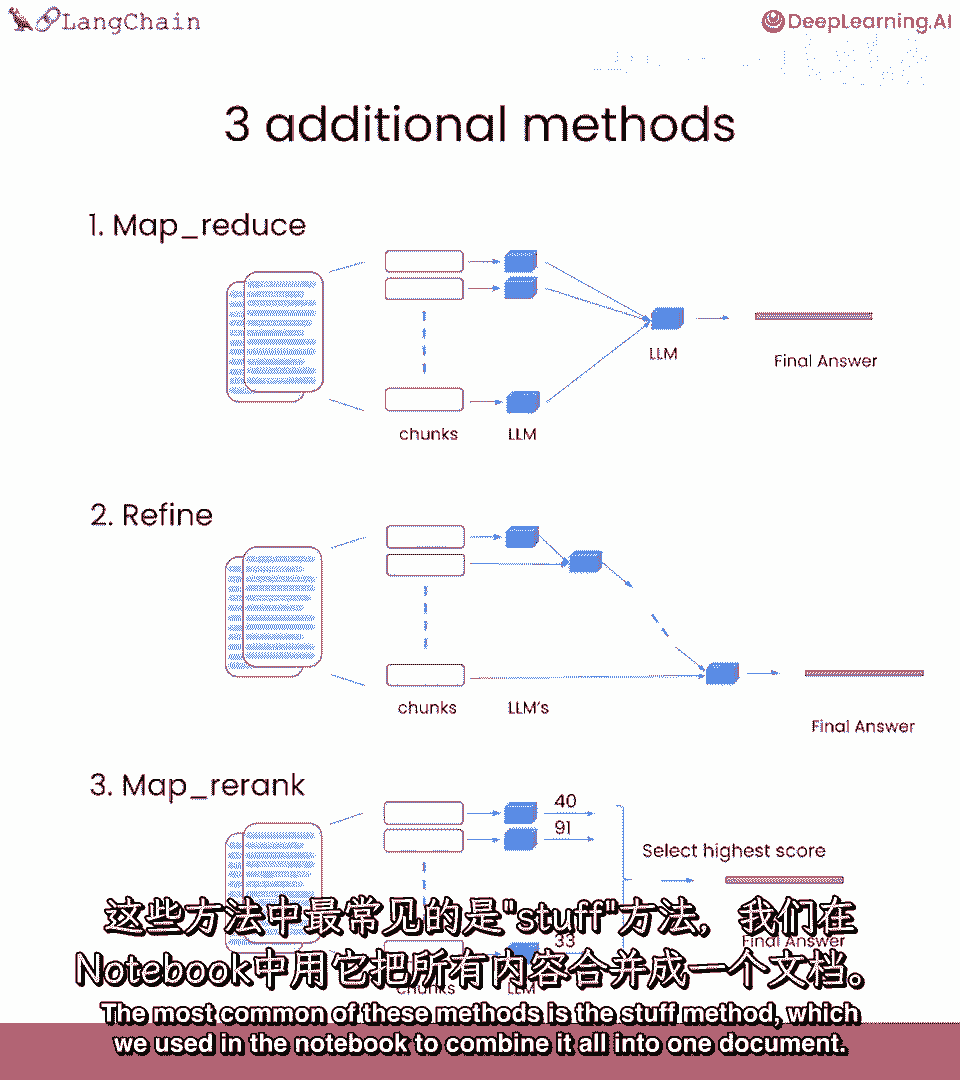
在创建索引时也可用,我们在笔记本中使用stuff方法,stuff方法真的很棒,因为它很简单,你只需将所有内容放入一个提示中,并将其发送给语言模型以获取一个响应,所以很容易理解正在发生的事情。
它非常便宜并且工作得很好。

但并不总是有效,好吧,所以如果你记得我们在笔记本中检索文档。

我们只得到了四份文档,它们相对较小,但如果你想要做同样类型的问题。

回答大量不同类型的块,我们可以使用几种不同的方法。

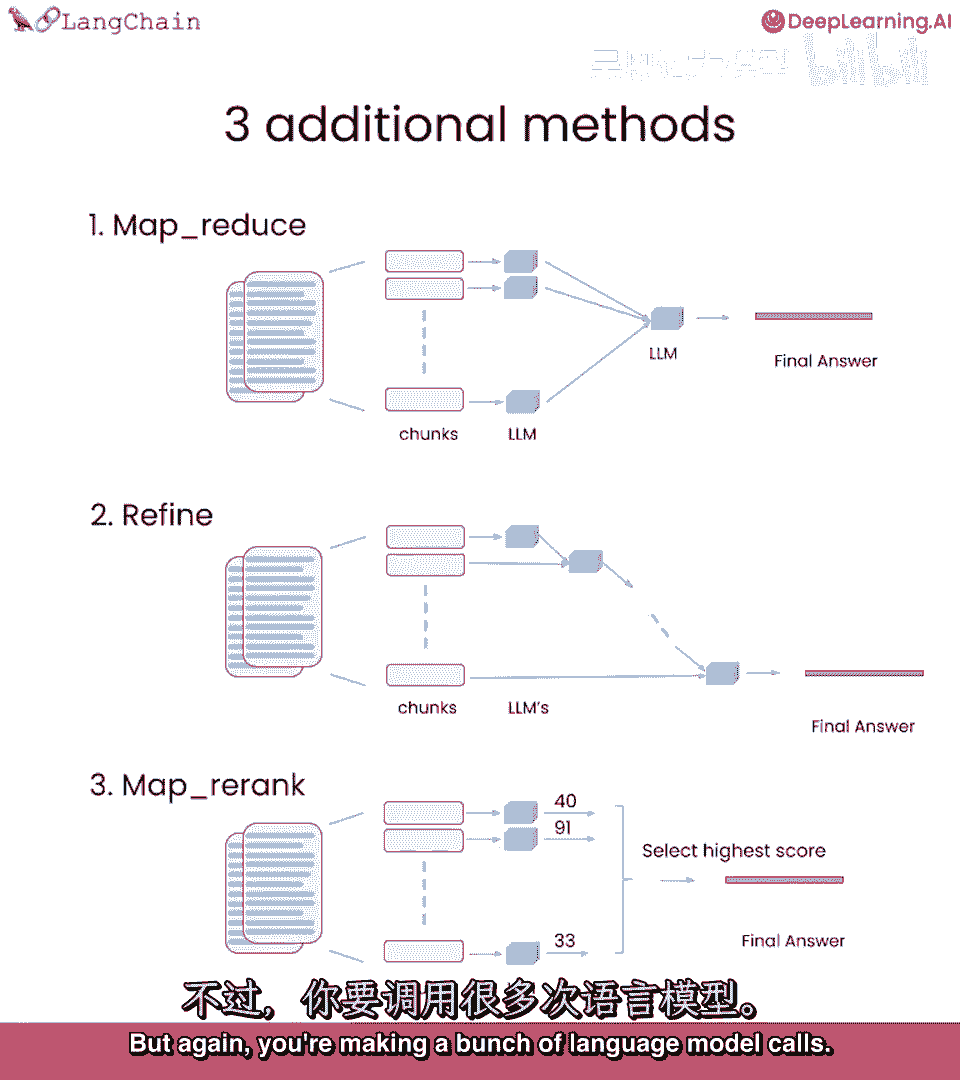
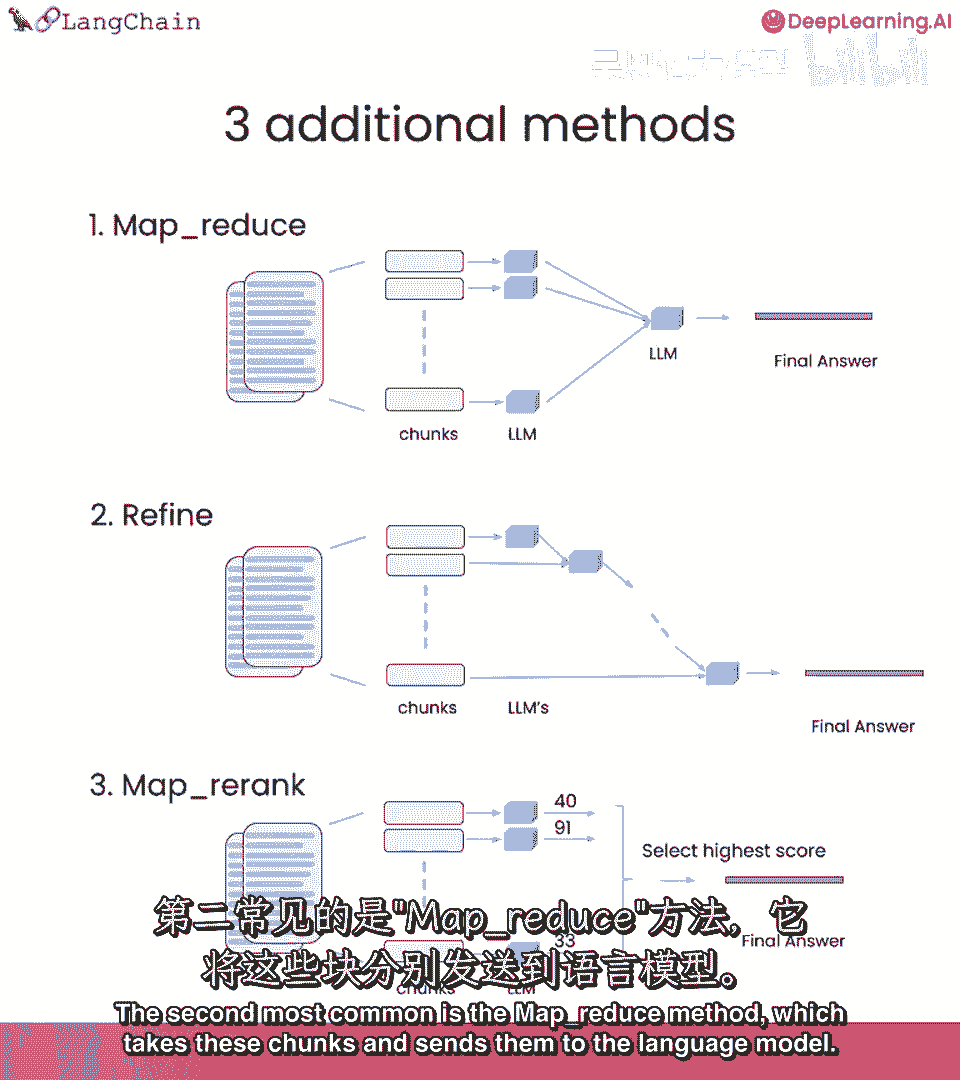
第一个是mapreduce,基本上将所有块,与问题一起传递给语言模型,得到响应。

然后使用另一个语言模型调用来总结所有个别响应到一个最终答案。
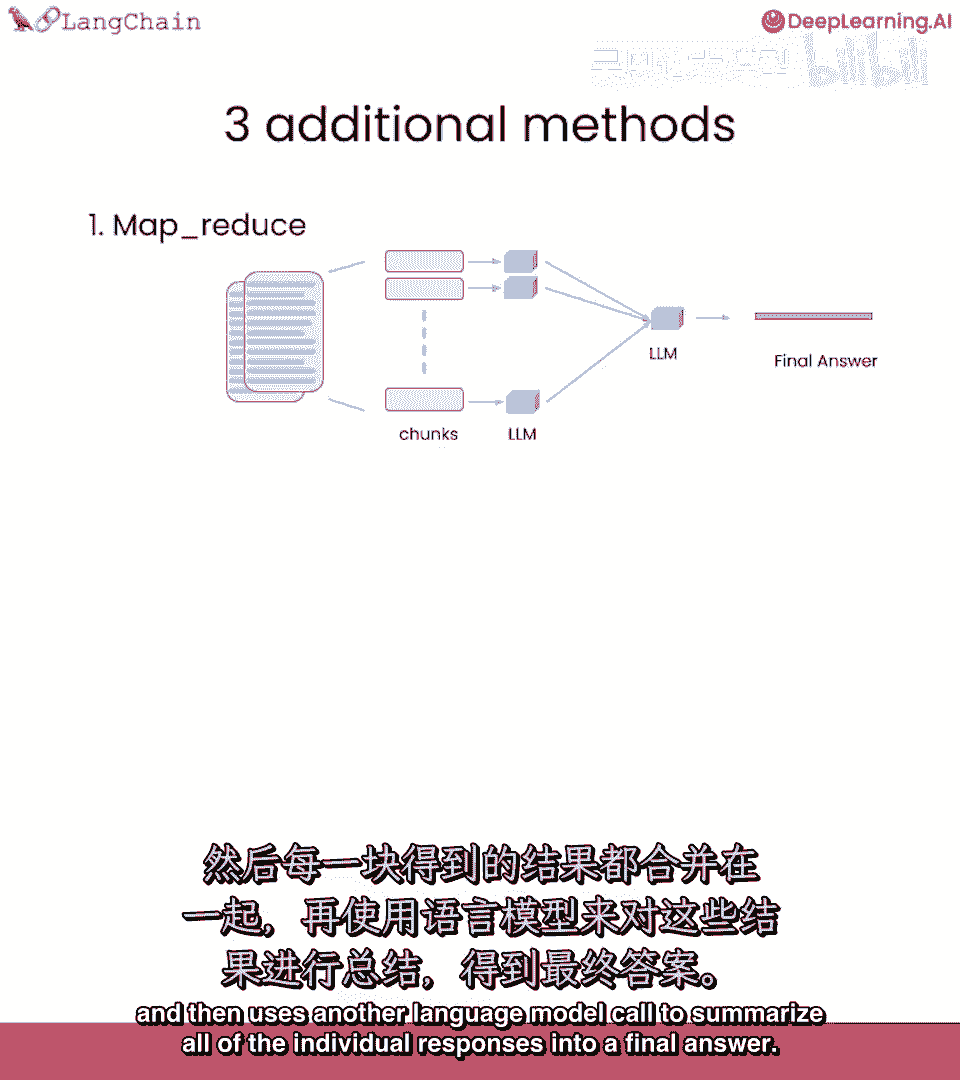
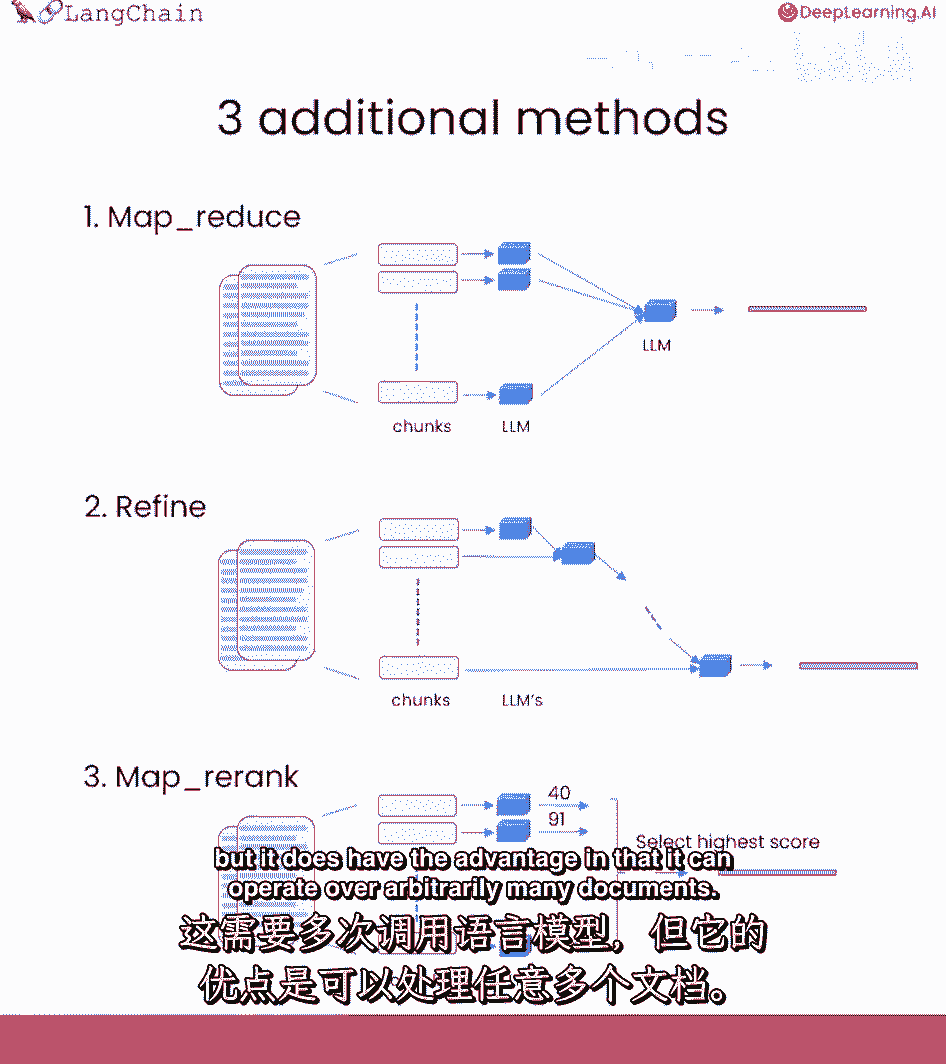
这非常强大,因为它可以操作任何数量的文档,它也非常强大,因为你可以并行处理个别问题,但它确实需要更多的调用,所有文档视为独立。
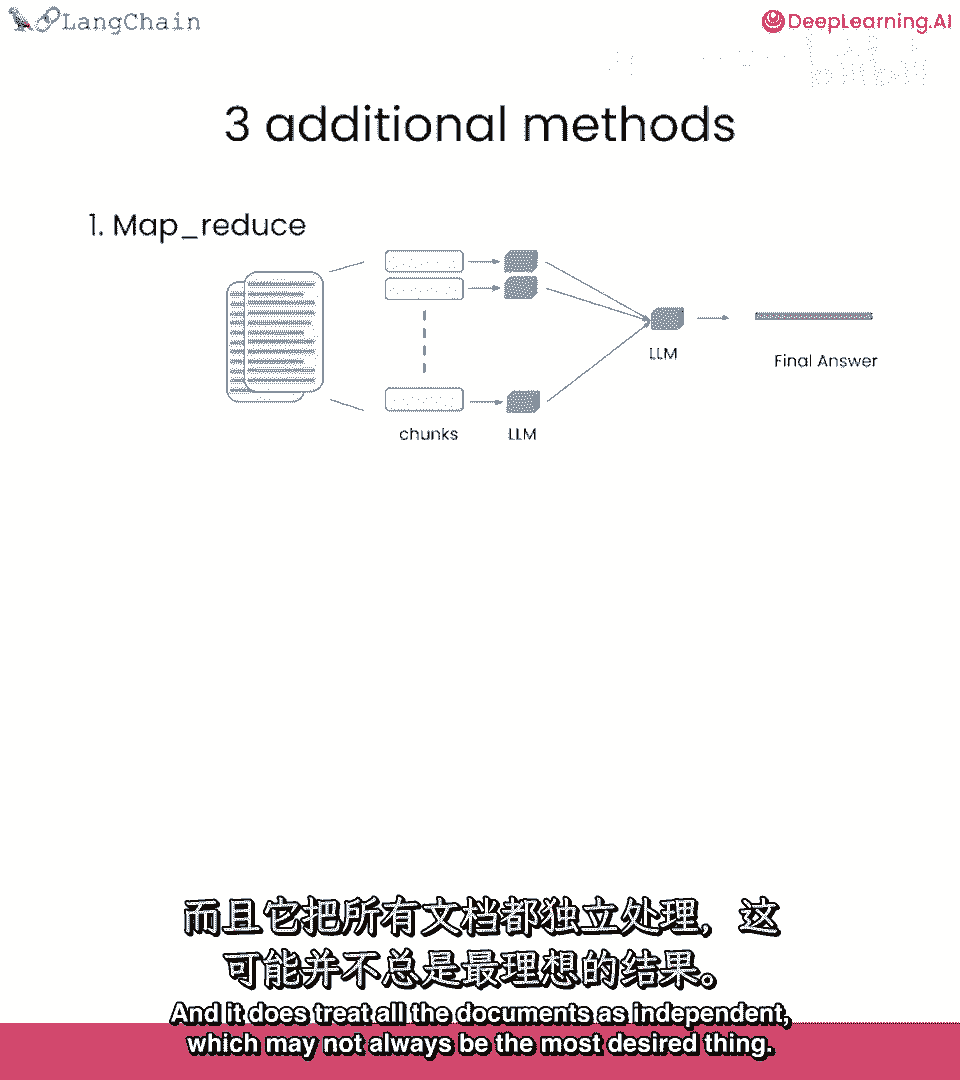
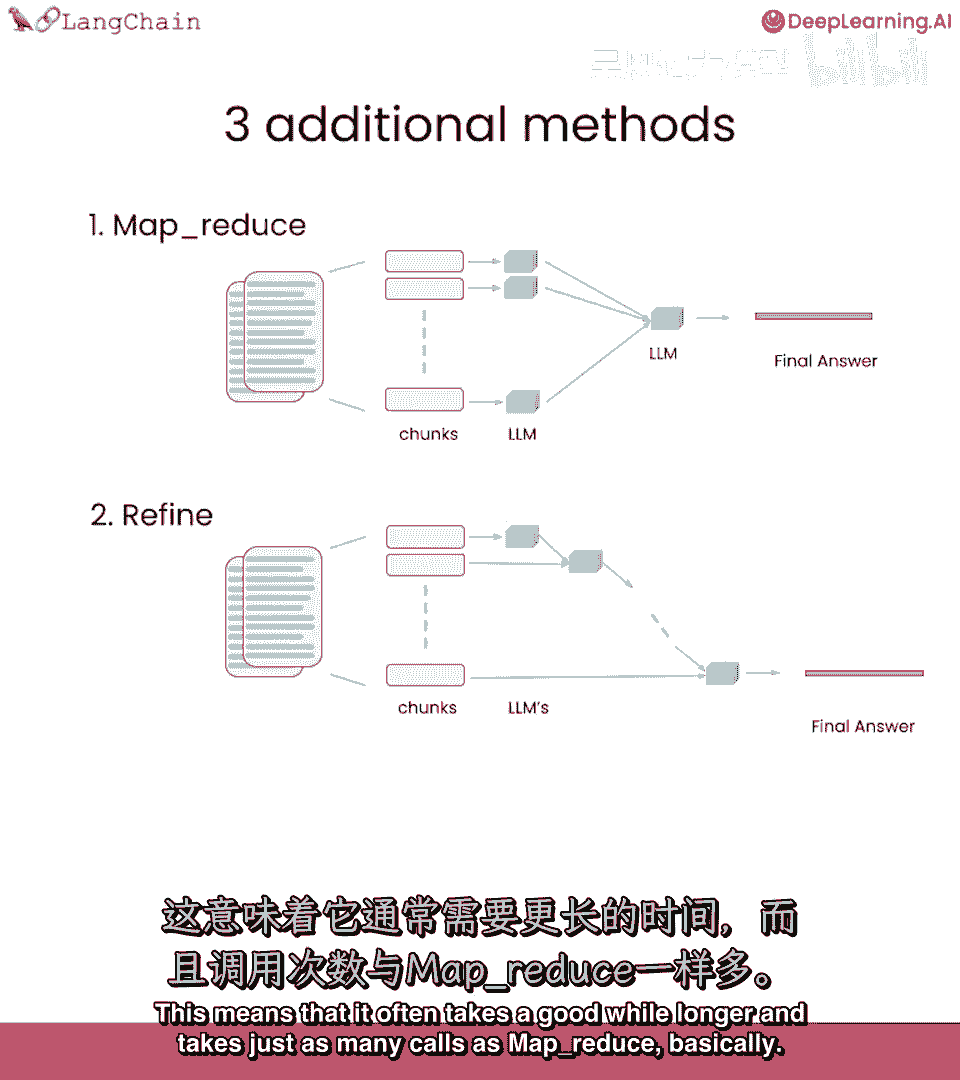
这不总是最想要的,精炼,再次遍历多文档的方法,实际上迭代进行,基于前文档的答案构建,非常适合组合信息,随时间构建答案,通常导致较长的答案,也不那么快,因为调用不再独立,依赖于前次调用的结果。
这意味着通常需要更长的时间,与MapReduce一样多的调用。
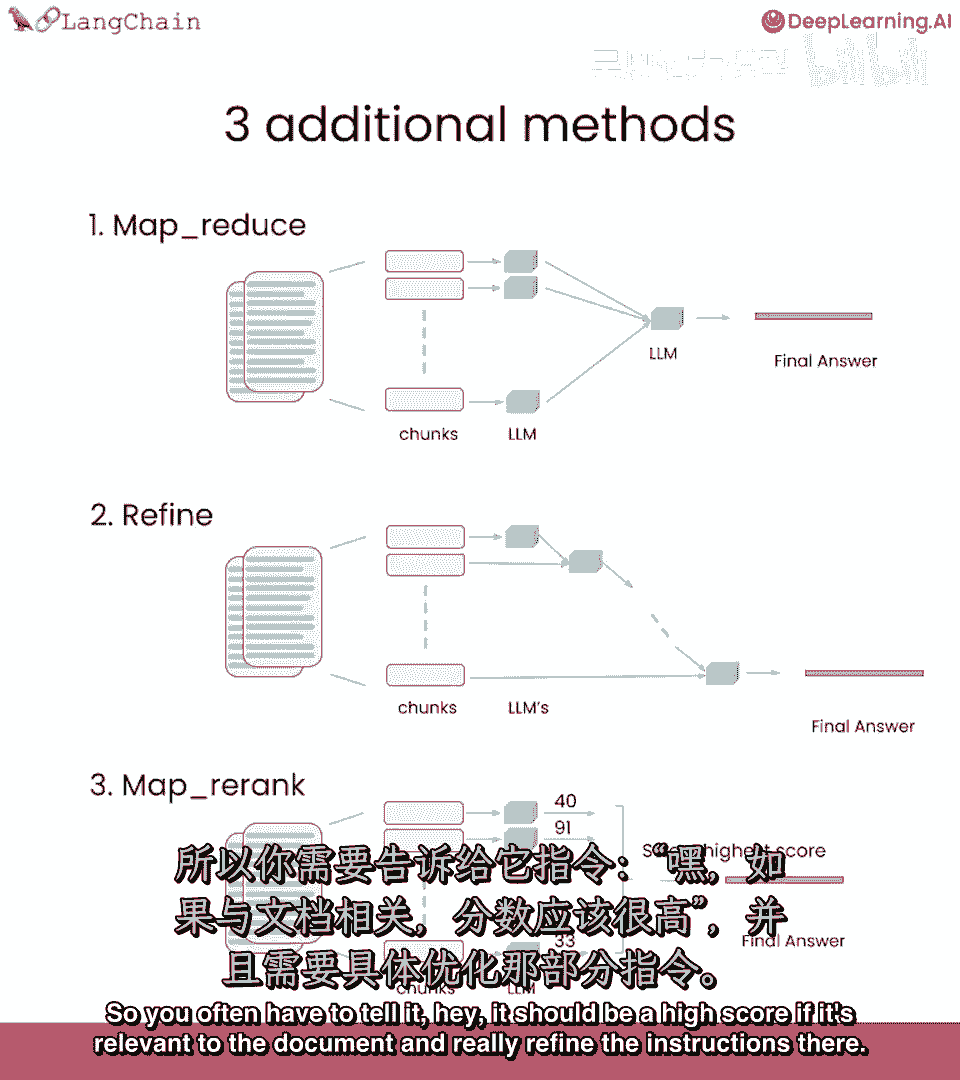
MapRerank是一个有趣且更实验性的方法,对每个文档进行一次语言模型调用。
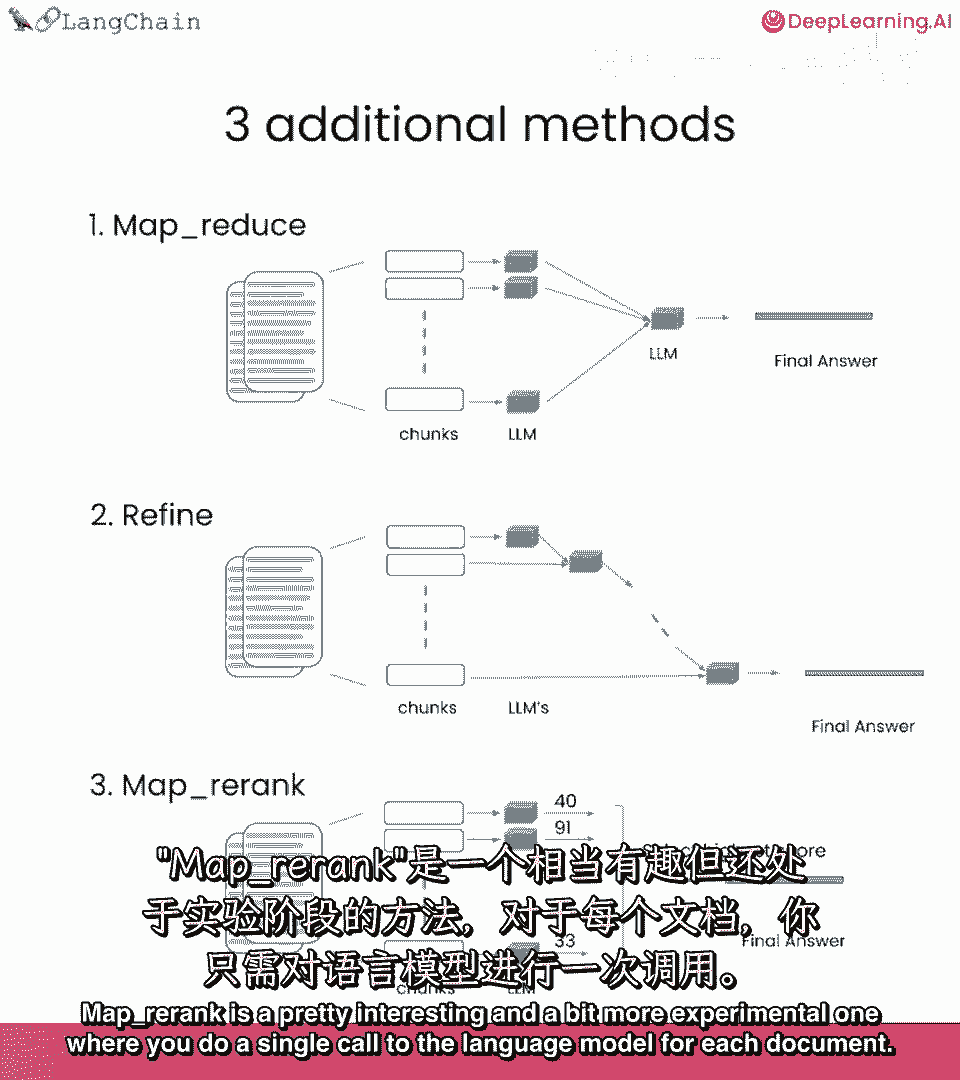
并要求它返回一个分数,然后选择最高分,这依赖于语言模型知道分数应该是什么。
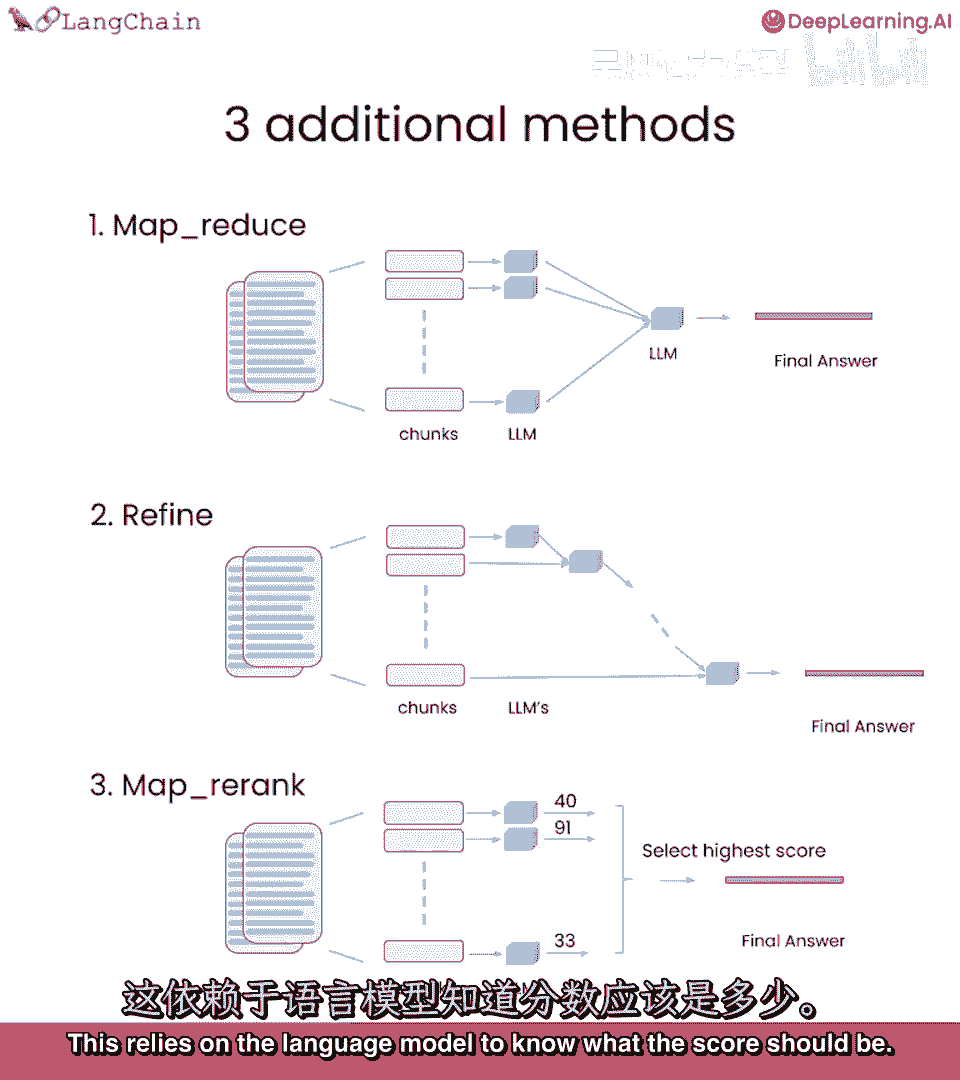
所以经常需要告诉它,嘿,如果与文档相关,应该是高分,真正细化指示。
类似于MapReduce,所有调用都是独立的,因此可以批量处理,相对较快,但再次进行了很多语言模型调用。
所以会稍微贵一些,最常用的方法是stuff方法。
我们在笔记本中用它把所有内容组合成一个文档,第二常用的是MapReduce方法,将这些块发送到语言模型。
这些方法,Stuff,MapReduce精炼,以及WeRank也可以用于许多其他链条。
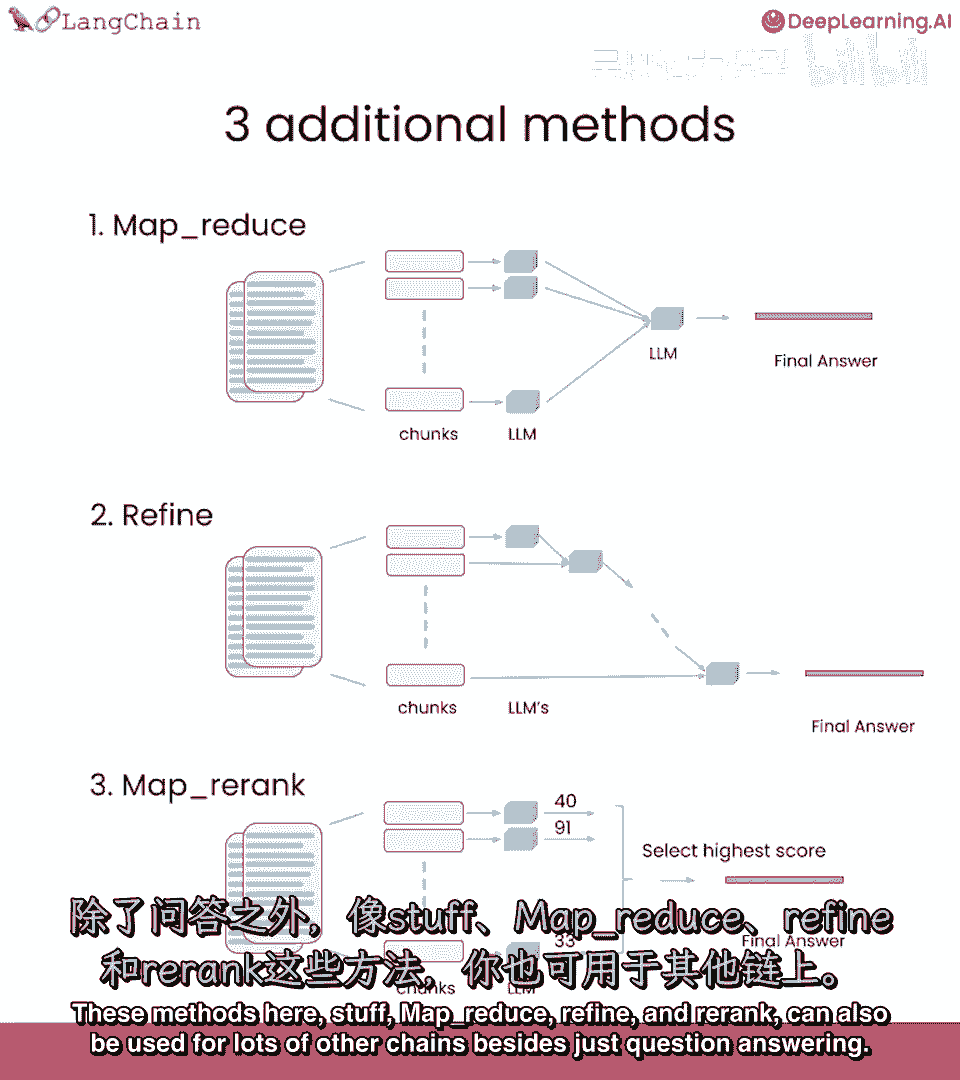
不仅仅是问答,例如,MapReduce链的一个非常常见的用例是摘要,您有一个非常长的文档,并希望递归总结信息片段,这就是文档问答的全部,你可能已经注意到,我们这里的不同链条中有很多正在进行的事情。
所以在下一节。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P3:3-微调在训练过程中的位置 - 吴恩达大模型 - BV1gLeueWE5N
在这堂课中,你将了解精细调整如何真正融入训练过程,它发生在一个被称为预训练的步骤之后,你将对其有一些详细的了解,然后,你将学习到所有可以应用的不同任务,精细调整就绪,让我们继续,好吗。
让我们先看看精细调整在哪里。

让我们看看预训练,这是精细调整发生之前的第一个步骤,实际上,它在开始时有一个模型,那完全是随机的,它对世界一无所知,所以所有它的权重,如果你熟悉权重,那么它们是完全随机的,它完全无法形成英语单词。
它还没有语言技能,而且它学习的目标下一个标记预测或真的,你知道,从简化的角度来看,在这里它就是下一个词的预测,所以你看到一次这个词,所以我们现在希望它能预测这个词。
但是当你看到llm只是产生sd感叹号时,感叹号在所以,离这个词upon非常远,这就是它开始的地方,但它正在从巨大的数据集中读取和理解,常常从整个网络中抓取,我们常常称这个为未标记的。
因为它不是我们一起结构化的。

我们只是直接从网络上抓取它,我会说它已经经历了许多许多清洁过程,所以,为了获取这个数据集,仍然需要大量的手动工作,对于模型预训练来说,要有效,因为模型本质上是在通过下一个标记词的预测来监督自己。
它只需要预测下一个词,实际上没有标签,否则,在这里训练后,你看,模型现在能够预测单词或标记或,嗯,而且它是一种学习的语言,它从互联网上学习了大量的知识,所以,这个过程实际上能工作真是太棒了,用这种方式。
而且因为它只是试图预测下一个标记,所以令人惊叹,现在,它正在阅读整个互联网的数据量来做到这一点。

好的,也许'整个互联网'上有一个星号,数据和从整个互联网上抓取的数据,这个背后的实际理解和知识往往并不公开,人们,实际上并不清楚那个数据集的具体样子,对于大型公司的许多封闭源模型。

但是luther ai进行了一次惊人的开源努力,创建了一个数据集叫做堆,你在这个实验室中将有机会探索它,它的意思是它是一个由两个组成的集合,两个来自整个互联网的多样化数据集。

你可以在这里看到这个图表,你知道有四百八十七年,还有林肯的胡萝卜蛋糕食谱,当然也是从pubmed中抓取,有关不同医学文本的信息,最后这里还有来自github的代码,所以它是一个包含相当智能的数据集。
被精心挑选在一起,以实际将这些模型注入知识,现在,这个预训练步骤实际上是非常昂贵和时间消耗的,因为它需要花费大量的时间来让模型遍历所有这些数据,从绝对的随机性到理解一些这些文本,你知道。
制作胡萝卜蛋糕食谱,同时编写代码。

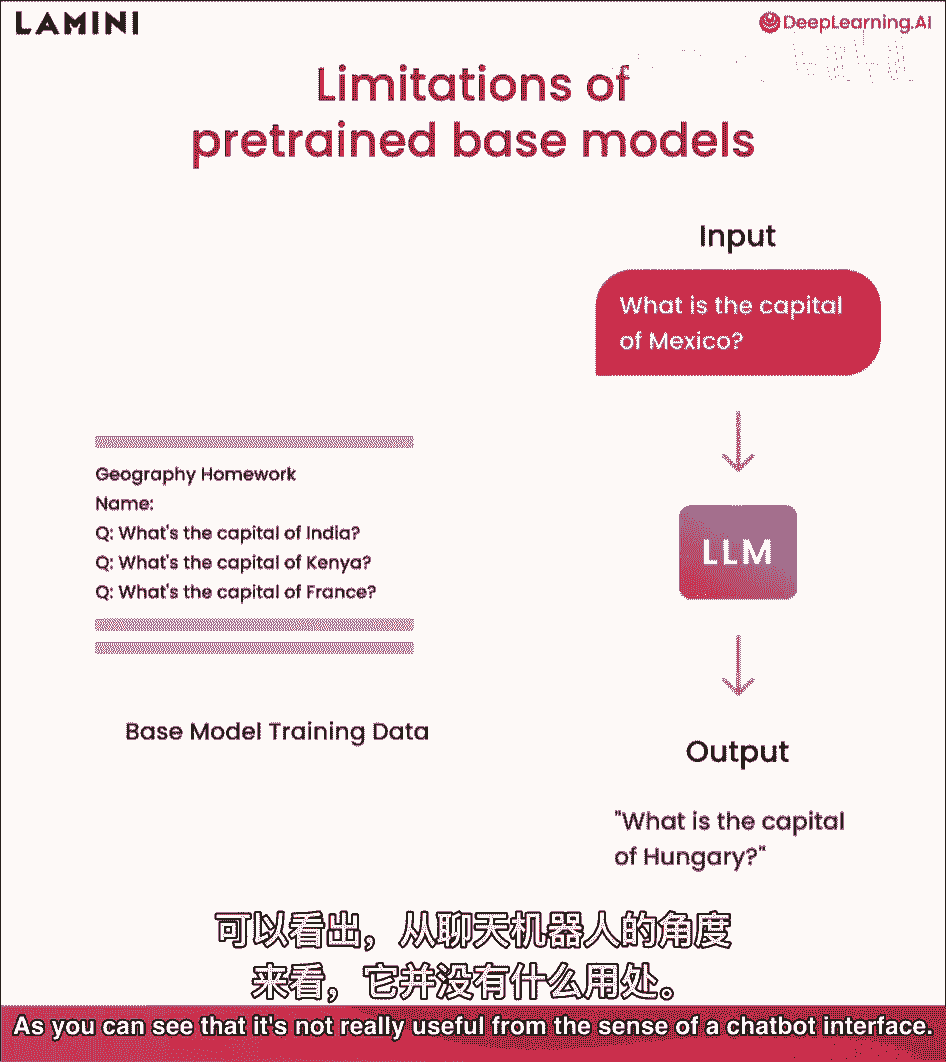
好的,这些基于预训练的模型很棒,实际上,外面有很多开源的它们,你知道,它们被训练在这些来自网络的数据集上,你可能在这里看到左上角的地理作业,它问,印度的首都是什么,肯尼亚的首都是什么,在所有这些中。
法国的首都是什么,你知道,在没有看到答案的情况下,当你输入墨西哥的首都是什么时,lm可能会说匈牙利的首都是什么,你可以看到,它不是从聊天机器人界面的角度来看非常有用的。
那么如何使它达到聊天机器人界面,微调是实现这一目标的一种方式,它应该是你工具箱中的一种工具,预训练实际上是第一步,它给你那个基础模型,当你添加更多的数据时,实际上不是那么多数据。
你可以使用微调来获取一个微调模型,甚至一个微调模型,你可以在后续添加更多的微调步骤,微调实际上是一个后续步骤,你可以使用相同的类型的数据,实际上,你可能可以从不同的来源抓取数据并一起筛选。
稍后你会看到这一点,这样它就可以是这个引言,未标记的数据,但你也可以自己编辑数据,以便为模型学习提供更多的结构化信息,我认为一个关键的区别在于,微调与预训练,需要的数据要少得多。
你正在构建在这个基础模型上,这个模型已经学习了如此多的知识和基本语言技能,你实际上是将其提升到下一个级别,你不需要那么多数据,所以这确实在你的工具箱中,如果你来自其他机器学习领域。
你知道这是对判别性任务的微调,也许你在处理图像,你已经在imagenet上进行了微调,在这里,微调的定义稍微宽松一些,对于生成性任务,它定义得不如判别性任务明确,因为我们实际上是在更新整个模型的权重。
不仅仅是它的一部分,这通常是微调的情况,那些其他的模型类型,所以,我们在这里与预训练的目标相同,对于微调,下一个标记的生产,我们所做的只是改变数据,以便以某种方式更有结构。
并且模型可以更一致地输出和模仿这种结构,此外,还有更先进的方法可以减少您想要更新此模型的程度,稍后我们将讨论这个问题。

所以,微调对你们做了什么,所以你现在开始理解它是什么样子了,但是任务有哪些不同,这样你就可以用它做得很好,我想象的一个巨大类别就是行为改变,你在改变模型的行为,你正在告诉它确切的,你知道在这个聊天界面。
我们现在在一个聊天设置中,我们不在看调查,所以这导致模型能够更一致地响应,这意味着模型可以更专注于,也许这对审核来说会更好,例如,而且这也是一般性地在挖掘其能力,所以这里它在对话上更好。
所以它可以现在谈论各种各样的事情,与以前相比,我们需要做很多提示工程,以便挖掘出那个信息,微调也可以帮助模型获得新知识。

所以这可能是关于不在那个基础中的特定主题。

预训练模型,这可能意味着纠正旧的错误信息,所以也许有,你更希望模型实际吸收的更新一些最近的信息,当然,最常见的是你正在做这两件事,所以经常你会改变行为,你想要它获得新知识,所以往下降一个档次。

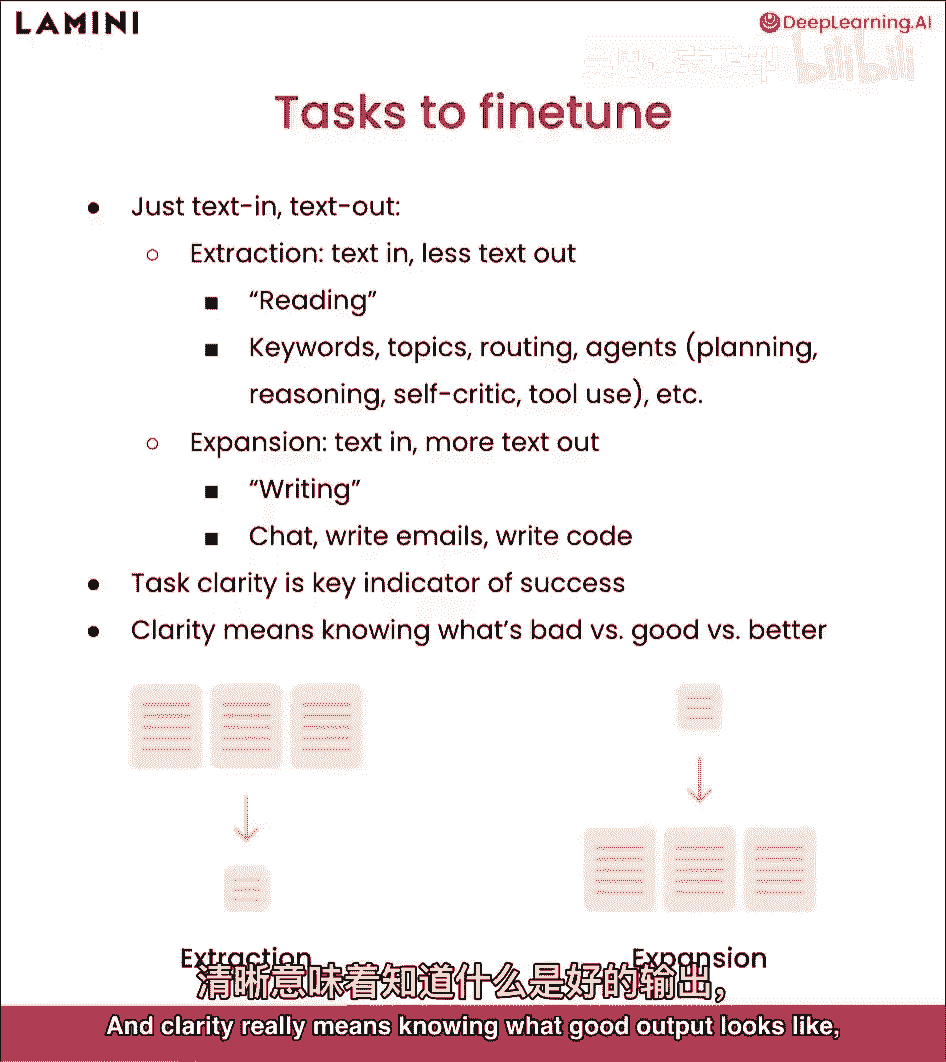
所以微调任务,对于llms来说,实际上就是文本和文本输出,我喜欢把它分为两个不同的分类,所以你可以这么想,一个作为提取文本,所以你输入文本,然后你得到较少的文本输出,所以很多工作都在阅读上。
这可能是提取关键词,你可能要路由的主题,你知道,基于你看到的所有数据,你路由聊天,例如,路由到API或其他不同代理在这里,像不同代理的能力,这与扩展相反,这就是你输入文本的地方。
然后你得到更多的文本输出,我喜欢把它想成写作,所以这可能是聊天,写电子邮件,写代码,真正理解你的任务,这两个不同任务之间的确切区别,或者你可能有多个任务想要微调,我发现这是最明确的成功指标。
如果你想成功,微调模型是明确你想要做什么任务的关键,清晰意味着知道什么是,你知道一个好的,你知道什么样的好输出看起来。
那个输出看起来什么样子,但也知道什么样的输出更好,当你知道某件事在写代码方面做得更好,或者在实际帮助路由任务方面做得更好。

你实际上微调这个模型来做得很好,好的,如果你这是首次微调,我推荐几个不同步骤,首先,通过提示工程识别一个任务,只要大型llm,例如,聊天bot,可以是,所以,你就只是在与chgbt玩耍。
像你通常做的那样,然后你找到了一些,你知道,它正在执行的任务,好的,是的,所以不是非常好,但也不像非常糟糕,所以你知道这在可能的范围内是可能的,但它不是,它不是最好的,你想要它为你的任务做得更好。
所以选择那个任务,然后只选择一个,然后数字四,嗯,为那个任务获取一些输入和输出,所以你输入一些文本,然后你得到了一些文本输出,嗯,获取输入,你在哪里输入文本,得到文本输出,输出,对于这个任务。
这些对的数量,其中我喜欢使用的一个黄金数字是一千,因为我发现那是开始需要数据的一个好地方。

并确保这些输入和输出比'好'更好。

在您无法生成这些输入之前,LLM的结果,输出的必要并非总是,所以确保你有这些数据对,你也将在实验室中探索这一点,整个管道在这里,从那里开始,然后,你可以在这个数据上微调一个小的LLM。
只是为了感受到性能的提升,如果这是你第一次,这是我推荐的,现在让我们进入实验室,在那里,你可以探索用于预训练和微调的数据集,所以你完全理解这些输入输出对的样子。

好的,我们将开始通过导入一些不同的库来开始,我们将运行那个,我们首先将使用的库是datasets,来自Hugging Face的库,他们有一个伟大的函数叫做load data set。
你可以直接从他们的hub拉取数据集并运行它。

我在这里将拉取预训练数据集,叫做你看到的那个堆栈,我在这里抓取分割,训练集与测试集,并且非常具体地,我实际上正在抓取流式,等于true,因为这个数据集非常大,我们不能在没有破坏这个笔记本的情况下下载它。
所以实际上,我将逐个流式传输它,以便我们可以探索那里的不同数据部分,所以只是加载它。
现在我要只看前五个,所以这正在使用itertools。

很好,好的,在这里,你可以在预训练数据集中看到,这里有很多看起来像是从网络上抓取的数据,你知道,这个文本说它已经完成并提交,你可以在安卓上玩生存模式tcs,这就是一个例子,让我们看看是否能找到另一个。
在这里,这里有另一个,这就是从网络上抓取的代码,被抓取的XML代码,这是另一个数据点,在这里,你会看到文章内容,你会看到这个主题的内容,你知道,亚马逊在aws上宣布了一个新服务,然后这里是关于,你知道。
大满贯钓鱼游艇,这是一家家庭企业,这就是,你知道,就是一种从互联网上抓取的不同数据集的混乱,我想对比,与将在不同实验室中使用的一组进行微调的数据集,我们正在抓取一家公司的,问题答案对数据集,你知道。
是从FAQ抓取的,也是关于内部工程文档的汇编,它被称为lamini docs,是关于公司的,Lamini,嗯,所以我们只是读取那个json文件,并看看里面有什么,好的,所以这是非常结构化的数据,对吗。
这里有问题答案对,它对这个公司非常具体。

使用这个数据集的最简单的方法是将问题与答案拼接起来。

实际上,这些问题和答案,并服务给模型,这就是我在这里要做的,我将将其转换为字典,然后我会看看将其中一个拼接起来实际上看起来像什么。
所以你知道,只是将问题直接拼接起来,然后。

在这里直接给出答案,当然,你可以以任何可能的方式准备你的数据。

我只是想指出几种不同的常见方式,来格式化和结构化你的数据,所以问题答案对,但是,也包括指令和响应对,输入输出对,在这里非常通用,而且,实际上,你可以只是,因为我们正在拼接它。
它就是你看到的上面的文本堆叠,好的,所以拼接它,你知道这非常简单,但有时这就是足够的看到结果,有时它不是嗯你,所以你会发现模型可能需要更多的结构来帮助它。

这实际上与提示工程非常相似,所以进一步来说,你也可以使用指令跟随的数据处理,在这种情况下,问题回答提示模板,这里有一个常见的模板注意。

在问题前面有一个###,一种标记,所以这可以很容易地被用作结构来告诉模型期待什么接下来。

它期待看到问题后的问题,这也可以帮助你后处理模型的输出。

即使在它被微调后,我们有那个,所以让我们来看看这个提示模板在实际中的作用。

并看看它与拼接的问题答案如何不同。

你可以看到如何,这就是提示模板的样子,问题答案在那里做得很整洁。

常常帮助保持输入和输出分开,所以我实际上要删除这个答案在这里,并将它们分开出来,因为这个房子只是使用数据集很容易地进行评估,你知道,当你将数据集分成训练和测试时,所以现在我要做的就是将所有这些。

你知道,将所有模板应用到整个数据集上。

所以只是运行一个for循环,并仅填充提示,那就是,你知道,将问题答案添加到这个中,使用f字符串或格式化东西。

在这里使用Python,好吧,所以让我们看看文本之间的差异。

唯一的事情,嗯,和问题答案格式。

酷,所以只包含文本,所有的内容都在这里拼接,你是输入的,在这里只有问题答案,更加结构化,你可以使用任何一种,当然,我推荐结构化它以帮助评估,基本上就是这样。
存储这种数据的最常见的方式通常是在json行文件中。

所以json l文件,Json l,它基本上就是,你知道,每一行都是一个json对象。

这就是全部,所以只是将那个写入文件,你也可以将这个数据集上传到hugging face。

嗯,在这里显示,因为你也会 later 使用它。

你可以从那样从云中拉取它,接下来,你将深入到一个特定的微调变体,叫做指令。

LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P30:6——评估 - 吴恩达大模型 - BV1gLeueWE5N
构建复杂应用时,重要但有时棘手,步骤是如何评估应用表现,是否满足准确度标准,若决定更改实现,可能替换不同LM,或改变向量数据库使用策略,或更改系统其他参数,如何知道改进与否,Harrison将深入框架。
思考评估LM应用,及辅助工具,应用是许多步骤链,老实说,首先应理解每一步,进出内容,部分工具可视化为调试器,但全面评估数据点,模型表现很有用,可通过肉眼观察,也可用语言模型评估,深入探讨,许多酷话题。
开发转向提示式,使用LM开发应用,评估流程被重新思考,视频中有许多激动人心概念,深入开始,首先设置评估,需要评估的链或应用,使用上节课文档问答链,导入所需,加载相同数据,创建索引一行代码。
创建检索QA链,指定语言模型,链类型,检索器,打印详细程度,有了这个应用,首先需要,确定评估数据点,将覆盖几种方法,第一种最简单,基本上,我们想出好例子,几种方法将覆盖,第一种最简,基本上。
我们想出好例子,因此,我们可以这样做,我们可以查看一些数据并想出示例问题,然后示例地面真实答案,我们稍后可以用来评估,所以如果我们查看一些文档,我们可以大致了解里面的内容,看起来第一个。
有一个套头衫套装,第二个有一个,有一个夹克,它们都有很多细节,从这些细节中我们可以创建一些示例查询答案对,所以第一个我们可以问一个简单的问题,舒适套头衫套装是否有侧口袋,我们可以通过看上面看到。
它实际上有一些侧口袋,然后对于第二个我们可以看到这件夹克来自某个系列,羽绒技术系列,所以我们可以问一个问题,这件夹克来自哪个系列,答案是,羽绒技术系列,所以这里我们创建了两个例子。
但这并不真正扩展得很好,查看每个示例并弄清楚正在发生的事情需要一些时间,是否有方法可以自动化它,我们认为我们可以使用语言模型本身来实现自动化,我们有一个链和lang链可以做到这一点。
因此我们可以导入qa生成链,这将接受文档,并从每个文档中创建一个问答对,它将使用语言模型本身来做这件事,因此我们需要通过传递聊天Open AI语言模型来创建此链,然后从那里我们可以创建大量示例。
因此我们将使用apply和parse方法,因为这是在结果上应用输出解析器,因为我们想要得到一个包含查询和答案对的字典,而不仅仅是一个单一的字符串,所以现在如果我们看看这里返回的确切内容。
我们可以看到一个查询,我们可以看到一个答案,让我们检查一下这是对哪个文档的查询和答案,我们可以看到它询问这个的重量,我们可以看到它从这里获取重量,看,我们刚刚生成了大量问答对,我们不必自己编写。
这为我们节省了大量时间,我们可以做更多令人兴奋的事情,所以现在让我们继续并将这些示例添加到我们已经创建的示例中,所以现在我们有这些示例了,但是究竟如何评估正在发生的事情。
首先我们想做的就是运行一个示例通过链,查看输出结果,传入查询,返回答案,在可查看内容方面有些限制,链内部实际发生的事,实际提示是什么,进入语言模型的提示,检索到的文档,若为多步复杂链,中间结果是什么。
仅看最终答案不够,理解链中出错或可能出错,为此,long chain有个实用工具,称为link chain debug,若设置lane chain,Debug为true,重新运行上述示例。
开始输出更多信息,查看具体输出内容,首先深入检索qa链,然后深入stuff documents链,如前所述,使用stuff方法,现在进入llm链,有几个不同输入,原始问题就在那里,现在传入此上下文。
并且,可以看到,此上下文由检索到的不同文档创建,进行问答时,若返回错误结果,不一定是语言模型出错,实际上是检索步骤出错,仔细查看问题本身和上下文,有助于调试问题所在,可以再深入一层。
查看进入语言模型的内容,Chat openai本身,可以看到传入的完整提示,有系统消息,这是问答链使用的提示描述,我们甚至还没看过,可以看到提示打印出,使用以下上下文回答用户问题,若不知道答案。
就说不知道,不要编造答案,然后看到插入前的许多上下文,然后看到一个人类问题,这是我们问它的问题,还可以看到更多关于实际返回类型的信息,与其只是字符串,我们得到的信息如token使用。
所以是提示token,完成token,总token数,模型名称,这可以非常有用来跟踪你使用的token,或随时间对语言模型的调用,并跟踪总token数,这非常接近总成本,因为这个链相对简单。
我们现在可以看到最终响应,舒适的舒适套头衫条纹确实有,侧口袋正通过链传递并返回给用户,所以我们刚刚走过,如何查看和调试这个链的一个输入,但关于我们创建的所有例子,我们如何评估它们,类似于创建它们时。
一种方法是手动,我们可以运行链对所有例子,然后查看输出并尝试弄清楚发生了什么,是否正确,错误,部分正确,类似于创建例子,这开始随着时间的推移变得有点乏味,所以让我们回到我们最喜欢的解决方案。
我们能先问语言模型吗,在这样做之前,我们需要为所有例子创建预测,实际上我将关闭调试模式,以避免将所有内容打印到屏幕上,然后我将为所有不同的例子创建预测,我想我们总共有了七个例子。
我们将循环遍历这个链七次,为每个例子得到一个预测,现在我们有这些例子,我们可以考虑评估它们,所以我们将导入qa问答评估链,我们将使用语言模型创建此链,因为再次,我们将使用语言模型来帮助做评估。
然后我们将调用evaluate在这个链上,我们将传入示例和预测,我们将得到一堆评分输出,为了看到每个例子到底发生了什么,我们将循环遍历它们,我们将打印出问题,这由语言模型生成,我们将打印出真实答案。
这同样由语言模型生成,当它有,整个文档在前面时,所以它可以生成地面真相答案,我们将打印出预测答案,这是由语言模型在执行qa链时生成的,当检索向量库中的嵌入时,传入语言模型,尝试猜测预测答案。
然后打印出成绩,同样,这也是语言模型生成的,当询问评估链评分时,是否正确或错误,因此,当我们遍历所有示例并打印它们时,我们可以详细查看每个示例,看起来这里,全答对了,这是一个相对简单的检索问题。
这让人放心,让我们看第一个例子,问题是舒适套头衫,是否有侧袋,真实答案是,我们创建的答案是 是的,预测答案是,语言模型产生的是重置条纹的舒适感,有侧口袋,因此我们可以理解这是一个正确答案。
实际上语言模型也做到了,它给它评分为正确,但让我们思考一下我们为什么首先需要使用语言模型,这两个字符串实际上完全不同,它们是非常不同的,一个很短一个很长。
我甚至认为'是'这个词在这串中任何地方都没有出现,如果我们尝试字符串匹配,甚至正则,X在这里,它将不知所措,它们不是一回事,这显示使用语言模型评估的重要性,你有这些答案,任意强度。
没有单一的真理字符串是最好的答案,有许多不同的变体,只要语义相同,应评分相近,语言模型帮助于此,而非精确匹配,比较字符串的难度使语言模型评估困难,首先,我们用于这些非常开放的任务,要求生成文本。
这之前从未做过,因为直到最近模型都不够好,因此,之前存在的许多评估指标,都不够好,我们正在发明新的指标和新的启发式方法,当前最有趣最流行的,实际上使用语言模型评估,完成评估课程。
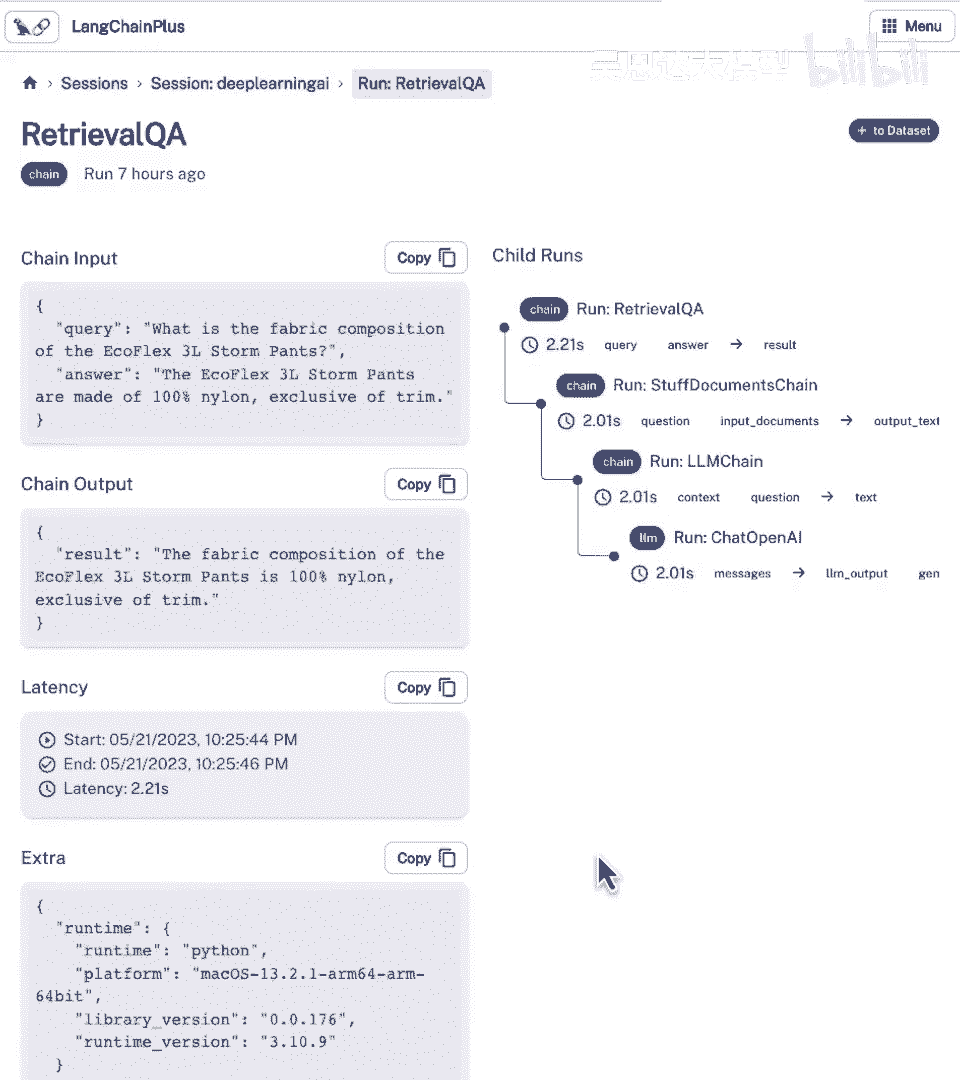
但最后想展示的是链接链评估平台,这是做我们在笔记本中做的一切的方式,但持久化并显示在UI中,让我们看看这里,我们可以看到有一个会话,我们称之为深度学习AI,我们可以看到我们实际上已经持久化了。
我们在笔记本中运行的所有运行,这是一个很好的方式来跟踪高层次的输入和输出,但也是一个很好的方式来查看下面到底发生了什么,这是与笔记本中打印出的相同的信息,当我们打开调试模式时。
但只是在UI中以更漂亮的方式可视化,我们可以看到链的输入,以及每一步链的输出,然后我们可以进一步点击链,并查看更多关于实际传递的信息,所以如果我们一直向下滚动到底部。
我们现在可以看到确切传递给聊天模型的内容,我们有系统消息在这里,我们有人类问题在这里,我们有聊天模型的响应在这里,我们有一些输出元数据,我们在这里添加了一个功能,可以将这些示例添加到数据集中。
所以如果你记得在开始时创建那些示例数据集,我们部分手动创建,部分使用语言模型,这里我们可以通过点击这个小按钮将其添加到数据集中,我们现在有输入查询和输出结果,所以我们可以创建数据集。
我们可以称之为深度学习,然后我们可以开始向这个数据集添加示例,所以再次回到我们课程开始时处理的事情,我们需要创建这些数据集以便进行评估,这是一个很好的方式让它在后台运行。
然后随着时间的推移添加到示例数据集中,并开始构建这些例子,您可以使用它们进行评估,并开始评估的飞轮转动。

LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P31:7——代理 - 吴恩达大模型 - BV1gLeueWE5N

有时人们认为大语言模型是知识库,因为它学习记忆大量信息,可能来自互联网,当你提问时,它能回答问题,但更实用的看法是将其视为推理引擎,你可以给它文本块或其他信息源,然后大型语言模型(LM)。
可能使用从互联网学到的背景知识,来回答问题,用新信息帮你回答问题,或决定下一步做什么,这就是lang chain的代理框架,代理可能是我最喜欢的部分,我认为它们也是最强大的部分,但它们也是最新的部分。
我们正在看到很多新东西出现,这对领域内所有人都是全新的,这应该是一堂非常令人兴奋的课程,当我们深入探讨代理是什么,如何使用代理,如何装备不同工具,如内建语言链的搜索引擎,以及如何创建自己的工具。
这样可以让代理与任何数据存储交互,任何API,任何你想要的功能,这是令人兴奋的前沿技术,但已有重要的应用案例,那么让我们深入探讨,首先,我们将设置环境变量,并导入稍后使用的许多东西。

我们将初始化语言模型。

我们将使用Chat Open AI,重要的是,我们将温度设置为0。

这很重要,因为我们将使用语言模型作为代理的推理引擎,它与其他数据和计算源连接。

因此我们希望这个推理引擎尽可能好和精确,因此我们将它设置为0,消除任何可能出现的不确定性,接下来加载一些工具,将加载两个工具:llm数学工具和维基百科工具。

llm数学工具实际上是一个链本身,结合语言模型和计算器解决数学问题。
维基百科工具是一个API,连接到维基百科,允许您对维基百科运行搜索查询并获取结果。

接下来初始化一个代理,将使用工具初始化代理。

语言模型,然后输入代理类型,我们将使用chat零射反应描述。

注意这里首先是chat,这是一个优化与聊天模型合作的代理。

其次是react,这是一种设计用来从语言模型中获得最佳推理性能的提示技术。

我们还将传入handle_parsing_errors等于true。

当语言模型可能输出无法解析的内容时,这很有用,嗯,无法解析成动作和动作输入。

这是期望的输出,当这种情况发生时。

实际上我们会将格式错误的文本传回语言模型,并要求它纠正自己。

最后我们将传入verbose等于true,这将在jupyter笔记本中打印出很多步骤,使我们非常清楚,正在发生什么,我们稍后将在笔记本的全球级别设置debug等于true。

这样我们可以更详细地了解到底发生了什么,首先我们将向代理询问一个数学问题,三百的百分之二十五是多少。

这是一个相当简单的问题,但了解确切发生了什么将是有益的,因此,我们可以看到,当它进入代理执行链时。

它首先考虑需要做什么。

所以它有一个想法。
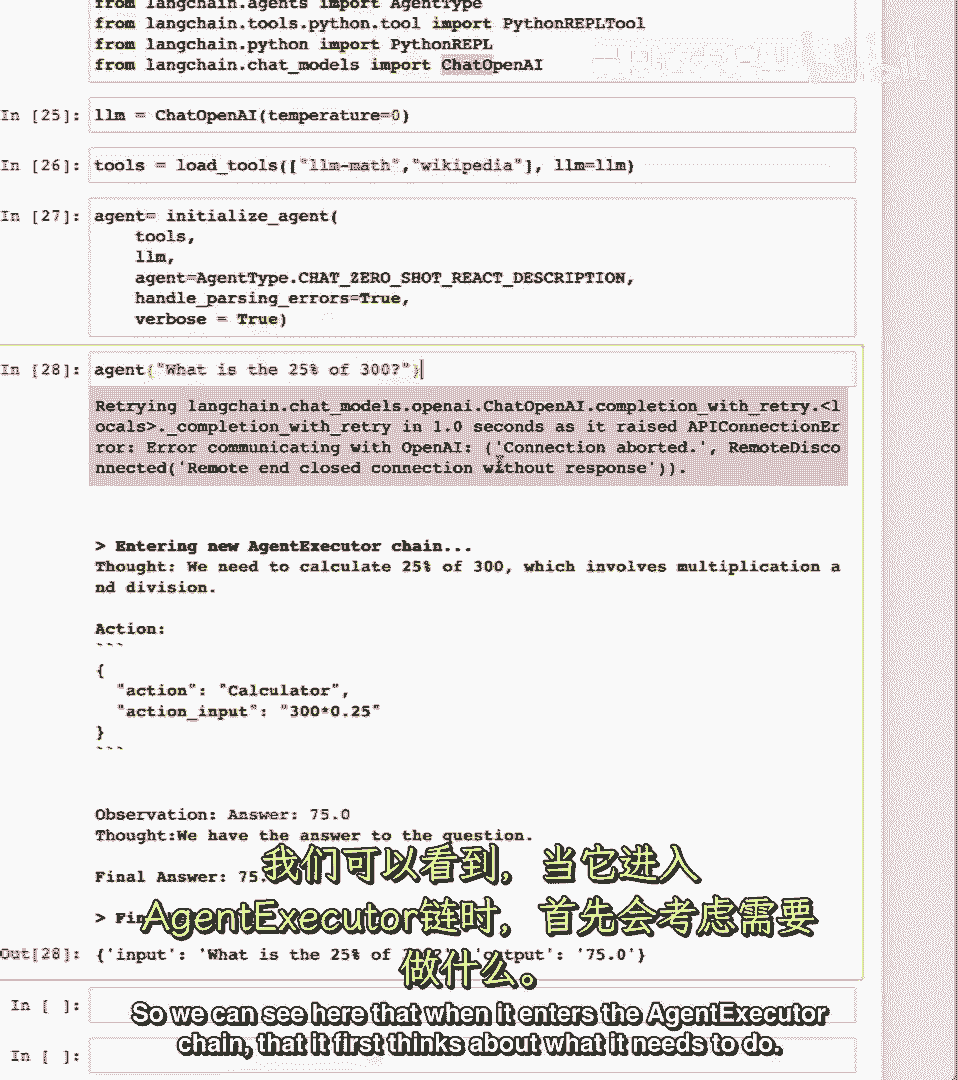
然后它有一个动作,这个动作实际上是一个块,对应两个东西,一个动作和一个动作输入,动作对应要使用的工具。

所以这里是计算器,动作输入是该工具的输入。
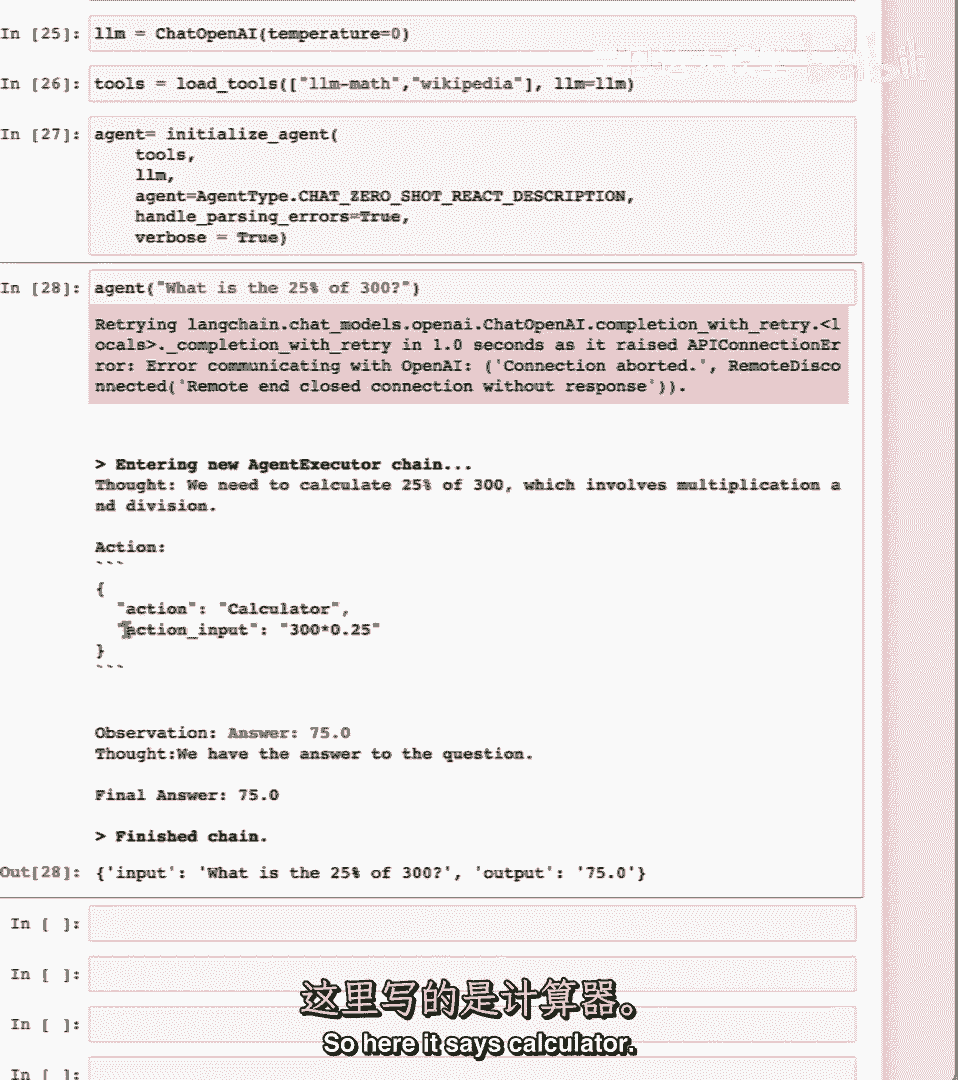
这里它是三百乘以点二五的字符串,接下来我们可以看到,带有答案的观察以不同的颜色出现。
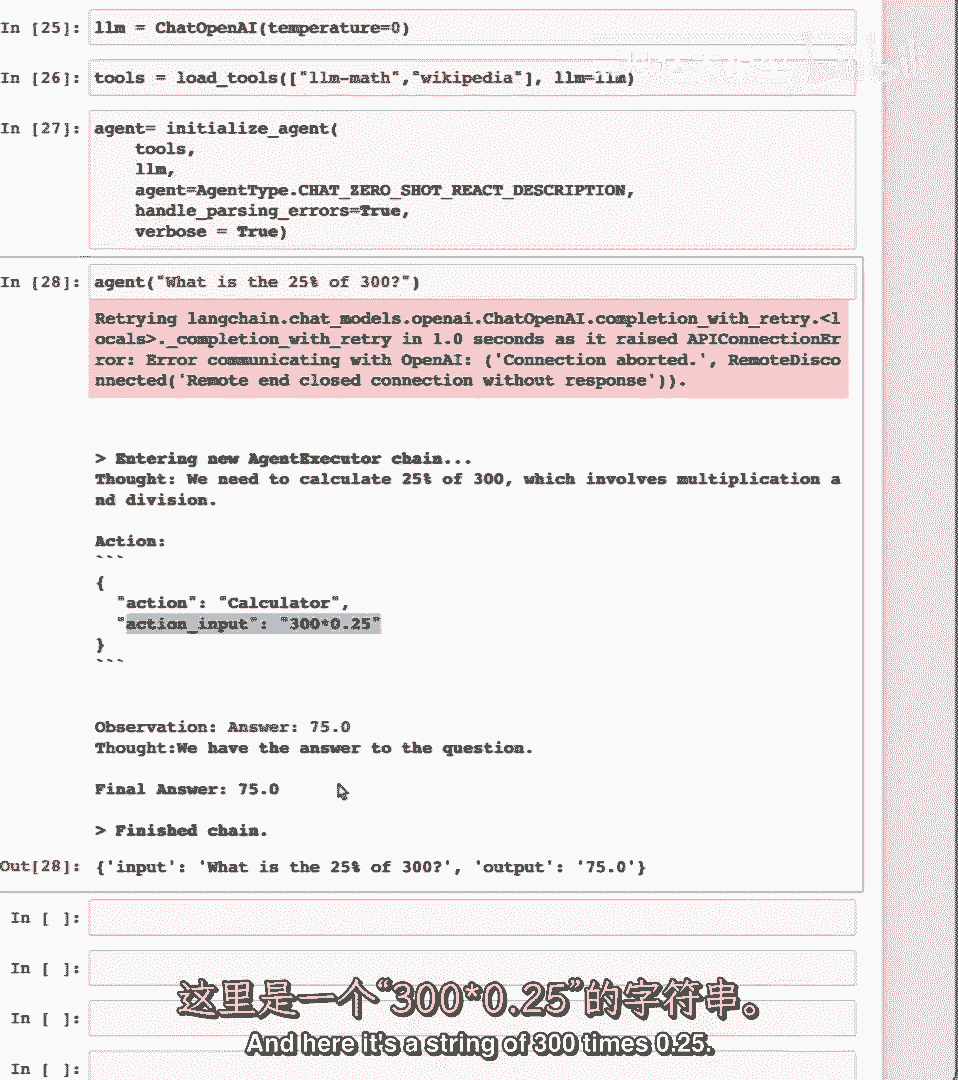
这个观察答案等于七十五点零实际上是来自计算器工具本身。

接下来我们回到语言模型,当文本变成绿色时。

我们有问题的答案,最终答案,七十五点零,这是我们得到的输出,现在是一个暂停并尝试自己不同数学问题的好时机,接下来我们将通过wikipedia api的例子,这里我们将问你关于汤姆·米切尔的问题。

我们可以查看中间步骤来了解它做了什么。

我们可以再次看到它思考。

并且它正确地意识到应该使用wikipedia,它说动作等于wikipedia,动作输入等于汤姆·米切尔。

这次观察以黄色返回,我们使用不同的颜色来表示不同的工具,注意这里首先是chat,这是一个优化与聊天模型合作的代理,维基百科汤姆·米切尔页面的总结结果,从维基百科返回的观察结果是两个结果,两个页面。
因为有两位不同的汤姆·米切尔,我们可以看到第一个页面涵盖了计算机科学家,第二个页面,看起来是一位澳大利亚足球运动员,我们可以看到回答这个问题所需的信息,即他写的那本书的名字。
机器学习出现在第一个汤姆·米切尔的摘要中,我们可以看到接下来代理试图查找更多关于这本书的信息,所以它查找了维基百科上的机器学习书籍,这并不严格必要,这是一个有趣的例子,展示了代理并不完全可靠。
但我们可以看到在这次查找之后,代理意识到它拥有所有需要回答的信息,并回答了正确的答案,机器学习,接下来我们要看的是一个很酷的例子,如果你见过像Copilot或带有代码解释器插件的Chat GPT。

他们正在使用语言模型编写代码,然后执行该代码。

我们在这里可以做完全相同的事情,所以我们要创建一个Python代理,并且我们将使用之前相同的LLM,我们将给它一个工具,Python REPL工具,REPL基本上是一种与代码交互的方式。
你可以把它想象成一个Jupyter笔记本,所以代理可以使用这个REPL执行代码,它将运行。

然后我们会得到一些结果,这些结果将被返回给代理,所以它可以决定接下来做什么。

我们要让这个代理解决的问题是。

我们将给它一个名字列表,然后要求它按姓氏排序,所以你可以看到这里。

我们有一个名字列表,哈里森,蔡斯,语言链LLM,杰夫,融合变压器,生成AI。

我们将要求代理首先按姓氏排序这些名字,然后按名字排序。

然后打印输出,重要的是我们要求它打印输出,这样它实际上可以看到结果是什么。

以便它可以决定接下来做什么。

这些打印的语句稍后将回传给语言模型,以便它能推理刚运行的代码的输出。

让我们试试,进入代理执行链时。

它首先意识到可以使用sorted函数列出客户。


内部使用了不同类型的代理,这就是为什么动作和动作输入的格式略有不同,这里,它采取的行动是使用Python REPL,你可以看到动作输入实际上是代码,首先写出客户,等于这个列表,然后对客户排序。
然后遍历这个列表并打印。

你可以看到,代理考虑要做什么并意识到需要编写一些代码,动作和动作输入的格式与之前略有不同。

它使用的是内部不同的代理类型来执行动作,它将使用Python REPL,对于动作输入,它将有一堆代码,所以如果我们看看这段代码在做什么,它首先创建一个变量来列出这些客户名称。
然后对它排序并创建一个新的变量。

然后遍历这个新变量并打印每行。

就像我们要求它做的,我们可以看到我们得到了观察结果,这是一个名字列表。

然后代理意识到它完成了并返回这些名字,从打印出的内容中,我们可以看到正在发生的高层情况。

但让我们深入一点并使用lane chain debug运行,设置为true,因为这会打印出所有不同链的所有级别的所有内容,让我们看看它们到底在做什么,所以首先我们从代理执行器开始,这是顶级代理运行器。
我们可以看到我们这里有,我们的输入,按姓氏和名字排序客户,然后打印输出,从这里我们调用一个llm链。

这是代理使用的lm链,所以lm链记住了一个提示和lms的组合,此时它只在代理草稿中有输入,我们稍后会回到这一点,以及一些停止序列来告诉语言模型何时停止生成,在下一级,我们看到对语言模型的确切调用。
所以我们可以看到完全格式的提示,它包括关于它可访问的工具的说明以及如何格式化其输出的说明,从那里可以看到语言模型的确切输出,可以看到文本键,包含思想和行动,并将所有内容放入一个字符串。
然后它通过那里结束llm链,接下来它调用的是一个工具,可以看到工具的确切输入。

也可以看到工具的名称,Python repl,然后可以看到输入,即这段代码,然后可以看到该工具的输出,即打印出的字符串,同样,这是因为特别要求Python repl打印出正在发生的事情。
然后可以看到下一个输入到llm链,这里如果看变量,llm链是代理,所以这里,如果看变量,输入未改变,这是我们要求的高层目标,但现在agent scratch pad有一些新值。
可以看到这是之前生成的组合加上工具输出,并将此返回,以便语言模型理解之前发生了什么并使用它来推理接下来要做什么,接下来的几个打印语句涵盖了,当语言模型意识到它基本上完成了工作时会发生什么。
可以看到完全格式的语言模型提示,响应,它意识到它已经完成。

并说最终答案,这里是代理用来识别它已经完成工作的序列,然后可以看到它退出llm链然后退出代理执行器,这应该能让你很好地了解内部发生了什么,在这些代理中。

这应该能让你很好地了解内部发生了什么,并且希望是有指导意义的,当你暂停并设置自己的编码代理目标时,试图完成。

这种调试模式也可以用来突出显示哪里出了问题,如上面的维基百科示例所示。

有时代理行为有点古怪,所以拥有所有这些信息对于理解正在发生的事情真的很有帮助。

到目前为止,我们使用了LinkedIn上已经找到的工具。

但代理的一大力量是你可以将其连接到你自己的信息源,你自己的API,你自己的数据。
所以这里我们将介绍如何创建自定义工具,以便你可以将其连接到你想要的一切。

让我们先做一个工具,它会告诉我们当前日期。

我们将导入这个工具装饰器,这可以应用于任何函数,并将其转换为LinkedIn可以使用的工具。

我们要写一个函数,叫time,它在任何文本字符串中震动,我们实际上不会使用它,它将通过调用date time返回今天的日期。

除了函数名外,我们还将编写一个非常详细的文档字符串。

因为这就是代理将用来知道何时应该调用此工具的原因。

以及如何调用此工具,例如,这里我们说输入应该始终为空字符串,因为我们不使用它,如果我们对输入应该有更严格的要求。

例如,如果我们有一个函数应该始终接受搜索查询或SQL语句。

您将希望确保在这里提及这一点,我们现在将创建另一个代理,这次我们将时间工具添加到现有工具列表中。

最后让我们调用代理并询问它今天的日期。

它认识到需要使用时间工具,在这里指定,它有动作输入为空字符串,这很好,这是我们告诉它要做的,然后它返回一个观察结果,然后最终语言模型取该观察结果并响应用户,今天日期是2023年,05月,21日。
在这里暂停视频并尝试输入不同内容,代理课程结束,这是长链中较新、更令人兴奋和更实验性的一部分,希望你喜欢使用它,希望它展示了如何使用语言模型作为推理引擎。

LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P32:8——总结 - 吴恩达大模型 - BV1gLeueWE5N
在这门短课中,你看到了一系列应用。

包括处理客户评论和构建回答文档问题的应用程序,嗯,甚至使用lm决定何时调用外部工具,如网络搜索以回答复杂问题,如果一两周前有人问你,构建所有这些应用程序需要多少工作,我想很多人会想,天啊。
这听起来像几周,你知道,甚至更长时间的工作,但在这门短课中,我们只用了一些合理的代码行,你可以使用lang chain高效构建所有这些应用程序,所以我希望你能接受这些想法。
也许你可以使用一些你在jupyter笔记本中看到的代码片段,并在你自己的应用程序中使用它们,这些想法只是开始,你可以使用语言模型进行许多其他应用,因为这些模型非常强大,因为它们适用于如此广泛的任务。
无论是回答关于CSV的问题,查询SQL数据库,与API交互,有很多使用chains的不同示例,以及提示和输出解析器的组合,然后更多的链在lang chain中做所有这些事情。
而这大部分归功于langing社区,所以我也想向社区中的每个人表示衷心的感谢,无论是谁做出了贡献,无论是改进文档,还是让其他人更容易开始,或新的链类型开启了一个全新的可能性世界。

所以就这样,如果你还没有这样做,我希望你打开你的笔记本电脑,你的台式机和运行pip,安装lang chain。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P33:《LangChain:构建与数据对话的聊天机器人》1——介绍 - 吴恩达大模型 - BV1gLeueWE5N

你好,很高兴与你分享,使用线链与数据聊天的全新课程,与Harrison Chase合作开发,他是Lang Chain的联合创始人兼CEO,大型语言模型(如ChatGPT)可以回答许多主题的问题。
但一个孤立的大型语言模型只知道它被训练的内容,不包括你的个人数据,比如你在公司,有专有文档,不在互联网上,以及大型语言模型训练后撰写的数据或文章,若对你或他人有用,比如你的客户。
能与你的文档对话并解答问题,利用那些文档的信息和本课程中的LM,我们将涵盖如何用Link Chain与数据聊天,Link Chain是一个开源开发者框架,用于构建LLM应用。
Link Chain由多个模块化组件和更多端到端模板组成,Link Chain中的模块化组件包括提示,模型,索引,链条和代理,深入了解这些组件,可查看我与安德鲁合上的第一门课,在这门课中。
我们将深入聚焦lang chain的一个流行用例,如何用lang chain与数据聊天,首先将介绍如何使用lang chain文档加载器,从各种激动人心的来源加载数据。
然后将触及如何将这些文档分割为有意义的语义块,这个预处理步骤看似简单,但含义丰富,接下来,将概述语义搜索,获取相关信息的基本方法,给定用户问题,这是入门最简单的方法,但有几个情况会失败,将讨论这些情况。
然后讨论如何修复,然后展示如何使用检索文档,使LLM回答文档问题,但显示你缺一关键,为完全重现聊天体验,最后将涵盖缺失部分记忆,展示如何构建完全功能的聊天机器人,通过它,你可以与数据聊天。
这将是一门激动人心的短期课程,我们感谢安哥拉,以及兰斯·马丁,来自Lang Chain团队的,为哈里森稍后呈现的所有材料工作,以及深度学习,艾赛杰夫。

路德维希和迪亚拉·艾恩,如果你正在学习这门课程,并决定想复习一下语言链的基础,我鼓励你也要参加那个早期的语言链短课程,对于哈里森提到的LM应用开发,但就这些,我们现在继续下一个视频,在那里。
哈里森将向你展示如何使用。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P34:2——文档加载 - 吴恩达大模型 - BV1gLeueWE5N

为了创建一个你可以与你的数据进行交流的应用程序,首先,你需要将你的数据加载到一个可以工作的格式中,这就是长链文档加载器发挥作用的地方,我们拥有过八十种不同类型的文档加载器,在本课程中。
我们将覆盖一些最重要的加载器和让你熟悉这个概念,总的来说,让我们开始,文档加载器处理访问和转换数据的具体细节,从各种不同格式和来源转换为标准化格式,我们可以从像网站这样的不同地方加载数据,不同的数据库。
Youtube,而且这些文档可以以不同的数据类型出现,如pdfs。

Html json,而且,而且所以,文档加载器的整个目的是从这种数据源的多样性中提取,并将它们加载到一个标准的文档对象中,它由内容和相关的元数据组成。

链式链接中有很多不同类型的文档加载器,我们没有时间覆盖它们全部。
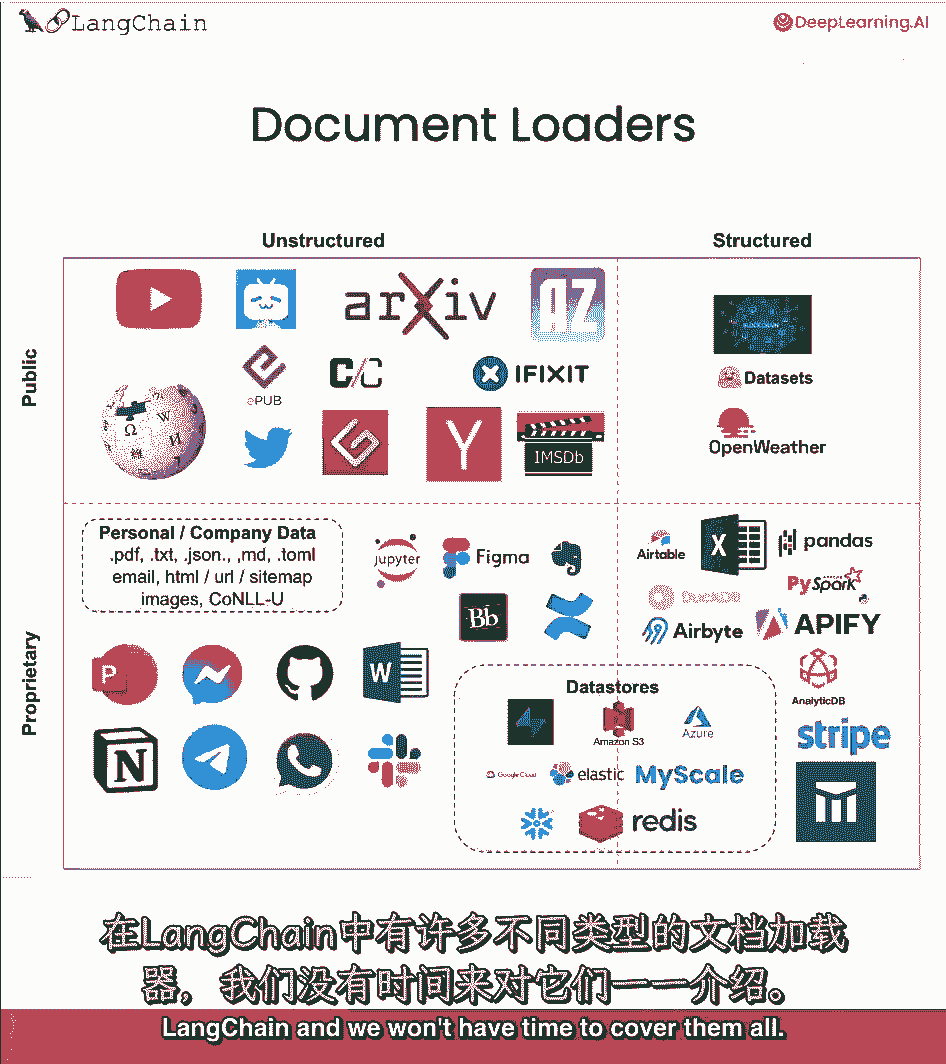
但是,以下是对八十个的大致分类,再加上我们有很多处理非结构化数据的,如来自公共数据源如YouTube的文本文件。
Twitter,Hacker News,而且还有更多的处理非结构化数据的,来自你可能或你的公司拥有的专有数据源如Figma Notion的,文档加载器也可以用于加载结构化数据,表格格式的数据。
其中可能只有一些文本数据存在于这些单元格或行中,你仍然想要问的问题,回答,或语义搜索,因此,这里的来源包括像airbyte这样的东西,Stripe,Airtable。
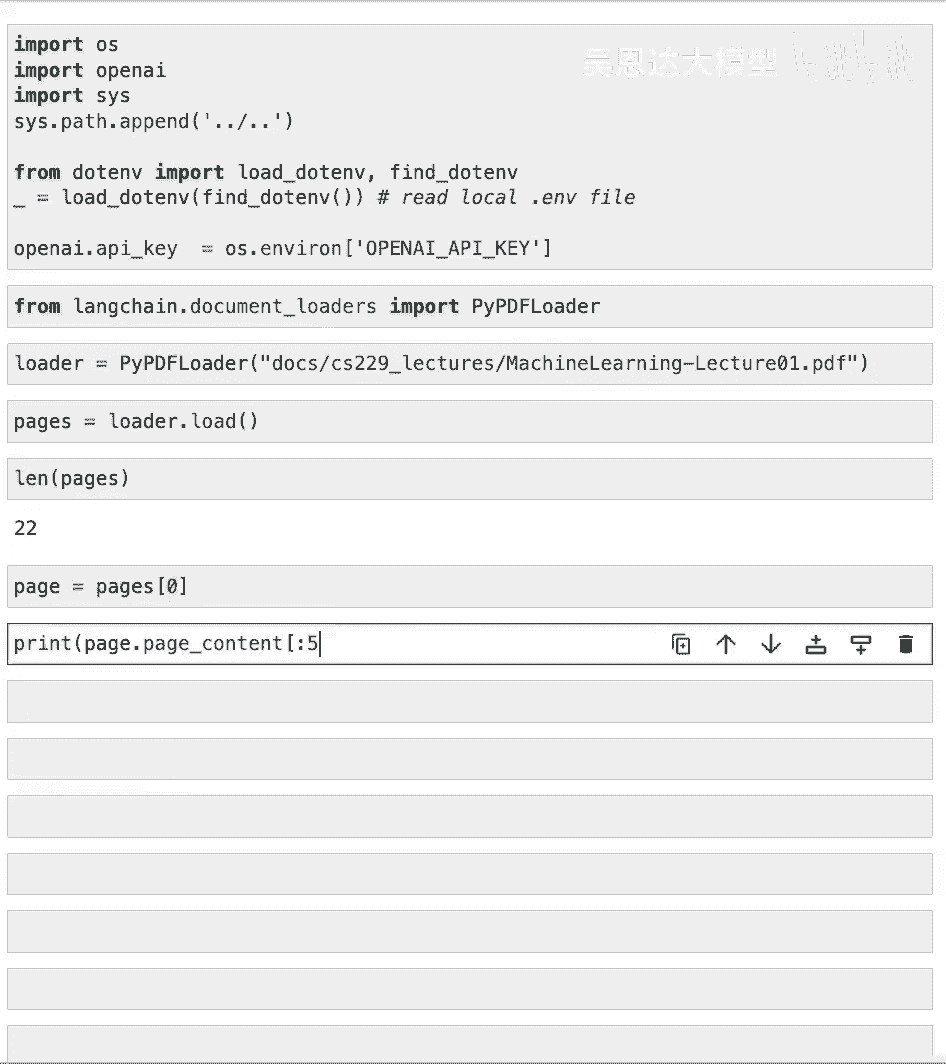
好了现在,让我们进入有趣的部分,实际上在使用文档加载器,首先,我们将加载一些我们需要的环境变量,如openai api密钥,我们首先将处理的文档类型设置为pdfs。
所以让我们从long chain中导入相关的文档加载器,我们将使用pi pdf floater,我们已经将许多pdfs加载到工作空间的文档文件夹中。

因此,让我们选择一份并将其放入加载器中,现在,让我们通过调用load方法加载文档,让我们看看实际上我们加载了什么,所以这,默认情况下,将加载一份文档列表,在这种情况下,这个pdf中有二十二个不同页面。
每个都是一个独特的文档,让我们来看看第一个并看看它包含什么,文档首先包含一些页面内容,这是页面的内容,这可能有点长,所以让我们只打印出前几百个字符。
另一个非常重要的信息是与每个文档相关的元数据,这可以通过元数据元素访问。

你可以在这里看到有两个不同的部分,一个是源信息,这是pdf,我们从其他地方加载它的文件名是页面字段,这对应于pdf的页面,它是我们从我们将要查看的下一种文档加载器加载的,是一种从youtube加载的。
youtube上有很多有趣的内容,因此,很多人使用这种文档加载器来提问,对他们的最爱视频或讲座,或类似的东西。

我们将在这里导入一些不同的东西,关键的部分是youtube音频加载器,这从youtube视频中加载音频文件,另一个关键部分是openai whisper解析器,这将使用openai的whisper模型。
一种语音到文本模型,将youtube音频转换为我们可以工作的文本格式。

我们现在可以指定一个URL。

指定一个保存音频文件的目录,然后创建通用加载器作为这个youtube音频加载器,与openai whisper解析器的组合,然后我们可以调用loader点load来加载与这个youtube相应的文档。
这可能需要几分钟,所以我们要加速并发布,现在加载完成后。

我们可以查看加载的页面内容,这是来自youtube视频的第一部分转录,这是一个好的时间暂停,去选择你最喜欢的youtube视频,看看这个转录是否对你有用。

我们接下来要讨论的一组文档。
如何加载来自互联网的URL,互联网上有很多真的很棒的教育内容,难道不酷,如果你能只是聊天,我们将通过导入link chain中的web基加载器来使能这一点。

然后我们可以选择任何URL,我们这里的 favorite URL,我们将从这个github页面上选择一个markdown文件,并创建一个加载器。

然后接下来我们可以调用loader点load,然后我们可以查看页面的内容。

在这里你会注意到有很多空白。

紧随其后是一些初始文本和一些更多的文本,这是一个很好的例子,说明你为什么实际上需要处理信息的后处理,以便将其转换为可工作的格式。

最后我们将覆盖如何从notion加载数据,Notion是一个非常流行的个人和公司数据的存储库。
并且很多人已经创建了与笔记本中的 notion 数据库对话的聊天机器人,你将看到如何从 notion 数据库中导出数据的指示,通过这种方式,我们可以将其加载到链接链中,一旦我们以那种格式有了它。
我们可以使用 notion 目录加载器来加载那个数据,并获取我们可以工作的文档。

如果我们看看这个内容,我们可以看到它是在 markdown 格式中,并且这个 notion 文档来自 blend 的员工手册,我相信正在听的很多人已经使用了 notion。
并且他们有一些他们想要聊天的数据库。

因此,这是一个将数据导出的绝佳机会。

把它带到这里,开始在这种格式中工作,这就是文档加载的全部,我们已经覆盖了如何从各种来源加载数据,并将它转换为标准化的文档界面,然而,这些文档仍然相当大。

因此,在下一节中,我们将讨论如何将它们分成较小的部分,这是有关和重要的,因为当你在进行这种增强的生成检索时,你需要检索出最相关的内容片段,所以你不想选择我们这里加载的所有文档,而是只选择段落。
或与你谈论的主题最相关的几句话,这也是一个更好地思考数据来源的机会,我们目前还没有为这些数据源加载器的,但你可能仍然想要探索谁知道。

也许你可以甚至做出一个pr来链接。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P35:3——文档分割 - 吴恩达大模型 - BV1gLeueWE5N

我们刚刚讨论了如何将文档加载到标准格式中,现在,我们将讨论如何将它们分成较小的片段,这可能听起来非常容易,但是,这里有许多微妙之处,它们对后来的影响很大,让我们开始吧。
文档分割发生在您将数据加载到文档格式后,但在它进入向量存储之前,这可能看起来非常简单,您可以根据每个字符的长度或其他类似的方式分割片段。
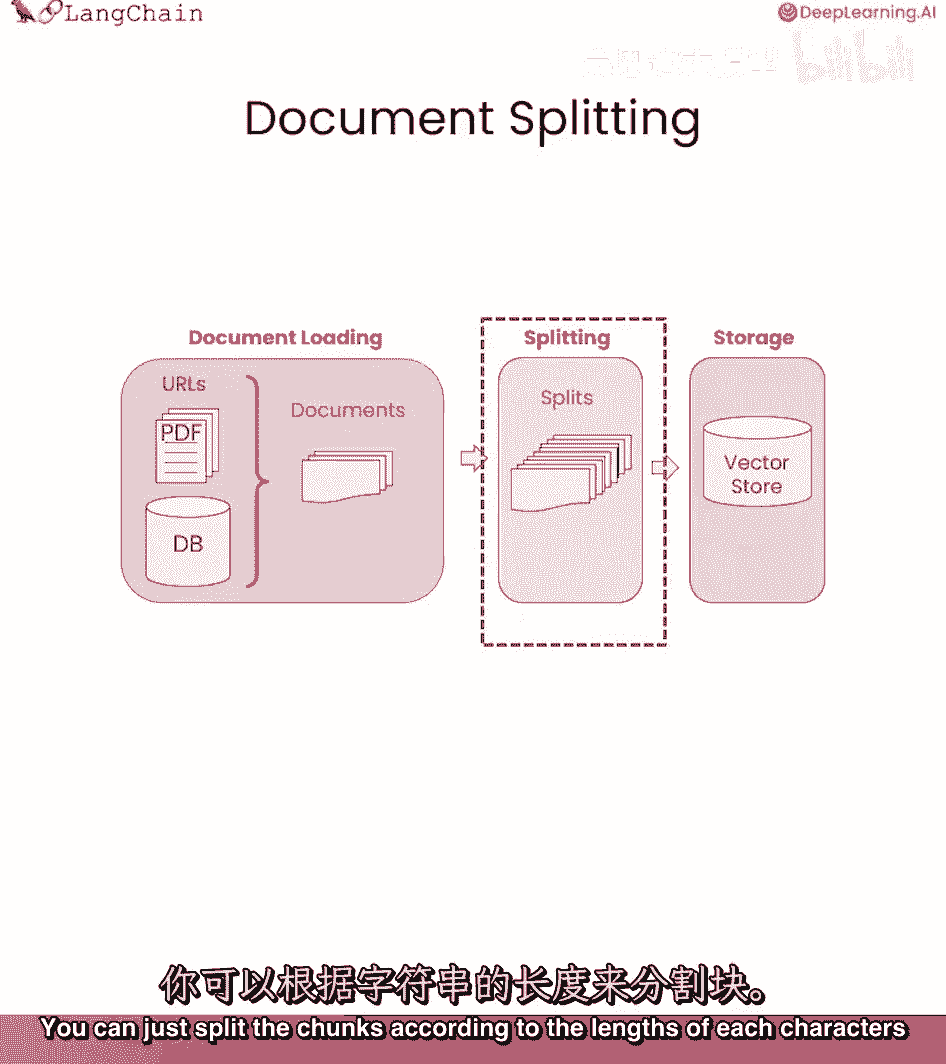

但是,作为为什么这既更复杂又非常重要在下游的原因的示例,让我们看看这个例子在这里,我们中有一个关于丰田卡罗拉的句子和一些规格。

如果我们进行简单的分割,我们可能会得到一个句子的一部分在一个片段中,句子的另一部分在另一个片段中,然后,当我们在下游尝试回答问题时。

关于卡罗拉的规格是什么。

我们实际上在任一个片段中都没有正确的信息,所以它被分割开来,因此,我们无法正确地回答这个问题,因此,如何在分割片段时如何处理有许多微妙和重要性,以便将语义相关的片段组合在一起。

所有在lane chain中的文本分割器都基于分割片段,在某个片段大小和一些片段重叠下。

所以我们这里有一个下面的图表来显示这看起来像什么,片段大小对应于片段的大小,片段的大小可以以几种不同的方式测量,我们在课程中会讨论一些,因此,我们允许传递一个长度函数来测量片段的大小。
这通常是字符或标记,片段重叠通常被保持为一些重叠在两个片段之间,就像我们在从一个到另一个移动时滑动的窗口,这允许同一部分上下文在片段的末尾,并在另一个片段的开始,并帮助创建一些一致性的概念。
文本分割器和lane chain都有创建文档和分割文档的方法,这涉及到相同的逻辑在内部,它只是暴露了一个稍微不同的用户界面。

一个接受文本列表,另一个接受文档列表,lane chain中有许多不同类型的分割器,我们在这门课程中会覆盖一些,但我鼓励你在空闲时间检查其余的,这些文本分割器在许多维度上差异很大。
它们可以差异于如何分割片段,哪些字符进入那个,它们可以差异于,如何测量片段的长度,是按字符,是按标记,甚至有一些使用其他较小的模型来确定句子的结束可能何时,并且将其用作分块方式。

分块成片段的另一个重要部分也是元数据。

在所有片段中保持相同的元数据,但在相关时也添加新的元数据,因此,有些文本分割器真的很专注于这一点。

片段的分割往往特定于,我们正在处理的文档类型。

这在您在代码上分割时尤为明显,所以我们有一个语言文本分割器,有许多不同的分隔符。

用于各种不同的语言。

如Python,Ruby c,当分割这些文档时,它将考虑这些不同的语言和这些语言的相关分隔符。

在执行分割时,我们将首先按照之前设置环境,加载Open AI API密钥。

接下来,我们将导入两种最常见的文本分割器和长链。
递归字符文本分割器和字符文本分割器,我们将首先尝试一些玩具用例,只是为了了解这些做什么,因此,我们将设置一个相对较小的片段大小为二十六。

和一个甚至更小的片段重叠为四,只是为了看到它们可以做什么。

让我们初始化这两个不同的文本分割器为r_splitter和c_splitter,然后,让我们看一些不同的使用案例。

让我们加载第一个术语,从a到z的所有字母,让我们看看当我们使用各种分割器时发生了什么。

当我们使用递归字符文本分割器时。

它仍然只是一个字符串,这是因为这有二十六个字符长,我们已指定片段大小为二十六,因此,实际上在这里甚至不需要进行任何分割,让我们在稍长的字符串上进行分割,它比我们指定的二十六个字符的片段大小更长,在这里。
我们可以看到创建了两个不同的片段,第一个片段以z结束,所以这是二六字符,我们可以看到下一个片段从w开始,X,Y,Z,这些是四个片段重叠,然后,它继续与字符串的其余部分,让我们看一个稍微更复杂的字符串。

其中字符之间有许多空格,我们现在可以看到它被分割成三个片段,因为有空格,所以它占用更多的空间,因此,如果我们看重叠,我们可以看到在第一个中,有llm,然后在第二个中也有l和m,这似乎只有两个字符。
但是因为在l和n之间有空格,然后在l前面和m后面,实际上这相当于构成块重叠的四个字符,让我们现在尝试使用字符文本分割器。

我们可以看到当我们运行它时,它实际上并没有尝试在任何地方分割它,所以这里发生了什么,问题在于字符文本在一个字符上分裂。

并且默认那个字符是新行字符,但在这里没有新的,如果我们将分隔符设置为空白。

我们可以看到会发生什么,然后。

在这里它与以前相同分裂,这是一个暂停视频并尝试一些新例子的好时机,无论是用你创造的不同字符串,还是交换分隔符并看会发生什么,此外,尝试不同的块大小和块重叠也很有趣,所以,通过几个玩具示例。
你可以大致了解正在发生的事情,这样,当我们转向更真实的世界示例时,你对场景下发生的事情会有良好的直觉。

现在,让我们在更多的真实世界示例上尝试一下。

这里有一段很长的段落,我们可以看到,大约在这里我们有一个双行新符号。

这是段落之间的典型分隔符,让我们检查这段文本的长度。

"我们可以看到,它就大约是五百","现在让我们定义我们的两个文本分割器","我们将像以前那样与字符文本分割器合作","以空间作为分隔符","然后,我们将初始化递归字符文本分割器","并且。
这里是一个分隔符列表"。
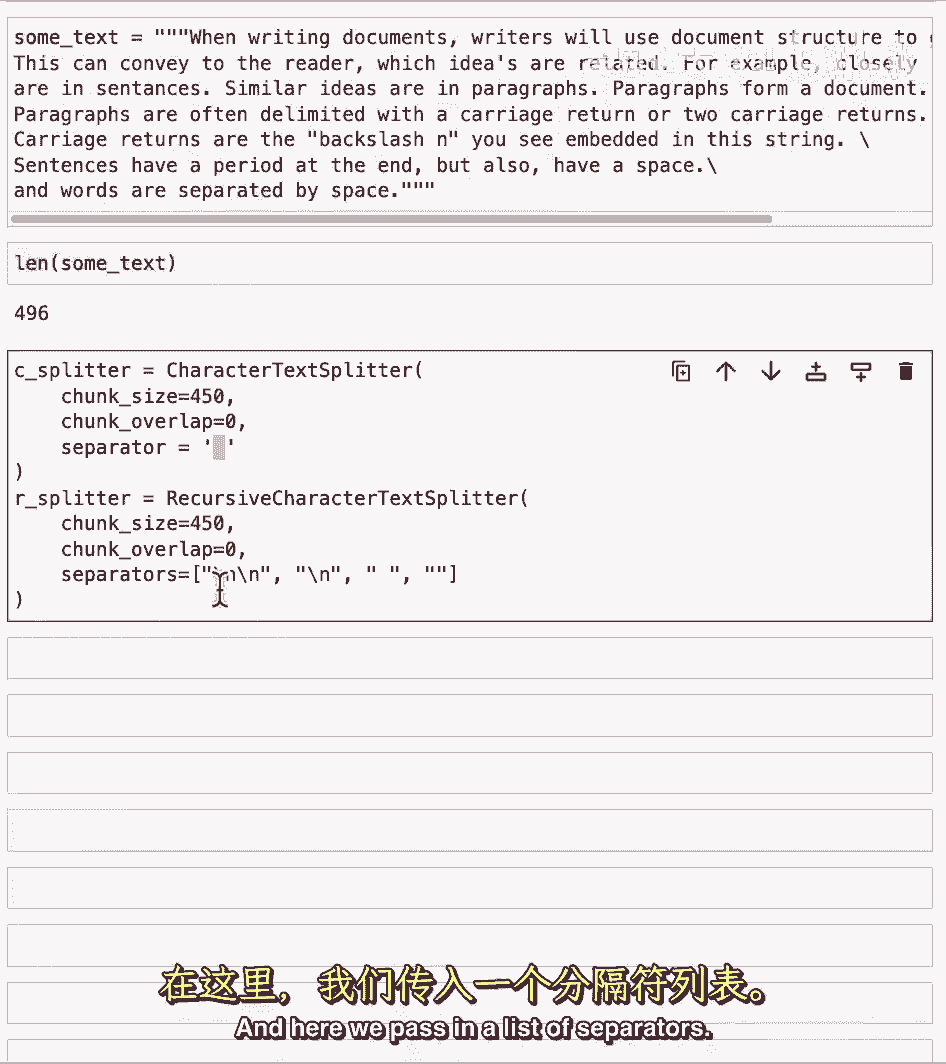
"这些是默认的分隔符","但我们只是把它们放在这个笔记本里,以更好地展示正在发生的事情"。
因此,我们可以看到,我们拥有一份包含双行空格的列表。"单行空格",然后什么,一个空的字符串,这些意味着当你在分割一段文本时,它会首先尝试按双行新符分割它,然后,如果它还需要进一步分割单个块。
它会继续按单行新符分割,然后,如果它还需要更多,它会继续到空格。
最后,它会只是按字符分割,如果它真的需要这样做,看这些在上述文本中的表现。

我们可以看到,字符文本分割器在空格上分裂。

因此,我们最终得到了句子中间奇怪的分隔。

递归文本分割器首先尝试在双行新线上分裂,因此,它将其分割成两个段落,尽管第一个段落比指定的四百五十个字符要短,这可能是一个更好的分割,因为现在,每个自己的段落都在块中,与在中间分割句子不同。
让我们现在将其分割成更小的块,只是为了更好地理解正在发生的事情,我们还将添加句号分隔符。
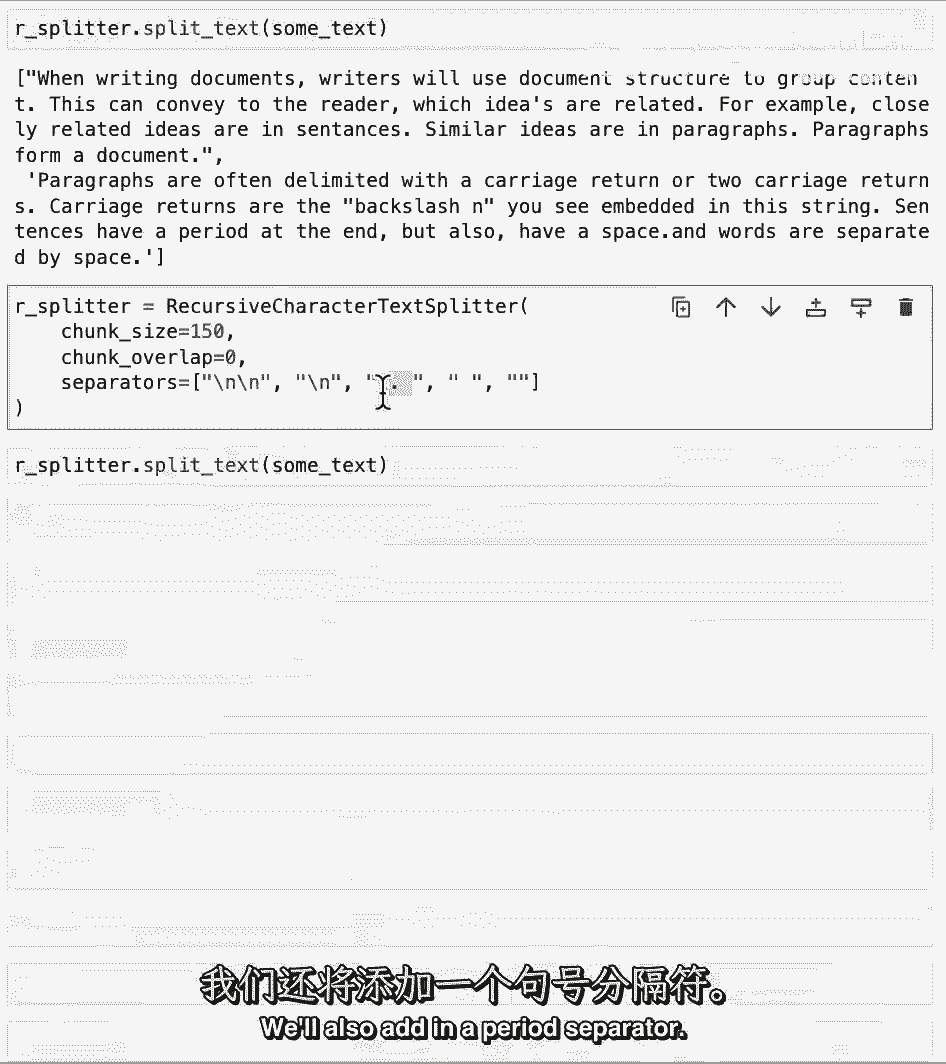
这是为了在句子之间分割,如果我们运行此文本分割器,我们可以看到按句子分割,但句号实际上在错误的位置,这是因为下面的正则表达式x在起作用,为了修复这个问题,我们可以实际上指定一个稍微更复杂的正则表达式x。
带有一个后视镜,现在如果我们运行这个,我们可以看到它被分割成句子,并且它以正确的方式分割,句号在正确的位置,让我们现在将这个应用到一个更真实的世界例子中。

与在第一个文档加载部分我们工作的一个pdf中,让我们加载它,然后让我们在这里定义我们的文本分割器这里我们传递长度函数,这是用lone的,Python内置的,这是默认的,但我们只是明确指定它以增加清晰度。

在幕后发生了什么,并且这正在计算字符的长度,因为我们现在要使用文档,我们使用split documents方法,并传递一个文档列表。
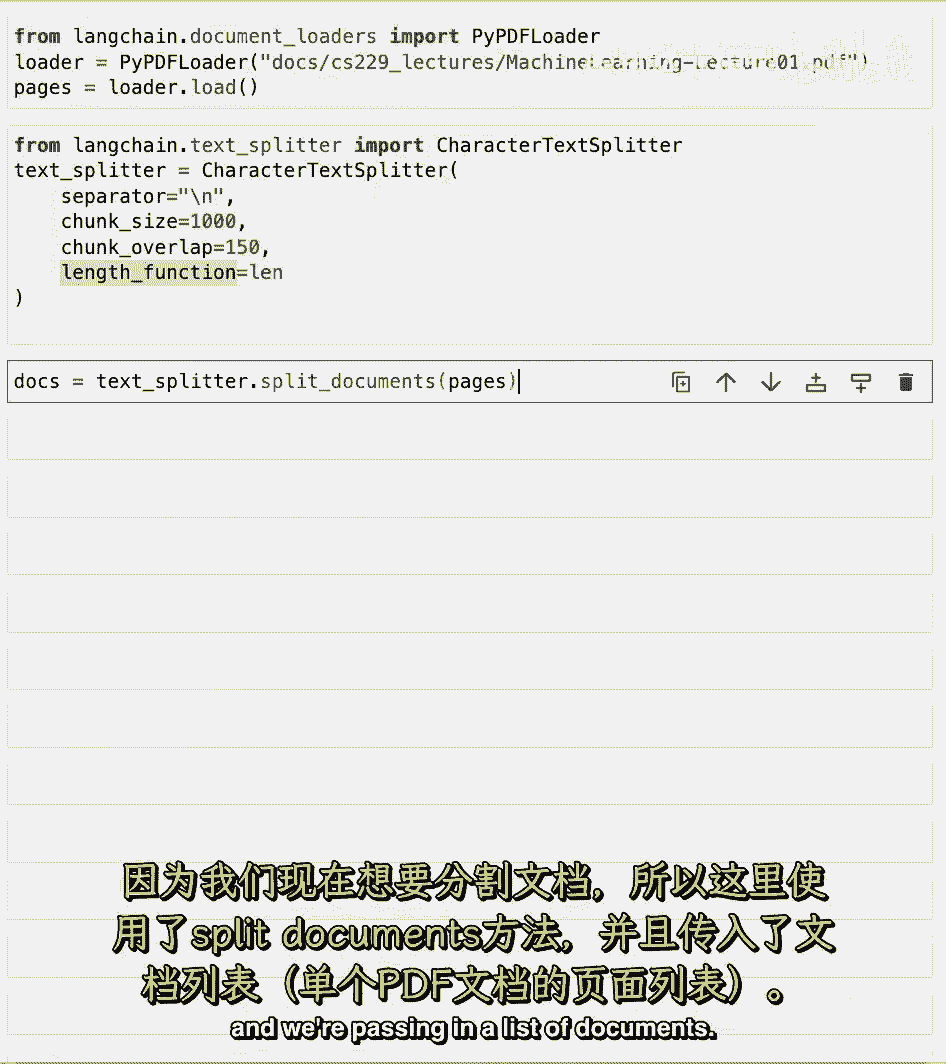
如果我们比较那些文档的长度与原始页面的长度。

我们可以看到创建了许多更多的文档。

作为这个分割的结果,我们可以对在第一次讲座中使用的概念db做类似的事情。

再次比较原始文档的链接与新的拆分文档。

我们可以看到有许多文档,现在,我们完成了所有分割,这是一个好暂停视频的点,尝试一些新的示例。

我们已经基于字符进行了所有分割,但还有其他一种分割方式,这是基于标记的,为了此,我们将导入标记文本分割器,这是因为经常LMS有上下文窗口,由标记数指定,因此,了解标记是什么以及它们出现在哪里很重要。

然后,我们可以基于它们进行分割,为了获得一个稍微更代表性的想法,看看llm如何看待他们,真正理解标记和字符之间的差异,让我们初始化标记文本分割器,以块大小为一,块重叠为零。
所以这将将任何文本分割为一个标记列表,让我们创建一个有趣的虚构文本。
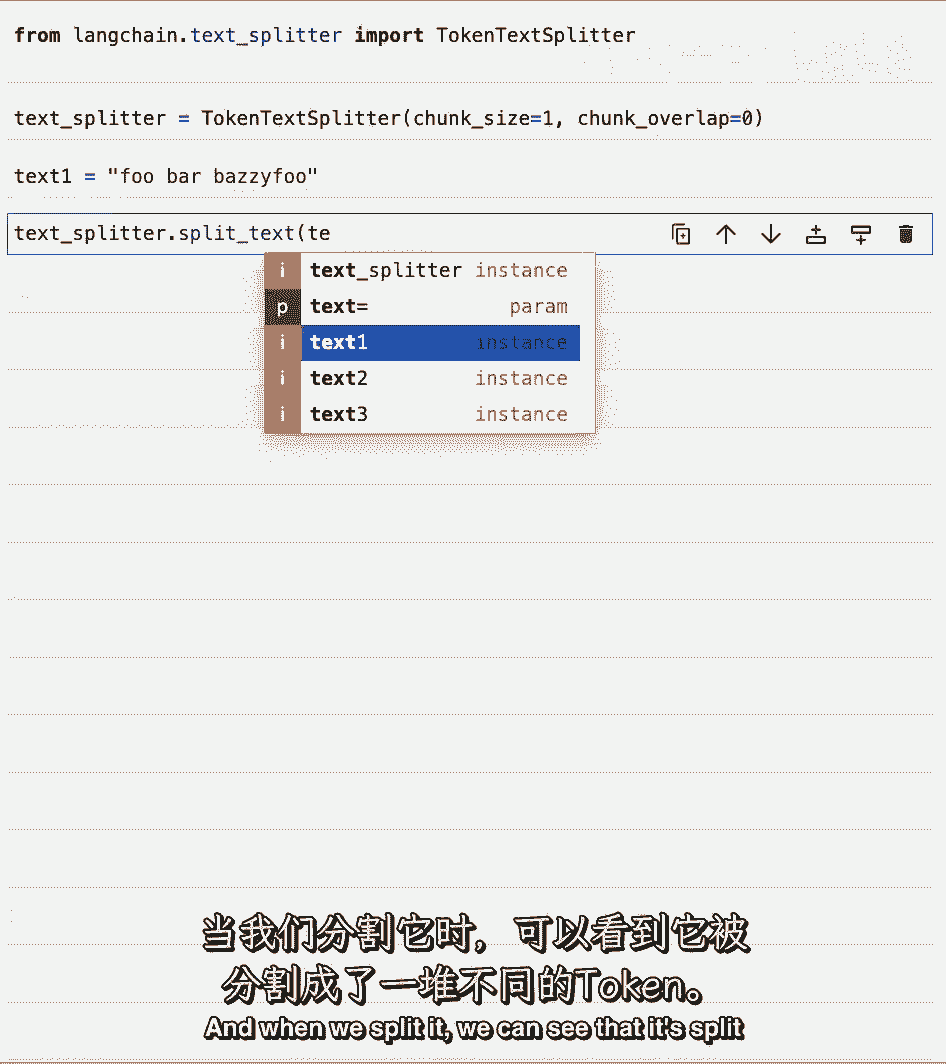
当我们分割它,我们可以看到它被分割成一堆不同的马克标记,并且它们在长度上都有所不同,以及它们内部的字符数量,所以第一个就是foo,然后你有一个空格然后bar,然后只有b有一个空格,然后一个z。
然后z然后foo又出现了,这显示了一下在字符分裂与标记分裂之间的一些差异,让我们将这个应用到我们上面加载的文档中,以类似的方式,以类似的方式,我们可以在页面上调用分割的文档。

如果我们看一下第一个文档,我们有我们的新分割文档,页面内容大致是标题,然后,我们有源文档和它来自的页面的元数据,在这里,你可以看到源文档的元数据,以及页面在块中与原始文档相同,因此,如果我们看那个。
只是为了确保页面零,元数据,我们可以看到它对齐,这很好,它将元数据适当地传递到每个块中,但也可能存在您实际上想要向块添加更多元数据的情况,在你分割它们时,这可以包含文档中的位置信息,块来自哪里。
它位于何处,相对于文档中的其他事物或概念,一般来说,这种信息可以在回答问题时使用,以提供关于这个块确切内容的更多上下文,以便看到,一个具体的例子,我们来看看另一种文本分割器,实际上。
它将信息添加到每个片段的元数据中,你现在可以暂停并尝试一些你自己想出来的例子。

这个文本分割器是Markdown标题文本分割器,它会做什么,它将根据标题或任何子标题分割Markdown文件,然后,我将将这些标题作为内容添加到元数据字段中。
这将被传递给来自那些分割的片段的任何其他片段。

让我们先做一个玩具示例,玩一玩文档,我们有一个标题,然后,第一章的子标题,然后我们在那里有一些句子,然后,另一个甚至更小的子标题的部分。

然后,我们跳回到第二章,在一些句子中,让我们定义一个我们要在文本上分割的标题列表,以及那些标题的名称,所以首先我们有一个单独的哈希标签,我们将其称为标题一,然后我们有两个哈希标签标题二。
三个哈希标签标题三。

我们可以然后使用这些标题初始化Markdown标题文本分割器,然后分割我们上面的玩具示例,如果我们看一些这些例子,我们可以看到第一个有一个内容hi,这是吉姆hi,这是乔,现在,在元数据中我们有标题一。
然后,我们将其作为标题,标题二作为第一章。
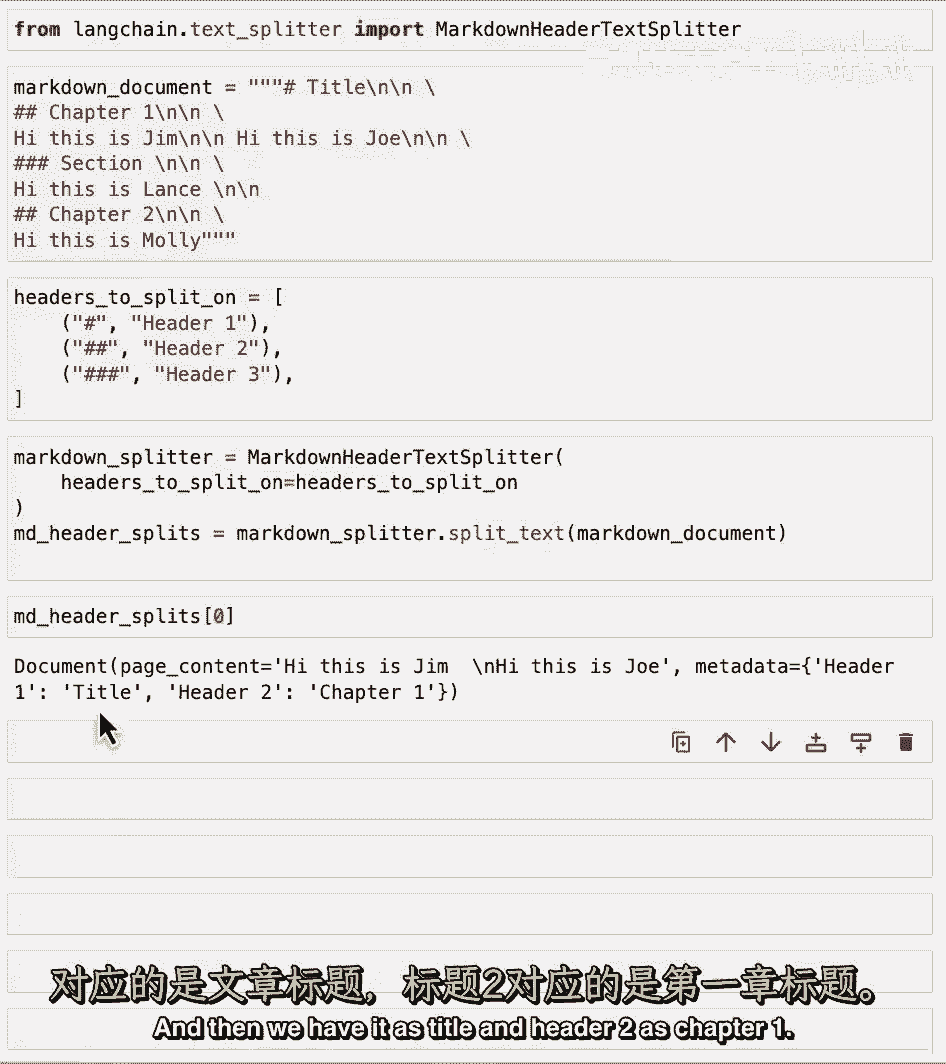
这是从这里来的。
在上述示例文档中,让我们看看下一个,在这里,我们可以看到我们已经跳入了一个甚至更小的子部分,所以我们有内容的hi,这是兰斯,现在我们不仅有标题一,还有标题二和标题三,这又从内容和名称中来。
在上述Markdown文档中。

让我们试试在真实世界的例子中,在加载Notion目录使用Notion目录加载器之前,并加载了Markdown文件。

这对于Markdown标题分割器是有关的,所以让我们加载那些文档,然后定义Markdown分割器,标题一为一个单独的哈希标签,标题二为两个哈希标签。

我们分割文本,得到我们的分割,如果看它们。

我们可以看到第一个有内容的一些页面,如果向下滚动到元数据,我们可以看到我们已经加载标题一作为Blendel的员工手册,我们已经覆盖了如何以适当的元数据获取语义相关的片段。
下一步是将这些数据片段移动到一个向量存储中。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P36:4——向量和嵌入 - 吴恩达大模型 - BV1gLeueWE5N

我们现在已经将文档分成了小的,语义上有意义的片段,现在是将这些片段放入索引的时候,这样我们就可以轻松地检索它们,当需要回答关于这个数据集的问题时,我们将利用嵌入和向量存储。
让我们看看那些是什么我们之前在之前的课程中简要覆盖了,但我们将再次回顾它,有几个原因。
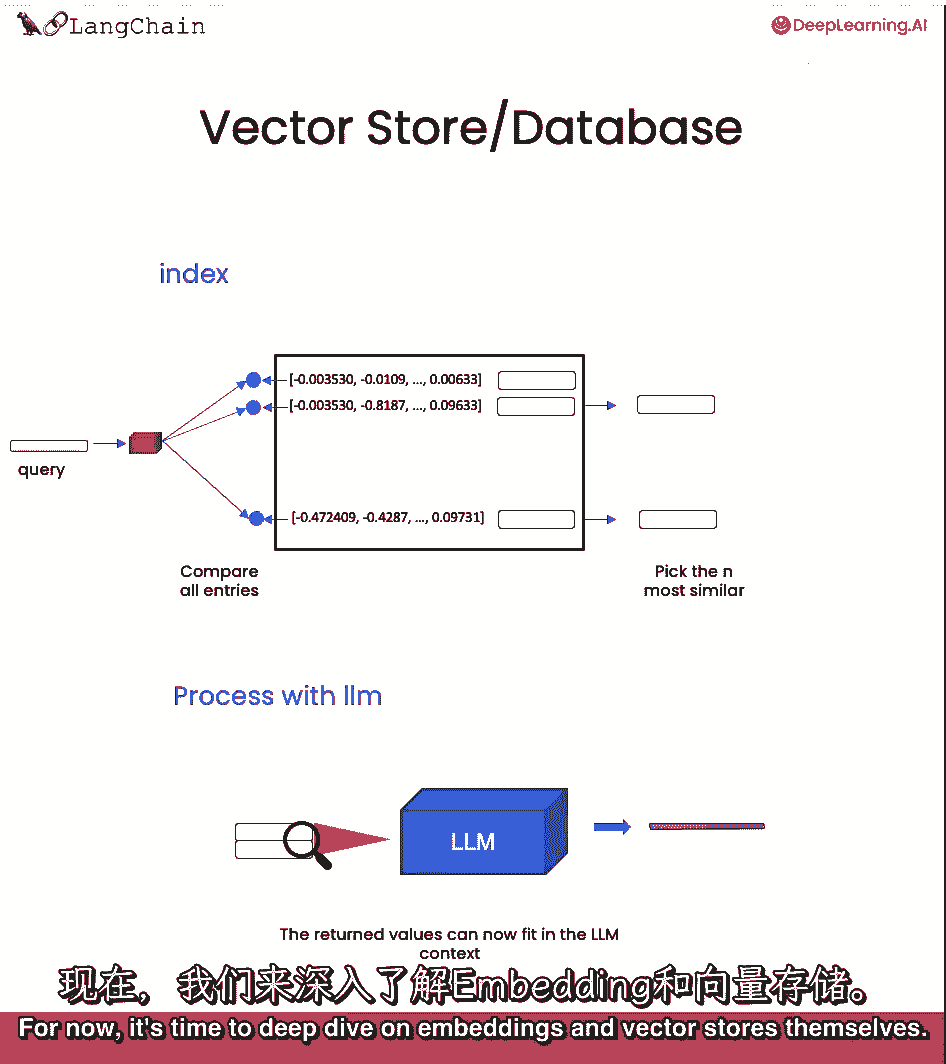
首先,这些对于在你的数据上构建聊天机器人来说至关重要。
其次,我们将深入探讨,并谈论边缘情况,以及这个通用方法实际上可以失败的地方。
不要担心,我们将在后来修复这些问题,但现在让我们谈谈向量存储和嵌入。
这发生在文本分割之后,当我们准备好以易于访问的格式存储文档时,什么是嵌入。
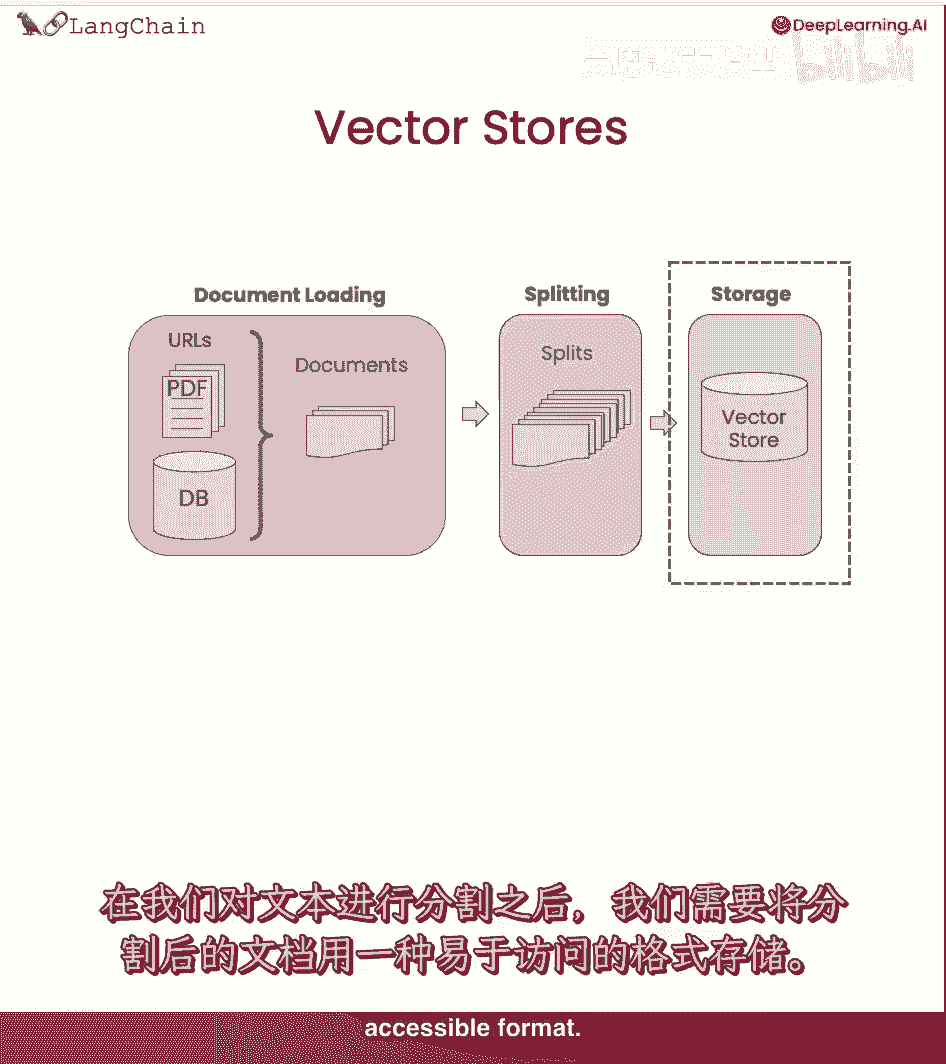
它们将一段文本,并创建该文本的数值表示。

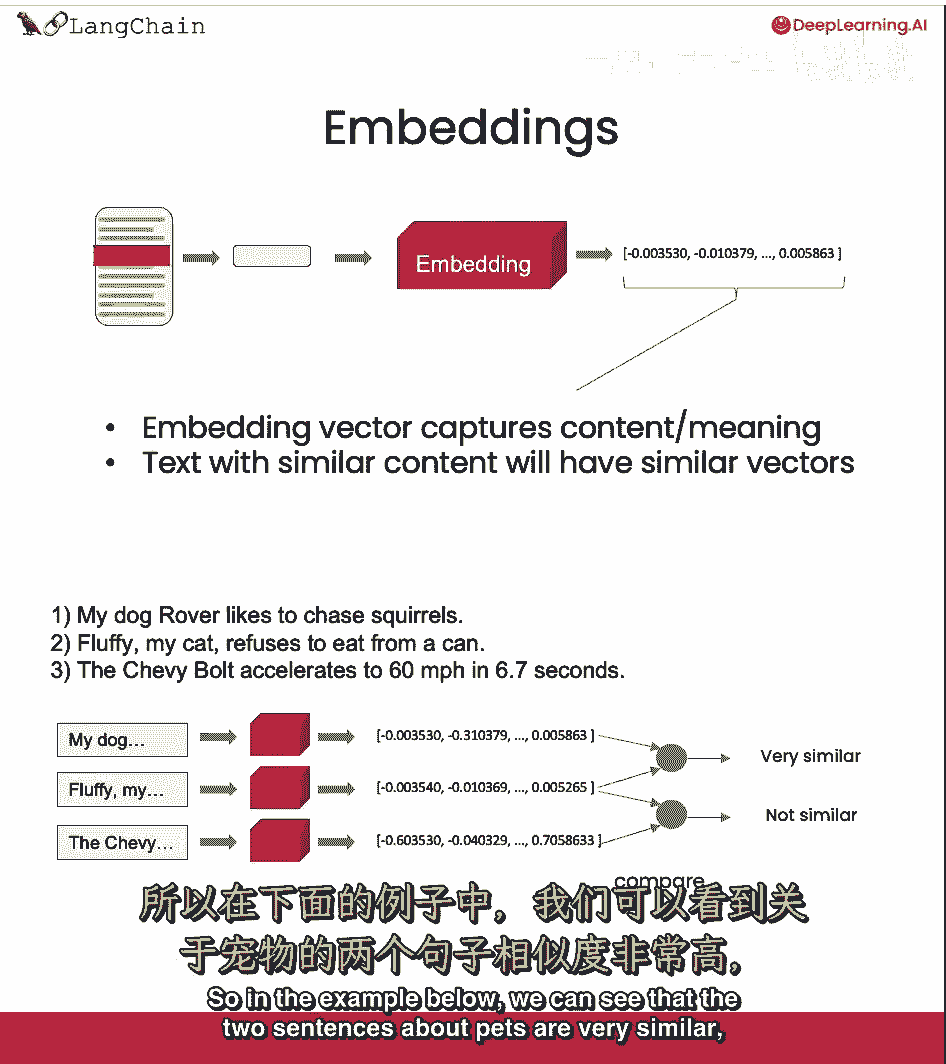
与内容相似的文本将在这个数值空间中有相似的向量。

这意味着,我们可以然后比较那些向量并找到相似的文本部分。

例如,在下面的例子中,我们可以看到关于宠物的两句话非常相似。
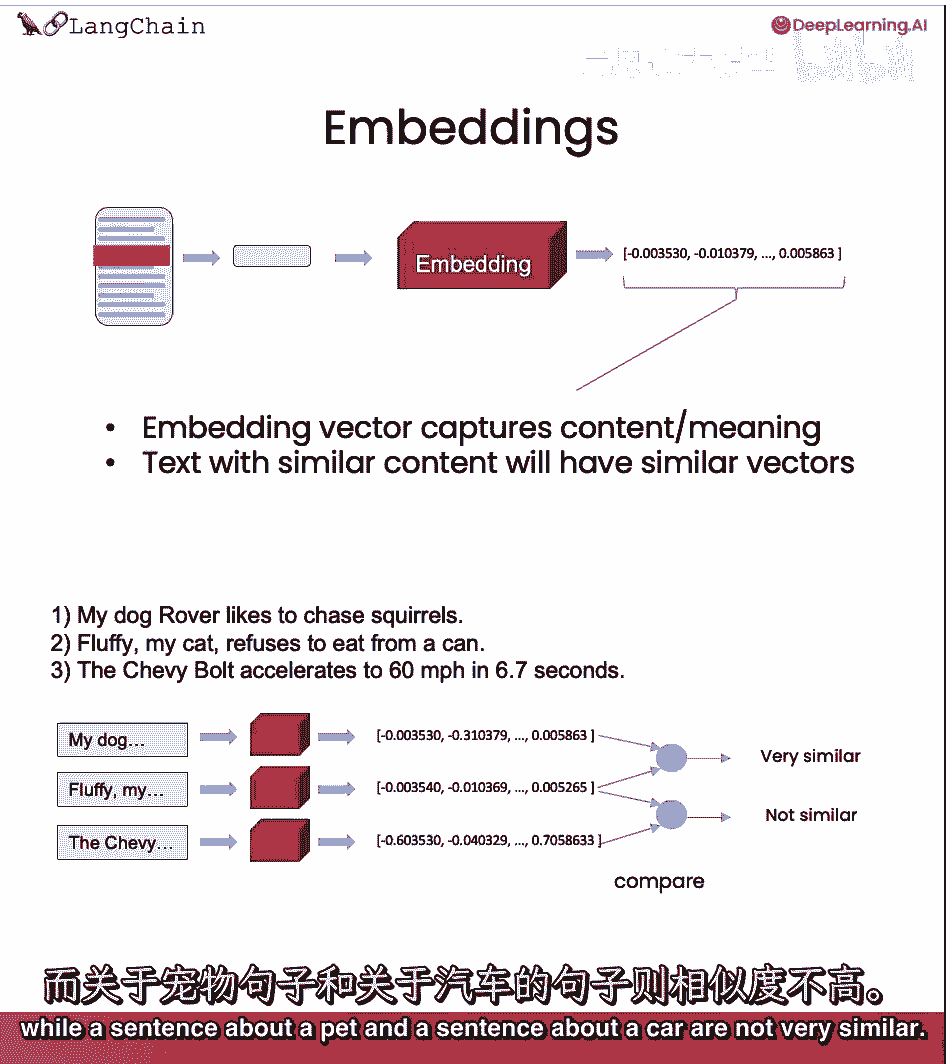
而在关于汽车的句子中提到宠物的句子并不相似。
作为对完整工作流程的全面回顾,我们开始与文档。

然后创建这些文档的较小分割,然后创建这些文档的嵌入。
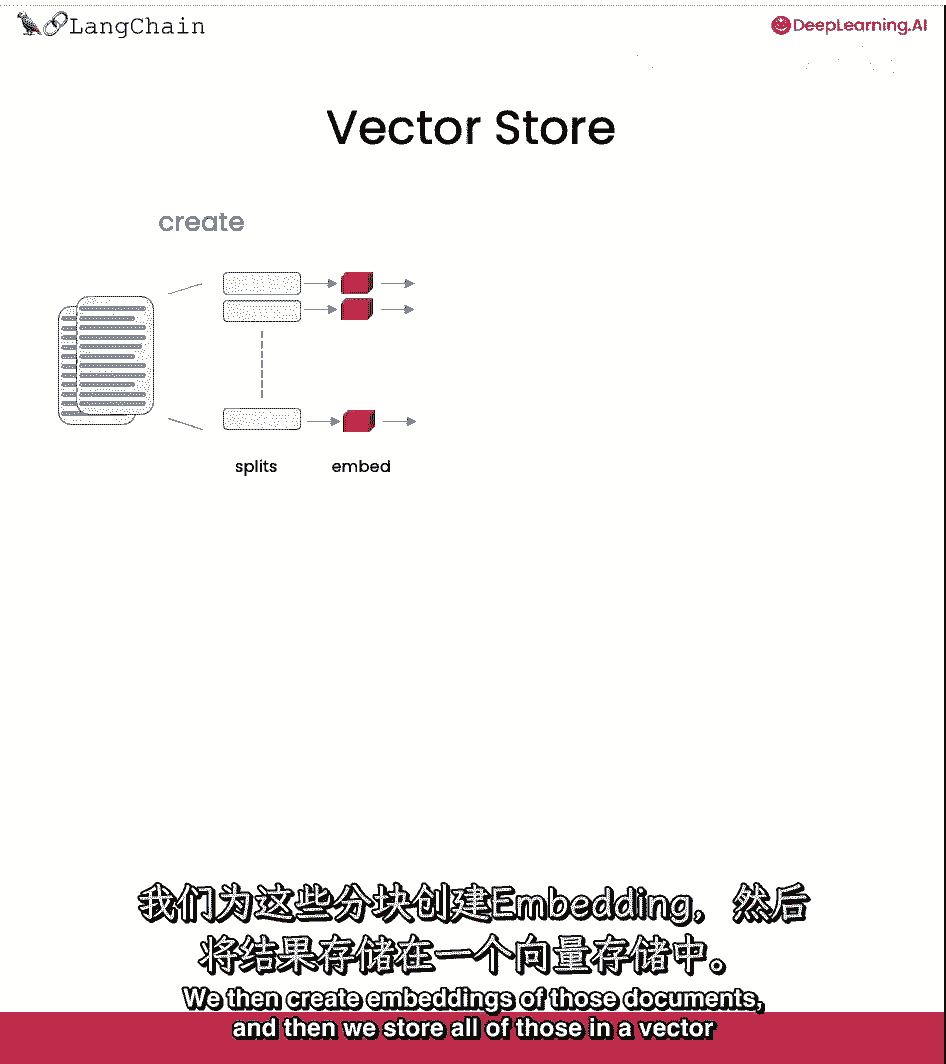
并将所有这些都存储在向量存储中,向量存储是一种数据库,您可以在其中后来轻松地查找相似的向量。
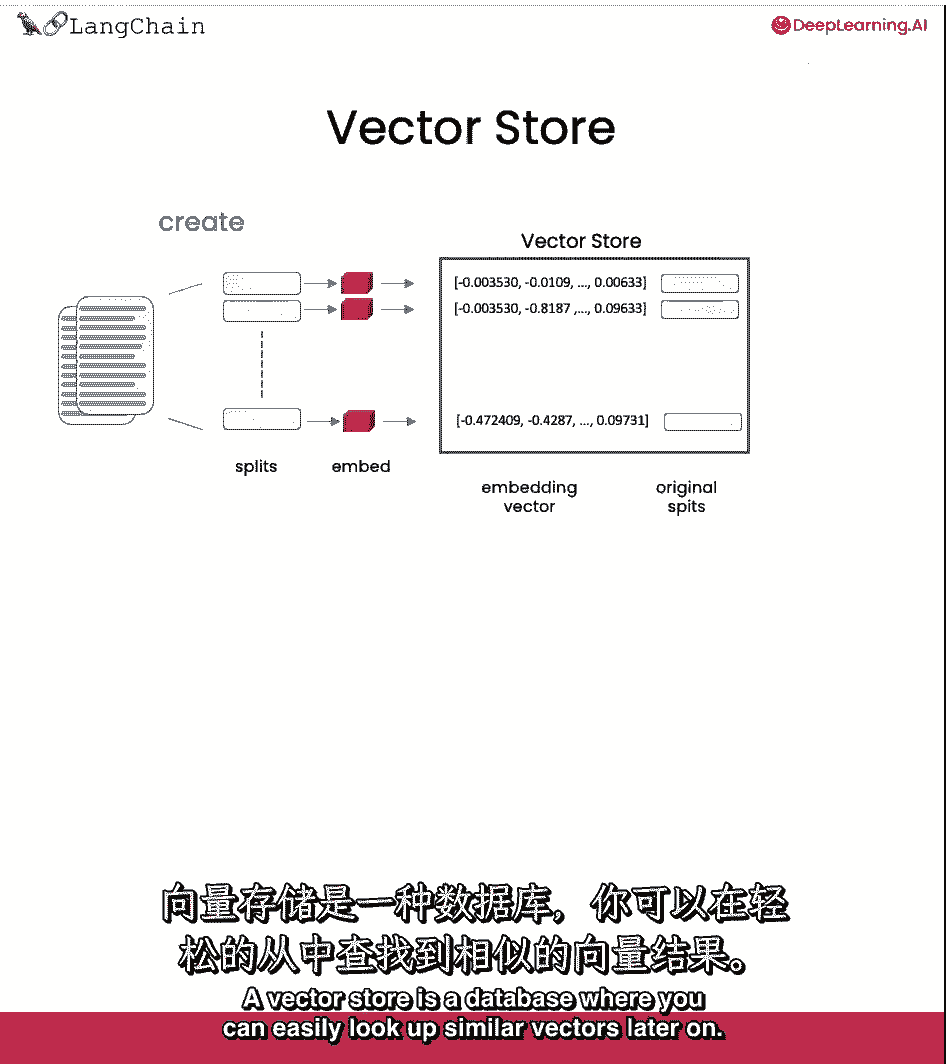
这将在尝试找到与手头问题相关的文档时非常有用。
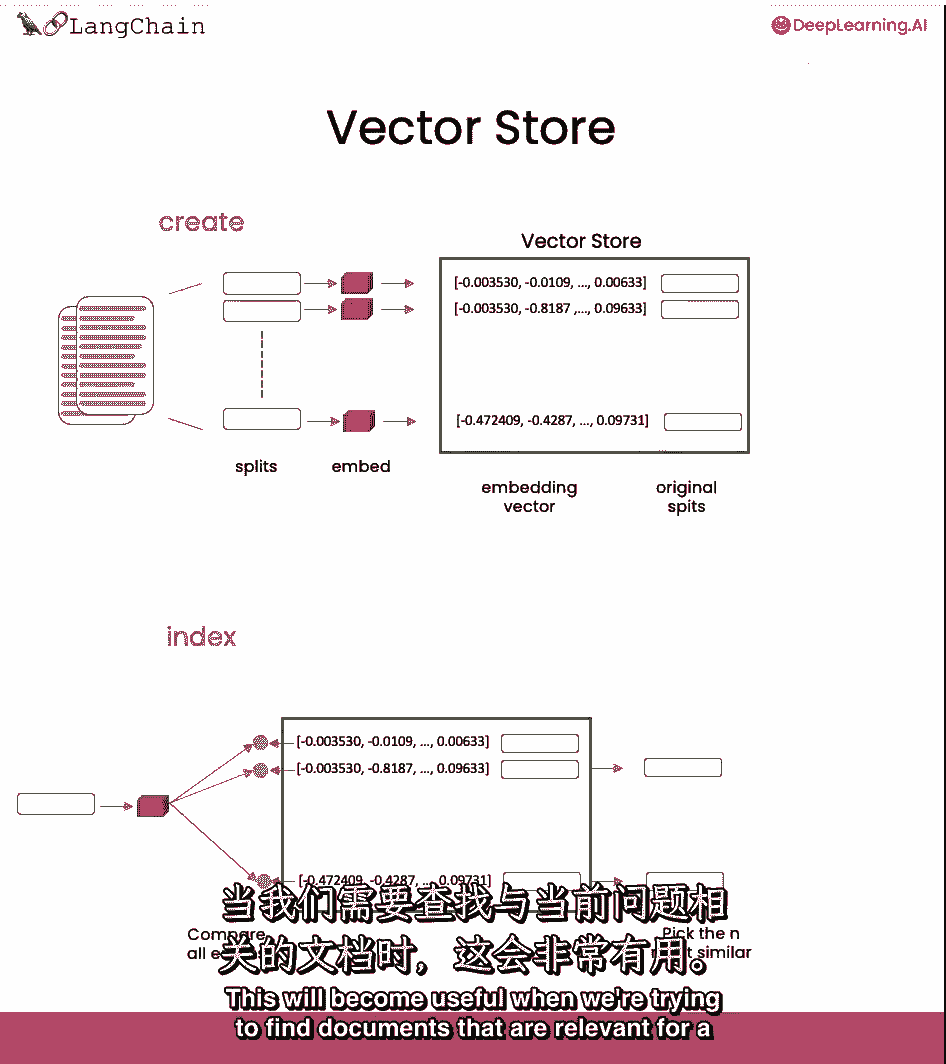
我们可以然后处理手头的问题,创建一个嵌入,然后与向量存储中的所有不同向量进行比较。
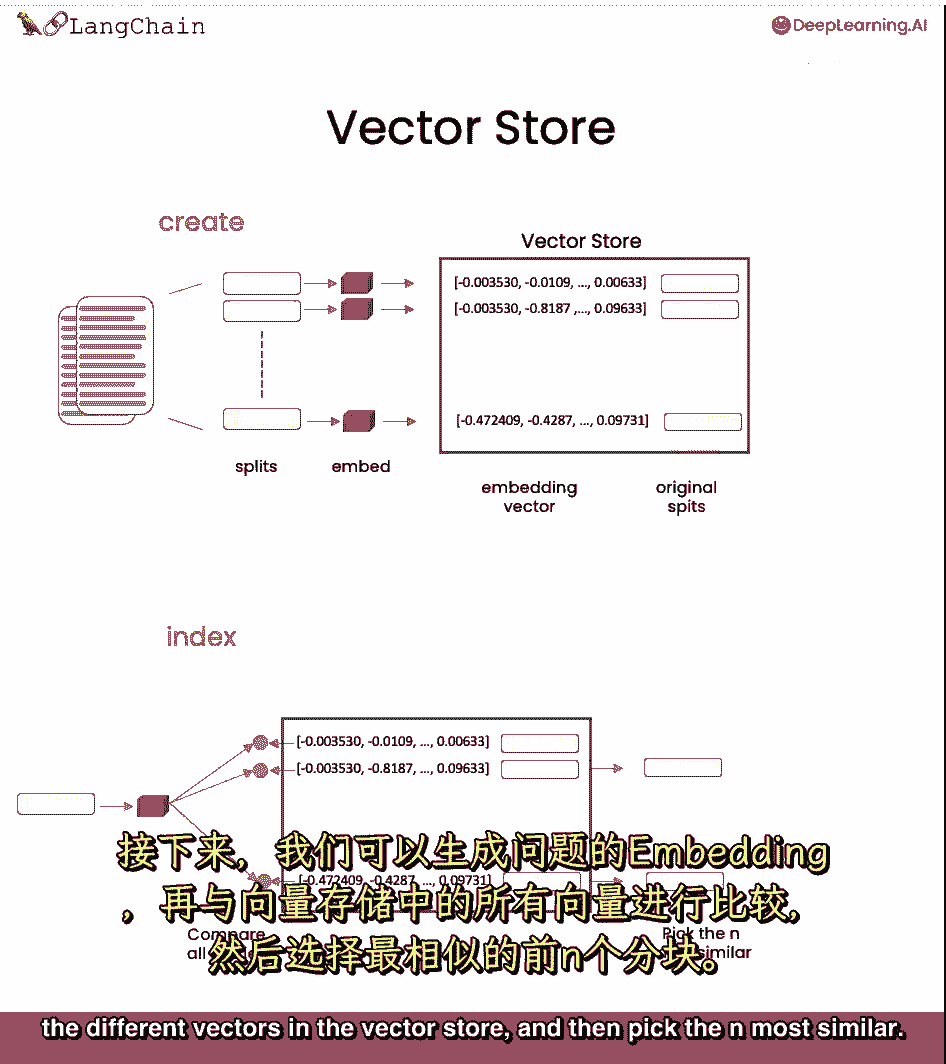
然后选择最相似的一个,我们然后取这些和最相似的片段,并将它们与问题一起传递给llm,并得到答案。
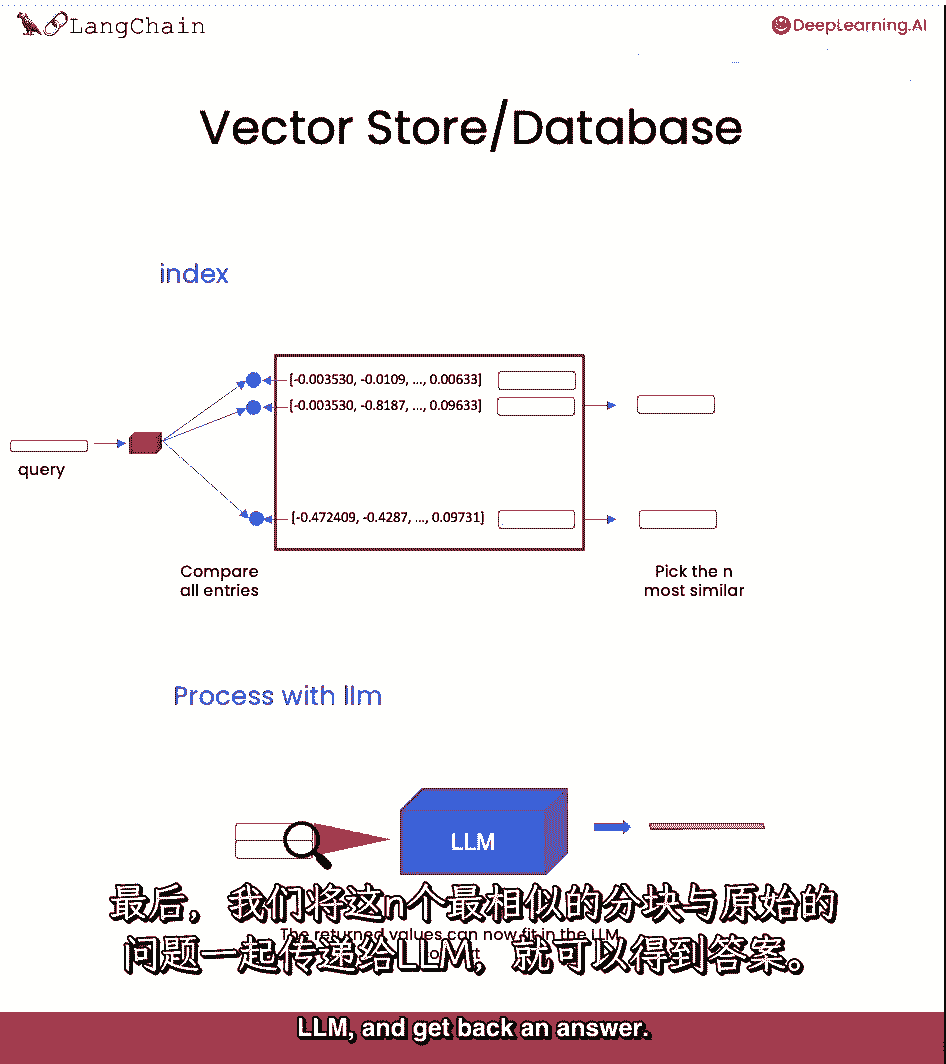
我们将稍后覆盖所有这些,现在,是我们深入探讨嵌入和向量存储本身的时候。
首先,我们将再次设置适当的环境变量。

从这里开始,我们将与相同的一组文档工作,这些是cs two twenty九的讲座,我们将加载,其中一些在这里,注意,我们将实际上复制,第一堂课,这是为了模拟一些脏数据。
文档加载后,我们可以然后使用递归字符文本分割器创建块。

我们可以看到,我们已经创建了超过二百个不同的分块,是时候转向下一个部分并为它们创建嵌入式向量了。

我们将使用openai来创建这些嵌入式向量,然后在实际世界中跳入。

让我们尝试使用几个玩具测试案例。

只是为了了解引擎内部的情况,我们有一些示例句子,其中前两句非常相似。

而第三句与前两句无关。
然后,我们可以使用嵌入类为每个句子创建嵌入式向量。
然后,我们可以使用numpy来比较它们并看到哪些最相似。

我们预期前两句应该非常相似,然后,第一和第二与第三相比不应该那么相似。
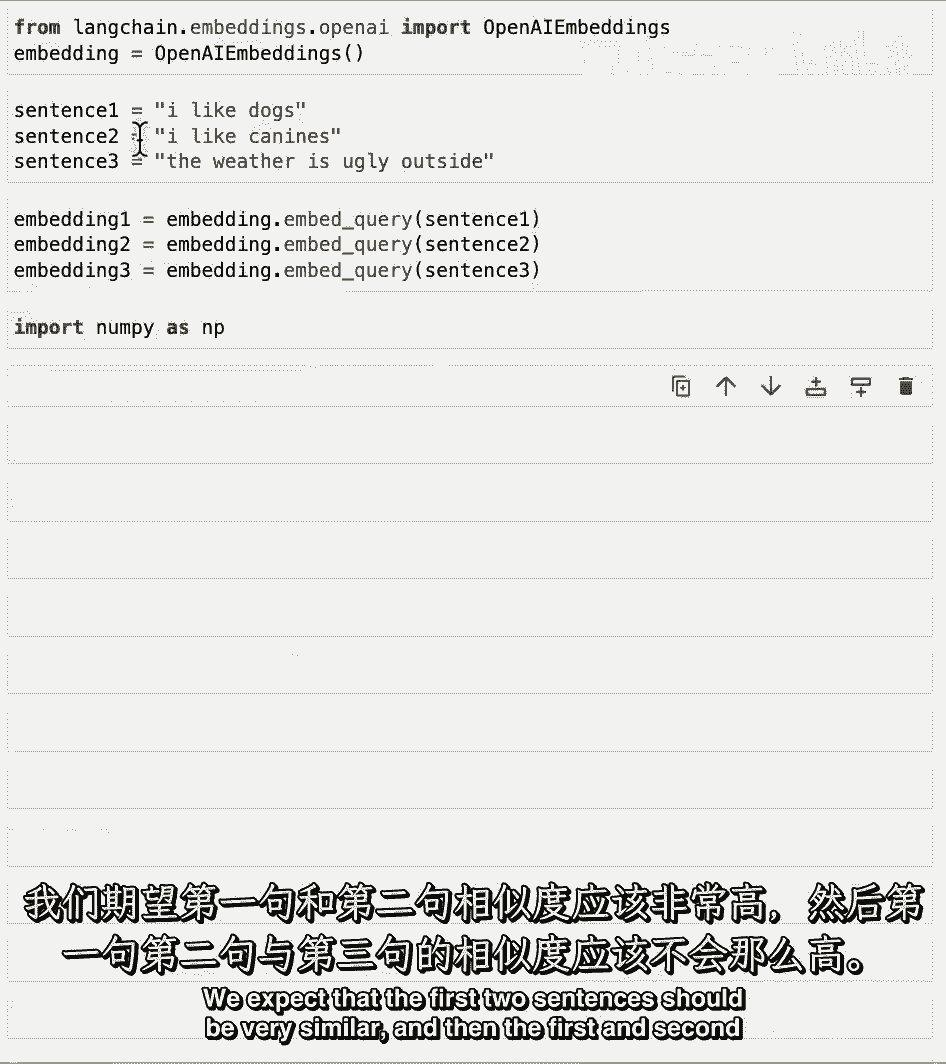
我们将使用点积来比较两个嵌入式向量。
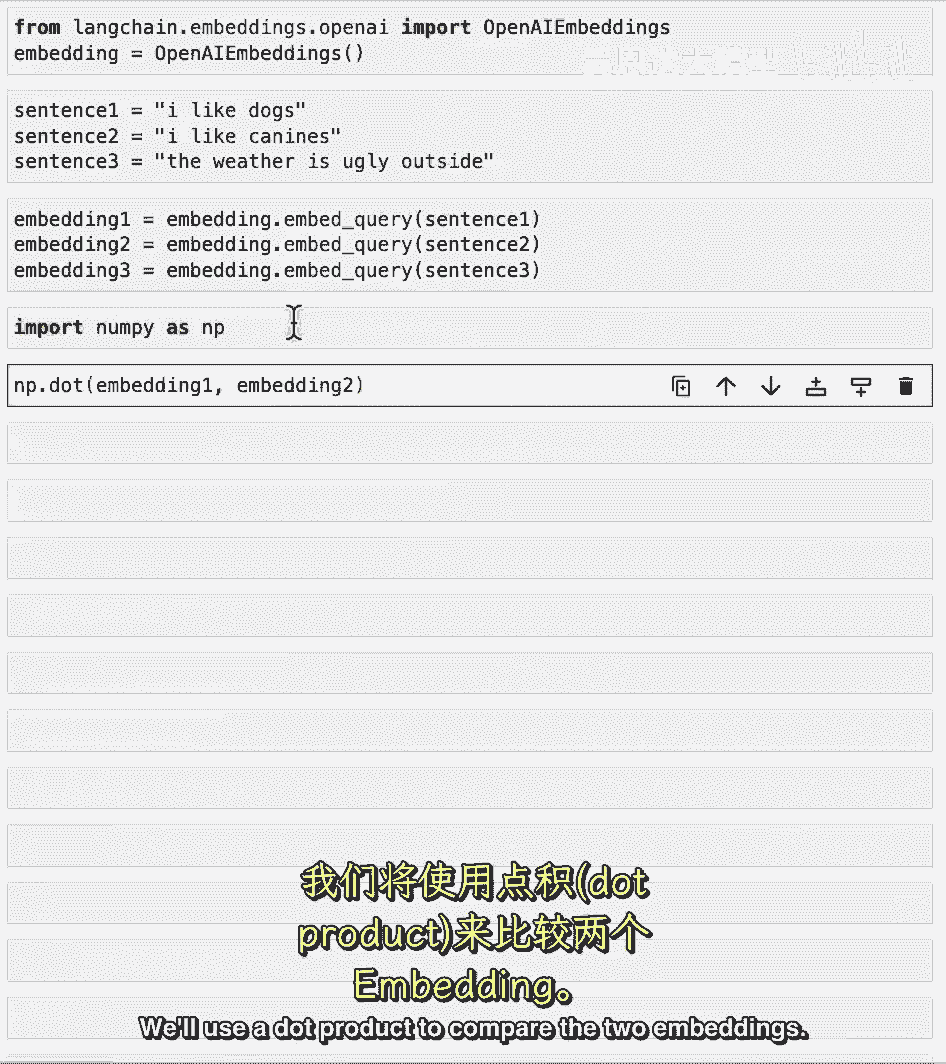
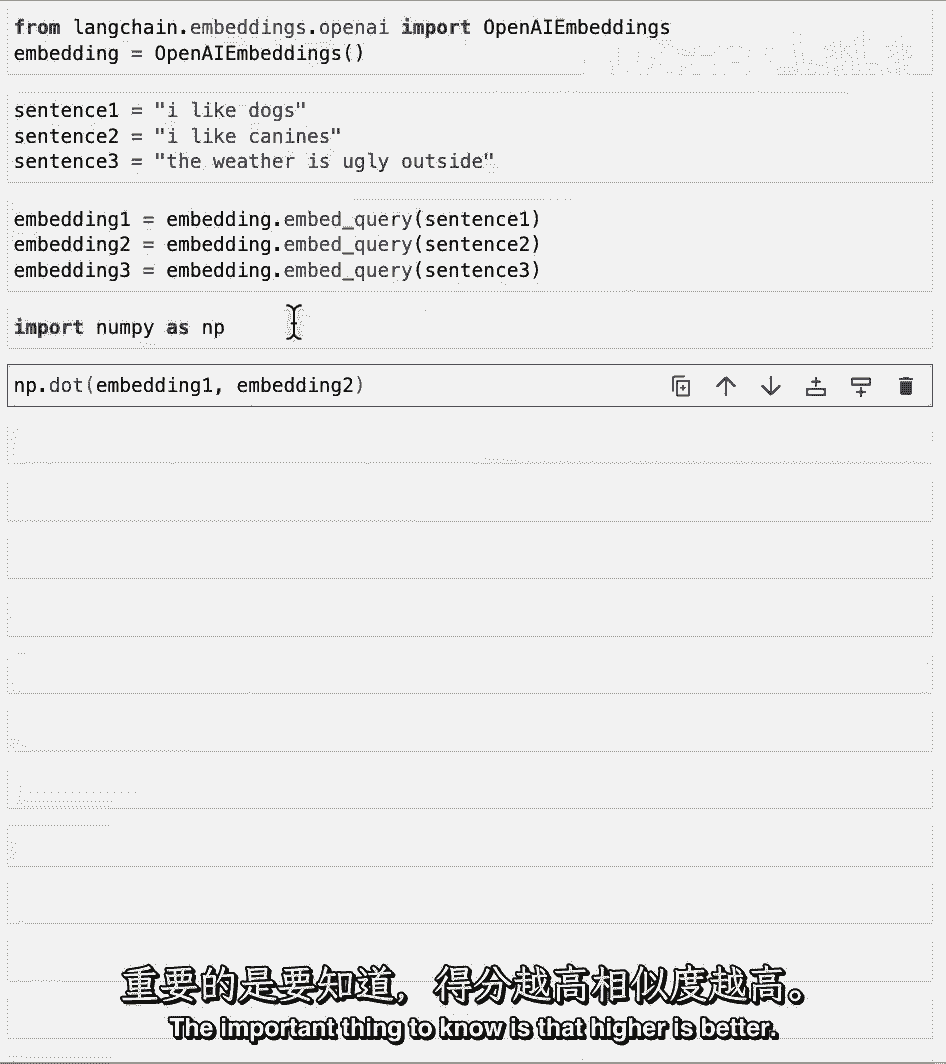
如果你不知道点积是什么,没关系,重要的是要知道,更高的分数越好。
在这里,我们可以看到,第一个和第二个嵌入式向量有一个相当高的得分为9。6。

如果我们比较第一个嵌入式向量与第三个嵌入式向量。
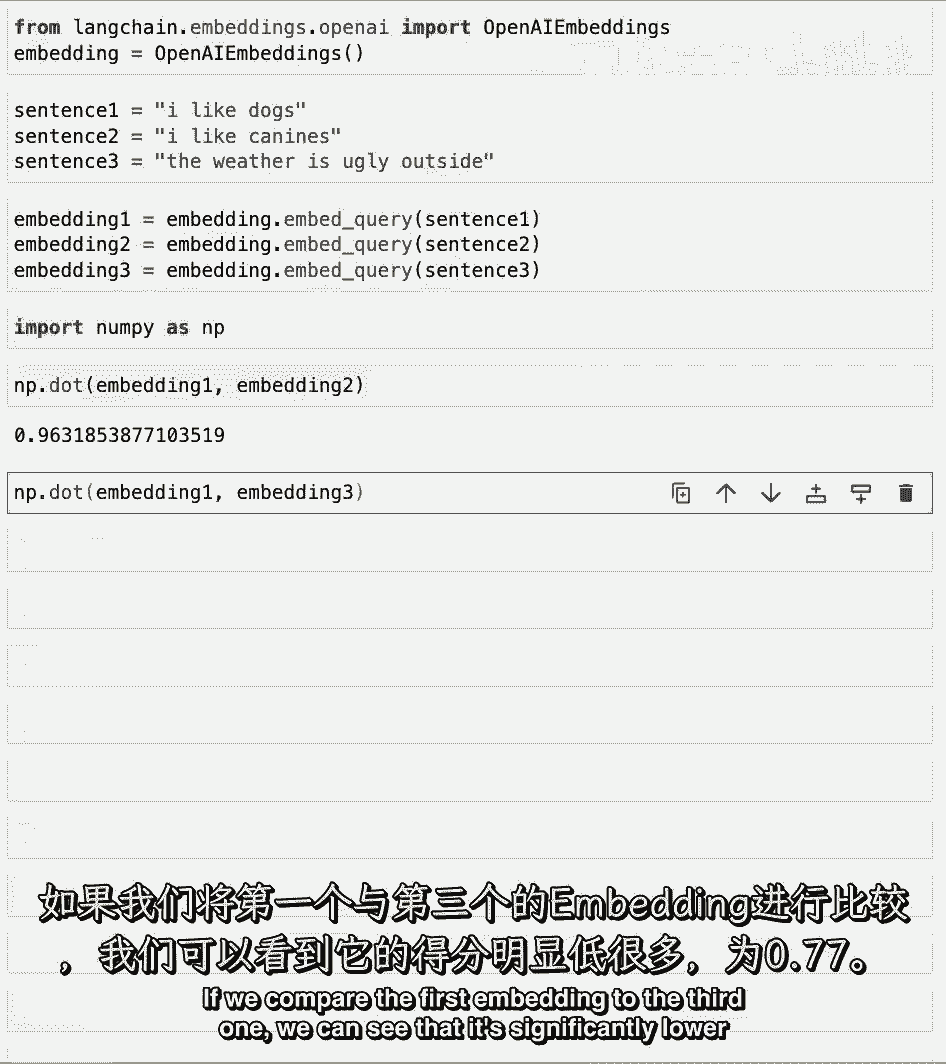
我们可以看到,它显著低于7。7,如果比较第二个与第三个。
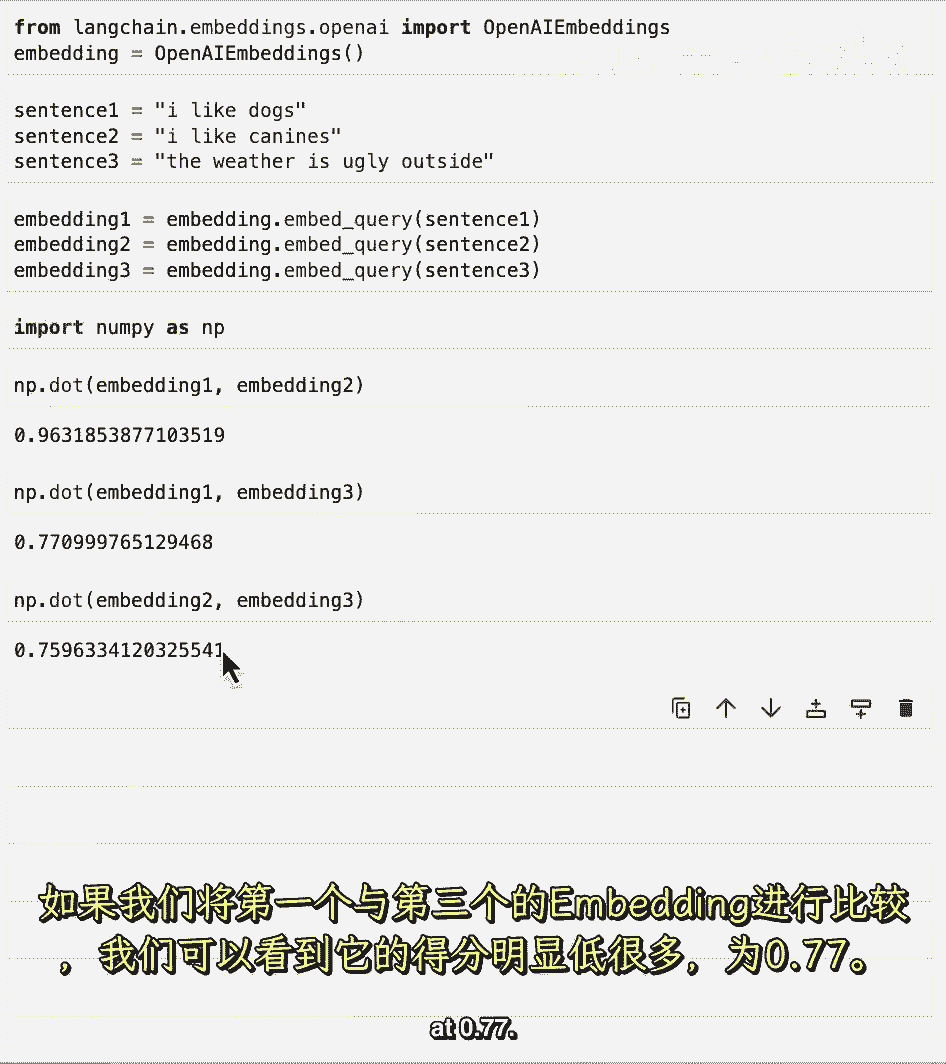
我们可以看到,它大约相同于7。6。

现在是一个暂停并尝试自己几句的好时机,并看看点积是什么。

现在让我们回到实际世界的例子,是时候为pdf块的所有部分创建嵌入式向量了。

然后存储它们为向量,我们将用于本课程的向量存储是chroma,所以让我们导入它lane chain与超过三十个向量存储有集成。

我们选择chroma因为它在内存中轻量级。

这使得它非常容易开始使用。

还有其他向量存储提供托管解决方案,这可能在您试图持久大量数据时非常有用,或持久在云存储中。

我们将想在某个地方保存这个向量存储,以便我们在未来课程中使用它。

所以让我们创建一个变量叫做持久目录,我们将在后续的doc chroma中使用它。

让我们也确保那里什么都没有。

如果有东西在那里,可能会引起问题,我们不想要那样。

所以让我们rm dash rf docs chroma,只是为了确保那里什么都没有。

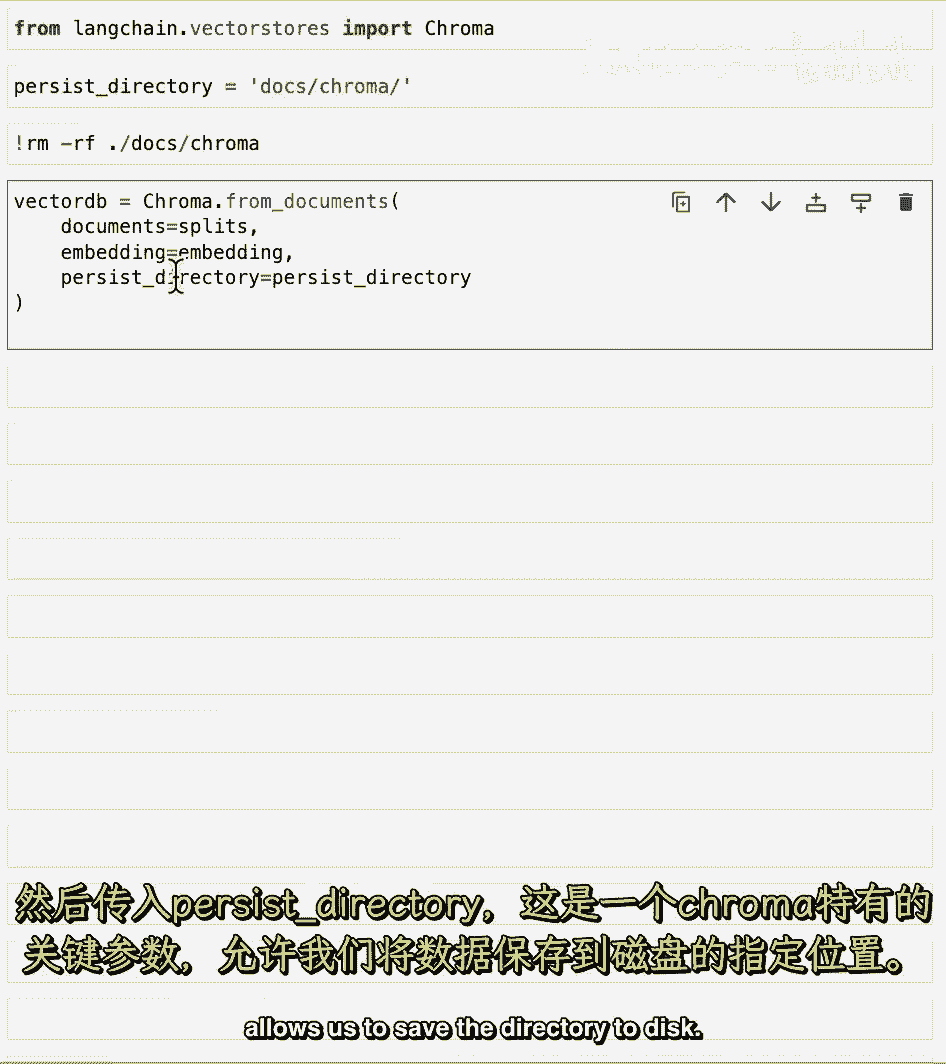
现在让我们创建向量存储,所以我们从文档中调用chroma,传递分裂,这些是我们 earlier 创造的分裂,传递嵌入。

这是开放AI嵌入模型,然后,我们将传入持久目录,这是一个chroma特定的关键字参数,允许我们将目录保存到磁盘。

如果我们看一下集合计数,做完这个之后,我们可以看到它是209,这与我们从前的分裂数相同。

现在让我们开始使用它,让我们思考一个问题,我们可以问这个数据,我们知道这是关于一堂课的。

所以让我们问是否有我们可以寻求帮助的电子邮件,如果我们需要关于课程或材料的任何帮助。

我们将使用相似性搜索方法,我们将传递问题,然后,我们还将传递k等于3,这指定我们要返回的文档数量。

如果我们运行那个,然后我们看文档的长度,我们可以看到它是3,因为我们指定的。
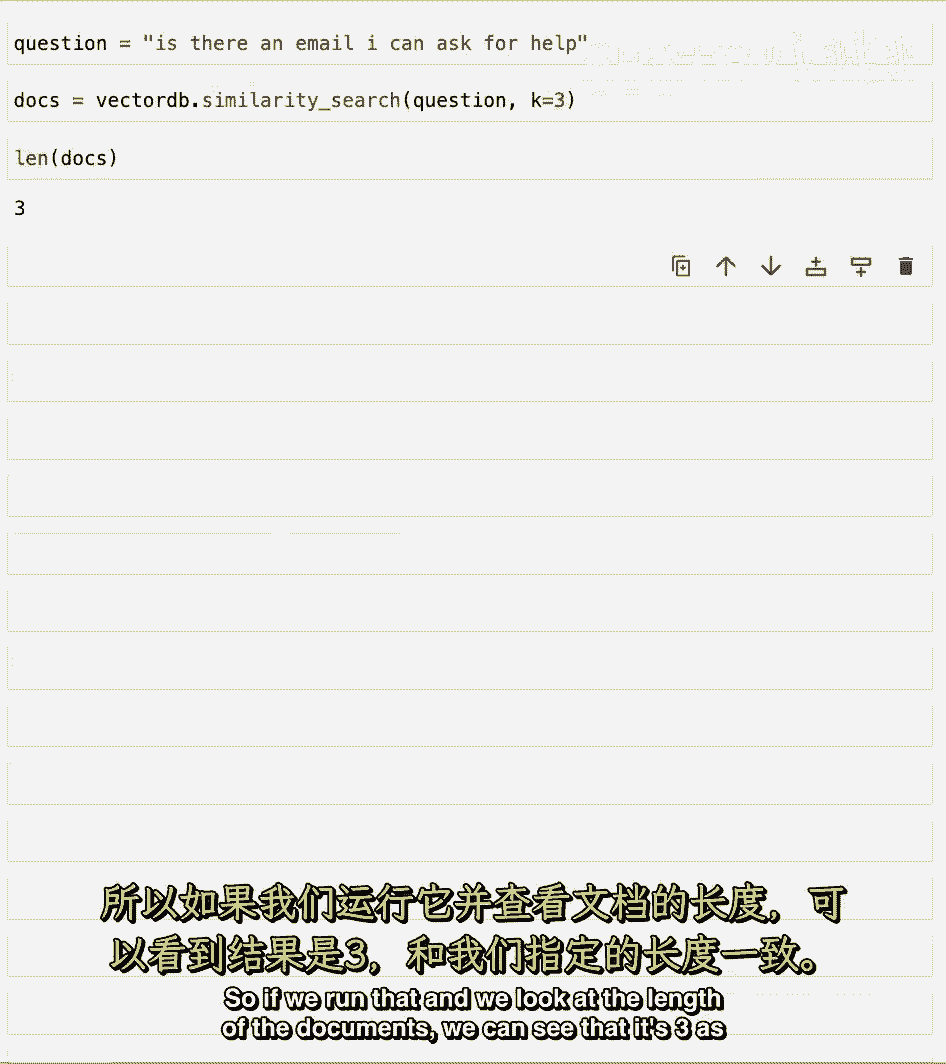
如果我们看第一个文档的内容。

我们可以看到它实际上关于电子邮件地址,cs2-299-dash-qa-cs,斯坦福,edu,这是我们可以发送问题的电子邮件地址,并且由所有tas阅读,做完之后,让我们确保持久向量数据库。
以便我们可以在未来的课程中使用它,通过运行向量db。dot。persist。

这覆盖了语义搜索的基本知识,并展示了我们可以仅基于嵌入物就得到很好的结果。

但它不是完美的,在这里,我们将讨论几个边缘情况并显示在哪里这可能会失败。

让我们尝试一个新问题,他们对matlab说了什么,让我们运行这个,指定k等于5,并获取一些结果。

如果我们看第一个两个结果,我们可以看到它们实际上是相同的,这是因为当我们加载pdfs时,如果你记得我们特意指定,一个重复项,这是很糟糕的,因为我们在同一个部分中有相同的信息。
我们将这两个部分都传递给语言模型往下游,第二个部分的信息并没有真正的价值,而且如果存在一个不同,独特的部分,语言模型可以从中学习,在下一节课中,我们将覆盖如何同时获取相关和独特的部分。
这是另一种可能会发生的失败模式,让我们看看这个问题。

他们在第三堂课中说了什么关于回归的内容。

当我们得到这些文档时,直觉上,我们预期它们应该都是第三堂课的一部分。

我们可以检查这个,因为元数据中包含了它们来自哪些讲座的信息。

所以让我们遍历所有文档并打印出元数据。

我们可以看到实际上有一组结果。

一些来自第三堂课,一些来自第二堂课,还有一些来自第一堂课,关于为什么这失败直觉的原因是第三堂课。

以及我们想要只从第三堂课获取文档的事实是一段结构化信息。

但我们只是在基于嵌入的语义查找上做。
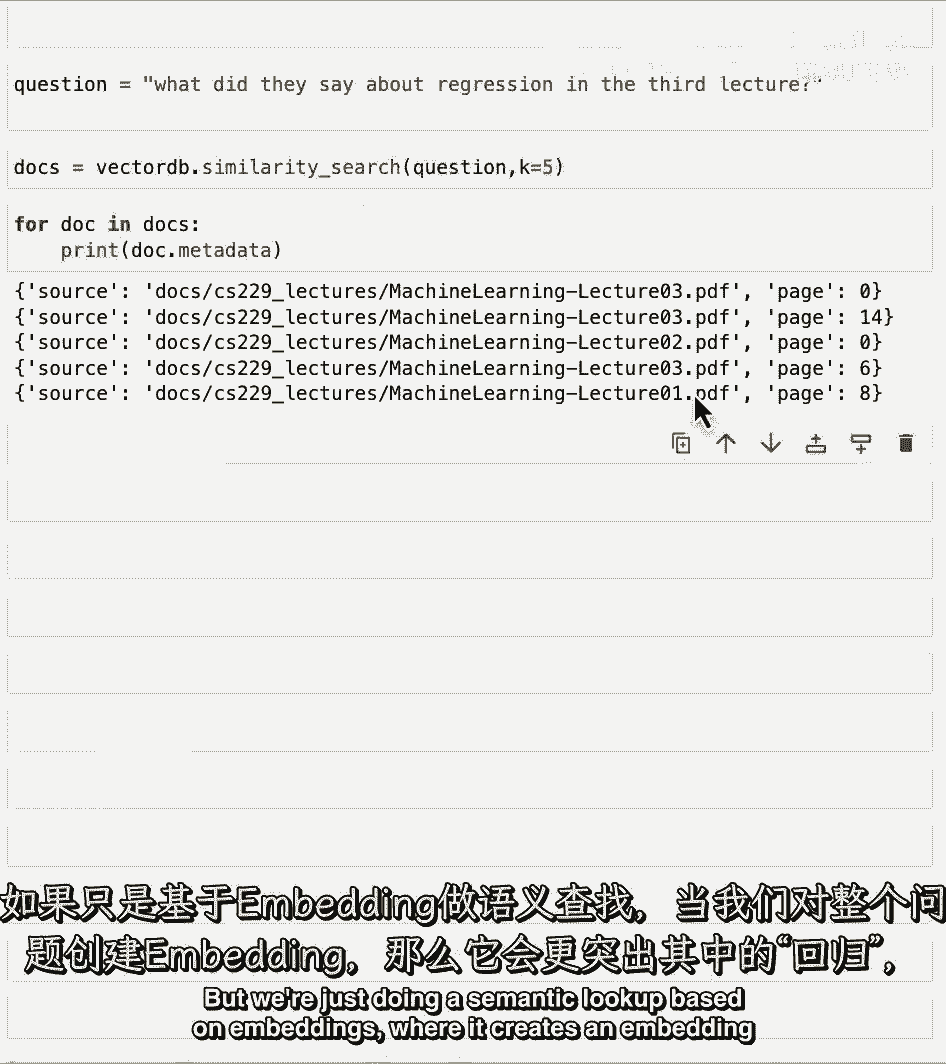
它为整个句子创建了一个嵌入。

而且它可能更专注于回归,因此我们得到的结果可能对回归非常相关。

所以如果我们看第五个,查看来自第一堂课的那个,我们可以看到它确实,实际上,提到了回归,所以它捕捉到了这个,但它没有捕捉到事实,它只应该查询来自第三堂课的文档,因为再次,这是一段结构化信息。
并不是我们创建的语义嵌入完全捕捉的,现在是个好时机暂停并尝试一些更多的查询,你还能注意到哪些边缘情况出现,你也可以尝试改变k,你检索的文档数量,正如你在这堂课中注意到的,我们使用了前三个,然后五个。
你可以尝试调整它成为你想要的任何数字,你可能注意到当你使它更大时,你将检索更多的文档,但是那个尾端的文档可能不如开始的那些相关,现在,我们覆盖了语义搜索的基本知识,以及一些失败模式,让我们继续下一堂课。
我们将讨论如何解决这些失败模式并增强我们的检索,让我们转到下一堂课。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P37:5——检索 - 吴恩达大模型 - BV1gLeueWE5N

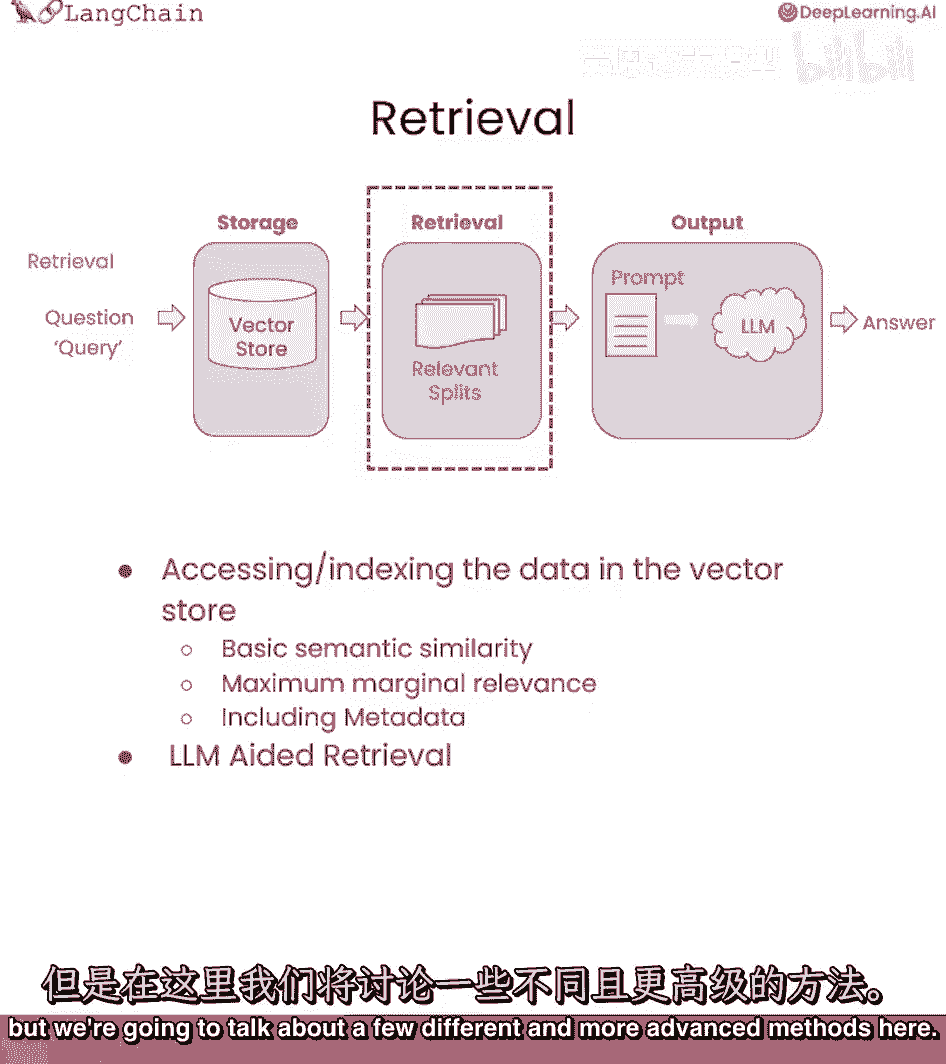
在上一节课中,我们覆盖了语义搜索的基本知识,并看到了它在许多使用场景中表现良好的情况,但我们也看到了一些边缘情况,并看到了事情可能会如何出错,在这节课中,我们将深入研究检索。
并覆盖一些更先进的方法来克服这些边缘情况,我对此非常兴奋,因为我认为检索是新的,而且我们正在谈论的技术在过去的几个月里出现了,这是一个前沿的主题,所以你们将处于前沿,让我们有一些乐趣,在这节课中。
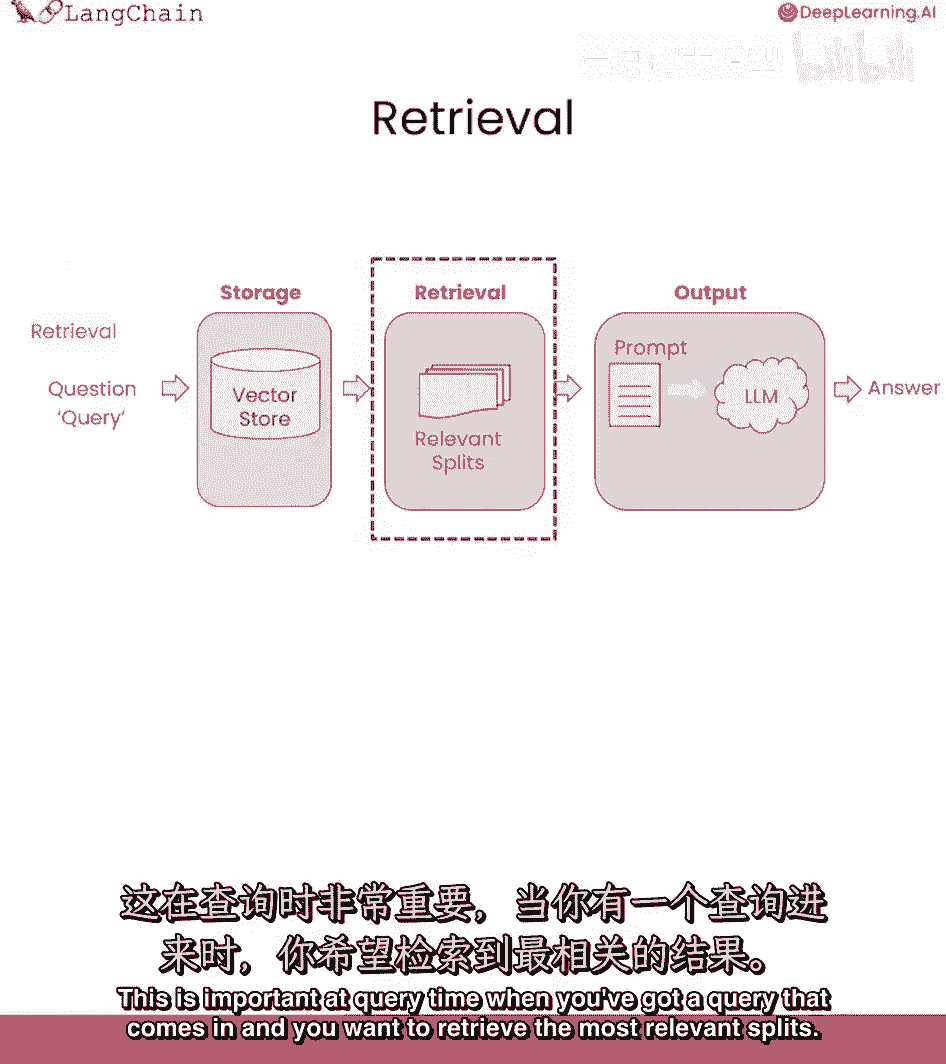
我们将谈论检索,这在查询时间非常重要,当你有一个查询进来时,并且你想要检索最相关的片段。
我们在上一节课中讨论了语义相似性搜索。
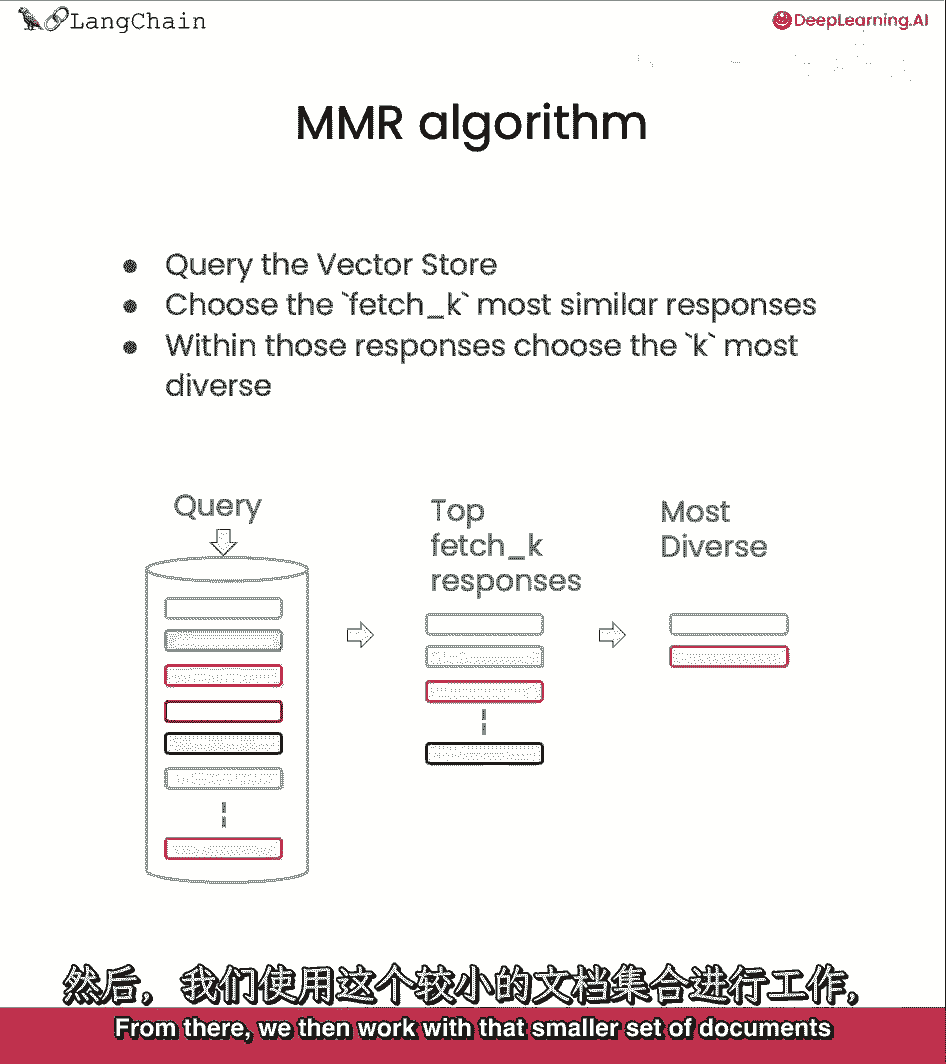
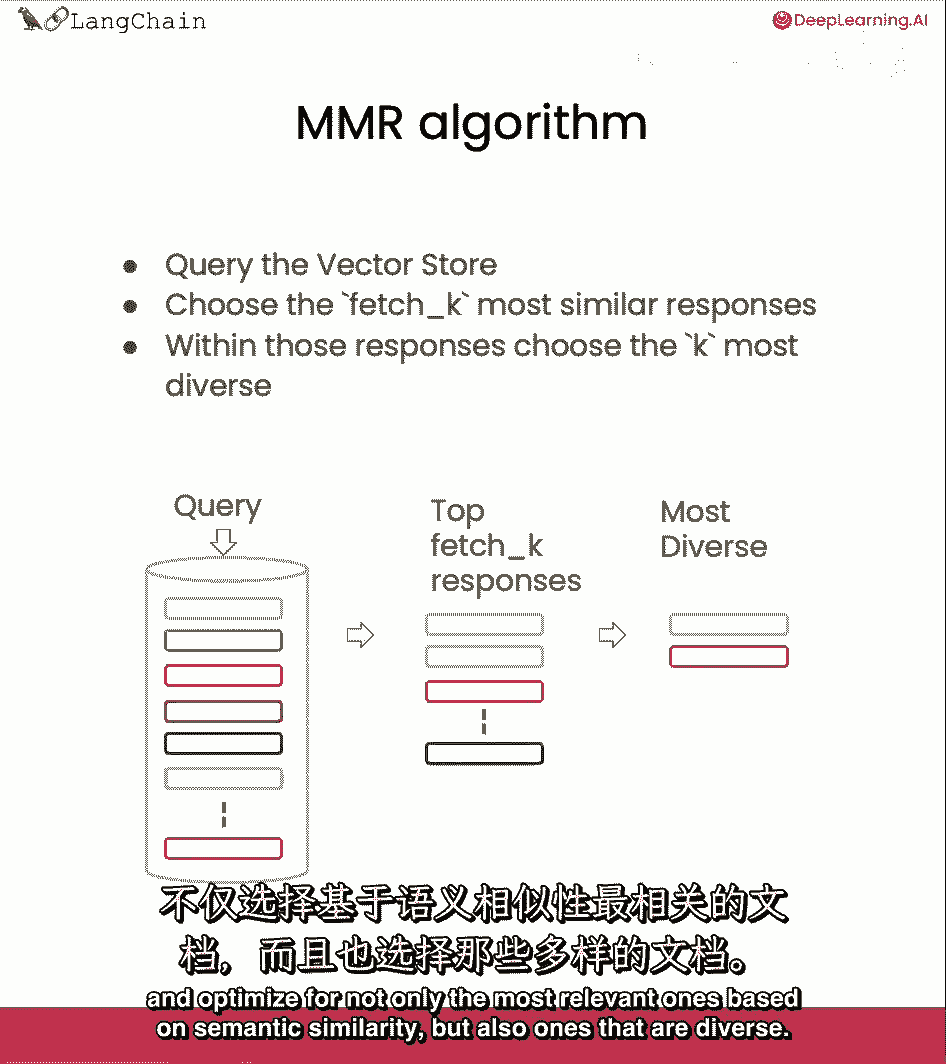
但我们将讨论一些不同和更先进的方法在这里,我们将首先覆盖的最大边际相关性或mmr。
所以这背后的想法是。

如果你总是取与查询在嵌入空间中最相似的文档。

你可能实际上会错过多样化的信息,因为我们在边缘情况中看到了,例如,我们有一个厨师在询问所有种类的白蘑菇。

所以如果我们看最相似的结果。

那些将是前两个文档,它们有许多与查询相似的信息,关于菌核,并且都是白色的,但我们确实想要确保我们也得到其他信息。

如它真的很有毒,这就是mmr发挥作用的地方。

因为它将选择一个多样化的文档集,mmr的想法是我们发送一个查询,然后我们最初得到一组响应。

与fetch underscore k参数可以控制的响应数量有关。

以确定我们得到多少响应,这仅基于语义相似性,从那里。
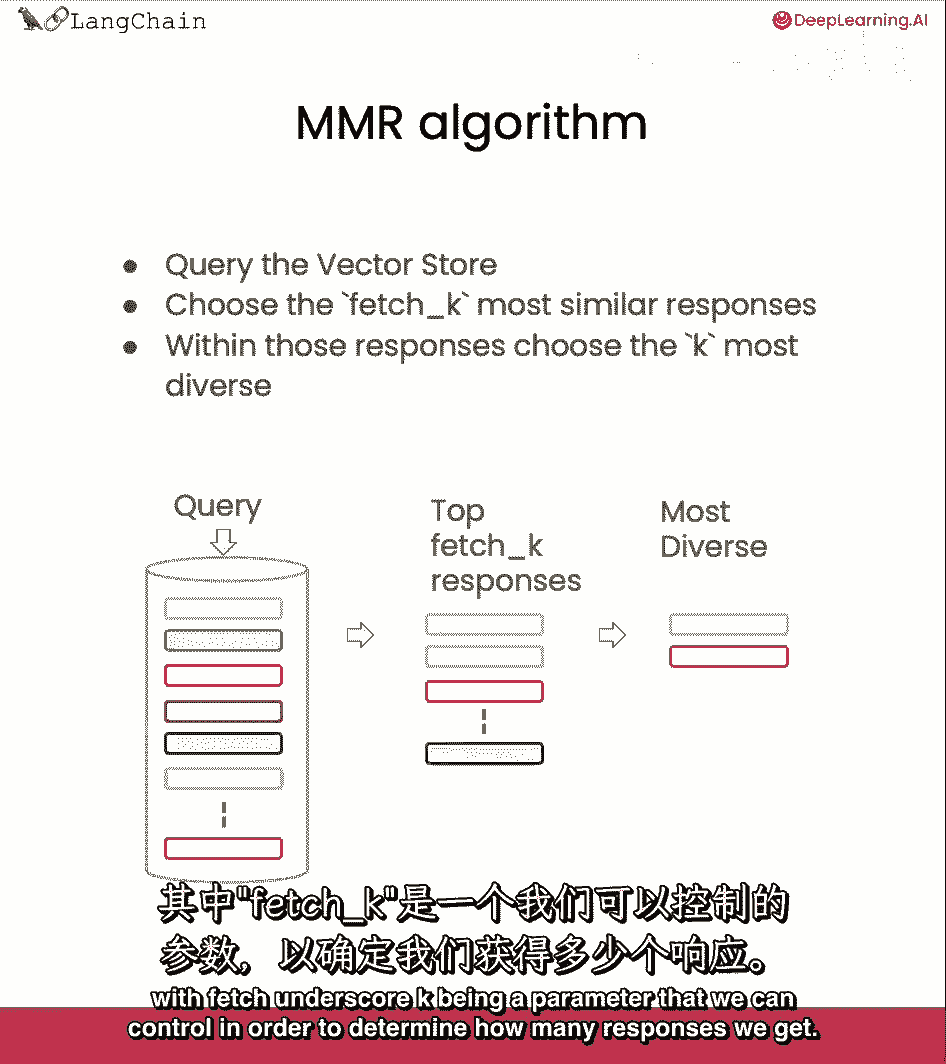
然后我们与那个较小的文档集一起工作,并优化为,不仅基于语义相似性的最相关的文档,但也是多样化的。
从那个文档集中,我们选择一个最终k来返回给用户,另一种检索我们可以做的是我们称之为自我查询,所以这对你来说很有用,当你得到的问题不仅仅是。
你想要查找的语义内容,还包括一些你想要过滤的元数据。

让我们以问题为例,哪部在1980年制作的关于外星人的电影。
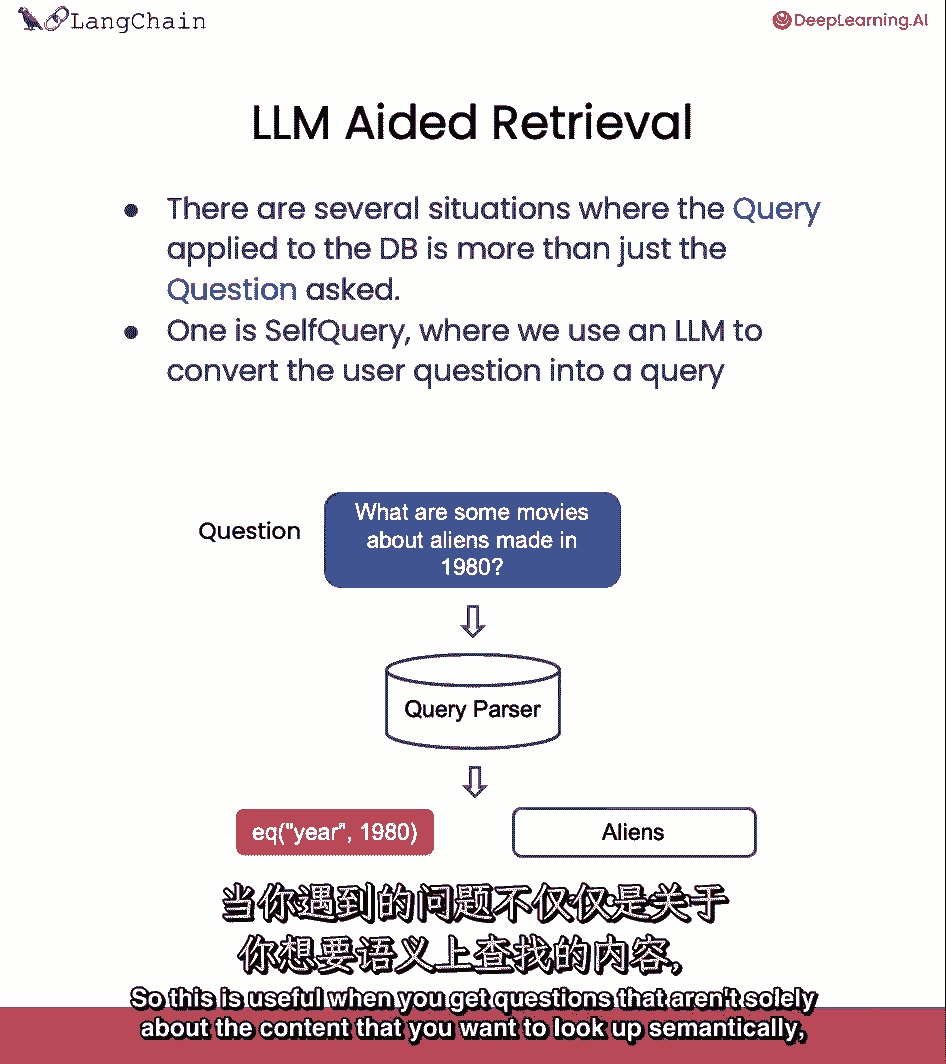
这实际上有两个部分,它有一个语义部分,还有一个关于元数据的部分,所以让我们看问题,哪些关于外星人的电影在1980年制作,外星人咬了。
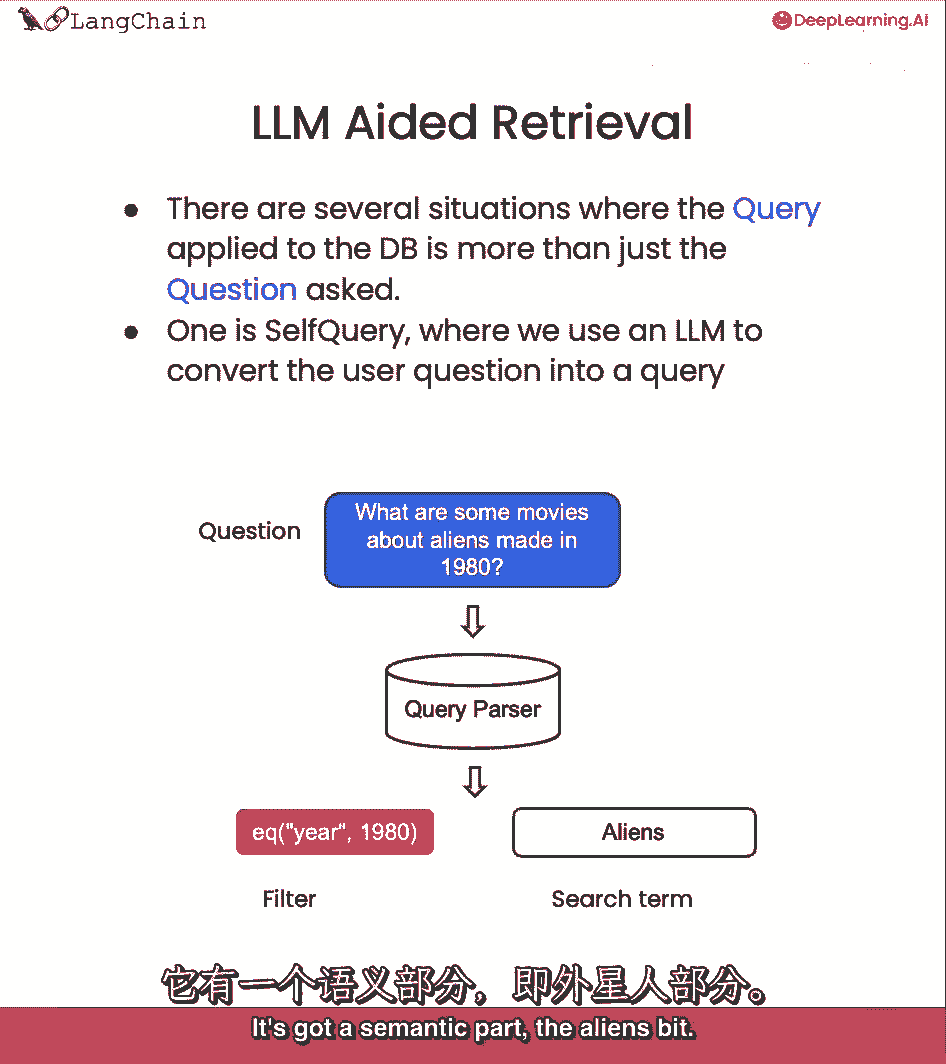
所以我们想要查看我们在电影数据库中的外星人,但它也有一个部分真正指的是关于每部电影的元数据,那就是事实,年份应该是一九八零。
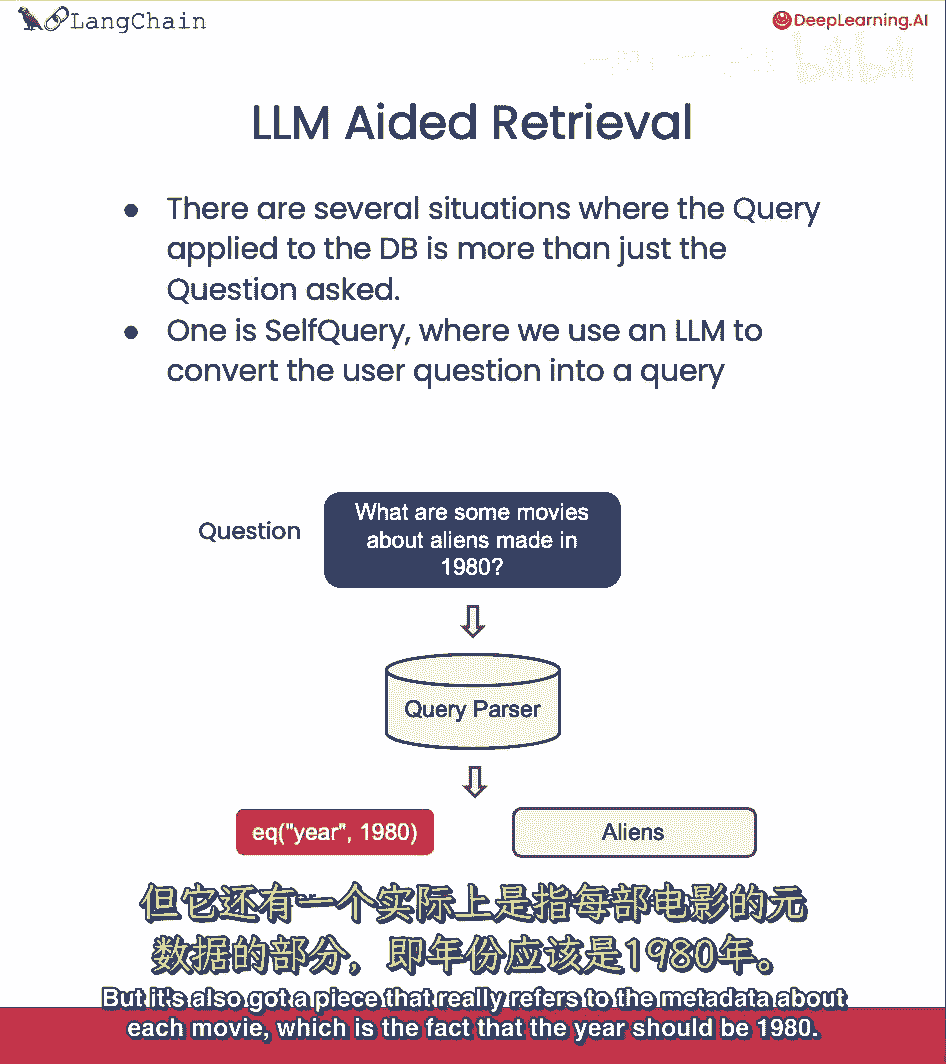
我们可以做,我们可以使用自然语言模型本身来将原始问题分成两个分开的东西,一个过滤器和一个搜索术语。
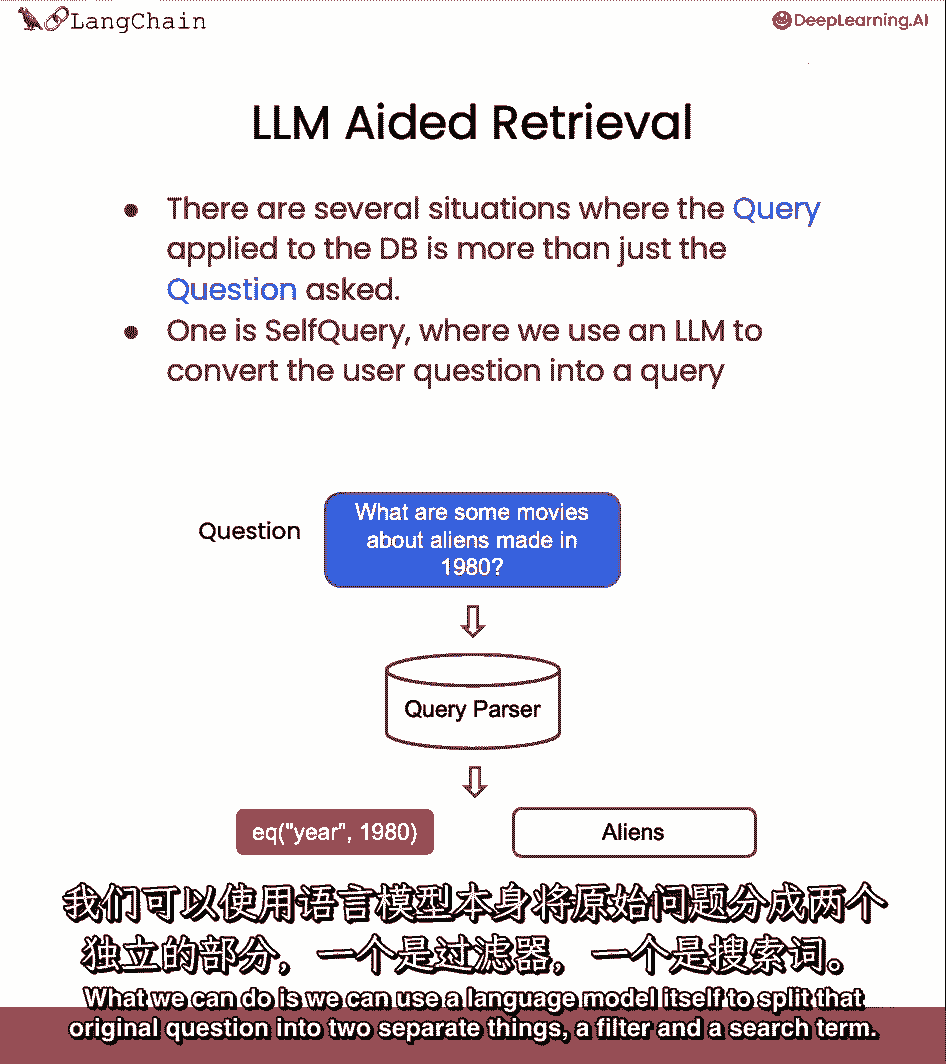
大多数向量存储都支持元数据过滤,所以你可以很容易地根据元数据过滤记录。
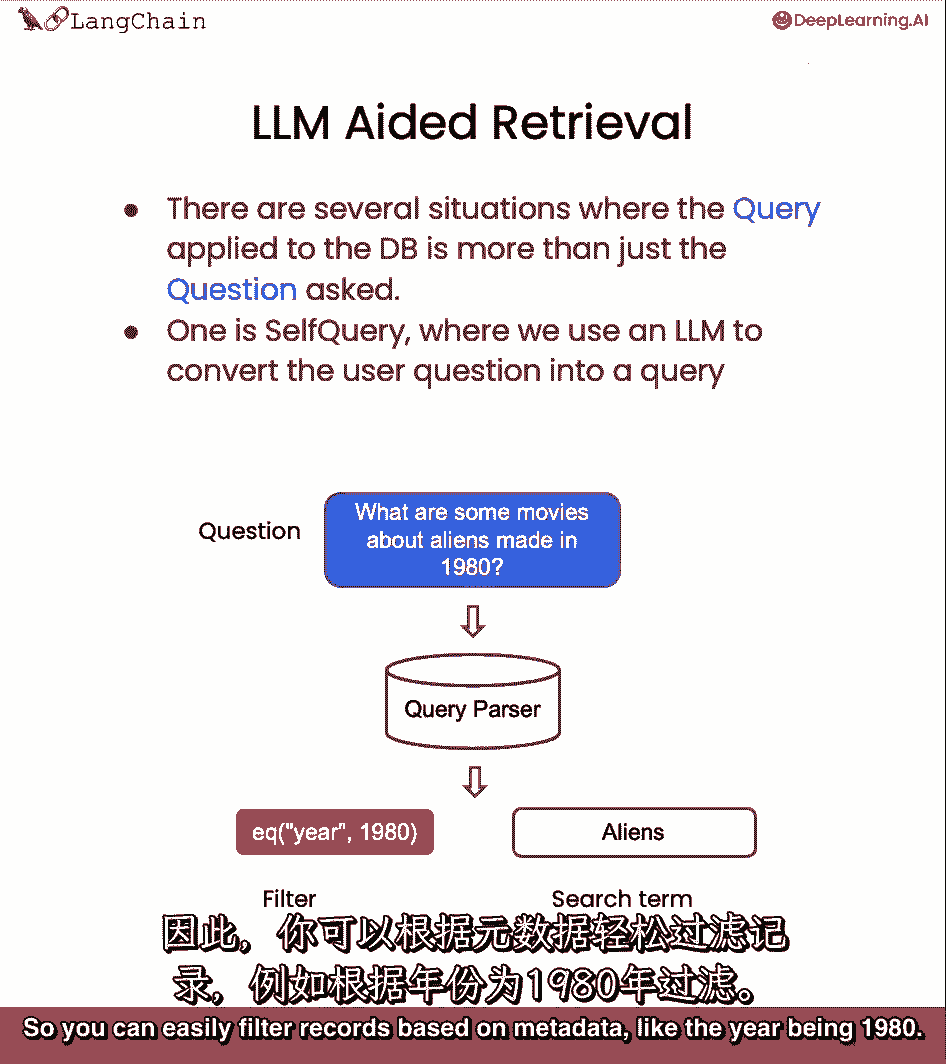
像年份是一九八零。
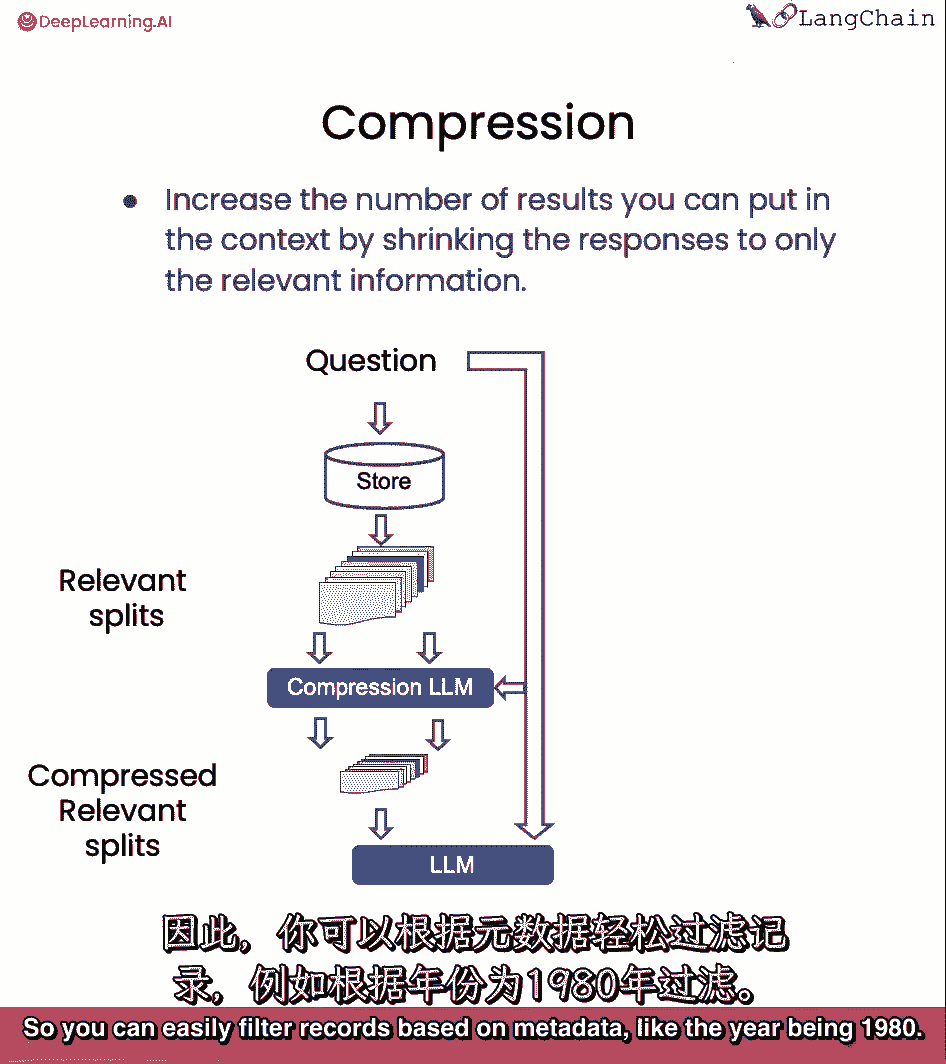
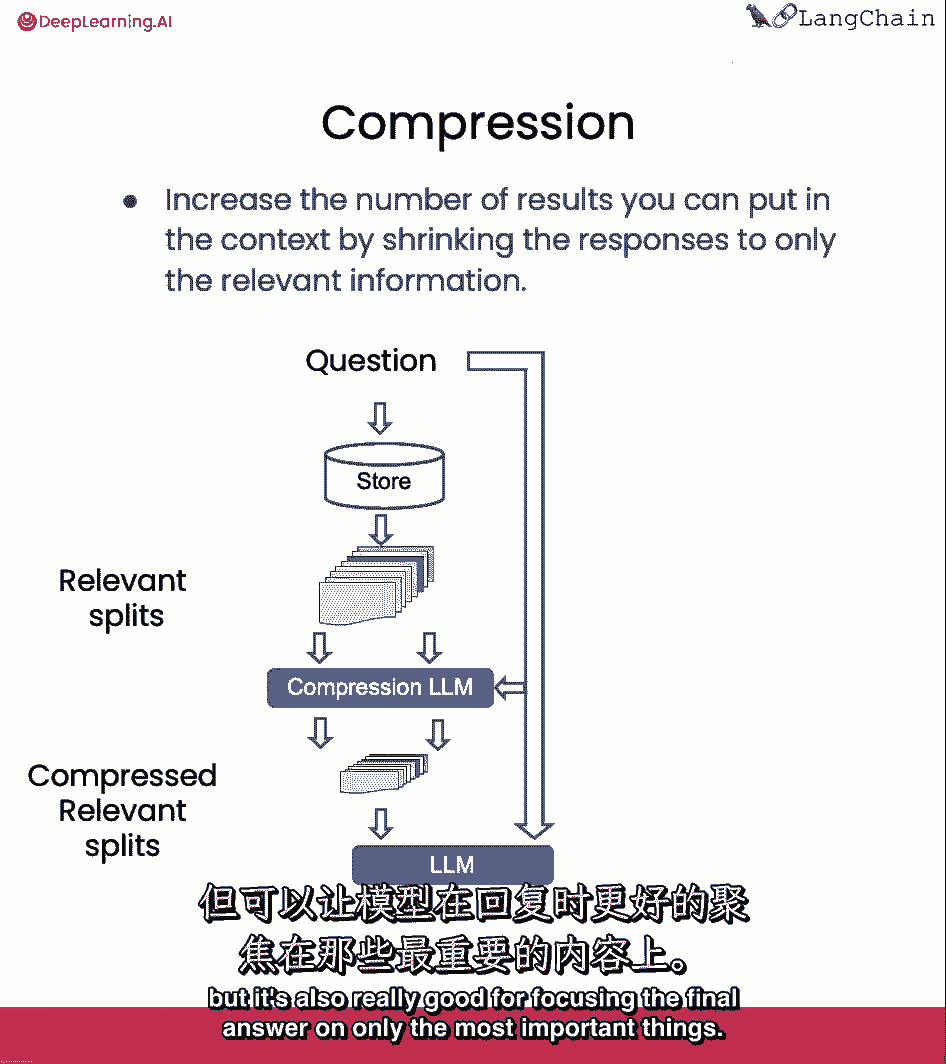
最后我们将谈论压缩,这可以有用于真正提取从检索的段落中只有有关的部分,例如,当提问时,你会得到存储的整个文档。
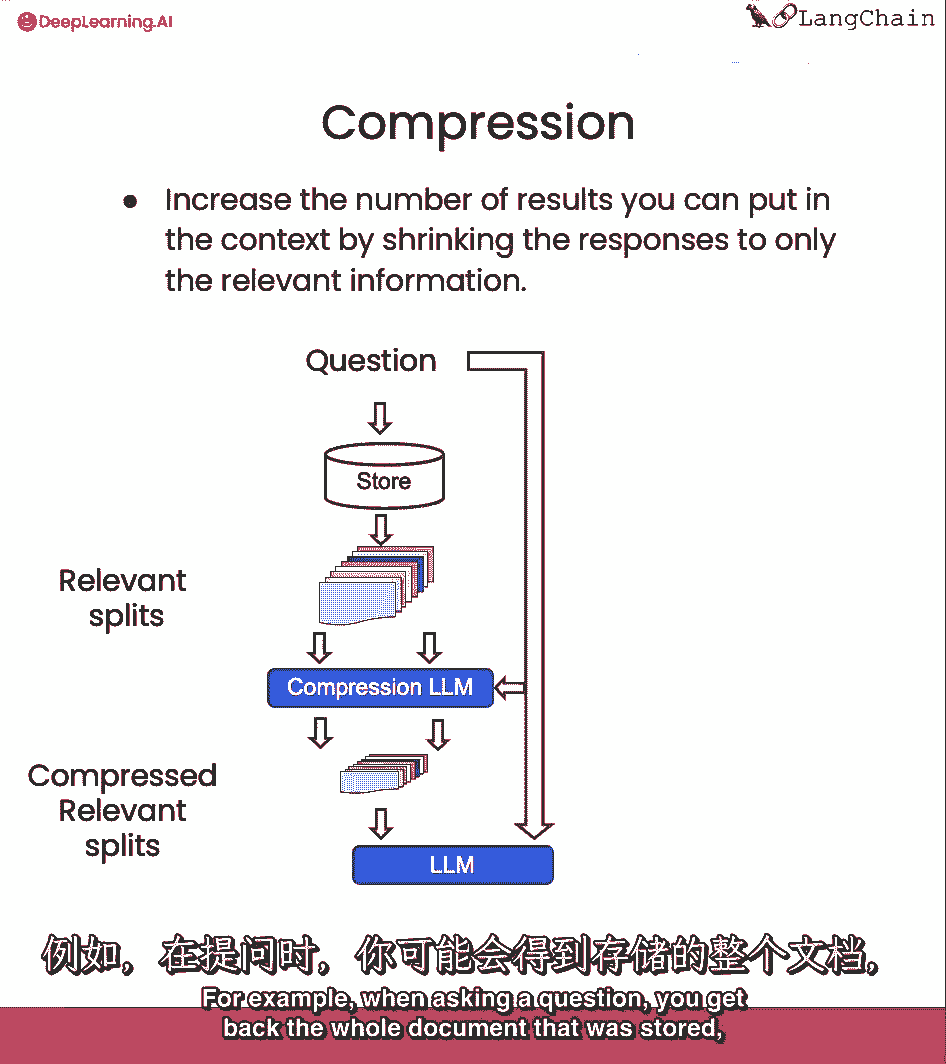
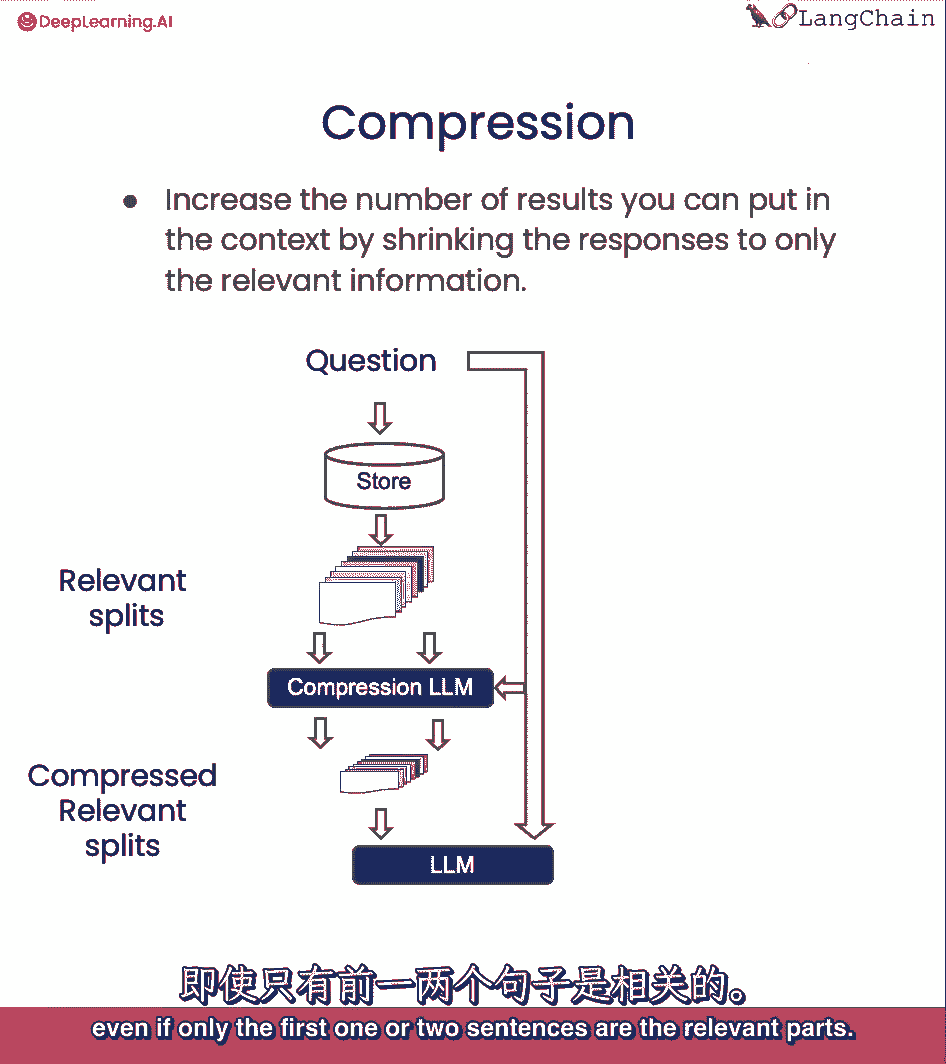
即使只有第一个或两个句子是有关的部分,使用压缩。
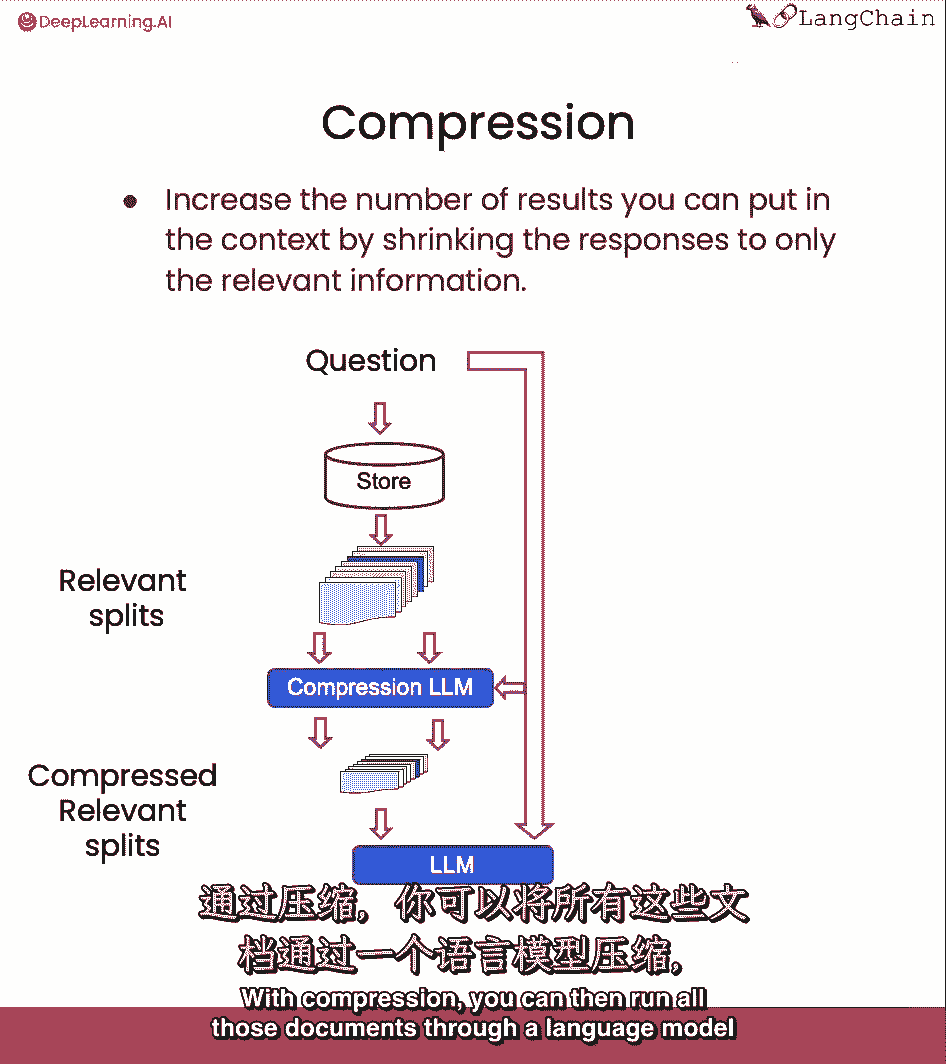
你可以然后运行所有这些文档通过自然语言模型并提取最相关的部分。
然后只将最相关的部分传递给最终的自然语言模型调用。
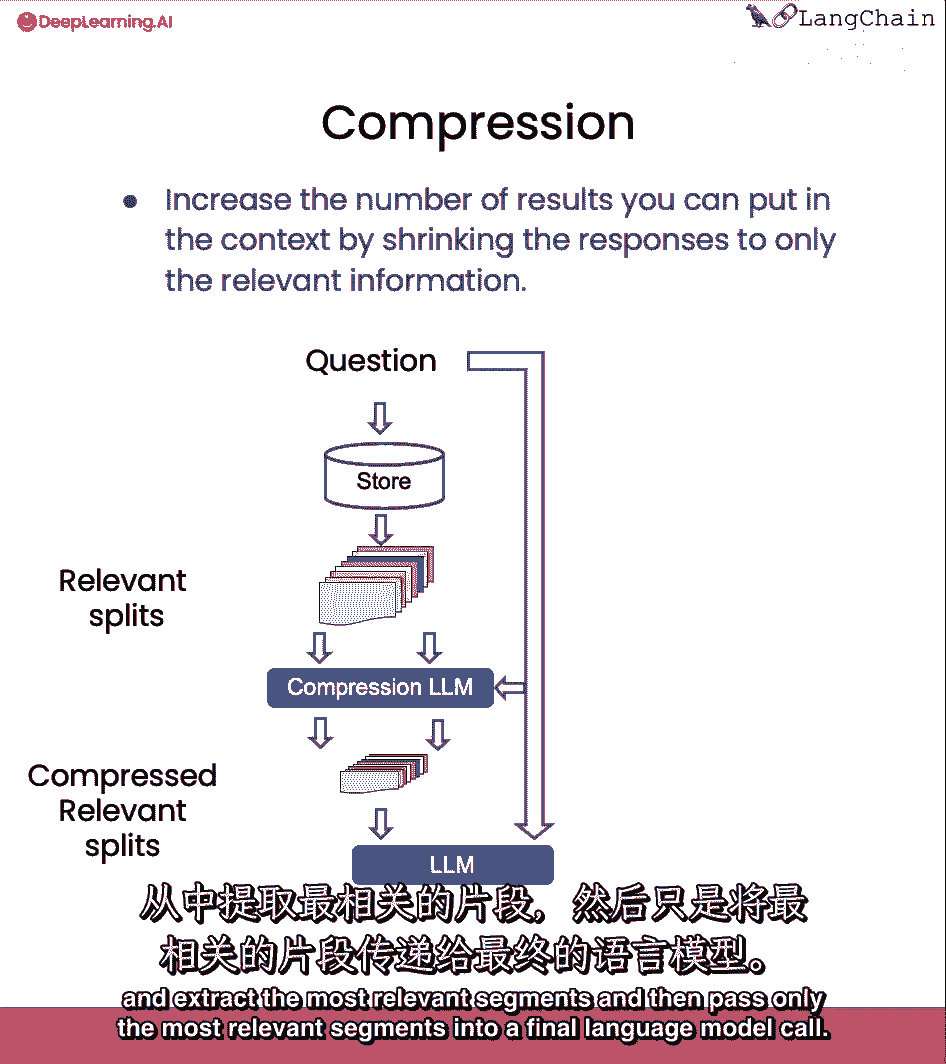
这以使更多的调用自然语言模型为代价。
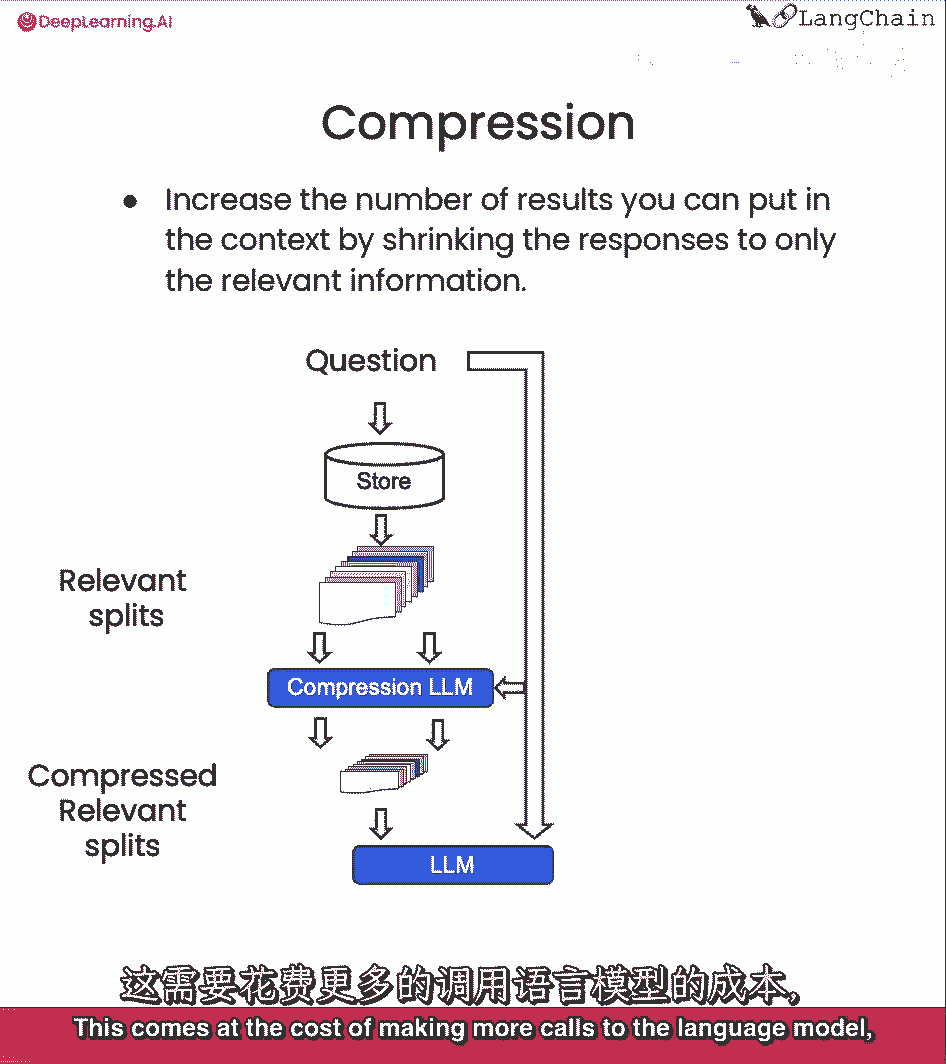
但它也非常好用于将最终答案集中在最重要的事情上。
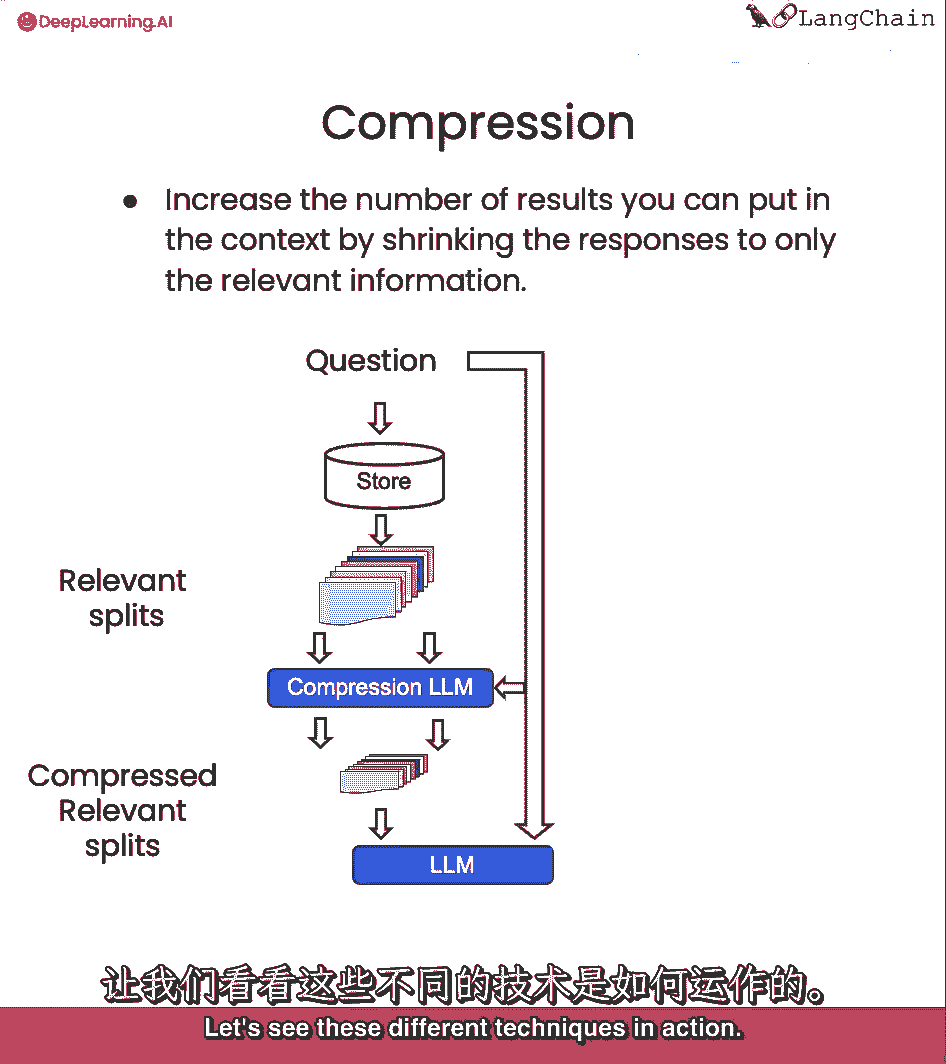
因此,它是一种权衡,让我们看看这些不同的技术如何发挥作用。
我们将开始加载环境变量,像我们总是做的。

导入chroma和open ai,因为我们之前使用过它们。

我们可以通过查看集合看到,计数,它包含了我们之前加载的209个文档。

现在让我们来看看最大边际相关性的例子。

因此,我们将加载来自示例的文本,其中我们有关于蘑菇的信息,对于这个例子,我们创建了一个小数据库,我们可以简单地使用它作为玩具,例如。

我们有我们的问题,现在我们可以运行相似性搜索,我们将k设置为2,只返回最相关的两个文档。

我们可以看到,没有提到它是有毒的,现在让我们运行它与mmr,除非将k设置为2,我们仍然想要返回两个文档,让我们将fetch k设置为3,我们获取所有3个文档,最初。

我们可以看到,有毒的信息在我们的检索文档中被返回。

让我们回到前一节课中的一个例子,当我们问关于matlab并返回包含重复信息的文档以刷新您的记忆。

我们可以查看前两个文档。

仅看前几个字符,因为它们否则很长,我们可以看到它们相同,当我们在这些结果上运行mmr时。

我们可以看到第一个与以前相同。

因为那是最相似的,但当我们转向第二个时,我们可以看到它不同。

响应中有一些多样性。

现在让我们转向自我查询示例,这是我们有问题的一个。

第三讲座中他们说了什么关于回归,它不仅返回来自第三讲座的结果。

而且还来自第一和第二,如果我们手动修复这个。

我们会做的就是我们指定一个元数据过滤器,所以我们传递这个信息,我们想要源等于第三讲座。

Pdf,然后如果我们看要检索的文档,它们都将来自精确的那一课。

我们可以使用语言模型来做这个,所以我们不需要手动指定,要做这个。
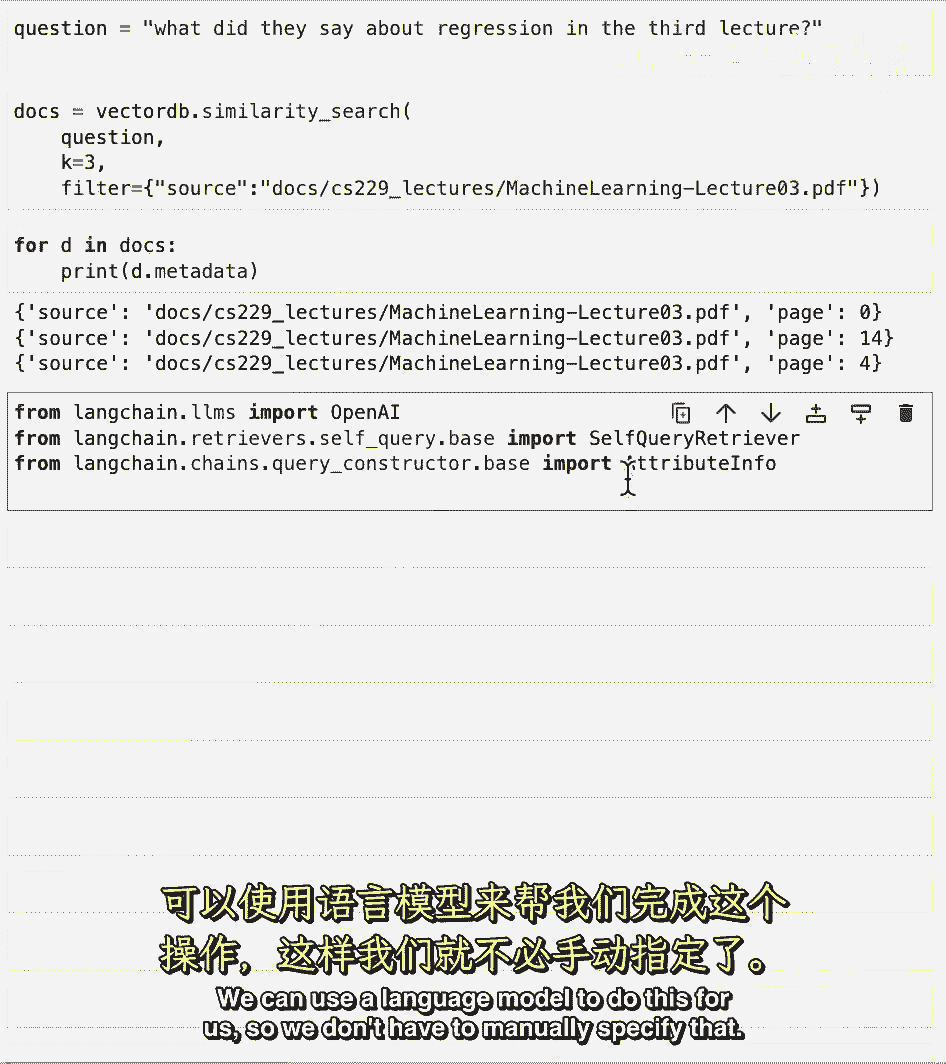
我们将导入一个语言模型open ai,我们将导入一个检索器叫做自我查询检索器。

然后我们将导入属性信息,这是 where 我们可以指定元数据中的不同字段以及它们对应什么。

我们在元数据中只有兩個字段。

來源和頁面,我們填寫每個屬性的名稱。

描述和類型,這信息實際上將被傳遞給語言模型。

因此,使它盡可能描述性是非常重要的。

我們將指定一些關於這個文档存儲的信息,我們將初始化語言模型,然後我們將初始化自我查询检索器使用 from lm 方法。

並傳遞給語言模型我們將要查詢的基礎向量數據庫,關於描述和元数据的信息,我們還將傳遞 verbose 等于 true 的設置。

verbose 等于 true 的話,讓我們看看底下的情況,當 llm 推断出應該與任何元数据过滤器一起傳送的查询時。

當我們使用這個問題運行自我查询检索器時。

我們可以 thanks to ruo 等于 true,儘管我們在打印出底下的情況。

我們得到一個關於回歸的查询,這是語義的部分,然後我們得到一個過濾器,我們有一個比較器等于,在來源屬性和一個值 docs 之間。

然後這是一個路徑,這是到第三機器學習講座的路徑,所以,这基本上在告诉我们在回归语义空间中进行查找,然后进行过滤,只查看源值为此值的文档。

因此,如果我们遍历文档并打印出元数据,我们应该看到它们全部来自第三堂课。

确实如此,这是一个例子,在这里,自我查询检索器可以用于精确过滤元数据。

我们可以讨论的最后一种检索技术是上下文压缩,因此,让我们在这里加载一些相关的模块。

上下文压缩检索器,然后一个llm链提取器。

这将做什么,这将从每个文档中提取只有有关的部分。

然后将这些作为最终返回响应,我们将定义一个漂亮的小函数来打印出文档。

因为它们往往很长且困惑,这将使事情更容易看到。

我们可以然后创建一个压缩器与llm链提取器。
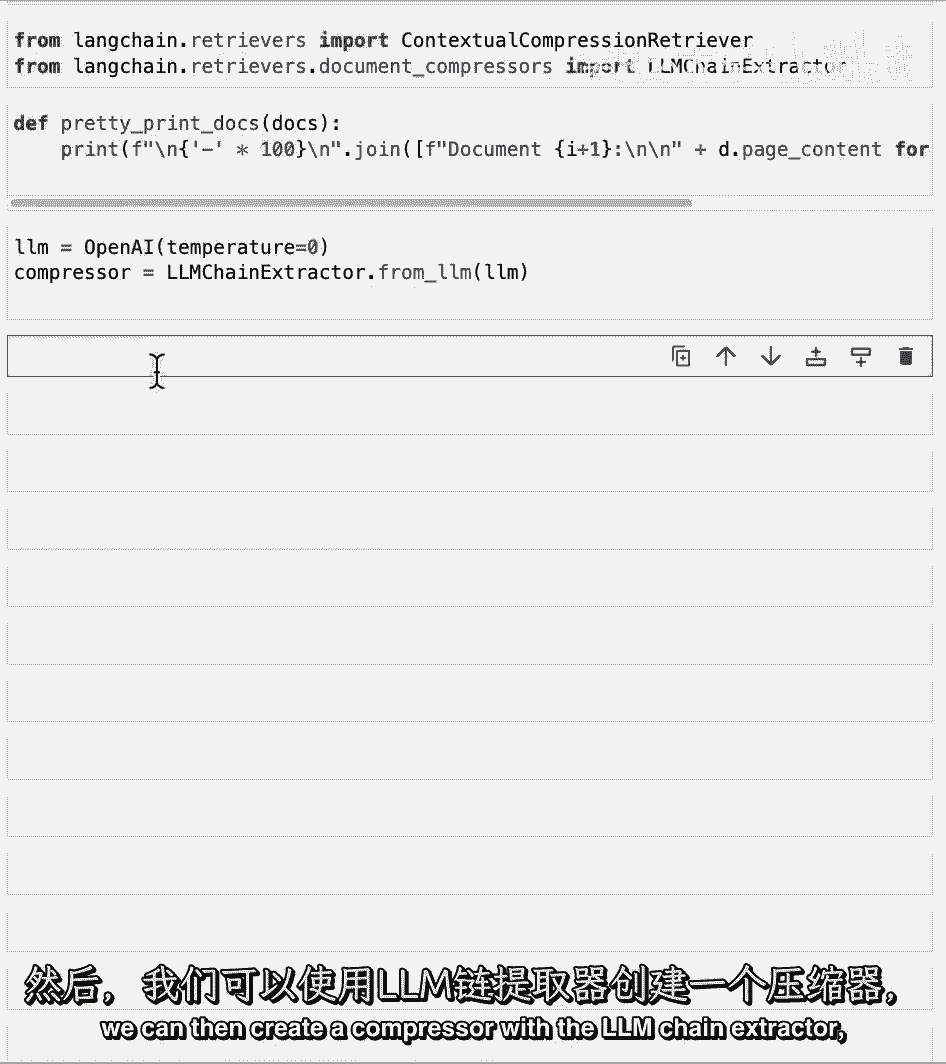
然后我们可以创建上下文压缩检索器,输入压缩器。
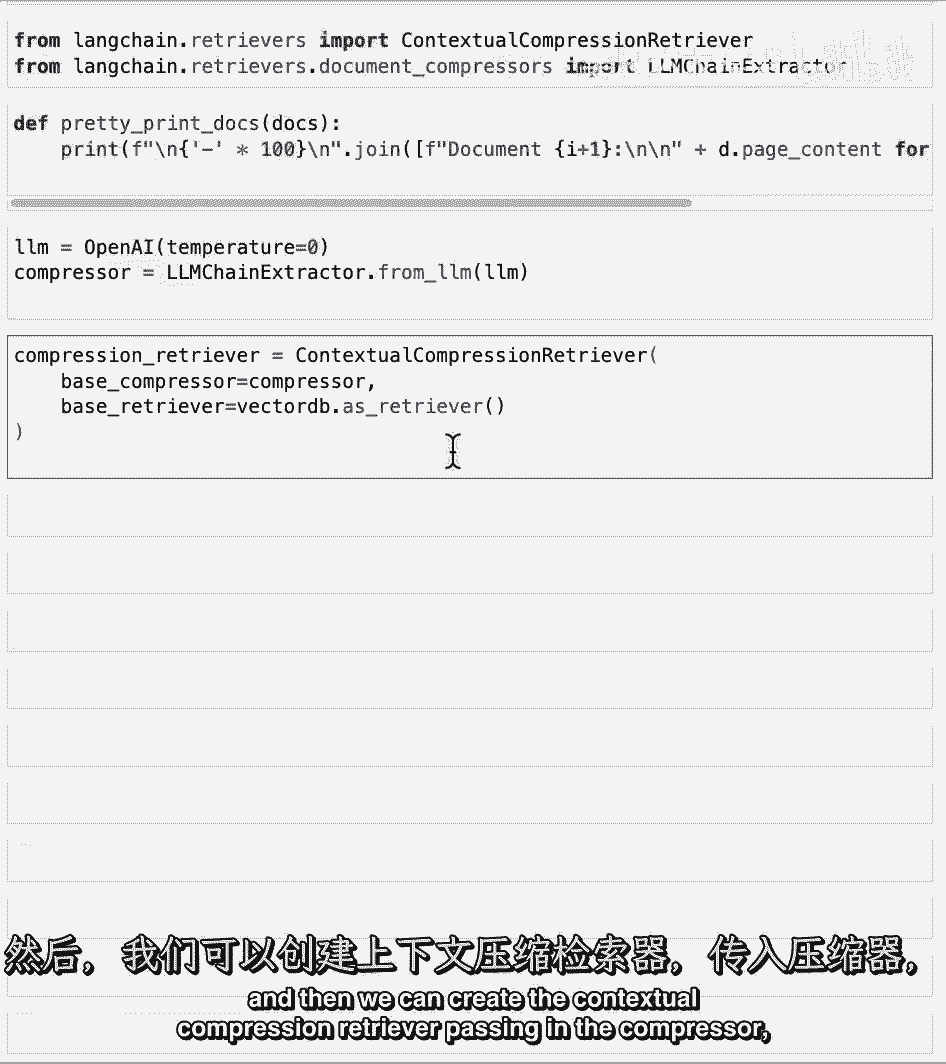
然后向量存储的基础检索器,现在我们输入问题,他们对matlab说了什么。

我们查看压缩的文档,如果我们查看返回的文档,我们可以看到两件事,一,它们比正常文档短得多,但二我们还有一些重复的东西在进行,这是因为我们底层使用了语义搜索算法。
这就是我们通过本课程前面的mmr解决这个问题的方式,这是一个你可以结合各种技术以获得最佳可能结果的好例子,为了做到这一点,当我们从向量数据库创建检索器时,我们可以将搜索类型设置为mr。
然后我们可以重新运行这个,并看到我们返回,一个不含有任何重复信息的过滤结果集,到目前为止,我们所提到的所有附加检索技术都建立在向量数据库之上。

值得注意的是,还有其他类型的检索方法根本不使用向量数据库。

而是使用其他,更传统的nlp技术。

在这里,我们将重新创建一个检索管道,使用两种不同类型的检索器,和一个svm检索器和一个tf-idf检索器。

如果你从传统的nlp或传统的机器学习中认识这些术语,那太好了。

如果你不,这也没关系,这只是一些其他技术在外面的例子。

除了这些,还有更多的,我鼓励你去检查一下,其中的一些。

我们可以很快地运行加载和分割的常规管道。
然后这两个检索器都暴露了一个从文本方法,一个接受嵌入模块的检索器是svm检索器,tf idf检索器只是直接接受分割。

现在我们可以使用其他检索器,让我们传递,他们对matlab说了什么,给svm检索器,我们可以查看最顶部的文档,我们回来可以看到它提到了很多关于matlab的东西,所以它在那里取得了一些好的结果。
我们也可以尝试在tf idf检索器上这样做,我们可以看到结果看起来稍微差一些,现在是个好时机,停下来尝试所有这些不同的回收技术,我想你会注意到一些比其他的好在一些事情上。
所以我鼓励你尝试在各种问题上进行广泛的测试,特别是自查询检索器,这是我最喜欢的,所以我建议你尝试使用更多的复杂元数据过滤,甚至可能创建一些没有实际意义的元数据,其中包含嵌套的元数据结构。
你可以尝试让llm推断,我认为这非常有趣,我认为这是一些更先进的东西,所以我非常兴奋能够与你分享它,现在我们已经谈论了检索,我们将谈论这个过程的下一步。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P38:6——问答聊天机器人 - 吴恩达大模型 - BV1gLeueWE5N

已讲解如何检索相关文档,下一步是处理这些文档,取原始问题,连同文档一起给语言模型,让它回答问题,本课将讲解及几种方法,让我们开始这节课。
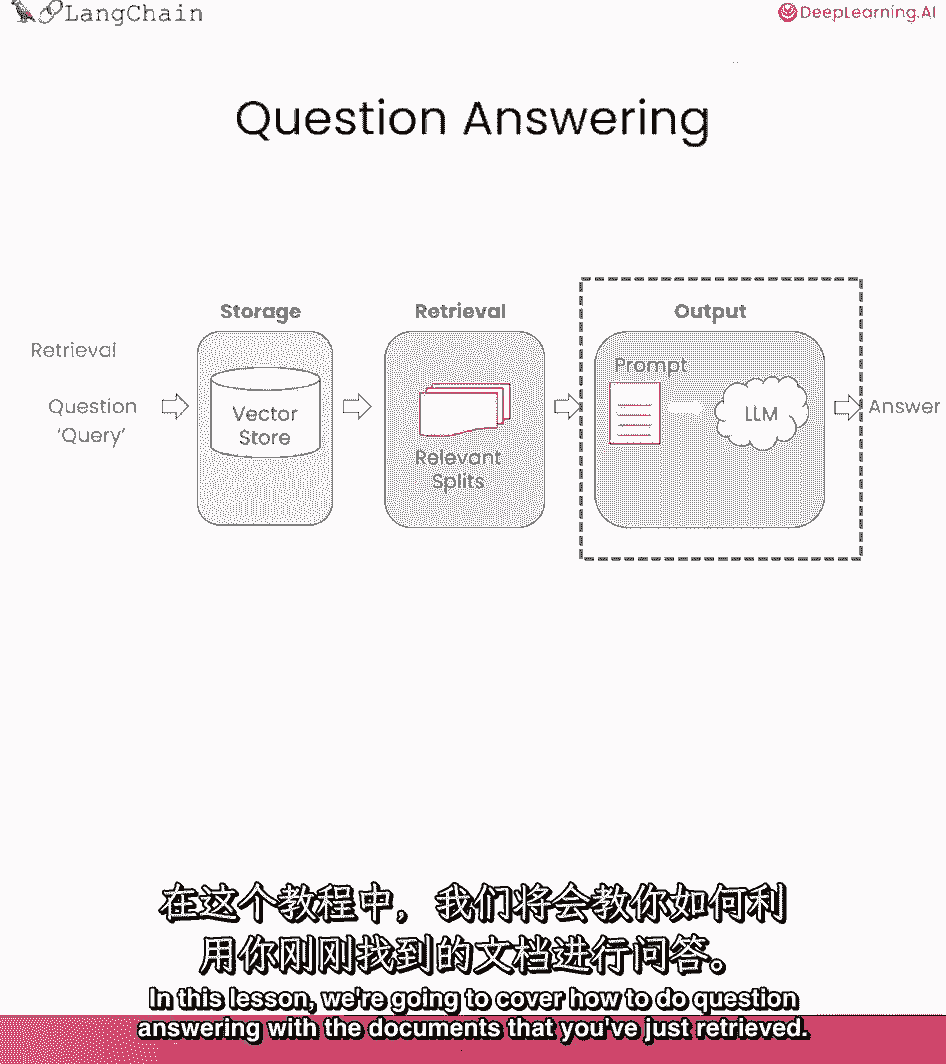
将讲解如何用已检索文档,回答问题,在完成存储和导入后,获取相关切分后,需传入语言模型得答案。
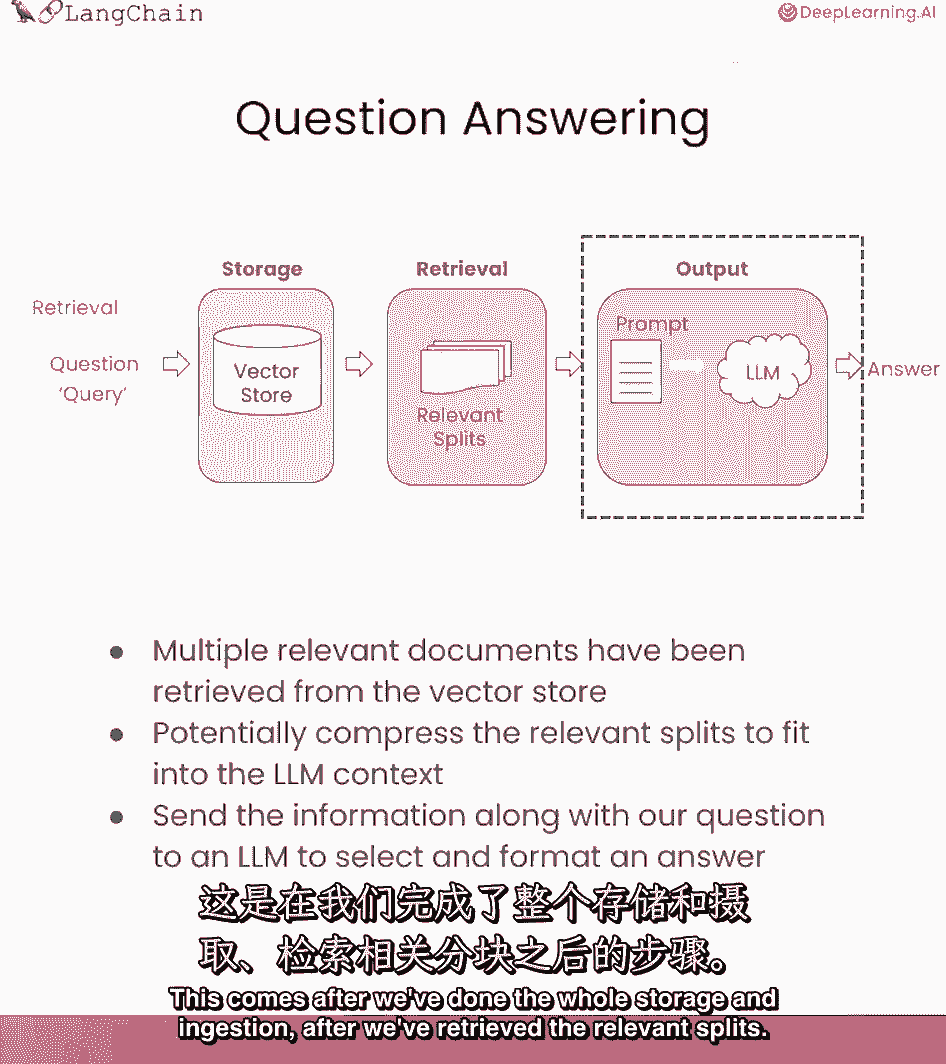
流程大致如下,问题输入。
查找相关文档,然后传入这些切分,连同系统提示和问题。
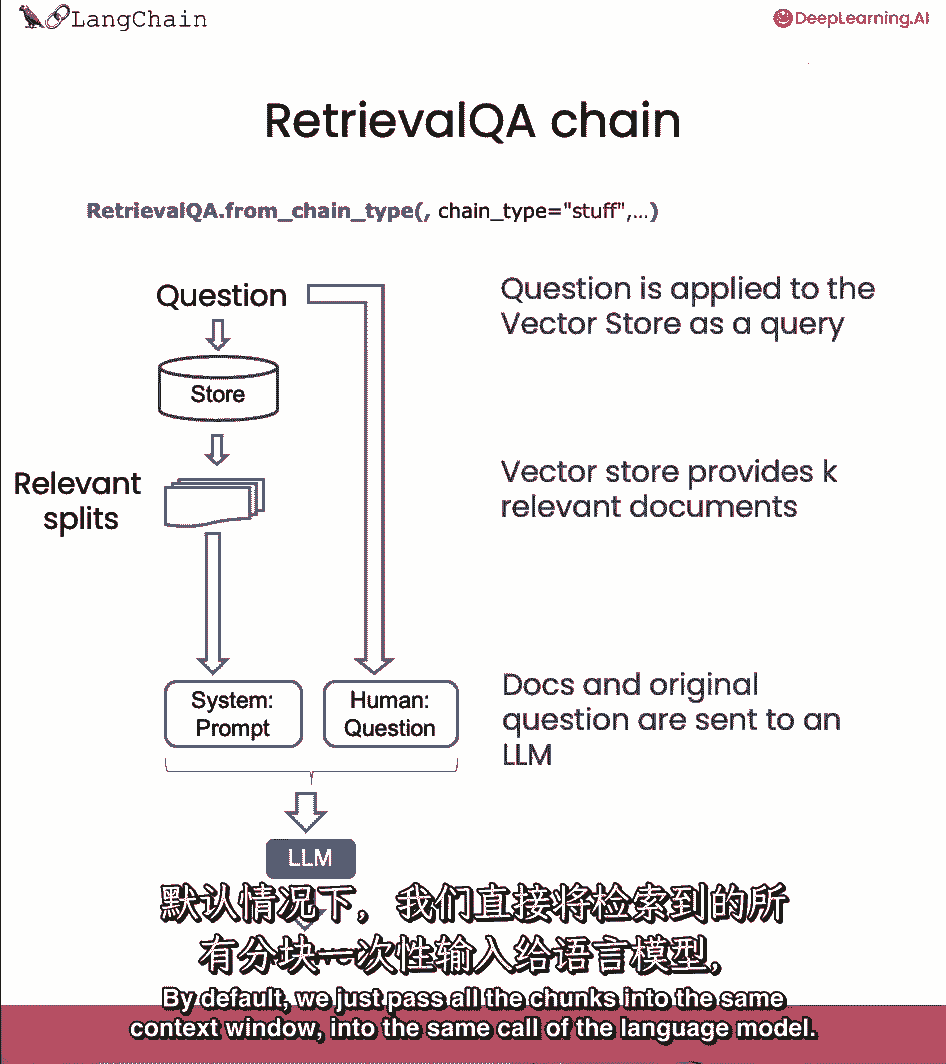
语言模型给出答案,默认情况下,所有块放入同一上下文,进入语言模型的呼唤。
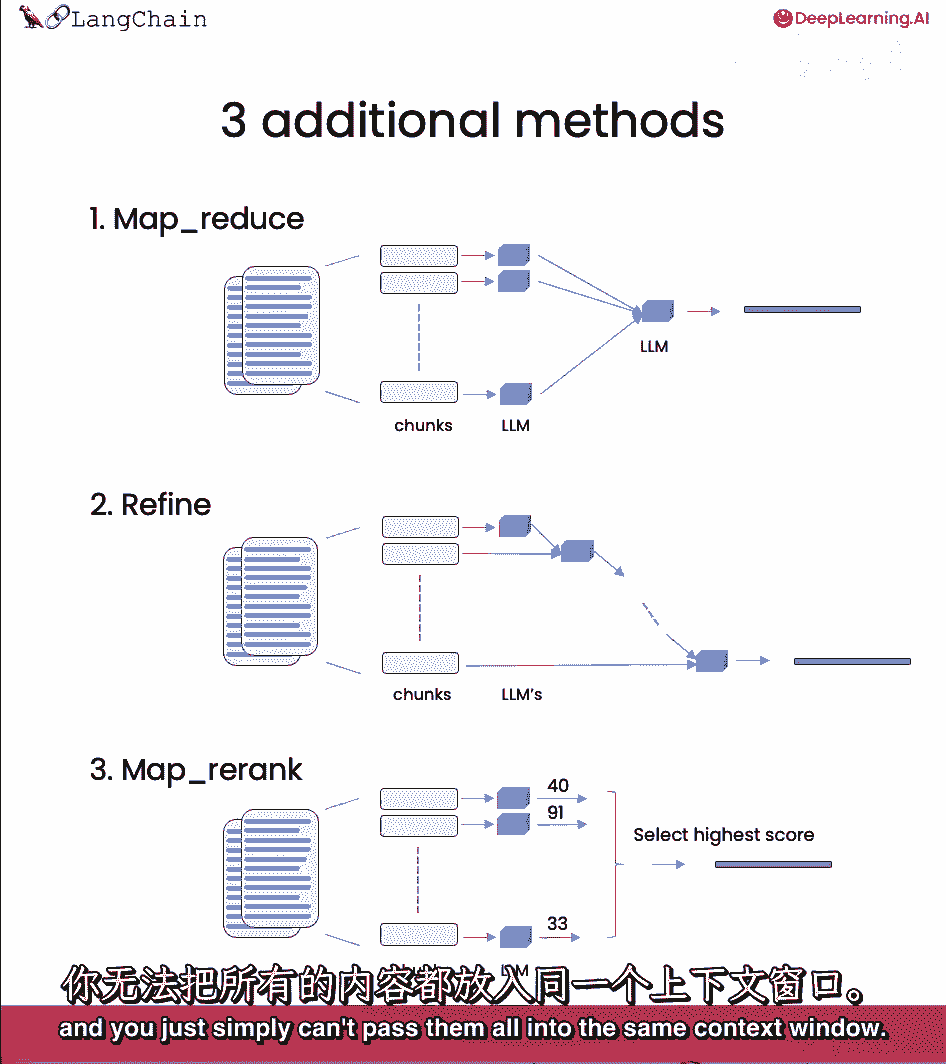
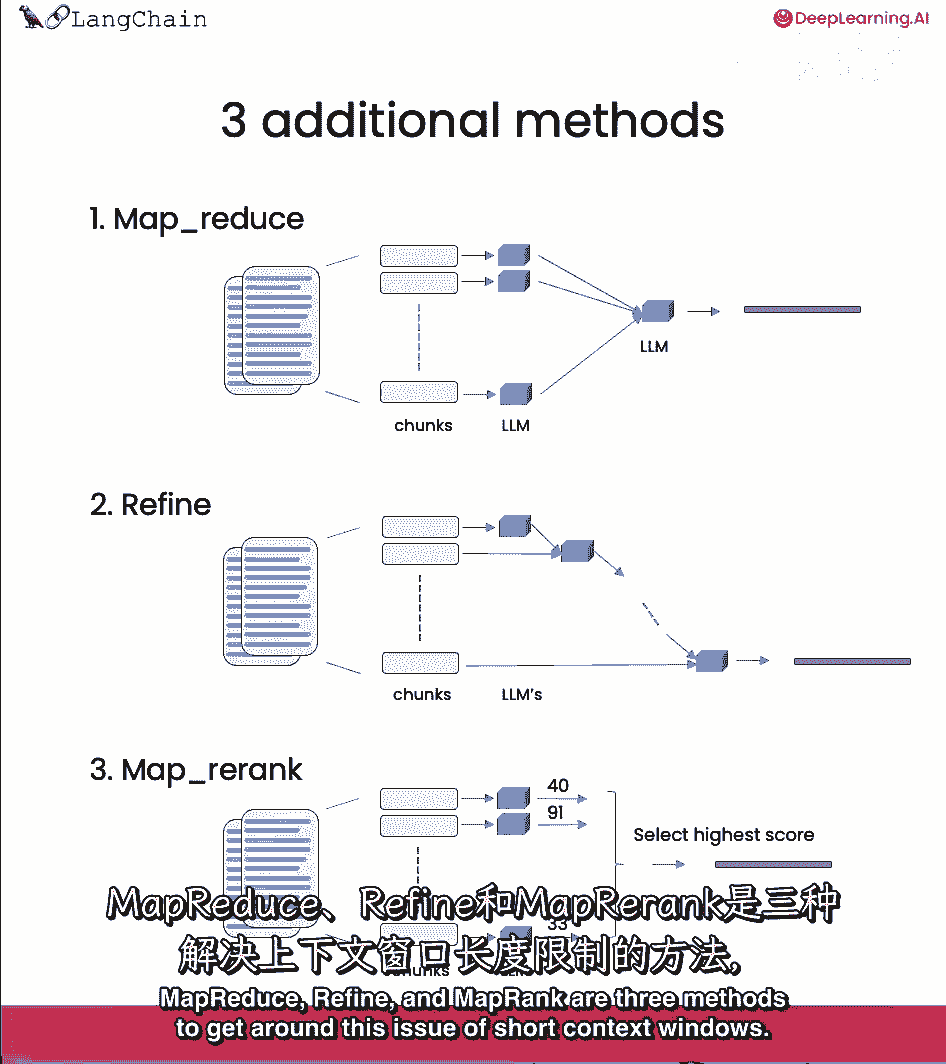
但有几种不同方法,各有优缺点。
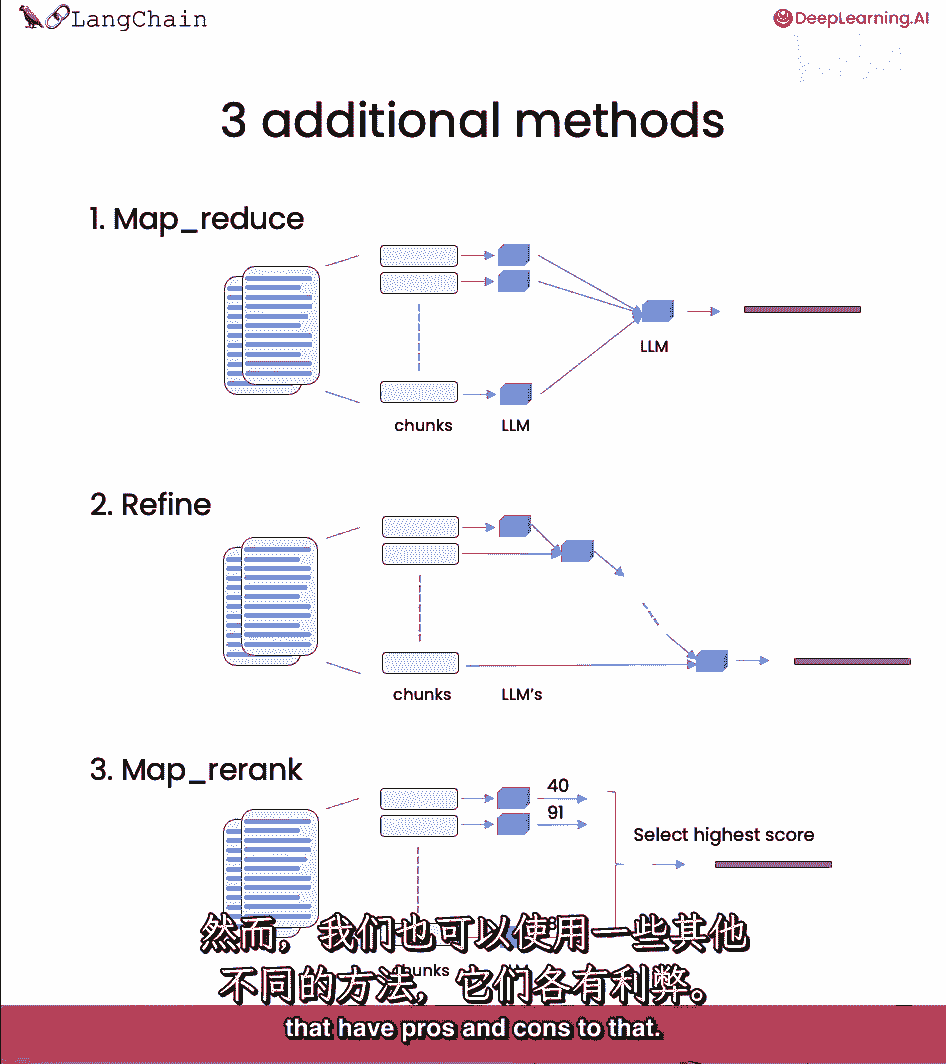
大部分优点来自有时会有很多文档,你无法将它们全部放入同一上下文中。
Mapreduce,精炼。
今天课程中我们将涵盖其中一些,开始编码。
首先,我们将加载环境变量。

然后加载之前持久化的向量数据库,我将检查其正确性。
可见与之前相同,有209个文档。
快速检查相似性搜索,确保为第一个问题工作:本课程的主要主题是什么。
现在初始化将用于回答问题的语言模型。

我们将使用Chat Open AI模型gpt 3。5。

并将温度设置为0,当我们需要事实答案时,这非常好。

因其变化性低,通常提供最高保真度,最可靠答案。

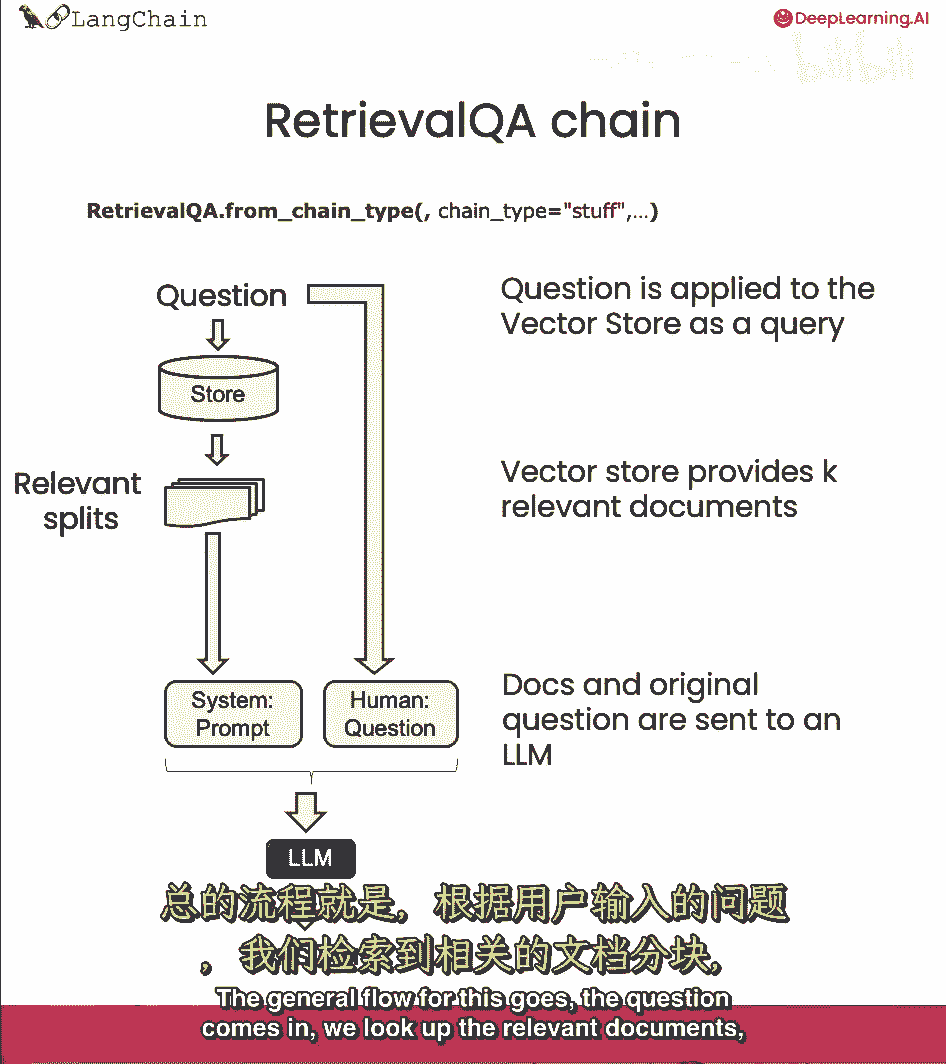
然后导入检索QA链,这是基于检索的问题解答,由检索步骤支持。

可通过传入语言模型创建。
然后向量数据库作为检索器。

然后可调用它,查询等于要问的问题。
查看结果,我们得到一个答案,本课主要话题是机器学习,此外,讨论部分可能会复习统计和代数。

本季度晚些时候,讨论部分还将涵盖主要讲座材料的外延。

让我们试着更好地理解,底层发生了什么,并揭示一些主要部分的调整旋钮,重要的是我们使用的提示,这是接受文档和问题并将其传递给语言模型的提示。

关于提示的复习。

可以查看我与安德鲁的第一堂课,这里我们定义了一个提示模板。

有一些关于如何使用以下上下文片段的说明,然后它有一个上下文变量的占位符,这是文档将放置的地方,还有一个问题变量的占位符。

我们现在可以创建一个新的检索,Qn,我们将使用与之前相同的语言模型,与之前相同的向量数据库,但我们将传递一些新的参数,所以我们有返回源文档,所以我们将此设置为真,这将使我们能够轻松检查检索到的文档。

然后我们还将传递一个提示。

等于qa链,上面定义的提示,让我们尝试一个新问题是概率,一个课程主题。

我们得到一个结果,如果我们检查里面的内容,我们可以看到是的,概率被认为是课程的前提。

讲师假设对基本概率统计熟悉,我们将在讨论部分复习一些先决条件,作为复习课程,谢谢提问回答我们也很高兴,为了更好地理解它从哪里获取数据。

我们可以看一下返回的源文档。

如果你浏览它们,你应该看到所有被回答的信息都在这些源文档之一中,现在是一个暂停并尝试一些不同问题的好时机,或者你自己的不同提示模板,看看结果如何变化。
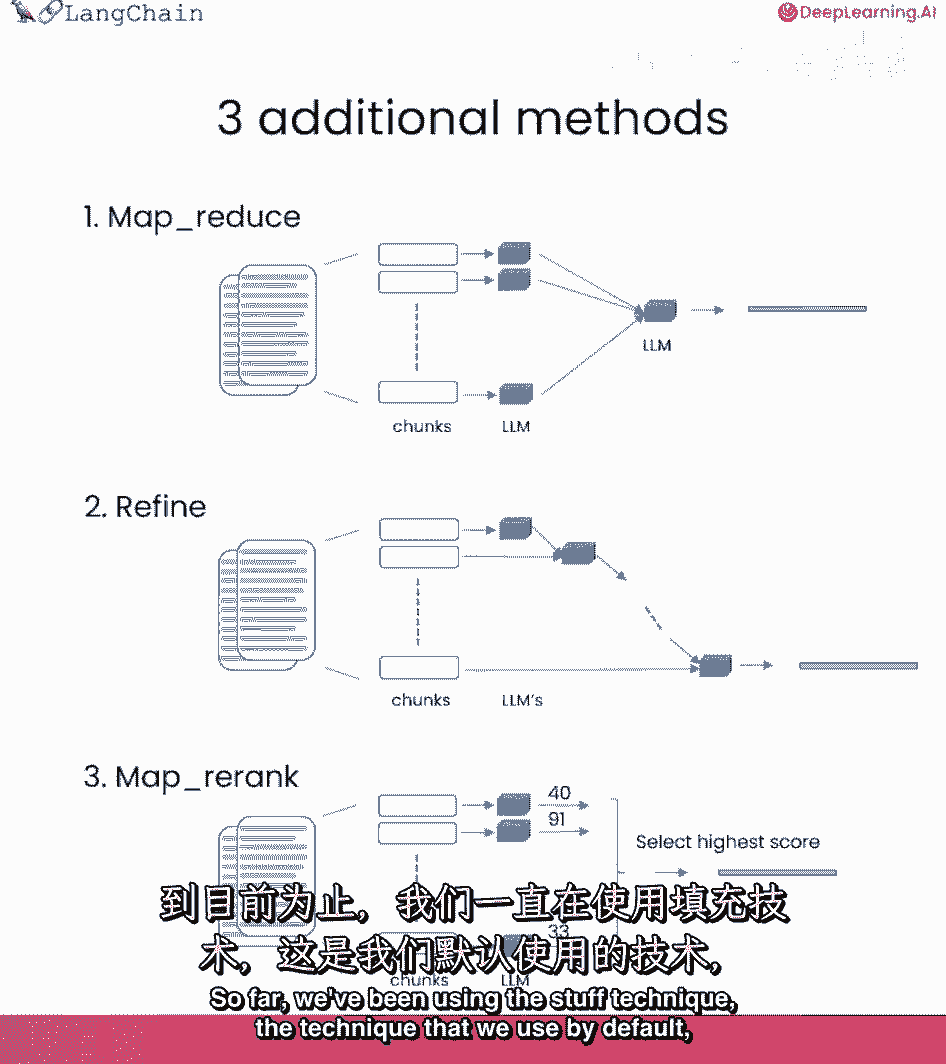
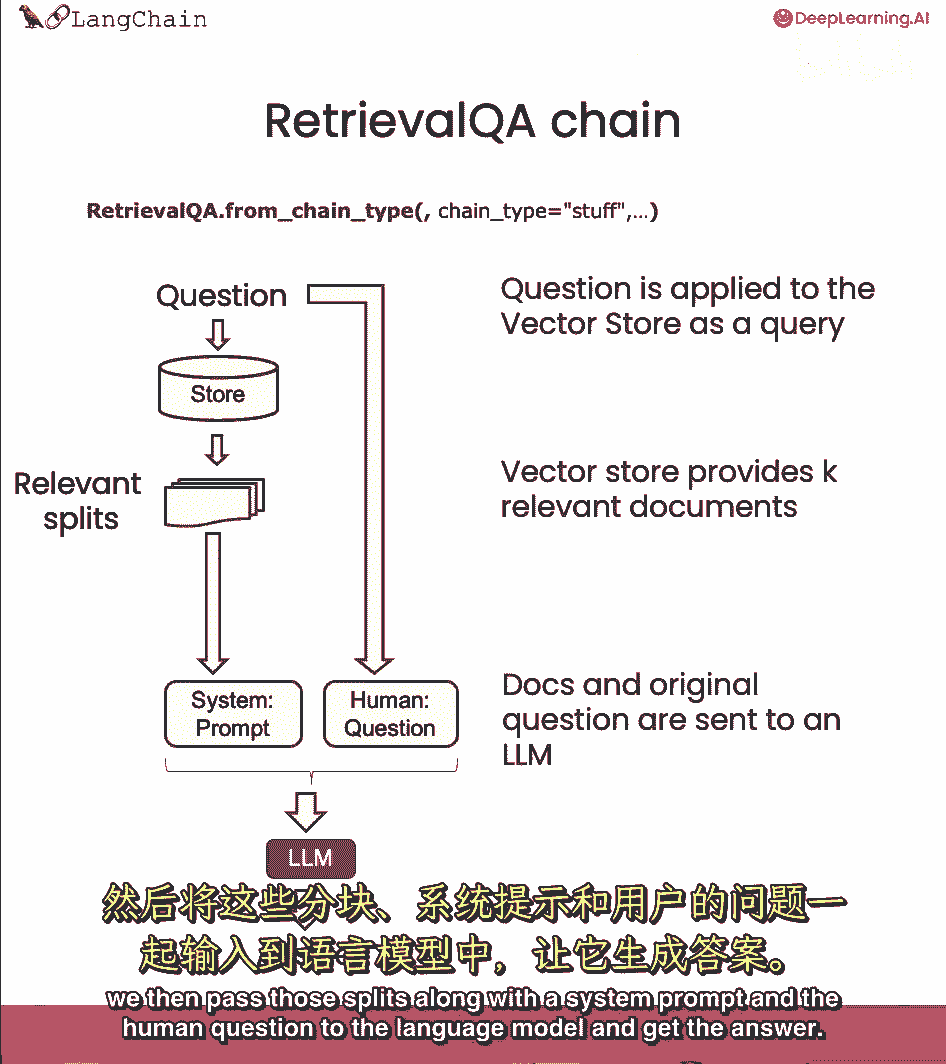
我们一直在使用stuff技术,我们默认使用的技术,基本上只是把所有文档都塞入最终提示中,这真的很好因为它只涉及一次对语言模型的调用,然而,这也有一个限制,如果有太多的文档。
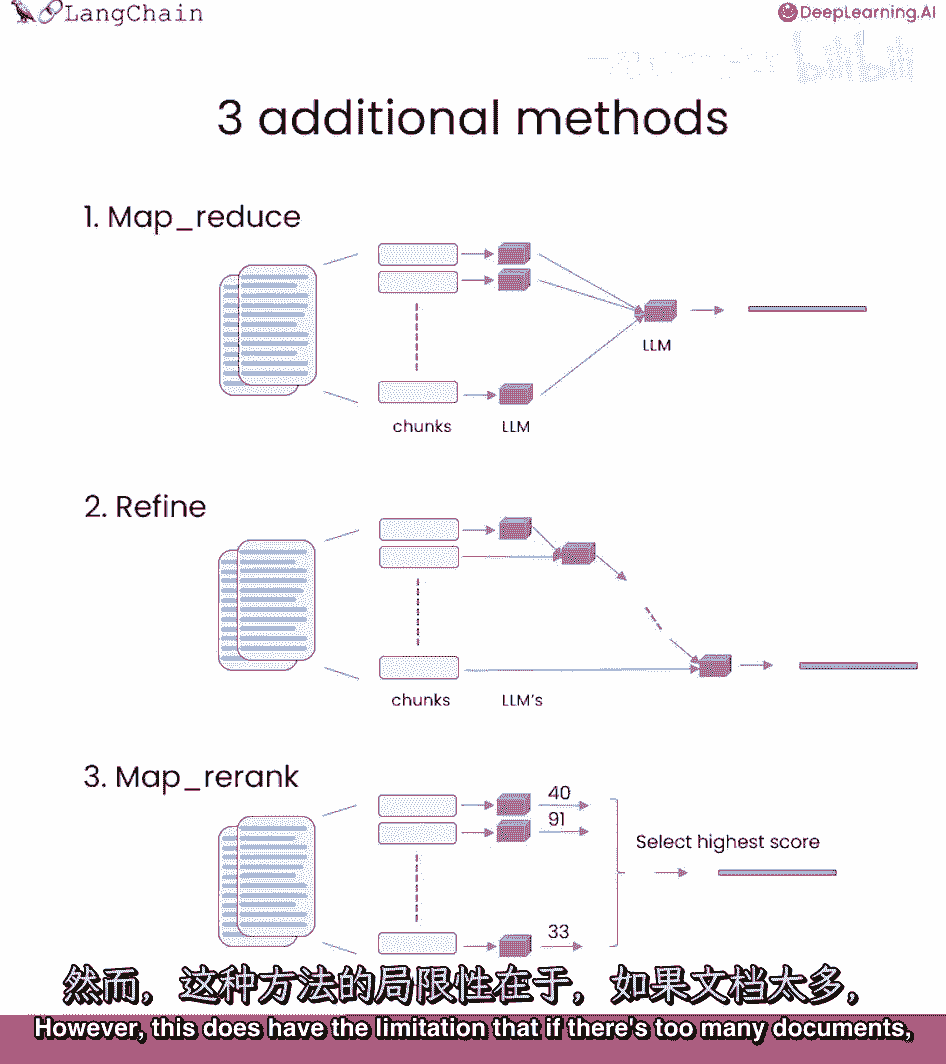
它们可能无法全部放入上下文窗口,我们可以使用的不同技术,文档问答中的mapreduce技术,每个文档先单独送至语言模型。
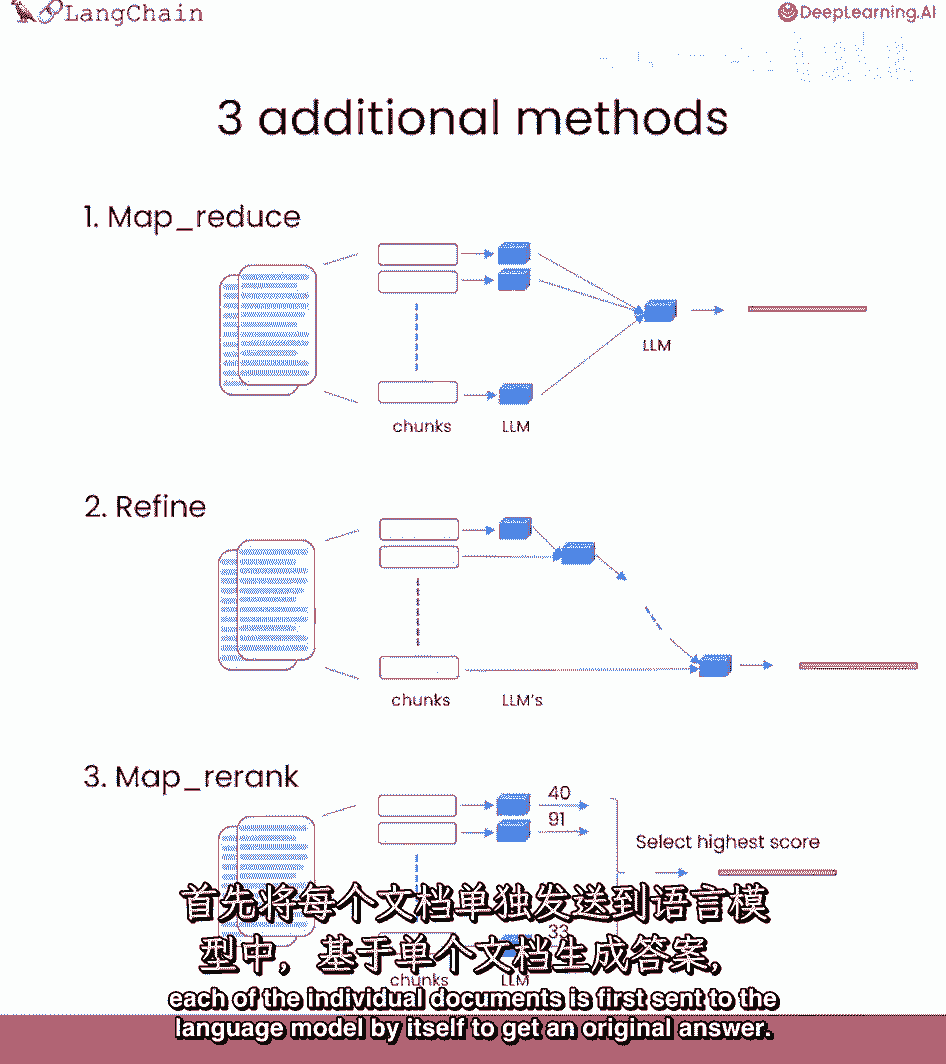
然后这些答案组合成最终答案。
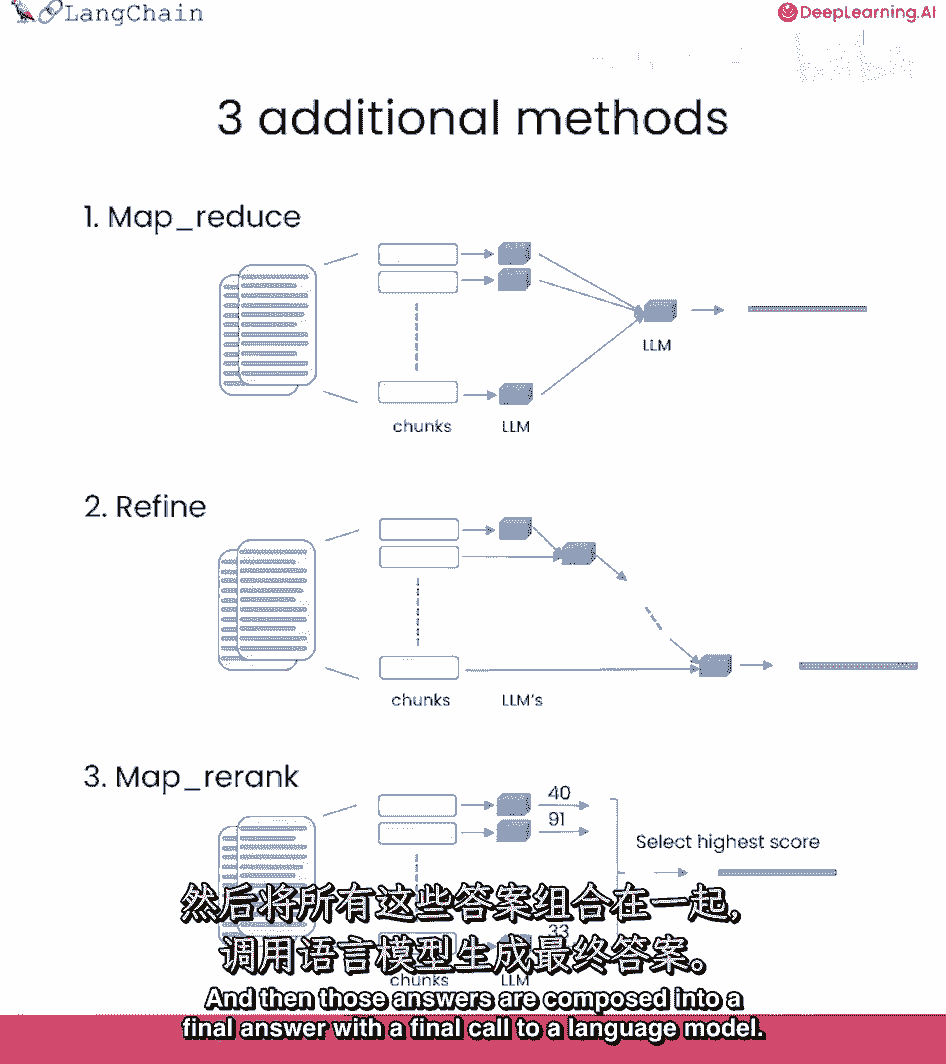
这涉及更多语言模型的调用,但它可以处理任意多文档。
运行前一个问题,可看到此方法的另一个限制,实际上可以看到两个,它要慢得多,二,结果实际上更糟,这个问题没有明确答案,根据文档的部分内容,这可能是因为它基于每个文档单独回答。

因此,如果信息分散在两个文档中,它没有在同一上下文中拥有所有信息。

这是一个使用车道链平台获得更好理解的机会,关于这些链条内部正在发生的事情。

我们将在此处演示,如果你想自己使用。

课程材料中有说明,如何获取API密钥,设置这些环境变量后,我们可以重新运行映射,减少链,然后我们可以切换到UI查看。

内部,从这里可以找到刚运行的运行。
我们可以点击查看输入和输出,然后可看到孩子跑分析,内部,首先,有MapReduce文档链,实际涉及4次语言模型调用。

若点击其中一个调用,可看到每个文档的输入和输出。

若返回,然后可看到遍历每个文档后,最终合并为链,将所有回复填入最终调用的填充文档链,点击进入。
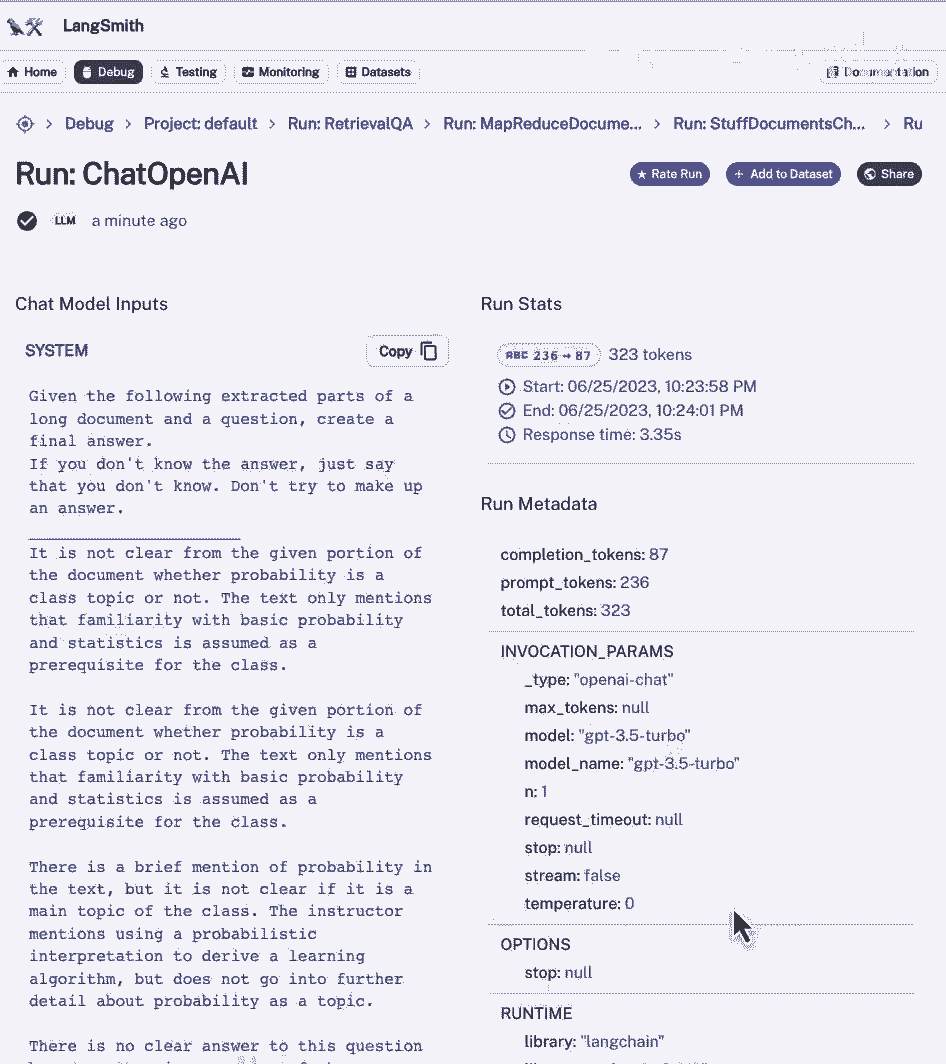
我们看到系统消息,来自先前文档的4个摘要,然后使用你的问题,然后有答案在那里,我们可以做类似的事情,将链类型设置为细化。

这是一种新的链类型,让我们看看内部是什么样子,我们看到它在调用精炼文档链,涉及对llm链的四个连续调用,让我们看看这个链中的第一个调用,看看这里发生了什么,在发送给语言模型之前,我们有提示。
我们可以看到一个由几部分组成的系统消息,此上下文信息在下面的部分,是系统消息的一部分,它是我们提前定义的提示模板的一部分,接下来的这部分,所有这些文本,这是我们检索到的其中一个文档,下面是用户问题。
然后这里是答案,如果我们回到前面,我们可以看看对语言模型的下一个调用,发送给语言模型的最终提示,是一个将先前响应与新数据组合的序列,然后请求改进的响应,所以我们可以看到,我们有了原始用户问题。
然后我们有了答案,这跟之前的一样,然后我们说我们有机会仅用下面的更多上下文改进现有答案,如果需要的话,这是提示模板的一部分,一部分指令,其余部分是我们在列表中检索到的第二个文档,然后我们可以看到。
在新的上下文中,我们有一些额外的指令,改进原始答案以更好地回答问题,然后在下面我们得到了最终答案,但这是第二个最终答案,这个过程运行四次,在所有文档之前运行,然后到达最终答案,最终的答案就在这里。
课程假设熟悉基本概率和统计,但我们将有复习部分来刷新先决条件,你会发现这比MapReduce链更好,因为使用精炼链确实允许你组合信息,尽管是顺序的,它实际上比MapReduce链更鼓励信息的传递。
这是一个暂停的好机会,尝试一些问题,尝试不同的链,尝试不同的提示模板,看看它在UI中看起来像什么,这里有很多可以玩的东西,聊天机器人的一大优点,也是它们越来越受欢迎的原因之一是你可以问后续问题。

你可以要求对之前的答案进行澄清,所以让我们在这里这样做,创建问答链,使用默认内容。

问它,问题概率,课程主题。

然后问后续问题,提到概率是前提,然后问,为何需要前提,得到答案,课程前提是计算机基础,和之前无关的计算机技能,我们问概率,怎么回事,我们用的链无状态概念,不记得先前问题或答案,需引入记忆。