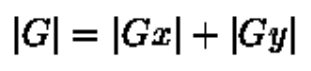HieRec: Hierarchical User Interest Modeling for Personalized News Recommendation论文阅读笔记
Abstract
现存的问题:
用户兴趣建模对于个性化新闻推荐至关重要。现有的新闻推荐方法通常从每个用户以前的行为中学习一个单一的用户嵌入,以代表他们的整体兴趣。然而,用户兴趣通常是多样化和多粒度的,很难通过单一的用户嵌入来准确建模。
解决方案:
我们提出了一种具有分层用户兴趣建模的新闻推荐方法,称为HieRec。在我们的方法中,每个用户都用分层兴趣树来表示,而不是单一的用户嵌入,以更好地捕捉他们对新闻的多样化和多粒度兴趣。我们使用三级层次结构来表示:
1)用户的整体兴趣;
2)用户对粗粒度主题(如体育)的兴趣;
3)用户对细粒度主题(如足球)的兴趣。此外,我们还提出了一个分层用户兴趣匹配框架,将候选新闻与不同层次的用户兴趣相匹配,以实现更准确的用户兴趣定位。
Introduction
本文提出了一种分层用户兴趣建模的个性化新闻推荐方法,命名为 HieRec,它能有效捕捉多样化和多粒度的用户兴趣。我们的方法包含三个层次的用户兴趣表征,从不同方面和粒度对用户兴趣进行建模。
第一个层次是子主题层次,包含多个兴趣表征,以模拟用户对不同新闻子主题的细粒度兴趣。它们是从子主题的嵌入和相应子主题的点击新闻中学习的。
第二种是主题级,它包含多个兴趣表征,用于捕捉用户对主要新闻主题的粗粒度兴趣。这些兴趣表征是从新闻主题及其下属子主题级兴趣表征的嵌入中学习而来的。
第三个是用户级兴趣表征,它包含一个兴趣表征来模拟用户的整体兴趣。它是从主题级兴趣表征中学习的。此外,我们还提出了一个分层用户兴趣匹配框架,将候选新闻与不同层次的兴趣表征进行匹配,从而更准确地定位用户兴趣。
Method
问题定义
这里不同的是每个新闻都有标题,主题和子主题,标题是由文本序列和实体序列组成。我们假设每个用户有M个点击新闻,在HieRec中,我们根据它们的主题和子主题进一步划分这些点击,用于分层用户兴趣建模。
分层的用户兴趣建模
分层的用户兴趣建模的结构图如下所示

一般来说,用户的兴趣通常是非常多样化和多粒度的。理解用户对不同方面和粒度的兴趣,有可能更准确地建模用户的兴趣。因此,我们提出了一个分层的用户兴趣建模框架,该框架学习一个分层的兴趣树来捕获多样化和多粒度的用户兴趣。如图2所示,HieRec通过一个三层的层次结构来表示用户的兴趣。
首先,我们学习多个子主题级兴趣表征,以模拟用户对不同新闻子主题(如足球和高尔夫)的细粒度兴趣。子主题 \(s_j^i\)的子主题级兴趣表征是从 \(N_j^i\)中学习的,\(N_j^i\)由用户在子主题 \(s_j^i\)中点击的新闻组成。由于点击新闻在用户兴趣建模中可能具有不同的信息量,因此我们采用子主题级注意力网络来选择信息量大的点击新闻,以建模用户对子主题\(s_j^i\) 的兴趣:
\(\mathbf{c}_j^i=\sum_{k=1}^l\gamma_k\mathbf{n}_k^{i,j},\gamma_k=\frac{\exp(\phi_s(\mathbf{n}_k^{i,j}))}{\sum_{p=1}^l\exp(\phi_s(\mathbf{n}_p^{i,j}))},\)
此外,我们还采用了一个子主题嵌入层来捕获不同子主题的语义信息,从中我们可以得到子主题 \(s_j^i\)的嵌入向量。
最后,我们根据 \(c_j^i\)和\(s_j^i\)的组合学习子主题级用户兴趣表示 \(u_{i,j}^s\),即 \(\mathbf{u}_{i,j}^s=\mathbf{c}_j^i+\mathbf{s}_j^i\)。同样,我们也会学习用户点击的其他子主题的子主题级兴趣表征。
其次,我们学习多种主题级别的兴趣表示,以模拟主要新闻主题(如体育和金融)中的粗粒度用户兴趣。所点击的主题ti的主题级兴趣表示是从子主题\(\{s_{i,j}^s|j=1,...,d\}\)的子主题级兴趣表示\(\{\mathbf{u}_{i,j}^s|j=1,...,d\}\)中学习出来的。
更具体地说,用户对不同子话题的兴趣可能对特定话题的用户兴趣建模具有不同的重要性。此外,一个子话题的新闻点击量也可能反映出其在主题级用户兴趣建模中的重要性。因此,我们利用话题级注意力网络来选择重要的子话题级用户兴趣表征,以模拟用户对话题 ti 的兴趣:
\(\mathbf{z}_i=\sum_{j=1}^d\beta_j\mathbf{u}_{i,j}^s,\beta_j=\frac{\exp(\phi_t(\mathbf{v}_{i,j}^s))}{\sum_{k=1}^d\exp(\phi_t(\mathbf{v}_{i,k}^s))},\)
其中:\(\mathbf{v}_{i,j}^s=[\mathbf{u}_{i,j}^s;\mathbf{r}_j^i]\)。\(r_j^i\)是子主题\(s_j^i\)上点击新闻次数的嵌入向量。此外,我们还使用话题嵌入层对不同话题的语义信息进行建模,并驱动话题\(t_i\)的嵌入向量 。最后,我们汇总 zi 和 ti,学习主题 ti 中的主题级用户兴趣表征\(\mathbf{u}_i^t=\mathbf{z}_i+\mathbf{t}_i\)。同样,我们也会学习其他点击主题的主题级兴趣表征。
第三,我们学习用户级兴趣表征 u g 来模拟用户的整体兴趣。它是从主题级兴趣表征中学习的。同样,我们采用用户级注意力网络来模拟主题级用户兴趣的相对重要性,从而学习用户级兴趣表征:
\(\mathbf{u}^g=\sum_{i=1}^m\alpha_i\mathbf{u}_i^t,\alpha_i=\frac{\exp(\phi_g(\mathbf{v}_i^t))}{\sum_{j=1}^m\exp(\phi_g(\mathbf{v}_j^t))},\)
层次的用户匹配
候选新闻与用户兴趣在不同粒度上的匹配可以为用户兴趣定位提供各种线索。候选新闻与用户细粒度兴趣之间的匹配有助于个性化新闻推荐。此外,并非所有候选新闻都能与细粒度用户兴趣相匹配。候选新闻与粗粒度的用户兴趣和整体用户兴趣进行匹配也很重要。因此,我们提出了一个分层用户兴趣匹配框架,它对用户对不同兴趣粒度的候选新闻的兴趣建模。
层次的用户匹配框架如下:

它以候选新闻(包括其表示 nc、主题 tc 和子主题 sc)和分层用户兴趣表示为输入。首先,我们将候选新闻与用户总体兴趣相匹配,并根据 nc 和 ug 之间的相关性计算出用户级兴趣得分 og:\(o_g=\mathbf{n}_c\cdot\mathbf{u}^g.\)其中\(u^g\)是上一步学习到的用户级兴趣表征。
其次,主题级兴趣表示\(u_{t_c}^t\)模拟用户对候选新闻主题 tc 的粗粒度兴趣。它可以提供粗粒度信息,以了解用户对候选新闻的兴趣。因此,我们将话题级兴趣表征 \(u_{t_c}^t\) 与候选新闻 nc 匹配为\(\hat{o}_t=\mathbf{n}_c\cdot\mathbf{u}_{t_c}^t\)。此外,我们还可以推断用户可能对他们点击次数较多的话题更感兴趣。因此,我们根据话题 tc 在历史点击新闻中的比例\(w_{t_c}\)对\(\hat{o}_t\)进行加权,得到话题级兴趣得分 ot : \(o_t=\hat{o}_t*w_{t_c}\)。此外,如果候选新闻不属于任何用户点击过的主题,则直接将 ot 设为 0。
第三,子主题级兴趣表征 \(u_{s_c}^s\)模拟了用户对候选新闻子主题 sc的细粒度兴趣,可用于捕捉用户对候选新闻的细粒度兴趣。因此,我们将子主题级兴趣表征\(u_{s_c}^s\)与候选新闻 nc 匹配为\(\hat{o}_s=\mathbf{n}_c\cdot\mathbf{u}_{s_c}^s\).同样,我们根据用户点击新闻中子主题 sc 的比例 \(w_{s_c}\)对 \(\hat{o}_s\)进行加权,得到子主题级兴趣得分:\(o_s=\hat{o}_s*w_{s_c}\)。
最后,将三个不同级别的兴趣分数汇总为一个总体兴趣分数o:
新闻表示
我们将介绍了如何从文本和新闻标题的实体中获取新闻表示,学习新闻表示的框架如下所示。

我们首先使用文本编码器对新闻文本进行建模。它首先应用单词嵌入层来丰富模型的语义信息。接着,它采用文本自注意力网络从新闻文本的上下文中学习单词表征。然后,它采用文本注意力网络,通过聚合词表征来学习文本表征 nt。除了文本,知识图谱也能通过新闻中的实体为理解新闻内容提供丰富的信息因此,我们采用实体编码器来学习新闻的实体表征。我们首先使用实体嵌入层将知识图谱中的信息纳入我们的模型。我们进一步应用实体自我关注网络来捕捉实体间的相关性。接下来,我们利用实体关注网络,通过聚合实体来学习新闻的实体表示。最后,我们建立了新闻的表示n为\(\mathbf{n}=\mathbf{W}_t\mathbf{n}_t+\mathbf{W}_e\mathbf{n}_e\)
模型训练
在训练数据集中O中给定一个正样本\(n_i^+\)(一个已被点击的新闻),我们从显示给用户u的相同新闻印象中随机选择K个负样本\([n_i^1,...,n_i^K]\)(未被点击的新闻)。NCE损失L要求阳性样本\(o_i^+\)应比其他阴性样本\([o_i^1,...,o_i^K]\)分配更高的兴趣评分,并表述为:
\(\mathcal{L}=-\sum_{i=1}^{|O|}\log\frac{\exp(o_i^+)}{\exp(o_i^+)+\sum_{j=1}^K\exp(o_i^j)}.\)
总结
这篇文章感觉讲的非常清晰,就不总结了。贴一下论文的conclusion
本文针对分层用户兴趣建模提出了一种名为 HieRec 的个性化新闻推荐方法,它能有效地对多样化和多粒度的用户兴趣进行建模。HieRec 通过学习三层层次结构,从不同方面和粒度来表示用户兴趣。首先,我们学习多个子主题级兴趣表征,对不同新闻子主题中的细粒度用户兴趣进行建模。其次,我们学习多个主题级兴趣表征,以模拟用户对几个主要新闻主题的粗粒度兴趣。第三,我们学习一个用户级兴趣表征来模拟用户的整体兴趣。此外,我们还提出了一个分层用户兴趣匹配框架,将候选新闻与不同粒度的用户兴趣进行匹配,从而实现更准确的用户兴趣定位。