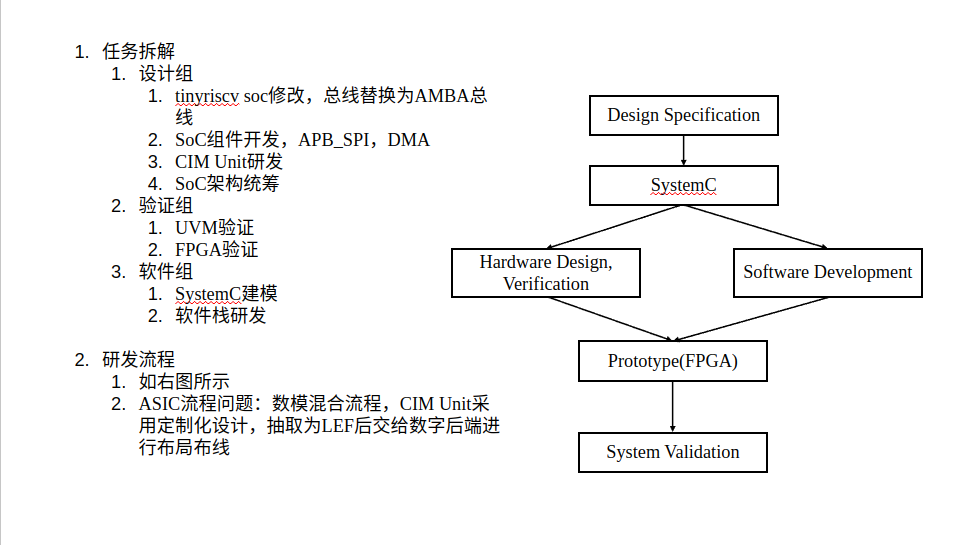
RISC-V SoC研发flow的总结
今年的流片接近尾声了,我个人的评价是相比去年,在进度管理和流程管理上做的更好了一些。对比今年一月份开会时开会的PPT,基本上当时的规划和目标基本上都达成了。这次聊聊整个研发过程中的一些感悟。
首先是对于整个团队的研发方向做了一个比较大的修正,大概是从22年开始,参与和主导了近存/存内多核处理器的一些工作,两年时间摸索下来,虽说也有一些成果,但感觉到的问题也很多。最主要的瓶颈是采用高度定制化的软硬件栈的研发成本问题,仅仅是硬件可能还好,但如果涉及到从汇编器,到编译器,到仿真器,到多核的编程框架,再到顶层的算子库开发这样的一整套软件栈都要自己进行研发,而且还得考虑到软硬件协同的问题,很多硬件上没有设计好的部分(比如缓存一致性)都是在给软件埋坑。这样的工作量对于我们现在的小作坊研发团队来说是不切实际的,尤其是在极其缺乏软件研发人员的情况下。即使强行沿着这条路往下去做,每次工作迭代时依然有过多的工作量,会影响后面的流片进度,且能够拿到的总的流片面积也是有限的,总体来说过于得不偿失。所以痛定思痛之后,我最后决定(也是顺应ISSCC上感受到的趋势),将整体的工作方向从完全自研的架构转换回RISC-V生态上,做RISC-V的SoC。
切换到RISC-V的生态之后,最直接的感受是研发上的压力小了很多,有大量的轮子可以直接复用。聊一聊这次我们主要利用的一些开源组件:
- tinyriscv:一个国人开源的RISC-V SoC,挑选它的理由是足够轻量,足够简单,但是麻雀虽小五脏俱全,包括JTAG调试接口之类的组件,CPU,外设都有了。同样是知名的开源RISC-V SoC,之前打集创赛用过e203的SoC,但是在进行权衡之后,我最后还是选了用tinyriscv,因为我们这次要做比较多的自定义修改,以及组内同僚在SoC开发上没有太多经验。我们基本上保留了原tinyriscv中的CPU和JTAG部分,主要修改了其自定义的rib总线,替换为了更标准更通用的AMBA总线。
- CMSDK:集创赛ARM杯的老朋友,选用CMSDK有多方面的考虑,虽然我们不使用Cortex-M3作为CPU,但是并不影响我们利用CMSDK里面的总线矩阵组件和外设组件等。CMSDK足够全面,可以帮助我们快速搞定这次的SoC开发工作。即使偶有缺的IP(比如SPI和DMA)我们也可以很容易的找到AMBA总线的开源IP来使用,或者基于开源IP做修改,比如从freecores里面去找,相比tinyriscv本来的自定义rib总线显然要方便得多。
- RISC-V-TLM:这次仿真器我们没有从头自己研发,而是直接使用了一个基于SystemC TLM的开源仿真器。之前写了一些SystemC有关的博客,其实目的就是为了这次能够使用基于SystemC的仿真器。我们在这个仿真器的基础上挂上了一些自己写的SystemC外设模型。这也是使用RISC-V生态的一个好处,如果从头构建一个仿真器那么时间上的成本太高了。
- riscv-gnu-toolchain:编译器工具链我们使用了riscv-gnu-toolchain作为交叉编译工具链。依然是加入RISC-V生态的优势,gcc,g++,gdb,objdump等一系列工具不需要从头手搓了。大大节省了工作量,可以直接使用成熟的软件工具。
- UVM:这次使用了UVM-1.1d,但是整个UVM框架我们主要是基于张强的《UVM实战》书中的代码进行仿照和修改搭建的,其实严格来说这不应该算开源组件哈哈.......也可以找其他的github上的开源UVM框架,在整个研发过程中的主要工作量其实还是在怎么把框架和自己的设计适配起来。我们这次的UVM验证思路是以SystemC作为reference model,将二进制格式的程序送入到dut(verilog编写的SoC)和reference model中进行比较,比较的对象是每次commit时的指令地址,指令内容,寄存器内容,内存地址,内存内容这些。
总体来说,通过积极使用开源组件,这次开发的工作量被大大减小了。可以说能够比较按时的完成开发进度有这方面决策的功劳,当然也离不开项目组成员日以继夜的努力工作。
最后聊一些对flow的感想:首先是这次引入的SystemC模型和UVM验证两个东西的作用和意义。
开发模拟器的意义不必多说,对于大型软件代码,想在硬件上通过仿真,或者是用fpga进行原型验证,消耗的时间都比较久。通过模拟器则可以更快速的验证软件的行为,对软件进行debug。之前的工作中我们一般是自己造轮子,从零开始编写仿真器,包括对汇编指令的支持,对处理器周期行为的模拟等,使用开源RISC-V-TLM节省的工作量姑且不表,关键是通过SystemC,利用其内建机制可以快速完成一些包括信号传递,周期模拟,导出波形等之前自己搓的仿真器没做好或者不好做的部分,加快了研发进度,减少了很多无效的debug时间,同时SystemC也是工业界上更加成熟的建模方案,我们可以找到不少SystemC建模的参考。尽管我们这次的仿真器更多是完成一个行为级模型的功能,并没有对硬件进行一比一的建模,但已经可以用于软件功能的验证,以及作为UVM验证时的reference model的功能了。
UVM验证主要是解决以前人工验证不全面低效的问题,通过自动化比较的方式可以更全面更快捷的找出设计中的bug。这次应用UVM,我们实际上查出了不少“隐藏”的bug,这种bug一般能够混过人工验证和FPGA验证,比如某个寄存器的错误或者内存的错误,并没有直接影响某段程序的执行结果或者外设功能的体现。但是实际上只是在巧合之下ok的,一旦条件有所变化,这个bug就会引发出问题。类似这种bug出现了很多次,基本上都是依赖UVM查出来的。可以举一个例子,我们有一次发现dut和reference model在堆栈初始化的指令上存在差别,可以理解成两者初始化的堆栈指针位置上有差异,当时是一个DMA的测试程序,两者执行结果上没有看出什么差别,但这是建立在程序本身很简单且规模小的基础上的,堆栈本身只被用掉了很小的一部分,所以没有出现任何异常。但如果编写的程序规模增大,会大量利用堆栈的话,那么dut就会因为这个问题提前爆栈,显然这是一个严重的问题,但是在我们简单的测试程序中,只看结果是发现不了这个问题的。
然后是数模混合flow上的一些改进。之前我们在工作中,对于merge的处理是比较简单粗暴的,直接把数字当成一个模块去综合,产生gds,然后和模拟的部分做手动连接。这样的问题是,首先无法做自动布局布线,有大量的手动连线的工作量,其次是在进行设计时并不好把模拟模块的timing给考虑进去,最后是数字和模拟的merge存在串行的关联,会影响整体的进度。针对这个问题,我们这次对模拟模块做了IP化的处理,即先对模拟模块编写.lib和抽取.lef,将模拟模块和数字模块的merge统一纳入到数字后端的flow中,这样就可以完成模块之间的自动连线,并且模拟模块和数字模块的后端可以并行进行,以lef为接口最后统一即可。当然,timing的问题这次由于时间和水平不够,在编写.lib时没有用k库的手段,而是自己手动编写的,并没有去把模拟模块接口处的timing(更毋论power了)编写进去,尽管我们以前做过标准单元库用Cadence Liberate进行k库的flow,但是这次没来得及在整个macro上再做一次。后续可以再把这个flow给规范化一下之后用到模拟模块的IP化的flow中,到时候也会写篇博客讲讲这个过程。由于没有模块的timing模型,所以只能通过数模混合后仿真,然后对模拟模块进行调整来确保时序了,数字这边在接口上确实难以设置constraint。
此外在数模混合验证上,这次依托于所里的强大服务器,可以把整个chip的数模部分都带上进行混合仿真了。等后续数字后端那边吐sdf了之后会再做一下AMS的混合后仿。到时候会把这个flow也记录到博客里。
最后是团队的管理,个人认为这次分组分工的规划是比较有成效的,尽管有部分能力比较强的个人去做了跨组的工作,以及一直在所有组和流片phase之间游走的我自己,但大部分人基本上只是专注于自己那部分的工作,这样的好处就是避免了分散精力,提高了效率,并且把位置和人固定下来之后,可以通过反复的项目上的training对自己负责的一块越来越熟练,效率越来越高,类似于一种工程师化(我个人认为,尽管让大家囿于一个环节上打螺丝也许不符合教育的初衷,但是也要考虑的实际问题是并不是每个人都能精力和能力去掌握流片的完整flow的,此外去工作时,对多数人来说也只是做对口岗位上的工作,并不是人人都要去当全栈工程师,虽然在平时我会努力把每个flow怎么做去share给小组里的同僚,但我觉得从小组合作,以及未来发展的角度来说,有一门精通的拿手活是强过门门都做过但门门都没有什么成体系的工作经验的,至少我觉得在这次的项目里,做SystemC模型,做UVM,做RISC-V SoC的同僚,负责的工作量都已经是比较完整,可以自豪的写上简历的了)。当然,也需要Leader在顶层规划,工作分配,以及跨组合作交流时当好润滑剂作用,把调配工作处理好(我就是那个多而不精的哈哈)。