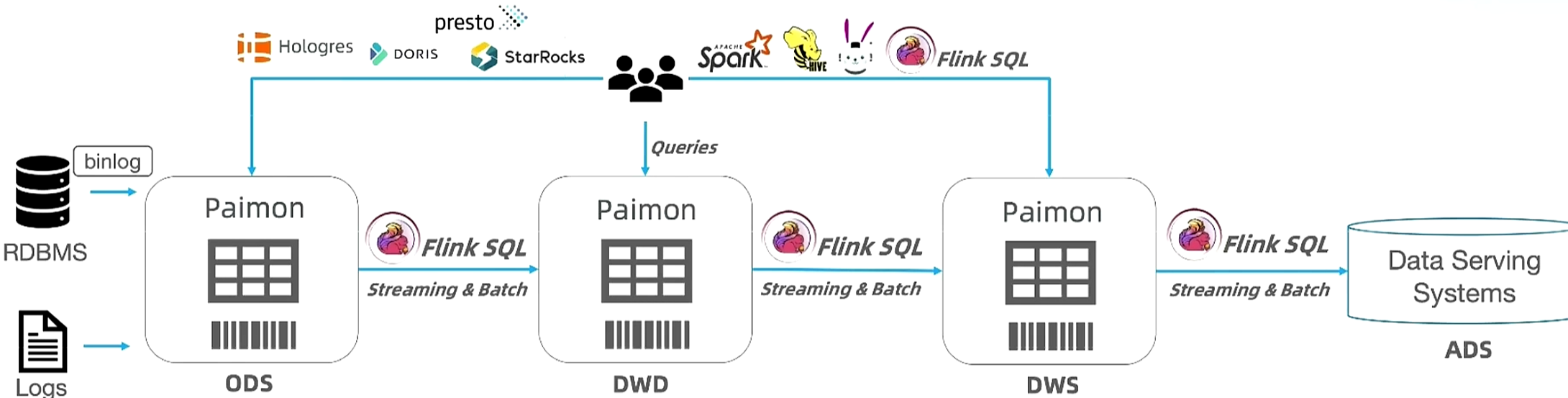
支持高吞吐数据摄入、变更追踪、高效分析的流批数据湖
基于LSM提升写入速度并降低写入消耗;基于有序的SortRun裁剪大部分数据以提升查询性能;支持多种merge引擎实现高性能流表打宽
基于Flink&Paimon实现,提供数据一致性管理能力,解决流式数仓普遍存在的问题
paimon通过snapshot定义数据版本,即数据按snapshot对齐。
实现方案:提交阶段查询系统表中的血缘表设置起始消费位置;运行阶段按照消费的snapshot粒度响应chkpt请求,chkpt coordinator将barrier放在两个snapshot中间;chkpt成功后通知sink提交对应的表;提交完成后由CommitListener将血缘关系写入系统表
问题:
缺少血缘管理(表血缘、数据血缘)
缺少统一的版本管理(多表关联查询时不一致)
数据订正困难(复杂的数据修正过程、链路双跑、业务逻辑修正)

特点
是 Flink SQL 的内置存储
- Flink DDL 会真实创建或删除物理表,不再只是一个外部物理表的映射
- 掩盖和抽象底层技术细节,没有烦人的选项如connector配置
支持亚秒级流写入和消费
高吞吐量扫描能力
降低了认知门槛,存储需要自动处理各种Insert/Update/Delete输入和表定义
- 接收任何类型的变更日志,接收任何类型的数据类型
- 表可以有主键或没有主键
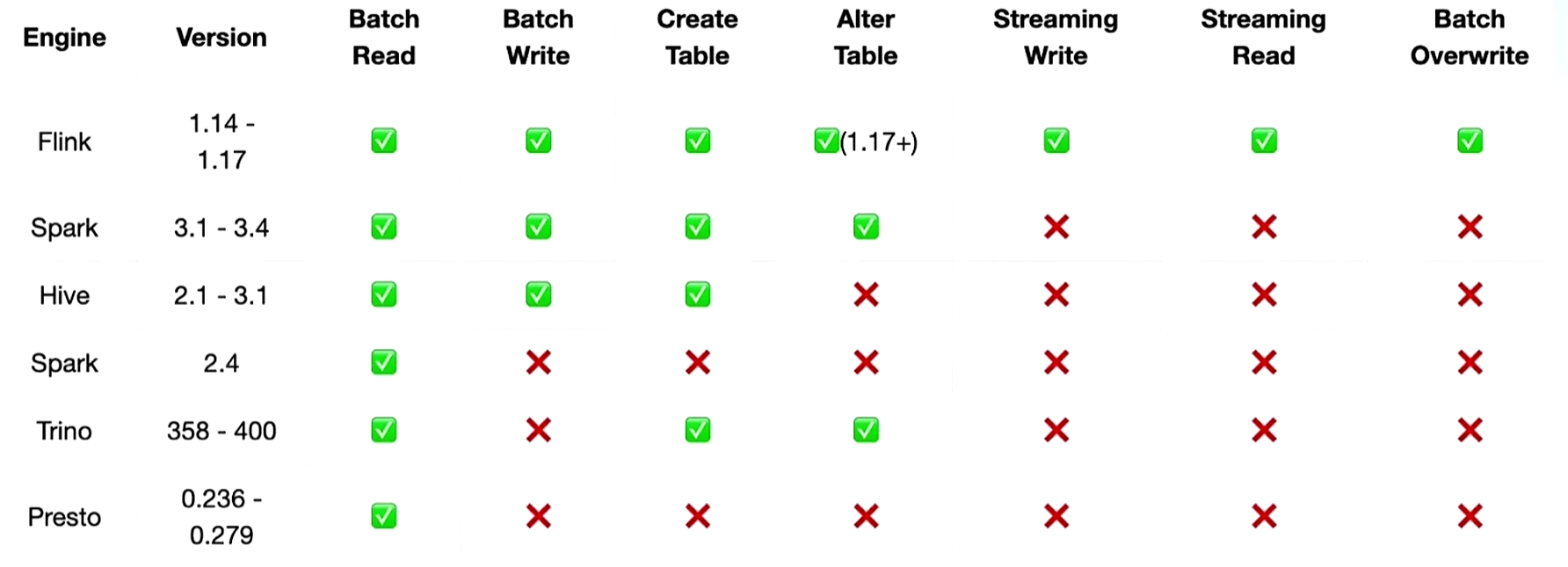
支持多种引擎
存储
LogStore append延时很低,但有TTL限制,可用于流读。FileStore确保可以查询历史数据:
- LogStore:存储最新数据,支持秒级流式增量消费,默认使用Kafka实现
- 完全支持插入/更新/删除
- 根据主键(若有)或整行(无主键)将记录散列到不同的kafka分区
- FileStore:存储最新数据+历史数据,提供批量Ad-Hoc分析,使用LSM、parquet/orc实现
- 为了完全支持插入/更新/删除和可选的主键定义,我们需要一个支持更新和自定义合并的灵活存储结构,LSM 是一个不错的选择
- 为了支持高性能和多场景分析,应该支持多种列式文件格式
- key若有主键则默认json格式,若无则空。value默认使用debezium-json格式
如果是流模式且开启change-tracking,log与file同时生效,生成HybridSource读,如果是流模式且未开启change-tracking、批模式,生成FileStoreSource读。
文件结构
元数据与数据存储在表的同一级目录下,包括 snapshot 目录、manifest 目录、schema 目录、数据文件。桶文件是读写的最小存储单元。
每个snapshot会有对应的一个base清单列表、一个delta清单列表文件,base清单列表包含了本次操作之前的清单文件,清单列表文件会对应一个或多个清单,每个清单会对应一个或多个不同操作类型的数据文件
- snapshot 目录:记录了每次提交产生的 snapshot 文件,记录了本次 commit 正在使用的schema文件、新增了哪些 manifest 文件、删除了哪些 manifest 文件
- snapshot-x 一次checkpoint生成一个或两个snapshot(当有append、compact同时发生时出现会生成两个),若检查点间隔内未写入数据,只会创建compact快照
- EARLIEST 最早的快照编号,一开始是-8
- LATEST 最新的快照编号
- manifest 目录:记录了每次经 checkpoint 触发而提交的数据文件变更,每个文件记录了产生了哪些 sst 文件、删除了哪些 sst 文件,以及每个 sst 文件所包含记录的主键范围、每个字段的 min/max/null count 等统计信息
- schema 目录:表结构文件
- 数据文件:按分区、存储桶分到对应目录,每个桶目录都包含一个LSM树和变更日志文件,每个 sst 文件则包含了按主键排好序的、列存格式的记录。对于 Level 0 的文件,会异步地触发 compact 合并线程来消除主键范围重叠带来的读端 merge 开销
- LSM树将sst文件组织成多个SortedRun,SortedRun与文件是一对多的关系,对于主键表,不同的SortedRun可能具有重叠的主键范围或相同的主键,查询LSM树时必须MOR,根据指定的合并引擎和每条记录的时间戳来合并所有SortedRun
- 当write-buffer-size耗尽时会将数据flush生成文件
Catalog
file
CREATE CATALOG my_catalog WITH ( 'type' = 'paimon', 'warehouse' = 'hdfs:///path/to/warehouse' ); USE CATALOG my_catalog;
hive
表
分类
- 管理表,paimon catalog下建的表,删除会删所有数据
- 外部表,非paimon catalog下建的表,属性要有'connector'='paimon', 'path'='xxx',可以直接读写外部的paimon数据,删除后只是show tables无,未删元数据、数据
- 临时表,仅flink支持,在paimon catalog下建的外部表,会话级的,会话退出后自动失效。create tempoary table t1,with属性与外部表一样
- 系统表,表名$系统表名,如快照表$snapshots、schema表$schemas、选项表$options、审计日志表$audit_log、文件表$files
有主键表
如果定义具有主键的表,则可以在表中插入、更新或删除记录。
无主键表
1、append表
若无主键则默认是append表。流式传输只能向表中插入一条完整的记录。这种类型的表适合不需要流式更新的用例。默认是zstd压缩
CREATE TABLE my_table ( product_id BIGINT, price DOUBLE, sales BIGINT ) WITH ( 'file.compression' = 'zstd' );
流式读取:
- 默认情况下,流式读取在第一次启动时会对表生成最新的快照,并继续读取最新的增量记录。
- 可以指定scan.mode、scan.snapshot-id、scan.timestamp-millis或scan.file-creation-time-millis仅流式读取增量。
OLAP查询
- 按顺序跳过数据,Paimon 默认记录清单文件中每个字段的最大值和最小值,在查询的时候,根据WHERE查询的条件,根据manifest中的统计信息做文件过滤
- 按文件索引跳过数据
CREATE TABLE <PAIMON_TABLE> (<COLUMN> <COLUMN_TYPE> , ...) WITH ( 'file-index.bloom-filter.columns' = 'c1,c2', 'file-index.bloom-filter.c1.items' = '200' );
2、bucketed append表
必须指定bucket-key
CREATE TABLE my_table ( product_id BIGINT, price DOUBLE, sales BIGINT ) WITH ( 'bucket' = '8', 'bucket-key' = 'product_id' );
系统表
snapshots 快照表
manifests 清单表
audit_log 审计日志表,包含表的变更统计
schemas 表结构
partitions 分区
files 文件表
tags 标签表
ro Read-optimized表,当需要非常高的读性能且能接受较旧的数据,使用该表,读时不需要MOR,对于有主键表只读取最新的full compaction,对于无主键表,无变化
consumers 消费者表
aggregation_fields 查表的聚合字段情况
全局系统表
- sys.all_table_options
- sys.catalog_options
- sys.source_table_lineage
- sys.sink_table_lineage
生态
重要特性
Predicate
读取时会filter过滤掉不需要读的内容
- 读取 manifest:根据文件的 min/max、分区,执行分区和字段的 predicate,淘汰多余的文件
- 读取文件 footer:根据 chunk 的 min/max,过滤不需要读取的 chunk
- 读取剩下的文件以及其中的 chunks
写入
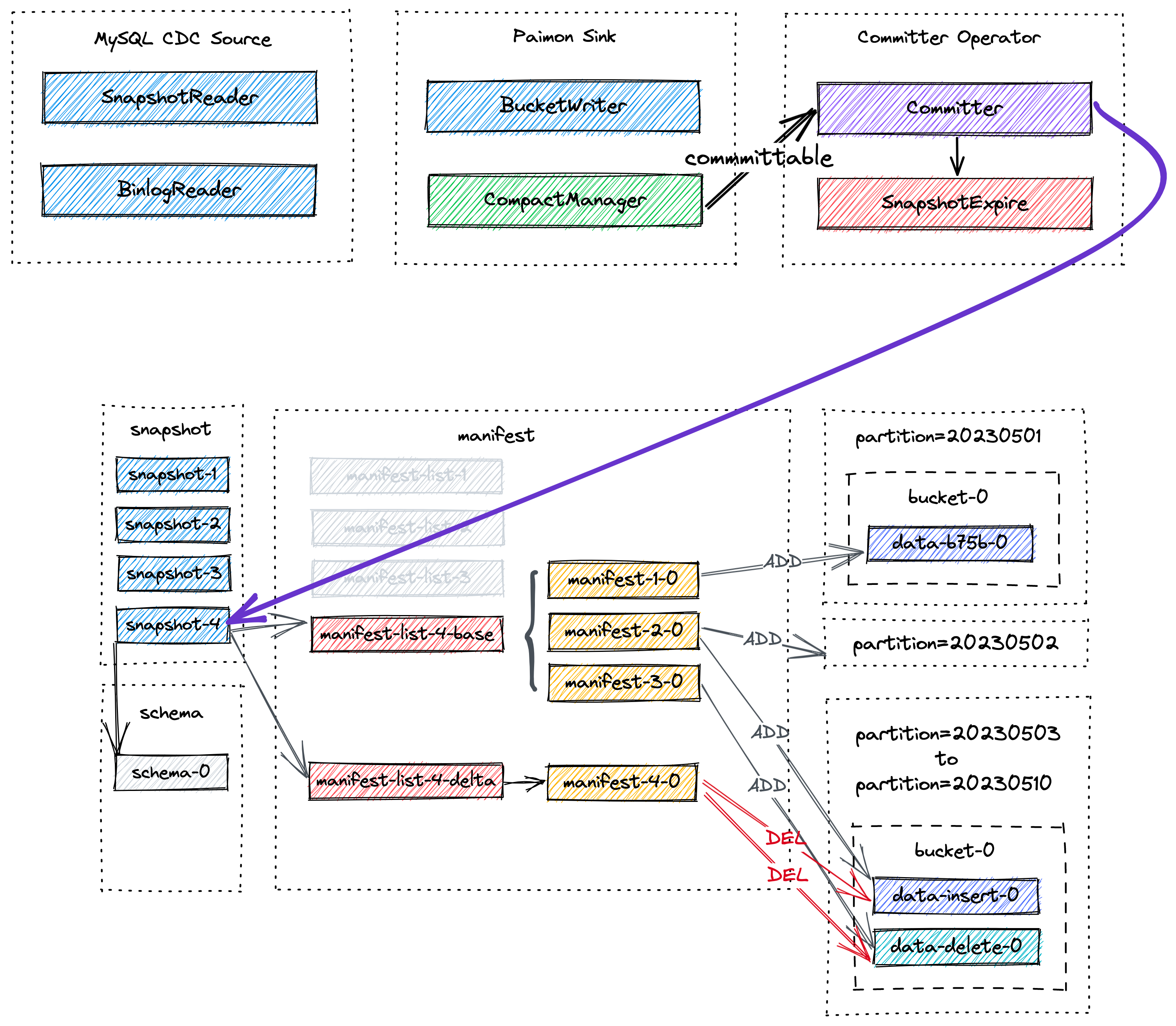
Paimon Sink 首先在内存堆的 LSM 树中缓冲新记录,并在内存缓冲区满时将它们刷新到磁盘。注意,写入的每个数据文件都是一个SortedRun。此时,不会创建清单文件和快照。就在 Flink 检查点发生之前,Paimon Sink 将flush所有遗留的缓冲记录,并向下游发送committable,该消息在检查点期间由Committer算子读取和提交。
在检查点期间,Committer算子将创建一个新的快照并将其与清单列表关联,以便快照 包含有关表中所有数据文件的信息。
稍后可能会进行异步Compaction,由 CompactManager 生成的committable包含以前文件和合并文件的信息,以便Committer算子可以构造相应的清单条目。此时Committer算子可能在 Flink 检查点期间生成两个快照,一个用于写入(Append 类型的快照) ,另一个用于压缩(Compend 类型的快照)。如果在检查点间隔期间没有写入任何数据文件,则将只创建 Compact 类型的快照。Committer算子将检查快照过期情况,并对标记的数据文件执行物理删除。
批查
RESET 'execution.checkpointing.interval';
SET 'execution.runtime-mode'='batch';
TimeTraveling
-- read the snapshot with id 1L SELECT * FROM t /*+ OPTIONS('scan.snapshot-id' = '1') */; -- read the snapshot from specified timestamp in unix milliseconds SELECT * FROM t /*+ OPTIONS('scan.timestamp-millis' = '1678883047356') */; -- read tag 'my-tag' SELECT * FROM t /*+ OPTIONS('scan.tag-name' = 'my-tag') */; -- read the snapshot from watermark, will match the first snapshot after the watermark SELECT * FROM t /*+ OPTIONS('scan.watermark' = '1678883047356') */;
批增量查
读快照a到b间的增量变更,不包含起始快照a本身
-- incremental between snapshot ids SELECT * FROM t /*+ OPTIONS('incremental-between' = '12,20') */; -- incremental between snapshot time mills SELECT * FROM t /*+ OPTIONS('incremental-between-timestamp' = '1692169000000,1692169900000') */; --批模式下,-D数据不会展示,如果想查看-D数据,可以看审计系统表 SELECT * FROM t$audit_log /*+ OPTIONS('incremental-between' = '12,20') */;
流查
SET 'execution.checkpointing.interval'='30s';
SET 'execution.runtime-mode'='streaming';
TimeTraveling
-- read changes from snapshot id 1L 快照1之后的增量,且包含在快照1阶段的变更 SELECT * FROM t /*+ OPTIONS('scan.snapshot-id' = '1') */; -- read changes from snapshot specified timestamp SELECT * FROM t /*+ OPTIONS('scan.timestamp-millis' = '1678883047356') */; -- read snapshot id 1L upon first startup, and continue to read the changes SELECT * FROM t /*+ OPTIONS('scan.mode'='from-snapshot-full','scan.snapshot-id' = '1') */;
consumer-id
- 类似于kafka消费者组,会自动记录消费offset,重启后会自动从上次消费点位开始,不需要手动指定savepoint。可指定'consumer.mode'='at-least-once',默认是exactly-once,
- 类似于JVM GC,判断快照是否过期时会查看该表的所有消费者,若还有消费者依赖该快照则不会因过期而删除。指定consumer.expiration-time参数
--直接查出当前的全量数据,是全+I的 SELECT * FROM pk1 /*+ OPTIONS('consumer-id' = 'myid') */; insert into pk1 values (9,'f'); --只会显示+I 9,因为是从上一次消费位点开始 SELECT * FROM pk1 /*+ OPTIONS('consumer-id' = 'myid') */;
流读overwrite changelog
select * from pk_part2 /*+OPTIONS('streaming-read-overwrite'='true')*/;
查询过滤优化
增强性能支持如下过滤
- =
- <
- <=
- >
- >=
- IN (...)
- LIKE 'abc%'
- IS NULL
过滤条件的字段应该在主键前缀范围内,顺序也应该一致,若有多个要用AND联接
Lookup Join维表查询
支持有主键的非分区表作为维表,维护一个本地的rocksdb cache并实时拉取最新的变更,且会下推谓词
SELECT o.order_id, o.total, c.country, c.zip FROM Orders AS o JOIN customers /*+ OPTIONS('lookup.cache-rows'='20000') */ FOR SYSTEM_TIME AS OF o.proc_time AS c ON o.customer_id = c.id;
独立的compaction作业
--调用procedure CALL sys.compact('default.t', '', '', '', 'sink.parallelism=4') --调用action <FLINK_HOME>/bin/flink run \ /path/to/paimon-flink-action-0.9-SNAPSHOT.jar \ compact \ --warehouse s3:///path/to/warehouse \ --database test_db \ --table test_table \ --partition dt=20221126,hh=08 \ --partition dt=20221127,hh=09 \ --table_conf sink.parallelism=10 \ --catalog_conf s3.endpoint=https://****.com \ --catalog_conf s3.access-key=***** \ --catalog_conf s3.secret-key=*****
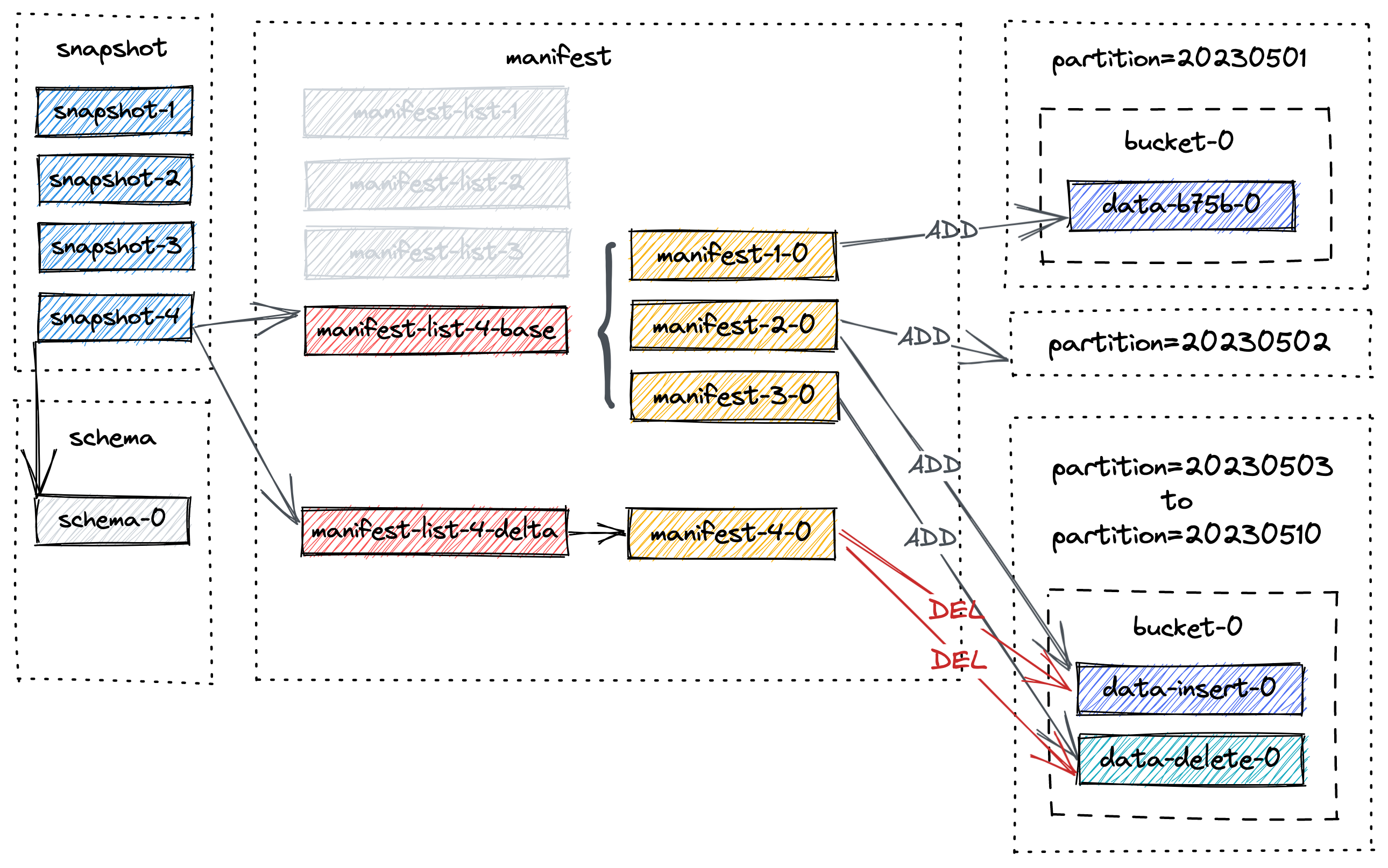
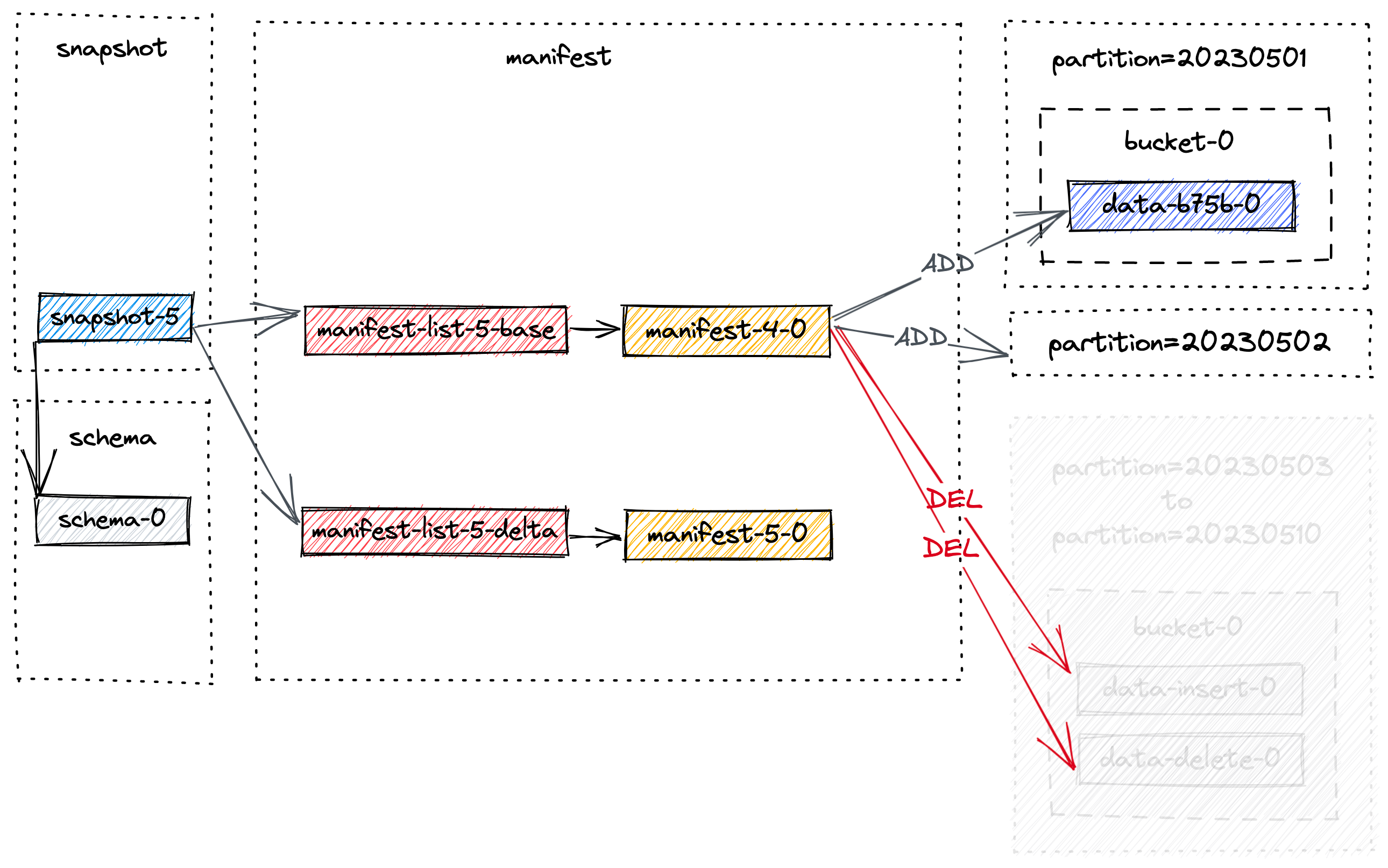
过期快照
首先删除所有标记的数据文件,并记录所有发生变更的桶。
然后删除任何变更日志文件和相关的清单。
最后,它删除快照本身并更新EARLIEST文件。
缩放桶
一、不停任务
alter table t1 set ('bucket'='4'); --仅修改元数据,不会自动重分布数据
set 'execution.runtime-mode'='batch';
insert overwrite t1 partition (dt='2024-05-27') select ...; --重分布数据,若直接insert into会报TableException
二、停任务
flink stop --savePointPath xxx $JOB_ID
alter table t1 set ('bucket'='4'); --仅修改元数据,不会自动重分布数据
set 'execution.runtime-mode'='batch';
insert overwrite t1 partition (dt='2024-05-27') select ...; --重分布数据,若直接insert into会报TableException
--overwrite任务完成后,用流模式重启任务
SET 'execution.runtime-mode' = 'streaming';
SET 'execution.savepoint.path' = ;
insert into t1 select ...;
CDC集成
支持模式演化,修改的列会实时同步到paimon表且不需要重启作业。
- mysql一张或多张表->一个paimon表
- mysql整个数据库->一个paimon库
- DataSteram api表->一个paimon表
- kafka一个topic对应的一张或多张表->一个paimon表
- kafka整个数据库->一个paimon库
mysql同步单表或多表
多表的字段会合并到一张paimon表,同名字段不重复增加
--partition_keys pt 指定分区列
--primary_keys pt,uid 指定主键
--mysql_conf database-name='source_db.+' 多shards同步
--catalog_conf paimon的catalog配置
<FLINK_HOME>/bin/flink run \ /path/to/paimon-flink-action-0.9-SNAPSHOT.jar \ mysql_sync_table \ --warehouse hdfs:///path/to/warehouse \ --database test_db \ --table test_table \ --partition_keys pt \ --primary_keys pt,uid \ --computed_column '_year=year(age)' \ --mysql_conf hostname=127.0.0.1 \ --mysql_conf username=root \ --mysql_conf password=123456 \ --mysql_conf database-name='source_db' \ --mysql_conf table-name='source_table1|source_table2' \ --catalog_conf metastore=hive \ --catalog_conf uri=thrift://hive-metastore:9083 \ --table_conf bucket=4 \ --table_conf changelog-producer=input \ --table_conf sink.parallelism=4
mysql同步整库
--including_tables test|paimon.*
--excluding_tables
--table_prefix
--table_suffix
--mode 默认是divided,每张表会生成单独的sink,若同步新表需要重启指定--fromSavepoint。可以指定combined,所有表共用一个sink,新表会自动同步无需重启
<FLINK_HOME>/bin/flink run \ /path/to/paimon-flink-action-0.9-SNAPSHOT.jar \ mysql_sync_database \ --warehouse hdfs:///path/to/warehouse \ --database test_db \ --mysql_conf hostname=127.0.0.1 \ --mysql_conf username=root \ --mysql_conf password=123456 \ --mysql_conf database-name=source_db \ --catalog_conf metastore=hive \ --catalog_conf uri=thrift://hive-metastore:9083 \ --table_conf bucket=4 \ --table_conf changelog-producer=input \ --table_conf sink.parallelism=4
kafka一个topic对应的一张或多张表同步
支持canal-cdc、debezium-cdc、maxwell-cdc、ogg-cdc,schema从topic的cdc消息中获取
--computed_column 'part=date_format(create_time,yyyy-MM-dd)'
<FLINK_HOME>/bin/flink run \ /path/to/paimon-flink-action-0.9-SNAPSHOT.jar \ kafka_sync_table \ --warehouse hdfs:///path/to/warehouse \ --database test_db \ --table test_table \ --partition_keys pt \ --primary_keys pt,uid \ --computed_column '_year=year(age)' \ --kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \ --kafka_conf topic=order \ --kafka_conf properties.group.id=123456 \ --kafka_conf value.format=canal-json \ --catalog_conf metastore=hive \ --catalog_conf uri=thrift://hive-metastore:9083 \ --table_conf bucket=4 \ --table_conf changelog-producer=input \ --table_conf sink.parallelism=4
kafka整库同步:一个或多个topic同步到一个paimon库
若一个topic中有不同的schema会自动拆分到多个表
<FLINK_HOME>/bin/flink run \ /path/to/paimon-flink-action-0.9-SNAPSHOT.jar \ kafka_sync_database \ --warehouse hdfs:///path/to/warehouse \ --database test_db \ --kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \ --kafka_conf topic=order\;logistic_order\;user \ --kafka_conf properties.group.id=123456 \ --kafka_conf value.format=canal-json \ --catalog_conf metastore=hive \ --catalog_conf uri=thrift://hive-metastore:9083 \ --table_conf bucket=4 \ --table_conf changelog-producer=input \ --table_conf sink.parallelism=4
核心属性
|
bucket
|
-1
|
-1是动态桶模式,大于0的数是固定桶数
|
|
|
bucket-key
|
数据根据桶key这些字段的hash值进行分发,若有多个用逗号分隔,若不指定,有主键则默认用主键字段,无主键则使用所有字段
|
||
|
primary-key
|
|||
|
partition
|
分区键必须是主键的子集
|
分区
|
|
|
partition.expiration-time
|
Paimon定期检查分区的状态,并根据时间删除过期的分区
|
||
|
partition.expiration-check-interval
|
1 h
|
检查分区过期的间隔,比较分区时间与当前时间
|
|
|
partition.timestamp-formatter
|
|||
|
partition.timestamp-pattern
|
|||
|
file.format
|
|||
|
auto-create
|
false
|
若数据目录不存在,是否自动创建
|
|
|
sequence.field
|
为主键表生成序列号的字段,序列号确定哪些数据是最新的
|
||
|
snapshot.time-retained
|
1 h
|
已完成快照的最长时间保留,对于过期的snapshot,会无法做到其之后的增量读取
|
|
|
snapshot.num-retained.min
|
10
|
要保留的已完成快照的最小数量
|
|
|
snapshot.num-retained.max
|
Integer.MAX_VALUE
|
要保留的已完成快照的最大数量
|
|
|
write-buffer-size
|
256 mb
|
在转换为磁盘sst文件前的内存使用量,增大可增加写入性能
|
写缓冲区
批量模式'execution.runtime-mode'='batch'也能提高写入性能
|
|
write-buffer-spillable
|
是否写缓冲区可溢出到磁盘,若使用对象存储则默认开启
|
||
|
write-buffer-spill.max-disk-size
|
infinite
|
写缓冲区溢写的最大磁盘占用容量
|
|
|
sink.parallelism
|
writer并行度,为优化写入性能应该最好等于bucket数
|
写并行度
|
|
|
num-sorted-run.compaction-trigger
|
5
|
触发compaction的sorted run数量,包括0级文件(一个文件一个sorted run)和高级runs(一个level一个sorted run)
|
合理通过SortedRun数量控制compact次数,权衡写入、读取性能和资源消耗
|
|
num-sorted-run.stop-trigger
|
触发writer停止写入的sorted run数量,会极大影响写入性能,默认是'num-sorted-run.compaction-trigger'+3
|
||
|
write-only
|
false
|
若为true则在write阶段忽略快照过期和compaction,与独立的compact action结合使用
|
解耦write和compact
|
|
write-manifest-cache
|
0 bytes
|
减少重启时与文件系统的交互,提高manifest加载初始化速度
|
影响重启时加载清单文件的速度
|
|
scan.manifest.parallelism
|
扫描清单文件的并行性,默认值为 CPU 处理器的大小。注意: 放大此参数将在扫描清单文件时增加内存使用。当扫描时遇到内存不足异常时,我们可以考虑缩小它
|
||
|
scan.mode
|
default
|
|
|
|
read.batch-size
|
1024
|
对orc、parquet的批量读大小,若有的行太大可适当减小
|
|
|
full-compaction.delta-commits
|
增量commit多少次后执行full compaction
注意对主键表、append-only表都有效
|
对于主键表,使用的是MOR来读
若想查得足够快但不需要多新的数据,指定本配置后,再配置scan.mode为compacted-full
|
|
|
compaction.max.file-num
|
50
|
对append-only无主键表,触发compaction的最大小文件数量
|
|
|
compaction.min.file-num
|
5
|
对append-only无主键表,若未达到此值则都不触发compaction,防止对几乎完整的文件compact,防止过于频繁的compact
|
|
|
deletion-vectors.enabled
|
开启删除向量特性可以在稍微影响写入性能的情况下,不合并文件即可获取最新的数据,可有效提高读取性能
|
||
|
continuous.discovery-interval
|
10 s
|
持续读的发现间隔
|
|
|
streaming-read-overwrite
|
false
|
是否在流模式读insert overwrite产生的变更,不能在changelog-producer为full-compaction或lookup使用
|
|
|
scan.split-enumerator.batch-size
|
10
|
在 StaticFileStoreSplitEnumerator 中,为了避免超过'akka.framesize'限制,应该为每个子任务一次分配多少个split
|
1、changelog-producer
- 'full-compaction', 对比两次full compaction后的结果生成完整的changelog,频率取决于full compaction的生成间隔,成本低
- 'changelog-producer.compaction-interval' = '' 在此时间区间内会至少运行一次full compaction,推荐3-10min时延
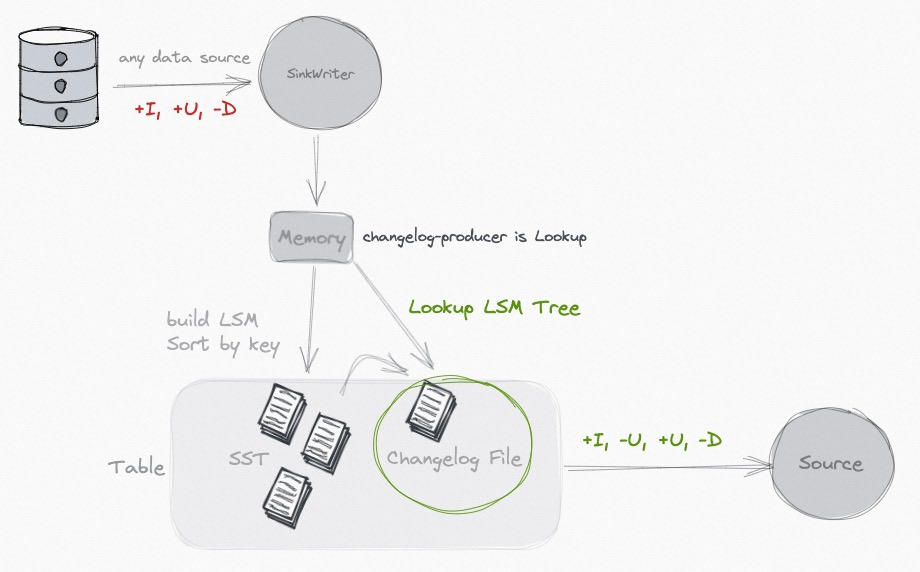
- lookup 在提交数据写入前通过lookup LSM tree生成changelog文件,推荐1-3min时延,成本高
- lookup.cache-file-retention
- lookup.cache-max-disk-size
- lookup.cache-max-memory-size
- 'input' 会在存储层LSM文件之外直接持久化cdc流成changelog文件
- 'none' 增加一个normalize单并行度高消耗算子,不会生成changelog文件

2、merge-engine
(1)deduplicate 默认
去重且保留主键的最新数据
(2)partial-update支持部分更新
双流join存储所有state成本过高但结果准确、维表join成本低但无法应对维表更新的数据,通过在存储层面支持Partial Update解决join问题
指定sequence.field无法解决多流部分更新的乱序问题,因为会互相影响,因此引入sequence-group机制,每个流都可以定义自己的sequence-group,且是真正的部分更新,指定的sequence-group字段的值为空或更小,将不更新对应的字段
'fields.g_1.sequence-group'='a,b' 若g_1为空或更小,则不更新a b两个字段
(3)aggregation
对除键外的所有列的数据的最近结果与新来的数据一一聚合,注意所有非主键列都要指定fields..aggregate-function表属性
CREATE TABLE MyTable ( product_id BIGINT, price DOUBLE, sales BIGINT, PRIMARY KEY (product_id) NOT ENFORCED ) WITH ( 'merge-engine' = 'aggregation', 'fields.price.aggregate-function' = 'max', 'fields.sales.aggregate-function' = 'sum' );
(4)first-row
保留相同键的第一行数据,只会产生append cdc流。
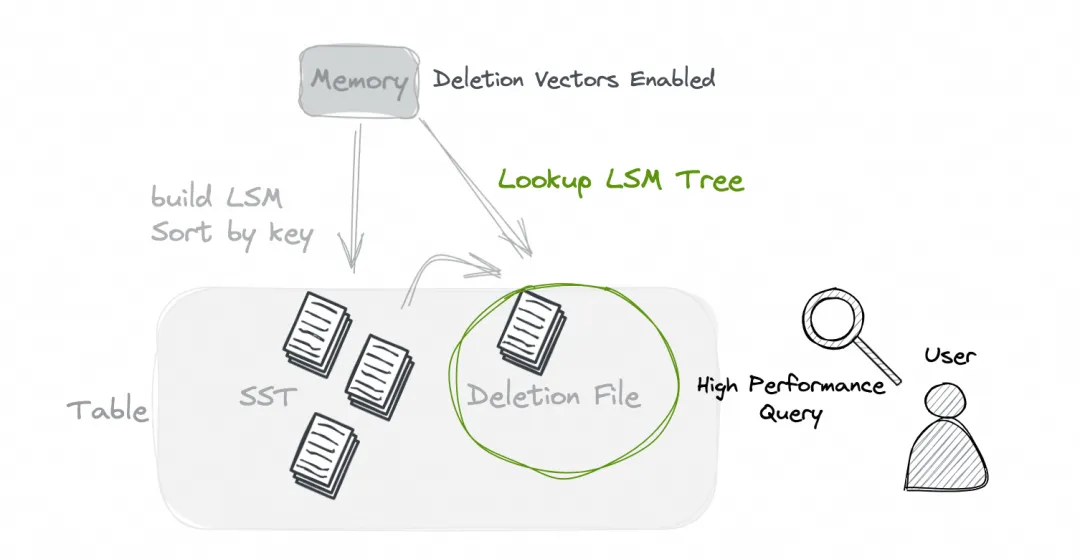
7、Deletion vectors
设计是为了兼顾写入、读取的效率。该模式下,写入时会引入额外的开销(查找LSM Tree并生成对应的Deletion File),但读取时可以直接使用有删除向量的数据找回数据,避免了不同文件之间额外的merge开销。总体来说,在这种模式下,我们可以在不损失太多写入性能的情况下,获得巨大的读取性能提升。
'deletion-vectors.enabled' = 'true'
安装
1、打包成fat包,拷到flink/lib目录
mvn clean package -DskipTests
2、配置HADOOP_CLASSPATH或拷https://flink.apache.org/downloads.html里的预编译hadoop jar包到flink/lib
3、修改conf/config.yaml,numberOfTaskSlots: 8,比1大的值
执行
set 'execution.runtime-mode'='batch'; //批模式,跑得更快些 create catalog paimon1 with ('type'='paimon','warehouse'='file:///home/rick/data/paimon1'); use catalog paimon1; CREATE TABLE my_table ( product_id BIGINT, price DOUBLE, sales BIGINT ) WITH ( 'file.compression' = 'zstd' ); CREATE TABLE MyTable ( user_id BIGINT, item_id BIGINT, behavior STRING, dt STRING, PRIMARY KEY (dt, user_id) NOT ENFORCED ) PARTITIONED BY (dt) WITH ( 'bucket' = '4', 'file.format' = 'parquet' ); insert into MyTable values (1,2,'a','part1'); insert into MyTable partition (dt='part2') values (2,3,'a'); set 'execution.checkpointing.interval'='20s'; set 'execution.runtime-mode'='streaming'; --kafka CREATE TABLE t1 (id int,name string) WITH ( 'log.system' = 'kafka', 'kafka.bootstrap.servers' = 'localhost:9092', 'kafka.topic' = 'topic1' );