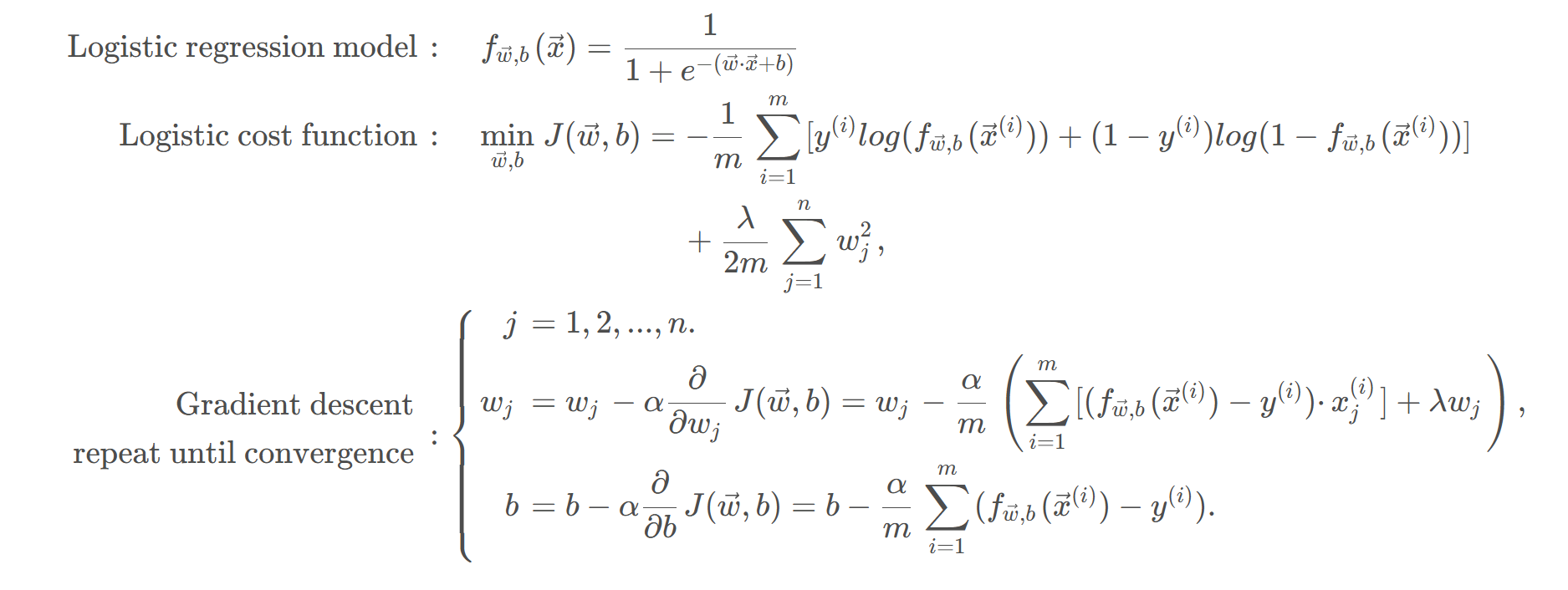逻辑回归
机器学习中的逻辑回归(Logistic Regression)是一种广泛使用的分类算法,尽管它的名字中包含“回归”这个词,但实际上它主要用于解决分类问题,特别是二分类问题。逻辑回归模型可以用来预测某一类事件发生的概率,例如预测用户是否会点击广告、病人是否患有某种疾病等。
逻辑回归的核心是使用一个Sigmoid函数(也称为Logistic函数),该函数将线性组合的输出转换为一个介于0到1之间的数值,这个数值可以解释为正类(或目标类)发生的概率。
Sigmoid函数

基本形式
假设我们有一个数据集,其中每个样本x 都有一个对应的标签 y,其中 ( y \in {0, 1} )。逻辑回归模型可以表示为:
这里的 ( w ) 是权重向量,( b ) 是偏置项,( w^T x ) 表示 ( w ) 和 ( x ) 的点积。这个表达式的结果是一个概率值,表示给定输入 ( x ) 时,输出为正类的概率。
损失函数与优化
为了训练模型,我们需要定义一个损失函数来度量预测值与实际标签之间的差距。对于逻辑回归来说,常用的损失函数是交叉熵损失(Cross-Entropy Loss),有时也被称为对数损失(Log Loss)。对于单个样本,损失函数可以写作:
其中,( \hat{y} ) 是模型预测的概率,( y ) 是真实标签。
在训练过程中,通常会用梯度下降法或其他优化算法来最小化损失函数,从而找到最佳的权重 ( w ) 和偏置 ( b )。
应用场景
逻辑回归由于其简单性和解释性强的特点,在许多领域都有应用,包括但不限于:
- 医疗诊断:预测患者是否患病。
- 金融风控:评估贷款申请者的违约风险。
- 市场营销:预测客户是否会响应某个促销活动。
尽管逻辑回归在某些情况下表现良好,但它也有一些限制,比如它假设特征之间是线性相关的,并且模型的非线性表达能力有限。因此,在面对复杂的数据关系时,可能需要考虑使用其他更复杂的模型如决策树、支持向量机或者神经网络等。
决策边界
在机器学习中,决策边界(Decision Boundary)是指在特征空间中划分不同类别区域的边界。这个边界决定了分类器如何对新的输入数据进行分类。不同的分类算法会有不同的决策边界形状,这些边界可以是直线、曲线或是更复杂的多维超平面。
决策边界的类型
线性决策边界
对于线性分类器,如逻辑回归和支持向量机(当使用线性核函数时),决策边界通常是线性的。这意味着在二维空间中,决策边界是一条直线;在多维空间中,则是一个超平面。这种类型的决策边界适用于那些可以通过一条直线或超平面较好地分离的特征空间。
非线性决策边界
对于非线性分类器,如决策树、支持向量机(使用非线性核函数)、神经网络等,决策边界可以是任意复杂的形状。这意味着它们能够处理那些不能通过简单的线性边界来分离的数据集。例如,在二维空间中,决策边界可以是曲线、闭合图形甚至是更复杂的形状。
如何确定决策边界?
对于逻辑回归而言,决策边界是由模型参数 ( w ) 和偏置项 ( b ) 决定的。逻辑回归的决策规则是基于Sigmoid函数的输出大于等于某个阈值(通常为0.5)来决定最终的类别归属。因此,决策边界是所有满足以下条件的点组成的集合:
[ w^T x + b = 0 ]
这个方程定义了一个超平面,任何位于该超平面一侧的点都属于同一类别,而另一侧则属于另一个类别。这个超平面就是逻辑回归的决策边界。
决策边界的影响因素
决策边界的位置和形状受到以下几个因素的影响:
- 特征选择:所选特征对分类任务的重要性影响着决策边界的形状。
- 模型复杂度:更复杂的模型能够拟合更复杂的决策边界。
- 过拟合与欠拟合:过于复杂的决策边界可能导致过拟合,而过于简单的边界可能会导致欠拟合。
理解决策边界对于选择正确的模型和调整模型参数是非常重要的。通过观察决策边界,我们可以了解模型是如何对输入数据进行分类的,并据此改进我们的模型以获得更好的性能。
逻辑回归的代价函数

实现梯度下降
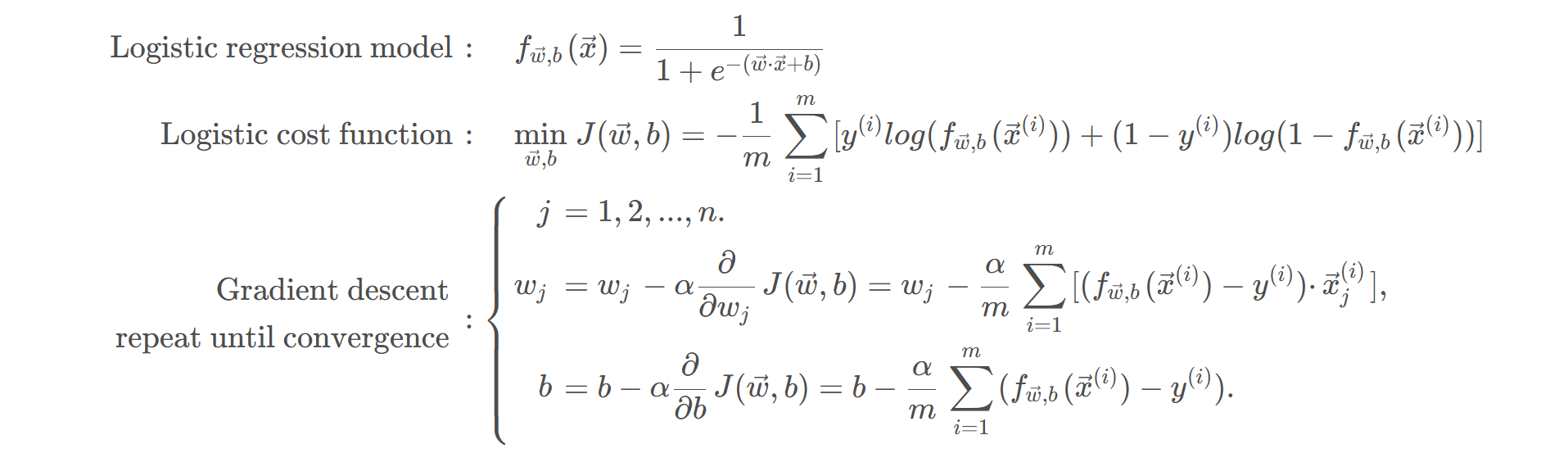
过拟合、欠拟合
过拟合(Overfitting)是在机器学习和统计建模中常见的一个问题,指的是模型在训练集上表现得非常好,但在未见过的新数据上表现较差。换句话说,模型学习到了训练数据中的噪声或细节,而不是数据背后的真实模式,导致模型的泛化能力降低。
过拟合的原因
- 模型复杂度过高:如果模型太复杂(例如深度神经网络),它可能会过度拟合训练数据。
- 训练数据不足:如果训练数据量不够大,模型可能无法学到足够的通用特征,而是学习了特定于训练集的特征。
- 特征选择不当:过多或无关紧要的特征可能导致模型学习到不必要的模式。
过拟合的表现
过拟合通常表现为训练误差(Training Error)很低,而验证误差(Validation Error)或测试误差(Test Error)很高。这意味着模型在训练数据上表现很好,但在新数据上的表现却很差。
解决过拟合的方法
- 简化模型:减少模型的复杂度,比如减少多项式回归的阶数或减少神经网络的层数和节点数。
- 正则化:在损失函数中加入正则化项(如L1或L2正则化),惩罚过大或过多的参数值,这有助于减少模型的复杂度。
- 早停(Early Stopping):在训练过程中监控验证集的性能,一旦验证误差开始增加,就停止训练。
- 数据增强(Data Augmentation):通过生成训练数据的变种来扩大训练集,这样可以增加模型的泛化能力。
- 集成方法(Ensemble Methods):使用多个模型的预测结果来进行集成学习,如随机森林(Random Forests)或Boosting方法。
- 交叉验证(Cross Validation):通过将数据分成几个部分并在不同部分上训练和验证模型,可以更准确地估计模型的泛化性能。
- 特征选择(Feature Selection):移除不相关的特征或使用特征选择算法来保留最重要的特征。
- 增加训练数据:更多样化的训练数据可以帮助模型学习到更广泛的模式,从而提高泛化能力。
在逻辑回归中的应用
在逻辑回归中,过拟合可以通过以下方式缓解:
- 使用L2正则化(Ridge Regression)或L1正则化(Lasso Regression),以减少模型参数的大小。
- 在训练过程中使用早停策略。
- 如果适用,增加更多多样化的训练数据。
- 特征工程,例如选择最相关的特征或创建新的有意义的特征。
通过综合运用上述方法,可以有效地减轻过拟合现象,提高模型在未知数据上的表现。
欠拟合(Underfitting)是机器学习中另一种常见的问题,与过拟合相反,欠拟合指的是模型在训练数据上的表现也不好,这意味着模型未能充分捕捉到数据中的模式。简单来说,欠拟合的模型过于简单,无法很好地拟合训练数据,因此在训练集、验证集和测试集上的性能都很差。
欠拟合的原因
- 模型复杂度过低:如果模型过于简单(例如,使用线性模型去拟合非线性数据),那么它可能无法捕捉到数据中的复杂关系。
- 特征不足:如果模型没有足够的特征来描述数据中的模式,那么它可能会欠拟合。
- 训练不足:如果模型训练的时间或迭代次数不够,也可能导致欠拟合。
欠拟合的表现
欠拟合通常表现为训练误差(Training Error)较高,而且验证误差(Validation Error)或测试误差(Test Error)也很高。这意味着模型既不能很好地拟合训练数据,也无法很好地泛化到新数据。
解决欠拟合的方法
- 增加模型复杂度:使用更复杂的模型结构,如增加多项式回归的阶数、增加神经网络的层数或节点数等。
- 增加特征数量:引入更多的特征或创建新的特征(特征工程),以便模型可以从更多的信息中学习。
- 特征组合:尝试创建新的特征组合,如多项式特征、交叉特征等,以捕捉数据中的非线性关系。
- 减少正则化强度:如果使用了正则化来防止过拟合,可以尝试减小正则化参数,使模型更加灵活。
- 训练更长时间:确保模型已经充分训练,有时候增加训练迭代次数可以帮助模型更好地拟合数据。
- 调整学习率:适当调整学习率,有时候较小的学习率可以让模型更细致地调整参数。
- 使用更强大的模型:如果当前模型仍然欠拟合,可以考虑使用更强大的模型,如从线性模型转为非线性模型(如决策树、支持向量机、神经网络等)。
在逻辑回归中的应用
在逻辑回归中,解决欠拟合问题的方法主要包括:
- 增加特征的数量或质量,通过特征工程来增加有用的特征。
- 考虑使用多项式特征或交互特征来提高模型的复杂度。
- 适当减少正则化强度,以允许模型更加灵活地拟合数据。
通过以上方法,可以有效地改善欠拟合的问题,提高模型在训练数据上的表现,并提升模型的泛化能力。
综合考虑
在实际应用中,需要综合考虑过拟合和欠拟合的风险,选择合适的模型复杂度,并通过验证集来监测模型的性能。合理的模型复杂度应该是在训练集和验证集上都能取得较好的性能,并且尽可能地保持两者之间的性能差异最小。这样可以确保模型不仅在已有的数据上表现良好,还能在未来未见过的数据上保持良好的泛化能力。
正则化

用于线性回归的正则方法

用于逻辑回归的正则方法