前几次内容分享,我们逐步搭建了传统hadoop大数据平台、zookeeper、kafka集群等。
假设现在一个场景是:今天产品经理提了1个优先级极高的需求:应用系统前端埋点数据都需要被采集到大数据平台hadoop上。
“前端埋点数据的采集系列”,主要分为以下5个部分:
一、采集系统架构设计
二、mock应用系统10万条前端埋点数据
三、Flume采集数据
四、Flume消费Kafka数据到HDFS
五. 前端埋点数据采集总结
一、明确项目目标设计方案
这个需求意味着公司项目开始由javaweb端的数据走向大数据平台,再到数仓平台,最终由报表系统、用户画像系统、推荐系统等展示数据分析平台,来监控经营决策和衡量公司业绩。
1、明确项目目标
- 首先,我们要明确项目目标:前端埋点数据需要从javaweb端上传采集到大数据平台HDFS端。
- 其次,前端APP、H5、PC、小程序等产生的数据分为两大类:一类是业务数据,比如用户的交易、下单、支付、退单等在应用系统的数据库存储;
- 第二类是埋点数据,比如用户的手机型号、位置、点击屏幕、购买路径等行为会由应用系统写到日志文件log中。
- 需要采用不用的采集方法。
2、设计方案
-
前端埋点的采集我们有很多方案:
- 可以通过自行编写java代码来模拟实现生成数据到本地文件;
- 也可以通过第三方工具,埋点系统工具来实现日志的生成。比如:友盟和talking data、神策平台、后裔采集器等等。
- 梳理本地数据被采集到HDFS上的过程
- flume采集数据到kafka
- Kafka生产和消费数据
- flume消费kafka数据到HDFS上
二、应用系统架构设计
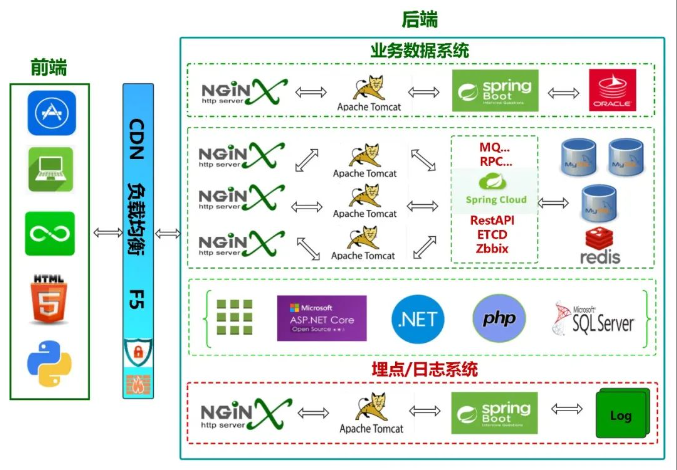
我们首先需要了解应用系统涉及架构以及数据的流向。
1、前端
大前端数据来源包括:APP、PC、小程序、H5、爬虫等数据;
2、CDN
主要组成部件是:防火墙、网络安全设施、F5、负载均衡等。我们关注的点是数据来源,其实这层对企业来说非常重要涉及网络信息安全、负载等等。
3、后端
后端这里分成两大类:主要是根据数据结构来分。
1)业务数据系统
- 单体架构单nginx,单tomcat,基于SpringBoot,单数据库Oracle;
- 分布式架构多负载均衡多个nginx,下挂多个tomcat的,基于SpringCloud,分布式数据库mysql、非关系型数据库redis;
- 其他架构:如:基于ASPnet Core、net、php、sqlserver数据库的;
2)日志埋点数据系统
基于SpringBoot生成log到服务器。前端埋点的日志会被系统采集到log文件夹里面存放在服务器。
三、采集系统整体架构设计
采集系统的架构设计:
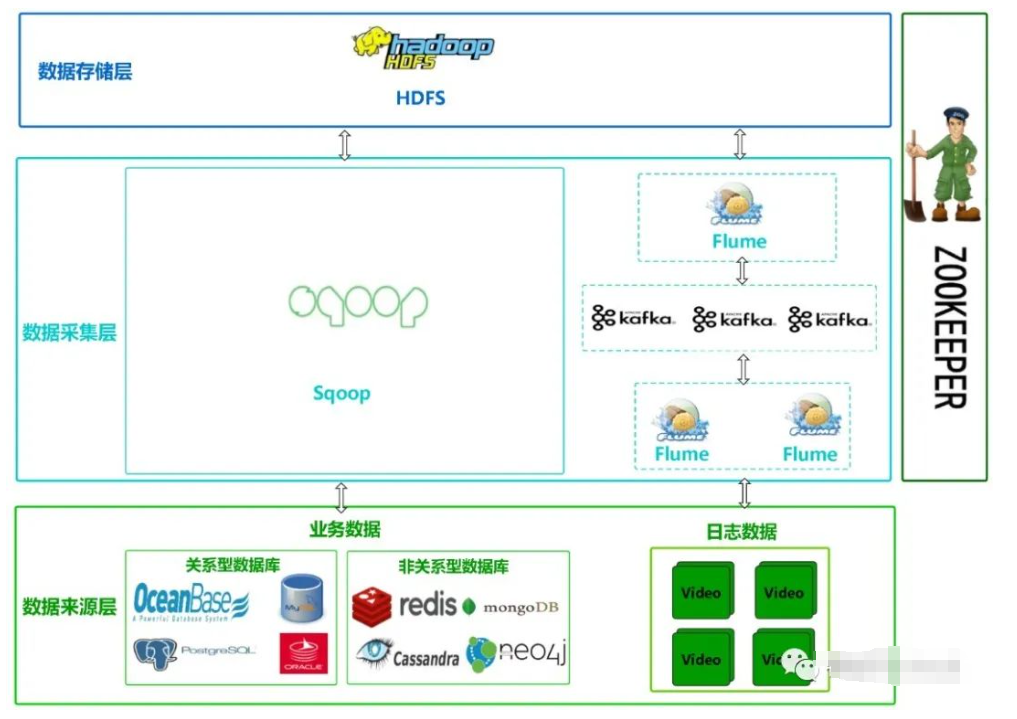
-
从底层数据业务类型来看分为两大类:埋点日志和业务系统数据
- 逻辑分层来看:分为三层
- 数据来源层
- 数据采集层
- 数据存储层
1、数据来源层
- 业务数据
- 关系型数据库数据
常用常见的如:传统型Oracle、互联网公司Mysql、PGsql、OceanBase来自阿里系已经独立奥星贝斯公司。属于国产化数据库,工行目前对公理财已经使用,部分中小型银行中原银行等也已经使用。对于金融行业近年来一直要求新创,未来应该会成为主流数据库。
非关系型数据库Not Only Sql数据基于键值存储的redis;基于文档数据库mongoDB;基于图形存储的Neo4j
基于宽列存储的Cassandra; - 日志数据作为一种非结构化数据,如:log、video、picture等。
2、数据采集层
- 业务数据采集 业务系统数据库产生的数据,需要通过分布式组件Sqoop来采集。sqoop主要用于在Hadoop(Hive)与传统的数据库(mysql)间进行数据的传递,可以将一个关系型数据库(例如:MySQL ,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- 日志数据采集日志作为一种非结构化数据,如:log、video、picture等。采集到HDFS平台,需要通过flume、kafka等组件完成。涉及到服务器采集的选型通道的建立等等。
3、数据存储层
Hadoop集群数据存储主要是数据存在分布式文件系统HFDS上,后面会使用hive存储。
4、注册中心zookeeper
它提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
总结:
- 先了解应用程序简单基本架构
- 了解大数据平台数据采集架构
- 涉及到项目管理知识,当你拿到一个项目首先要明确PM给你的项目目标是什么?你需要交付什么?然后拆分项目目标,拆分梳理实现项目目标的流程步骤,设计整体方案。