基础解析:
select 要几列
where要几行,用来对行进行过滤,加where,查出来的行变少
*代表所有的列
增删改查
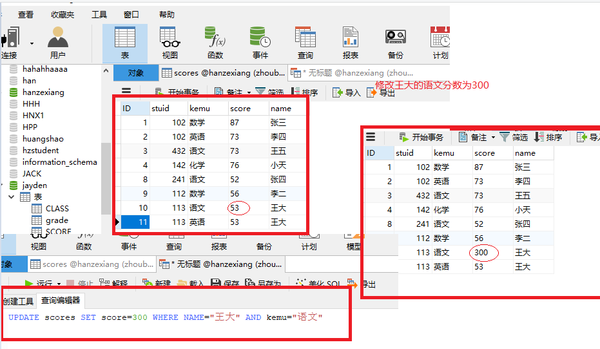
UPDATE SET 更新
UPDATE scores SET score=300 WHERE NAME="王大" AND kemu="语文"
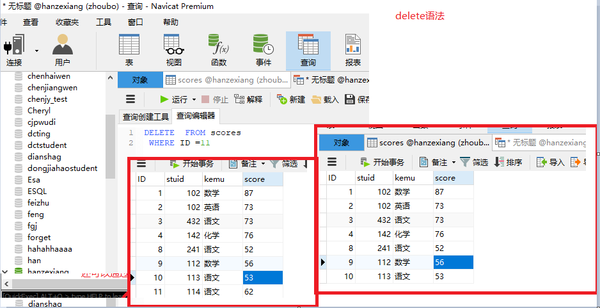
delete语法
DELETE FROM scores WHERE ID =11
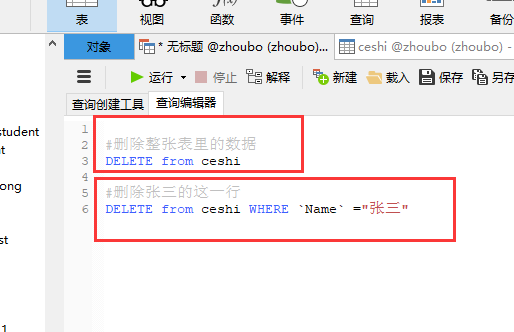
#删除整张表里的数据
DELETE from ceshi
#删除张三的这一行
DELETE from ceshi WHERE Name ="张三"
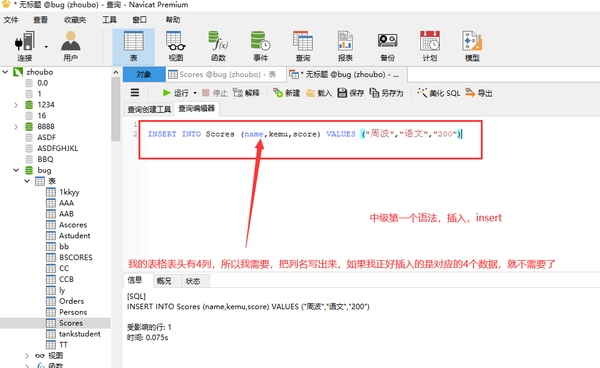
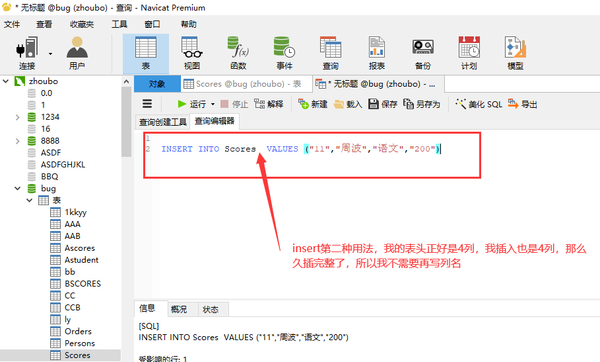
INsert into values插入
插入为空
INSERT INTO ceshi VALUES (9,"李二四","天津",62,NULL,"英语","男")

LIMIT1
取第一列数据
where 状态="单生" order by score DESC LIMIT1
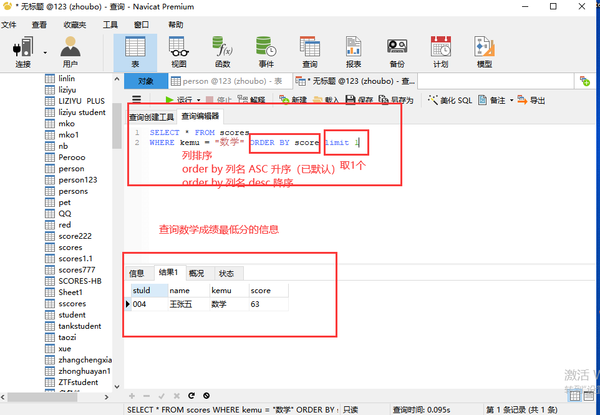
LIMIT高级用法
从第几条开始,取几条
where 状态="单生" order by score DESC LIMIT2,,5
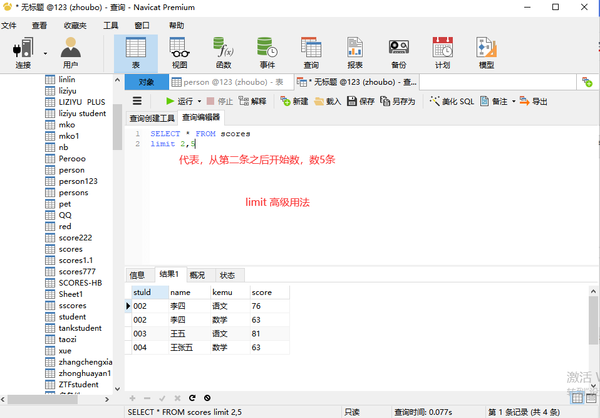
order by排序
ASC DESC
(where和order by之间不需要AND)
where 状态="单生" order by score(默认ASC升序)
where 状态="单生" order by score DESC(降序)
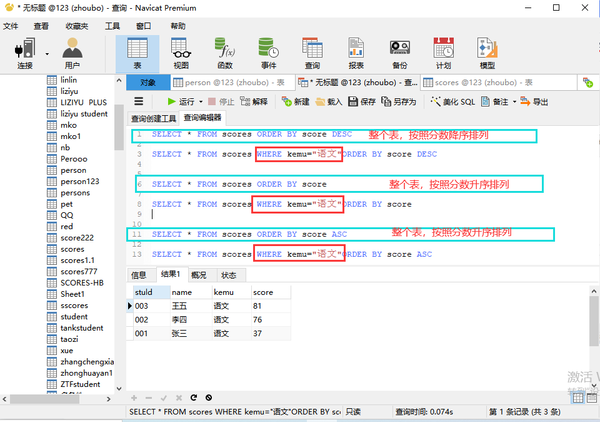
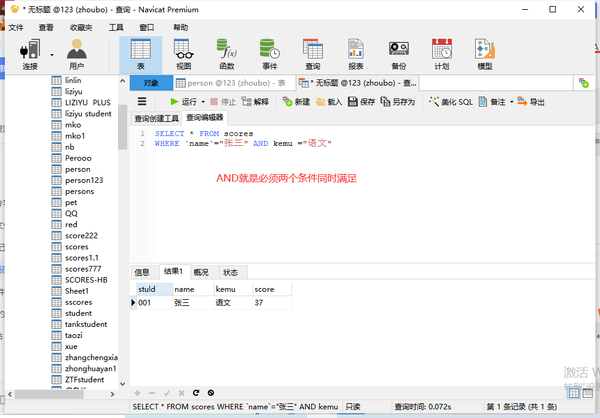
多条件用AND连接
(AND是必须同时满足所有条件)
列名="语文" AND 列名=“19”
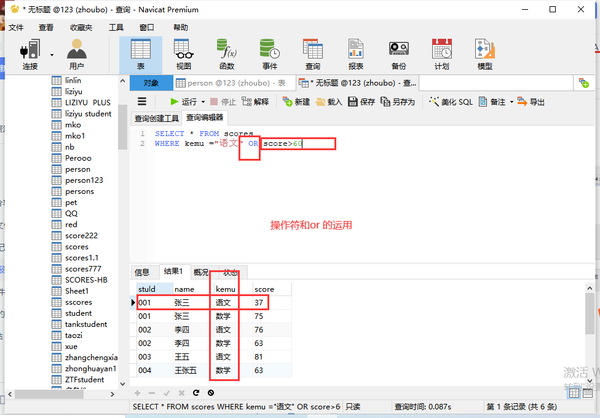
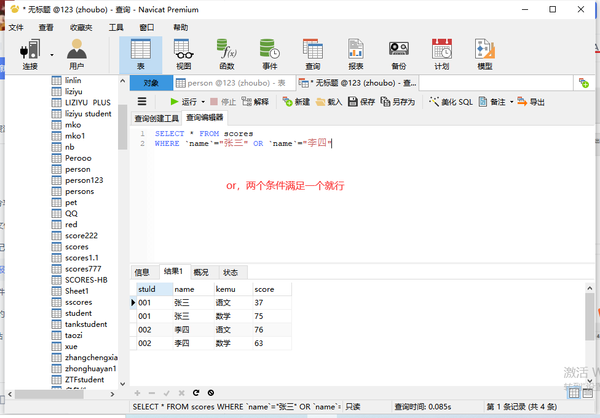
或者OR
(OR是必须同时任意满足条件)
列名="语文" OR 列名=“19”
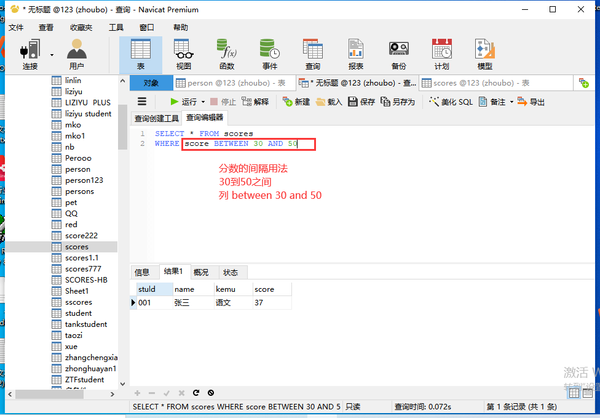
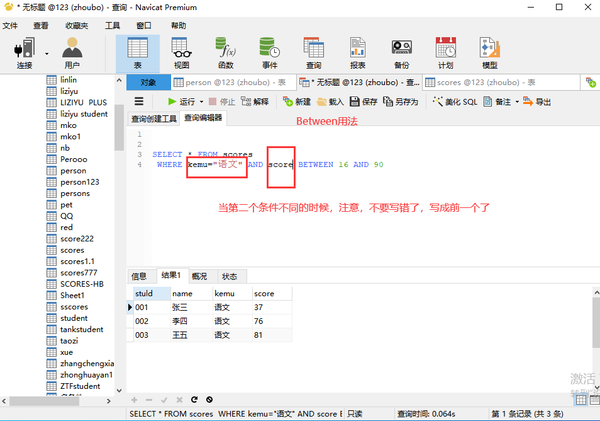
Between and
19到29
列名 Between 19 and 29
不等于
<>
SELECT*FROM ceshi where kemu <>"英语"
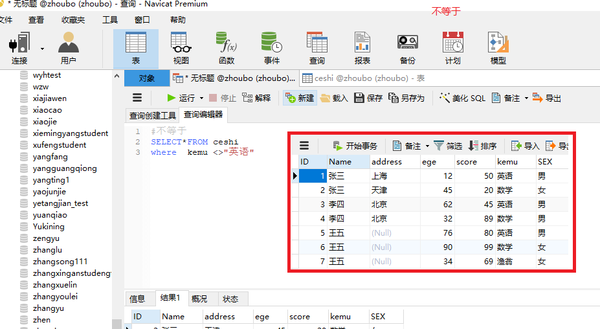
大于等于
SELECT * FROM studentliu WHERE Age >=25
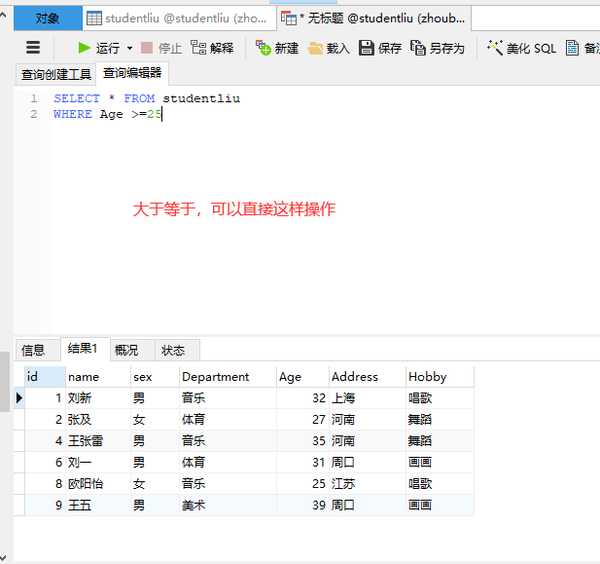
模糊查询like%
列名 LIKE "张%"
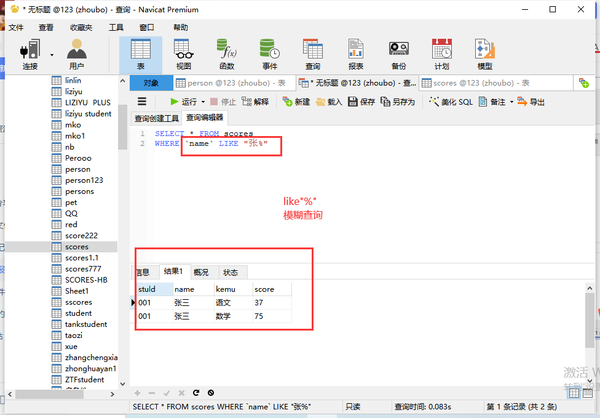
包含like
列名 LIKE "%张%"
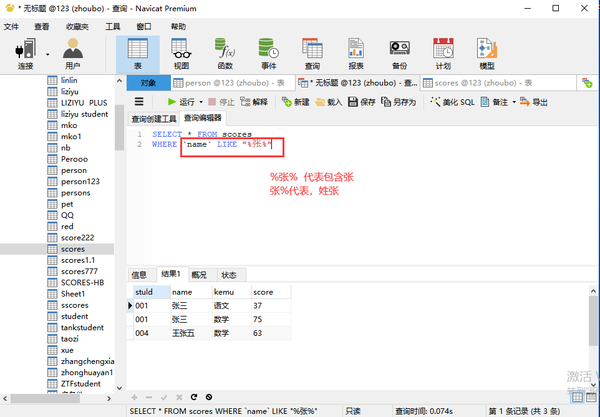
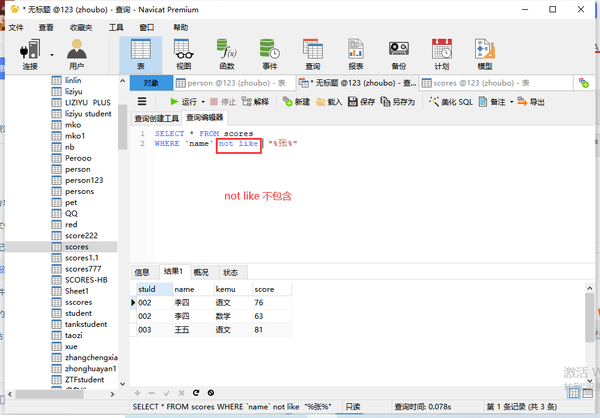
不包含not like
列名 not LIKE "%张%"
多条件in
列名 IN("1","2","3")
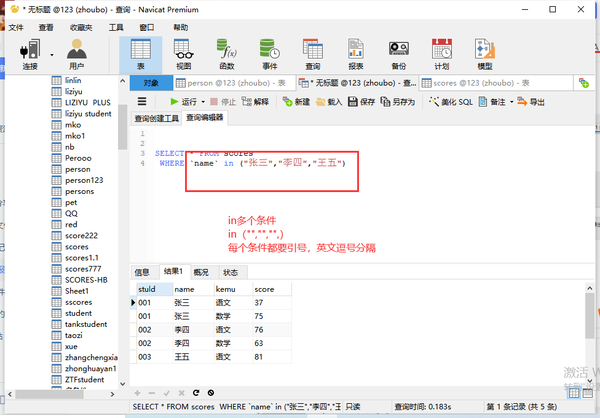
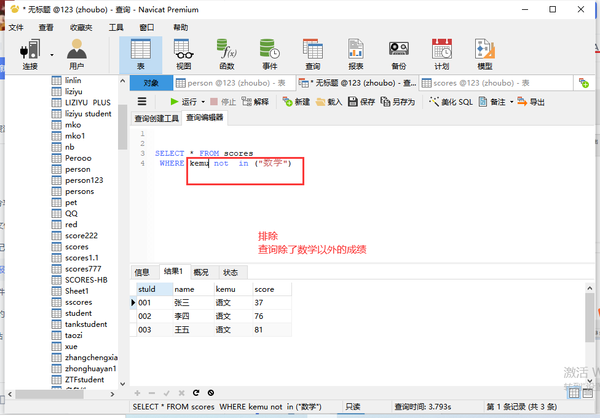
not in排除(以外)
列名 not in('1')
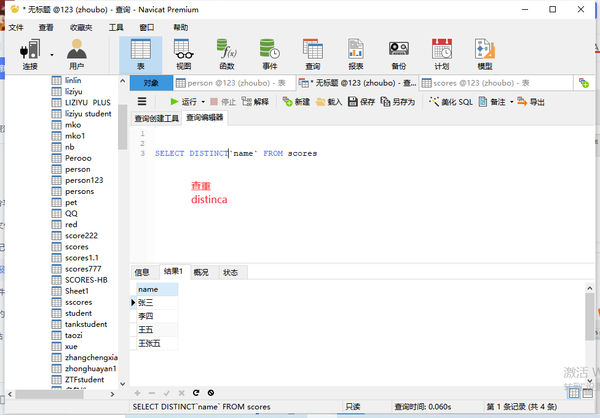
查重
distinca 列名
为空
列名 is NULL
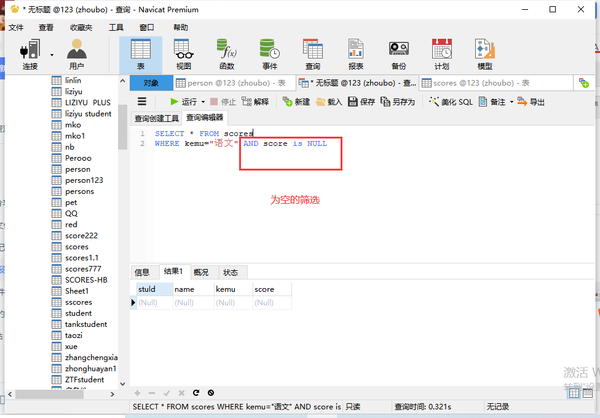
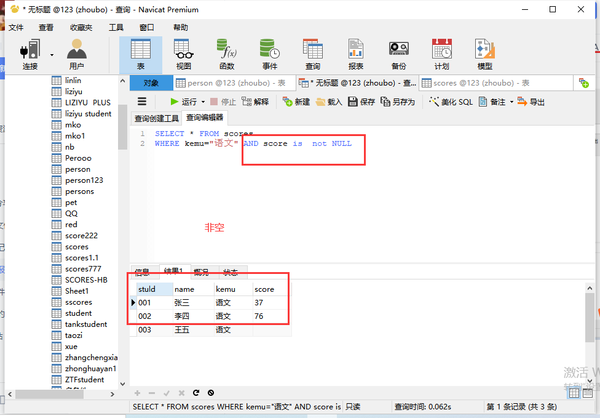
非空
is not NULL
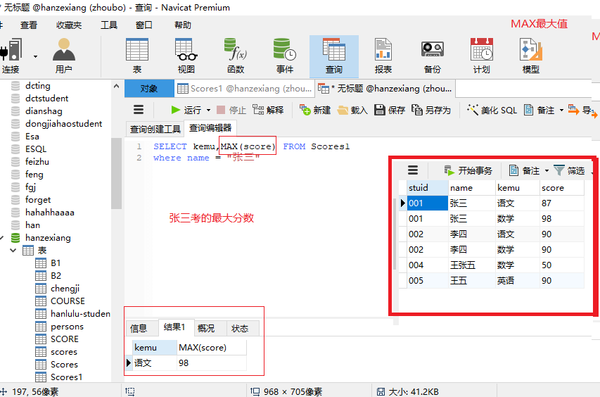
聚合函数
MAX(列名)最大值
SELECT kemu,MAX(score) FROM Scores1 where name = "张三"
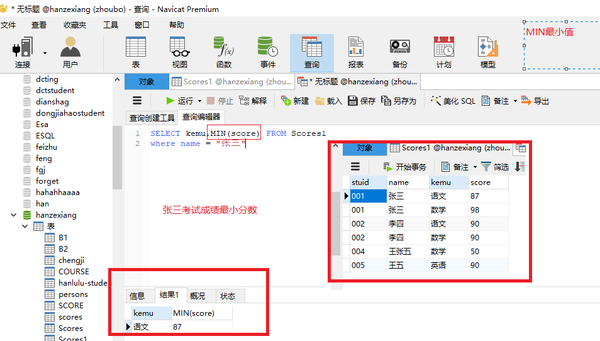
MIN(列名) 最小值
SELECT kemu,MIN(score) FROM Scores1 where name = "张三"
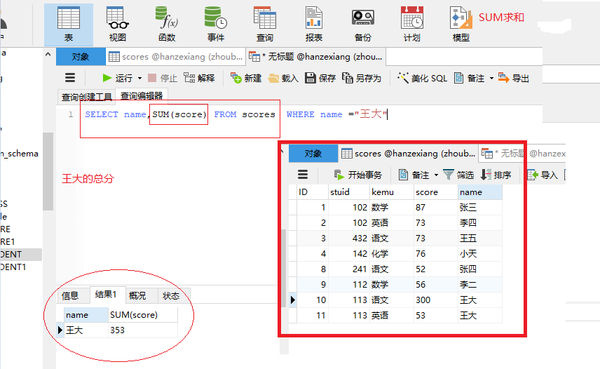
SUM(列名)求和
SELECT name,SUM(score) FROM scores WHERE name ="王大"
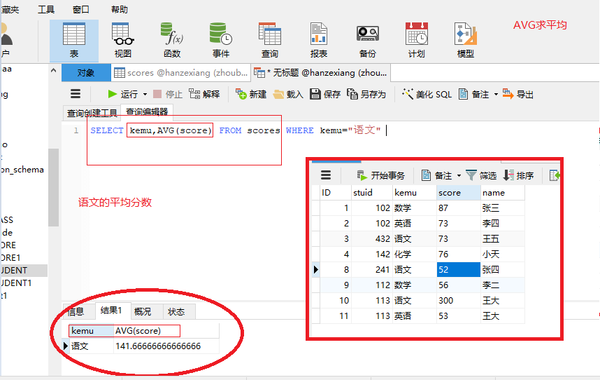
AVG(列名)求平均
SELECT kemu,AVG(score) FROM scores WHERE kemu="语文"
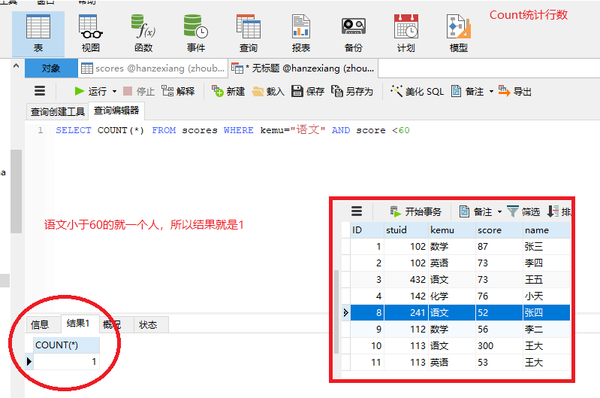
Count统计行数
SELECT COUNT(*) FROM scores WHERE kemu="语文" AND score <60
括号内容没搞懂,好像并没有意义,不是别名,也不是新值,列名的话无意义()*
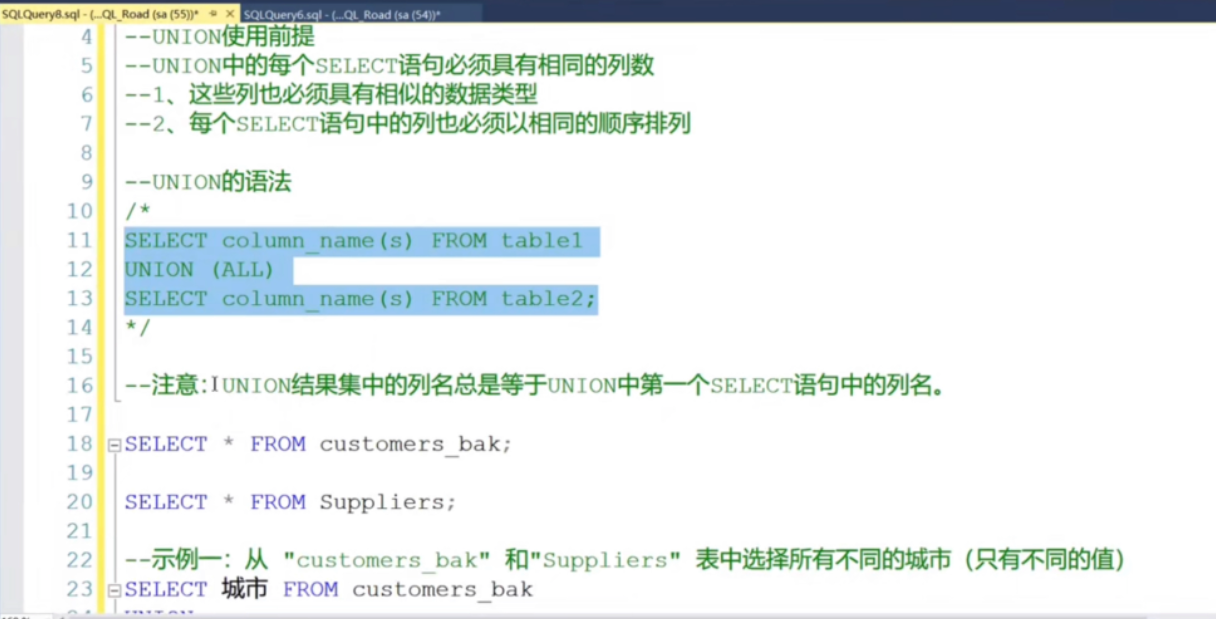
uinion结果拼接
首先,列名需要相同,如不同需要AS 别名一致,
其次,列的数据类型要相似或者一样
然后union union all的区别是,union是两个数据去重以后的,all是不去重的
实例:
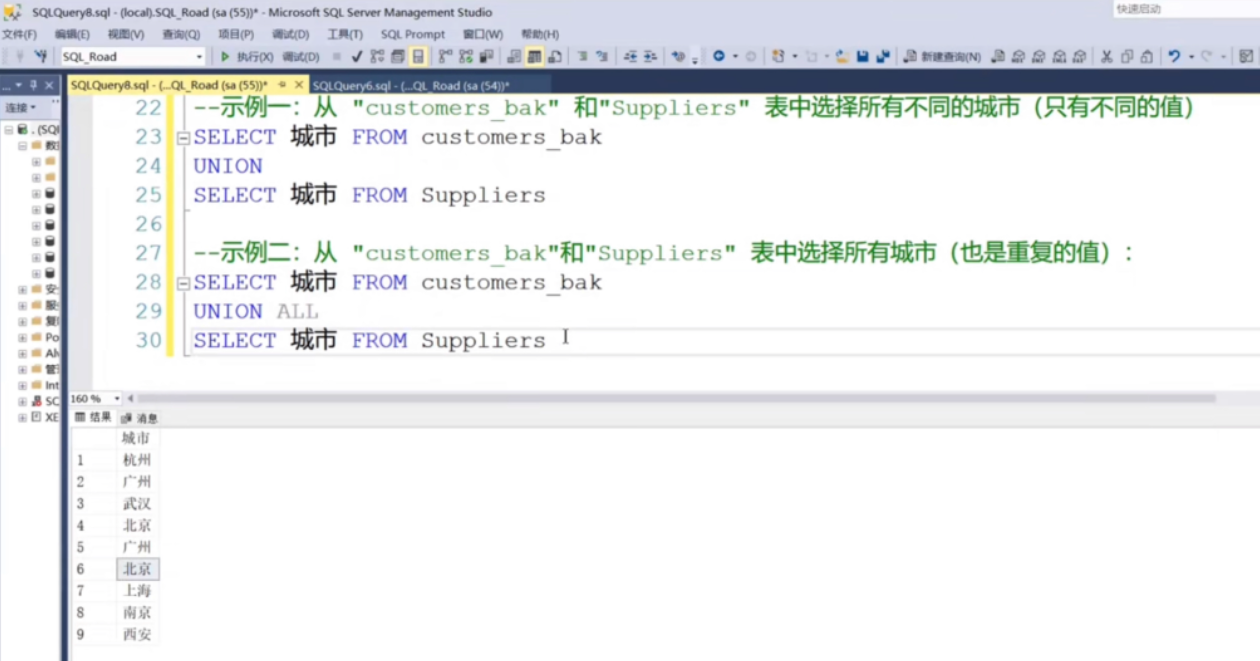
full join全链接
SELECT * FROM liancha1 full JOIN liancha2 on liancha1.ID=liancha2.ID
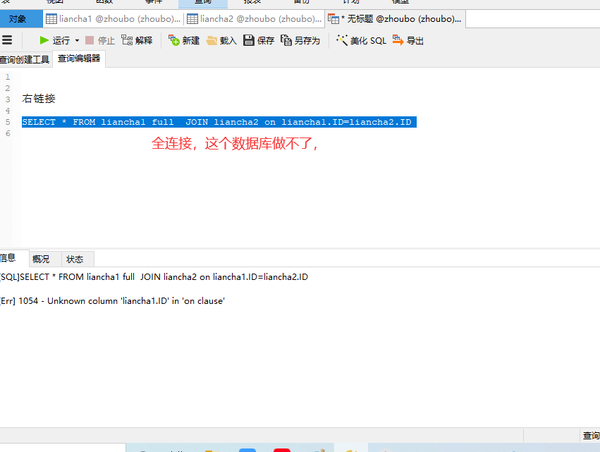
左连接右链接
SELECT * FROM liancha1 right JOIN liancha2 on liancha1.ID=liancha2.ID
SELECT * FROM liancha1 left JOIN liancha2 on liancha1.ID=liancha2.ID
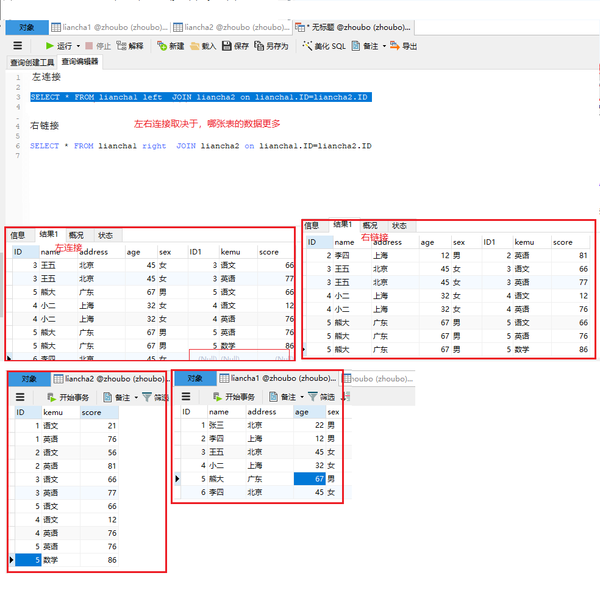
inner join内连接
求张三的考试情况(两表联查)
SELECT name,kemu,score FROM liancha1 INNER JOIN liancha2 on liancha1.ID=liancha2.ID
WHERE name="张三"
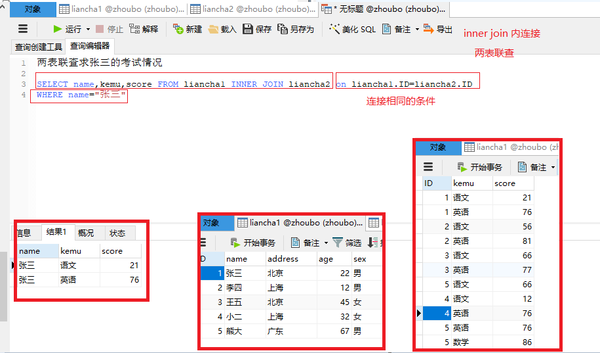
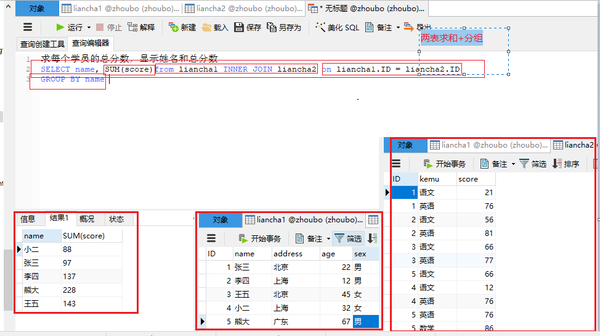
两表求和+分组
SELECT name, SUM(score)from liancha1 INNER JOIN liancha2 on liancha1.ID = liancha2.ID
GROUP BY name
两表+分组+Where+HAVing
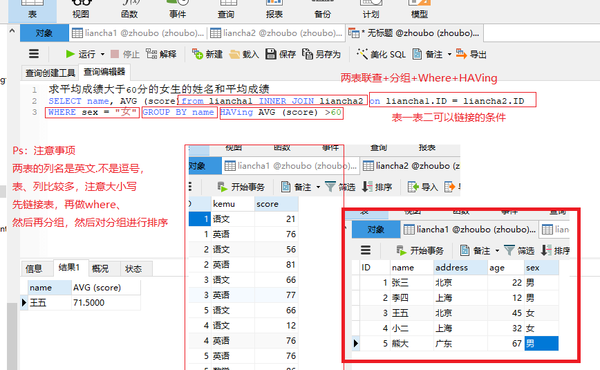
SELECT name, AVG (score)from liancha1 INNER JOIN liancha2 on liancha1.ID = liancha2.ID
WHERE sex = "女" GROUP BY name HAVing AVG (score) >60
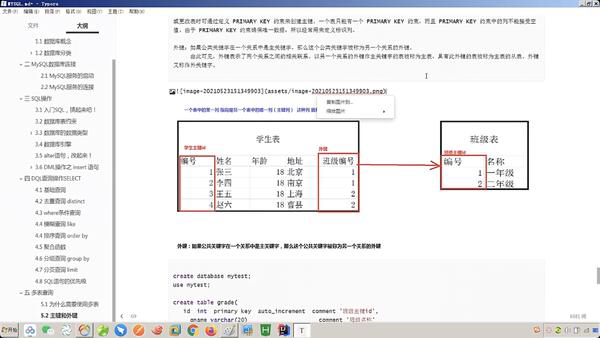
主键和外键
两表联查一定要知道主键和外键的区别
一个表中的某一列,指向另一个表中唯一一列(主键列)这种列就称之为外键
在左右连接的时候,就要注意是以哪个表为主
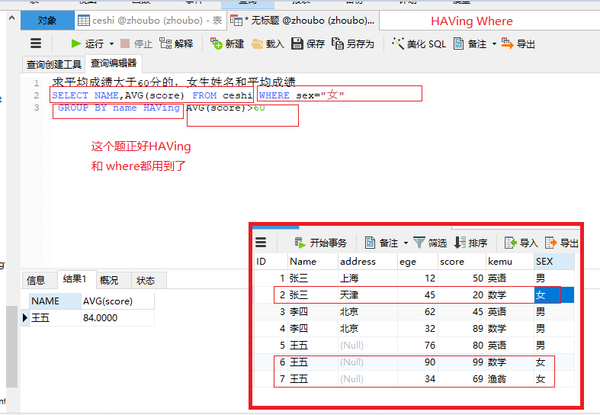
HAVing+Where
SELECT NAME,AVG(score) FROM ceshi WHERE sex="女"
GROUP BY name HAVing AVG(score)>60
两表联查
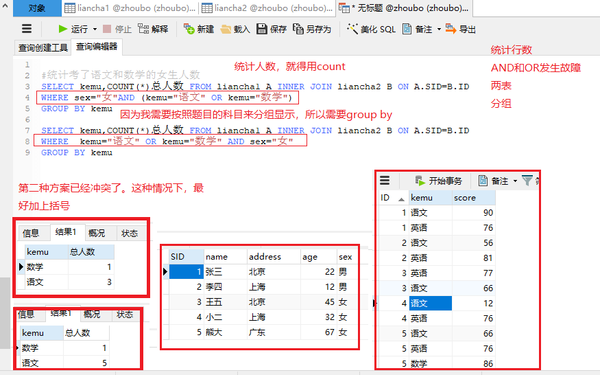
两表INNER join+统计行数count(*)+分组group by+OR/and发生错误
#统计考了语文和数学的女生人数
SELECT kemu,COUNT(*)总人数 FROM liancha1 A INNER JOIN liancha2 B ON A.SID=B.ID
WHERE sex="女"AND (kemu="语文" OR kemu="数学")
GROUP BY kemu
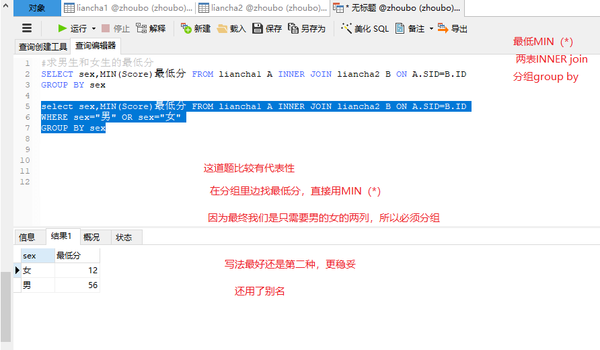
两表INNER join+最低MIN(*)+分组group by
#求男生和女生的最低分
select sex,MIN(Score)最低分 FROM liancha1 A INNER JOIN liancha2 B ON A.SID=B.ID
WHERE sex="男" OR sex="女"
GROUP BY sex
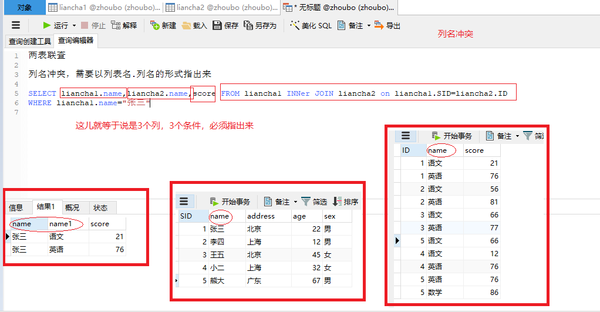
列名冲突,需要以列表名.列名的形式指出来
SELECT liancha1.name,liancha2.name,score FROM liancha1 INNer JOIN liancha2 on liancha1.SID=liancha2.ID
WHERE liancha1.name="张三"
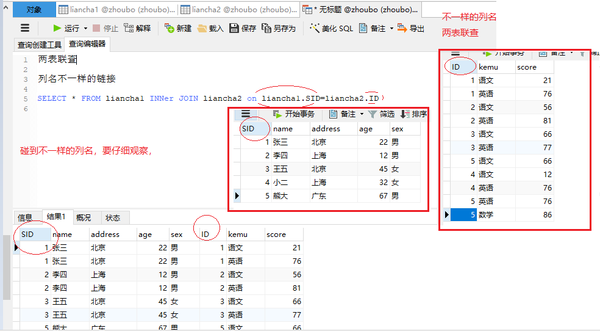
列名不一样的链接
SELECT * FROM liancha1 INNer JOIN liancha2 on liancha1.SID=liancha2.ID
as 新名(别名)
SELECT sex ,name,SUM(Score) as总分 FROM ceshi
WHERE SEX ="女" GROUP BY Name
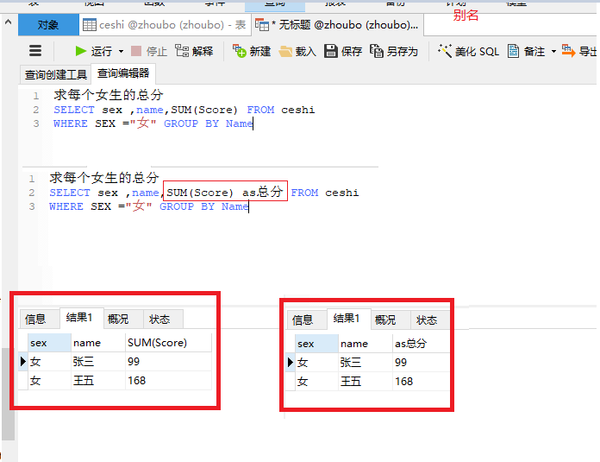
group by 分组
group by+聚合函数
考过1门以上的学生的信息
SELECT name,count()考试次数 from ceshi group by name HAVING COUNT()>2

每门课都大于60分的学生姓名
子查询
SELECT DISTINCT name from ceshi
WHERE name not in (SELECT DISTINCT name FROM ceshi where score<60)
分组+聚合函数
SELECT name,score from ceshi GROUP BY name HAVING MIN(score)>60
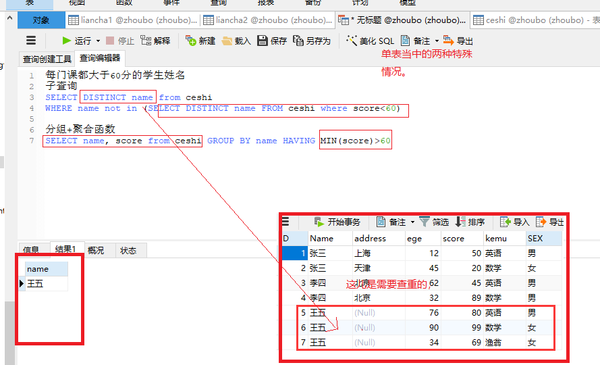
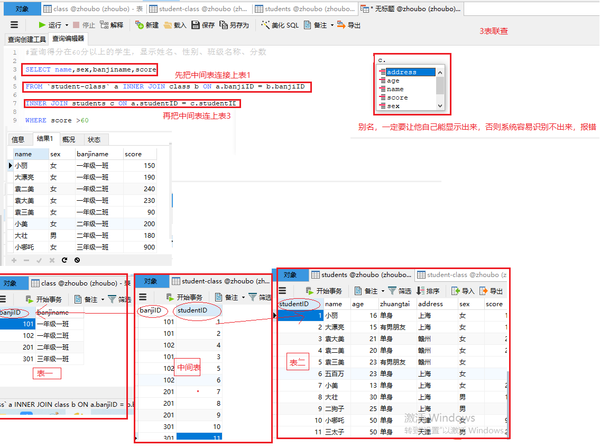
三表联查
三表联查+MAX+分组
#查询每班分数最高的学生
SELECT banjiname,name,MAX(score)分数
FROM student-class a INNER JOIN class b ON a.banjiID = b.banjiID
INNER JOIN students c ON a.studentID = c.studentID
GROUP BY banjiname
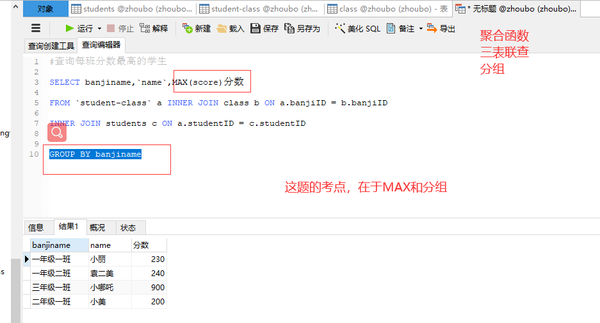
三表联查+聚合函数+分组
#查询班级名称、和所有班中的女生的人数和平均分
SELECT banjiname,sex,count(*)人数,AVG(score)平均分
FROM student-class a INNER JOIN class b ON a.banjiID = b.banjiID
INNER JOIN students c ON a.studentID = c.studentID
WHERE sex="女"
GROUP BY banjiname
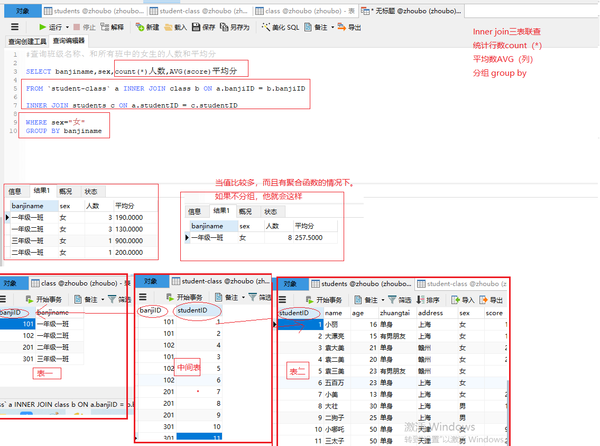
普通三表联查
#查询得分在60分以上的学生,显示姓名、性别、班级名称、分数
SELECT name,sex,banjiname,score
FROM student-class a INNER JOIN class b ON a.banjiID = b.banjiID
INNER JOIN students c ON a.studentID = c.studentID c.
WHERE score >60
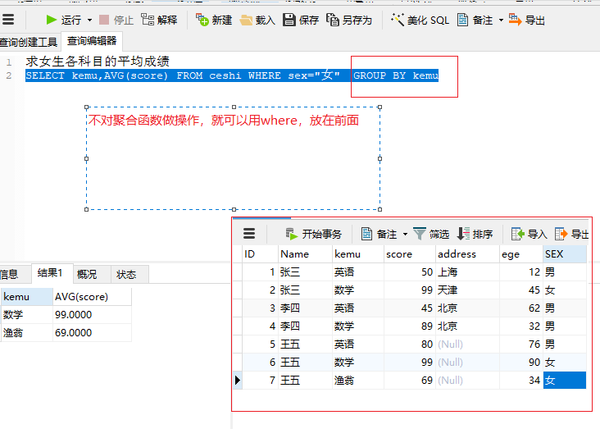
group by (对非聚合函数)再排序
SELECT kemu,AVG(score) FROM ceshi WHERE sex="女" GROUP BY kemu
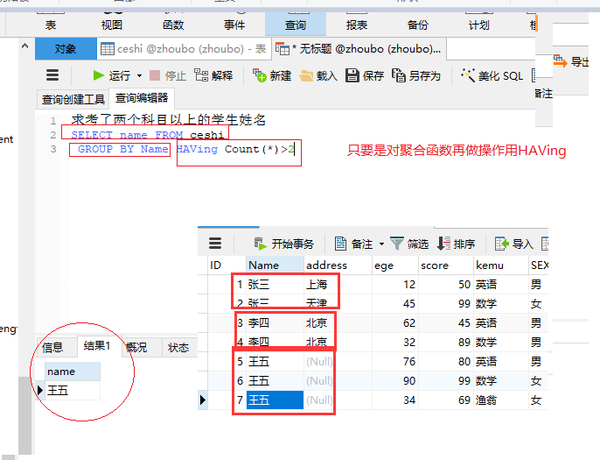
group by (再对聚合函数做操作)
求考了两个科目以上的学生姓名
SELECT name FROM ceshi GROUP BY Name HAVing Count(*)>2
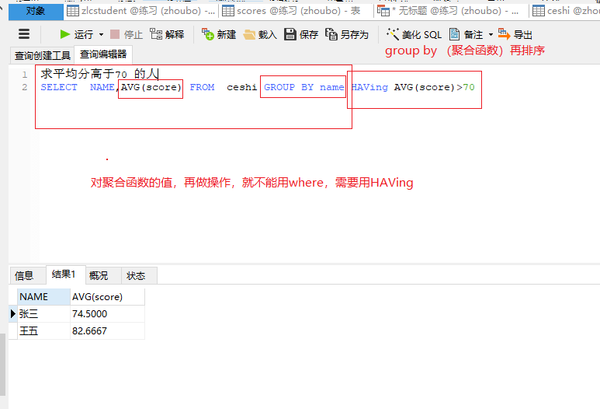
group by (聚合函数)再排序
SELECT NAME,AVG(score) FROM ceshi GROUP BY name HAVing AVG(score)>70
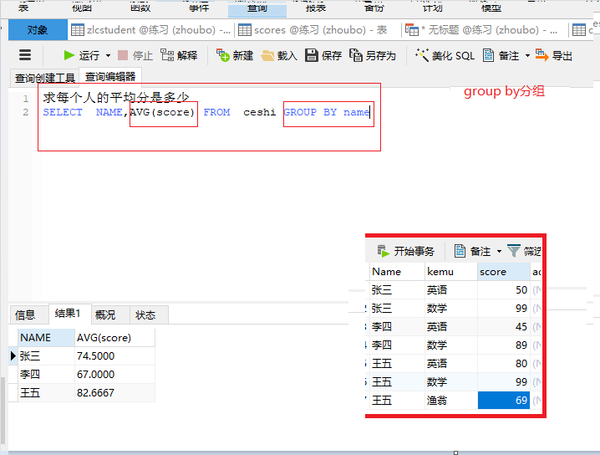
group by 分组(再求最平均)
SELECTNAME,AVG(score) FROM ceshi GROUP BY name
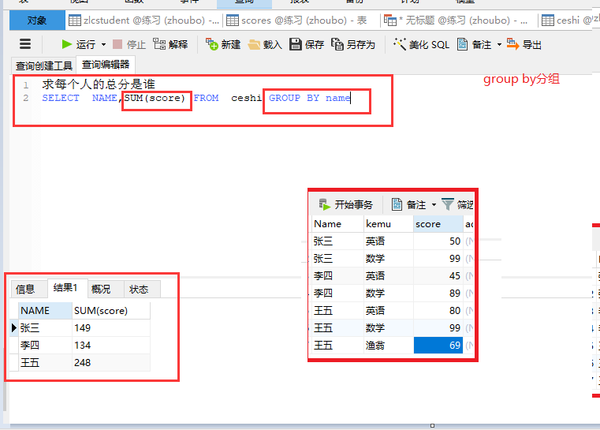
group by 分组(再求和)
SELECTNAME,SUM(score) FROM ceshi GROUP BY name
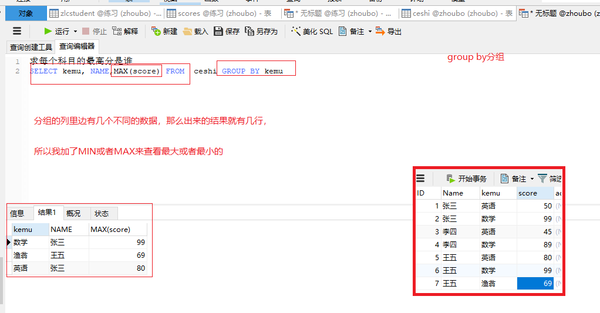
group by 分组(再求最小/大值)
SELECT kemu, NAME,MAX(score) FROM ceshi GROUP BY kemu
SELECT kemu, NAME,MIN(score) FROM ceshi GROUP BY kemu
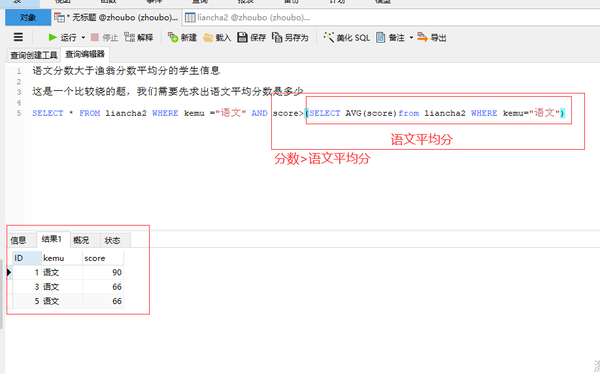
子查询
语文分数>语文分数平均分的学生信息
这是一个比较绕的题,我们需要先求出语文平均分数是多少
SELECT * FROM liancha2 WHERE kemu ="语文" AND score>(SELECT AVG(score)from liancha2 WHERE kemu="语文")
Not in 不包含子查询
SELECT NAME,score FROM ceshi
WHERE name not in (SELECT name FROM ceshi WHERE score<60 )
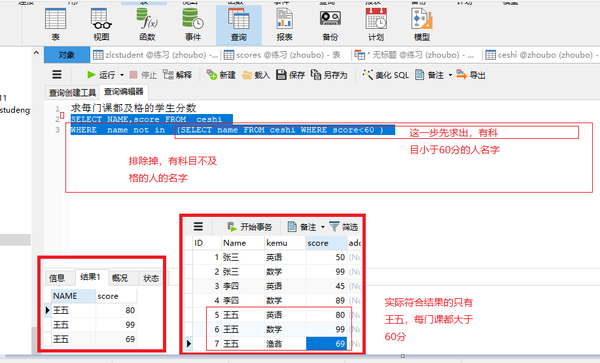
in like(%%)子查询包含
SELECT kemu,score FROM scores
WHERE kemu ="语文" AND id in (SELECT id FROM zlcstudent WHERE address LIKE "%周口%")
子查询不包含not in like(%%)
SELECT kemu,score FROM scores
WHERE kemu ="语文" AND id not in (SELECT id FROM zlcstudent WHERE address LIKE "%周口%")
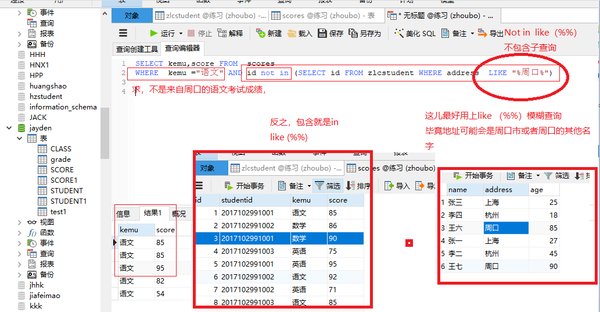
子查询=
SELECT * FROM scores WHERE score >5 AND id = (SELECT id FROM zlcstudent WHERE address = "周口")
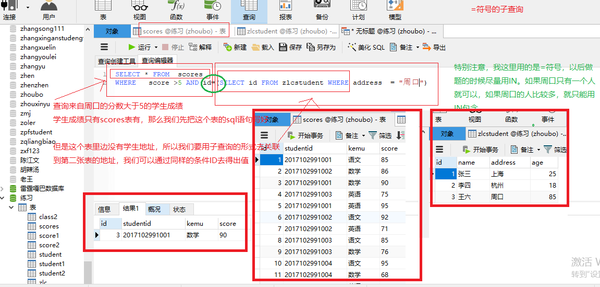
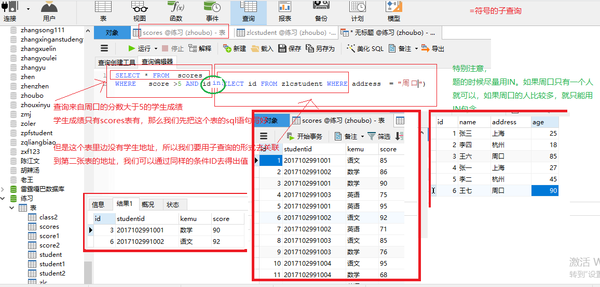
子查询in
SELECT * FROM scores WHERE score >5 AND id in (SELECT id FROM zlcstudent WHERE address = "周口")
附加项:
本文这里简要介绍MySQL的事务和索引概念。
事务:
具有原子性,(原子为最小质量不可再被分割)
事务中的全部操作在数据库中是不可分割的,要么全部完成,要么全部不执行。是一个不可分割的工作单位。
比如,我们去银行转账,操作可以分为下面两个环节:
(1)从第一个账户划出款项。
(2)将款项存入第二个账户。
[3] 在这个过程中,两个环节是关联的。第一个账户划出款项必须保证正确的存入第二个账户,如果第二个环节没有完成,整个的过程都应该取消,否则就会发生丢失款项的问题。整个交易过程,可以看作是一个事务,成功则全部成功,失败则需要全部撤消,这样可以避免当操作的中间环节出现问题时,产生数据不一致的问题。
从底层逻辑来看,他是一个预操作,就是比如说你去执行3条sql。他虽然每一条都去执行了,但是他的执行,并没有真的落实。事务中只要有一项失败了,其他操作都不算数。
那么实际工作中,事务该怎么去使用呢?
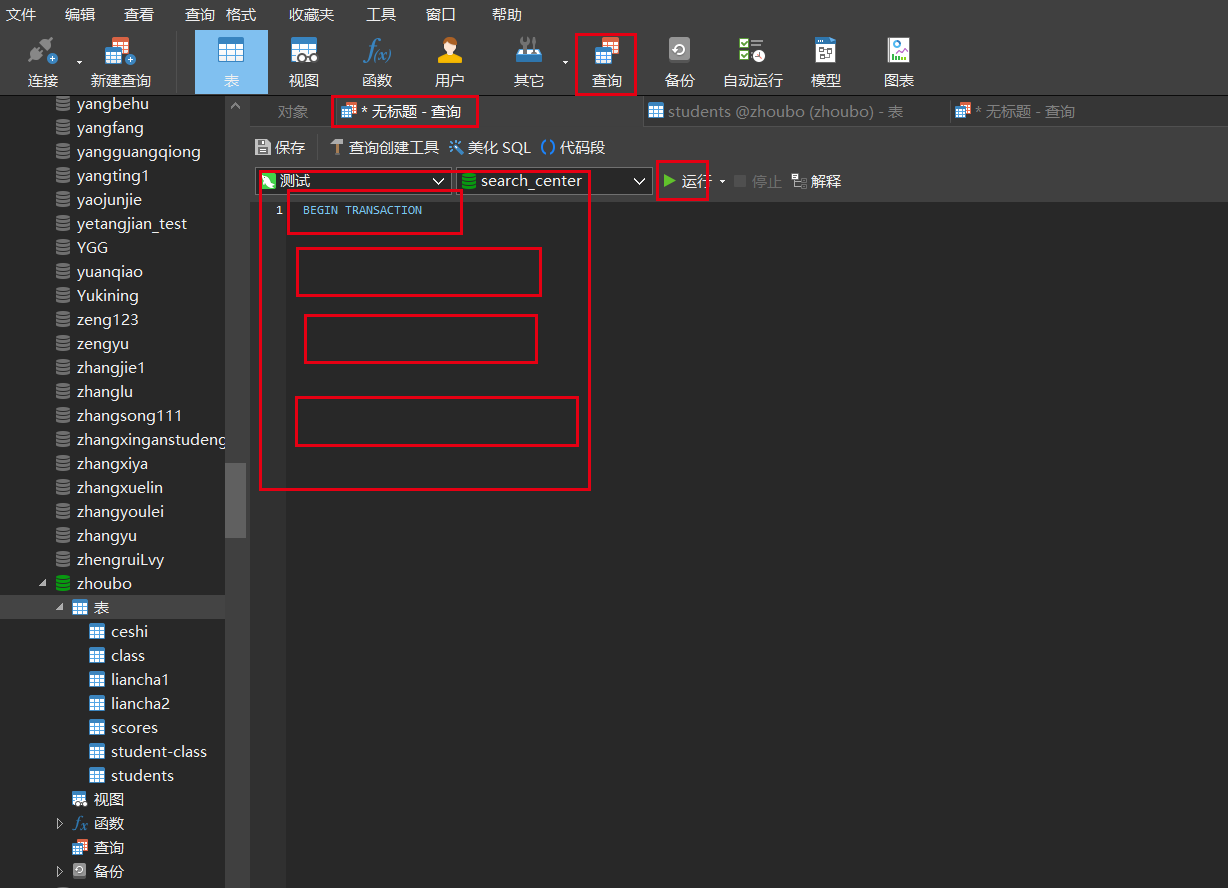
我们需要在我们执行的众多SQL之前,加一个Begin Transaction。然后去写我们的SQL就行了。然后运行。
Begin Transaction(开始事务)(数据库高难度,最容易问的问题,切记多默写几遍,最好去尝试执行一下)
Begin /bɪˈɡɪn/
Transaction /trænˈzækʃ(ə)n/
索引
增删改查以及稍复杂些的比如连接操作,基本都需要先锁定数据位置,再执行操作。而定位这个步骤,如果没有索引,是非常“耗时”的操作。
数据库的索引,本质上就像一个目录,可以帮我们快速去定位。提高我们执行SQL的速度。当然了,一般数据要是只有几千条,或者万把条,是看不出来啥区别的,如果数据一旦上了几十几百万条,那就效果出来了。
他的运作原理大概是这样的,假设我们这张表有个几万条数据,我们的数据正好在第10000条和第19999条,那么我们的SQl,会去把整个表去搜索一遍,然后最终返回这两条
那么我们如果去把C加入了索引,那么我们的SQl执行过程,第一步就会先直接定位到索引中的所有C。然后直接返回数据。
这样就能提高效率了。

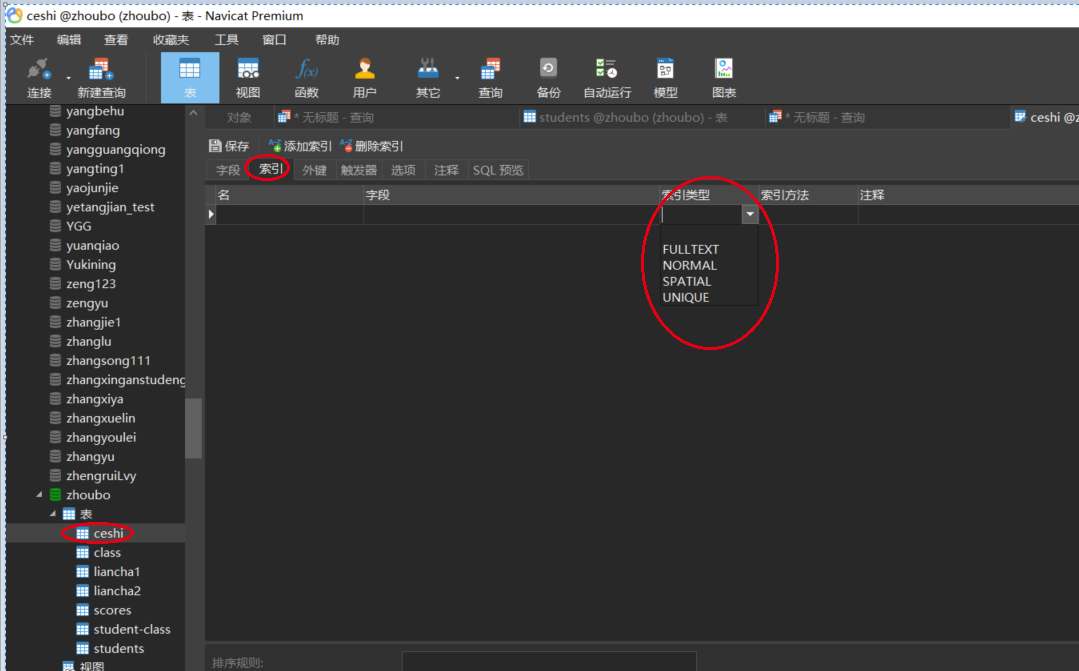
我们也可以自己在navicat去自己建索引,选中表名右键,设计表,然后选择上方的索引。就可以了,索引一共分为4种
1.Normal普通索引,基本的索引,没有任何限制,用于加速查询,数据可以重复
2.组合索引,指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用
3.Full Text全文索引,用来查找文本中的关键字
4.Unique唯一索引,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
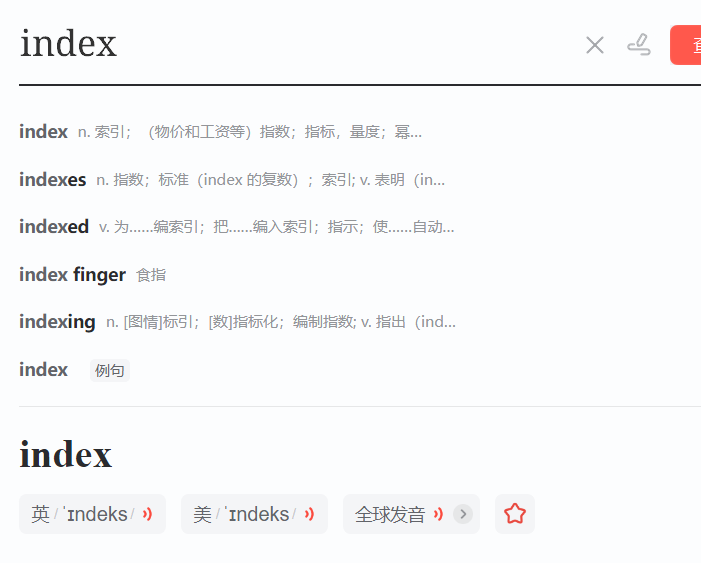
索引的英文叫index。如果我们在工作中看到这样的,带index的就是索引名称了