谢斌红,李玉,赵红燕. 基于无监督集成聚类的开放关系抽取方法. 中文信息学报. 2022, 36(5): 49-58
相关工作
- 关系抽取(RE)旨在从纯文本中抽取两个实体之间的关系,并以三元组形式进行描述。
- 传统的关系抽取方法主要是有监督的分类模型,需要一组预定义的关系标签和大量的标注数据。
- 远程监督是一种广泛采用的减少人工标注的方法,通过在语料库和知识库之间对齐实体来自动生成关系标签,然而,远程监督仍然局限于知识库中的已知关系,无法有效获取文本中蕴含的新型关系。
- 目前的OpenRE方法大致可以分为三类:基于序列标注的方法、基于Bootstrapping的方法和基于聚类的方法。
(1)基于序列的方法侧重于寻找关系mention,即直接从无监督或监督范式的句子中提取由单词组成的关系短语。由于表达方式的多样性,同一种关系类型通常会被提取多个过于具体的关系短语。
(2)基于Bootstrapping的方法,用一小组种子实例快速适应新的关系,对于开放式关系增长是可扩展的,但迭代过程中容易出现语义漂移现象,且在发现一定量的关系实例后很难继续挖掘。
(3)基于聚类的方法通过对从句子中提取的关系表示进行聚类,从而自动形成关系种类,具有发现高度可区分的关系类型的优势。
本文提出的方法:无监督集成聚类UEC
- UEC主要由两个模块组成:关系编码模块和集成聚类模块。
- 关系编码模块使用卷积梯形网络(CLN)提取句子的上下文关系特征,它将句子的嵌入表示作为输入,学习预测实体之间所表达的关系。
- 集成聚类模块采用集成模型投票的方式聚类无标注句子,并应用规则选择出高置信度句子为其标记伪标签,基于聚类结果的伪标签被视为半监督训练所需的监督信息,进一步指导关系编码模块更好地进行上下文关系特征学习和关系分类。
- UEC的结构图如图1所示:
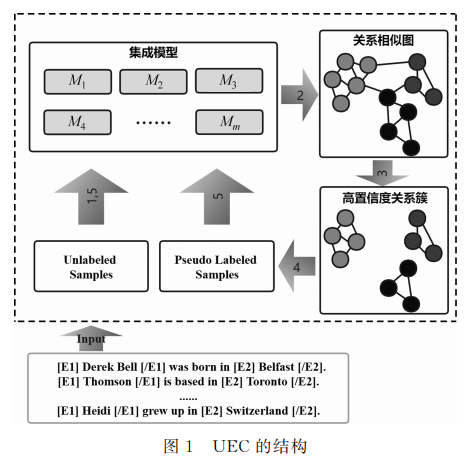
(1)在整个数据集上对集成模型中的每个卷积梯形网络Mj独立地进行无监督预训练。
(2)通过集成模型的投票对句子间的关系相似性建模,构建关系相似图。
(3)对关系相似图进行剪支,获得k 个高置信度关系簇。
(4)为关系簇中的句子分配伪标签,生成伪标记样本。
(5)使用无标记样本和伪标记样本执行半监督聚类过程。迭代进行第二步至第五步,生成最终的关系集群。
关系编码模块
- 关系编码模块旨在通过提取句子中给定实体之间的上下文特征并对其关系进行预测,本文使用卷积梯形网络(CLN),包括嵌入层、两个编码器和一个解码器。
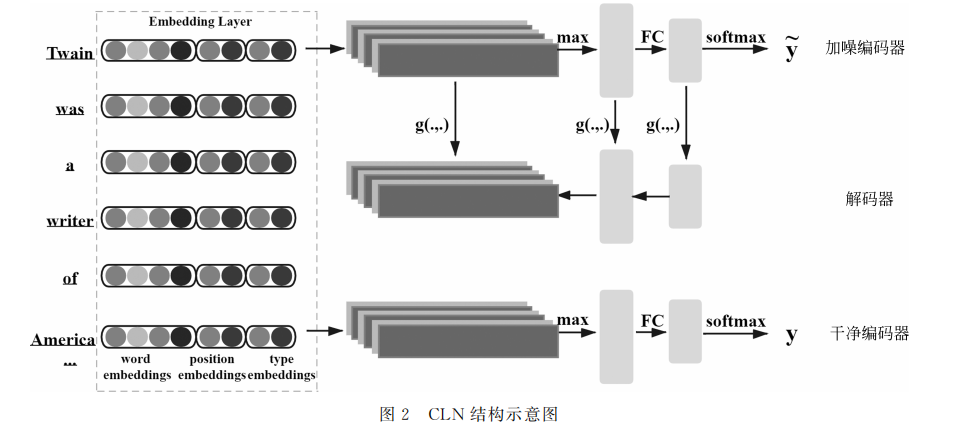
- 嵌入层:使用预训练的bert模型对句子进行编码,得到基于上下文的词嵌入表示。同时将句子中实体对的位置转换为随机初始化的位置嵌入,用于表征句子中某个单词与两个实体之间的相对距离。直觉上关系可以关联到某些类型的实体,所以实体类型信息也可以为关系发现提供很强的归纳偏差。
- 输入:句子S={w1,w2,...wq},其中q为句子最大长度。
- 输出:Sw是词嵌入表示,Sp是实体位置嵌入,St是实体类型嵌入,d是词嵌入维度,c是实体位置嵌入维度,t是实体类型嵌入维度。

- 编码器:CLN包括两个编码组件,加噪编码器和干净编码器。其中加噪编码器的每一层施加了随机高斯噪声,通过学习重构叠加噪声的输入句子,可防止编码器只简单地保留原始输入的信息,从而使编码器学习到的句子特征更具鲁棒性,提高网络的泛化能力。两个编码器结构相同,都由卷积层、池化层、全连接层以及分类层组成。
- 解码器:句子经过加噪编码器编码得到带噪的隐层表示之后,各层得到的特征向量通过跳跃连接映射到对应的解码层,解码器对其进行逐层降噪解码。由于加噪编码器的所有层都被噪声破坏,另一个具有共享参数的干净编码器负责提供干净的重构目标,辅助解码器进行无监督训练,以达到对有噪数据的最佳映射效果。(最小化二者的均方误差)
- 无监督关系预测:在常规梯形网络的重构损失基础上增加互信息损失,使CLN对表达相似的句子给出相似的关系类别预测,并在总体上最大化关系预测的多样性,从而使不同关系的句子拥有不同的预测结果。
集成聚类模块
- 集成聚类模块旨在将句子聚成k个语义上有意义的关系簇,从而发现潜在的关系类型。该模块使用CLN的集成模式对无标注句子进行聚类,以达到比单个网络决策更高的可靠性。
- 具体来说:对于一对输入句子,首先利用CLN集成模型M分别预测它们的关系类别。然后遍历整个数据集,根据预测结果构造一个具有n个节点的关系相似图G。其中,n是数据集的大小,G中的节点代表每个输入句子的嵌入表示U,Epos和Eneg是节点之间的两种边,由M中的CLN投票决定。
当M中的大多数CLN对输入的句子对的关系预测达成一致时,在其对应的节点之间添加强正边Epos。
当M中的大多数CLN对输入的句子对的关系预测不一致时,在其对应的节点之间添加强负边Eneg。
- 每个由强正边组成的子图就是一个集群,在一个集群内,节点对应的句子高置信度地属于同一关系类别。
自启动的伪半监督聚类
- 通过集成聚类模块提取出属于每个类的高置信度样本之后,将这些样本视为伪标记样本,对集成模型迭代执行半监督训练,进一步提高聚类性能。由于使用了半监督学习思想,而未使用真正的标记数据,因此称为“伪半监督”。