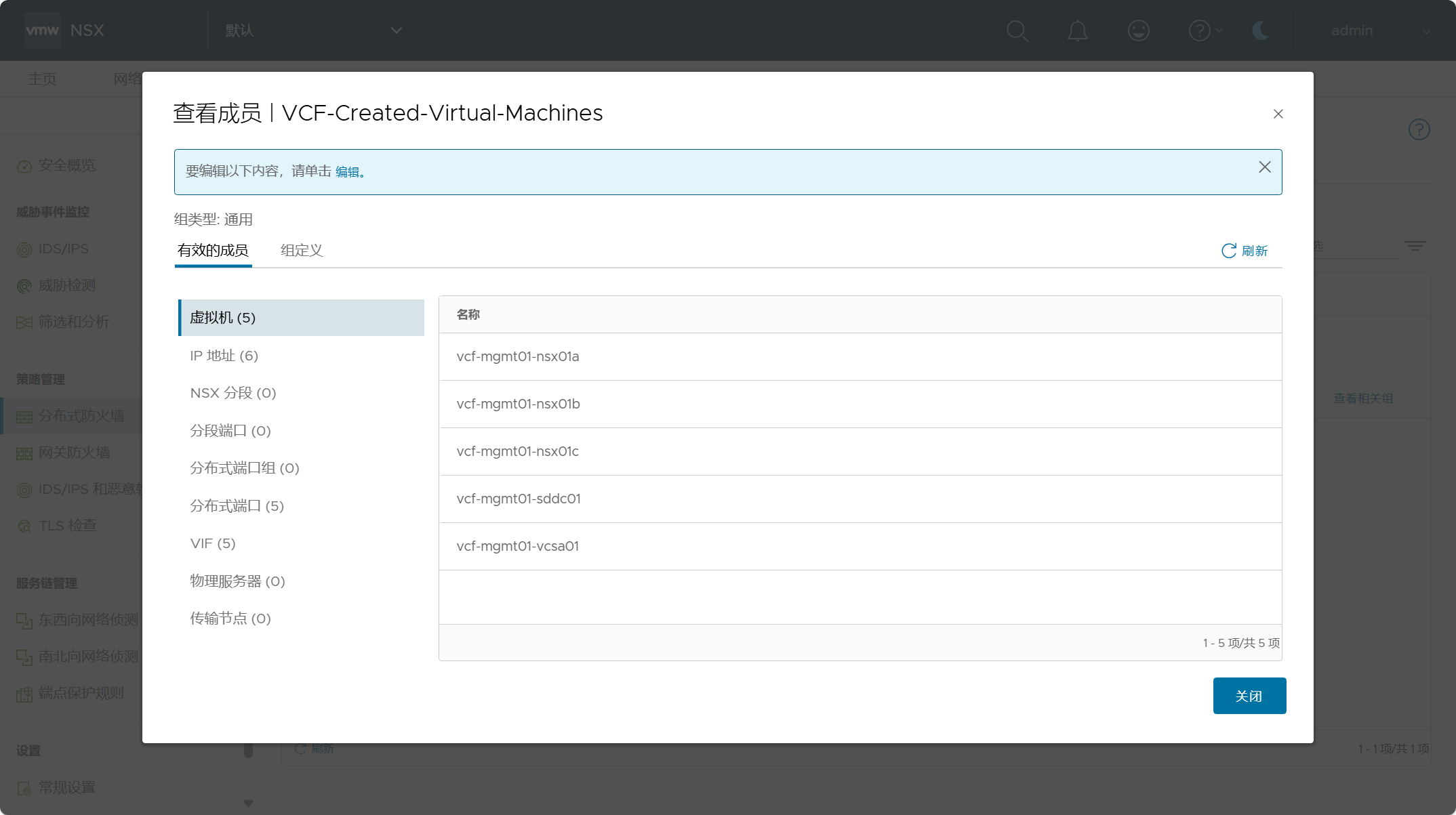
写这玩意的原因是初赛做到了
SadBee csdn
第一部分:DLX算法的提出
1.1一类被称为精确覆盖的问题
在计算机科学中,精确覆盖问题指找出这样的一种覆盖,或证明其不存在。
满足以下条件的集合为一个精确覆盖:
- S*中任意两个集合没有交集,即X中的元素在S*中出现最多一次
- S*中集合的全集为X,即X中的元素在S*中出现最少一次
合二为一,即X中的元素在S*中出现恰好一次。
这是一个NP-完全问题,也是卡普的二十一个NP-完全问题之一。
1.2经典的精确覆盖问题举例——矩阵覆盖
模板
1.2.1问题描述
给定一个N行M列的矩阵,矩阵中的每个元素要么是1,要么是0
现在需要在矩阵中挑选若干行,使得对于矩阵的每一列 j,在挑出的这些行中,有且仅有一行的第 j个元素为1,比如下面的选择方法:

简单的来说,就是从一个由0、1组成的矩阵中挑出若干整行,重新组成一个新的矩阵,使其满足下列条件:
- 设新矩阵的列数为M,则这个新矩阵中刚好含有M个1。
- 在这个新的矩阵中,任意两个1不位于同一列。(不知道看到这里有没有想到八皇后问题,这也是DLX的应用之一)
1.2.2从暴力算法到X算法
最直接也是最容易想到的方法应该就是暴力枚举算法了。从第一行开始,DFS枚举下面的所有行,利用判定函数判断是否成功。
如果刚好覆盖,层层跳出递归(利用flag);
如果到达底层都不成功则进行回溯,到上一层递归进入下一个状态,继续DFS搜索,直到找到对应的答案为止。
(暴力的代码就不写了,反正复杂度绝对死翘翘)
上述的暴力复杂度是多少呢?考虑到每一行都有两种状态:被选中以及未选中。因此递归的复杂度达到了2的N次方,妥妥的T飞。
下面进行一次优化,经过认真观察可以得到在搜索时如果有两个1位于同一列中,那么该种情况必定不合法,再继续搜索下去没有必要,此时直接回溯,可以极大降低时间复杂度。
进行第二次优化,既然不会有两个1出现在同一列中,也就是说如果递归选中了一行,那么该行中所有1所在的列也可以一起删除掉,以减小矩阵规模。
到了这里,基本与Donald E.Knuth的X算法很接近了
第二部分:精确覆盖问题的X算法
X算法的核心依然是采用回溯穷举搜索
2.1 X算法分析——矩阵覆盖问题的解决
Step 1:图中最上面一行(紫色标出)称为哨兵行,用于监视覆盖状态。首先选择一行(通常选择含1数量最少的一行),图中用红色标出。同时,在同一列中也有1且与红色行冲突的列用蓝色标出

Step 2:从所有蓝色的列看下去,把所有不属于红色行的1标注出来,并选中他们所在的行(图中用青色标注出来)

Step 3:根据前面的分析,图中用蓝色和青色标注出来的行和列都是不需要的,因此执行删除操作,大量减少搜索的范围。接着将剩下的矩阵单独提取出来。

Step 4:继续选择第一行,对剩下的矩阵进行同样的操作(递归性的体现),删除用红色、蓝色、青色标注出的行和列。

Step 5:经过步骤4的删除后,矩阵变成了空矩阵,但是哨兵栏并未清空,所以此次搜索失败,回溯到第三步的状态。
Step 6:回溯到之前的状态,这次选择第二行,再次进行查找、删除操作

Step 7:再次执行删除操作,矩阵中所有元素都被删除(包括哨兵栏)。至此,找到了一个精确覆盖的可行解。


第三部分:用于X算法的数据结构——双向十字循环链表
3.1主角登场——双向十字循环链表
概览上述X算法执行的过程中,出现了大量的删除、添加操作,最容易想到的数据结构是什么呢?当然是链表!
然而,不同的链表不能处理二维的数据,同时考虑到在此过程中大量的删除、添加操作,因此需要一种二维强化版的链表,这就是——双向十字循环链表(简称舞蹈链)。
先来看看整体的舞蹈链长什么样子:

整体链表的最上端是哨兵节点(上文有提过它的作用)。
对于每一个节点而言:
- 首先,对于每一个节点而言,他的四个方向都被链接,所以称为十字链表。
- 其次,每一条链接都是双向的,可以由左节点访问右节点,也可以有右节点访问左节点,所以它又是双向链表。
- 最后,它的行和列都是循环的,意味着可以通过每一列的哨兵节点向上访问列的最末节点。
每一行也是同样的,具有循环链表的性质。
3.2详细分析——双向十字循环链表的操作
Part 1:舞蹈链的节点结构体定义
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int MAXN=250501;
int ansk[MAXN]; //存储答案的数组
int node_size,row_head[MAXN]; //节点总数,第i行的头节点编号
struct Node
{int left,right; //左右节点编号 int upper,down; //上下节点编号 int row,col; //节点所在行数、列数 int col_size; //如果该节点为列哨兵节点,存储该列的节点总数
}node[MAXN];
Part 2:舞蹈链的初始化函数
void init(int col_size)
{for(int i=0;i<=col_size;i++){node[i].col=i,node[i].row=0; //初始化行号、列号 node[i].upper=node[i].down=i; //节点上下形成自环 node[i].left=i-1; node[i].right=i+1; //左右与其他节点相连 node[i].col_size=0; //列节点数初始化为0 }/*链接最左节点与最右节点,形成横向的环*/ node[col_size].right=0;node[0].left=col_size;memset(row_head,-1,sizeof(row_head)); //每一行的头节点初始化为-1 node_size=col_size+1; //非常重要!!!!!!!!千万别忘了
}
说明:舞蹈链的初始化主要针对第一行的哨兵节点,哨兵节点的上下形成自环,左右与其他节点相连。每列节点数初始化为0,每行头节点初始化为-1重要提醒:最后千万别忘了给节点总数赋值!!!不然建立新结点的时候会有下标冲突。
Part 3:新节点的建立与插入函数
void insert_node(int row,int col)
{node[col].col_size++; //所在列的节点数+1node[node_size].row=row,node[node_size].col=col;node[node_size].down=col; //新节点与哨兵节点相连node[node_size].upper=node[col].down; //新节点与哨兵节点下方的节点相连node[node[col].down].down=node_size; //哨兵节点下方的节点与新节点相连node[col].upper=node_size; //哨兵节点与新节点相连if(row_head[row]==-1) //如果当前所在行没有头节点{row_head[row]=node_size; //当前节点作为头节点node[node_size].left=node_size;node[node_size].right=node_size;}else{/*与所在行的头节点以及头节点左侧的节点相连*/node[node_size].left=node[row_head[row]].left;node[node[row_head[row]].left].right=node_size;node[node_size].right=row_head[row];node[row_head[row]].left=node_size;row_head[row]=node_size; //因为插入位置,代替了原来的头节点}node_size++; //节点总数自增操作return;
}
说明:根据给出的行号、列号从内存池中建立相应的新节点,为新节点的结构体赋值。同时将新节点插入到原来已经构建好的关系网中。插入的原则为:在下方直接与所在列的哨兵节点相连,上方与原来哨兵节点连接的节点相连。
特别注意连接顺序(先连接哨兵节点连接的节点,再连接哨兵节点,同时注意边的双向性)。左侧与所在行的头节点的左节点(循环性,可以认为是末尾节点)相连,右侧与头节点相连。
特别注意:如果将要插入的行现在没有节点,那么当前节点作为该行的头节点。=)
Part 4:指定列的删除和恢复函数
void node_delete(int col)
{/*先把哨兵节点的左右节点链接,跳过哨兵节点*/node[node[col].left].right=node[col].right;node[node[col].right].left=node[col].left;/*从该行哨兵节点开始,自上而下遍历,并删除遍历到的节点所在行*/for(int i=node[col].down;i!=col;i=node[i].down){for(int j=node[i].right;j!=i;j=node[j].right){node[node[j].upper].down=node[j].down; //将上方的节点连接至下方node[node[j].down].upper=node[j].upper; //将下方的节点连接至上方node[node[j].col].col_size--; //所在列的节点总数-1}}
}void node_reverse(int col)
{for(int i=node[col].upper;i!=col;i=node[i].upper){for(int j=node[i].left;j!=i;j=node[j].left){node[node[j].upper].down=j; //删除逆操作node[node[j].down].upper=j;node[node[j].col].col_size++;}}/*把哨兵节点连接回去*/node[node[col].left].right=col;node[node[col].right].left=col;
}说明:删除给定行时,先把哨兵节点移除,即把哨兵节点的左右节点互连,跳过哨兵节点。接下来自上而下遍历所有位于该列的节点,删除各个节点所在的行。回复给定行即为删除的逆操作。
Final Part:起舞函数——让指针跳起来
bool dance(int depth)
{/*如果当前哨兵节点已经被删除完了,说明递归成功,输出答案并返回*/if(node[0].right==0) {for(int i=0;i<depth;i++) cout<<ansk[i]<<" "; return true;}/*开始遍历:首先找到节点数最小的列*/int temp=node[0].right;for(int i=node[0].right;i!=0;i=node[i].right) if(node[i].col_size<node[temp].col_size) temp=i;node_delete(temp); //删除该列for(int i=node[temp].down;i!=temp;i=node[i].down) //自上而下遍历,逐层递归{ansk[depth]=node[i].row; //修改当前答案数组里的值,如果有上一次递归失败的值,直接覆盖for(int j=node[i].right;j!=i;j=node[j].right) node_delete(node[j].col);if(dance(depth+1)) return true; //递归下一层,如果下一层递归成功,返回for(int j=node[i].left;j!=i;j=node[j].left) node_reverse(node[j].col);}node_reverse(temp); //恢复该列return false;
}函数说明:主要看之前的X算法的过程理解。重要步骤:递归开始前寻找节点数最小的列进行递归。同时注意状态回溯的时候要把删除的列全部回溯到之前状态。
补充附录:示例程序
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int MAXN=250501;
int ansk[MAXN];
int node_size,row_head[MAXN];
struct Node
{int left,right;int upper,down;int row,col;int col_size;
}node[MAXN];void init(int col_size)
{for(int i=0;i<=col_size;i++){node[i].col=i,node[i].row=0;node[i].upper=node[i].down=i;node[i].left=i-1; node[i].right=i+1;node[i].col_size=0;}node[col_size].right=0;node[0].left=col_size;memset(row_head,-1,sizeof(row_head));node_size=col_size+1;
}void insert_node(int row,int col)
{node[col].col_size++;node[node_size].row=row,node[node_size].col=col;node[node_size].down=col;node[node_size].upper=node[col].down;node[node[col].down].down=node_size;node[col].upper=node_size;if(row_head[row]==-1){row_head[row]=node_size;node[node_size].left=node_size;node[node_size].right=node_size;}else{node[node_size].left=node[row_head[row]].left;node[node[row_head[row]].left].right=node_size;node[node_size].right=row_head[row];node[row_head[row]].left=node_size;row_head[row]=node_size;}node_size++;return;
}void node_delete(int col)
{node[node[col].left].right=node[col].right;node[node[col].right].left=node[col].left;for(int i=node[col].down;i!=col;i=node[i].down){for(int j=node[i].right;j!=i;j=node[j].right){node[node[j].upper].down=node[j].down;node[node[j].down].upper=node[j].upper;node[node[j].col].col_size--;}}
}void node_reverse(int col)
{for(int i=node[col].upper;i!=col;i=node[i].upper){for(int j=node[i].left;j!=i;j=node[j].left){node[node[j].upper].down=j;node[node[j].down].upper=j;node[node[j].col].col_size++;}}node[node[col].left].right=col;node[node[col].right].left=col;
}bool dance(int depth)
{if(node[0].right==0) {for(int i=0;i<depth;i++) cout<<ansk[i]<<" "; return true;}int temp=node[0].right;for(int i=node[0].right;i!=0;i=node[i].right) if(node[i].col_size<node[temp].col_size) temp=i;node_delete(temp);for(int i=node[temp].down;i!=temp;i=node[i].down){ansk[depth]=node[i].row;for(int j=node[i].right;j!=i;j=node[j].right) node_delete(node[j].col);if(dance(depth+1)) return true;for(int j=node[i].left;j!=i;j=node[j].left) node_reverse(node[j].col);}node_reverse(temp);return false;
}int main()
{int n,m; scanf("%d%d",&n,&m);init(m);for(int i=1;i<=n;i++){for(int j=1;j<=m;j++){int temp; scanf("%d",&temp);if(temp) insert_node(i,j);}}if(!dance(0)) printf("No Solution!");return 0;
}