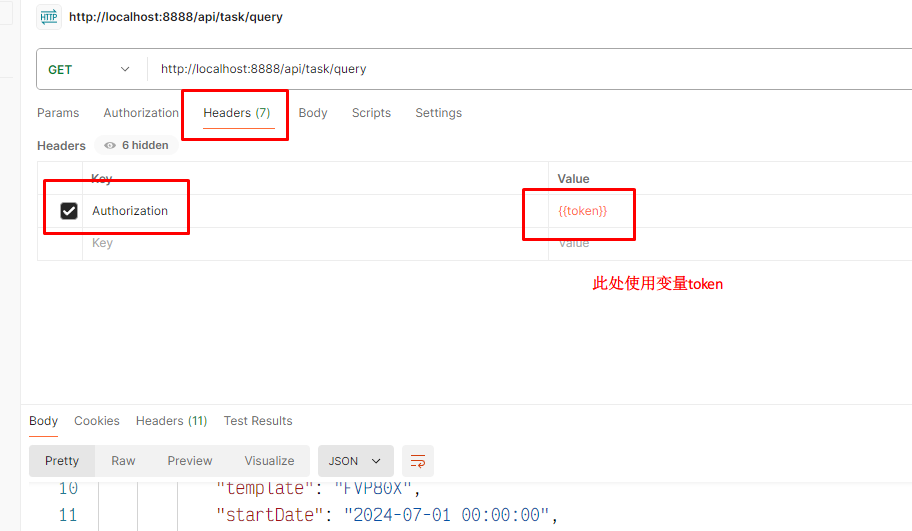
前言
本文介绍卷积神经网络的入门案例,通过搭建和训练一个模型,来对几种常见的花朵进行识别分类;使用到TF的花朵数据集,它包含5类,即:“雏菊”,“蒲公英”,“玫瑰”,“向日葵”,“郁金香”;共 3670 张彩色图片;通过搭建和训练卷积神经网络模型,对图像进行分类,能识别出图像是“蒲公英”,或“玫瑰”,还是其它。

本篇文章主要的意义是带大家熟悉卷积神经网络的开发流程,包括数据集处理、搭建模型、训练模型、使用模型等;更重要的是解在训练模型时遇到“过拟合”,如何解决这个问题,从而得到“泛化”更好的模型。
思路流程
- 导入数据集
- 探索集数据,并进行数据预处理
- 构建模型(搭建神经网络结构、编译模型)
- 训练模型(把数据输入模型、评估准确性、作出预测、验证预测)
- 使用训练好的模型
- 优化模型、重新构建模型、训练模型、使用模型
目录
- 导入数据集
- 探索集数据,并进行数据预处理
- 构建模型
- 训练模型
- 使用模型
- 优化模型、重新构建模型、训练模型、使用模型(过拟合、数据增强、正则化、重新编译和训练模型、预测新数据)
一、导入数据集
使用到TF的花朵数据集,它包含5类,即:“雏菊”,“蒲公英”,“玫瑰”,“向日葵”,“郁金香”;共 3670 张彩色图片;数据集包含5个子目录,每个子目录种存放一个类别的花朵图片。
点击查看代码
# 下载数据集
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)# 查看数据集图片的总数量
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)二、探索集数据,并进行数据预处理
查看一张郁金香的图片:
点击查看代码
# 查看郁金香tulips目录下的第1张图片;
tulips = list(data_dir.glob('tulips/*'))
PIL.Image.open(str(tulips[0]))
加载数据集的图片,使用keras.preprocessing从磁盘上加载这些图像。
点击查看代码
# 定义加载图片的一些参数,包括:批量大小、图像高度、图像宽度
batch_size = 32
img_height = 180
img_width = 180# 将80%的图像用于训练
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)# 将20%的图像用于验证
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)# 打印数据集中花朵的类别名称,字母顺序对应于目录名称
class_names = train_ds.class_names
print(class_names)
查看一下训练数据集中的9张图像
点击查看代码
# 查看一下训练数据集中的9张图像
import matplotlib.pyplot as pltplt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):for i in range(9):ax = plt.subplot(3, 3, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")
图像形状
传递这些数据集来训练模型model.fit,可以手动遍历数据集并检索成批图像:
点击查看代码
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
能看到输出:(32, 180, 180, 3) (32,)
image_batch是图片形状的张量(32, 180, 180, 3)。32是指批量大小;180,180分别表示图像的高度、宽度,3是颜色通道RGB。32张图片组成一个批次。
label_batch是形状的张量(32,),对应32张图片的标签。
数据集预处理
下面进行数据集预处理,将像素的值标准化至0到1的区间内:
点击查看代码
# 将像素的值标准化至0到1的区间内。
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
为什么是除以255呢?由于图片的像素范围是0255,我们把它变成01的范围,于是每张图像(训练集、测试集)都除以255。
标准化数据
点击查看代码
# 调用map将其应用于数据集:
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixels values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
三、构建模型
常见卷积神经网络(CNN),主要由几个 卷积层Conv2D 和 池化层MaxPooling2D 层组成。卷积层与池化层的叠加实现对输入数据的特征提取,最后连接全连接层实现分类。
*特征提取——卷积层与池化层
*实现分类——全连接层
CNN 的输入是张量 (Tensor) 形式的 (image_height, image_width, color_channels),包含了图像高度、宽度及颜色信息。通常图像使用 RGB 色彩模式,color_channels 为 (R,G,B) 分别对应 RGB 的三个颜色通道,即:image_height 和 image_width 根据图像的像素高度、宽度决定color_channels是3,对应RGB的3通道。
花朵数据集中的图片,形状是 (180, 180, 3),我们可以在声明第一层时将形状赋值给参数 input_shape 。
点击查看代码
num_classes = 5model = Sequential([layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(32, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(64, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(num_classes)
])
该模型由三个卷积块组成,每个卷积块中包括2D卷积层+最大池化层。最后有一个全连接层,有128个单元,可以通过relu激活功能激活该层。
编译模型
点击查看代码
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
查看一下网络模型:tf.keras.utils.plot_model(model) ,或者用这样方式看看:model.summary()

四、训练模型
这里我们输入准备好的训练集数据(包括图像、对应的标签),测试集的数据(包括图像、对应的标签),模型一共训练10次。
点击查看代码
epochs=10
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
下图是训练过程的截图:

通常loss越小越好,对了解释下什么是loss;简单来说是 模型预测值 和 真实值 的相差的值,反映模型预测的结果和真实值的相差程度;通常准确度accuracy 越高,模型效果越好。
评估模型
在训练和验证集上创建损失和准确性图。
点击查看代码
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

从图中可以看出,训练精度和验证精度相差很大,模型仅在验证集上获得了约60%的精度。
训练精度随时间增长,而验证精度在训练过程中停滞在60%左右。训练和验证准确性之间的准确性差异很明显,这是过拟合的标志。
可能过拟合出现的原因 :当训练示例数量很少时,像这次的只有3000多张图片,该模型有时会从训练示例中的噪音或不必要的细节中学习,从而模型在新示例上的性能产生负面影响。
五、使用模型
通常使用 model.predict( ) 函数进行预测。
六、优化模型、重新构建模型、训练模型、使用模型
这里的优化模型,主要是针对模型出现“过拟合”的问题。
过拟合
模型将过度拟合训练数据,在训练集上达到较高的准确性,但在未见的数据(测试集)上得到比较低的准确性;模型的“泛化能力”不足。
我们训练模型的主要目的,也是希望模型在未见数据的预测上能有较高的准确性;解决过拟合问题是比较重要的。
解决过拟合的思路
- 使用更完整的训练数据。(最好的解决方案)
- 使用正则化之类的技术。
- 简化神经网络结构。
使用更完整的训练数据,数据集应涵盖模型应处理的所有输入范围。仅当涉及新的有趣案例时,其他数据才有用。
比如:在训练集的花朵图片都是近距离拍摄的,测试集的花朵有部分是远距离拍摄,训练出来的模型,自然在测试集的准确度不高了;如果一开始在训练集也包含部分远距离的花朵图片,那么模型在测试集时准确度会较高,基本和训练集的准确度接近。
使用正规化等技术,这些限制了模型可以存储的信息的数量和类型。如果一个网络只能记住少量的模式,优化过程将迫使它专注于最突出的模式,这些模式更有可能很好地概括。
简化神经网络结构,如果训练集比较小,网络结构又十分复杂,使得模型过度拟合训练数据,这时需要考虑简化模型了。减少一些神经元数量,或减少一些网络层。
结合上面的例子,使用数据增强和正则化技术,来优化网络。
数据增强
通过对已有的训练集图片 随机转换(反转、旋转、缩放等),来生成其它训练数据。这有助于将模型暴露在数据的更多方面,并更好地概括。
这里使用 tf.layers.experimental.preprocessing 层实现数据增强。
点击查看代码
data_augmentation = keras.Sequential([layers.experimental.preprocessing.RandomFlip("horizontal", input_shape=(img_height, img_width,3)),layers.experimental.preprocessing.RandomRotation(0.1),layers.experimental.preprocessing.RandomZoom(0.1),]
)
RandomFlip("horizontal", input_shape=(img_height, img_width, 3)) 指定输入图片,并对图片进行随机水平反转
RandomRotation(0.1) 对图片进行随机旋转
RandomZoom(0.1) 对图片进行随机缩放
通过将数据增强应用到同一图像中几次来可视化几个增强示例的外观:

点击查看代码
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):for i in range(9):augmented_images = data_augmentation(images)ax = plt.subplot(3, 3, i + 1)plt.imshow(augmented_images[0].numpy().astype("uint8"))plt.axis("off")
正则化
正则化的方法有多种,这里使用 Dropout 应用到网络层中,它会随机将一部分神经元的激活值停止工作,在训练过程中从该层中暂时退出,从而不对输出产生影响;后续训练先恢复之前被停止工作的神经元,再随机将一部分神经元停止工作,再训练。
这样使模型不会太依赖某些局部的特征,泛化性更强。a图全连接结构的模型。b图是在a网络结构基础上,使用 Dropout后,随机将一部分神经元的暂时停止工作。

训练流程:
首先随机(临时)删除网络中一些的隐藏层神经元(退出此次训练),输入输出神经元保存不变。
然后把输入x通过修改后的网络前向传播,得到的损失结果通过修改后的网络反向传播;一批训练样本执行完这个过程后,在没有被删除的神经元上按照梯度下降法更新对应的参数(w, b)。
最后重复1、2步过程。恢复被删掉的神经元,此时被删除的神经元保持原样,而没有被删除的神经元已经更新相关参数。
参考:Dropout(正则化)
Dropout 以一小部分数字作为其输入值,形式为 0.1、0.2、0.4 等。使得此层的10%、20%、40%的神经元被暂时停止工作。
下面使用:layers.Dropout(0.2)
点击查看代码
model = Sequential([data_augmentation,layers.experimental.preprocessing.Rescaling(1./255),layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(32, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(64, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Dropout(0.2),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(num_classes)
])
重新编译和训练模型
点击查看代码
# 编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
# 查看网络结构
model.summary()
# 训练模型
epochs = 15
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
在训练和验证集上查看损失值和准确性:
点击查看代码
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

对比之前模型的效果,差别还是挺大的;使用数据增强、正则化后的模型,降低了过拟合的影响;验证集的损失和模型准确度,与训练集更接近了。
预测新数据
点击查看代码
# 预测新数据 下载一张新图片,来预测它属于什么类型花朵
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)img = keras.preprocessing.image.load_img(sunflower_path, target_size=(img_height, img_width)
)
img_array = keras.preprocessing.image.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batchpredictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])print("该图像最有可能属于{},置信度为 {:.2f}%".format(class_names[np.argmax(score)], 100 * np.max(score))
)
该图像最有可能属于sunflowers,置信度为 97.38%
完整代码
点击查看代码
'''
环境:Tensorflow2 Python3.x
'''import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tffrom tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential# 下载数据集
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)# 查看数据集图片的总数量
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)# 查看郁金香tulips目录下的第1张图片;
tulips = list(data_dir.glob('tulips/*'))
PIL.Image.open(str(tulips[0]))# 定义加载图片的一些参数,包括:批量大小、图像高度、图像宽度
batch_size = 32
img_height = 180
img_width = 180# 将80%的图像用于训练
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)# 将20%的图像用于验证
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)# 打印数据集中花朵的类别名称,字母顺序对应于目录名称
class_names = train_ds.class_names
print(class_names)# 将像素的值标准化至0到1的区间内。
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)# 调用map将其应用于数据集:
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixels values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))# 数据增强 通过对已有的训练集图片 随机转换(反转、旋转、缩放等),来生成其它训练数据
data_augmentation = keras.Sequential([layers.experimental.preprocessing.RandomFlip("horizontal", input_shape=(img_height, img_width,3)),layers.experimental.preprocessing.RandomRotation(0.1),layers.experimental.preprocessing.RandomZoom(0.1),]
)# 搭建 网络模型
model = Sequential([data_augmentation,layers.experimental.preprocessing.Rescaling(1./255),layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(32, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(64, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Dropout(0.2),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(num_classes)
])# 编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 查看网络结构
model.summary()# 训练模型
epochs = 15
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)# 在训练和验证集上查看损失值和准确性
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()原文链接:https://blog.csdn.net/qq_41204464/article/details/116567051