Abstract
这个系列主要用来记录我自己这种的AI小白的学习之路,通过将所学所知总结下来,记录下来。之前总喜欢记录在笔记本上,或者ipad上,或者PC端的Typora上,但总是很难回头检索到一些系统的知识,因此我觉得博客是一个不错的选择,因为时不时我就会登录网站翻看过去的痕迹,我觉得这是一种很不错的学习习惯,特此开坑,以后研究生三年时间,我将不断更新的随笔日志,既为了系统记录我的新知,也为了便于后人学习。
所以如有不当之处,欢迎评论指出,因为鄙人也是在学习。
【tip】之后的学习中我将大量使用"3W"原则来记录,就是Why?HOW?WHAT?将为什么用它、怎么用它到将它用在哪里一一说明。
这里贴出我的学习源头:
https://www.bilibili.com/video/BV13z421U7cs/?spm_id_from=333.337.search-card.all.click&vd_source=dbf0a5b21ee3e608136d2de2f7aa4035
WHY
GPT
GPT全称是一种“生成式预训练Transformer”
即:Generative Pre-trained Transformer,从名字不难看出,我们为啥要了解Transformer了
- Generative指的是生成文本这种
- Pre-traned指的是模型经历了从大量数据中学习的过程。预是预先的意思,指的是模型能够针对具体任务,通过额外的训练来进行微调
- Transformer就是一种特殊的神经网络,也是一种机器学习的模型
语言翻译
输入数据,预测输出,取softmax,作为预测的下一个值

但实际中GPT-3的输出感觉就比GPT-2要舒服太多了,这也是由于模型规模所造成的。
与GPT交谈的过程
step1
你的输入媒体被翻译为Token,也即是小片段,可以是单词、单词片段、语音片段或者图像小块

一个token就是一个向量
step2
Attention注意力机制。就是找出上下文中那些词会改变哪些词的含义,然后更新这些词的含义,就比如下文中的model和model是含义完全不同的两个词。
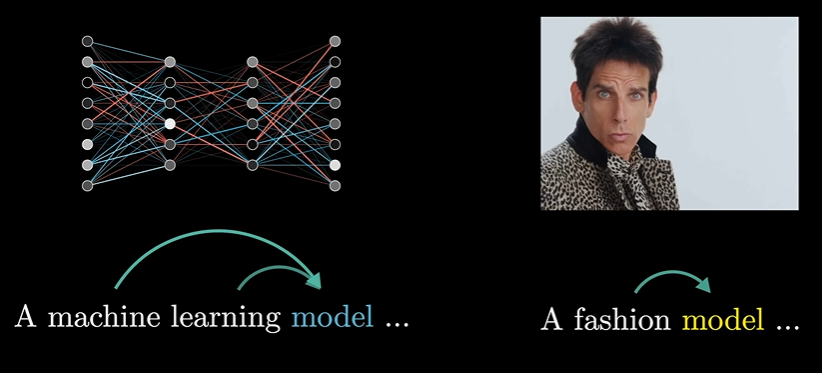
step3
多层感知机 Multilayer Perception
前馈神经网络层,类比于神经网络的计算
step4、5、6、7、8、9………………
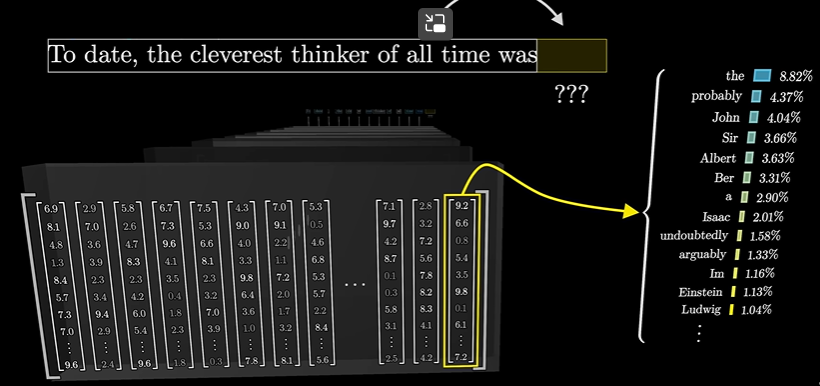
最终得到所有token的概率分布,进而预测下一个词
以上就是我们为啥要学习Transformer的原理了
HOW?
这个地方就详细说明他的原理了。
比方说我们想得到这么一种函数,就是输入图像我们可以让它输出对图像的描述,或者就上面所述,输入文本,能够预测输出。
AI初期做法
写死model,也就是控制领域的”开环“
即:try to explicitly define a procedure for how to do that task in code
试图在代码中,明确定义如何执行一个任务

AI现在做法
一堆参数,给我什么类型的数据,我就改变对应的参数。像一堆仪表盘一样,调整数值。

机器学习最基本的模型
线性回归
比如你们老师上课常举得例子:房价预测模型
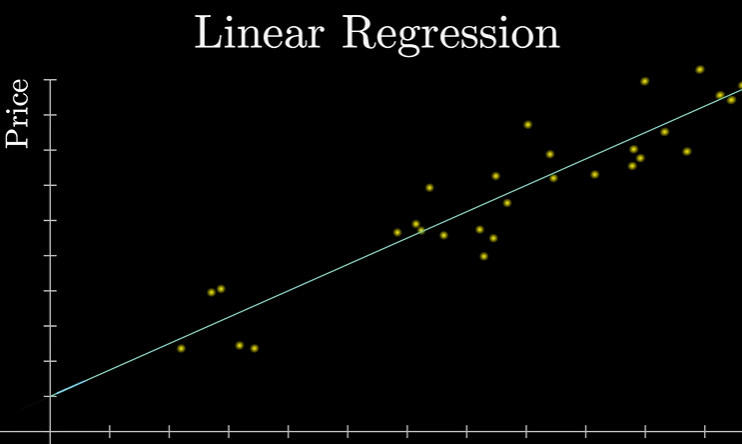
就是找一条曲线来尽可能的拟合所有数据。当然这种数据也是一对一的,自变量为1,因变量也为1.
将参数矩阵分为几大类
俗话说的好,数据越多越复杂(当然你很可能认为是废话)
由于参数多,所以集成化

几何角度的加权求和
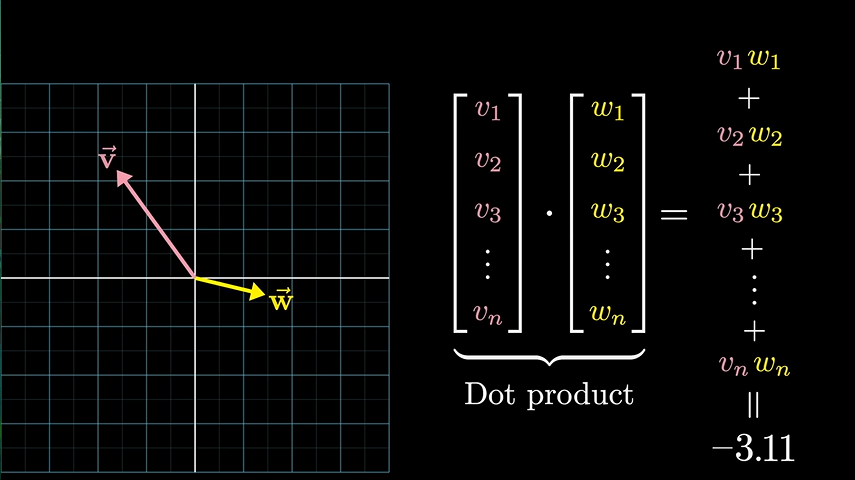
向量点乘
词嵌入(Word Embedding)
我们为什么要将单词映射到向量?
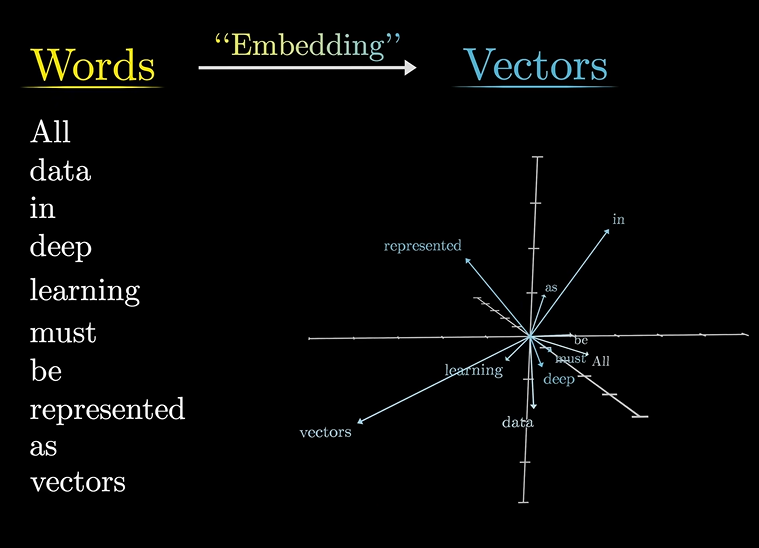
这就不得不提到词向量模型了,这是自然语言处理领域一大重点。
词向量模型可以分为两类:基于统计的方法和基于深度学习的方法。基于统计的方法包括one-hot编码、n-gram等,而基于深度学习的方法则包括Word2Vec、GloVe和Transformer等。我们重点介绍Transformer的。
在Transformer模型中,词向量是通过嵌入层实现的。嵌入层将输入的单词转换为固定大小的向量,这些向量表示单词的语义信息。与传统的词向量方法不同,Transformer使用的是位置编码(Positional Encoding)技术来捕获单词的位置信息。
那么是如何实现的呢?
我们常用one-hot编码,也就是独热编码:
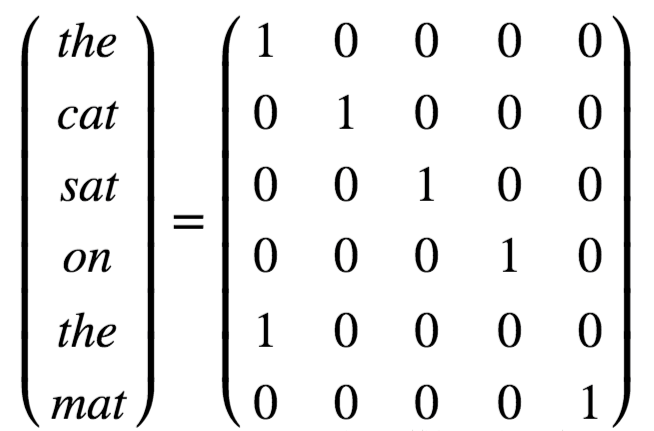
这种编码方式有一个缺点,那就是一个单词对应一个向量,所不同的仅仅是1的位置不同而已,这也就是独热编码的特点,也是缺点。。。。
而词嵌入的方式:
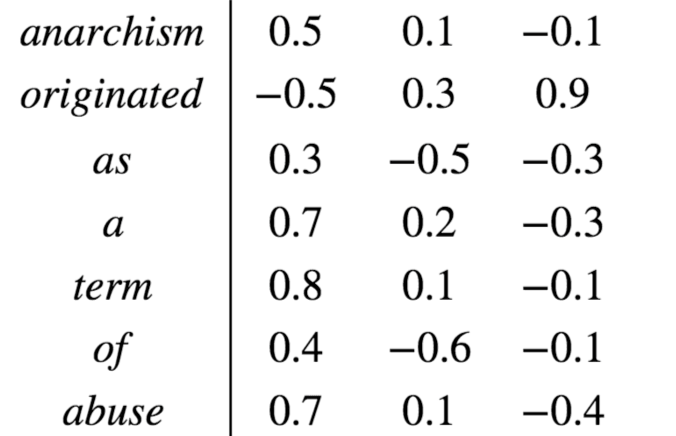
使用的是向量,向量在三维空间包含了方向、大小,不同向量之间还包含了夹角,代表两个词的关系程度,可以通过向量之间的点乘来实现,如下图:
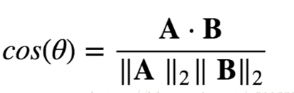
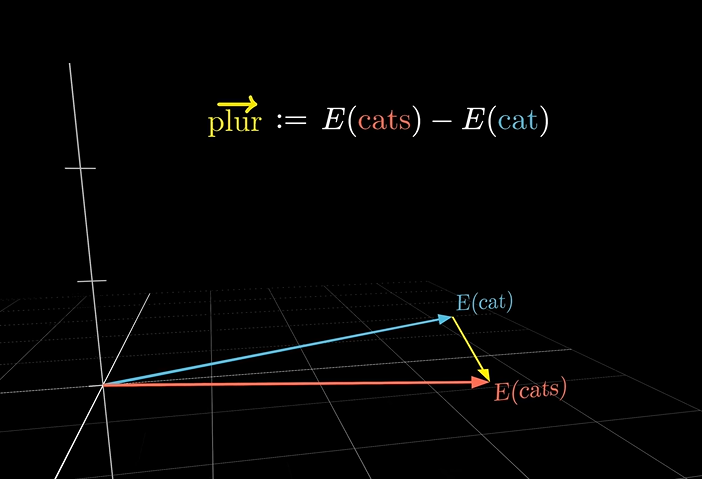
我们两个向量的关系越近,那么我们点乘的值应该越大,关系越远,点乘之间的值应该越小(负数)。这些代表单词的向量可以像数学那样随意加减,构成了一张复杂的关系网络,比如:
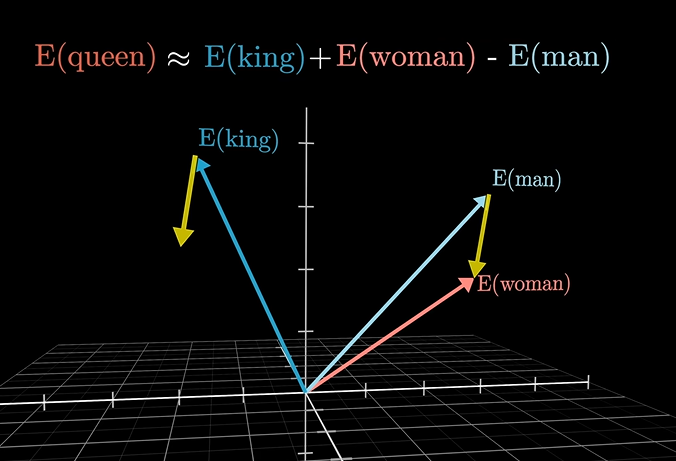
有趣的一点是,当使用cats-cat向量,将生成复数向量(这个复数不是虚数实数那个复数,是单词的复数!!!!!!)
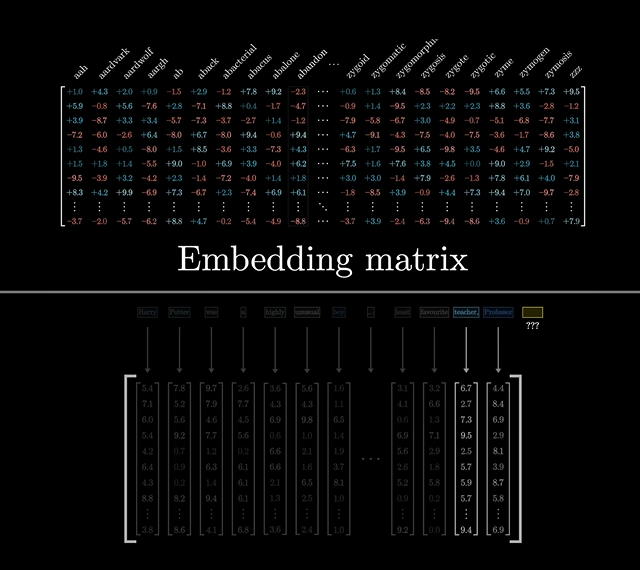
嵌入矩阵(Embedding Matrix)---大字典
这是GPT-3所用到的所有的词嵌入,总规模有6亿的参数量

大家可以把这个理解为一个大字典,你要的啥单词,查一下这个矩阵字典,就可以找到其对应的向量是啥。下面我们还会用到这个大字典。
语义分析
我们人类在思考问题时,常常会结合上下文来分析一个词的含义,比如:

这个词就受到很多词意思的左右。当然我帮大家查了这个词是羽毛笔的意思。

预处理
GPT拿来一个句子,首先进行的是将句子理解为一个一个的Token,注意哈:这时并没有考虑上下文的意思,仅仅是把Token从大字典里拿来进行一个简单的替换,得到对应的向量值是多少。
而流经这个神经网络(Transformer)的作用,就是让这些向量能够获得比单个词更丰富更具体的含义
然而我们注意到矩阵含有行和列,其中行代表着语义宽度,也就是GPT一次所能处理的单词长度,注意:我这里的话指的是能够结合上下位语义的长度,也就是说,一旦问的多了,问的久了,你再问之前的,超过了这个长度,那么GPT就会遗忘之前你说的话。
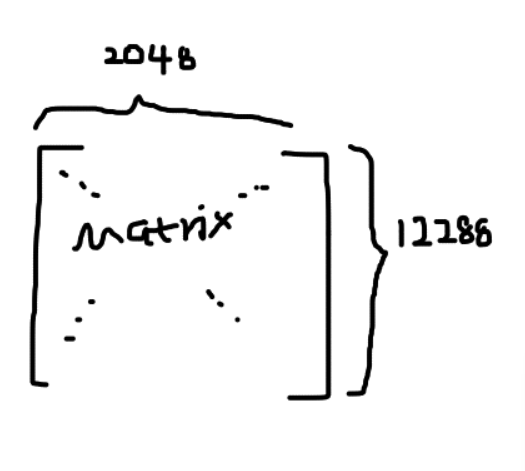
哈哈,这就是为什么早期GPT版本会遗忘的原因。
预测结果
我们来看看结果我们是如何操作的。
比如生成了这样一个矩阵:

我们会根据上述矩阵的最后一列,将其映射到一个含有5000元素的列向量,这个矩阵叫做”Unembedding matrix“,解嵌入矩阵。
最后通过softmax分类器进行概率预测

softmax
这个网上就比较多了,这里不再赘述,仅记录个人发现。
我们又引入了一个温度T参量,当参量的值很大时,会给小的概率值匀更多的机会,看起来会更均匀些:
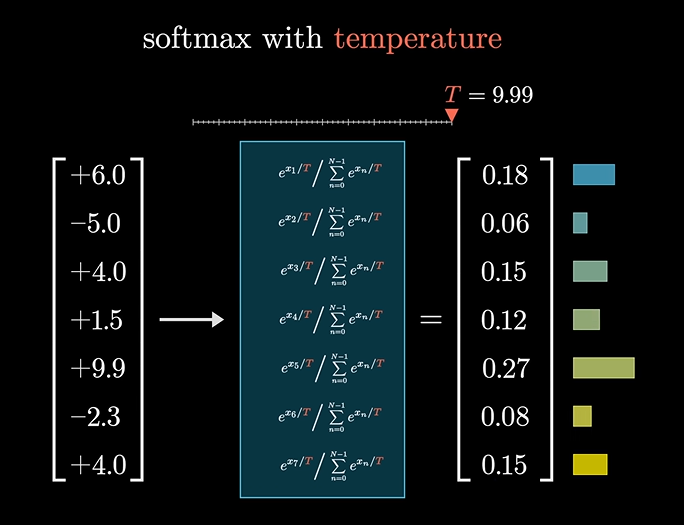
反之。
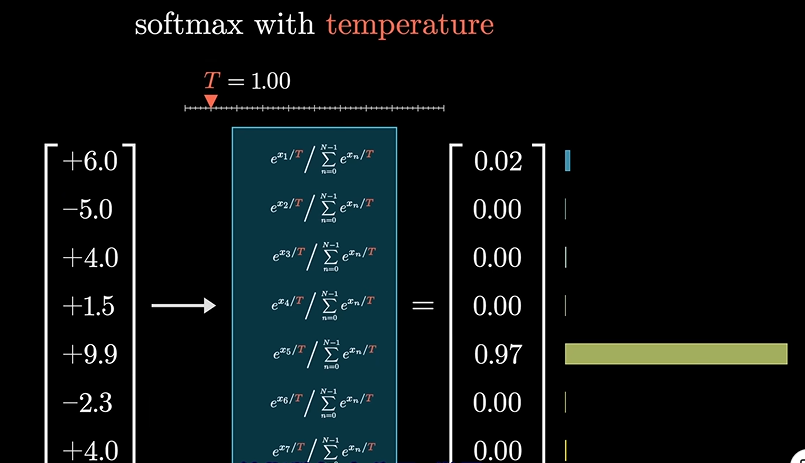
同样我们也可以操作这个T值,来改变GPT的文本生成特点

左边就很古板,而右边就很创新,但逐渐趋向于无稽之谈了,因为其更倾向于选择可能性更小的词了。官网API不允许T大于2
Logits
We call the logits for the next word prediction
《Attention is all you need》
【回顾】:
step1:三个向量初始化一样,因为这个时候是没有上下文参考的。当然,实际中他们代表着不同的含义。
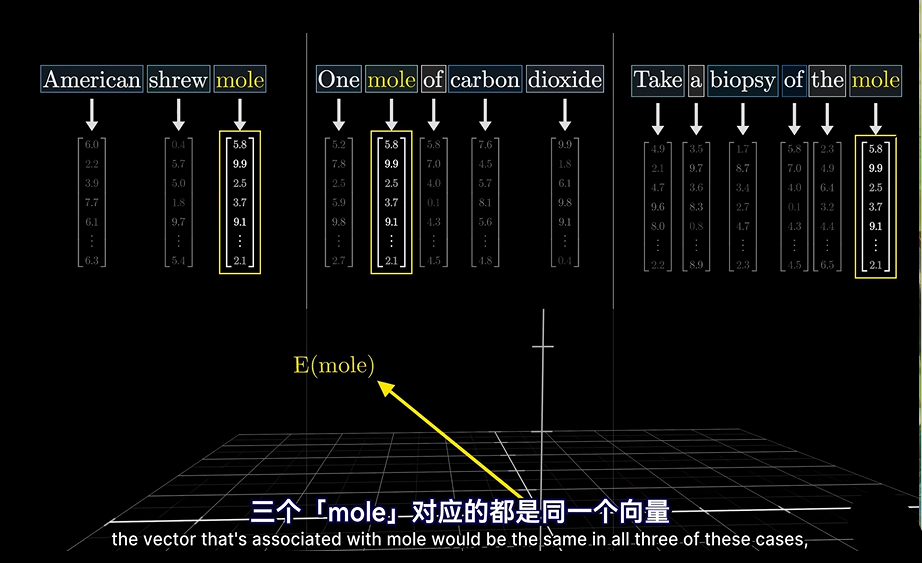
step2:等到Transformer这一步,才会改变传到的意思,集合上下文
还记得我们提到的这里用到的向量的集合意义吗?
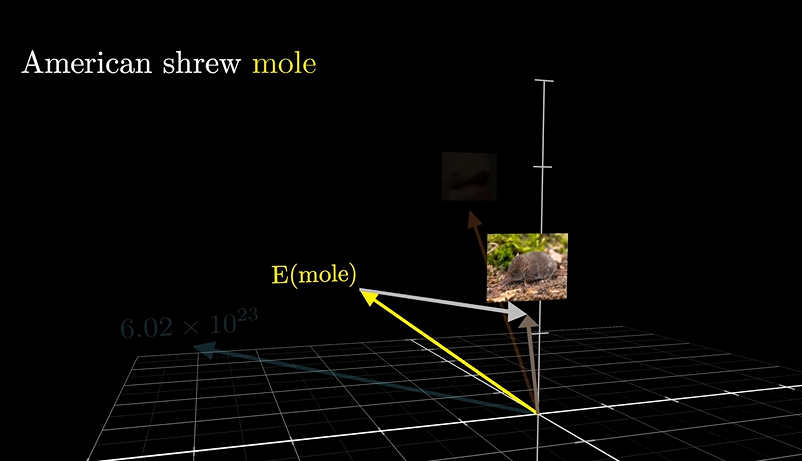
把实际的含义”扳“到正确的向量上
举个简单的例子
Candy,给他一个普通的向量,会和棒棒糖、蛋糕等甜食联系到一起,然而如果是 Spicy candy,则就会和辣联系到一起,如果是spicy candy cannon,就会和糖果大炮联系起来,就不再是食物了。
这便是注意力机制
那么注意力机制到底是如何运作的呢??
一个单词,会问前面和后面的单词:我前面还有形容词吗?这时可能前面的俩哥们就说我在我在!!
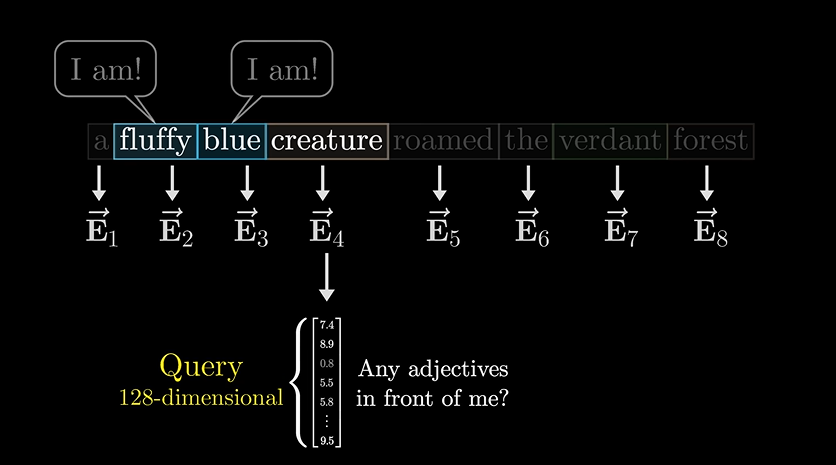
这个疑问,就是一个询问矩阵Query,比如假设有128维。
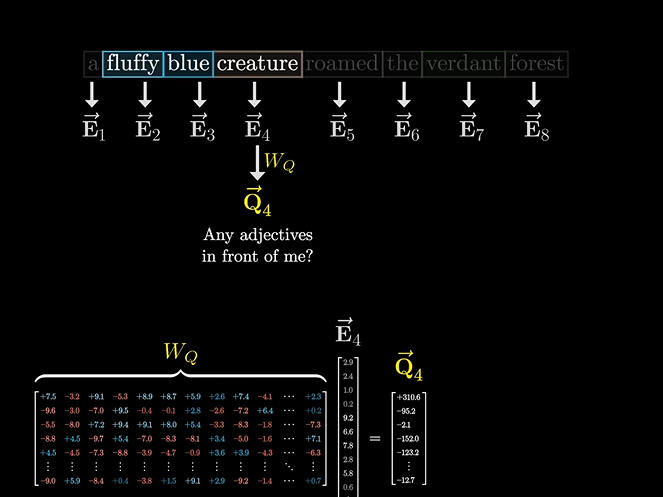
通过一个变化矩阵得到询问矩阵
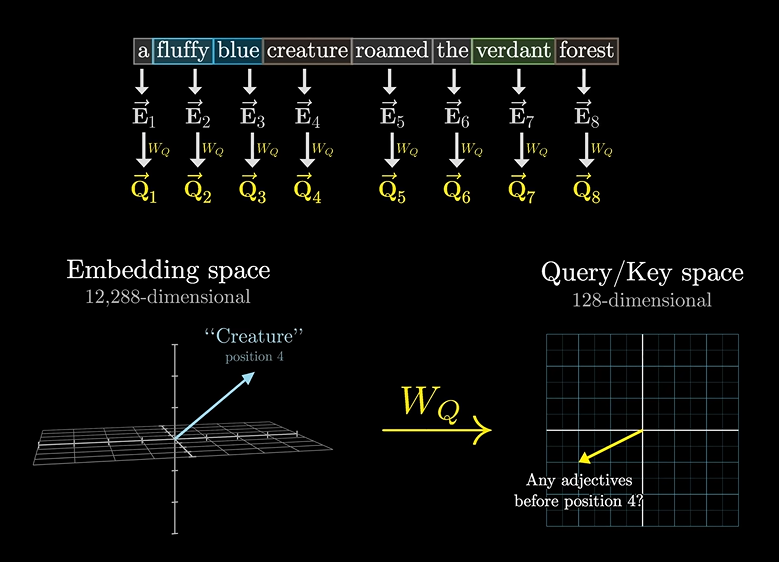
同样,应答的矩阵我们叫做应答矩阵,也叫”键矩阵“
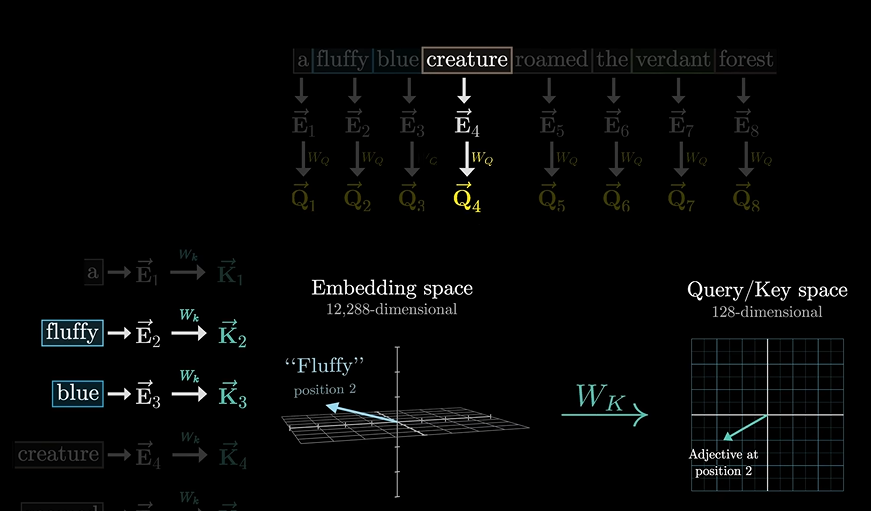
因为有问就得有答嘛,所以:
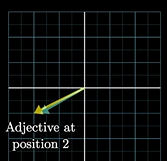
可以看向量的匹配程度(不记得了,网上翻看,我前面讲了)
然后汇成一个图,用来指示二者的匹配程度:
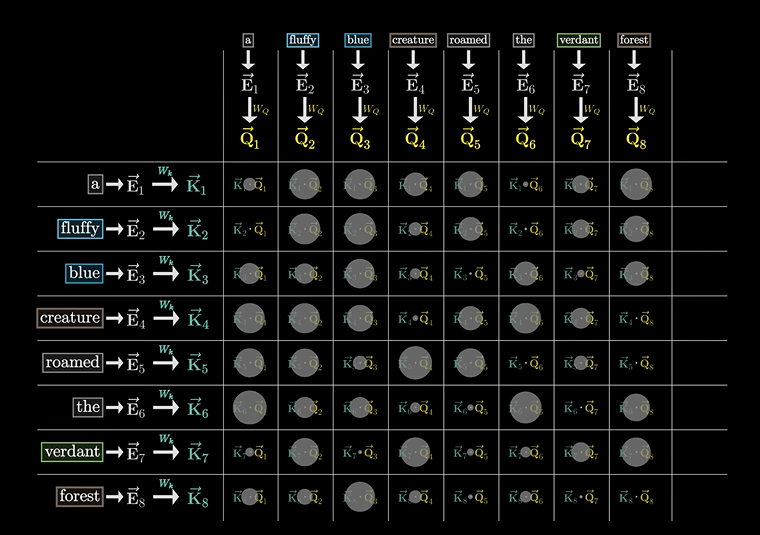
然后我们找到了匹配点乘最大的值,我们认为二者的匹配程度是最大的。

也就说明了二者的相关程度。
但数值可能随意分配,所以再次需要使用softmax进行归一化,得到应答和询问的归一化数值。
注意力模型
我们管这个模型叫做注意力模型,得到的是询问和应答的相关性矩阵。

这是著名论文的给出的公式推导结果,非常精彩
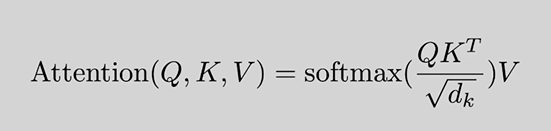
掩码(masking)
一句话多次训练:
提供了多次训练的机会:
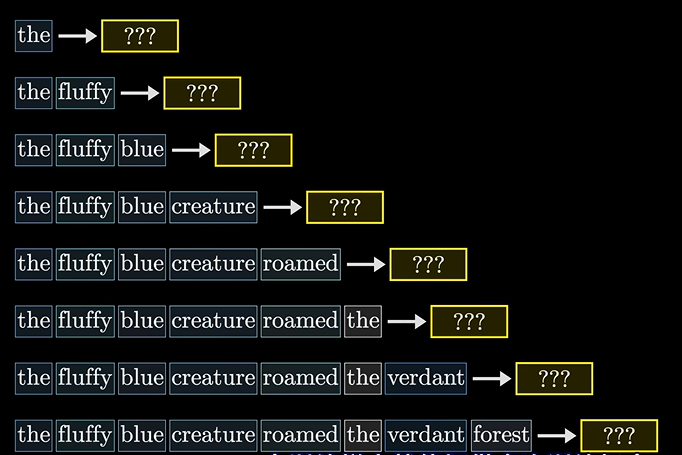
但注意的是不能让后面的词预测影响到前面,因为后面我都知道是啥词了,我还预测啥啊,对吧。。

所以我们把注意力模型里面的这些数值清零。。
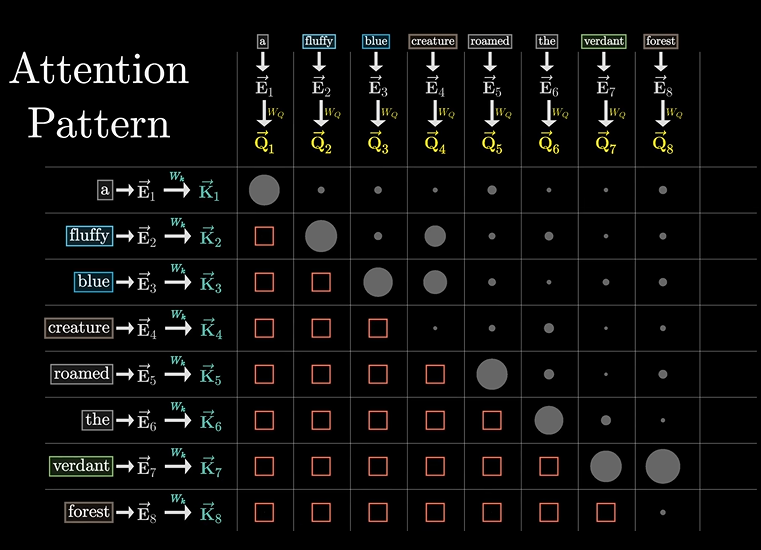
但这样会影响softmax的结果,所以还需要先设置为-无穷
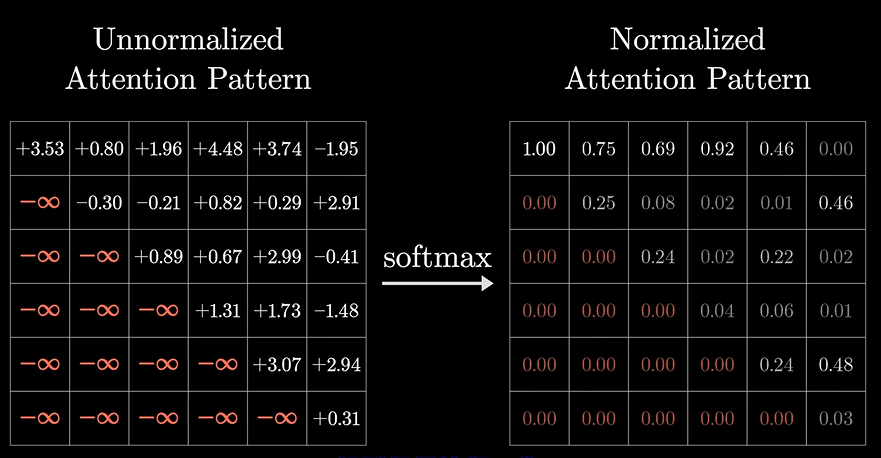
这一过程被称为Masking
注意力模型的尺寸
其大小等于上下文长度的平方,这也就是上下文长度不能太长
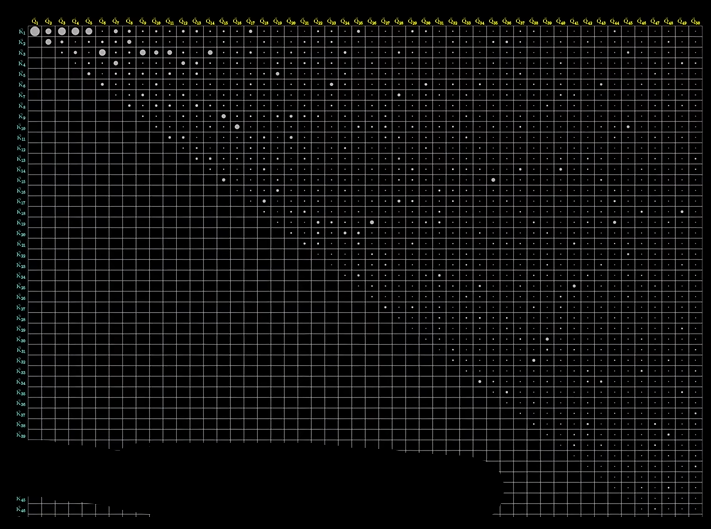
怎么“扳”?
我们前面知道,我们要将向量,根据正确的语义,扳到正确的位置上,那么我们要怎么扳???
而且前面论文公式里的V是什么意思呢?换言之,我们要如何知道向量的变换呢?
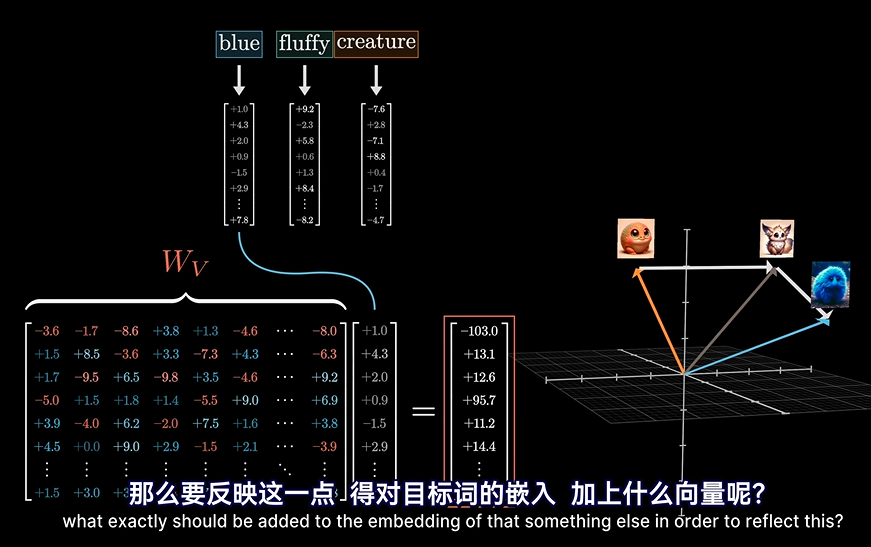
这时,我们其实可以这样来理解:

根据应答矩阵,被作用到Wv这个转换矩阵算子上,将产生一种作用(这个作用笔者认为可以理解为一个向量),然后询问矩阵加上这样一个响应,就变化了。最后就可以根据不同的语义产生向量的变换!!
这个Wv矩阵我们暂且称它为值矩阵。。

就像上图所说的那样
如果向量多了也一样:
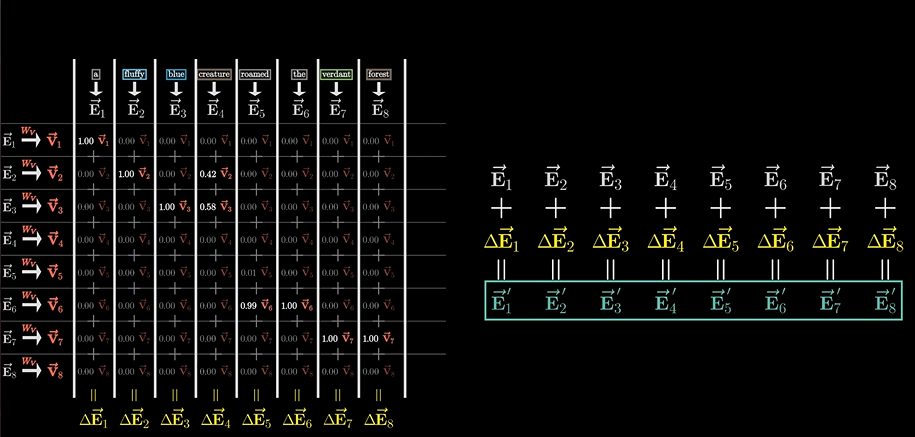
但我们得到了三个矩阵参数

下面这个图将很好的说明这一点:
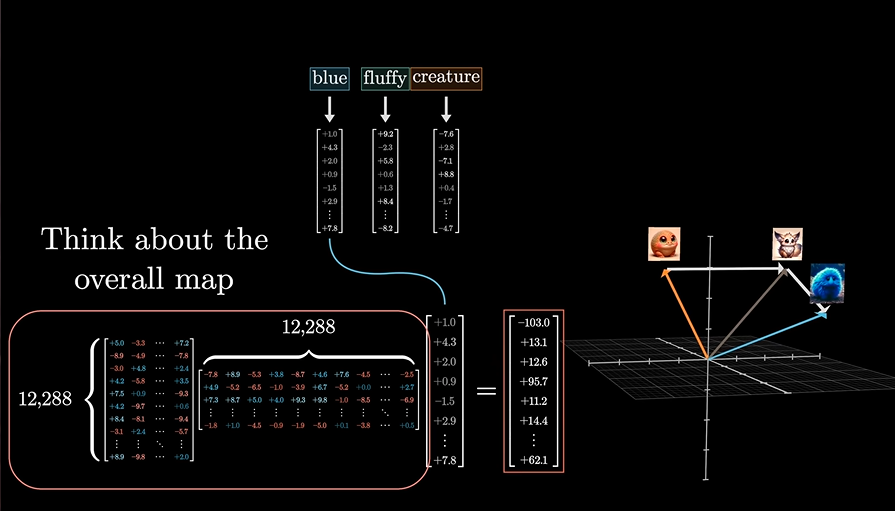
非常的清晰且明了
目前学到的参数

上面的值矩阵可以拆分为两个小矩阵
他们还各有自己的名字:
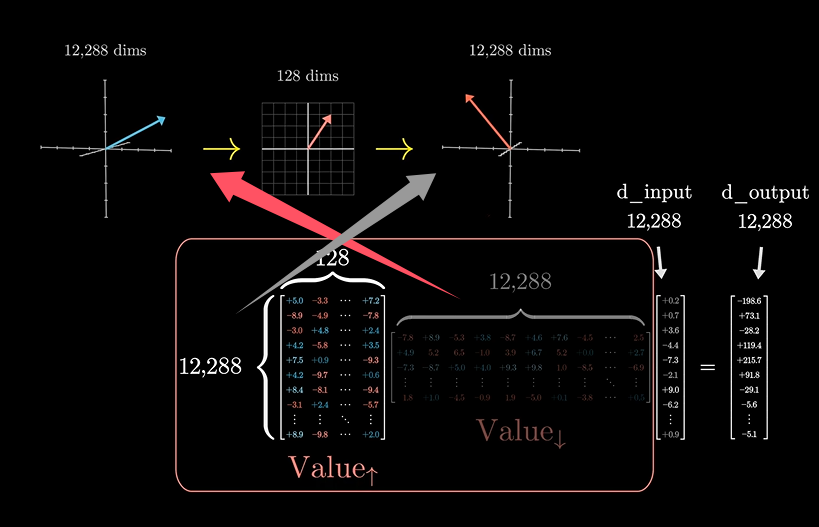
这种操作实质上就是对大矩阵进行“地址”
交叉注意力模型
这里不赘述,后面学到我也会详细介绍。
单注意力头
Single-attention
就是一个注意力的矩阵格式呗
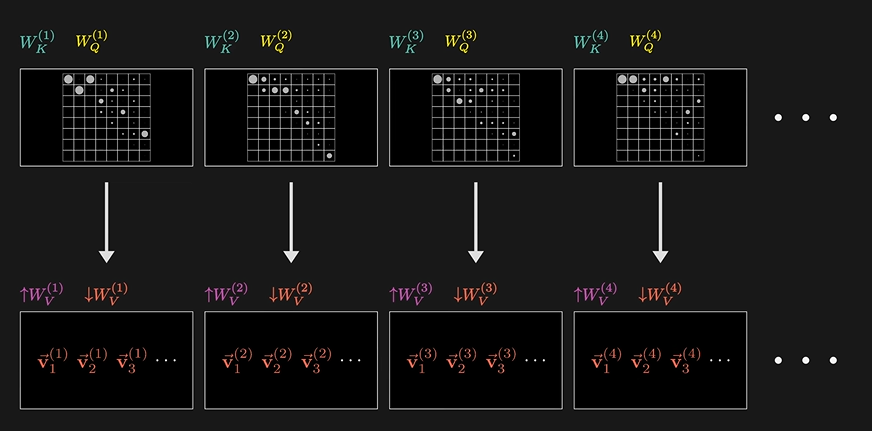
Multi-attention
就是GPT-3内使用的96个注意力头,同时进行着并行的运算。

![Python - [05] 爬虫](https://img2024.cnblogs.com/blog/1729889/202409/1729889-20240930160537191-1527253843.png)