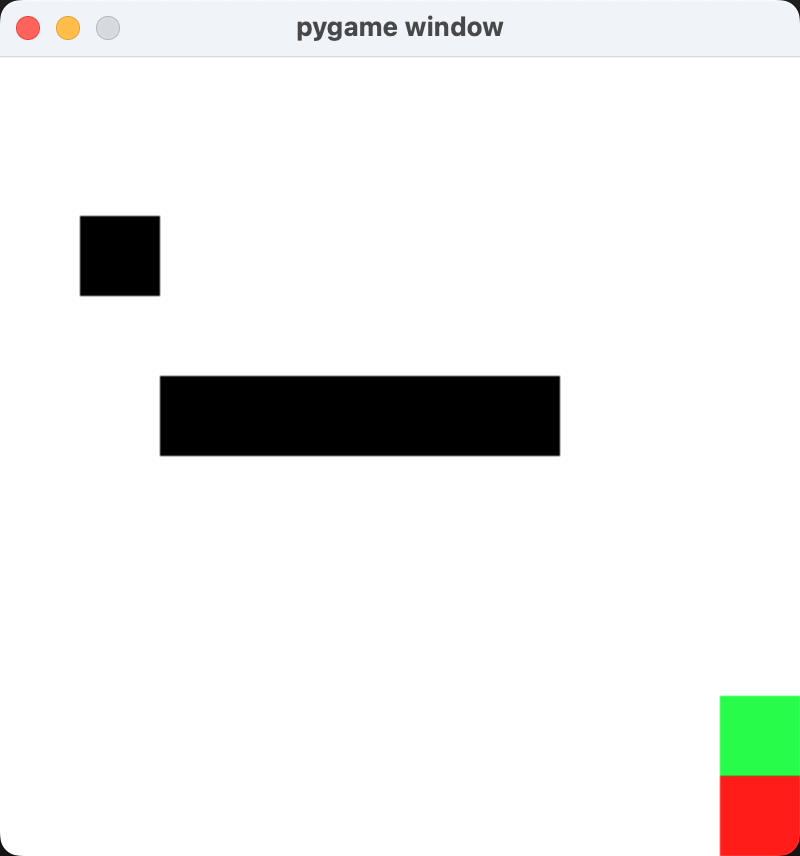
import pygame import numpy as np import random import sys# 定义迷宫环境 class Maze:def __init__(self):self.size = 10self.maze = np.zeros((self.size, self.size))self.start = (0, 0)self.goal = (9, 9)self.maze[4, 2:7] = 1 # 添加墙壁self.maze[2, 1] = 1self.current_position = self.startdef reset(self):self.current_position = self.startreturn self.current_positiondef manhattan_distance(self):return abs(self.current_position[0] - self.goal[0]) + abs(self.current_position[1] - self.goal[1])def step(self, action):x, y = self.current_positionif action == 0: # 上x -= 1elif action == 1: # 右y += 1elif action == 2: # 下x += 1elif action == 3: # 左y -= 1if 0 <= x < self.size and 0 <= y < self.size and self.maze[x, y] == 0:self.current_position = (x, y)if self.current_position == self.goal:reward = 100done = Trueelse:reward = -1done = Falseelse:reward = -100done = True# done = self.current_position == self.goalreturn self.current_position, reward, donedef render(self, screen):for x in range(self.size):for y in range(self.size):color = (255, 255, 255) if self.maze[x, y] == 0 else (0, 0, 0)if (x, y) == self.current_position:color = (0, 255, 0)if (x, y) == self.goal:color = (255, 0, 0)pygame.draw.rect(screen, color, (y*40, x*40, 40, 40))pygame.display.flip()# Q-learning class QLearning:def __init__(self, env):self.env = envself.q_table = np.zeros((env.size, env.size, 4))self.gamma = 0.9self.epsilon = 0.1self.alpha = 0.1def select_action(self, state):if random.random() < self.epsilon:return random.randint(0, 3)else:x, y = statereturn np.argmax(self.q_table[x, y])def update(self, state, action, reward, next_state):x, y = statenx, ny = next_statefuture_rewards = np.max(self.q_table[nx, ny])self.q_table[x, y, action] += self.alpha * (reward + self.gamma * future_rewards - self.q_table[x, y, action])# 主程序 def main():pygame.init()screen = pygame.display.set_mode((400, 400))clock = pygame.time.Clock()maze = Maze()agent = QLearning(maze)for episode in range(10000):state = maze.reset()done = Falsewhile not done:action = agent.select_action(state)next_state, reward, done = maze.step(action)agent.update(state, action, reward, next_state)state = next_statefor event in pygame.event.get():if event.type == pygame.QUIT:pygame.quit()sys.exit()if episode >= 8000:screen.fill((0, 0, 0))maze.render(screen)clock.tick(10)if __name__ == '__main__':main()
运行效果: