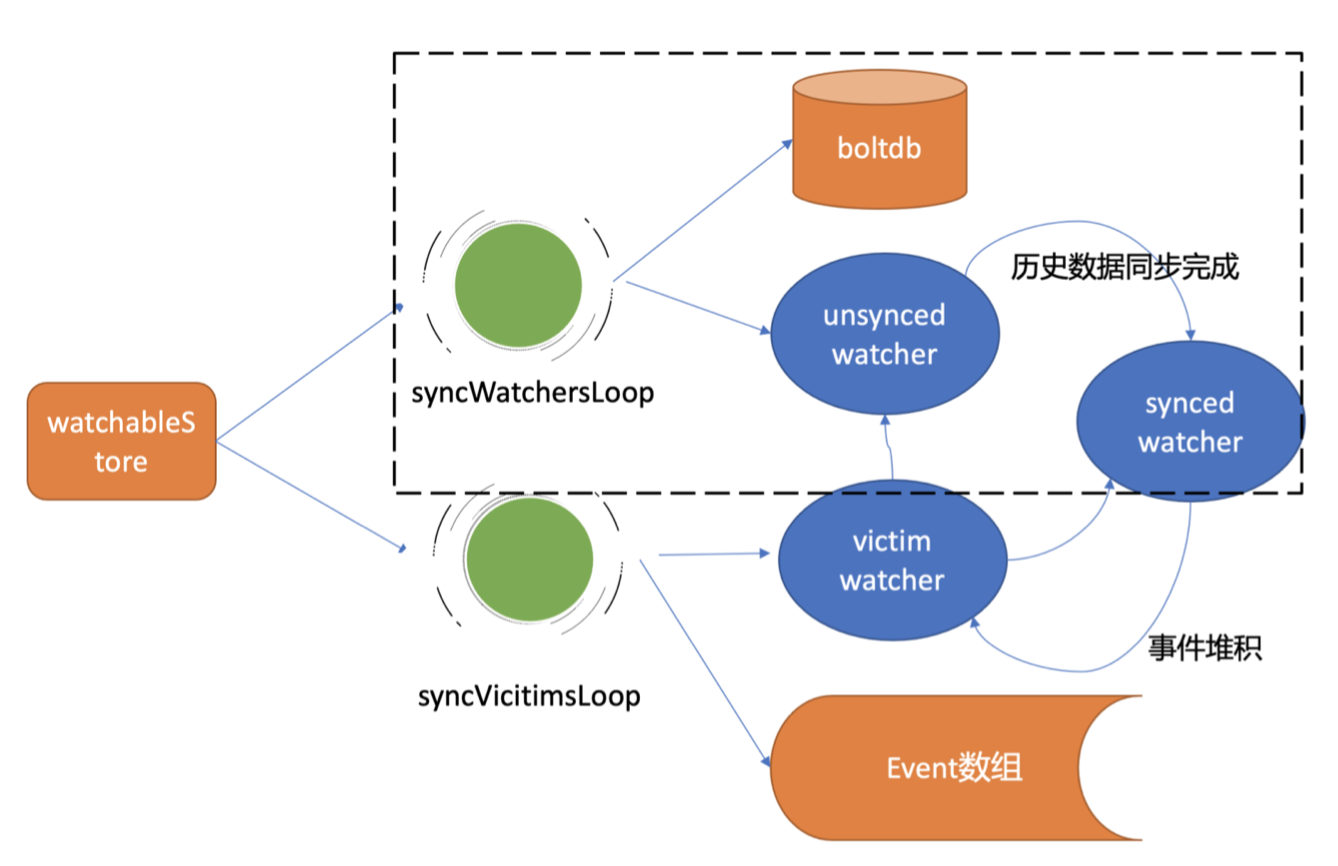
- 1. 点估计
- 1.1 最大似然估计
- 1.1.1 似然函数
- 1.1.2 最大似然估计
- 1.1.3 最大似然估计例子
- 1.2 矩估计(Method of Moments, MoM)
- 1.2.1 矩估计思想
- 1.3 估计量的评选标准
- 1.1 最大似然估计
- 2. 区间估计
- 2.1 置信区间
- 2.1.1 置信区间引入
- 2.1.2 置信区间
- 2.2 单个正态总体的均值和方差的置信区间
- 2.2.1 正态总体 $\sigma$ 已知时 $\mu$ 的置信区间
- 2.2.2 正态总体 $\sigma$ 未知时 $\mu$ 的置信区间
- 2.2.3 正态总体 $\mu$ 已知时 $\sigma^2$ 的置信区间
- 2.2.4 正态总体 $\mu$ 未知时 $\sigma^2$ 的置信区间
- 2.3 两个正态总体的均值差和方差比的置信区间
- 2.3.1 均值差 $\mu_1-\mu_2$ 的置信区间
- 2.3.2 方差比 $\sigma_12/\sigma_22$ 的置信区间
- 2.1 置信区间
- 参考资料
1. 点估计
设总体 $X$ 的分布形式已知,但含有未知参数 $\theta$;或总体的数字特征存在但未知,从总体 $X$ 中抽取样本 $X_1,X_2,\cdots,X_n$,相应的样本值为 $x_1,x_2,\cdots,x_n$。借助于样本给出未知参数一个具体数值的参数估计问题就是点估计问题。常用的点估计方法有矩估计和最大似然估计
1.1 最大似然估计
1.1.1 似然函数
假设 $Y=(x_1,x_2,\ldots,x_n)$ 是来自概率质量函数 $p_X(t|\theta)$($X$ 离散时)或来自概率密度函数 $f_X(t|\theta)$($X$ 连续时)的独立同分布的随机变量,$\theta$ 是一个参数(或参数向量)。我们将给定 $\theta$ 下的 $Y$ 的似然函数定义为参数为 $\theta$ 时 $Y$ 出现的概率:
-
当 $X$ 离散时,$L(Y|\theta) = \prod_{i=1}^np_X(x_i|\theta)$;
-
当 $X$ 连续时,$L(Y|\theta) = \prod_{i=1}^nf_X(x_i|\theta)$;
当 $X$ 连续时,由似然函数的定义可得,我们需要对每一个 $x_i$ 出现的概率进行连乘,由于连续随机变量在单点的概率为零,所以连续情况下用单点概率进行连乘得到的似然函数没有意义(总为零)。因为 $P(X=u)\approx f_X(u)$,所以在连续情况下可以用概率密度函数近似单点的概率,来使得连续情况下的似然函数有意义。
1.1.2 最大似然估计
接下来我们将正式定义一个参数下的最大似然估计。直观上来说,它就是使得观测数据出现的概率( $L(X|\theta)$ )最大的 $\theta$ 值。
假设 $Y=(x_1,x_2,\ldots,x_n)$ 是来自概率质量函数 $p_X(t|\theta)$($X$ 离散时)或来自概率密度函数 $f_X(t|\theta)$($X$ 连续时)的独立同分布的随机变量,$\theta$ 是一个参数(或参数向量)。我们将 $\theta$ 的最大似然估计量 $\widehat{\theta}_{MLE}$ 定义为使似然函数最大的参数。
$$
\widehat{\theta}{MLE} = \mathop{\text{arg max}}\limitsL(Y|\theta) =\mathop{\text{arg max}}\limits_{\theta}lnL(Y|\theta)
$$
因为要求似然函数的最大值,而求最大值一般涉及到求极值,求极值的方法中又需要求导并且似然函数是连乘的可用对数法简化求导的过程,而且对数函数是单调递增的,所以在取对数后得到的最大参数与未取对数前的最大参数相同
如上,我们有下述定义 $\widehat{\theta}{MLE} = \mathop{\text{arg max}}\limitsL(Y|\theta)$,注意一下 $\text{max}$ 和 $\text{arg max}$ 的区别:假设 $f(x)=1-x^2$,该函数的 $\text{max =1, arg max=0}$,即 $\text{f(arg max) = max}$。在 $\text{MLE}$ 我们找的是使得似然函数最大的参数,并不关心似然函数的最大值。
下面是一个简单的例子。假设 $Y = (x_1,x_2,x_3,x_4,x_5) = (1,1,1,1,0)$ 是取自 $\text{Ber}(\theta)$ 的独立同分布的样本,$\theta$ 为未知参数。利用 $\text{MLE}$ 估计 $\theta$。
首先构造似然函数,$L(HHHHT|\theta)=\theta^4(1-\theta) = \theta^4 - \theta^5$;
然后求似然函数的最大值:求极值,确定极值点,将极值点和端点进行比较得到最大值。
$$
L^{'}(Y|\theta) = 4\theta^3 -5\theta^4 = \theta^3(4-5\theta)\rArr \text{likely extreme points 0, 4/5}
$$
为什么是 $0,4/5$ 是可能的极值点,因为极值点的判断除了一阶导为零外,还需要一阶导左右两侧异号
$\theta\in[0,1]$,所以求最大值,只需要比较 $0,4/5,1$ 这三点的似然函数的值即可求得最大值,可以求得 $\widehat{\theta} = \frac45$ 时取得最大值。
求 $\widehat{\theta}_{MLE}$ 的一般步骤:
- 构造似然函数或对数似然函数;
- 求使得似然函数达到最大值的参数;
- 有时还需要验证(但我们不考虑);
1.1.3 最大似然估计例子
例一、$Y = (x_1,x_2,\ldots, x_n)$ 是来自 $\text{Poi}(\theta)$ 的独立同分布的样本,利用 $\text{MLE}$ 对 $\theta$ 进行估计。
构造似然函数,取对数,
$$
L(Y|\theta) = \prod_{i=1}^np_X(x_i|\theta) = \prod_{i=1}ne\frac{\theta^{x_i}}{x_i!}\
\text{ln}L(Y|\theta) = \text{ln}\left(\prod_{i=1}ne\frac{\theta^{x_i}}{x_i!}\right) = \sum_{i=1}^n[-\theta+x_i\text{ln}\theta - \text{ln}x_i!]
$$
求最值,求出可能的极值点然后和端点一起比较,得出最大值,
$$
\begin{align}
&\left[\text{ln}L(Y|\theta)\right]^{'} = \sum_{i=1}^n[-1+\frac{x_i}{\theta}] = 0\nonumber\
&\rArr -n + \frac{1}{\widehat{\theta}}\sum_{i=1}^nx_i = 0\rArr\widehat{\theta} = \frac1n\sum_{i=1}^nx_i\nonumber\
\end{align}
$$
由泊松分布的图像可得,在其定义区间内,只存在一个极大值点,所以该点同时也为最大值点。
例二、$Y = (x_1,x_2,\ldots, x_n)$ 是来自 $\text{Exp}(\theta)$ 的独立同分布的样本,利用 $\text{MLE}$ 对 $\theta$ 进行估计。
构造似然函数,取对数,
$$
L(Y|\theta) = \prod_{i=1}^nf_X(x_i|\theta) = \prod_{i=1}^n\theta e^{-\theta x_i}\
\text{ln}L(Y|\theta) = \sum_{i=1}^n\text{ln}\left(\theta e^{-\theta x_i}\right) = \sum_{i=1}^n\left[\text{ln}(\theta)-\theta x_i\right]\
$$
求最值,求出可能的极值点然后和端点一起比较,得出最大值,
$$
\begin{align}
&\left[\text{ln}L(Y|\theta)\right]^{'} = \sum_{i=1}^n[\frac{1}{\theta} - x_i] = 0\nonumber\
&\rArr \frac{n}{\theta} - \sum_{i=1}^nx_i = 0\rArr\widehat{\theta} = \frac{n}{\sum_{i=1}^nx_i}\nonumber\
\end{align}
$$
例三、$Y = (x_1,x_2,\ldots, x_n)$ 是来自 $\text{Unif}(0, \theta)$ 的独立同分布的样本,利用 $\text{MLE}$ 对 $\theta$ 进行估计。
构造似然函数,取对数。因为均匀分布的密度函数是分段函数,我们需要利用分段函数将其化简为一个表达式,
$$
\begin{align}
&f_X(x|\theta)\begin{cases} \frac1\theta,\quad0\leqslant x\leqslant\theta,\
0,\quad \text{otherwise}
\end{cases}\quad
I_A\begin{cases}
1,\quad \text{A is true},\
0,\quad \text{A is false}
\end{cases}\nonumber\
&\rArr f_X(x|\theta) = \frac1\theta I_{{0\leqslant x\leqslant \theta}}\nonumber\
&\rArr L(Y|\theta) = \prod_{i=1}^n f_X(x_i|\theta) = \prod_{i=1}^n \frac1\theta I_{{0\leqslant x_i\leqslant \theta}} = \frac{1}{\theta^n} I_{{0\leqslant x_1,\ldots,x_n\leqslant \theta}}\nonumber\
\end{align}
$$
求最值,求出可能的极值点然后和端点一起比较,得出最大值。
$$
\frac{d}{d\theta}L(Y|\theta) = -\frac{n}{\theta^{n+1}}I_{{0\leqslant x_1,\ldots,x_n\leqslant \theta}}
$$
$I_{{0\leqslant x_1,\ldots,x_n\leqslant \theta}}$ 只是为了表示 $0\leqslant x_1,\ldots,x_n\leqslant \theta$ 时函数为 $\frac{1}{\theta^n}$,所以求导时只需要对 $\frac{1}{\theta^n}$ 求导即可。虽然得到了求导的结果,但是求得导数为零的点,即无法直接求得极值点。下面是 $\frac{1}{\theta^n}$ 的图像:

从上面的图片可以得到,$\theta = 0$ 时,$\frac{1}{\theta^n}$ 可能取到最大值。但是似然函数为 $\frac{1}{\theta^n} I_{{0\leqslant x_1,\ldots,x_n\leqslant \theta}}$,当 $x_1,\ldots,x_n$ 的最大值小于等于 $\theta$ 时,那么 $x_i$ 都小于 $\theta$,所以似然函数也可以改写为 $\frac{1}{\theta^n} I_{{0\leqslant x_{max}\leqslant \theta}}$,所以似然函数的图像如下:

所以 $\widehat{\theta}{MLE} = x = max{x_1,\ldots, x_n}$。
例三只是一个特殊的均匀分布的例子,因为均匀分布的范围一般由两个变量决定 $(\text{Unif(a,b)}$ 的范围为 $[a,b])$。另一方面,对于大多数分布来说,无论它们的值为多少,它们总有相同的范围。例如,对于 $\text{Poi}(\lambda)$ 来说,它的范围总是为 ${0,1,2,\ldots}$;对于 $\text{Exp}(\lambda)$ 的范围总是为 $[0, +\infin)$。
1.2 矩估计(Method of Moments, MoM)
矩估计的基本思想是用样本矩估计总体矩。首先回顾一下矩的概念,然后引出样本矩。$E[X^k]$ 称为随机变量 $X$ 的 $k$ 阶矩;$E[(X - \mu)^k]$ 称为随机变量 $X$ 的 $k$ 阶中心矩,其中 $\mu$ 为随机变量 $X$ 的方差。由期望和方差的定义可得,$X$ 的一阶矩为期望,二阶中心矩为方差。
接下来定义样本矩,$X$ 的 $k$ 阶矩为随机变量 $X^k$ 的均值,那么样本的 $k$ 阶矩也应为样本的 $k$ 次方的均值,即 $A_k = \frac1n\sum_{i=1}nX_ik$,样本的 $k$ 阶中心矩为 $B_k = \frac1n\sum_{i=1}n(X_i-\mu)k$。由样本均值和样本方差的定义的,样本的一阶矩为样本均值,即 $A_1=\frac1n\sum_{i=1}^nX_i = \overline X$;样本的二阶中心矩为样本方差,即 $B_2 = \frac1n\sum_{i=1}n(X_i-\overline{X})2$
考试中的矩估计一般只会用到一阶或二阶
1.2.1 矩估计思想
假设我们只需要估计一个参数 $\theta$(有时你可能需要估计两个参数,比如 $N(\mu,\sigma^2)$)。矩估计背后的思想是:找到一个好的估计量,可以使得真实的矩和样本矩尽可能接近。也就是说,我们应该选择参数 $\theta$ 使得一阶真实矩 $E[X]$ 等于一阶样本矩 $\overline{X}$。下面是一个例子:

$$
\begin{align}
E[X]&=\frac\theta2=\overline{X}=\frac1n\sum_{i=1}^nx_i\qquad E[\text{Unif}(a,b)=\frac{a+b}{2}]\nonumber\
\widehat{\theta}{MoM}&=\frac2n\sum^nx_i=2\overline{X}\nonumber
\end{align}
$$
联想一下之前学的大数定理可以发现上面的结果显然正确。
$$
\lim_{n\to\infin}P(|\overline{X} -\mu|\geqslant\epsilon) = 0\rArr n\to\infin,,,\overline{X}\to \mu
$$
当有两个参数的时候该如何解决?令一阶真实矩等于一阶样本矩(就像我们上面做的那样),再令二阶真实矩等于二阶样本矩然后解方程,解得的结果记得加帽子。当我们有 $k$ 个参数的时候该如何解决?


$$
\begin{align}
E[X] &= \theta_1 = \overline{X} = \frac1n\sum_{i=1}^nx_i\nonumber\
E[X^2] &= Var(X) - (E[X])^2 =\theta_2+\theta_1^2 = \frac1n\sum_{i=1}nx_i2 \nonumber\
\text{solved } \widehat{\theta}1 &= \frac1n\sum^nx_i,,,\widehat{\theta}2 = \frac1n\sumnx_i2-(\frac1n\sum_{i=1}^nx_i)\nonumber
\end{align}
$$
了解矩估计的思想,会解题即可,书上和课上都没有提及矩估计的证明,一个参数的矩估计用大数定理即可证,两个及 $n$ 个参数的矩估计都可以用大数定理进行证明
1.3 估计量的评选标准
-
无偏性:若 $\theta$ 的估计量 $\widehat{\theta} = \widehat{\theta}(X_1,\ldots,X_n)$ 的数学期望 $E(\widehat{\theta})$ 存在并且 $E(\widehat{\theta}) = \theta$,则称 $\widehat{\theta}$ 是参数 $\theta$ 的无偏估计量;
-
有效性:设 $\widehat{\theta}_1 = \widehat{\theta}_1(X_1,\ldots,X_n)$ 与 $\widehat{\theta}_2 = \widehat{\theta}_2(X_1,\ldots,X_n)$ 都是未知参数 $\theta$ 的无偏估计量,若 $D(\widehat{\theta}_1)\leqslant D(\widehat{\theta}_2)$,则称 $\widehat{\theta}_1$ 比 $\widehat{\theta}_2$ 有效;
-
一致性(相合性):设 $\widehat{\theta} = \widehat{\theta}(X_1,\ldots,X_n)$ 为未知参数 $\theta$ 的估计量,若当 $n\to\infin$ 时,$\widehat{\theta} = \widehat{\theta}(X_1,\ldots,X_n)$ 依概率收敛于 $\theta$,则称 $\widehat{\theta}$ 为未知参数 $\theta$ 的一致估计量(或相合估计量)
2. 区间估计
置信区间是经典统计下的区间估计;可信区间是贝叶斯统计下的区间估计。
2.1 置信区间
2.1.1 置信区间引入
由点估计 $\text{(MoM, MLE)}$ 得到的估计值是真实值的概率为 $0$,即 $P(\widehat{\theta} = \theta) = 0$。原因是因为 $\theta$ 是实数,可以取任意值,所以估计值完全正确的概率为 $0$,即使非常接近。但是,我们可以求得一个区间, $\theta$ 有很大的概率落在这个区间中。
$$
P\left( \theta \in\left[\widehat{\theta} - \Delta,\widehat{\theta} + \Delta\right]\right) = 0.95
$$
下述是这个区间三种等价的描述方法:
$$
P\left( \theta \in\left[\widehat{\theta} - \Delta,\widehat{\theta} + \Delta\right]\right) = P\left(\left|\widehat{\theta}-\widehat{\theta}\right|\leqslant\Delta\right) =P\left( \widehat{\theta} \in\left[\theta - \Delta,\theta + \Delta\right]\right)= 0.95
$$
特别注意第一个和第三个(交换了 $\widehat{\theta}$ 和 $\theta$)。
2.1.2 置信区间
置信区间定义:假设有一个带未知参数 $\theta$ 的分布,你从中得到了一系列独立同分布的样本值 $x_1,\ldots,x_n$,使用 $\widehat{\theta}$ 对 $\theta$ 进行估计。$\theta$ 的一个置信度为 $100(1-\alpha)%$ 置信区间为集中于 $\widehat{\theta}$ 的一个小区间(一般来说以 $\widehat{\theta}$ 为中心),这个区间有 $100(1-\alpha)%$ 的概率能够捕获到 $\theta$,即
$$
P\left(\theta\in\left[\widehat{\theta}-\Delta, \widehat{\theta}+\Delta\right]\right) = 1-\alpha
$$
如何理解置信区间——以 $99%$ 的置信区间 $[0.279, 0.401]$ 为例:
错误理解:$\theta$ 有 $99%$ 的概率落在置信区间 $\left [\widehat{\theta}-\Delta, \widehat{\theta} + \Delta\right ] = [0.279,0.401]$ 中。这种理解是错误的,其中没有随机性,$\theta$ 是一个固定的参数。
正确理解:如果我们多次重复这个过程(每次得到 $n$ 个样本并构造不同的置信区间),我们构造的置信区间中有 $99%$ 的置信区间会包含 $\theta$。
2.2 单个正态总体的均值和方差的置信区间
设 $X_1, X_2, · · · , X_n$ 是来自总体 $N(\mu, \sigma^2)$ 的样本,条件分别如下,分别构造 $(1-\alpha)$ 的置信区间:
2.2.1 正态总体 $\sigma$ 已知时 $\mu$ 的置信区间
由 $\text{MoM}$ 进行估计可得,$\widehat{\mu} =\overline{X} = \frac1n\sum_{i=1}^nX_i\sim N(\mu, \sigma^2/n)$,
对其进行标准化,$\frac{\overline{X} - \mu}{\sigma/\sqrt{n}}\sim N(0,1)$,由置信区间的定义可得,
$$
\begin{align}
&P\left(\mu\in\left (\widehat{\mu}-\Delta, \widehat{\mu}+\Delta\right)\right) = 1-\alpha=P\left(\widehat{\mu}\in\left (\mu-\Delta, \mu+\Delta\right)\right)\nonumber\
&=P\left(\mu-\Delta<\widehat{\mu}<\mu+\Delta\right)=P\left(\frac{-\Delta}{\sigma/\sqrt{n}}<\frac{\widehat{\mu}-\mu}{\sigma/\sqrt{n}}<\frac{\Delta}{\sigma/\sqrt{n}}\right)\nonumber\
&=2\Phi\left(\frac{\Delta}{\sigma/\sqrt{n}}\right) - 1 = 1-\alpha\nonumber\
&\rArr\Phi\left(\frac{\Delta}{\sigma/\sqrt{n}}\right) = 1-\frac\alpha2\nonumber\rArr\Delta =\Phi^{-1}\left(1-\frac\alpha2\right)\sigma/\sqrt{n}
\end{align}
$$
令 $z_{1-\frac{\alpha}{2}} = \Phi^{-1}\left(1-\frac\alpha2\right)$,则 $\mu$ 的置信区间为:
$$
\left[\overline{X}- z_{1-\frac\alpha2}\frac{\sigma}{\sqrt{n}},\overline{X}+ z_{1-\frac\alpha2}\frac{\sigma}{\sqrt{n}}\right]
$$
2.2.2 正态总体 $\sigma$ 未知时 $\mu$ 的置信区间
$\sigma$ 未知时,求 $\mu$ 的置信区间,可用样本标准差 $S$ 对已知 $\sigma$ 下 $\mu$ 的置信区间中的 $\sigma$ 进行估计,标准化后的变量为 $\frac{\overline{X} - \mu}{S/\sqrt{n}}$,由计算可得(不知道怎么算的),这个随机变量并不服从标准正态,我们将其定义为自由度为 $n-1$ 的 $t$ 分布,即 $t(n-1)$。此时 $\mu$ 的置信区间为:
$$
\left[\overline{X}- t_{\frac\alpha2}(n-1)\frac{S}{\sqrt{n}},\overline{X}+t_{\frac\alpha2}(n-1)\frac{S}{\sqrt{n}}\right]
$$
$t_{\frac\alpha2}(n-1)$ 意味着,对于 $T\sim t(n-1)$ 有唯一的 $t_{\frac\alpha2}(n-1)$ 使得 $P(T\geqslant t_{\frac\alpha2}(n-1)) = \frac\alpha2$。
2.2.3 正态总体 $\mu$ 已知时 $\sigma^2$ 的置信区间
由 $\frac{1}{\sigma2}\sum_{i=1}n(X_i-\mu)2\sim\chi2(n)$,上述变量中,只有 $\sigma^2$ 未知,因此可作为枢轴变量,进一步构造 $1-\alpha$ 置信区间,可得
$$
\begin{align}
&\chi_{1-\frac\alpha2}2(n)<\frac{1}{\sigma2}\sum_{i=1}n(X_i-\mu)2<\chi_{\frac\alpha2}^2(n)\nonumber\
\rArr&\frac{\sum_{i=1}n(X_i-\mu)2}{\chi_{\frac\alpha2}^2(n)} < \sigma^2 <\frac{\sum_{i=1}n(X_i-\mu)2}{\chi_{1-\frac\alpha2}^2(n)}\nonumber
\end{align}
$$
注:卡方分布不是对称的,但是由于习惯,在选择上侧分位数的时候仍然使用 $\frac{\alpha}{2}$,但是不能像正态分布或者 $t$ 分布一样直接使用相反数,比如上面的 $t_{\frac\alpha2}(n-1)$ 和 $-t_{\frac\alpha2}(n-1)$,而是要使用 $\chi_{1-\frac\alpha2}^2(n)$ 和 $\chi_{\frac\alpha2}^2(n)$
2.2.4 正态总体 $\mu$ 未知时 $\sigma^2$ 的置信区间
当 $\mu$ 未知时,可用 $\overline{X}$ 对其进行估计,对上例枢轴变量中的 $\mu$ 进行估计可得,$\frac{1}{\sigma2}\sum_{i=1}n(X_i-\overline{X})2\sim\chi2(n-1)$,与上例中不同的是估计后的枢轴变量服从的是自由度为 $n-1$ 的卡方分布,而不是 $n$,不知道怎么证明,理解就好。
简单理解记忆:用 $\overline{X} = \frac1n(X_1+\ldots+X_n)$ 代替 $\mu$,使新的枢轴变量中多出一个约束(方程)。联系线性方程组的知识点,多一个方程就少一个自由未知量,因此自由度就比下面的少1。
联想样本方差,对 $\frac{1}{\sigma2}\sum_{i=1}n(X_i-\overline{X})^2$ 进行化简可得 $\frac{(n-1)S2}{\sigma2}$。由于样本是已知的,所以样本容量和样本方差都是已知的,只有要估计的 $\sigma^2$ 是未知的,所以可将其作为枢轴变量,类似地,对此枢轴变量构造 $1-\alpha$ 的置信区间,可得:
$$
\begin{align}
&\chi_{1-\frac\alpha2}2(n-1)<\frac{(n-1)S2}{\sigma2}<\chi_{\frac\alpha2}2(n-1)\nonumber\
\rArr&\frac{(n-1)S2}{\chi_{\frac\alpha2}2(n-1)} < \sigma^2 <\frac{(n-1)S2}{\chi_{1-\frac\alpha2}2(n-1)}\nonumber
\end{align}
$$
2.3 两个正态总体的均值差和方差比的置信区间
设 $X\sim N(\mu_1,\sigma_1^2),,,Y\sim N(\mu_2,\sigma_2^2)$,$X_1,X_2,\ldots,X_n$ 是来自 $X$ 的样本,$Y_1,Y_2,\ldots,Y_m$ 是来自 $Y$ 的样本,总体 $X$ 和 $Y$ 独立,于是
$$
X_1,X_2,\ldots,X_n,Y_1,\ldots,Y_m
$$
相互独立。
2.3.1 均值差 $\mu_1-\mu_2$ 的置信区间
-
当 $m=n$ 时,令 $Z_i = X_i- Y_i,,,i= 1,2,\ldots,n$,则有
$$
Z_i\sim N(\mu_Z, \sigma_Z^2),,,\mu_Z = \mu_1 - \mu_2,\sigma_Z^2 = \sigma_1^2 + \sigma_2^2
$$
由此可转换为单个正态总体当 $\sigma_Z^2$ 未知时,求其均值 $\mu_Z$ 的置信区间的问题。显见 $\overline{Z} = \overline{X} - \overline{Y}$ 是 $\mu_Z$ 的一个良好的无偏估计,枢轴变量
$$
T_Z = \frac{(\overline{Z} - \mu_z)}{S_Z/\sqrt{n}}\sim t(n-1)
$$
此处 $S_Z^2 = \frac{1}{n-1}\sum_{i=1}^n(Z_i - \overline{Z})^2$,由于样本是已知的,所以样本容量、样本均值和样本方差都是已知的,只有要估计的 $\mu_Z$ 是未知的,所以可将其作为枢轴变量,类似地,对此枢轴变量构造 $1-\alpha$ 的置信区间,可得
$$
\begin{align}
&-t_{\frac\alpha2}(n-1)<\frac{(\overline{Z} - \mu_z)}{S_Z/\sqrt{n}}<t_{\frac\alpha2}(n-1)\nonumber\
\rArr&\overline{Z}-t_{\frac\alpha2}(n-1)\frac{S_Z}{\sqrt{n}} < \mu_Z < \overline{Z}+t_{\frac\alpha2}(n-1)\frac{S_Z}{\sqrt{n}}\nonumber
\end{align}
$$ -
当 $m\neq n,,,\sigma_12,\sigma_22$ 已知时,$\overline{X} - \overline{Y}$ 为 $\mu_1 - \mu_2$ 的一个良好的无偏估计,枢轴变量为 $Z$,然后构造 $1-\alpha$ 置信区间,
$$
\begin{align}
&Z = \frac{\overline{X} - \overline{Y} - (\mu_1 - \mu_2)}{\sqrt{\sigma_1^2/n + \sigma_2^2/m}}\sim N(0,1)\nonumber\[1.5ex]
\rArr &-z_{\frac\alpha2} <\frac{\overline{X} - \overline{Y} - (\mu_1 - \mu_2)}{\sqrt{\sigma_1^2/n + \sigma_2^2/m}} <z_{\frac\alpha2}\nonumber\[1.5ex]
\rArr&\overline{X}-\overline{Y}-z_{\frac\alpha2}\sqrt{\sigma_1^2/n + \sigma_22/m}<\mu_1-\mu_2\nonumber\&<\overline{X}-\overline{Y}-z_{\frac\alpha2}\sqrt{\sigma_12/n + \sigma_2^2/m}\nonumber\[1.5ex]\rArr&\left[\overline{X}-\overline{Y}-z_{\frac\alpha2}\sqrt{\sigma_1^2/n + \sigma_22/m},,,\overline{X}-\overline{Y}-z_{\frac\alpha2}\sqrt{\sigma_12/n + \sigma_2^2/m}\right]\nonumber
\end{align}
$$ -
当 $m\neq n,,,\sigma_12,\sigma_22$ 未知,但 $\sigma_1^2 = \sigma_2^2 = \sigma^2$,由
$$
\begin{align}
&\xi_1 = \frac{(n-1)S_12}{\sigma2} =\frac{1}{\sigma2}\sum_{j=1}n(X_j - \overline{X}_n)2\sim\chi2(n-1)\nonumber\
&\xi_2 = \frac{(n-1)S_22}{\sigma2} =\frac{1}{\sigma2}\sum_{j=1}m(Y_j - \overline{Y}_m)2\sim\chi2(m-1)\nonumber\
\end{align}
$$
因为 $X,Y$ 独立,$\xi_1,\xi_2$ 分别为 $X,Y$ 的函数,所以 $\xi_1,\xi_2$ 独立,由 $\chi^2$ 的性质可得,
$$
\xi_1+\xi_2\sim\chi^2(n+m-2)\nonumber
$$
引入
$$
S_W^2 = \frac{(\xi_1+\xi_2)\sigma^2}{n+m-2} = \frac{(n-1)S_1^2 + (m-1)S_2^2}{n+m-2}
$$若 $\overline{X}_n$ 和 $S^2$ 分别为正态分布的样本均值和样本方差,则 $\overline{X}$ 与 $S^2$ 独立,所以 $Z,\xi_1,\xi_2$ 也独立,又因为 $\sigma_12=\sigma_22 = \sigma^2$ 以及卡方分布和 $t$ 分布的定义可得,
$$
\begin{align}
&\frac{\overline{X}_n - \overline{Y}_m - (\mu_1 - \mu_2)}{S_W\sqrt{1/n+1/m}}\nonumber\
&=\frac{Z}{\sqrt{(\xi_1+\xi_2)/(n+m-2)}}\sim t(n+m-2)\nonumber\
\end{align}
$$利用上式构造 $\mu_1-\mu_2$ 的置信度为 $(1-\alpha)$ 的置信区间,
$$
\left[(\overline{X}_n-\overline{Y}m)-t S_W\sqrt{\frac1n+\frac1m}, (\overline{X}_n-\overline{Y}m)+t S_W\sqrt{\frac1n+\frac1m}\right]
$$其中 $t_{\frac\alpha2}= t_{\frac\alpha2}(n+m-2)$。
个人理解:$\sigma^2$ 未知,所以要找到一个估计量来对其进行估计,常用样本方差对其 $\sigma$,又因为样本方差和卡方分布的性质,以及正态总体可标准化为标准正态,联想到 t 分布。感觉思路有点乱。
-
其余情况现阶段不需要考虑;
2.3.2 方差比 $\sigma_12/\sigma_22$ 的置信区间
$$
\begin{align}
&\frac{(n-1)S_12}{\sigma_12}\sim \chi2(n-1),\frac{(m-1)S_22}{\sigma_22}\sim\chi2(m-1)\nonumber\[1.5ex]
&\text{IF }X\sim\chi2(m),Y\sim\chi2(n), F = \frac{X/m}{Y/n}, \text{ then } F \sim F(m, n)\nonumber\[1.5ex]
&\rArr\frac{S_22/\sigma_22}{S_12/\sigma_12}\sim F(m-1, n-1)\nonumber\[1.5ex]
&\rArr F_{1-\frac\alpha2}(m-1, n-1)< \frac{S_22\sigma_12}{S_12\sigma_22} <F_{\frac\alpha2}(m-1, n-1)\nonumber\[1.5ex]
&\rArr\frac{S_12}{S_22}F_{1-\frac\alpha2}(m-1, n-1)< \frac{\sigma_12}{\sigma_22} <\frac{S_12}{S_22}F_{\frac\alpha2}(m-1, n-1)\nonumber\[1.5ex]
\end{align}
$$
注意:与 $\chi^2(n)$ 类似 $F$ 分布也不对称图形。
参考资料
- https://web.stanford.edu/class/archive/cs/cs109/cs109.1218/files/student_drive/7.3.pdf
- https://web.stanford.edu/class/archive/cs/cs109/cs109.1218/files/student_drive/8.1.pdf
- http://staff.ustc.edu.cn/~zwp/teach/Math-Stat/lec7.pdf
- https://www.cnblogs.com/feixianxing/p/confidence-interval.html



![CSP历年复赛题-P5017 [NOIP2018 普及组] 摆渡车](https://img2024.cnblogs.com/blog/3330618/202406/3330618-20240610134332791-135241159.png)