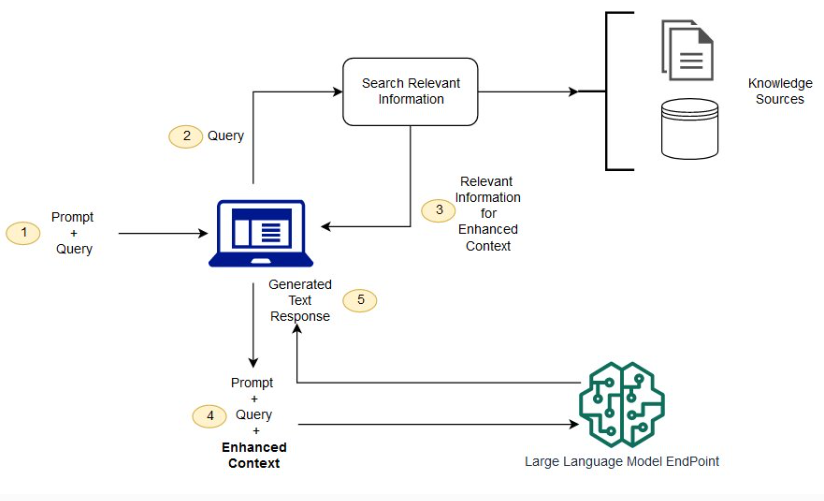
LLM大模型的核心功能之一就是聊天对话(信息检索),RAG的使用必不可少!大致的流程是:用户的query先转成embedding,去向量数据库查询最接近的top K回答;然后这query + top K的回答 + 其他context一起进入LLM,让LLM整合上述所有的信息后给出最终的回复!
为了简便、快速地实现RAG的功能,搭配上langchain使用效果更佳!为配合下面的功能说明,这里先加载长文档,并分割后求embedding后存入向量数据库
from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.document_loaders import PyPDFLoader from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import Chroma# Load pdf loader = PyPDFLoader("data\\baichuan.pdf") data = loader.load()# Split 分割长文档,每个chunk 500个token text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0) splits = text_splitter.split_documents(data[:6])
使用指定的LLM把每个chunk转成embedding后存入Chroma向量数据库(换成FAISS也行)
import os from getpass import getpassOPENAI_API_KEY = getpass()os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY# VectorDB embedding = OpenAIEmbeddings() vectordb = Chroma.from_documents(documents=splits, embedding=embedding)#调用上面的embedding工具,把分割后的文档转成embedding,存入Chroma向量数据库;
1、MuitiQueryRetriever:从名字就能看出来这个类能生成多个query,那么问题来了:为啥要这样做了?
用户的query,存在如下两个问题:
- 过于简单,比如“什么是地球?”,常见于通用的聊天工具
- 不专业,比如“我肚子疼”,常见于垂直领域的聊天工具
经常使用各种聊天工具的用户都有一个体会:query1达不到自己的预期,换个角度生成query2继续提问,如果还达不到预期,继续换个角度生成query3再次提问,这就是人为从不同角度花样生成不同的query提问,以提高检索的多样性和覆盖面!幸运的是,这个功能在langchain已经实现,demo如下:
from langchain.retrievers.multi_query import MultiQueryRetriever from langchain.chat_models import ChatOpenAIquestion = "what is baichuan2 ?" llm = ChatOpenAI(temperature=0) # 这里可以换成其他的llm retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectordb.as_retriever(), llm=llm #通过上述的llm生成多个query,并指定检索的向量数据库 )
效果如下:同一个query被指定的大模型衍生出了3个query:
INFO:langchain.retrievers.multi_query:Generated queries: ['1. Can you provide information about baichuan2?', '2. What can you tell me about baichuan2?', '3. Could you explain the concept of baichuan2 to me?']
然后直接和向量数据库中的embedding计算距离:
docs = retriever_from_llm.get_relevant_documents(query=question)#多个query和向量数据库的embedding向量直接计算距离
[Document(page_content='In this technical report, we introduce Baichuan\n2, a series of large-scale multilingual language\nmodels. Baichuan 2 has two separate models,\nBaichuan 2-7B with 7 billion parameters and\nBaichuan 2-13B with 13 billion parameters. Both\nmodels were trained on 2.6 trillion tokens, which\nto our knowledge is the largest to date, more than\ndouble that of Baichuan 1 (Baichuan, 2023b,a).\nWith such a massive amount of training data,\nBaichuan 2 achieves significant improvements over', metadata={'page': 1, 'source': 'data\\baichuan.pdf'}),Document(page_content='demonstrates strong performance on medical and\nlegal domain tasks. On benchmarks such as\nMedQA (Jin et al., 2021) and JEC-QA (Zhong\net al., 2020), Baichuan 2 outperforms other open-\nsource models, making it a suitable foundation\nmodel for domain-specific optimization.\nAdditionally, we also released two chat\nmodels, Baichuan 2-7B-Chat and Baichuan 2-\n13B-Chat, optimized to follow human instructions.\nThese models excel at dialogue and context\nunderstanding. We will elaborate on our', metadata={'page': 1, 'source': 'data\\baichuan.pdf'}),Document(page_content='Baichuan 1-13B-Base 52.40 51.60 55.30 49.69 43.20 43.01 26.76 11.5913B\nBaichuan 2-13B-Base 58.10 59.17 61.97 54.33 48.17 48.78 52.77 17.07\nTable 1: Overall results of Baichuan 2 compared with other similarly sized LLMs on general benchmarks. * denotes\nresults derived from official websites.\nFigure 1: The distribution of different categories of\nBaichuan 2 training data.\nData processing : For data processing, we focus\non data frequency and quality. Data frequency', metadata={'page': 2, 'source': 'data\\baichuan.pdf'}),Document(page_content='Baichuan 1. On general benchmarks like MMLU\n(Hendrycks et al., 2021a), CMMLU (Li et al.,\n2023), and C-Eval (Huang et al., 2023), Baichuan\n2-7B achieves nearly 30% higher performance\ncompared to Baichuan 1-7B. Specifically, Baichuan\n2 is optimized to improve performance on math\nand code problems. On the GSM8K (Cobbe\net al., 2021) and HumanEval (Chen et al., 2021)\nevaluations, Baichuan 2 nearly doubles the results\nof the Baichuan 1. In addition, Baichuan 2 also', metadata={'page': 1, 'source': 'data\\baichuan.pdf'}),Document(page_content='overall performance of the Baichuan 2 base models\ncompared to other open or closed-sourced models\nin Table 1. We then describe our pre-training data\nand data processing methods. Next, we elaborate\non the Baichuan 2 architecture and scaling results.\nFinally, we describe the distributed training system.\n2.1 Pre-training Data\nData sourcing : During data acquisition, our\nobjective is to pursue comprehensive data\nscalability and representativeness. We gather data', metadata={'page': 1, 'source': 'data\\baichuan.pdf'})]
LLM又是怎么把一个query变成三个的了?核心在这里了:https://python.langchain.com/v0.2/docs/how_to/MultiQueryRetriever/ 本质还是使用合适的prompt,调用LLM的能力把1个query扩展到多个:
from typing import Listfrom langchain_core.output_parsers import BaseOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field# Output parser will split the LLM result into a list of queries class LineListOutputParser(BaseOutputParser[List[str]]):"""Output parser for a list of lines."""def parse(self, text: str) -> List[str]:lines = text.strip().split("\n")return linesoutput_parser = LineListOutputParser()QUERY_PROMPT = PromptTemplate(input_variables=["question"],template="""You are an AI language model assistant. Your task is to generate 3different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to helpthe user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines.Original question: {question}""", ) llm = ChatOpenAI(temperature=0)# Chain llm_chain = QUERY_PROMPT | llm | output_parser# Other inputs question = "What are the approaches to Task Decomposition?"
2、Contextual Compression:知识库中的有些文档又大又长,根据向量距离检索出来后长度过长,用户可能没耐心挨个看,需要适当压缩,去掉细枝末节,只保留主干或主题;demo代码如下
from langchain.retrievers import ContextualCompressionRetriever from langchain.retrievers.document_compressors import LLMChainExtractor from langchain.chat_models import ChatOpenAI# 创建LLM实例 llm = ChatOpenAI(temperature=0)# 创建压缩器实例 compressor = LLMChainExtractor.from_llm(llm)# 假设retriever是你的基础检索器,例如向量数据库检索器 retriever = vectordb.as_retriever()# 创建上下文压缩检索器实例 compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever )# 获取压缩后的相关文档 compressed_docs = compression_retriever.get_relevant_documents("What is baichuan2 ?")# 输出结果 for doc in compressed_docs:print(doc)
原来的文档:
Baichuan2 is a next-generation artificial intelligence model developed by XYZ Corp. It is designed to handle complex natural language processing tasks, including text generation, translation, and summarization. Baichuan2 utilizes a novel neural network architecture that improves on previous models by incorporating advanced machine learning techniques. Additionally, it supports real-time data processing and can be integrated into various applications to enhance their AI capabilities. The development of Baichuan2 marks a significant milestone in AI research and development.
压缩后的文档:
Baichuan2 is a next-generation artificial intelligence model developed by XYZ Corp. It handles complex natural language processing tasks and utilizes a novel neural network architecture.
压缩的原理也很简单,和MuitiQueryRetriever类似,都是依赖prompt实现的,详见:https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/retrievers/document_compressors/chain_extract_prompt.py
prompt_template = """Given the following question and context, extract any part of the context *AS IS* that is relevant to answer the question. If none of the context is relevant return {no_output_str}. Remember, *DO NOT* edit the extracted parts of the context.> Question: {{question}} > Context: >>> {{context}} >>> Extracted relevant parts:"""
核心原理还是通过prompt让LLM帮忙压缩信息,提取主干!
3、EnsembleRetriever:前面最常用的Retriever就是计算两个embedding的距离了,这种方式又称“密集检索”,因为embedding的每个维度都有数值,看起来很紧凑和密集,所以叫密集检索!既然有密集检索,那肯定有稀疏检索啦,最常见的是BM25稀疏检索,如下:

传统做NLP的对TF-IDF肯定不陌生,本以为transformer爆火后中文分词、TF-IDF已经不再需要,没想到在这里居然还用上了,宝刀未老啊!

和密集检索比,稀疏检索的优势:
- 性能优势:BM25只需要计算词频和文档长度,计算量比密集计算小
- 语义捕捉:通过考虑词频和文档频率,BM25能够准确捕捉到用户查询的意图,提供高度相关的结果
- 灵活调节:通过调节K1和b的值,适应不同的检索场景。K1调节词频的影响,一般取值范围为1.2到2;b 调节文档长度归一化的影响,一般取值范围为0到1。
- 新闻文章检索:新闻类的文档(文章)通常较长,重要的内容可能分布在文档的各个部分,所以K1=1.5,适度重视词频;而b=0.75,对文档长度归一化!这种设置下,BM25可以在长文档中有效地找到与查询相关的段落,避免因文档长度而导致的评分偏差。
- twtter、微博这种短文本检索:这类文本通常较短,词频的重要性更高,所以K1=1.2,更重视词频;而b=0.25,较少考虑文本长度;
langChain的接口很简单:
from langchain.retrievers import BM25Retriever, EnsembleRetriever bm25_retriever = BM25Retriever.from_documents(documents=splits ) #生成bm25检索器 bm25_retriever.k = 4 #BM25返回top4文档 vectordb = Chroma.from_documents(documents=splits, embedding=embedding)retriever = vectordb.as_retriever(search_kwargs={"k": 4})#embedding的密集检索 ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, retriever], weights=[0.5, 0.5] )#两个检索器各自的权重都是0.5,大家均分 docs = ensemble_retriever.invoke("What is baichuan2 ?")
上述的权重组合实现方式如下:密集和稀疏检索器分别打分,然后乘以各自的权重后相加,得到整体的分数,然后返回得分topK的文档即可!
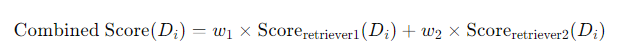
4、任何系统都要有合适的评价指标,否则怎么知道质量好坏了?传统的机器学习常用准确率、覆盖率、AUC等指标评价模型的好坏,大模型本身可以用BLUE、ROUGE等指标评判,RAG应该怎么量化评价指标了?
(1)先看看评估架构如下:
- query: 用户的输入
- relevant context:通过query的embedding从向量数据库检索到的top K上下文
- Answer:把query + context输入LLM后综合得到的结果
- ground truth:人为确定的正确答案
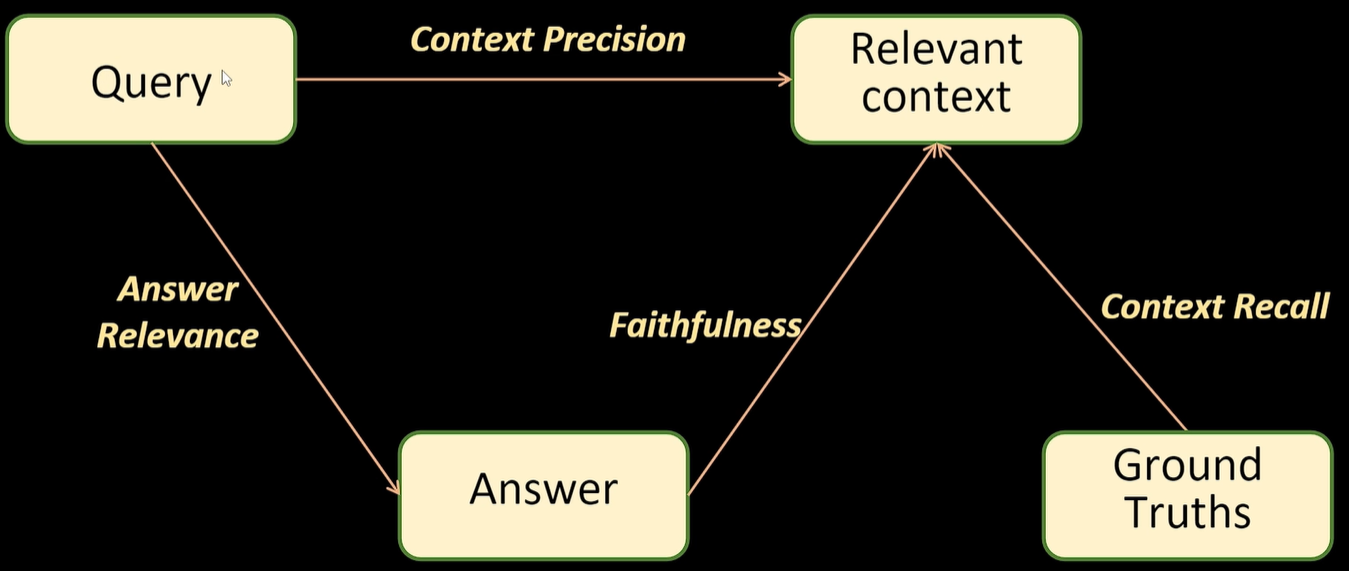
根据以上架构,衍生出三大类的评价指标:
- Faithfulness:LLM所有的回答的语义全都要基于context,不能让LLM产生幻觉胡乱回答
- answer relevant:回答的相关性,也就是LLM的回答要满足query
- context relevant:上下文的相关性,从知识库中初步召回的N条context一定要和query高度相关
(2)Faithfulness:衡量生成答案与给定上下文之间的事实一致性【避免产生幻觉】。忠实度得分是基于答案和检索到的上下文计算出来的,答案的评分范围在0到1之间,分数越高越好;如果生成的答案的每个token都在context里面,评分就是1;

(3)Answer relevance:答案相关性的评估指标旨在评估生成的答案与给定提示的相关程度。如果答案不完整或包含冗余信息,则会被赋予较低的分数。这个指标使用问题和答案来计算,其值介于0到1之间,得分越高表明答案的相关性越好。

这个评价指标最难的点在于:怎么计算分数?这就要用到逆向思维方式了:某个特定answer用LLM生成N个query_i,每个query_i和原始用户的query求相似度,然后N个query_i的相似度求均值,就是该answer和query之间的Answer relevance得分啦!感觉这是在用LLM评价LLM啊,实属是左右互搏!
(4)Context Precision:上下文精确度衡量上下文中所有相关的真实信息是否被排在了较高的位置。理想情况下,所有相关的信息块都应该出现在排名的最前面。这个指标是根据问题和上下文来计算的,数值范围在0到1之间,分数越高表示精确度越好。

(5)Context Recall:用来衡量检索到的上下文与被视为事实真相的标注答案的一致性程度。它根据事实真相和检索到的上下文来计算,数值范围在0到1之间,数值越高表示性能越好; 为了从事实真相的答案中估计上下文召回率,需要分析真实答案中的每个句子是否可以归因于检索到的上下文。在理想情况下,事实真相答案中的所有句子都应该能够对应到检索到的上下文中。

(6)上面的评价指标很多,总的来说可以分成两类:
-
Retriever的评价
- Context Precision:评估初步从向量数据库召回context的质量,有没有召回错误(或者说不相关)信息
- Context Recall:评估初步从向量数据库召回context的覆盖率,有没有遗漏重要信息
- Generator的评价(主要针对LLM)
- Faithfulness:LLM根据query+context生成最终回答在语义上有没有遵从context,避免回答跳出context的范围,产生幻觉,进而驴唇不对马嘴
- Answer relevance:LLM根据query+context生成的最终回答有没有紧扣query的要求,答案是否完整或包含冗余信息
幸运的是,这些指标的计算在langChain都已经实现,直接调用即可!https://github.com/blackinkkkxi/RAG_langchain/blob/main/learn/evaluation/RAGAS-langchian.ipynb 这有整个完整的流程参考!
先定义好prompt: 明确告知LLM根据question和context生成answer,不要自己胡乱联想,不知道就是不知道!
from langchain import PromptTemplatetemplate = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Question: {question} Context: {context} Answer: """prompt = PromptTemplate(template=template, input_variables=["context","question"])print(prompt)
再利用 `Runnable` 定义一个 `chain` 实现rag全流程,指定LLM、prompt、retriever等关键信息!
from langchain.schema.runnable import RunnablePassthrough from langchain.schema.output_parser import StrOutputParser from langchain.chat_models import ChatOpenAIllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)rag_chain = ({"context": base_retriever, "question": RunnablePassthrough()} | prompt | llm| StrOutputParser() )
定义评价指标所需要的数据:
# Ragas 数据集格式要求 ['question', 'answer', 'contexts', 'ground_truths'] ''' {"question": [], <-- 问题基于Context的"answer": [], <-- 答案基于LLM生成的"contexts": [], <-- context"ground_truths": [] <-- 标准答案 } '''from datasets import Datasetquestions = ["What is faithfulness ?", "How many pages are included in the WikiEval dataset, and which years do they cover information from?","Why is evaluating Retrieval Augmented Generation (RAG) systems challenging?",] ground_truths = [["Faithfulness refers to the idea that the answer should be grounded in the given context."],[" To construct the dataset, we first selected 50 Wikipedia pages covering events that have happened since the start of 2022."],["Evaluating RAG architectures is, however, challenging because there are several dimensions to consider: the ability of the retrieval system to identify relevant and focused context passages, the ability of the LLM to exploit such passages in a faithful way, or the quality of the generation itself."]] answers = [] contexts = []# 生成答案 for query in questions:answers.append(rag_chain.invoke(query))contexts.append([docs.page_content for docs in base_retriever.get_relevant_documents(query)])# 构建数据 data = {"question": questions,"answer": answers,"contexts": contexts,"ground_truths": ground_truths } dataset = Dataset.from_dict(data)
最后一步直接调用现成接口评估:
from ragas import evaluate from ragas.metrics import (faithfulness,answer_relevancy,context_relevancy,context_recall,context_precision, )result = evaluate(dataset = dataset, metrics=[context_precision,context_recall,faithfulness,answer_relevancy,], )
评估结果:

根据评估指标判断:如果context两个指标较低,明显是retriever的问题,可以引入EnsembleRetriver、LongContextReorder、ParentDocumentRetriever;如果faithfulness或answer relevance较低,可以考虑换LLM!
参考:
1、https://www.bilibili.com/video/BV1Dm411X7H1/?spm_id_from=pageDriver&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 RAG:来自实际场景中的挑战与见解
2、https://github.com/blackinkkkxi/RAG_langchain
3、https://www.bilibili.com/video/BV1Jz421Q7Lw/?spm_id_from=333.788&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 如何利用RAGAs评估RAG系统的好坏
4、https://arxiv.org/pdf/2309.15217.pdf RAGAS: Automated Evaluation of Retrieval Augmented Generation