当您有可以比较的真实数据时,评估检索-增强生成(RAG)模型要容易得多。但是如果你没有呢?这就是事情变得有点棘手的地方。然而,即使在缺乏基本事实的情况下,仍然有一些方法可以评估 RAG 系统的性能。下面,我们将介绍三种有效的策略,从零开始创建 ground truth 数据集的方法,当你确实拥有数据集时可以用来评估的指标,以及可以帮助你完成这一过程的现有框架。
RAG 评价有两种类型:检索评价和生成评价
下面的每个策略将被标记为检索评估、生成评估或兼顾两者。
如果没有真实数据,如何评估 RAG ?
向量相似度搜索阈值
类型:检索评价
如果您正在使用像 Pinecone 这样的矢量数据库,那么您可能对矢量相似性的概念很熟悉。本质上,数据库根据你查询的向量与潜在结果的向量的接近程度来检索信息。即使没有一个“正确”的答案来衡量,你仍然可以依靠余弦相似度等指标来衡量检索文档的质量。
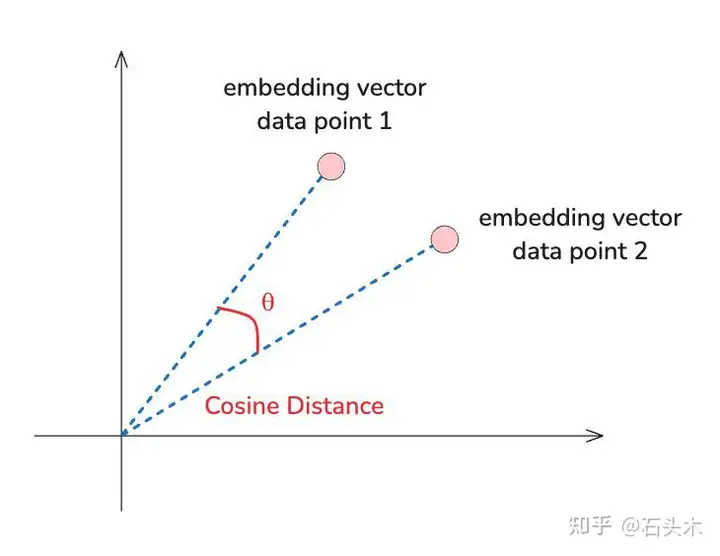
余弦距离
例如,Pinecone 将返回余弦相似度值,显示每个结果与查询的接近程度。
#创建一个使用余弦相似度 pc 的 pinecone(向量数据库)索引。
create_index(
name=index_name,
dimension=2,
metric="cosine",
spec=ServerlessSpec(
cloud='aws',
region='us-east-1'
)
)
#检索最接近的前 3 个向量
query_results =index。query(
namespace="example-namespace1",
vector=[1.0, 1.5],
top_k=3,
include_values=True
)
# query_results
#这里的"score"是余弦相似度值
# {'matches': [{'id': 'vec1', 'score': 1.0, 'values': [1.0, 1.5]}
,# {'id': 'vec2', 'score': 0.868243158, 'values': [2.0, 1.0]}
,# {'id': 'vec3', 'score': 0.850068152, 'values': [0.1, 3.0]}],通过暴露相似度分数,您可以对检索到的文档设置及格或不及格的分数。较高的阈值(如 0.8 或更高)意味着有更严格的要求,而较低的阈值将带来更多的数据,这可能是有帮助的,也可能只是嘈杂的。
这个过程并不是要马上找到一个完美的数字——这是一个反复试验的过程。当结果始终对我们的特定应用程序有用时,我们就知道我们是否已经达到了最佳点。
使用多个LLM来判断反应
类型:检索+生成评价
评估 RAG 系统的另一种创造性方法是利用多个LLM来判断响应。即使LLM不能在缺乏真实数据的情况下提供完美的答案,你仍然可以使用他们的反馈来比较回答的质量。
通过比较不同 llm 的响应并查看它们是如何排序的,您可以衡量检索和代的总体质量。这不是完美的,但它是一种创造性的方式,可以从多个角度了解系统输出的质量。
human -in- loop 反馈:让专家参与
类型:检索+生成评估
有时候,评估一个系统的最佳方式是老式的方式——通过询问人类的判断。
从领域专家那里获得反馈可以提供即使是最好的模型也无法比拟的见解。
设置评级标准
为了使人类的反馈更加可靠,它有助于建立清晰一致的评级标准。你可以让你的评论者对以下内容进行评价:
- 相关性:检索的信息是否针对查询?(检索评价)
- 正确性:内容是否事实准确?(检索评价)
- 流畅度:是否好吗,还是觉得别扭或勉强?(一代评估)
- 完整性:它是否完全覆盖了问题或留下空白(检索+生成评估)
有了这些标准,你可以对你的系统的表现有一个更结构化的感觉。
获得基线
评估人工反馈质量的一个聪明方法是检查不同的评论者之间的意见是否一致。您可以使用皮尔逊相关性等指标来查看他们的判断是否一致。如果你的审稿人意见不一致,这可能意味着你的标准不够清晰。这也可能是一个信号,表明这个任务比你预期的更主观。
皮尔逊相关系数
减少噪音
人类的反馈可能是嘈杂的,尤其是在标准不明确或任务是主观的情况下。
这里有几个方法可以解决这个问题:
- 平均分数:通过平均多个人类评论者的评分,您可以消除任何个人偏见或不一致。
- 关注一致性:另一种方法是只考虑审稿人同意的情况。这将给你一个更清晰的评估集,并有助于确保你反馈的质量。
从头开始创建 Ground Truth Dataset
在评估没有 ground truth 数据的 RAG 系统时,另一种方法是创建自己的数据集。这听起来很吓人,但有几种策略可以让这个过程变得更容易,从寻找相似的数据集到利用人类反馈,甚至是综合生成数据。让我们来分析一下如何做到这一点。
在线查找相似的数据集
这似乎是显而易见的,大多数得出结论认为他们没有地面真实数据集的人已经用尽了这个选择。但仍然值得一提的是,可能存在与你需要的数据集相似的数据集。也许它与你的用例在不同的业务领域,但它是你正在使用的问答格式。像 Kaggle 这样的网站有各种各样的公共数据集,你可能会惊讶于有多少与你的问题空间一致。
例子:
- 斯坦福问答数据集
- 亚马逊问答数据集
手动创建地面真实数据
如果你在网上找不到你需要的东西,你总是可以手动创建地面真值数据。这就是“人在循环”反馈派上用场的地方。还记得我们之前谈到的领域专家反馈吗?你可以利用这些反馈来构建你自己的迷你数据集。
通过策划一组人工审查的示例——其中结果的相关性、正确性和完整性已经得到验证——你为扩展数据集进行评估奠定了基础。
Katherine Munro 也有一篇很棒的文章,是关于敏捷聊天机器人开发的实验
方法。
训练一个 LLM 作为judge
一旦你有了最小的基础真值数据集,你就可以更进一步,训练一个 LLM 作为judge来评估你的模型的输出。
但在依靠 LLM 作为judge之前,我们首先需要确保它对我们的模型输出进行了准确的评级,或者至少是可靠的。以下是如何实现这一目标:
- 构建人工审核的示例:根据你的用例,20 到 30 个示例应该足够好,可以很好地了解 LLM 相比之下有多可靠。参考上一节关于评价的最佳标准以及如何衡量相互冲突的评价。
- 创建你的LLM评审:提示LLM根据你交给领域专家的相同标准给出评级。拿着这个评分,比较LLM的评分与人类的评分是如何一致的。同样,你可以使用像皮尔逊指标这样的指标来帮助评估。高相关性分数将表明 LLM 的表现与judge一样好。
- 应用即时工程最佳实践:即时工程可以成就或破坏这个过程。使用上下文预热 LLM 或提供一些示例(few-shot learning)等技术可以显着提高模型在判断时的准确性。
创建特定的数据集
另一种提高基础真实数据集质量和数量的方法是将文档分割成主题或语义组。与其将整个文档作为一个整体来看,不如将它们分解成更小、更集中的部分。
例如,假设你有一个文档(documentId: 123),其中提到:
“在推出产品 ABC 后,XYZ 公司在 2024 年第一季度的收入增长了 10%。”
这句话包含了两个不同的信息:
- 推出产品 ABC
- 2024 年第一季度收入增长 10%
现在,你可以将每个主题扩展到自己的查询和上下文中。例如:
- 问题 1:“XYZ 公司推出了什么产品?”
- 背景 1:“启动产品 ABC”
- 问题 2:“2024 年 Q1 营收的变化是什么?”
- 背景 2:“XYZ 公司 2024 年第一季度的收入增长了 10%”
通过将数据分解成这样的特定主题,你不仅可以为训练创造更多的数据点,还可以使你的数据集更加精确和集中。另外,如果你想将每个查询追溯回原始文档以提高可靠性,你可以很容易地为每个上下文段添加元数据。例如:
- 问题 1:“XYZ 公司推出了什么产品?”
- 上下文 1:“启动产品 ABC(文档 id: 123)”
- 问题 2:“2024 年第一季度的收入变化是什么?”
- 背景 2:“XYZ 公司在 2024 年第一季度的收入增长了 10%(文档 id: 123)”
这样,每个细分都被绑定回其来源,使您的数据集对评估和训练更有用。
综合创建一个数据集
如果所有这些方法都失败了,或者如果您需要的数据多于手动收集的数据,那么合成数据生成可以改变游戏规则。使用数据增强甚至 GPT 模型等技术,您可以根据现有示例创建新的数据点。例如,你可以采用一组基本的查询和上下文,并稍微调整它们以创建变化。
例如,从这个查询开始:
- “XYZ 公司推出了什么产品?”
你可以合成如下的变体:
- “XYZ 公司推出了什么产品?”
- “XYZ 公司推出的产品叫什么名字?”
这可以帮助您构建更大的数据集,而无需从头开始编写新示例的手动开销。
还有一些框架可以自动为你生成合成数据的过程,我们将在最后一节探讨。
一旦你有了一个数据集:是时候评估了
现在你已经收集或创建了你的数据集,是时候进入评估阶段了。RAG 模型涉及两个关键领域:检索和生成。两者都很重要,了解如何评估每一个将有助于你微调你的模型,以更好地满足你的需求。
评估检索:检索数据的相关性如何?
RAG 中的检索步骤是至关重要的—如果您的模型不能提取正确的信息,它将难以生成准确的响应。以下是你需要关注的两个关键指标:
- 上下文相关性:这衡量了检索到的上下文与查询的一致性。从本质上讲,你是在问:这些信息是否与所问的问题有关?你可以使用你的数据集来计算相关性分数,要么通过人工判断,要么通过比较查询和检索文档之间的相似度指标(如余弦相似度)。
- 上下文召回(Context Recall):上下文召回关注的是检索到多少相关信息。有可能是提取了正确的文档,但只包含了部分必要的信息。为了评估召回率,你需要检查你的模型提取的上下文是否包含了所有的关键信息片段,以完全回答查询。理想情况下,你想要高召回率:你的检索应该抓住你需要的信息,不应该留下任何关键信息。
评估生成:是否反应既准确又有用?
一旦检索到正确的信息,下一步就是生成一个响应,该响应不仅要回答查询,而且要忠实而清晰。以下是需要评估的两个关键方面:
- 忠实度:这度量生成的响应是否准确地反映了检索到的上下文。从本质上讲,你想要避免幻觉——在这种幻觉中,模型会编造出检索数据中没
有的信息。忠实是指确保答案建立在模型检索到的文档所呈现的事实基础上。
- 答案相关度:这是指生成的答案与查询的匹配程度。即使信息忠实于检索到的上下文,它仍然需要与被询问的问题相关。你不希望你的模型提取出正确的信息,而这些信息并不能完全回答用户的问题。
进行加权评估
一旦你评估了检索和生成,你可以更进一步,以加权的方式结合这些评估。也许你更关心相关性而不是召回,或者忠诚是你的首要任务。您可以根据您的具体用例为每个指标分配不同的权重。
例如:
- 检索:60%上下文相关性+ 40%上下文召回
- 生成:70%忠实度+ 30%答案相关性
这种加权评估让你可以灵活地优先考虑对你的应用程序最重要的东西。如果你的模型需要 100%的事实准确性(比如在法律或医疗环境中),你可能会更重视忠诚度。另一方面,如果完整性更重要,你可能会关注回忆。
简化评估过程的现有框架
如果创建自己的评估系统让你感到不知所措,不要担心——有一些很棒的现有框架已经为你做了很多繁重的工作。这些框架附带了专门为评估 RAG 系统而设计的内置指标,使评估检索和生成性能变得更加容易。让我们来看看其中最有用的几个。
RAGAS(检索-增强生成评估)
RAGAS 是一个专门构建的框架,用于评估 RAG 模型的性能。它包括评估检索和生成的指标,提供了一种全面的方法来衡量您的系统在每个步骤中的表现。它还通过采用进化生成范式提供综合测试数据生成。
受 evolution<a href="https://http://arxiv.org/abs/2304.12244">- instruct 等作品的启发,Ragas 通过采用进化生成范式实现了这一目标,在该范式中,具有不同特征的问
题(如推理、条件反射、多上下文等)从提供的文档集中系统地制作出来。- RAGAS 文档
ARES:使用合成数据和 LLM 判断的开源框架
ARES 是另一个强大的工具,它结合了合成数据生成和基于LLM的评估。ARES 使用合成数据——由人工智能模型生成的数据,而不是从现实世界的交互中收集的数据——来构建一个可用于测试和改进 RAG 系统的数据集。
该框架还包括一个 LLM 判断器,正如我们之前讨论的那样,它可以通过将模型输出与人类注释或其他参考数据进行比较来帮助评估模型输出。
结论
即使没有真实数据,这些策略也可以帮助您有效地评估 RAG 系统。无论你是使用向量相似阈值、多个 llm、LLM-as-a-judge、检索指标还是框架,每种方法都为你提供了一种衡量性能和改进模型结果的方法。关键是找到最适合您特定需求的方法-并且不要害怕在此过程中进行调整。






![[转]线性代数库介绍](https://img2020.cnblogs.com/blog/2073733/202108/2073733-20210804182726736-1535014566.png)
