一. 概述
什么是自动化剪辑解说电影的 AI Agent?
自动化剪辑解说电影的 AI Agent 是一种利用大模型技术对电影进行自动化剪辑和解说的系统。这种 AI Agent 能够分析电影中的剧情、人物对话、场景变化等元素,自动生成解说词并进行剪辑,使得观众可以在更短的时间内了解电影的核心内容。
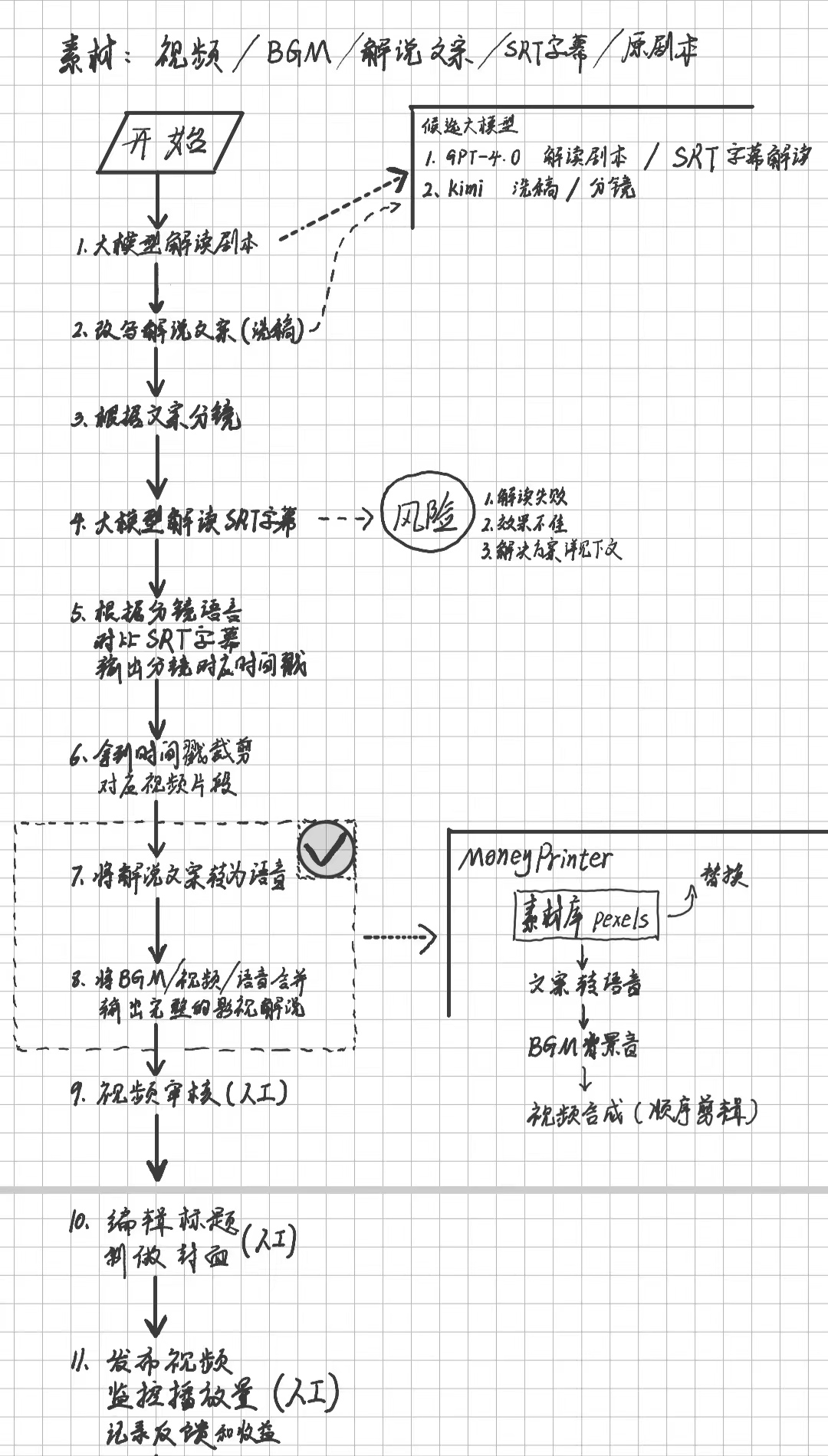
下面为方案流程图:
二. 快速开始
环境
- 显卡:不低于8G显存
- python版本:3.9
- pytorch版本:cu117
1.本地搭建视频理解大模型
- 克隆存储库
git clone https://github.com/linyqh/MiniGPT4-VideoLin
cd MiniGPT4-VideoLin
- 搭建环境
# 安装pytorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117# 安装其他包
pip install -r requirements.txt
- 下载 checkpoints
| MiniGPT4-Video (Llama2 Chat 7B) | MiniGPT4-Video (Mistral 7B) |
|---|---|
| Download | Download |
-
(可选)下载 Llama-2-7b-chat
国内下载会很慢,建议先提前下载到本地,然后修改模型加载路径,下载方法就不赘述了
-
运行demo
python minigpt4_video_inference.py --ckpt path_to_video_checkpoint --cfg-path test_configs/llama2_test_config.yaml
-
运行结果
本文以 《美国队长1》 为例演示效果,展示的片段为给美队注射血清的片段
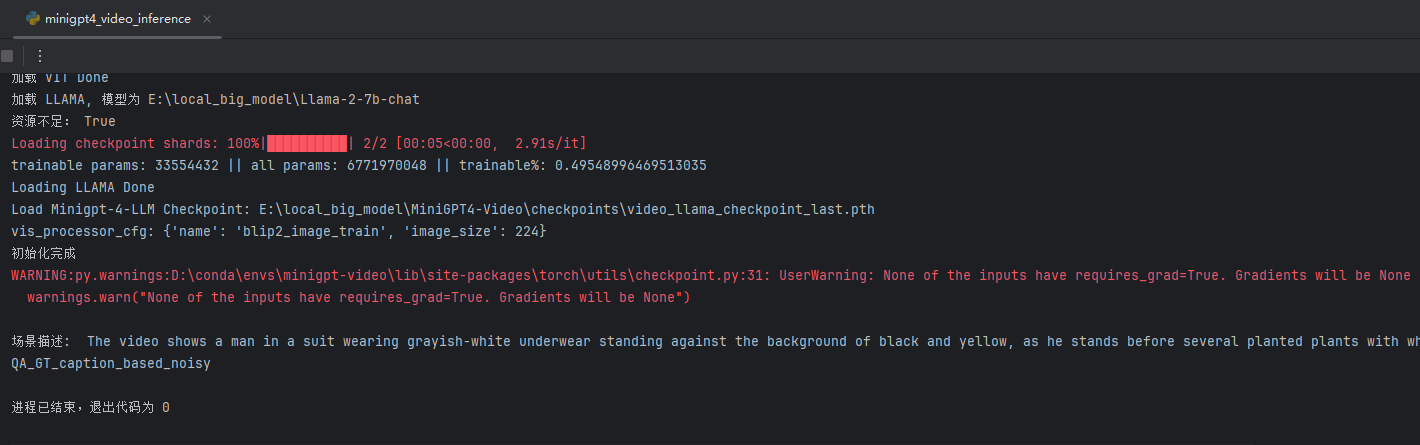
最后输出为:场景描述: The video shows a man in a suit wearing grayish-white underwear standing against the background of black and yellow, as he stands before several planted plants with white sheets around them. At some point while looking at his watch on one wristband when no people are present nearby him near a control panel.
2.搭建自动化剪辑工具
本步骤参考项目 MoneyPrinterTurbo 只需提供一个视频 主题 或 关键词 ,就可以全自动生成视频文案、视频素材、视频字幕、视频背景音乐,然后合成一个高清的短视频。
解读项目后,大概原理是提供一个主题,然后利用大模型生成文案和关键词,利用文本转语音的能力生成解说语音,然后根据关键词去 Pexels 网站搜索相关视频,然后配上背景音乐,使用 ImageMagick 工具合成完整视频。
存在问题:
- MoneyPrinterTurbo 项目最大的问题是视频素材为了确保版权,只能从 Pexels 网站获取,关键词搜索有时候完全不相关,视频素材不能自己提供
但是这个项目的生成音频,生成字母,视频合并还是非常好用的,我们只需要替换其中的素材来源,就不用重复造轮子了!!!
- 创建虚拟环境
git clone https://github.com/harry0703/MoneyPrinterTurbo.git
cd MoneyPrinterTurbo
conda create -n MoneyPrinterTurbo python=3.10
conda activate MoneyPrinterTurbo
pip install -r requirements.txt
-
安装 ImageMagick
Windows:
- 下载 https://imagemagick.org/archive/binaries/ImageMagick-7.1.1-31-Q16-x64-static.exe
- 安装下载好的 ImageMagick,注意不要修改安装路径
- 修改 配置文件 config.toml 中的 imagemagick_path 为你的实际安装路径(如果安装的时候没有修改路径,直接取消注释即可)
-
启动服务
python main.py
3.制作自己的素材库
大致思路:先根据时间将一个完整的视频裁剪为10分钟的片段,利用前面是视频理解大模型,为每个片段打上标签,便于后面的检索,然后再根据影视解说文案,进行 音画同步 (整个项目中音画同步是最难的部分,目前我也在想各种方案做音画同步的优化)
这部分等有更加好的方案,我再更新吧!!!
参考项目
视频理解大模型:
MiniGPT4-Video
Video-ChatGPT
一键生成短视频
MoneyPrinterTurbo
MoneyPrinterV2