import os
import redef process_md_file(file_path):with open(file_path, 'r', encoding='utf-8') as file:md_text = file.read()# 计数$$的出现次数dollar_count = md_text.count('$$')# 根据$$的出现次数奇偶性进行处理if dollar_count % 2 == 1: # 奇数次# 在$$后面换行processed_text = re.sub(r'\$\$', '$$\n', md_text)processed_text = re.sub(r'(?<!\n)\$\$(?!\n)', '$$\n', md_text)else: # 偶数次# 在$$前面换行processed_text = re.sub(r'(?<!\n)\$\$', '\n$$', md_text)# 写入处理后的MD文本到原文件with open(file_path, 'w', encoding='utf-8') as file:file.write(processed_text)def batch_process_md_files(directory):# 遍历目录下的所有文件for root, dirs, files in os.walk(directory):for file in files:if file.endswith('.md'):file_path = os.path.join(root, file)process_md_file(file_path)print(f"Processed file: {file_path}")# 指定要处理的目录为当前工作目录
directory = os.getcwd()# 批量处理Markdown文件
batch_process_md_files(directory)$$添加换行符
news/2024/9/21 0:03:38
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ryyt.cn/news/62769.html
如若内容造成侵权/违法违规/事实不符,请联系我们进行投诉反馈,一经查实,立即删除!相关文章

【笔记】机器学习算法在异常网络流量监测中的应用
这段时间在找方向,又看不懂文章,只能先从一些相对简单的综述类看起,顺便学学怎么写摘要相关工作的。机器学习算法在异常网络流量监测中的应用
原文:Detecting Network Anomalies in NetFlow Traffic with Machine Learning Algorithms
原文链接:Detecting Network Anomali…


Prometheus 监控系统
目录1.Prometheus 概述(1)TSDB 作为 Prometheus 的存储引擎完美契合了监控数据的应用场景(2)Prometheus 的特点(3)Prometheus的主要组件(1)prometheus server(2)exporter(3)alertmanager(4)pushgateway(5)grafana(4)Prometheus 的局限性2.Zabbix和Prometheus…

opencascade Bnd_OBB源码学习 OBB包围盒
opencascade Bnd_OBB OBB包围盒前言
类描述了定向包围盒(OBB),比轴对齐包围盒(AABB)更紧密地包围形状的体积。OBB由盒子的中心、轴以及三个维度的一半定义。与AABB相比,OBB在作为非干扰物体的排斥机制时可以更有效地使用。
方法
1. 空构造函数
//! 空构造函数
Bnd_OBB() …
Scala安装与环境配置详解教程
本文参考来源:
http://mengmianren.com/zhihuishu2020/641069.htmlScala运行在java的JVM之上,因此需要先安装Java运行环境
一、JDK8的下载和安装及环境变量配置
使用的jdk版本是:jdk-8u191-windows-i586.exe
https://pan.baidu.com/s/1RNNb7lcqKHC_2h0iiTlqFg?pwd=9t5e
提取…

大学C++程序设计课程开发指南——开发环境搭建
前言
由于某些大学程序设计课程仍然在使用VC6.0这一上古工具,不太适合学生与现代开发生产接轨,并且也有可能出现兼容问题等,故编写此文,仅供参考。
使用 Visual Studio
在介绍Visual Studio(此后简称VS)前,先给大家介绍这一工具的发展。
其前身正是VC6.0(全称Visual C++…
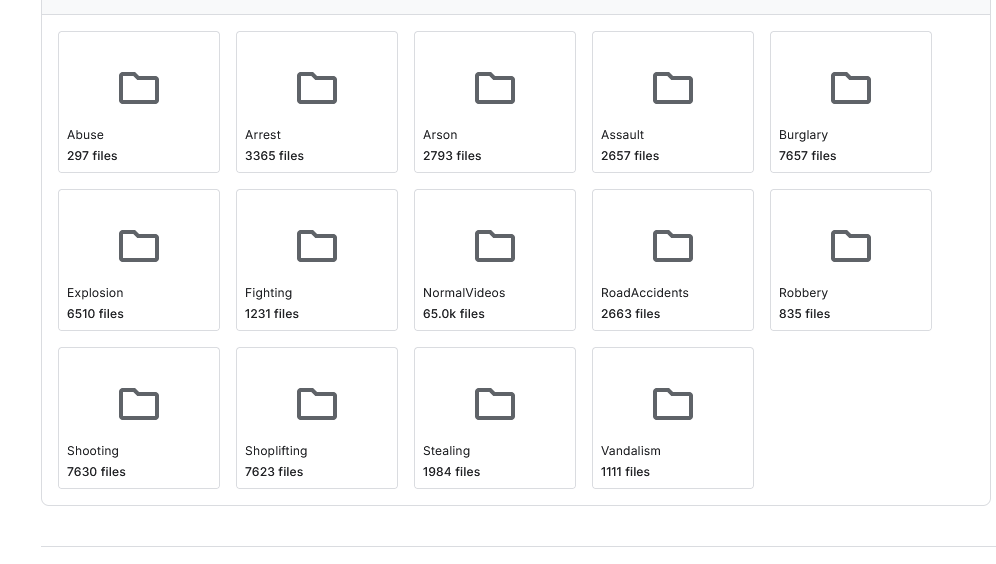
LLM DATASET
大模型的能力来源
https://arxiv.org/pdf/2402.18041 大模型合规来源
https://arxiv.org/html/2402.12193v2 大模型的罪恶检测来源
https://www.kaggle.com/datasets/odins0n/ucf-crime-dataset/data code math
https://github.com/mlabonne/llm-datasetsMath & LogicLLMs …