这篇博文包括 Onehouse 首席执行官 Vinoth Chandar 于 2022 年 3 月在奥斯汀数据委员会发表的重要演讲的后半部分。本文是第 2 部分,比较了架构的功能和性价比特征。最后,它描述了一个面向未来的、湖仓一体的架构。
数据仓库和Lakehouse:功能对比

对于核心读写:湖仓一体和仓库都可以支持更新、删除、事务、统计、排序、批量加载、审计、回滚、时间旅行这些基本功能。仓库具有更完整的关系或数据库功能,例如多表事务、聚簇等。
在Lakehouse中大多数技术都是以库的形式提供。例如在 Hudi 中从一开始就支持主键,因为在 Uber 时,唯一键约束对我们来说是一个非常困难的要求。
Lakehouse 的设计选择更多地反映了更大规模的数据需求
有些能力是专有的,有些是开放的,然后有一些围绕流式更新和所有这些东西的特定设计选择。通常会看到湖仓一体设计选择更多地反映了更大规模的数据需求,而仓库则贴近它们开始时使用的数据库源。

不仅仅是高效写入数据,还需要优化表的核心服务以确保真正良好的性能。
可以看到例如聚类或排序以获得良好的性能,空间回收。当数据变得脏时,如何管理它?在它们的自动化管理方式方面,或者是否需要将其中一些库放在Lakehouse上运行,这两者之间存在巨大差异。
像文件大小这类信息在数仓中是隐藏的文件,但它们仍然暴露在湖仓一体中,如果不能很好地管理它们可能会影响性能。一些框架具有自动强制执行功能,有些是DIY的。
在 Hudi 中也有这些功能,但仍然需要自我管理。Hudi 可以进行聚簇,但需要自己运行聚簇作业。而如果只是使用托管服务,这些都是在内部管理。数仓中的缓存是透明加速的,Lakehouse可使用或不用。

数据库更改数据捕获 (CDC)、引入日志事件等内容。许多使用云(现代数据栈或云数据仓库)的人都拥有托管的零操作摄取服务,他们更喜欢使用这些服务来获取数据并构建表。但是在湖上开发者使用Debezium或框架并与Hudi库捆绑在一起以构建一个端到端的系统。
因此如果想建造一个Lakehouse并投入使用,这确实需要一些时间,必须通过观察所有这些不同的问题并找到解决方案,这提供了极大的灵活性,但需要一些时间才能将其付诸实施。
数据仓库和Lakehouse:性价比
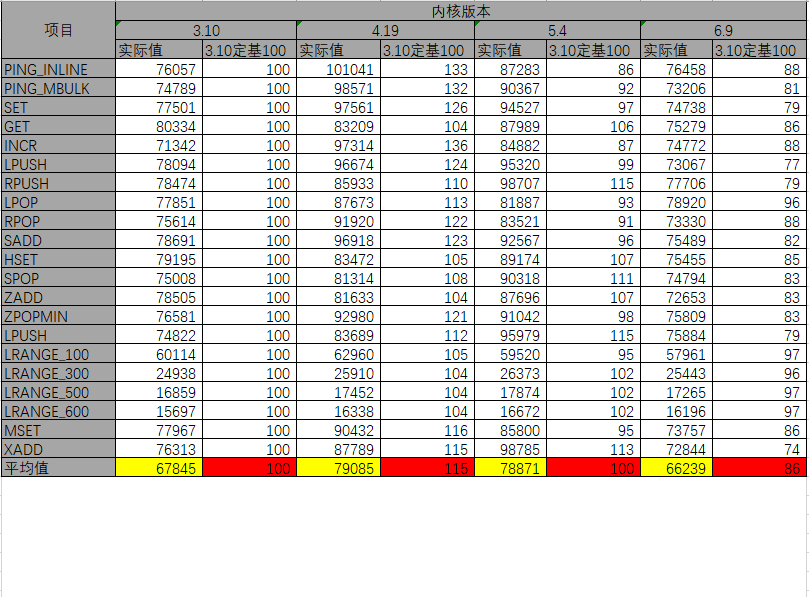
这是一个非常有趣的话题:价格/性能。首先考虑不同工作负载,当谈论性价比时会看到以 TPC-DS 的基准测试报告。

实际上至少需要有四种不同类型的工作负载,并且并非所有工作负载都需要高级引擎,例如 SQL 优化不一定能帮助进行数据摄取,因为非常受 I/O 限制。
不同工作负载具有不同的性价比特征,在湖上仍然需要做大量工作来管理表,可以选择为每个用例选择合适的引擎。因此对于某些人来说也许会选择开源版本,而对于某些人来说会选择云产商的产品。

对于 TPC-DS ,我们将做一些不同的事情并尝试剖析查询。
首先是Lakehouse或仓库中的性能差异从何而来?一个是获取元数据。可以查看表元数据、架构、统计信息以及了解如何规划查询所需的任何内容。
目前Lakehouse要么存储在像 Hive 这样的元存储中,要么存储在存储有关表的统计信息的文件中。然后仓库主要使用数据库存储,当数据量很大时数据库在很多方面都优于文件。因此Lakehouse现在还处于早期阶段,必须在此基础上发展Lakehouse的统计管理。
查询计划很大程度上取决于引擎和供应商。查询优化是一个非常困难的问题,随着花费的时间增加,它会变得更好,需要一个更成熟的优化器,这是一个不断发展的格局。
有了查询计划进行执行时,Lakehouse采用开放的文件格式,而数仓使用封闭的文件格式,但很多性能差异来自文件格式本身,而更像是运行时的差异 - 如果做一个分组查询,假设必须对数据进行洗牌,引擎是怎么做到的?即使在Lakehouse引擎内部,也存在巨大的差异。
像 Spark 会更有弹性地洗牌、重试;但像 Presto 希望保持交互式查询性能和更低的延迟。因此它可能会失败,并且在洗牌数据和响应查询时会做出不同的选择。
TPC-DS 固然很好,但更需要的是运行自身的工作负载,当运行工作负载时可能发现差距不是那么大,建议使用前五个查询或类似的查询,然后进行分析。

在基本的 EC2 成本之上,不同的引擎定价也不同。假设引擎收取 2 倍的费用,但完成该查询的速度比净值快 3 倍就会获得性价比优势。
但是都需要快吗?例如因为缓存也非常快,但它们需要花钱。如果在某些情况下可以负担得起较慢的速度,那么它也可以更便宜。
对自身的工作负载进行基准测试
最快并不是唯一的。还要看看数据仓库的定价:有些是按查询定价的,有些是针对不同虚拟实例类型的定价。因此主要还是对自身的工作负载进行基准测试。

ETL 工作负载在很多时候并没有得到太多关注——尽管很多人在它们上花费了大量时间。
实际上有一个用于数据集成的基准,TPC-DI,但很少看到有人报告任何关于它的内容。至少根据我们的经验,如果看右边的模式,有一个事实表、一个事件表和一些正在更新的维度表。可以看到更新模式确实非常不同,所有这些工作负载不都是一样的,因此我们需要更好的标准化。

数据优化确实很重要。正如我们所看到的关于聚簇如何提高性能的研究。一个来自 Hudi,一个来自 AWS,一个来自我们自己的博客和开源。可以仔细控制数据布局,但是如何在数百个表中做到这一点而不会产生副作用呢?如何通过数据布局控制进行成本和全局优化?这些都是非常开放的问题,很多人今天不得不手动调整并花费大量时间从这些技术中榨取价值。
有了Lakehouse,相对而言随着规模的扩大会更有性价比
总结一下:
- 开放。数据仓库通常是封闭的;Lakehouse是开放(但条件适用)。
- 使用案例。数据仓库是为 BI 设计的;数据湖仓一体具有更好的数据科学、分析和 ML/AI 支持。
- 操作。数据仓库往往是完全托管的;对于数据湖仓一体来说,可以DIY,更难管理。
- 费用。使用数据仓库时,费用会随着规模的扩大而增加;有了Lakehouse,相对而言随着规模的扩大会更有性价比。
使用Lakehouse优先、面向未来的架构
人们什么时候会采用Lakehouse?

开始通常只需复制运营数据,然后配置仪表盘。然后即使数据大小略有增长,也可以在仓库上执行一些 ETL。最终要么遇到成本限制,要么公司足够大,需要关心开放性、开放格式,以及前面讨论的内容。
使用Lakehouse,然后开始编写一些 ETL,这些 ETL 需要从仓库中提供一些数据。还可以复制从仓库卸载的任何 ETL,同时也开始复制数据,数据没有一个单一的事实来源。
Lakehouse必须与外部系统能互操作,即使是仓库。所有引擎中应该能够以横切方式访问该数据。对于给定的引擎,通常可以在开源之间进行选择;供应商提供的托管服务;和/或云提供商产品。
将数据保存在湖上
这里所说的“在湖上”是指开放数据格式。供应商起起落落,但数据就在那里。
在过去的五年中以开放格式将数据库变更或所有原始运营数据直接复制到湖仓一体上,可以为未来做好准备。因为这些通常是最庞大的数据集。
以开放格式将数据库变更或所有原始运营数据直接复制到 Lakehouse 上,为未来做好准备
即使在仓库中,通常影响成本的也是第一层的原始 ETL,即将其放入仓库,然后运行 dbt 来获取表。
因此使用Lakehouse可以很好地做到这一点,而且总是可以重新计算任何东西,可以切换查询引擎,可以重新计算,在这个架构中可以获得非常大的灵活性。
最重要的是:它现在提供了一个单一的事实来源,这意味着相同的数据可以输入到BI和数据科学团队中。
在数据湖上管理
我们可以尽可能地在Lakehouse上管理很多东西,因为它不需要高级计算。其中许多管理服务更多地受 IO 约束或依赖于外部交互。
我们看到了充分利用可互操作Lakehouse的三个最佳实践:
- 将大批量作业保留在Lakehouse中。在原始云存储上运行扫描。
- 在方便的地方处理小型 ETL 作业。这些可以在Lakehouse或仓库上运行。
- 更倾向于增量更新。更多地转向增量模型。
所有这些都提供了性价比的选择,可以拥有具有成本效益的 ETL - 大大降低成本,而不会在重要的地方损失性能。

当一切都完成后看起来像这样。对于Lakehouse,它是开放的并具有所有的互操作性,可以以一种经济高效的方式编写ETL,如果能够快速将数据(甚至是 ETL 和 ETL 数据)放入仓库或直接查询,将获得非常好的 BI 和报告性能。
可以轻松探索 ML 或流式处理等方法。许多这些新兴领域可以很好地整合,因为它同样是一种开放格式,生态系统可以自行发展,而不受制于供应商。当然这已被证明可以支持数据科学和工程。





![[转帖]性能分析之TCP全连接队列占满问题分析及优化过程](https://ask.qcloudimg.com/http-save/yehe-5836255/kwkncvysef.jpeg)