【一】MySQL进阶知识之存储过程
【1】什么是存储过程
存储过程就类似于Python中的自定义函数
内部包含了一系列可以执行的SQL语句,存储过程存储在MySQL服务端中,可以通过调用存储过程触发内部的SQL语句
- 存储过程是在关系型数据库中存储的一组预定义的SQL语句集合,可以接收参数并返回结果。
- 它们被封装在数据库服务器中,并由应用程序通过调用存储过程来执行特定的数据库操作。
【2】存储过程的特点
-
预编译:
- 存储过程在首次创建时会被编译和优化,之后每次执行时都不需要再进行编译,这样可以提高数据库的执行效率。
-
数据库端执行:
- 与应用程序中直接执行SQL语句相比,存储过程在数据库服务器端执行,减少了网络传输开销,提高了数据访问性能。
-
代码重用:
- 存储过程可以被多个应用程序共享和重用,避免了重复编写相同的SQL语句,提高了开发效率。
-
安全性:
- 通过存储过程,可以将对数据库的访问权限限制在一定范围内,从而提高数据的安全性。
-
事务支持:
- 存储过程可以包含事务处理逻辑,保证数据库操作的一致性和完整性。
-
简化复杂操作:
- 存储过程可以执行复杂的数据操作和计算,简化了应用程序的开发和维护过程。
【3】如何使用存储过程
(1)定义存储过程
create procedure 存储过程的名字(形参1,形参2...)
beginSQL代码
end
(2)调用
call 存储过程的名字();
(3)查看存储过程具体信息
show create procedure 存储过程的名字;
(4)查看所有存储过程
show procedure status;
(5)删除存储过程
drop procedure 存储过程的名字;
【4】存储过程的开发模式
(1)三种开发模式
[1] 第一种(提前编好存储过程)
-
应用程序
-
- 程序员写代码开发
-
MySQL
-
- 提前编好存储过程,供应用程序调用
-
优点
-
- 开发效率提升、执行效率提升
-
缺点
-
- 考虑到人为因素、跨部门沟通等问题
- 后续的存储过程的扩展性差
[2] 第二种(自己动手写库操作)
-
应用程序
-
- 程序员写代码开发之前
- 涉及到数据库操作需要自己动手写
-
优点
-
- 扩展性高
-
缺点
-
- 开发效率低
- 编写SQL语句繁琐,并且后续还需要考虑优化问题
[3] 第三种(ORM框架)
-
应用程序
-
- 只写程序代码
- 不写SQL语句
- 基于别人写好的操作MySQL的Python的框架直接调用即可(ORM框架)
-
优点
-
- 开发效率比上面的两种高
-
缺点
-
- 语句的扩展性差
- 可能会出现效率低下的问题
(2)示例
# 把原本的结束符替换到
delimiter $$# 创建存储过程
create procedure p1(# in表示这个参数必须只能是传入不能被返回出去in m int,in n int,# out表示这个参数可以被返回出去# 还有一个inout表示即可以传入也可以被返回出去out res int
)beginselect name from emp where dep_id > m and dep_id <n;# 将res变量修改,用来标识当前的存储过程代码确实执行了set res = 666;
end$$delimiter ;create table emp(id int primary key auto_increment,name varchar(50),dep_id int
);
- 使用存储过程
# 定义存储过程中的变量
set @res=10; # 查看写好的存储过程
select @res; # 调用存储过程
call p1(1,5,@res) # 查看存储过程信息
select @res;
mysql> create table emp(-> id int primary key auto_increment,-> name varchar(50),-> dep_id int-> );
Query OK, 0 rows affected (0.17 sec)mysql> create procedure p1(-> # in表示这个参数必须只能是传入不能被返回出去-> in m int,-> in n int,->-> # out表示这个参数可以被返回出去-> # 还有一个inout表示即可以传入也可以被返回出去-> out res int-> )->-> begin-> select name from emp where dep_id > m and dep_id <n;-> # 将res变量修改,用来标识当前的存储过程代码确实执行了-> set res = 666;-> end$$
Query OK, 0 rows affected (0.01 sec)mysql> delimiter ;mysql> set @res=100;
Query OK, 0 rows affected (0.00 sec)mysql> select @res;
+------+
| @res |
+------+
| 100 |
+------+
1 row in set (0.02 sec)mysql> call p1(1,5,@res); # m:1,n=5
Empty set (0.00 sec)Query OK, 0 rows affected (0.00 sec)mysql> select @res;
+------+
| @res |
+------+
| 666 |
+------+
1 row in set (0.00 sec)# 把原本的结束符替换到
delimiter $$# 创建存储过程
create procedure insert_data(in name varchar(50),in dep_id int
)begininsert into emp(name,dep_id) values (name,dep_id);
end$$delimiter ;call insert_data("chosen",200);
【二】函数
【1】什么是函数
- 跟存储过程是有区别的,存储过程是自定义函数,函数就类似于内置函数
- 注意与存储过程的区别,mysql内置的函数只能在sql语句中使用!
【2】字符串函数
- CONCAT(str1, str2, ...): 将多个字符串连接成一个字符串。
- SUBSTRING(str, start, length): 返回字符串的子串。
- UPPER(str): 将字符串转换为大写。
- LOWER(str): 将字符串转换为小写。
- LENGTH(str): 返回字符串的长度。
- Trim、LTrim、RTrim: 移除指定字符
- Left、Right: 获取左右起始指定个数字符
- Soundex: 返回读音相似值(对英文效果)
【3】示例
(1)数据准备
CREATE TABLE Customers (Name VARCHAR(100),Username VARCHAR(100)
);
- 插入数据
INSERT INTO Customers (Name, Username) VALUES ('John Doe', 'JDoe'),('Jane Smith', 'JSmith'),('Jim Brown', 'JBrown'),('Joseph Lee', 'JLee');
(2)CONCAT
CONCAT()函数可以将两个或更多的字符串连接在一起
SELECT CONCAT('Hello', ' ', 'World') AS Greeting;
-- 输出:Hello World
+------------+
| Greeting |
+------------+
| HelloWorld |
+------------+
(3)SUBSTRING
SUBSTRING()函数可以从字符串中提取部分字符
SELECT SUBSTRING('Hello World', 1, 5) AS Substring;
-- 输出:Hello
+-----------+
| Substring |
+-----------+
| Hello |
+-----------+
(4)UPPER/LOWER
UPPER()函数将字符串转换为大写LOWER()函数将字符串转换为小写。
SELECT UPPER('hello world') AS Uppercase;
-- 输出:HELLO WORLD
+-------------+
| Uppercase |
+-------------+
| HELLO WORLD |
+-------------+SELECT LOWER('HELLO WORLD') AS Lowercase;
-- 输出:hello world
+-------------+
| Lowercase |
+-------------+
| hello world |
+-------------+
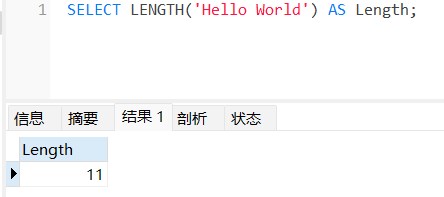
(5)LENGTH
LENGTH()函数返回字符串的长度。
SELECT LENGTH('Hello World') AS Length;
-- 输出:11
(6)Soundex
SOUNDEX()函数返回读音相似值(对英文效果),可以用来查找同音异形词。
SELECT SOUNDEX('John Doe') AS Soundex;
-- 输出:J530
+---------+
| Soundex |
+---------+
| J530 |
+---------+
【4】日期和时间函数
(1)介绍
- NOW(): 返回当前日期和时间。
- CURDATE(): 返回当前日期。
- CURTIME(): 返回当前时间。
- DATE_FORMAT(date, format): 格式化日期。
(2)示例
[1] NOW()
SELECT NOW() AS CurrentDateTime; -- 当前日期和时间
+---------------------+
| CurrentDateTime |
+---------------------+
| 2024-06-03 12:22:54 |
+---------------------+
[2] CURDATE()
SELECT CURDATE() AS CurrentDate; -- 当前日期
+-------------+
| CurrentDate |
+-------------+
| 2024-06-03 |
+-------------+
[3] CURTIME()
SELECT CURTIME() AS CurrentTime; -- 当前时间
+-------------+
| CurrentTime |
+-------------+
| 12:22:54 |
+-------------+
[4] DATE_FORMAT(date, format)
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s') AS FormattedDateTime; -- 格式化后的日期和时间
+---------------------+
| FormattedDateTime |
+---------------------+
| 2024-06-03 12:22:54 |
+---------------------+
【三】流程控制
# 【一】Python
if 条件:...
elif 条件:...
else:...# 【二】JavaScript / Java
if (条件){代码
}else if (条件){代码
}else{代码
}# 【三】MySQL
if 条件 then 子代码
elseif 条件 then 子代码
else 子代码
end if;'''
DECLARE num INT ;
SET num = 0 ;
WHILE num < 10 DOSELECT num ;SET num = num + 1 ;
END WHILE ;
'''# 【四】MySQL CASE语句
CASE expressionWHEN value1 THENstatements;WHEN value2 THENstatements;...ELSEstatements;
END CASE;'''
SELECT CASE WHEN Salary > 5000 THEN 'High'ELSE 'Low'END AS SalaryGroup,COUNT(*) AS EmployeeCount
FROM Employees
GROUP BY SalaryGroup;
'''# 【五】WHILE语句
WHILE condition DOstatements;
END WHILE;'''
FOR var IN start, increment, end DOstatements;
END FOR;
'''
【四】索引
【1】索引的概念
-
索引(在MySQL中也叫做“键(key)”)是存储引擎用于快速找到记录的一种数据结构,这也是索引最基本的功能。
-
索引对于良好的性能非常关键。
- 数据量越大时,索引对性能的影响也越重要,好的索引可以将查询性能提高几个数量级。
- 在数据量较小且负载较低时,不恰当的索引对性能的影响可能还不明显,但是在数据量逐渐增大时,糟糕的索引会使MySQL的性能急剧的下降。
-
索引优化是查询性能优化最有效的手段。
-
如果想要在一本书中找到某个特定主题,一般会先看书的目录,找到对应的页码,然后直接翻到对应的页码即可查看。
- 在MySQL中,存储引擎用类似的方法使用索引
- 首先在索引中找到对应的值
- 然后根据匹配的索引记录找到对应的数据行。
- 在MySQL中,存储引擎用类似的方法使用索引
-
简单的说,数据库索引类似于书前面的目录,能加快数据库的查询速度。
【2】MySQL中索引的类型
-
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建 对应列的索引。
-
索引在MySQL中也叫键,是存储引擎用于快速查找记录的一种数据结构
- 主键索引
- 辅助索引
- 全文索引
- 外键索引
- 唯一索引
-
foreign key
- 不是用来加速查询的
-
primary key/unique key
- 不仅可以加速查询速度,还具有对应的约束条件
-
index key
- 只有加速查询速度的功能
【3】索引的本质
-
通过不蹲的缩小想要的数据范围筛选出最终的结果
-
- 同时将随机事件(一页一页的翻)变成顺序时间(先找目录再找数据)
-
也就是说我们有了索引机制,我们可以总是用一种固定的方式查询数据
【4】索引的缺点
- 当表中有大量数据存在的前提下,创建索引的速度回非常慢
- 在索引创建完毕后,对表的查询性能会大幅度的上升,但是写的性能也会大幅度下降
不要随意地创建索引
【5】索引的使用场景
-
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
-
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。
-
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
-
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
【6】索引操作
[1] 查看索引
show index from 表名;
mysql> show index from student;
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 8 | NULL | NULL | | BTREE | | |
| student | 0 | sn | 1 | sn | A | 8 | NULL | NULL | YES | BTREE | | |
| student | 1 | classes_id | 1 | classes_id | A | 2 | NULL | NULL | YES | BTREE | | |
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.01 sec)mysql> desc student;-- 实现表结构 --
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| sn | int(11) | YES | UNI | NULL | |
| name | varchar(20) | YES | | unkown | |
| qq_mail | varchar(20) | YES | | NULL | |
| classes_id | int(11) | YES | MUL | NULL | |
+------------+-------------+------+-----+---------+----------------+
5 rows in set (0.01 sec)
[2] 创建索引
- 对于非主键、非唯一约束、非外键的字段,可以创建普通索引
create index 索引名 on 表名(字段名);# 索引名的命名规则一般是:index_表名_列名
[3]删除索引
drop index 索引名 on 表名
【7】索引的数据结构
- 对于索引的操作是非常简单的,但是关键在于我们要去学习支持索引的数据结构。
- 在数据结构那门课程里,我们可以使用二叉搜索树来加快查询,但是元素个数一多,对于输的高度就就会很高,而树高就代表着比较次数多,在实际项目中代表中I/O的访问次数多,因为数据库中的数据是存在硬盘里的。
- 或者我们还学过使用哈希表,他查询的时间复杂度为O(1)但是哈希表不支持范围查找,不支持模糊匹配。
- 实际上索引的背后使用的是B+树。
- 在了解B+树之前,先要了解B树,如果有考过408同学应该是对这个数据结构是非常熟悉的
(1)B+树的优势
- 当前一个结点保存更多的key,最终树的高度是相对更矮的(B树也有这个优点),查询的时候可以减少IO的访问次数。
- 所有的查询最终都会落在叶子结点上(查询任何一个数据,经过的IO访问次数,是一样的。)稳定是很重要的,稳定可以让程序员对程序的运行效率有更准确的评估。
- B+树的所有叶子结点都用链表进行了链接(并且是一个双向链表),这样就支持更直接的范围查询了。同时代码也更好写了。
- 由于数据都在叶子结点上,非叶子结点只存了key,所以我们就可以将叶子结点的一部分进行缓存(B树非叶子结点是存记录的),这样可以进一步减少IO次数。
(2)小结
- 总之,B+树是一种高效的数据结构,具有平衡性、多路搜索、顺序访问性和存储利用率高等特点,适用于需要高效查询和排序的场景。
- 只有叶子结点存放真实数据,根和树枝节点存的仅仅是虚拟数据
- 查询次数由树的层级决定,层级越低次数越少
【8】聚集索引(主键索引)
- 聚集索引(Clustered Index)是关系型数据库中的一种索引类型,它决定了表中数据的物理存储顺序。
- 在一个表中,只能有一个聚集索引。
- 聚集索引对表进行了重新组织,使得数据按照聚集索引的键值顺序存储在磁盘上。
- 由于聚集索引决定了数据的物理存储顺序,因此通过聚集索引可以快速地找到特定范围内的数据
- MySQL的聚簇索引是基于B+树的数据结构实现的,它会把数据存储在索引的叶子节点上,叶子节点之间按顺序链接,使得按主键进行搜索时速度最快。
- 如果没有主键,如果按主键搜索,速度是最快的。
(1)聚集索引的特点
- 数据的逻辑顺序和物理顺序是一致的,通过聚集索引可以直接访问特定行,因此聚集索引的查询速度很快。
- 聚集索引的键值必须是唯一的,不允许重复值存在。
- 当表中的数据发生插入、删除或更新操作时,聚集索引需要进行相应的调整以保持数据的有序性,这可能会对性能产生一定影响。
- 如果表中没有定义聚集索引,那么表的数据存储顺序将按照物理地址来存储。
- 表不建立主键,也会有个隐藏字段是主键,是主键索引
- 主键索引对于按照主键进行查询的性能非常高。
(2)小结
-
聚集索引适用于经常需要按照某个特定的列或列组进行查询的情况。
-
- 例如,在一个订单表中,如果根据订单号频繁地进行查询,那么可以将订单号作为聚集索引,这样可以提高订单查询的效率。
-
需要注意的是,聚集索引的选择需要根据具体的业务需求和数据访问模式进行权衡。
-
- 在一些特定情况下,聚集索引可能并不适合或者不符合最佳实践,此时可以考虑使用非聚集索引等其他索引类型。
【9】非覆盖索引
(1)什么是非覆盖索引
- 非覆盖索引是指在数据库中的索引结构中,存储了对应的键值(例如:主键、唯一键、普通索引)以及相应的行的定位信息(如物理存储位置或行标识),但没有包含查询所需的其他列数据。
- 当执行一个查询时,使用非覆盖索引需要通过索引定位到对应的行,并进一步访问主表来获取所需的列数据。
- 与覆盖索引相比,非覆盖索引需要进行额外的查询操作来检索主表中的其他列数据,因此在某些情况下可能会导致性能下降。
- 虽然查询的时候命中了索引字段name,但是要查的是age字段,所以还需要利用主键才去查找
select age from user where name='dream';
(2)非覆盖索引的适用场景和优势
- 提供高效的筛选能力:非覆盖索引可以根据所建索引的键值快速定位到满足查询条件的行,这可以减少需要扫描的数据量,提供高效的筛选能力。
- 减少磁盘I/O操作:虽然非覆盖索引需要额外的访问主表来获取数据,但是相对于全表扫描或者需要访问大量数据页的情况,非覆盖索引仍然可以减少磁盘的I/O操作次数,从而提升查询性能。
- 降低内存消耗:非覆盖索引通常比较小,占用的内存空间相对较少。这对于有限的内存资源来说,可以更好地利用内存空间。
(3)注意事项
- 列选择性:索引的列选择性是指该列上不同值的数量与总行数之间的比率。当列具有较高的选择性时,非覆盖索引的效果通常会更好。因为高选择性的列能够更快地筛选出满足查询条件的行。
- 查询性能评估:在设计索引时,需要仔细评估查询的频率和性能需求。如果某个查询经常执行,而且对性能要求很高,那么建立合适的非覆盖索引可以提升查询效率。
(4)小结
- 总结而言,非覆盖索引是一种常见的索引类型,在特定场景下可以提供高效的筛选能力和降低磁盘I/O操作的优势。
- 但在选择索引类型时,需要综合考虑查询需求、列选择性以及数据表大小等因素,以选择最合适的索引优化方案。